У сучасну епоху цифрових технологій дані є основою успіху кожної організації. Одним із найбільш часто використовуваних форматів для обміну даними є XML. Аналіз XML-файлів важливий з кількох причин. По-перше, XML-файли використовуються в багатьох галузях промисловості, включаючи фінанси, охорону здоров’я та уряд. Аналіз XML-файлів може допомогти організаціям отримати розуміння своїх даних, дозволяючи їм приймати кращі рішення та покращувати свою діяльність. Аналіз файлів XML також може допомогти в інтеграції даних, оскільки багато програм і систем використовують XML як стандартний формат даних. Аналізуючи XML-файли, організації можуть легко інтегрувати дані з різних джерел і забезпечити узгодженість у своїх системах. Однак XML-файли містять напівструктуровані, дуже вкладені дані, що ускладнює доступ до інформації та її аналіз, особливо якщо файл великий і має складна, дуже вкладена схема.
XML-файли добре підходять для додатків, але вони можуть бути не оптимальними для аналітичних механізмів. Щоб підвищити продуктивність запитів і забезпечити легкий доступ у низхідних аналітичних механізмах, таких як Амазонка Афіна, дуже важливо попередньо обробити XML-файли у стовпчастий формат, як-от Parquet. Ця трансформація дозволяє підвищити ефективність і зручність у робочих процесах аналітики. У цій публікації ми покажемо, як обробляти дані XML за допомогою Клей AWS і Афіна.
Огляд рішення
Ми досліджуємо дві різні техніки, які можуть оптимізувати робочий процес обробки файлів XML:
- Техніка 1: використовуйте сканер AWS Glue і візуальний редактор AWS Glue – Ви можете використовувати інтерфейс користувача AWS Glue у поєднанні зі сканером, щоб визначити структуру таблиці для файлів XML. Цей підхід забезпечує зручний інтерфейс і особливо підходить для осіб, які віддають перевагу графічному підходу до керування своїми даними.
- Техніка 2: використовуйте AWS Glue DynamicFrames із визначеними та фіксованими схемами – Сканер має обмеження, коли йдеться про обробку одного рядка у файлах XML розміром більше ніж 1 MB. Щоб подолати це обмеження, ми використовуємо блокнот AWS Glue для створення AWS Glue
DynamicFrames, використовуючи як виведені, так і фіксовані схеми. Цей метод забезпечує ефективну обробку XML-файлів із рядками, розмір яких перевищує 1 МБ.
В обох підходах наша кінцева мета полягає в тому, щоб перетворити файли XML у формат Apache Parquet, зробивши їх легкодоступними для запитів за допомогою Athena. За допомогою цих методів ви можете підвищити швидкість обробки та доступність своїх XML-даних, дозволяючи легко отримувати цінну інформацію.
Передумови
Перш ніж розпочати цей підручник, виконайте наступні попередні умови (вони стосуються обох методів):
- Завантажте файли XML техніка1.xml та техніка2.xml.
- Завантажте файли в Служба простого зберігання Amazon (Amazon S3) відро. Ви можете завантажити їх в одне й те саме відро S3 в різних папках або в різні сегменти S3.
- створити Управління ідентифікацією та доступом AWS (IAM) для вашої роботи ETL або блокнота згідно з інструкціями Налаштуйте дозволи IAM для AWS Glue Studio.
- Додайте вбудовану політику до своєї ролі за допомогою уже: PassRole дія:
- Додайте політику дозволів до ролі з доступом до сегмента S3.
Тепер, коли ми закінчили з попередніми умовами, давайте перейдемо до впровадження першої техніки.
Техніка 1: використовуйте краулер AWS Glue і візуальний редактор
Наступна діаграма ілюструє просту архітектуру, яку можна використовувати для реалізації рішення.
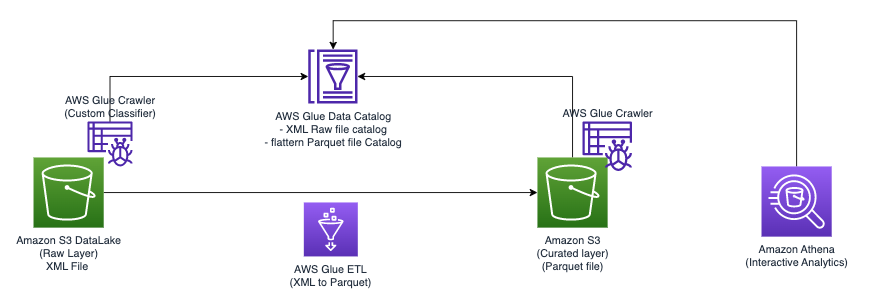
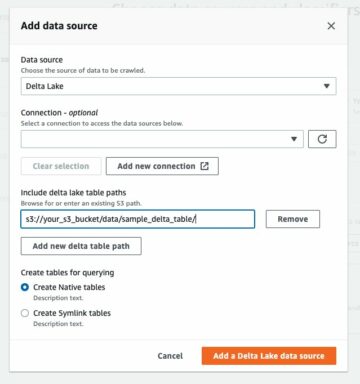
Щоб проаналізувати XML-файли, що зберігаються в Amazon S3 за допомогою AWS Glue і Athena, ми виконуємо такі кроки високого рівня:
- Створіть сканер AWS Glue для отримання метаданих XML і створення таблиці в каталозі даних AWS Glue.
- Обробляйте та перетворюйте XML-дані у формат (наприклад, Parquet), придатний для Athena, за допомогою завдання AWS Glue витягти, трансформувати та завантажити (ETL).
- Налаштуйте та запустіть завдання AWS Glue за допомогою консолі AWS Glue або Інтерфейс командного рядка AWS (AWS CLI).
- Використовуйте оброблені дані (у форматі Parquet) з таблицями Athena, увімкнувши запити SQL.
- Використовуйте зручний інтерфейс Athena для аналізу XML-даних за допомогою SQL-запитів до даних, які зберігаються в Amazon S3.
Ця архітектура є масштабованим, економічно ефективним рішенням для аналізу XML-даних на Amazon S3 за допомогою AWS Glue і Athena. Ви можете аналізувати великі набори даних без складного керування інфраструктурою.
Ми використовуємо сканер AWS Glue для вилучення метаданих XML-файлу. Ви можете вибрати класифікатор AWS Glue за замовчуванням для класифікації XML загального призначення. Він автоматично визначає структуру та схему даних XML, що корисно для поширених форматів.
У цьому рішенні ми також використовуємо спеціальний класифікатор XML. Він розроблений для конкретних схем або форматів XML, що дозволяє точно видобувати метадані. Це ідеально підходить для нестандартних форматів XML або коли вам потрібен детальний контроль над класифікацією. Спеціальний класифікатор забезпечує вилучення лише необхідних метаданих, що спрощує подальшу обробку та аналіз. Цей підхід оптимізує використання ваших файлів XML.
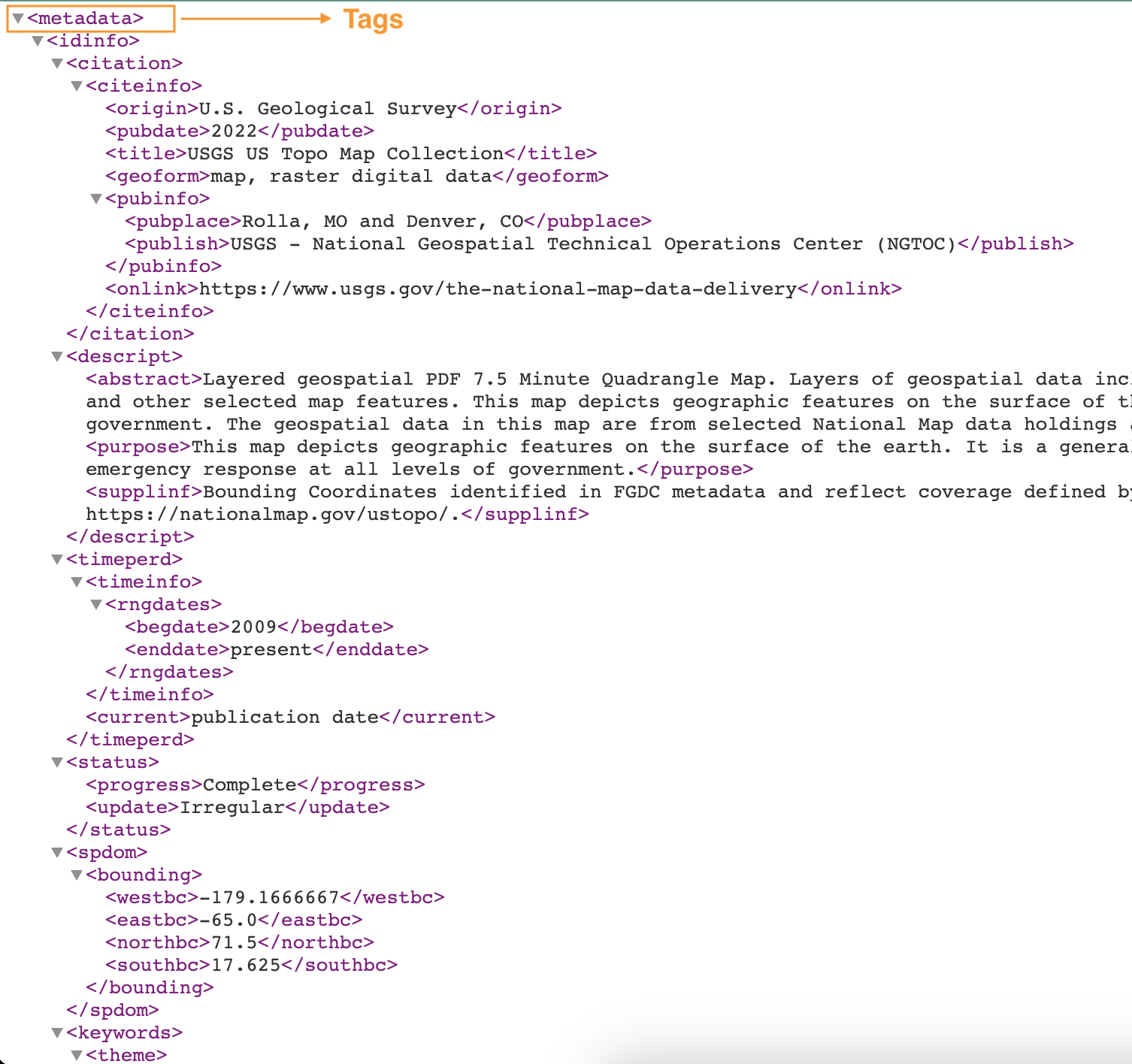
На наступному знімку екрана показано приклад XML-файлу з тегами.
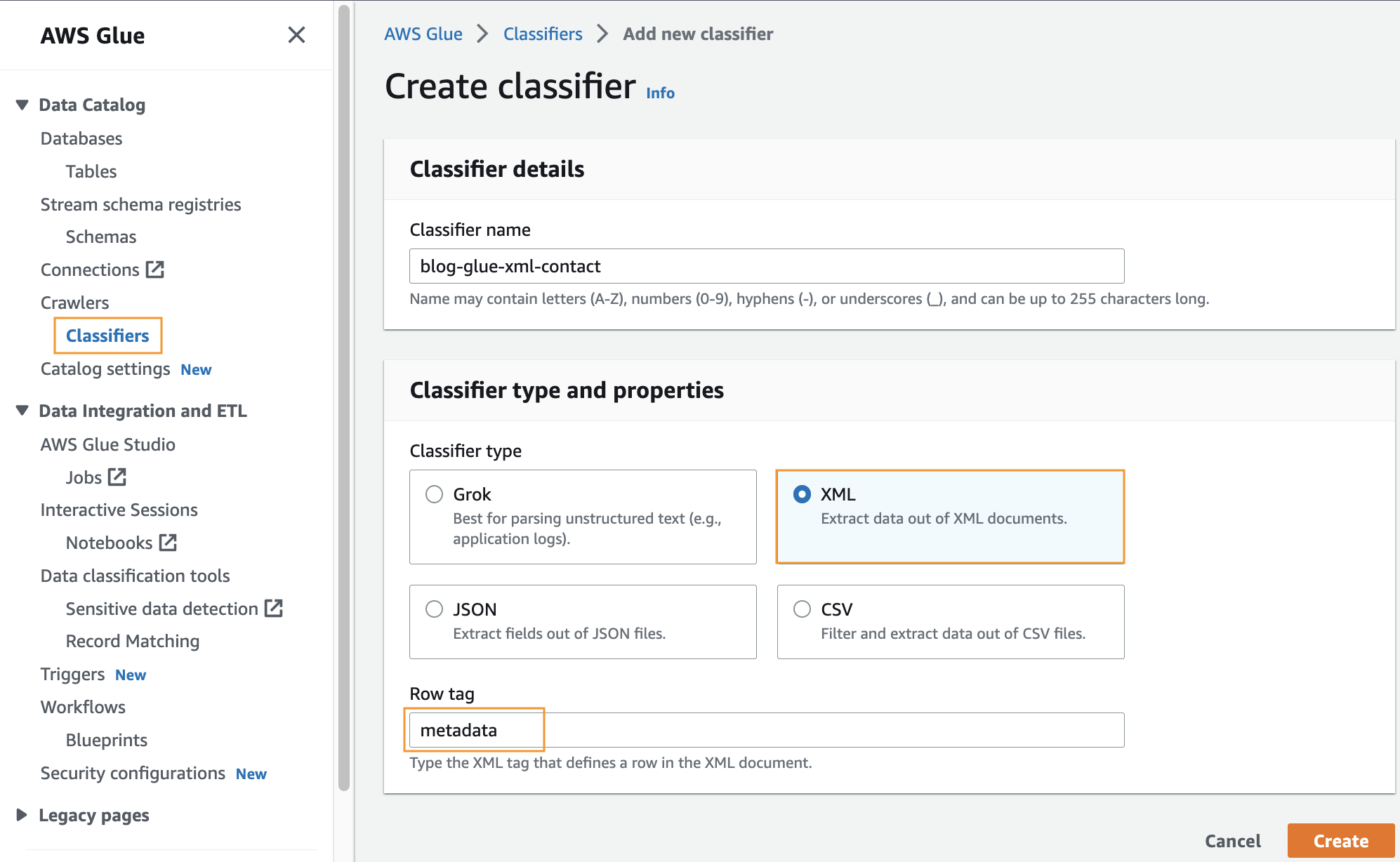
Створіть власний класифікатор
На цьому кроці ви створюєте спеціальний класифікатор AWS Glue для вилучення метаданих із файлу XML. Виконайте наступні дії:
- На консолі AWS Glue, під Гусениці на панелі навігації виберіть Класифікатори.
- Вибирати Додайте класифікатор.
- Select XML як тип класифікатора.
- Введіть назву для класифікатора, наприклад
blog-glue-xml-contact. - для Тег рядка, введіть назву кореневого тегу, який містить метадані (наприклад,
metadata). - Вибирати Створювати.
Створіть AWS Glue Crawler для сканування файлу xml
У цьому розділі ми створюємо Glue Crawler для вилучення метаданих із файлу XML за допомогою класифікатора клієнтів, створеного на попередньому кроці.
Створити базу даних
- Перейти до AWS Glue консольвиберіть Бази даних у навігаційній панелі.
- Натисніть на Додати базу даних.
- Введіть назву, наприклад
blog_glue_xml - Вибирати Створювати Database
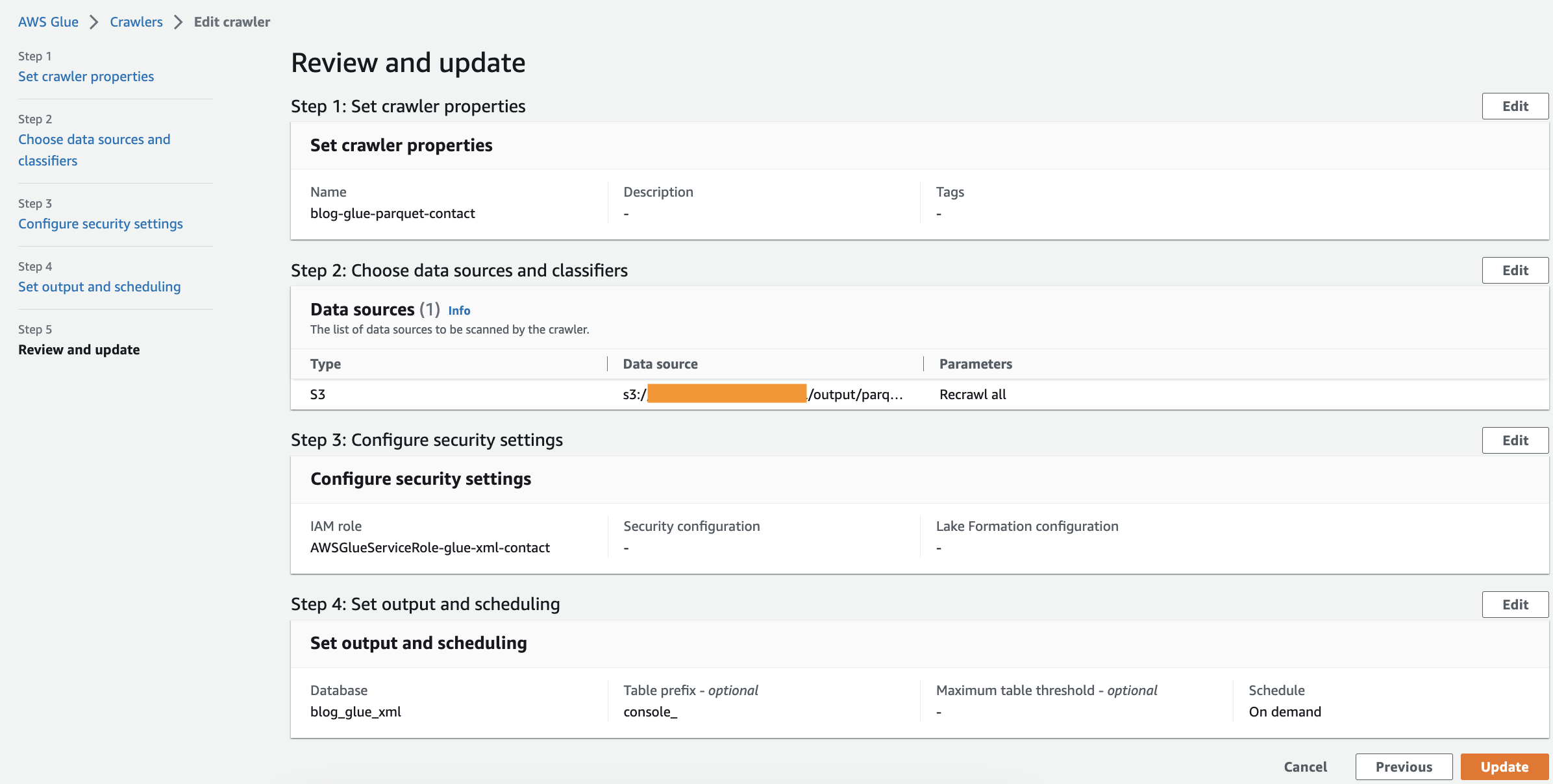
Створіть сканер
Щоб створити свій перший веб-сканер, виконайте наведені нижче дії.
- На консолі AWS Glue виберіть Гусениці у навігаційній панелі.
- Вибирати Створити сканер.
- на Встановити властивості сканера введіть назву для нового сканера (наприклад,
blog-glue-parquet), потім виберіть МАЙБУТНІ. - на Виберіть джерела даних і класифікатори сторінка, виберіть Ще ні при Конфігурація джерела даних.
- Вибирати Додайте сховище даних.
- для Шлях S3, перейдіть до
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Переконайтеся, що ви вибрали папку XML, а не файл у папці.
- Залиште решту параметрів за замовчуванням і виберіть Додайте джерело даних S3.
- Розширювати Спеціальні класифікатори – необов’язково, виберіть blog-glue-xml-contact, а потім виберіть МАЙБУТНІ і залишити решту параметрів за замовчуванням.
- Виберіть свою роль IAM або виберіть Створити нову роль IAM, додайте суфікс
glue-xml-contact(наприклад,AWSGlueServiceNotebookRoleBlog), і виберіть МАЙБУТНІ. - на Налаштуйте вихід і планування сторінка, під Вихідна конфігураціявиберіть
blog_glue_xmlта цінності Цільова база даних. -
Що натомість? Створіть віртуальну версію себе у
console_як префікс, що додається до таблиць (необов’язково) і під Розклад сканера, залиште встановлену частоту На вимогу. - Вибирати МАЙБУТНІ.
- Перегляньте всі параметри і виберіть Створити сканер.
Запустіть сканер
Створивши сканер, виконайте такі дії, щоб запустити його:
- На консолі AWS Glue виберіть Гусениці у навігаційній панелі.
- Відкрийте створений вами сканер і виберіть прогін.
Роботі сканера знадобиться 1–2 хвилини.
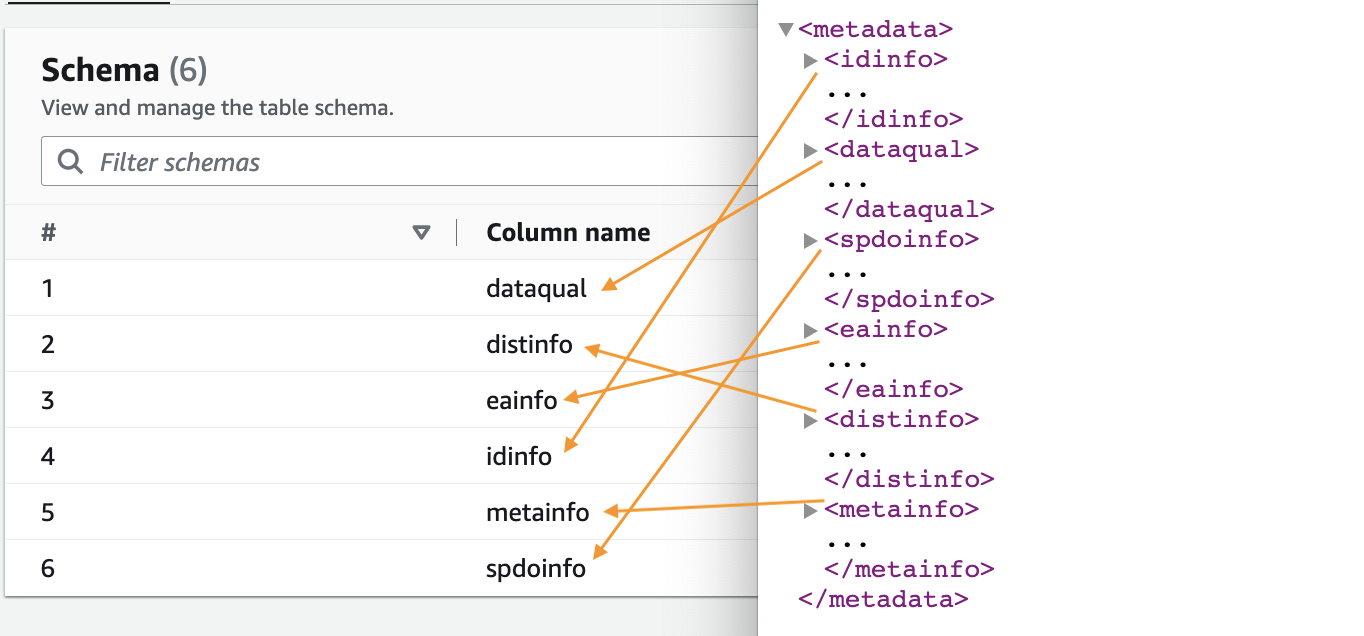
- Коли сканер буде завершено, виберіть Бази даних у навігаційній панелі.
- Виберіть базу даних, яку ви створили, і виберіть назву таблиці, щоб побачити схему, витягнуту сканером.
Створіть завдання AWS Glue для перетворення XML у формат Parquet
На цьому кроці ви створюєте завдання AWS Glue Studio для перетворення файлу XML у файл Parquet. Виконайте наступні дії:
- На консолі AWS Glue виберіть Джобс у навігаційній панелі.
- під Створити роботувиберіть Візуал із чистим полотном.
- Вибирати Створювати.
- Перейменуйте роботу на
blog_glue_xml_job.
Тепер у вас є порожній візуальний редактор завдань AWS Glue Studio. У верхній частині редактора є вкладки для різних переглядів.
- Виберіть Script вкладку, щоб побачити порожню оболонку сценарію AWS Glue ETL.
Коли ми додамо нові кроки у візуальному редакторі, сценарій оновлюватиметься автоматично.
- Виберіть Деталі роботи вкладку, щоб переглянути всі конфігурації завдань.
- для Роль IAMвиберіть
AWSGlueServiceNotebookRoleBlog. - для Клейовий варіантвиберіть Glue 4.0 – підтримка Spark 3.3, Scala 2, Python 3.
- Установка Запитувана кількість працівників в 2.
- Установка Кількість повторних спроб в 0.
- Виберіть Візуальний щоб повернутися до візуального редактора.
- на Source виберіть спадне меню Каталог даних AWS Glue.
- на Властивості джерела даних – Каталог даних надайте таку інформацію:
- для Databaseвиберіть
blog_glue_xml. - для таблицявиберіть таблицю, яка починається з імені console_, створеного сканером (наприклад,
console_geologicalsurvey).
- для Databaseвиберіть
- на Властивості вузла надайте таку інформацію:
- Редагувати ІМ'Я до
geologicalsurveyнабір даних. - Вибирати дію і перетворення Змінити схему (застосувати відображення).
- Вибирати Властивості вузла і змініть назву перетворення зі Змінити схему (Застосувати відображення) на
ApplyMapping. - на Мета меню, виберіть S3.
- Редагувати ІМ'Я до
- на Властивості джерела даних – S3 надайте таку інформацію:
- для сформованийвиберіть паркет.
- для Тип компресіївиберіть Нестиснений.
- для Тип джерела S3виберіть Розташування S3.
- для S3 URL, введіть
s3://${BUCKET_NAME}/output/parquet/. - Вибирати Властивості вузла і змінити назву на
Output.
- Вибирати зберегти щоб зберегти роботу.
- Вибирати прогін щоб запустити роботу.
На наступному знімку екрана показано завдання у візуальному редакторі.
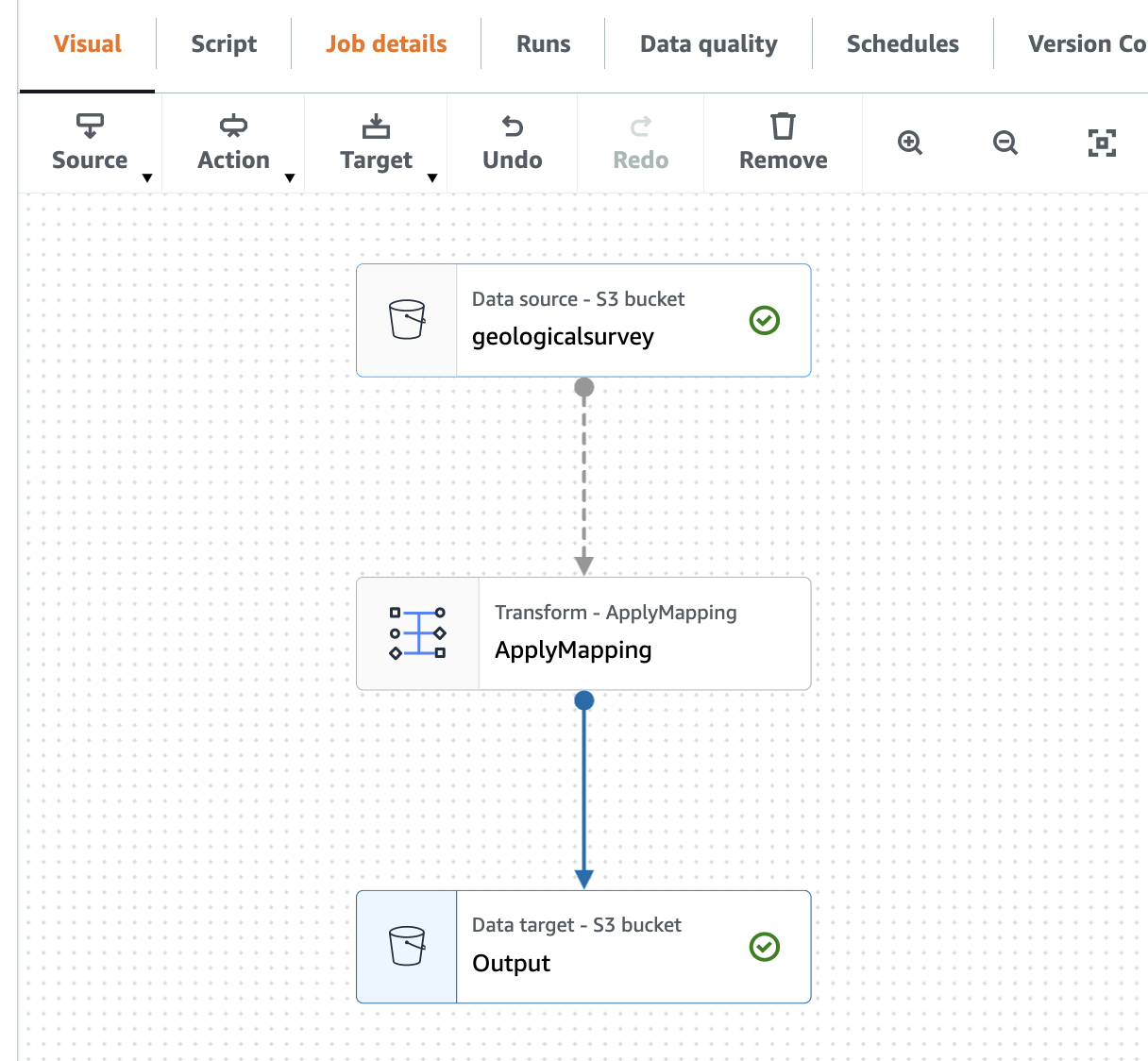
Створіть AWS Gue Crawler для сканування файлу Parquet
На цьому кроці ви створюєте сканер AWS Glue для отримання метаданих із файлу Parquet, створеного за допомогою завдання AWS Glue Studio. Цього разу ви використовуєте класифікатор за замовчуванням. Виконайте наступні дії:
- На консолі AWS Glue виберіть Гусениці у навігаційній панелі.
- Вибирати Створити сканер.
- на Встановити властивості сканера введіть назву для нового гусеничного сканера, наприклад blog-glue-parquet-contact, а потім виберіть МАЙБУТНІ.
- на Виберіть джерела даних і класифікатори сторінка, виберіть Ще ні та цінності Конфігурація джерела даних.
- Вибирати Додайте сховище даних.
- для Шлях S3, перейдіть до
s3://${BUCKET_NAME}/output/parquet/.
Переконайтеся, що ви вибрали parquet папку, а не файл у папці.
- Виберіть свою роль IAM, створену в розділі передумов, або виберіть Створити нову роль IAM (наприклад,
AWSGlueServiceNotebookRoleBlog), і виберіть МАЙБУТНІ. - на Налаштуйте вихід і планування сторінка, під Вихідна конфігураціявиберіть
blog_glue_xmlта цінності Database. -
Що натомість? Створіть віртуальну версію себе у
parquet_як префікс, що додається до таблиць (необов’язково) і під Розклад сканера, залиште встановлену частоту На вимогу. - Вибирати МАЙБУТНІ.
- Перегляньте всі параметри і виберіть Створити сканер.
Тепер ви можете запустити сканер, який займає 1–2 хвилини.

Ви можете попередньо переглянути щойно створену схему для файлу Parquet у каталозі даних AWS Glue, який схожий на схему файлу XML.
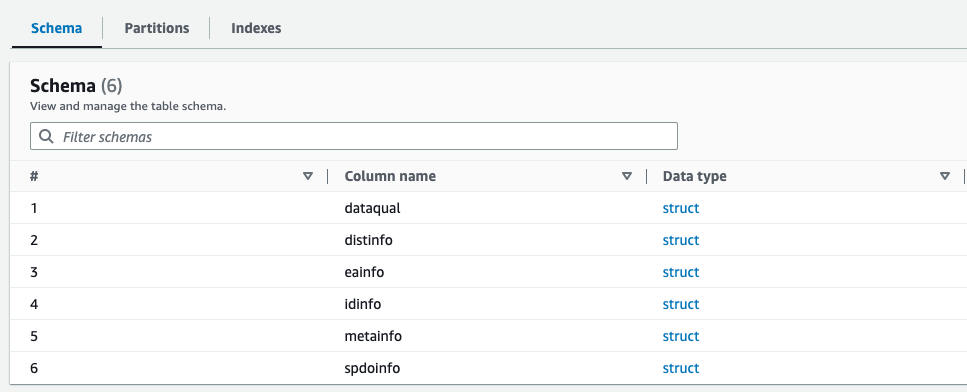
Тепер у нас є дані, які можна використовувати з Athena. У наступному розділі ми виконуємо запити даних за допомогою Athena.
Запитуйте файл Parquet за допомогою Athena
Афіна не підтримує запити Формат файлу XML, тому ви перетворили файл XML у Parquet для більш ефективного запиту та використання даних крапка нотації для запитів складних типів і вкладених структур.
У наступному прикладі коду використовується крапкова нотація для запиту вкладених даних:
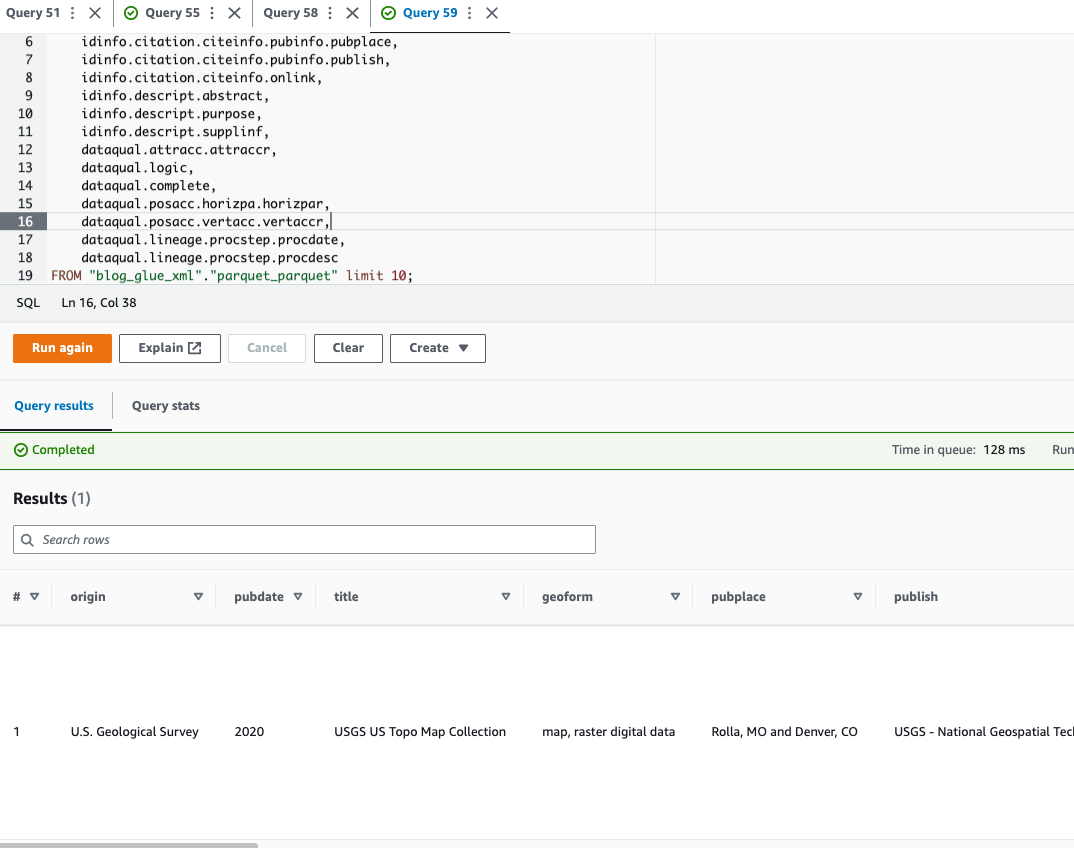
Тепер, коли ми завершили техніку 1, давайте перейдемо до вивчення техніки 2.
Техніка 2: використовуйте AWS Glue DynamicFrames із визначеними та фіксованими схемами
У попередньому розділі ми розглянули процес обробки невеликого файлу XML за допомогою сканера AWS Glue для створення таблиці, завдання AWS Glue для перетворення файлу у формат Parquet і Athena для доступу до даних Parquet. Однак сканер стикається з обмеженнями, коли справа доходить до обробки XML-файлів, які перевищують Розміром 1 МБ. У цьому розділі ми заглибимося в тему пакетної обробки великих XML-файлів, що вимагає додаткового синтаксичного аналізу для вилучення окремих подій і проведення аналізу за допомогою Athena.
Наш підхід передбачає читання файлів XML через AWS Glue DynamicFrames, використовуючи як виведені, так і фіксовані схеми. Потім ми витягуємо окремі події у формат Parquet за допомогою реляціонувати перетворення, що дозволяє нам запитувати та аналізувати їх без проблем за допомогою Athena.
Щоб реалізувати це рішення, ви виконуєте такі кроки високого рівня:
- Створіть блокнот AWS Glue для читання та аналізу файлу XML.
- Скористайтесь
DynamicFramesзInferSchemaщоб прочитати файл XML. - Використовуйте функцію relationalize, щоб роз’єднати будь-які масиви.
- Перетворіть дані у формат Parquet.
- Запитуйте дані Parquet за допомогою Athena.
- Повторіть попередні кроки, але цього разу передайте схему
DynamicFramesзамість використанняInferSchema.
XML-файл із даними про кількість електромобілів містить a response на кореневому рівні. Цей тег містить масив row теги, вкладені в нього. Тег рядка — це масив, який містить набір інших тегів рядка, які надають інформацію про транспортний засіб, включаючи його марку, модель та інші відповідні деталі. На наступному знімку екрана показано приклад.

Створіть блокнот AWS Glue
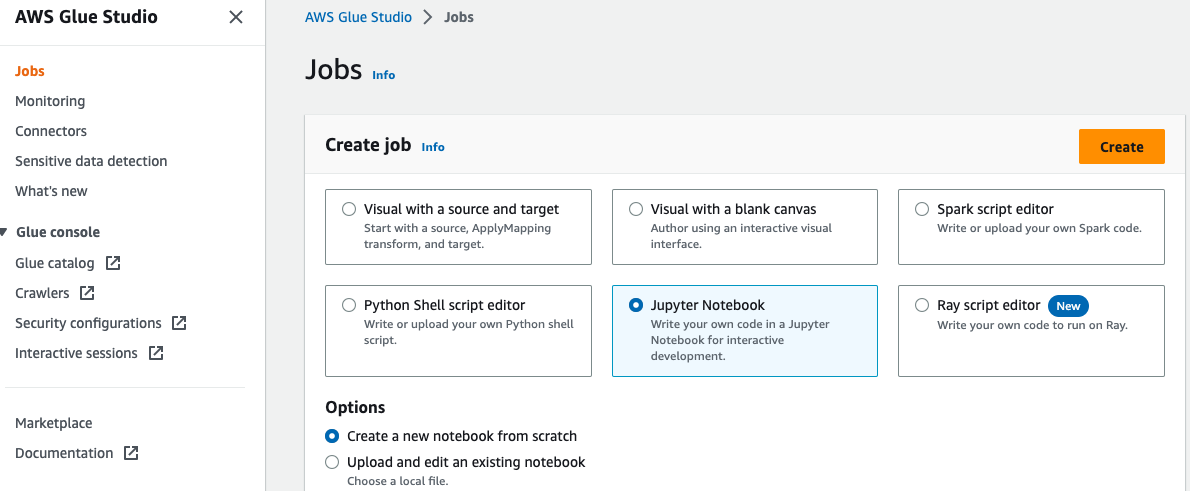
Щоб створити блокнот AWS Glue, виконайте такі дії:
- Відкрийте AWS Glue Studio консоль, виберіть Джобс у навігаційній панелі.
- Select Jupyter Notebook І вибирай Створювати.
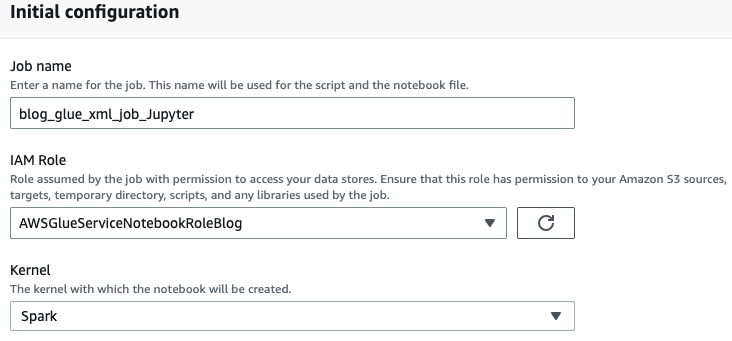
- Введіть назву для завдання AWS Glue, наприклад
blog_glue_xml_job_Jupyter. - Виберіть роль, яку ви створили в попередніх умовах (
AWSGlueServiceNotebookRoleBlog).
Блокнот AWS Glue постачається з уже існуючим прикладом, який демонструє, як надсилати запит до бази даних і писати вихідні дані в Amazon S3.
- Налаштуйте час очікування (у хвилинах), як показано на наступному знімку екрана, і запустіть клітинку, щоб створити інтерактивний сеанс AWS Glue.
Створіть основні змінні
Після створення інтерактивного сеансу в кінці блокнота створіть нову комірку з такими змінними (вкажіть власну назву сегмента):
Прочитайте XML-файл, що містить схему
Якщо ви не передасте схему до DynamicFrame, він визначить схему файлів. Щоб прочитати дані за допомогою динамічного кадру, ви можете використати таку команду:
Роздрукуйте схему DynamicFrame
Роздрукуйте схему з таким кодом:
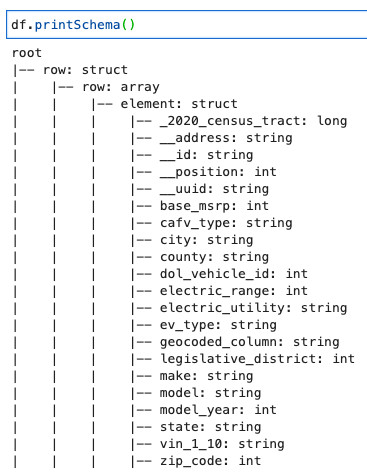
На схемі показано вкладену структуру з a row масив, що містить кілька елементів. Щоб роз’єднати цю структуру в лінії, ви можете використовувати клей AWS реляціонувати перетворення:
Нас цікавить лише інформація, що міститься в масиві рядків, і ми можемо переглянути схему за допомогою такої команди:
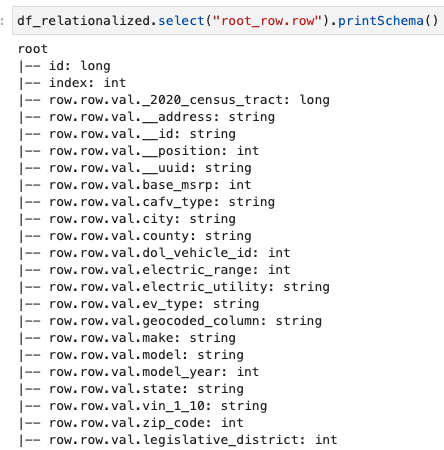
Назви стовпців містять row.row, які відповідають структурі масиву та стовпцю масиву в наборі даних. Ми не перейменовуємо стовпці в цій публікації; інструкції щодо цього див Автоматизуйте динамічне відображення та перейменування назв стовпців у файлах даних за допомогою AWS Glue: Частина 1. Потім ви можете конвертувати дані у формат Parquet і створити таблицю AWS Glue за допомогою такої команди:
Клей AWS DynamicFrame надає функції, які ви можете використовувати у своєму сценарії ETL для створення та оновлення схеми в каталозі даних. Ми використовуємо updateBehavior параметр для створення таблиці безпосередньо в каталозі даних. За такого підходу нам не потрібно запускати сканер AWS Glue після завершення роботи AWS Glue.

Прочитайте файл XML, встановивши схему
Альтернативним способом читання файлу є попереднє визначення схеми. Для цього виконайте наступні дії:
- Імпортуйте типи даних AWS Glue:
- Створіть схему для файлу XML:
- Передайте схему під час читання файлу XML:
- Роз’єднайте набір даних, як раніше:
- Перетворіть набір даних у Parquet і створіть таблицю AWS Glue:
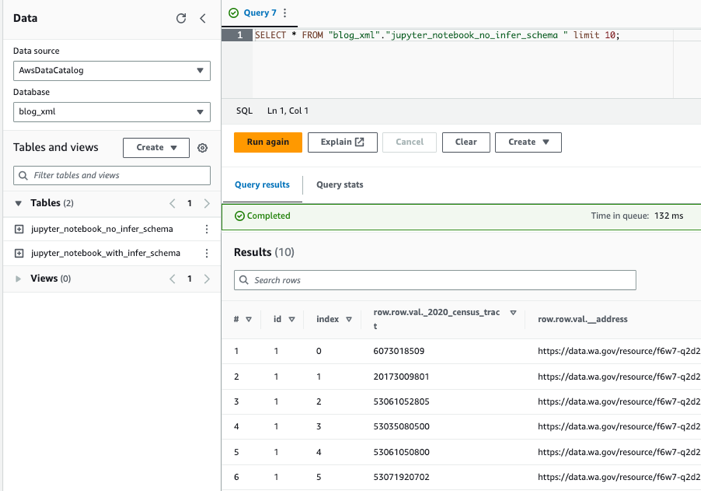
Зробіть запит до таблиць за допомогою Athena
Тепер, коли ми створили обидві таблиці, ми можемо запитувати таблиці за допомогою Athena. Наприклад, ми можемо використати такий запит:
Прибирати
У цій публікації ми створили роль IAM, блокнот AWS Glue Jupyter і дві таблиці в каталозі даних AWS Glue. Ми також завантажили деякі файли в сегмент S3. Щоб очистити ці об’єкти, виконайте такі дії:
- На консолі IAM видаліть створену роль.
- На консолі AWS Glue Studio видаліть спеціальний класифікатор, сканер, завдання ETL і блокнот Jupyter.
- Перейдіть до каталогу даних AWS Glue і видаліть створені вами таблиці.
- На консолі Amazon S3 перейдіть до створеного вами сегмента та видаліть названі папки
temp,infer_schemaтаno_infer_schema.
Ключові винесення
В AWS Glue є функція під назвою InferSchema в AWS Glue DynamicFrames. Він автоматично визначає структуру кадру даних на основі даних, які він містить. Навпаки, визначення схеми означає явне визначення того, якою має бути структура кадру даних перед завантаженням даних.
XML, будучи текстовим форматом, не обмежує типи даних своїх стовпців. Це може спричинити проблеми з функцією InferSchema. Наприклад, під час першого запуску файл із стовпцем A, що має значення 2, призводить до файлу Parquet із стовпцем A як ціле число. Під час другого запуску новий файл містить стовпець A зі значенням C, що призводить до файлу Parquet зі стовпцем A як рядок. Тепер на S3 є два файли, кожен зі стовпцем A різних типів даних, що може створювати проблеми в подальшому.
Те ж саме відбувається зі складними типами даних, такими як вкладені структури або масиви. Наприклад, якщо файл має один запис тегу, який викликається transaction, це виводиться як структура. Але якщо інший файл має такий самий тег, він виводиться як масив
Незважаючи на ці проблеми з типом даних, InferSchema корисно, коли ви не знаєте схему або визначати її вручну непрактично. Однак це не ідеально для великих або постійно змінюваних наборів даних. Визначення схеми є більш точним, особливо зі складними типами даних, але має свої проблеми, як-от потреба ручних зусиль і негнучкість до змін даних.
InferSchema має обмеження, як-от неправильне визначення типу даних і проблеми з обробкою нульових значень. Визначення схеми також має обмеження, наприклад ручні зусилля та можливі помилки.
Вибір між висновком і визначенням схеми залежить від потреб проекту. InferSchema чудово підходить для швидкого дослідження невеликих наборів даних, тоді як визначення схеми краще для великих, складних наборів даних, які вимагають точності та узгодженості. Розгляньте компроміси та обмеження кожного методу, щоб вибрати те, що найкраще підходить для вашого проекту.
Висновок
У цій публікації ми дослідили дві методики керування XML-даними за допомогою AWS Glue, кожна з яких розроблена відповідно до конкретних потреб і проблем, з якими ви можете зіткнутися.
Техніка 1 пропонує зручний шлях для тих, хто віддає перевагу графічному інтерфейсу. Ви можете використовувати сканер AWS Glue і візуальний редактор, щоб без зусиль визначити структуру таблиці для файлів XML. Цей підхід спрощує процес керування даними та особливо привабливий для тих, хто шукає простий спосіб обробки своїх даних.
Однак ми усвідомлюємо, що сканер має свої обмеження, особливо коли працює з XML-файлами, рядки яких перевищують 1 МБ. Тут на допомогу приходить техніка 2. За допомогою клею AWS DynamicFrames за допомогою як виведених, так і фіксованих схем, а також використовуючи блокнот AWS Glue, ви можете ефективно обробляти XML-файли будь-якого розміру. Цей метод забезпечує надійне рішення, яке забезпечує безперебійну обробку навіть XML-файлів із рядками, що перевищують обмеження в 1 МБ.
Коли ви орієнтуєтесь у світі управління даними, наявність цих методів у вашому наборі інструментів дає вам змогу приймати обґрунтовані рішення на основі конкретних вимог вашого проекту. Незалежно від того, віддаєте перевагу простоті методу 1 чи масштабованості методу 2, AWS Glue забезпечує гнучкість, необхідну для ефективної обробки даних XML.
Про авторів
 Навнит Шуклапрацює архітектором рішень спеціалістів AWS із фокусом на аналітиці. Він має великий ентузіазм у наданні допомоги клієнтам у виявленні цінної інформації з їхніх даних. Завдяки своєму досвіду він розробляє інноваційні рішення, які дають можливість підприємствам робити обґрунтований вибір на основі даних. Примітно, що Навніт Шукла є відомим автором книги під назвою «Суперечка даних на AWS.
Навнит Шуклапрацює архітектором рішень спеціалістів AWS із фокусом на аналітиці. Він має великий ентузіазм у наданні допомоги клієнтам у виявленні цінної інформації з їхніх даних. Завдяки своєму досвіду він розробляє інноваційні рішення, які дають можливість підприємствам робити обґрунтований вибір на основі даних. Примітно, що Навніт Шукла є відомим автором книги під назвою «Суперечка даних на AWS.
 Патрік Мюллер працює старшим архітектором Data Lab в AWS. Його основний обов’язок полягає в тому, щоб допомогти клієнтам перетворити їхні ідеї на готовий до виробництва продукт даних. У вільний час Патрік любить грати у футбол, дивитися фільми та подорожувати.
Патрік Мюллер працює старшим архітектором Data Lab в AWS. Його основний обов’язок полягає в тому, щоб допомогти клієнтам перетворити їхні ідеї на готовий до виробництва продукт даних. У вільний час Патрік любить грати у футбол, дивитися фільми та подорожувати.
 Амог Гайквад є старшим розробником рішень в Amazon Web Services. Він допомагає глобальним клієнтам створювати та розгортати рішення AI/ML на AWS. Його робота в основному зосереджена на комп’ютерному зорі та обробці природної мови, а також на допомозі клієнтам оптимізувати робочі навантаження AI/ML для сталого розвитку. Амог отримав ступінь магістра комп’ютерних наук, спеціалізуючись на машинному навчанні.
Амог Гайквад є старшим розробником рішень в Amazon Web Services. Він допомагає глобальним клієнтам створювати та розгортати рішення AI/ML на AWS. Його робота в основному зосереджена на комп’ютерному зорі та обробці природної мови, а також на допомозі клієнтам оптимізувати робочі навантаження AI/ML для сталого розвитку. Амог отримав ступінь магістра комп’ютерних наук, спеціалізуючись на машинному навчанні.
 Шила Сононе є старшим постійним архітектором AWS. Вона допомагає клієнтам AWS робити обґрунтований вибір і робити компроміси щодо прискорення роботи з даними, аналітикою та робочими навантаженнями та впровадженнями AI/ML. У вільний час вона любить проводити час із сім’єю – зазвичай на тенісних кортах.
Шила Сононе є старшим постійним архітектором AWS. Вона допомагає клієнтам AWS робити обґрунтований вибір і робити компроміси щодо прискорення роботи з даними, аналітикою та робочими навантаженнями та впровадженнями AI/ML. У вільний час вона любить проводити час із сім’єю – зазвичай на тенісних кортах.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- : має
- :є
- : ні
- :де
- $UP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- МЕНЮ
- РЕЗЮМЕ
- прискорення
- доступ
- доступність
- виконано
- точність
- через
- дію
- додавати
- доданий
- Додатковий
- адреса
- після
- вік
- AI / ML
- ВСІ
- дозволяти
- Дозволити
- дозволяє
- Також
- альтернатива
- Amazon
- Амазонка Афіна
- Amazon Web Services
- an
- аналіз
- аналітика
- аналізувати
- Аналізуючи
- та
- Інший
- будь-який
- Apache
- привабливий
- застосування
- Застосовувати
- підхід
- підходи
- архітектура
- ЕСТЬ
- масив
- AS
- допомогу
- допомагати
- At
- автор
- автоматично
- доступний
- AWS
- Клей AWS
- назад
- заснований
- основний
- BE
- оскільки
- перед тим
- починати
- буття
- КРАЩЕ
- Краще
- між
- порожній
- книга
- обидва
- будувати
- підприємства
- але
- by
- званий
- CAN
- каталог
- Викликати
- осередок
- проблеми
- зміна
- Зміни
- заміна
- вибір
- Вибирати
- Місто
- класифікація
- клієнтів
- код
- Колонка
- Колони
- COM
- приходить
- загальний
- зазвичай
- повний
- Зроблено
- комплекс
- комп'ютер
- Інформатика
- Комп'ютерне бачення
- стан
- Проводити
- зв'язок
- Вважати
- Консоль
- постійно
- обмеження
- будувати
- містити
- містяться
- містить
- контрастність
- контроль
- конвертувати
- перероблений
- рентабельним
- економічно вигідне рішення
- графство
- Суди
- покритий
- гусеничний
- створювати
- створений
- створення
- вирішальне значення
- виготовлений на замовлення
- клієнт
- Клієнти
- дані
- інтеграція даних
- управління даними
- керовані даними
- Database
- набори даних
- справу
- рішення
- дефолт
- визначати
- визначаючи
- заглиблюватися
- демонструє
- залежить
- розгортання
- призначений
- докладно
- деталі
- Розробник
- різний
- важкий
- цифровий
- цифровому столітті
- безпосередньо
- відкриття
- чіткий
- do
- Ні
- зроблений
- Не знаю
- DOT
- під час
- динамічний
- кожен
- простота
- легко
- легко
- редактор
- ефект
- фактично
- ефективність
- ефективний
- продуктивно
- зусилля
- легко
- електричний
- електромобіль
- елементи
- наймаючи
- уповноважувати
- повноваження
- порожній
- включіть
- дозволяє
- зіткнення
- кінець
- Двигуни
- підвищувати
- забезпечувати
- гарантує
- Що натомість? Створіть віртуальну версію себе у
- ентузіазм
- запис
- помилки
- особливо
- Ефір (ETH)
- Навіть
- Події
- Кожен
- приклад
- перевищувати
- обмін
- експертиза
- дослідження
- дослідити
- Розвіданий
- витяг
- видобуток
- сім'я
- особливість
- риси
- цифри
- філе
- Файли
- фінансування
- Перший
- фіксованою
- Гнучкість
- Сфокусувати
- увагу
- після
- для
- формат
- FRAME
- Безкоштовна
- частота
- від
- функція
- Отримувати
- Головна мета
- породжувати
- Глобальний
- Go
- мета
- Уряд
- великий
- обробляти
- Обробка
- відбувається
- Запрягання
- Мати
- має
- he
- охорона здоров'я
- Серце
- допомога
- допомогу
- допомагає
- її
- на вищому рівні
- дуже
- його
- Як
- How To
- Однак
- HTML
- HTTP
- HTTPS
- IAM
- ідеальний
- ідеї
- Особистість
- if
- ілюструє
- здійснювати
- реалізації
- реалізації
- імпорт
- удосконалювати
- поліпшений
- in
- У тому числі
- індивідуальний
- осіб
- промисловості
- інформація
- повідомив
- Інфраструктура
- інноваційний
- всередині
- розуміння
- замість
- інструкції
- інтегрувати
- інтеграція
- інтерактивний
- зацікавлений
- інтерфейс
- в
- включає в себе
- питання
- IT
- ЙОГО
- робота
- Джобс
- JPG
- json
- Jupyter Notebook
- тримати
- Знати
- lab
- мова
- великий
- більше
- провідний
- УЧИТЬСЯ
- вивчення
- рівень
- як
- МЕЖА
- обмеження
- недоліки
- Лінія
- ліній
- загрузка
- погрузка
- логіка
- шукати
- машина
- навчання за допомогою машини
- головний
- головним чином
- зробити
- Робить
- управління
- управління
- керівництво
- вручну
- багато
- відображення
- магістра
- Може..
- засоби
- Меню
- метадані
- метод
- протокол
- модель
- більше
- більш ефективний
- найбільш
- рухатися
- кіно
- множинний
- ім'я
- Названий
- Імена
- Природний
- Природна мова
- Обробка природних мов
- Переміщення
- навігація
- необхідно
- Необхідність
- потреби
- Нові
- нещодавно
- наступний
- особливо
- ноутбук
- зараз
- номер
- об'єкти
- of
- Пропозиції
- on
- ONE
- тільки
- операції
- оптимальний
- Оптимізувати
- Оптимізує
- Опції
- or
- порядок
- організації
- Походження
- Інше
- наші
- з
- вихід
- над
- Подолати
- власний
- сторінка
- pane
- параметр
- параметри
- частина
- особливо
- проходити
- шлях
- Патрік
- виконувати
- продуктивність
- Дозволи
- вибирати
- plato
- Інформація про дані Платона
- PlatoData
- ігри
- політика
- населення
- володіти
- пошта
- потенціал
- необхідність
- надавати перевагу
- передумови
- попередній перегляд
- попередній
- проблеми
- процес
- оброблена
- обробка
- Product
- проект
- проектів
- властивості
- забезпечувати
- забезпечує
- публікувати
- мета
- Python
- запити
- Швидко
- швидше
- Читати
- легко
- читання
- Причини
- отримано
- визнавати
- послатися
- доречний
- Вимога
- рятувати
- ресурс
- відповідь
- відповідальність
- REST
- обмежити
- обмеження
- результати
- міцний
- Роль
- корінь
- ROW
- прогін
- то ж
- зберегти
- масштаб
- масштабованість
- масштабовані
- наука
- сценарій
- безшовні
- плавно
- другий
- розділ
- побачити
- старший
- Послуги
- Сесія
- комплект
- установка
- кілька
- вона
- Склад
- Повинен
- Показувати
- показаний
- Шоу
- аналогічний
- простий
- простота
- спрощення
- один
- Розмір
- невеликий
- So
- Футбол
- рішення
- Рішення
- деякі
- Source
- Джерела
- Іскритися
- спеціаліст
- спеціалізується
- конкретний
- конкретно
- швидкість
- Витрати
- SQL
- standard
- починається
- стан
- Заява
- про те,
- Крок
- заходи
- зберігання
- зберігати
- просто
- раціоналізувати
- рядок
- сильний
- структура
- структур
- студія
- успіх
- такі
- підходящий
- підтримка
- Переконайтеся
- Sustainability
- Systems
- таблиця
- TAG
- з урахуванням
- Приймати
- приймає
- завдання
- методи
- теніс
- ніж
- Що
- Команда
- інформація
- світ
- їх
- Їх
- потім
- Там.
- Ці
- вони
- це
- ті
- через
- час
- назва
- під назвою
- до
- сьогоднішній
- Інструментарій
- топ
- тема
- Перетворення
- Перетворення
- Подорож
- Поворот
- підручник
- два
- тип
- Типи
- кінцевий
- при
- Оновити
- оновлений
- завантажено
- us
- юзабіліті
- використання
- використовуваний
- користувач
- Інтерфейс користувача
- зручно
- використовує
- використання
- зазвичай
- використовує
- Цінний
- значення
- Цінності
- автомобіль
- версія
- через
- вид
- думки
- бачення
- спостереження
- шлях..
- we
- Web
- веб-сервіси
- Що
- коли
- в той час як
- Чи
- який
- ВООЗ
- чому
- волі
- з
- в
- без
- Work
- робочий
- Робочі процеси
- працює
- світ
- запис
- XML
- ви
- вашу
- зефірнет