Великі мовні моделі (LLM) стають все популярнішими, постійно досліджуються нові випадки використання. Загалом, ви можете створювати додатки на основі LLM, включивши оперативне проектування у свій код. Однак є випадки, коли підказка існуючого LLM не вдається. Тут може допомогти тонке налаштування моделі. Оперативна інженерія полягає в керуванні виходом моделі шляхом створення вхідних підказок, тоді як тонке налаштування передбачає навчання моделі на спеціальних наборах даних, щоб зробити її краще придатною для конкретних завдань або доменів.
Перш ніж ви зможете точно налаштувати модель, вам потрібно знайти набір даних для конкретного завдання. Один з наборів даних, який зазвичай використовується, це Загальний набір даних сканування. Корпус Common Crawl містить петабайти даних, які регулярно збираються з 2008 року, і містить необроблені дані веб-сторінок, витяги метаданих і витяги тексту. На додаток до визначення того, який набір даних слід використовувати, потрібно очистити й обробити дані відповідно до конкретних потреб тонкого налаштування.
Нещодавно ми працювали з клієнтом, який хотів попередньо обробити підмножину останнього набору даних Common Crawl, а потім точно налаштувати свій LLM за допомогою очищених даних. Клієнт шукав, як можна досягти цього найбільш рентабельним способом на AWS. Після обговорення вимог ми рекомендували використовувати Amazon EMR без сервера як платформу для попередньої обробки даних. EMR Serverless добре підходить для великомасштабної обробки даних і усуває потребу в обслуговуванні інфраструктури. З точки зору вартості, він стягує плату лише на основі ресурсів і тривалості, використаних для кожної роботи. Клієнт зміг попередньо обробити сотні ТБ даних протягом тижня за допомогою EMR Serverless. Після попередньої обробки даних вони використовували Amazon SageMaker для точного налаштування LLM.
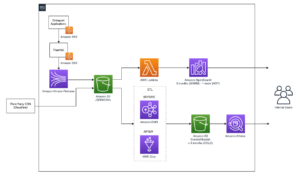
У цій публікації ми познайомимо вас із сценарієм використання та архітектурою клієнта.
У наступних розділах ми спочатку познайомимося з набором даних Common Crawl і тим, як досліджувати та фільтрувати дані, які нам потрібні. Амазонка Афіна стягується плата лише за розмір даних, які він сканує, і використовується для швидкого вивчення та фільтрації даних, але є економічно ефективним. EMR Serverless надає економічно ефективний варіант обробки даних Spark, який не потребує обслуговування, і використовується для обробки відфільтрованих даних. Далі використовуємо Amazon SageMaker JumpStart для точного налаштування Модель Лама 2 з попередньо обробленим набором даних. SageMaker JumpStart надає набір рішень для найпоширеніших випадків використання, які можна розгорнути лише кількома клацаннями миші. Вам не потрібно писати код для точного налаштування LLM, наприклад Llama 2. Нарешті, ми розгортаємо налаштовану модель за допомогою Amazon SageMaker і порівняйте відмінності у виведенні тексту для того самого запитання між оригінальною та налаштованою моделями Llama 2.
Наступна діаграма ілюструє архітектуру цього рішення.
Перш ніж заглибитися в деталі рішення, виконайте такі передумови:
Common Crawl — це відкритий набір даних, отриманий шляхом сканування понад 50 мільярдів веб-сторінок. Він містить величезні обсяги неструктурованих даних кількома мовами, починаючи з 2008 року і досягаючи рівня петабайтів. Він постійно оновлюється.
Під час навчання GPT-3 набір даних Common Crawl становить 60% даних навчання, як показано на наступній діаграмі (джерело: Мовні моделі - це малозабезпечені учні).
Ще один важливий набір даних, про який варто згадати, це Набір даних C4. C4, скорочення від Colossal Clean Crawled Corpus, — це набір даних, отриманий у результаті постобробки набору даних Common Crawl. У документі Meta LLaMA вони окреслили використовувані набори даних: Common Crawl становить 67% (використовує 3.3 ТБ даних), а C4 — 15% (використовує 783 ГБ даних). У документі підкреслюється важливість включення різних попередньо оброблених даних для підвищення ефективності моделі. Незважаючи на те, що вихідні дані C4 були частиною Common Crawl, Meta вибрала повторно оброблену версію цих даних.
У цьому розділі ми розглядаємо поширені способи взаємодії, фільтрації та обробки набору даних Common Crawl.
Набір необроблених даних Common Crawl включає три типи файлів даних: необроблені дані веб-сторінки (WARC), метадані (WAT) і вилучення тексту (WET).
Дані, зібрані після 2013 року, зберігаються у форматі WARC і включають відповідні метадані (WAT) і дані вилучення тексту (WET). Набір даних міститься в Amazon S3, оновлюється щомісяця, і до нього можна отримати прямий доступ Торговий майданчик AWS.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzНабір даних Common Crawl також надає індексну таблицю для фільтрації даних, яка називається cc-index-table.
cc-index-table — це індекс існуючих даних, що забезпечує табличний індекс файлів WARC. Це дозволяє легко шукати інформацію, наприклад, який файл WARC відповідає певній URL-адресі.
Наприклад, ви можете створити таблицю Athena для зіставлення даних cc-index за допомогою такого коду:
Попередні оператори SQL демонструють, як створити таблицю Athena, додати розділи та виконати запит.
Фільтруйте дані з набору даних Common Crawl
Як ви можете бачити з інструкції SQL для створення таблиці, є кілька полів, які можуть допомогти відфільтрувати дані. Наприклад, якщо ви хочете отримати кількість китайських документів протягом певного періоду, тоді оператор SQL може бути таким:
Якщо ви хочете виконати подальшу обробку, ви можете зберегти результати в іншому сегменті S3.
Проаналізуйте відфільтровані дані
Команда Сховище Common Crawl GitHub надає кілька прикладів PySpark для обробки необроблених даних.
Розглянемо приклад бігу server_count.py (приклад сценарію, наданого репозиторієм Common Crawl GitHub) на даних, розташованих у s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
По-перше, вам потрібне середовище Spark, наприклад EMR Spark. Наприклад, ви можете запустити Amazon EMR на кластері EC2 us-east-1 (оскільки набір даних знаходиться в us-east-1). Використання EMR на кластері EC2 може допомогти вам провести тести перед надсиланням завдань у виробниче середовище.
Після запуску EMR на кластері EC2 вам потрібно виконати вхід SSH на основний вузол кластера. Потім запакуйте середовище Python і надішліть сценарій (див Документація Conda щоб встановити Miniconda):
Обробка всіх посилань у warc.path може зайняти час. Для демонстраційних цілей ви можете покращити час обробки за допомогою таких стратегій:
- Завантажте файл
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzна ваш локальний комп’ютер, розпакуйте його, а потім завантажте в HDFS або Amazon S3. Це тому, що файл .gzip не можна розділити. Вам потрібно розпакувати його, щоб паралельно обробити цей файл. - Змінити
warc.pathфайл, видаліть більшість його рядків і збережіть лише два рядки, щоб робота виконувалася набагато швидше.
Після завершення роботи ви можете побачити результат s3://xxxx-common-crawl/output/, у форматі Паркет.
Реалізація налаштованої логіки
Сховище Common Crawl GitHub забезпечує загальний підхід до обробки файлів WARC. Як правило, ви можете розширити CCSparkJob щоб перевизначити один метод (process_record), чого достатньо для багатьох випадків.
Давайте розглянемо приклад, щоб отримати огляди останніх фільмів на IMDB. Спочатку вам потрібно відфільтрувати файли на сайті IMDB:
Потім ви можете отримати списки файлів WARC, які містять дані огляду IMDB, і зберегти імена файлів WARC як список у текстовому файлі.
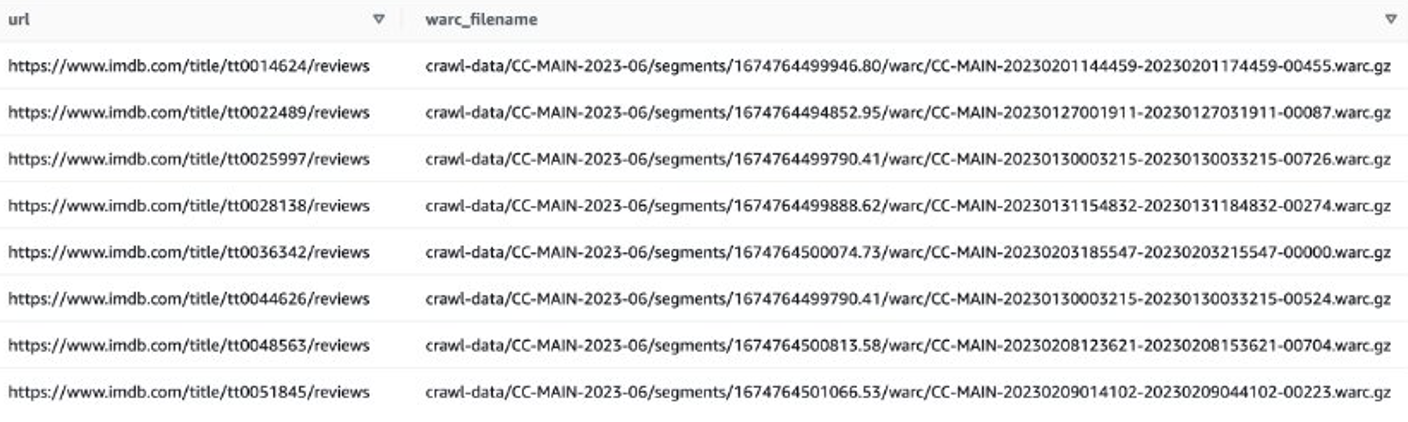
Крім того, ви можете використовувати EMR Spark, щоб отримати список файлів WARC і зберегти його в Amazon S3. Наприклад:
Вихідний файл має виглядати подібно до s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
Наступним кроком є вилучення відгуків користувачів із цих файлів WARC. Ви можете продовжити CCSparkJob відмінити process_record() метод:
Ви можете зберегти попередній сценарій як imdb_extractor.py, який використовуватимете в наступних кроках. Після того, як ви підготували дані та сценарії, ви можете використовувати EMR Serverless для обробки відфільтрованих даних.
EMR без сервера
EMR Serverless — це безсерверний варіант розгортання для запуску програм аналітики великих даних за допомогою фреймворків з відкритим кодом, таких як Apache Spark і Hive, без налаштування, керування та масштабування кластерів або серверів.
Завдяки EMR Serverless ви можете запускати аналітичні робочі навантаження в будь-якому масштабі з автоматичним масштабуванням, яке змінює розмір ресурсів за лічені секунди відповідно до мінливих обсягів даних і вимог до обробки. EMR Serverless автоматично масштабує ресурси вгору та вниз, щоб забезпечити необхідну кількість ресурсів для вашої програми, і ви платите лише за те, що використовуєте.
Обробка набору даних Common Crawl зазвичай є одноразовим завданням обробки, що робить його придатним для безсерверних навантажень EMR.
Створіть програму EMR Serverless
Ви можете створити програму EMR Serverless на консолі EMR Studio. Виконайте наступні дії:
- На консолі EMR Studio виберіть додатків при Без сервера у навігаційній панелі.
- Вибирати Створити додаток.

- Введіть назву програми та виберіть версію Amazon EMR.

- Якщо потрібен доступ до ресурсів VPC, додайте власне налаштування мережі.

- Вибирати Створити додаток.
Тоді ваше безсерверне середовище Spark буде готове.
Перш ніж ви зможете надіслати завдання в EMR Spark Serverless, вам все одно потрібно створити роль виконання. Відноситься до Початок роботи з Amazon EMR Serverless для більш докладної інформації.
Обробляйте дані загального сканування за допомогою EMR Serverless
Коли ваша безсерверна програма EMR Spark буде готова, виконайте такі кроки, щоб обробити дані:
- Підготуйте середовище Conda та завантажте його в Amazon S3, яке використовуватиметься як середовище в EMR Spark Serverless.
- Завантажте сценарії для запуску в сегмент S3. У наступному прикладі є два сценарії:
- imbd_extractor.py – Налаштована логіка для вилучення вмісту з набору даних. Зміст можна знайти раніше в цій публікації.
- cc-pyspark/sparkcc.py – Приклад фреймворку PySpark із Сховище Common Crawl GitHub, які необхідно включити.
- Надішліть завдання PySpark до EMR Serverless Spark. Визначте такі параметри, щоб запустити цей приклад у вашому середовищі:
- ідентифікатор програми – Ідентифікатор програми EMR Serverless.
- виконання-роль-арн – Ваша роль виконання EMR Serverless. Для його створення зверніться до Створіть роль середовища виконання завдання.
- Розташування файлу WARC – Розташування ваших файлів WARC.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtмістить відфільтрований список файлів WARC, який ви отримали раніше в цій публікації. - spark.sql.warehouse.dir – Розташування складу за замовчуванням (використовуйте свій каталог S3).
- spark.archives – Розташування S3 підготовленого середовища Conda.
- spark.submit.pyFiles – Підготовлений скрипт PySpark sparkcc.py.
Дивіться наступний код:
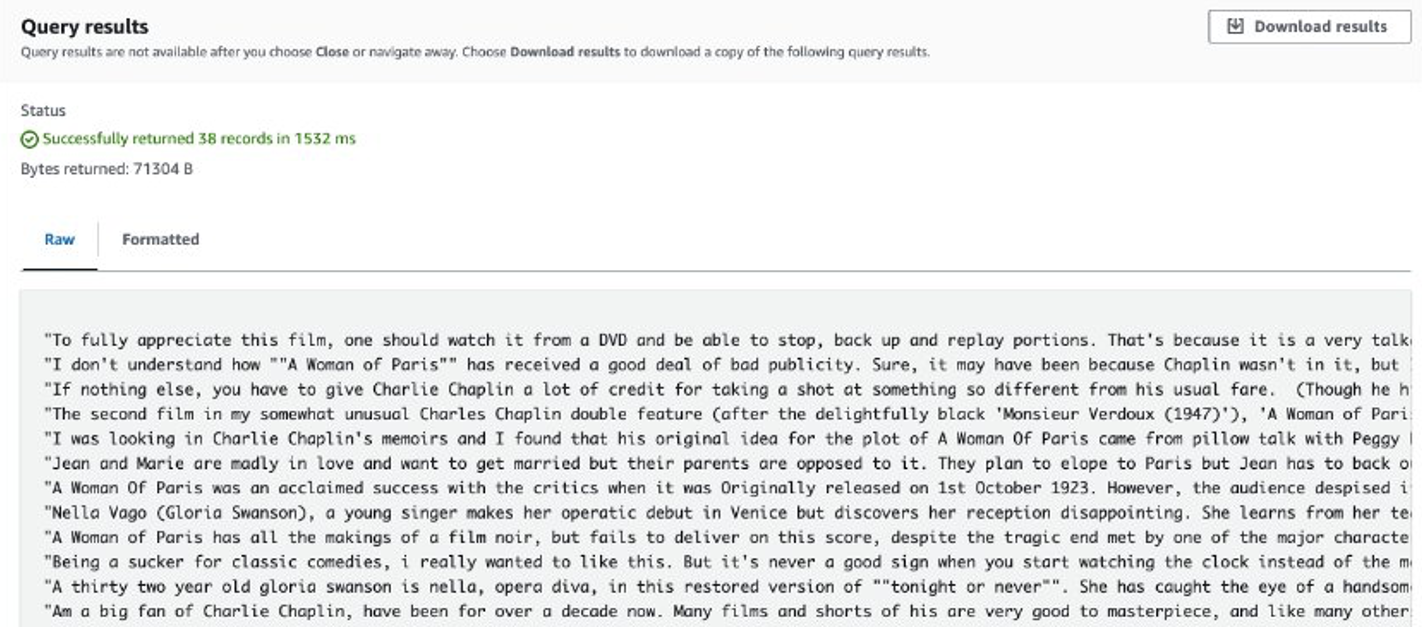
Після завершення роботи витягнуті відгуки зберігаються в Amazon S3. Щоб перевірити вміст, ви можете використовувати Amazon S3 Select, як показано на наступному знімку екрана.
Міркування
Нижче наведено моменти, які слід враховувати під час роботи з величезними обсягами даних із налаштованим кодом:
- Деякі сторонні бібліотеки Python можуть бути недоступні в Conda. У таких випадках ви можете перейти до віртуального середовища Python, щоб створити середовище виконання PySpark.
- Якщо потрібно обробити величезну кількість даних, спробуйте створити та використати декілька додатків EMR Serverless Spark, щоб розпаралелити їх. Кожна програма має справу з підмножиною списків файлів.
- Ви можете зіткнутися з уповільненням роботи Amazon S3 під час фільтрації або обробки даних Common Crawl. Це пояснюється тим, що сегмент S3, у якому зберігаються дані, є загальнодоступним, і інші користувачі можуть отримати доступ до даних одночасно. Щоб пом’якшити цю проблему, ви можете додати механізм повторних спроб або синхронізувати певні дані з сегмента Common Crawl S3 у свій сегмент.
Налаштуйте Llama 2 за допомогою SageMaker
Після підготовки даних ви можете точно налаштувати модель Llama 2 за допомогою них. Ви можете зробити це за допомогою SageMaker JumpStart без написання коду. Для отримання додаткової інформації див Налаштуйте Llama 2 для створення тексту на Amazon SageMaker JumpStart.
У цьому сценарії ви виконуєте тонке налаштування адаптації домену. Для цього набору даних вхідні дані складаються з файлів CSV, JSON або TXT. Вам потрібно помістити всі дані огляду у файл TXT. Для цього ви можете надіслати просте завдання Spark до EMR Spark Serverless. Перегляньте наведений нижче зразок фрагмента коду:
Підготувавши навчальні дані, введіть розташування даних для Навчальний набір даних, Потім виберіть поїзд.
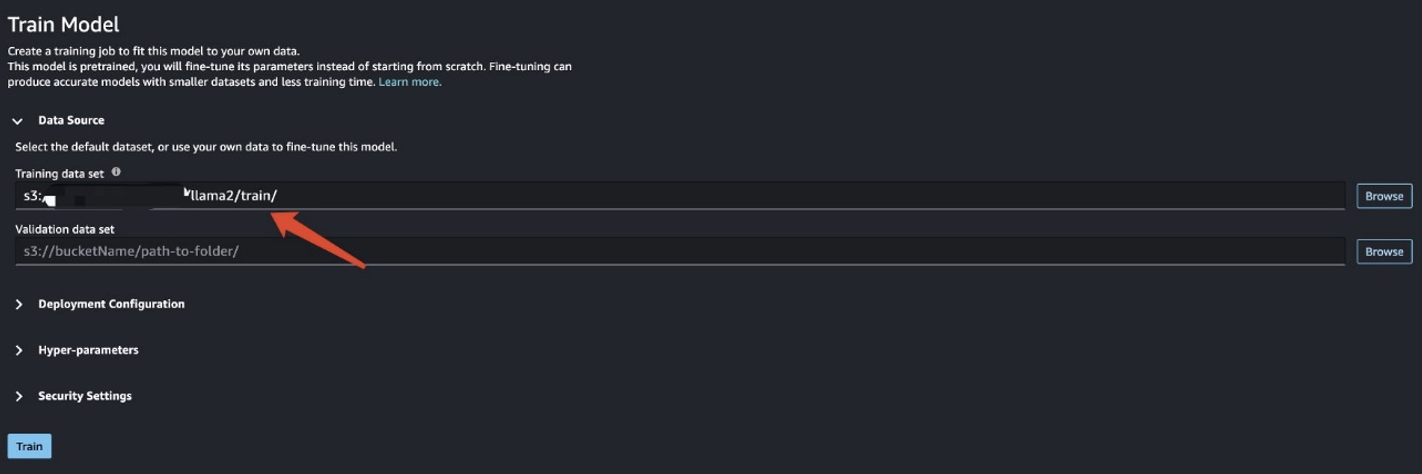
Ви можете відстежувати статус навчальної роботи.
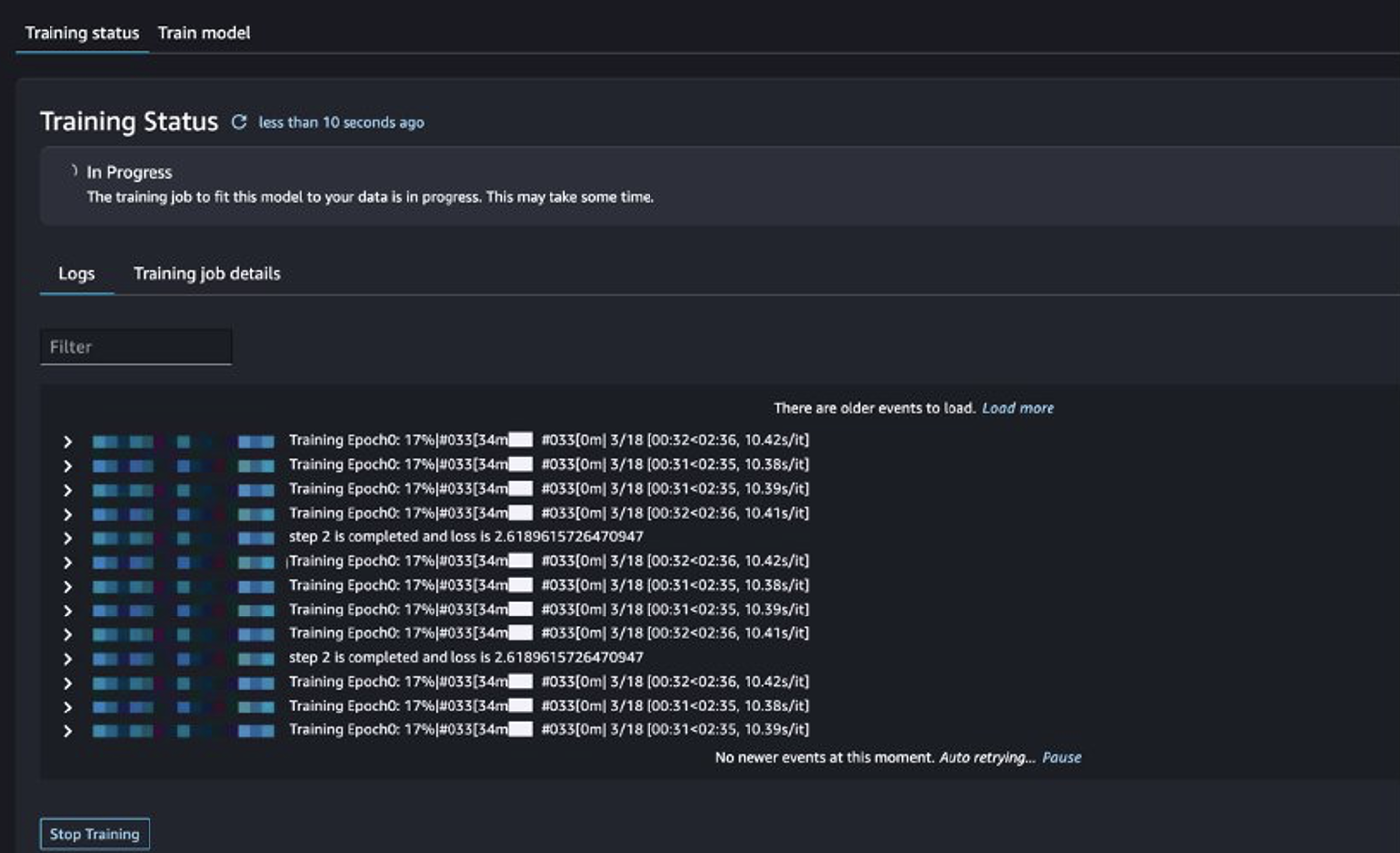
Оцініть налаштовану модель
Після завершення навчання виберіть Розгортання у SageMaker JumpStart для розгортання вашої точно налаштованої моделі.

Після успішного розгортання моделі виберіть Відкрийте Блокнот, який перенаправляє вас до підготовленого блокнота Jupyter, де ви можете запустити свій код Python.

Ви можете використовувати образ Data Science 2.0 і ядро Python 3 для ноутбука.
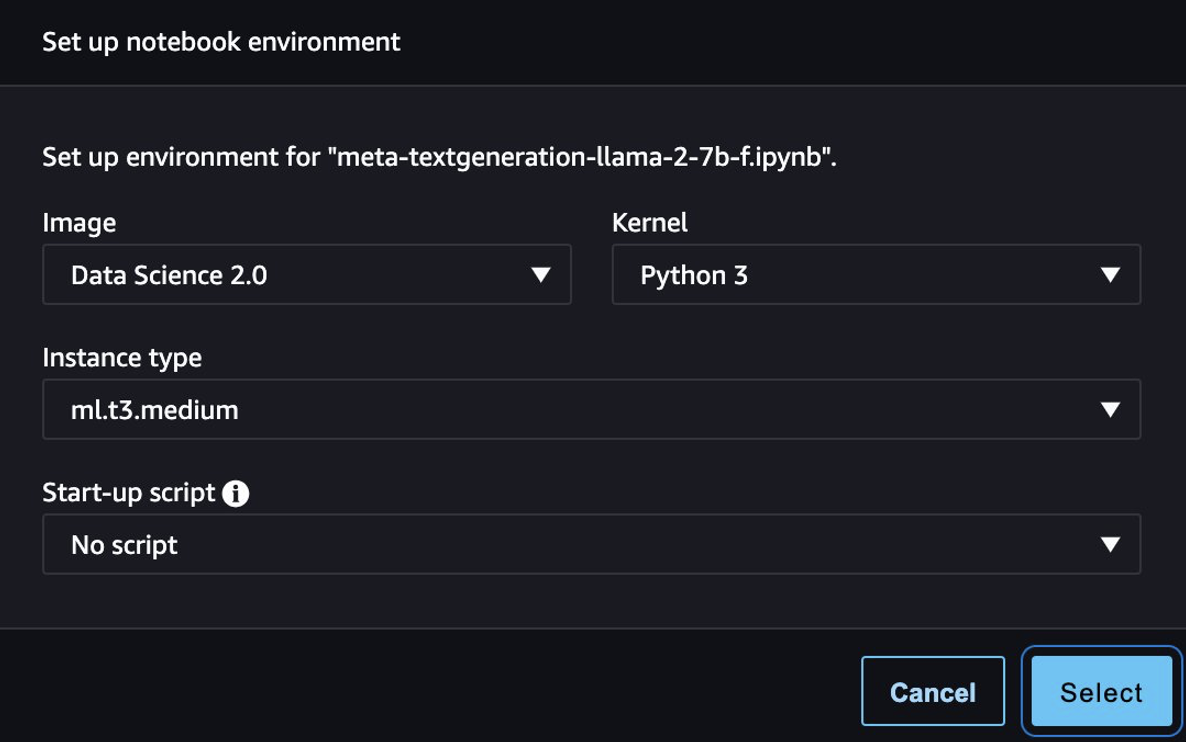
Тоді ви зможете оцінити налаштовану модель і оригінальну модель у цьому блокноті.
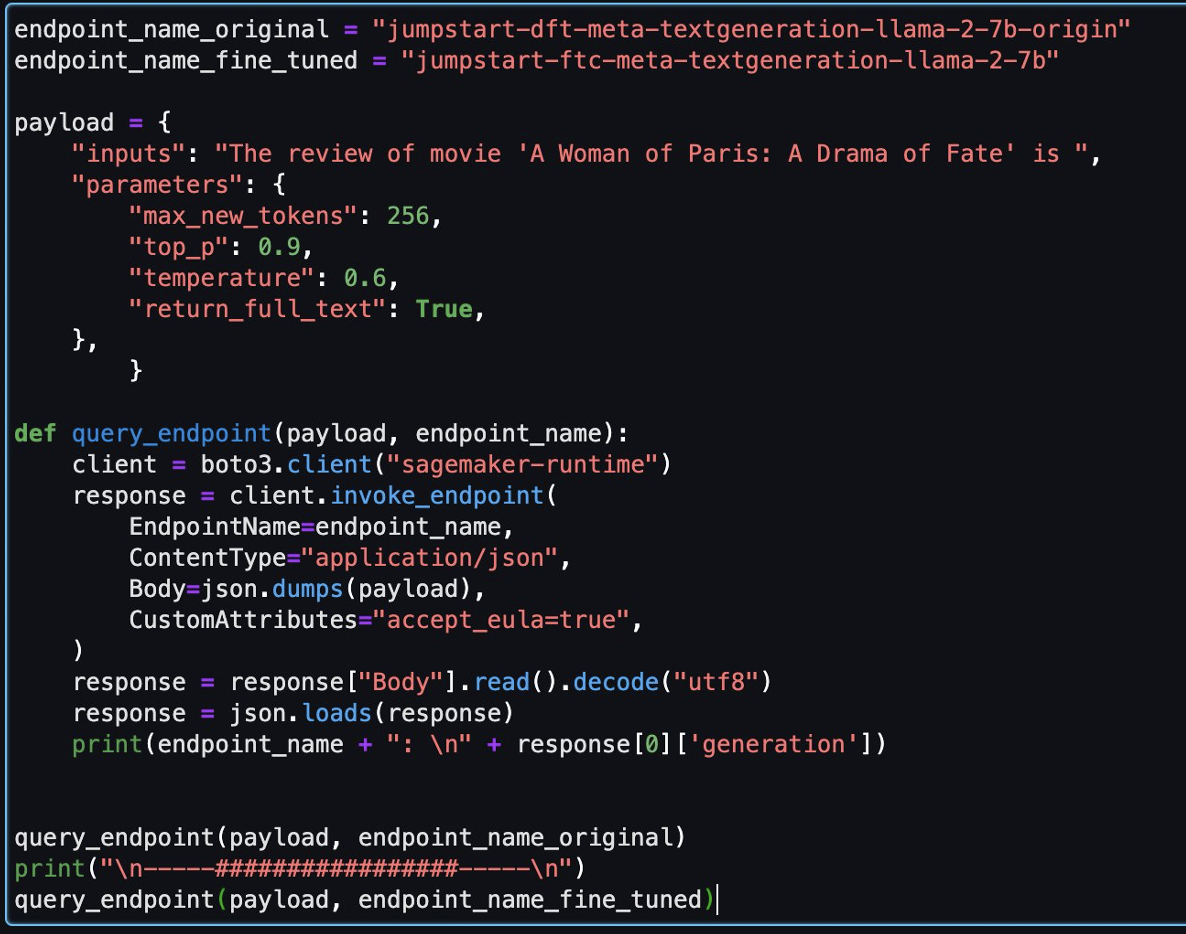
Нижче наведено дві відповіді, отримані оригінальною моделлю та налаштованою моделлю для того самого запитання.

Ми надали обом моделям однакове речення: «Рецензія на фільм «Парижанка: Драма долі»» і дозволили їм завершити речення.
Оригінальна модель виводить безглузді речення:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
На відміну від цього, результати налаштованої моделі більше схожі на огляд фільму:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
Очевидно, що налаштована модель працює краще в цьому конкретному сценарії.
Прибирати
Після завершення цієї вправи виконайте наступні кроки, щоб очистити свої ресурси:
- Видаліть сегмент S3 який зберігає очищений набір даних.
- Зупиніть безсерверне середовище EMR.
- Видаліть кінцеву точку SageMaker який містить модель LLM.
- Видаліть домен SageMaker який запускає ваші блокноти.
За замовчуванням створена вами програма повинна автоматично припинити роботу через 15 хвилин бездіяльності.
Як правило, вам не потрібно очищати середовище Athena, тому що плата не стягується, коли ви ним не користуєтеся.
Висновок
У цій публікації ми представили набір даних Common Crawl і те, як використовувати EMR Serverless для обробки даних для тонкого налаштування LLM. Потім ми продемонстрували, як використовувати SageMaker JumpStart для точного налаштування LLM і розгортання його без коду. Більше випадків використання EMR Serverless див Amazon EMR без сервера. Додаткову інформацію про хостинг і моделі точного налаштування на Amazon SageMaker JumpStart див Документація Sagemaker JumpStart.
Про авторів
 Шицзянь Тан є спеціалістом з аналітики, архітектором рішень Amazon Web Services.
Шицзянь Тан є спеціалістом з аналітики, архітектором рішень Amazon Web Services.
 Метью Лієм є старшим менеджером з архітектури рішень в Amazon Web Services.
Метью Лієм є старшим менеджером з архітектури рішень в Amazon Web Services.
 Далей Сюй є спеціалістом з аналітики, архітектором рішень Amazon Web Services.
Далей Сюй є спеціалістом з аналітики, архітектором рішень Amazon Web Services.
 Юйцзюнь Сяо є старшим архітектором рішень в Amazon Web Services.
Юйцзюнь Сяо є старшим архітектором рішень в Amazon Web Services.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- :є
- : ні
- :де
- $UP
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- Здатний
- МЕНЮ
- доступ
- доступний
- доступною
- бухгалтерський облік
- Рахунки
- Achieve
- активоване
- додавати
- доповнення
- Африка
- після
- ВСІ
- дозволяє
- Також
- дивовижний
- Amazon
- Amazon EMR
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- кількість
- суми
- an
- аналітика
- та
- Інший
- будь-який
- Apache
- Apache Spark
- додаток
- застосування
- підхід
- архітектура
- ЕСТЬ
- AS
- At
- Австралійський
- автоматичний
- автоматично
- доступний
- AWS
- фон
- заснований
- основа
- BE
- красивий
- оскільки
- становлення
- перед тим
- починати
- буття
- Краще
- між
- Великий
- Великий даних
- Мільярд
- тіло
- обидва
- будувати
- by
- званий
- CAN
- Може отримати
- потужність
- нести
- випадок
- випадків
- заміна
- характер
- вантажі
- перевірка
- китайський
- Вибирати
- клас
- очистити
- клієнт
- кластер
- код
- COM
- загальний
- зазвичай
- порівняти
- повний
- конфігурування
- Вважати
- складається
- Консоль
- постійно
- містити
- містить
- зміст
- постійно
- контрастність
- Відповідний
- відповідає
- Коштувати
- рентабельним
- може
- вважати
- обкладинка
- створювати
- створений
- виготовлений на замовлення
- клієнт
- налаштувати
- дані
- Analytics даних
- обробка даних
- наука про дані
- набори даних
- Девіс
- справу
- Пропозиції
- глибокий
- дефолт
- визначати
- Демонстрація
- демонструвати
- продемонстрований
- розгортання
- розгорнути
- розгортання
- Отриманий
- Незважаючи на
- деталі
- визначення
- схема
- Відмінності
- інакше
- спрямований
- безпосередньо
- обговорення
- занурення
- do
- документація
- домен
- домени
- Дональд
- Не знаю
- вниз
- Драма
- водій
- тривалість
- під час
- кожен
- Раніше
- легко
- Усуває
- підкреслює
- зіткнення
- Машинобудування
- підвищення
- Що натомість? Створіть віртуальну версію себе у
- Навколишнє середовище
- Ефір (ETH)
- оцінювати
- приклад
- Приклади
- виконання
- Здійснювати
- існуючий
- існує
- дослідити
- Розвіданий
- продовжити
- зовнішній
- витяг
- видобуток
- Виписки
- Фолс
- false
- швидше
- доля
- ознаками
- кілька
- Поля
- філе
- Файли
- фільтрувати
- фільтрація
- в кінці кінців
- знайти
- закінчення
- Перший
- після
- слідує
- для
- формат
- знайдений
- Рамки
- каркаси
- від
- далі
- Загальне
- в цілому
- породжує
- покоління
- отримати
- Git
- GitHub
- керівництво
- Мати
- допомога
- Вулик
- хостинг
- хостів
- Як
- How To
- Однак
- HTML
- HTTPS
- Сотні
- i
- IAM
- ID
- if
- ілюструє
- зображення
- імпорт
- важливо
- удосконалювати
- in
- включені
- includes
- включення
- зростаючий
- індекс
- інформація
- Інфраструктура
- вхід
- витрати
- встановлювати
- взаємодіяти
- в
- вводити
- введені
- питання
- IT
- ЙОГО
- роз'єм
- робота
- Джобс
- json
- Jupyter Notebook
- просто
- тримати
- ключ
- мова
- мови
- масштабний
- останній
- запуск
- запуск
- вести
- дозволяти
- рівень
- libraries
- як
- МЕЖА
- ліній
- список
- списки
- Лама
- llm
- місцевий
- розташований
- розташування
- логіка
- Логін
- подивитися
- шукати
- пошук
- машина
- обслуговування
- зробити
- Робить
- менеджер
- управління
- багато
- карта
- масивний
- Може..
- механізм
- Зустрічатися
- відповідає
- згадуючи
- Meta
- метадані
- метод
- протокол
- Пом'якшити
- модель
- Моделі
- щомісячно
- більше
- найбільш
- фільм
- кіно
- багато
- множинний
- ім'я
- Імена
- навігація
- необхідно
- Необхідність
- мережу
- Нові
- наступний
- немає
- вузол
- ноутбук
- ноутбуки
- отриманий
- жовтень
- of
- on
- ONE
- тільки
- відкрити
- з відкритим вихідним кодом
- варіант
- or
- оригінал
- Інше
- з
- викладені
- вихід
- виходи
- над
- перевизначення
- власний
- Pack
- пакет
- pane
- Папір
- Паралельні
- параметри
- Паріс
- частина
- шлях
- стежки
- Платити
- Люди
- продуктивність
- виступи
- виступає
- period
- петабайт
- Пітер
- фотограф
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- ділянку
- точок
- популярний
- пошта
- Харчування
- попередньо
- попередній
- Готувати
- підготовлений
- первинний
- процес
- оброблена
- обробка
- Production
- підказок
- забезпечувати
- за умови
- забезпечує
- забезпечення
- публічно
- цілей
- put
- Python
- запит
- питання
- швидко
- Сировина
- необроблені дані
- досягнення
- Читати
- готовий
- останній
- нещодавно
- рекомендований
- запис
- послатися
- посилання
- регулярно
- відносини
- випущений
- ремонт
- замінювати
- запитів
- вимагається
- Вимога
- ресурси
- відповідь
- відповіді
- результат
- результати
- огляд
- Відгуки
- право
- Роль
- Рорі
- прогін
- біг
- пробіжки
- мудрець
- то ж
- зберегти
- шкала
- ваги
- Масштабування
- сканування
- сценарій
- наука
- сценарій
- scripts
- seconds
- розділ
- розділам
- побачити
- сегмент
- вибрати
- SELF
- старший
- пропозиція
- Без сервера
- сервери
- Послуги
- комплект
- установка
- кілька
- вона
- Короткий
- Повинен
- показаний
- значення
- аналогічний
- з
- один
- сайт
- Розмір
- Уповільнення темпів
- уривок
- So
- рішення
- Рішення
- суп
- Source
- Іскритися
- спеціаліст
- конкретний
- SQL
- SSH
- почалася
- Починаючи
- Заява
- заяви
- Статус
- Крок
- заходи
- Як і раніше
- Стоп
- зберігати
- зберігати
- магазинів
- Історія
- просто
- стратегії
- рядок
- студія
- представляти
- подання
- Успішно
- такі
- достатній
- підходящий
- перемикач
- синхронізація.
- таблиця
- Приймати
- Мета
- Завдання
- завдання
- тензорний потік
- terms
- Тести
- текст
- генерація тексту
- Що
- Команда
- їх
- Їх
- потім
- Там.
- Ці
- вони
- третя сторона
- це
- три
- через
- час
- відмітка часу
- до
- трек
- Навчання
- мандри
- правда
- намагатися
- два
- Типи
- при
- неструктурований
- оновлений
- URL
- використання
- використання випадку
- використовуваний
- користувач
- відгуки про продукт
- користувачі
- використання
- використовує
- версія
- Віртуальний
- Обсяги
- ходити
- хотіти
- хотів
- Склад
- було
- шлях..
- способи
- we
- Web
- веб-сервіси
- week
- ДОБРЕ
- Що
- коли
- в той час як
- який
- в той час як
- ВООЗ
- Жива природа
- волі
- Вільям
- з
- в
- без
- жінка
- працював
- вартість
- запис
- лист
- вихід
- ви
- вашу
- зефірнет