Рекламні повідомлення

Проблеми побудови мультимодальних моделей з нуля
У багатьох випадках використання машинного навчання організації покладаються виключно на табличні дані та моделі на основі дерева, такі як XGBoost і LightGBM. Це тому, що глибоке навчання просто надто складно для більшості команд ML. Серед поширених проблем:
- Брак експертних знань, необхідних для розробки складних моделей глибокого навчання
- Такі фреймворки, як PyTorch і Tensorflow, вимагають від команд написання тисяч рядків коду, схильного до помилок людини
- Навчання розподілених конвеєрів DL вимагає глибоких знань інфраструктури та може зайняти тижні для навчання моделей
У результаті команди втрачають цінні сигнали, приховані в неструктурованих даних, таких як текст і зображення.
Швидка розробка моделі з декларативними системами
Нові декларативні системи машинного навчання, такі як Ludwig з відкритим вихідним кодом, створені в Uber, забезпечують підхід з низьким кодом до автоматизації машинного навчання, що дає змогу командам обробки даних швидше створювати та розгортати найсучасніші моделі за допомогою простого файлу конфігурації. Зокрема, Predibase — провідна декларативна платформа машинного навчання з низьким кодом — разом із Ludwig спрощують створення мультимодальних моделей глибокого навчання в < 15 рядках коду.
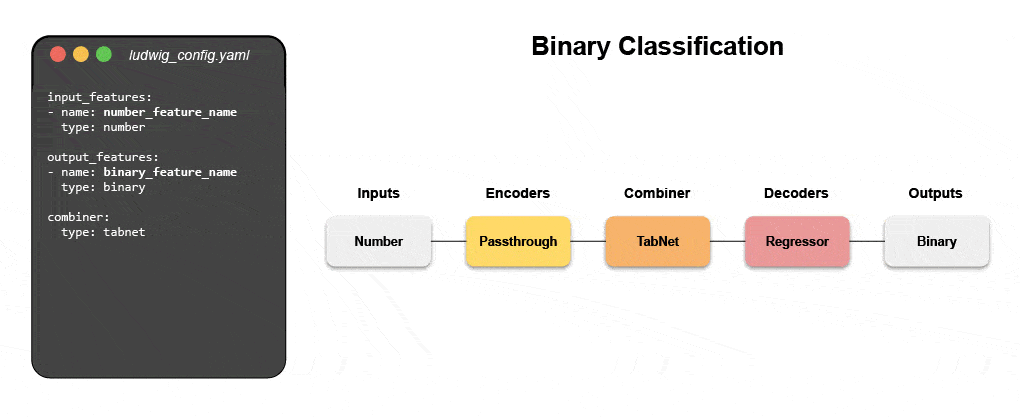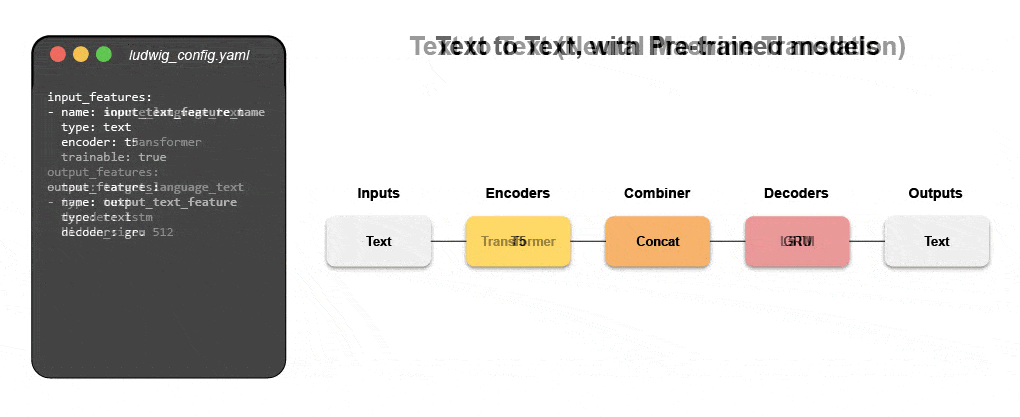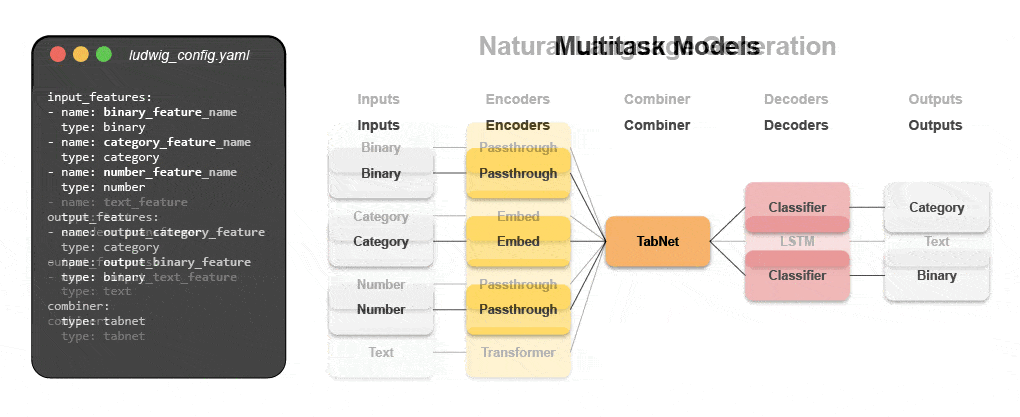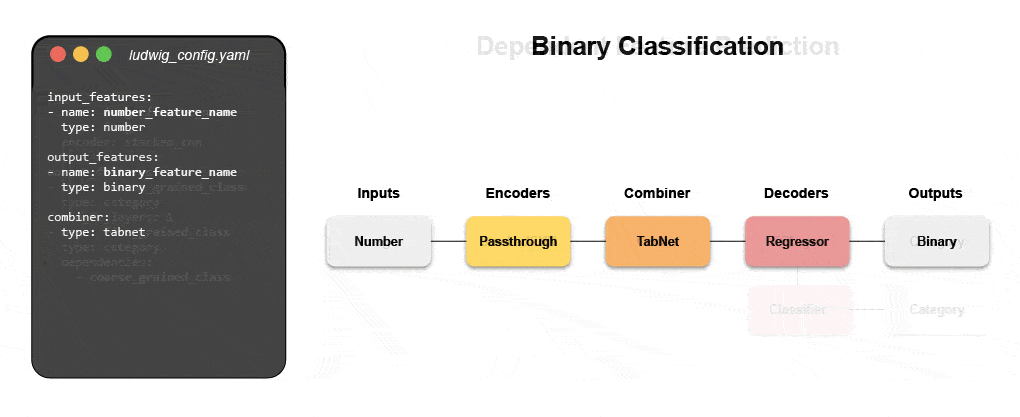
Дізнайтеся, як створити мультимодальну модель за допомогою декларативного ML
Приєднуйтесь до нашого майбутнього вебінару і живий навчальний посібник, щоб дізнатися про декларативні системи, такі як Ludwig, і слідувати покроковим інструкціям для створення мультимодальної моделі прогнозування відгуків клієнтів із використанням текстових і табличних даних.
На цьому занятті ви дізнаєтесь, як:
- Швидке навчання, ітерація та розгортання мультимодальної моделі для прогнозування відгуків клієнтів,
- Використовуйте декларативні інструменти ML з низьким кодом, щоб значно скоротити час, необхідний для створення кількох моделей ML,
- Використовуйте неструктуровані дані так само легко, як і структуровані дані за допомогою Ludwig і Predibase з відкритим кодом
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://www.kdnuggets.com/2023/01/predibase-multi-modal-deep-learning-less-15-lines-code.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-modal-deep-learning-in-less-than-15-lines-of-code
- a
- МЕНЮ
- та
- підхід
- автоматизація
- оскільки
- будувати
- Створюємо
- проблеми
- код
- загальний
- комплекс
- конфігурація
- клієнт
- дані
- глибокий
- глибоке навчання
- розгортання
- розвивати
- розробка
- розподілений
- різко
- легко
- дозволяє
- помилка
- експерт
- швидше
- філе
- стежити
- від
- GIF
- Жорсткий
- прихований
- Як
- How To
- HTML
- HTTPS
- людина
- зображень
- in
- включати
- Інфраструктура
- інструкції
- IT
- KDnuggets
- знання
- провідний
- УЧИТЬСЯ
- вивчення
- використання
- ліній
- жити
- машина
- навчання за допомогою машини
- зробити
- багато
- ML
- модель
- Моделі
- найбільш
- множинний
- необхідний
- з відкритим вихідним кодом
- організації
- plato
- Інформація про дані Платона
- PlatoData
- прогноз
- Прогнози
- піторх
- зменшити
- вимагати
- Вимагається
- результат
- огляд
- Сесія
- сигнали
- простий
- просто
- конкретно
- почалася
- впроваджений
- Крок
- структурований
- Systems
- Приймати
- приймає
- команди
- тензорний потік
- Команда
- тисячі
- час
- до
- занадто
- інструменти
- поїзд
- підручник
- Майбутні
- випадки використання
- Цінний
- тижня
- волі
- в
- запис
- XGBoost
- вашу
- зефірнет





