
Оскільки штучний інтелект переміщується з хмари в Edge, ми бачимо, як технологія використовується в дедалі більшій різноманітності випадків використання – від виявлення аномалій до програм, включаючи розумні покупки, спостереження, робототехніку та автоматизацію виробництва. Отже, універсального рішення для всіх не існує. Але завдяки стрімкому зростанню кількості пристроїв із підтримкою камер штучний інтелект отримав найбільше поширення для аналізу відеоданих у реальному часі для автоматизації відеомоніторингу, щоб підвищити безпеку, покращити операційну ефективність і забезпечити кращий досвід роботи з клієнтами, зрештою отримавши конкурентну перевагу в своїх галузях. . Щоб краще підтримувати аналіз відео, ви повинні розуміти стратегії оптимізації продуктивності системи в розгортаннях периферійного штучного інтелекту.
- Вибір обчислювальних механізмів потрібного розміру, щоб відповідати або перевищувати необхідні рівні продуктивності. Для програми штучного інтелекту ці обчислювальні механізми повинні виконувати функції всього конвеєра бачення (тобто попередня та постобробка відео, висновок нейронної мережі).
Може знадобитися спеціальний прискорювач штучного інтелекту, незалежно від того, чи він буде дискретним, чи інтегрованим у SoC (на відміну від запуску штучного інтелекту на центральному або графічному процесорі).
- Розуміння різниці між пропускною здатністю та затримкою; де пропускна здатність – це швидкість, з якою дані можуть бути оброблені в системі, а затримка вимірює затримку обробки даних у системі та часто пов’язана зі швидкістю реагування в реальному часі. Наприклад, система може генерувати дані зображення зі швидкістю 100 кадрів на секунду (пропускна здатність), але потрібно 100 мс (затримка), щоб зображення пройшло через систему.
- Розглядаючи здатність легко масштабувати продуктивність штучного інтелекту в майбутньому, щоб відповідати зростаючим потребам, вимогам, що змінюються, і технологіям, що розвиваються (наприклад, вдосконалені моделі штучного інтелекту для підвищення функціональності та точності). Ви можете досягти масштабування продуктивності за допомогою прискорювачів штучного інтелекту в модульному форматі або за допомогою додаткових чіпів прискорювача штучного інтелекту.
Фактичні вимоги до продуктивності залежать від програми. Як правило, можна очікувати, що для відеоаналітики система повинна обробляти потоки даних, що надходять від камер, зі швидкістю 30-60 кадрів на секунду та роздільною здатністю 1080p або 4k. Камера з підтримкою ШІ оброблятиме один потік; периферійний пристрій оброблятиме декілька потоків паралельно. У будь-якому випадку периферійна система штучного інтелекту повинна підтримувати функції попередньої обробки для перетворення даних датчика камери у формат, який відповідає вхідним вимогам розділу штучного інтелекту (рис. 1).
Функції попередньої обробки беруть необроблені дані та виконують такі завдання, як зміна розміру, нормалізація та перетворення колірного простору, перш ніж подавати вхідні дані в модель, що працює на прискорювачі AI. Попередня обробка може використовувати ефективні бібліотеки обробки зображень, такі як OpenCV, щоб скоротити час попередньої обробки. Постобробка передбачає аналіз результату висновку. Він використовує такі завдання, як немаксимальне придушення (NMS інтерпретує вихідні дані більшості моделей виявлення об’єктів) і відображення зображень для генерації корисних ідей, таких як обмежувальні прямокутники, мітки класів або показники достовірності.

Малюнок 1. Для визначення моделі штучного інтелекту функції попередньої та постобробки зазвичай виконуються на прикладному процесорі.
Виведення моделі штучного інтелекту може мати додаткову проблему з обробки кількох моделей нейронної мережі на кадр, залежно від можливостей програми. Програми комп’ютерного бачення зазвичай передбачають кілька завдань штучного інтелекту, що вимагають конвеєра з кількох моделей. Крім того, вихід однієї моделі часто є входом наступної моделі. Іншими словами, моделі в додатку часто залежать одна від одної і повинні виконуватися послідовно. Точний набір моделей для виконання може не бути статичним і може змінюватися динамічно, навіть на основі кадру за кадром.
Завдання динамічного запуску кількох моделей вимагає зовнішнього прискорювача штучного інтелекту зі спеціальною та достатньо великою пам’яттю для зберігання моделей. Часто інтегрований прискорювач штучного інтелекту всередині SoC не в змозі керувати багатомодельним робочим навантаженням через обмеження, накладені підсистемою спільної пам’яті та іншими ресурсами в SoC.
Наприклад, відстеження об’єкта на основі передбачення руху покладається на безперервне виявлення для визначення вектора, який використовується для ідентифікації відстежуваного об’єкта в майбутньому положенні. Ефективність цього підходу обмежена, оскільки він не має можливості справжньої повторної ідентифікації. За допомогою передбачення руху слід об’єкта може бути втрачений через пропуски виявлення, оклюзії або об’єкт покидає поле зору, навіть миттєво. Після втрати траєкторії об’єкта неможливо відновити. Додавання повторної ідентифікації усуває це обмеження, але вимагає вбудовування візуального вигляду (тобто відбитка зображення). Для вбудовування зовнішнього вигляду потрібна друга мережа для створення вектора ознак шляхом обробки зображення, що міститься всередині обмежувальної рамки об’єкта, виявленого першою мережею. Це вбудовування можна використовувати для повторної ідентифікації об’єкта, незалежно від часу чи простору. Оскільки вбудовування необхідно генерувати для кожного об’єкта, виявленого в полі зору, вимоги до обробки збільшуються, оскільки сцена стає більш завантаженою. Відстеження об’єктів із повторною ідентифікацією вимагає ретельного розгляду між виконанням виявлення з високою точністю/високою роздільною здатністю/високою частотою кадрів і резервуванням достатніх накладних витрат для масштабованості вбудовування. Один із способів вирішити вимоги до обробки – використовувати спеціальний прискорювач AI. Як згадувалося раніше, механізм штучного інтелекту SoC може страждати через брак спільних ресурсів пам’яті. Оптимізацію моделі також можна використовувати для зниження вимог до обробки, але це може вплинути на продуктивність і/або точність.
У інтелектуальній камері або периферійному пристрої інтегрований SoC (тобто головний процесор) отримує відеокадри та виконує етапи попередньої обробки, які ми описали раніше. Ці функції можна виконувати за допомогою ядер процесора чи графічного процесора (якщо він доступний), але вони також можуть виконуватися спеціальними апаратними прискорювачами в системі на процесорі (наприклад, процесор сигналів зображення). Після завершення цих етапів попередньої обробки прискорювач штучного інтелекту, інтегрований у SoC, може отримати прямий доступ до цього квантованого вхідного сигналу із системної пам’яті, або у випадку дискретного прискорювача штучного інтелекту вхідні дані потім доставляються для висновку, як правило, через Інтерфейс USB або PCIe.
Інтегрований SoC може містити низку обчислювальних блоків, включаючи центральні процесори, графічні процесори, прискорювач штучного інтелекту, процесори зору, відеокодери/декодери, процесор сигналу зображення (ISP) тощо. Усі ці обчислювальні блоки спільно використовують одну шину пам’яті й, отже, мають доступ до однієї пам’яті. Крім того, ЦП і ГП також можуть відігравати певну роль у висновках, і ці блоки будуть зайняті виконанням інших завдань у розгорнутій системі. Це те, що ми маємо на увазі під накладними витратами на системному рівні (рис. 2).
Багато розробників помилково оцінюють продуктивність вбудованого прискорювача штучного інтелекту в SoC, не враховуючи вплив накладних витрат на системному рівні на загальну продуктивність. Як приклад, розглянемо запуск тесту YOLO на прискорювачі 50 TOPS AI, інтегрованому в SoC, який може отримати результат тесту 100 висновків/секунду (IPS). Але в розгорнутій системі з усіма іншими активними обчислювальними блоками ці 50 TOPS можуть зменшитися приблизно до 12 TOPS, а загальна продуктивність дасть лише 25 IPS, припускаючи щедрий коефіцієнт використання 25%. Системні витрати завжди є фактором, якщо платформа постійно обробляє відеопотоки. В якості альтернативи, за допомогою дискретного прискорювача AI (наприклад, Kinara Ara-1, Hailo-8, Intel Myriad X), використання системного рівня може перевищувати 90%, тому що як тільки головний SoC ініціює функцію виведення та передає вхідні дані моделі AI даних, прискорювач працює автономно, використовуючи свою виділену пам’ять для доступу до вагових коефіцієнтів і параметрів моделі.
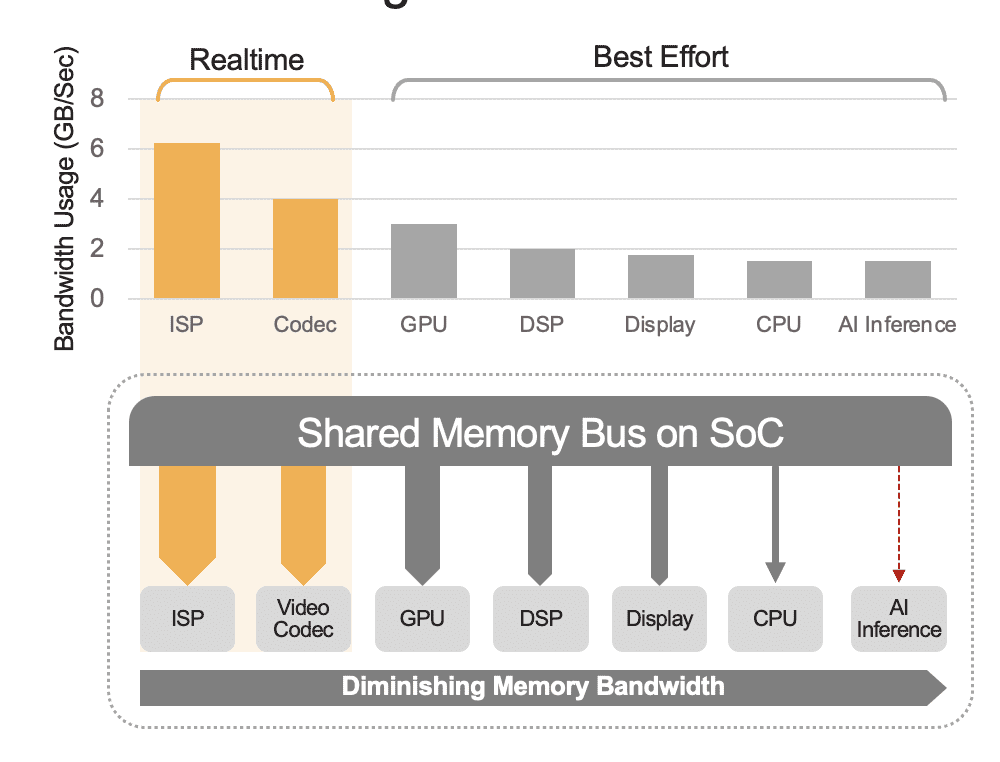
Малюнок 2. Шина спільної пам’яті керуватиме продуктивністю системного рівня, показано тут із приблизними значеннями. Справжні значення змінюватимуться залежно від моделі використання програми та конфігурації обчислювального блоку SoC.
До цього моменту ми обговорювали продуктивність штучного інтелекту з точки зору кадрів за секунду та TOPS. Але низька затримка є ще однією важливою вимогою для забезпечення оперативності реагування системи в реальному часі. Наприклад, в іграх низька затримка має вирішальне значення для безперебійної та чутливої ігри, особливо в іграх із керуванням рухом і системах віртуальної реальності (VR). У системах автономного водіння низька затримка життєво важлива для виявлення об’єктів у реальному часі, розпізнавання пішоходів, смуги руху та розпізнавання дорожніх знаків, щоб уникнути шкоди для безпеки. Для систем автономного водіння зазвичай потрібна наскрізна затримка менше 150 мс від виявлення до фактичної дії. Подібним чином у виробництві низька затримка є важливою для виявлення дефектів у реальному часі, розпізнавання аномалій, а роботизоване керування залежить від відеоаналітики з низькою затримкою для забезпечення ефективної роботи та мінімізації простою виробництва.
Загалом існує три компоненти затримки в програмі відеоаналітики (рис. 3):
- Затримка захоплення даних – це час від моменту захоплення відеокадром датчиком камери до моменту, коли кадр стає доступним системі аналітики для обробки. Ви можете оптимізувати цю затримку, вибравши камеру зі швидким датчиком і процесором із низькою затримкою, вибравши оптимальну частоту кадрів і використовуючи ефективні формати стиснення відео.
- Затримка передавання даних – це час, протягом якого захоплені та стиснені відеодані переміщуються від камери до периферійних пристроїв або локальних серверів. Це включає затримки обробки мережі, які виникають у кожній кінцевій точці.
- Затримка обробки даних означає час, протягом якого периферійні пристрої виконують завдання обробки відео, такі як декомпресія кадрів і алгоритми аналітики (наприклад, відстеження об’єктів на основі передбачення руху, розпізнавання облич). Як зазначалося раніше, затримка обробки ще більш важлива для додатків, які повинні запускати кілька моделей AI для кожного кадру відео.
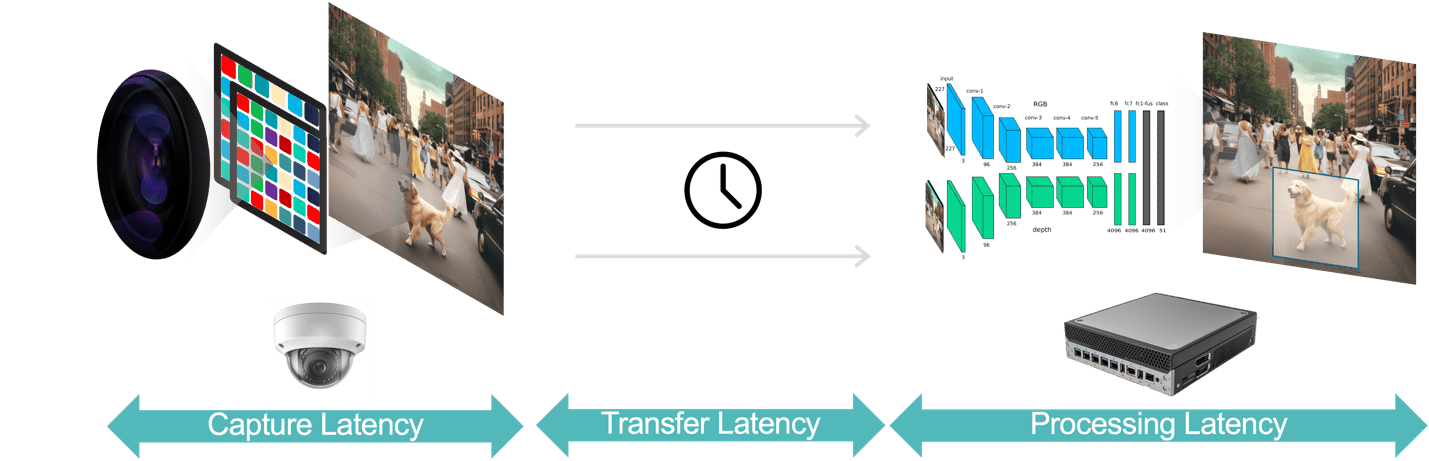
Рисунок 3. Конвеєр відеоаналітики складається із збору, передачі та обробки даних.
Затримку обробки даних можна оптимізувати за допомогою прискорювача штучного інтелекту з архітектурою, розробленою для мінімізації переміщення даних між чіпом і між обчисленням і різними рівнями ієрархії пам’яті. Крім того, щоб покращити затримку та ефективність системного рівня, архітектура повинна підтримувати нульовий (або майже нульовий) час перемикання між моделями, щоб краще підтримувати багатомодельні програми, про які ми говорили раніше. Інший фактор як для покращення продуктивності, так і для затримки пов’язаний з гнучкістю алгоритму. Іншими словами, деякі архітектури створені для оптимальної роботи лише на певних моделях штучного інтелекту, але в умовах швидкої зміни середовища штучного інтелекту нові моделі для вищої продуктивності та кращої точності з’являються щодня. Тому вибирайте периферійний процесор ШІ без практичних обмежень щодо топології моделі, операторів і розміру.
Існує багато факторів, які слід враховувати для максимізації продуктивності в периферійному пристрої ШІ, включаючи вимоги до продуктивності та затримки, а також накладні витрати на систему. Успішна стратегія має передбачити зовнішній прискорювач штучного інтелекту, щоб подолати обмеження пам’яті та продуктивності механізму штучного інтелекту SoC.
Ч.Х. сир Чи є досвідченим спеціалістом із маркетингу та управління продуктами, Чі має великий досвід просування продуктів і рішень у напівпровідниковій промисловості, зосереджуючись на штучному інтелекті на основі візуалізації, підключенні та відеоінтерфейсах для багатьох ринків, включаючи корпоративні та споживчі. Як підприємець, Чі став співзасновником двох стартапів відеонапівпровідників, які були придбані державною напівпровідниковою компанією. Чі очолював команди з маркетингу продуктів, і йому подобається працювати з невеликою командою, яка зосереджена на досягненні чудових результатів.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- : має
- :є
- : ні
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- здатність
- прискорювач
- прискорювачі
- доступ
- доступ до
- розмістити
- виконувати
- точність
- досягнення
- придбаний
- Набуває
- через
- дію
- активний
- фактичний
- додати
- Додатковий
- прийнята
- просунутий
- після
- знову
- AI
- Двигун AI
- Моделі AI
- алгоритмічний
- алгоритми
- ВСІ
- Також
- завжди
- an
- аналіз
- аналітика
- Аналізуючи
- та
- виявлення аномалії
- Інший
- додаток
- застосування
- підхід
- архітектура
- ЕСТЬ
- AS
- асоційований
- At
- автоматизувати
- Автоматизація
- автономний
- автономно
- наявність
- доступний
- уникнути
- заснований
- основа
- BE
- оскільки
- стає
- було
- перед тим
- буття
- еталонний тест
- Краще
- між
- обидва
- Box
- коробки
- вбудований
- bus
- зайнятий
- але
- by
- кімната
- камери
- CAN
- можливості
- можливості
- захоплення
- захоплений
- захопивши
- обережний
- випадок
- випадків
- виклик
- заміна
- чіп
- Чіпси
- Вибираючи
- клас
- хмара
- color
- майбутній
- компанія
- конкурентоспроможний
- Зроблено
- Компоненти
- компрометуючі
- обчислення
- обчислювальна
- обчислення
- комп'ютер
- Комп'ютерне бачення
- Програми комп'ютерного зору
- довіра
- конфігурація
- зв'язок
- Отже
- Вважати
- розгляду
- вважається
- беручи до уваги
- складається
- обмеження
- споживач
- містити
- містяться
- безперервний
- постійно
- Перетворення
- може
- центральний процесор
- критичний
- клієнт
- дані
- обробка даних
- день
- присвячених
- затримка
- затримки
- доставляти
- поставляється
- залежний
- Залежно
- розгорнути
- розгортання
- описаний
- призначений
- виявлено
- Виявлення
- Визначати
- розробників
- прилади
- різниця
- безпосередньо
- обговорювалися
- дисплей
- час простою
- водіння
- два
- динамічно
- e
- кожен
- Раніше
- легко
- край
- ефект
- ефективність
- Ефективність
- ефективність
- ефективний
- або
- вбудовування
- кінець
- кінець в кінець
- двигун
- Двигуни
- підвищувати
- забезпечувати
- підприємство
- Весь
- Підприємець
- Навколишнє середовище
- істотний
- оцінка
- оцінювати
- Навіть
- Кожен
- еволюціонує
- приклад
- перевищувати
- виконувати
- виконано
- виконавчий
- очікувати
- досвід
- Досліди
- обширний
- Великий досвід
- зовнішній
- Face
- розпізнавання обличчя
- фактор
- фактори
- завод
- ШВИДКО
- особливість
- годування
- поле
- Рисунок
- відбиток пальця
- Перший
- Гнучкість
- фокусується
- фокусування
- для
- формат
- FRAME
- від
- функція
- функціональність
- Функції
- Крім того
- майбутнє
- набирає
- Games
- азартні ігри
- ігровий досвід
- Загальне
- породжувати
- генерується
- щедрий
- Go
- GPU
- Графічні процесори
- великий
- великий
- Зростання
- Зростання
- керівництво
- апаратні засоби
- Мати
- отже
- тут
- ієрархія
- Високий
- вище
- господар
- HTTPS
- i
- ідентифікувати
- if
- зображення
- Impact
- важливо
- накладений
- удосконалювати
- поліпшений
- in
- В інших
- includes
- У тому числі
- Augmenter
- збільшений
- промисловості
- промисловість
- Посвячені
- вхід
- всередині
- розуміння
- інтегрований
- Intel
- інтерфейс
- Інтерфейси
- в
- залучати
- включає в себе
- незалежно
- ISP
- IT
- ЙОГО
- KDnuggets
- етикетки
- відсутність
- Lane
- великий
- Затримка
- догляд
- Led
- менше
- рівні
- libraries
- як
- обмеження
- недоліки
- обмеженою
- місцевий
- втрачений
- низький
- знизити
- управляти
- управління
- виробництво
- багато
- Маркетинг
- ринки
- Максимізувати
- максимізація
- Може..
- значити
- заходи
- Зустрічатися
- пам'ять
- згаданий
- може бути
- пропущений
- модель
- Моделі
- Модулі
- моніторинг
- більше
- найбільш
- рух
- руху
- множинний
- повинен
- безліч
- Близько
- потреби
- мережу
- Нейронний
- нейронної мережі
- Нові
- наступний
- немає
- об'єкт
- Виявлення об'єктів
- відбуваються
- of
- часто
- on
- один раз
- ONE
- тільки
- OpenCV
- операція
- оперативний
- Оператори
- протистояли
- оптимальний
- оптимізація
- Оптимізувати
- оптимізований
- оптимізуючий
- or
- Інше
- з
- вихід
- над
- загальний
- Подолати
- Паралельні
- параметри
- особливо
- для
- виконувати
- продуктивність
- виконується
- виконанні
- виступає
- трубопровід
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- Play
- точка
- положення
- подальша обробка
- Практичний
- прогноз
- процес
- оброблена
- обробка
- процесор
- процесори
- Product
- Production
- Продукти
- сприяння
- забезпечувати
- громадськість
- діапазон
- ранжування
- швидко
- швидко
- ставка
- ставки
- Сировина
- необроблені дані
- реальний
- реального часу
- Реальність
- визнання
- зменшити
- відноситься
- вимагати
- вимагається
- вимога
- Вимога
- Вимагається
- дозвіл
- ресурси
- реагувати
- Обмеження
- результат
- результати
- робототехніка
- Роль
- прогін
- біг
- пробіжки
- Безпека
- то ж
- масштабованість
- шкала
- масштаб ai
- Масштабування
- сцена
- безліч
- безшовні
- другий
- розділ
- побачити
- Здається,
- вибирає
- напівпровідник
- комплект
- Поділитись
- загальні
- покупка
- Повинен
- показаний
- підпис
- Сигнал
- Аналогічно
- з
- один
- Розмір
- невеликий
- розумний
- рішення
- Рішення
- ВИРІШИТИ
- Вирішує
- деякі
- що в сім'ї щось
- Простір
- конкретний
- стартапів
- заходи
- зберігати
- стратегії
- Стратегія
- потік
- потоки
- успішний
- такі
- достатній
- підтримка
- придушення
- спостереження
- система
- Systems
- Приймати
- приймає
- завдання
- команда
- команди
- Технології
- Технологія
- terms
- ніж
- Що
- Команда
- Майбутнє
- їх
- потім
- Там.
- отже
- Ці
- вони
- це
- ті
- три
- через
- пропускна здатність
- час
- times
- до
- верхівки
- Усього:
- трек
- Відстеження
- трафік
- переклад
- переклади
- Перетворення
- подорожувати
- правда
- два
- типово
- Зрештою
- не в змозі
- розуміти
- блок
- одиниць
- Використання
- USB
- використання
- використовуваний
- використовує
- використання
- зазвичай
- використовує
- Цінності
- різноманітність
- різний
- Відео
- вид
- Віртуальний
- Віртуальна реальність
- бачення
- життєво важливий
- vr
- шлях..
- we
- були
- Що
- Чи
- який
- широко
- волі
- з
- без
- слова
- робочий
- б
- X
- вихід
- Йоло
- ви
- вашу
- зефірнет
- нуль







