By Девід Вендт та Грегорі Кімбол
Ефективна обробка рядкових даних життєво важлива для багатьох програм обробки даних. Щоб отримати цінну інформацію з рядкових даних, RAPIDS libcudf надає потужні засоби для прискорення перетворень рядкових даних. libcudf — це бібліотека C++ GPU DataFrame, яка використовується для завантаження, об’єднання, агрегування та фільтрації даних.
У науці про дані рядкові дані представляють мову, текст, генетичні послідовності, журналювання та багато інших типів інформації. Під час роботи з рядковими даними для машинного навчання та розробки функцій дані часто потрібно нормалізувати та трансформувати, перш ніж їх можна буде застосувати до конкретних випадків використання. libcudf надає як API загального призначення, так і утиліти на стороні пристрою, щоб уможливити широкий спектр спеціальних операцій із рядками.
Ця публікація демонструє, як вміло трансформувати стовпці рядків за допомогою API загального призначення libcudf. Ви отримаєте нові знання про те, як розблокувати максимальну продуктивність за допомогою спеціальних ядер і утиліт libcudf на стороні пристрою. Ця публікація також проведе вас через приклади того, як найкраще керувати пам’яттю GPU та ефективно створювати стовпці libcudf, щоб пришвидшити перетворення рядків.
libcudf зберігає рядкові дані в пам'яті пристрою за допомогою Формат стрілки, який представляє рядкові стовпці як два дочірні стовпці: chars and offsets (Мал. 1).
Команда chars стовпець містить рядкові дані як символьні байти в кодуванні UTF-8, які безперервно зберігаються в пам’яті.
Команда offsets Стовпець містить зростаючу послідовність цілих чисел, які є байтовими позиціями, що визначають початок кожного окремого рядка в масиві даних chars. Останнім елементом зміщення є загальна кількість байтів у стовпці chars. Це означає розмір окремого рядка в рядку i визначається як (offsets[i+1]-offsets[i]).
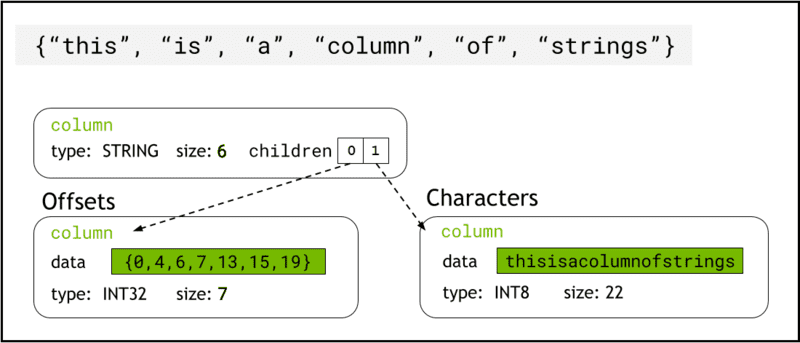 Малюнок 1. Схема, яка показує, як формат Arrow представляє стовпці рядків
Малюнок 1. Схема, яка показує, як формат Arrow представляє стовпці рядків chars та offsets дочірні стовпці
Щоб проілюструвати приклад перетворення рядка, розглянемо функцію, яка отримує два стовпці вхідних рядків і створює один відредагований стовпець вихідних рядків.
Вхідні дані мають такий вигляд: стовпець «імена», що містить імена та прізвища, розділені пробілом, і стовпець «видимість», що містить статус «публічний» або «приватний».
Ми пропонуємо функцію «редагувати», яка працює з вхідними даними, щоб отримати вихідні дані, що складаються з перших ініціалів прізвища, за якими йде пробіл і повне ім’я. Однак, якщо відповідний стовпець видимості є «приватним», тоді вихідний рядок має бути повністю відредаговано як «X X».
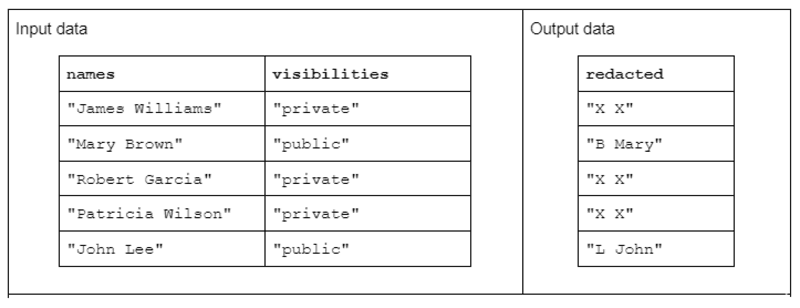 Таблиця 1. Приклад перетворення рядка «редагування», яке отримує стовпці рядків імен і видимості як вхідні дані та частково або повністю відредаговані дані як вихідні дані
Таблиця 1. Приклад перетворення рядка «редагування», яке отримує стовпці рядків імен і видимості як вхідні дані та частково або повністю відредаговані дані як вихідні дані
По-перше, перетворення рядка може бути здійснено за допомогою API рядків libcudf. API загального призначення є чудовою відправною точкою та хорошою базою для порівняння продуктивності.
Функції API працюють з усім стовпцем рядків, запускаючи принаймні одне ядро для кожної функції та призначаючи один потік для кожного рядка. Кожен потік обробляє один рядок даних паралельно через графічний процесор і виводить один рядок як частину нового вихідного стовпця.
Щоб виконати приклад функції редагування за допомогою API загального призначення, виконайте такі дії:
- Перетворіть стовпець рядків «видимості» на логічний стовпець за допомогою
contains - Створіть новий стовпець рядків зі стовпця імен, скопіювавши «XX», коли відповідний запис рядка в логічному стовпці має значення «false»
- Розділіть стовпець «відредаговано» на стовпці імені та прізвища
- Виріжте перші букви прізвищ як ініціали прізвищ
- Створіть вихідний стовпець, об’єднавши останній стовпець ініціалів і стовпець імен за допомогою пробілу (" ").
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
Цей підхід займає приблизно 3.5 мс на A6000 із 600 тис. рядків даних. Цей приклад використовує contains, copy_if_else, split, slice_strings та concatenate щоб виконати настроюване перетворення рядка. Профільний аналіз с Системи Nsight показує, що split функція займає найбільшу кількість часу, а потім slice_strings та concatenate.
На малюнку 2 показано дані профілювання від Nsight Systems прикладу redact, що демонструє наскрізну обробку рядків зі швидкістю до ~600 мільйонів елементів на секунду. Області відповідають діапазонам NVTX, пов’язаним із кожною функцією. Світло-блакитні діапазони відповідають періодам, коли працюють ядра CUDA.
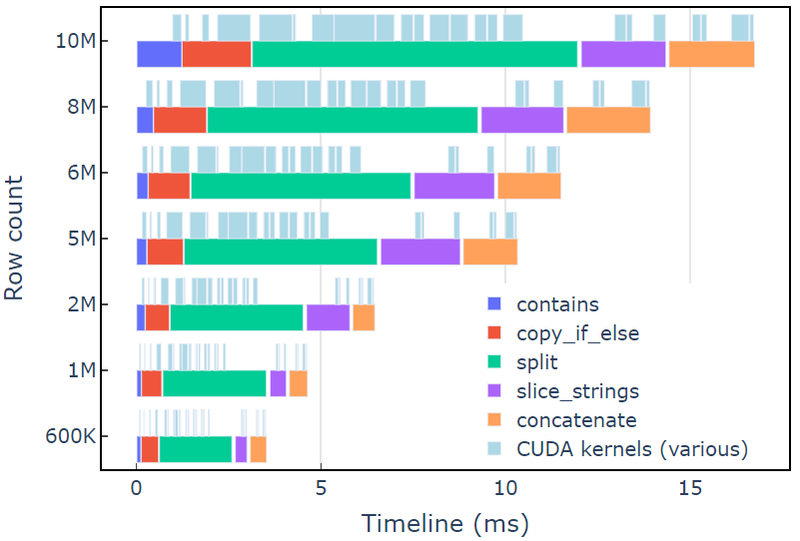 Малюнок 2. Дані профілювання з Nsight Systems прикладу redact
Малюнок 2. Дані профілювання з Nsight Systems прикладу redact
API рядків libcudf — це швидкий і ефективний набір інструментів для перетворення рядків, але інколи критичні для продуктивності функції повинні працювати ще швидше. Основним джерелом додаткової роботи в API рядків libcudf є створення принаймні одного нового стовпця рядків у глобальній пам’яті пристрою для кожного виклику API, що відкриває можливість об’єднати кілька викликів API у користувальницьке ядро.
Обмеження продуктивності у викликах malloc ядра
По-перше, ми створимо власне ядро для реалізації прикладу перетворення redact. Розробляючи це ядро, ми повинні мати на увазі, що стовпці рядків libcudf є незмінними.
Стовпці рядків не можна змінити на місці, оскільки байти символів зберігаються безперервно, і будь-які зміни довжини рядка призведуть до недійсності даних зсуву. Тому redact_kernel Спеціальне ядро створює новий стовпець рядків за допомогою фабрики стовпців libcudf для створення обох offsets та chars дочірні стовпці.
У цьому першому підході створюється вихідний рядок для кожного рядка динамічна пам'ять пристрою за допомогою виклику malloc всередині ядра. Спеціальний вихід ядра — це вектор покажчиків пристроїв на вихід кожного рядка, і цей вектор служить вхідними даними для фабрики стовпців рядків.
Спеціальне ядро приймає a cudf::column_device_view для доступу до даних стовпця рядків і використовує element метод повернення a cudf::string_view представлення даних рядка за вказаним індексом рядка. Вихід ядра є вектором типу cudf::string_view який містить покажчики на пам’ять пристрою, що містить вихідний рядок і розмір цього рядка в байтах.
Команда cudf::string_view Клас подібний до класу std::string_view, але реалізований спеціально для libcudf і обгортає фіксовану довжину символьних даних у пам’яті пристрою, закодованих як UTF-8. Він має багато однакових функцій (find та substr функції, наприклад) і обмеження (без нульового термінатора), як std відповідник. А cudf::string_view представляє послідовність символів, що зберігається в пам’яті пристрою, і тому ми можемо використовувати її тут для запису пам’яті mallocd для вихідного вектора.
Ядро Malloc
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
Це може здатися розумним підходом, поки не буде виміряно продуктивність ядра. Цей підхід займає приблизно 108 мс на A6000 із 600 тис. рядків даних, що більш ніж у 30 разів повільніше, ніж рішення, надане вище з використанням API рядків libcudf.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
Основним вузьким місцем є malloc/free виклики всередині двох ядер тут. Потрібна динамічна пам’ять пристрою CUDA malloc/free викликає синхронізацію в ядрі, в результаті чого паралельне виконання перетворюється на послідовне.
Попереднє виділення робочої пам'яті для усунення вузьких місць
Усуньте malloc/free вузьке місце шляхом заміни malloc/free виклики в ядрі з попередньо виділеною робочою пам'яттю перед запуском ядра.
Для прикладу redact вихідний розмір кожного рядка в цьому прикладі не повинен бути більшим за сам вхідний рядок, оскільки логіка видаляє лише символи. Таким чином, один буфер пам'яті пристрою може бути використаний з тим же розміром, що і вхідний буфер. Використовуйте введені зсуви, щоб знайти позицію кожного рядка.
Доступ до зсувів стовпця рядків передбачає обгортання cudf::column_view з cudf::strings_column_view і називає його offsets_begin метод. Розмір chars дочірній стовпець також можна отримати за допомогою chars_size метод. Потім а rmm::device_uvector попередньо виділяється перед викликом ядра для зберігання символьних вихідних даних.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);Попередньо виділене ядро
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
Ядро виводить вектор cudf::string_view об'єктів, які передаються в cudf::make_strings_column заводська функція. Другий параметр цієї функції використовується для ідентифікації нульових записів у вихідному стовпці. Приклади в цьому дописі не містять нульових записів, тому заповнювач nullptr cudf::string_view{nullptr,0} використовується.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
Цей підхід займає приблизно 1.1 мс на A6000 із 600 тис. рядків даних і, отже, перевищує базову лінію більш ніж у 2 рази. Приблизний розбивка показана нижче:
redact_kernel 66us make_strings_column 400us
Час, що залишився, витрачається на cudaMalloc, cudaFree, cudaMemcpy, що є типовим для накладних витрат на керування тимчасовими примірниками rmm::device_uvector. Цей метод добре працює, якщо гарантовано, що всі вихідні рядки мають такий самий розмір або менше, як і вхідні рядки.
Загалом, перехід до масового розподілу робочої пам’яті за допомогою RAPIDS RMM є значним покращенням і гарним рішенням для користувацької функції рядків.
Оптимізація створення стовпців для швидшого часу обчислень
Чи є спосіб ще більше покращити це? Вузьким місцем зараз є cudf::make_strings_column фабрична функція, яка створює два компоненти стовпця рядків, offsets та chars, від вектора cudf::string_view об’єкти.
У libcudf включено багато фабричних функцій для створення стовпців рядків. Фабрична функція, використана в попередніх прикладах, приймає a cudf::device_span of cudf::string_view об’єктів, а потім створює стовпець, виконуючи a gather на базових символьних даних для створення зсувів і дочірніх стовпців символів. А rmm::device_uvector автоматично перетворюється на a cudf::device_span без копіювання даних.
Однак, якщо вектор символів і вектор зсувів будуються безпосередньо, тоді можна використовувати іншу фабричну функцію, яка просто створює стовпець рядків, не вимагаючи збирання для копіювання даних.
Команда sizes_kernel робить перший прохід над вхідними даними, щоб обчислити точний вихідний розмір кожного вихідного рядка:
Оптимізоване ядро: Частина 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
Потім вихідні розміри перетворюються на зміщення шляхом виконання на місці exclusive_scan. Зауважимо, що offsets вектор створено за допомогою names.size()+1 елементів. Останній запис буде загальною кількістю байтів (усі розміри додані разом), тоді як перший запис буде 0. Обидва вони обробляються exclusive_scan виклик. Розмір chars стовпець витягується з останнього запису в offsets для побудови вектора символів.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
Команда redact_kernel логіка майже така сама, за винятком того, що вона приймає вихідні дані d_offsets вектор для визначення місця виведення кожного рядка:
Оптимізоване ядро: Частина 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
Розмір виходу d_chars стовпець витягується з останнього запису в d_offsets для розміщення вектора символів. Ядро запускається з попередньо обчисленим вектором зсувів і повертає заповнений вектор символів. Нарешті, фабрика стовпців рядків libcudf створює стовпці вихідних рядків.
це cudf::make_strings_column функція factory створює стовпець рядків без копіювання даних. The offsets дані та chars дані вже мають правильний очікуваний формат, і ця фабрика просто переміщує дані з кожного вектора та створює структуру стовпця навколо нього. Після завершення rmm::device_uvectors та цінності offsets та chars порожні, їх дані переміщено до вихідного стовпця.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
Цей підхід займає близько 300 мкс (0.3 мс) на A6000 із 600 тис. рядків даних і покращує попередній підхід більш ніж у 2 рази. Ви можете це помітити sizes_kernel та redact_kernel поділяють майже ту саму логіку: один раз для вимірювання розміру виводу, а потім знову для заповнення виводу.
З точки зору якості коду, корисно рефакторинг трансформації як функції пристрою, яка викликається ядрами sizes і redact. З точки зору продуктивності, ви можете бути здивовані, побачивши, що обчислювальні витрати на перетворення оплачуються двічі.
Переваги для керування пам’яттю та більш ефективного створення стовпців часто переважують обчислювальні витрати на виконання перетворення двічі.
У таблиці 2 показано час обчислення, кількість ядра та оброблені байти для чотирьох рішень, які обговорюються в цій публікації. «Загальна кількість запущених ядер» відображає загальну кількість запущених ядер, включаючи обчислювальні та допоміжні ядра. «Загальна кількість оброблених байтів» — це сукупна пропускна здатність DRAM для читання та запису, а «мінімальна кількість оброблених байтів» — це в середньому 37.9 байтів на рядок для наших тестових входів і виходів. Ідеальний випадок «обмеженої пропускної здатності пам’яті» передбачає пропускну здатність 768 ГБ/с, що є теоретичною максимальною пропускною здатністю A6000.
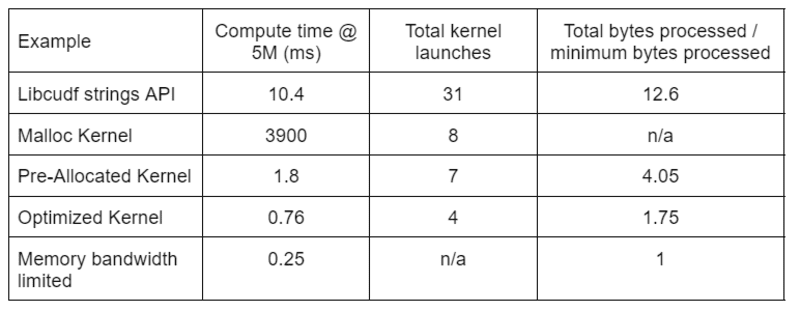 Таблиця 2. Час обчислення, кількість ядра та оброблені байти для чотирьох рішень, розглянутих у цій публікації
Таблиця 2. Час обчислення, кількість ядра та оброблені байти для чотирьох рішень, розглянутих у цій публікації
«Оптимізоване ядро» забезпечує найвищу пропускну здатність завдяки зменшеній кількості запусків ядра та меншій загальній кількості оброблених байтів. Завдяки ефективним користувацьким ядрам загальна кількість запусків ядра зменшується з 31 до 4, а загальна кількість оброблених байтів — з 12.6x до 1.75x від розміру введення та виведення.
Як наслідок, настроюване ядро забезпечує більш ніж у 10 разів більшу пропускну здатність, ніж API рядків загального призначення для перетворення редагування.
Ресурс пам'яті пулу в RAPIDS Memory Manager (RMM) це ще один інструмент, який можна використовувати для підвищення продуктивності. У наведених вище прикладах використовується стандартний «ресурс пам’яті CUDA» для розподілу та звільнення глобальної пам’яті пристрою. Однак час, необхідний для виділення робочої пам’яті, додає значну затримку між кроками перетворень рядків. «Ресурс пам’яті пулу» в RMM зменшує затримку, виділяючи великий пул пам’яті наперед і призначаючи підрозділи за потреби під час обробки.
З ресурсом пам’яті CUDA «Оптимізоване ядро» демонструє прискорення в 10-15 разів, яке починає зменшуватися при більшій кількості рядків через збільшення розміру розподілу (рис. 3). Використання ресурсу пам’яті пулу пом’якшує цей ефект і підтримує прискорення у 15–25 разів порівняно з підходом API рядків libcudf.
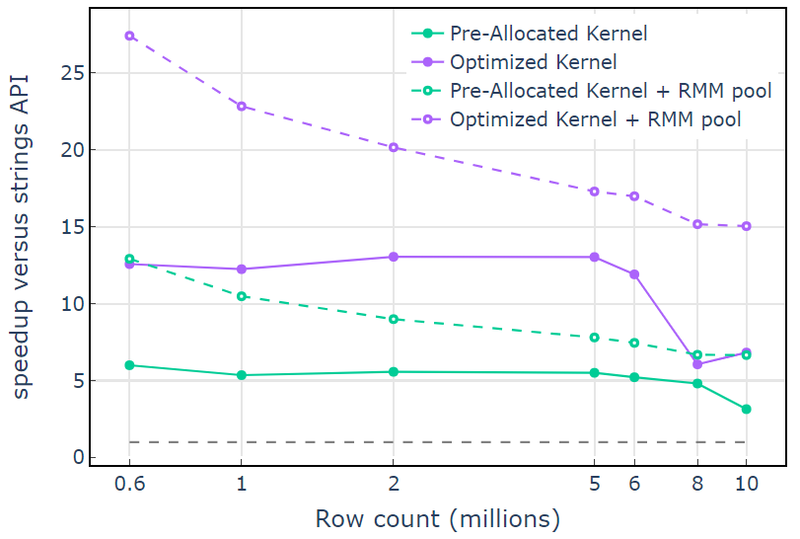 Малюнок 3. Прискорення від користувальницьких ядер «Попередньо виділеного ядра» та «Оптимізованого ядра» з ресурсом пам’яті CUDA за замовчуванням (суцільний) і ресурсом пам’яті пулу (пунктир), порівняно з API рядка libcudf, що використовує ресурс пам’яті CUDA за замовчуванням
Малюнок 3. Прискорення від користувальницьких ядер «Попередньо виділеного ядра» та «Оптимізованого ядра» з ресурсом пам’яті CUDA за замовчуванням (суцільний) і ресурсом пам’яті пулу (пунктир), порівняно з API рядка libcudf, що використовує ресурс пам’яті CUDA за замовчуванням
За допомогою ресурсу пам’яті пулу демонструється наскрізна пропускна здатність пам’яті, що наближається до теоретичної межі для двопрохідного алгоритму. «Оптимізоване ядро» досягає пропускної здатності 320-340 ГБ/с, виміряної з використанням розміру вхідних даних плюс розміру вихідних даних і часу обчислення (рис. 4).
Двопрохідний підхід спочатку вимірює розміри вихідних елементів, виділяє пам'ять, а потім встановлює пам'ять з виходами. Враховуючи двопрохідний алгоритм обробки, реалізація в «Оптимізованому ядрі» працює близько до обмеження пропускної здатності пам’яті. «Пропускна здатність наскрізної пам’яті» визначається як вхідний і вихідний розмір у ГБ, поділений на час обчислення. *Пропускна здатність пам'яті RTX A6000 (768 ГБ/с).
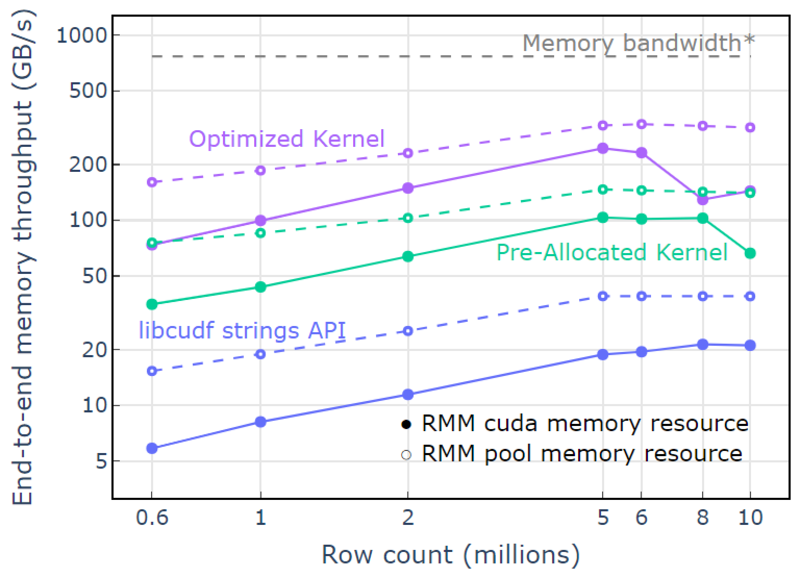 Рисунок 4. Пропускна здатність пам’яті для «оптимізованого ядра», «попередньо виділеного ядра» та «API рядків libcudf» як функція кількості рядків вводу/виводу
Рисунок 4. Пропускна здатність пам’яті для «оптимізованого ядра», «попередньо виділеного ядра» та «API рядків libcudf» як функція кількості рядків вводу/виводу
Ця публікація демонструє два підходи до написання ефективних перетворень рядкових даних у libcudf. API загального призначення libcudf є швидким і простим для розробників і забезпечує хорошу продуктивність. libcudf також надає утиліти на стороні пристрою, призначені для використання з користувальницькими ядрами, у цьому прикладі розблокування >10x більшої продуктивності.
Застосовуйте свої знання
Щоб почати роботу з RAPIDS cuDF, відвідайте rapidsai/cudf Репо GitHub. Якщо ви ще не випробували cuDF і libcudf для своїх робочих навантажень обробки рядків, радимо вам протестувати останню версію. Контейнери Docker надаються як для випусків, так і для нічних збірок. Пакети Conda також доступні для полегшення тестування та розгортання. Якщо ви вже використовуєте cuDF, ми радимо вам запустити новий приклад перетворення рядків, відвідавши rapidsai/cudf/tree/HEAD/cpp/examples/strings на GitHub.
Девід Вендт є старшим інженером системного програмного забезпечення NVIDIA, що розробляє код C++/CUDA для RAPIDS. Девід має ступінь магістра з електротехніки в Університеті Джона Гопкінса.
Грегорі Кімбол є менеджером з розробки програмного забезпечення в NVIDIA, який працює в команді RAPIDS. Грегорі керує розробкою libcudf, бібліотеки CUDA/C++ для обробки даних у стовпцях, яка підтримує RAPIDS cuDF. Грегорі отримав ступінь доктора філософії з прикладної фізики в Каліфорнійському технологічному інституті.
Оригінал. Повідомлено з дозволу.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- МЕНЮ
- вище
- прискорення
- Приймає
- доступ
- доступний
- виконано
- через
- доданий
- Додає
- алгоритм
- ВСІ
- виділяє
- розподіл
- вже
- кількість
- аналіз
- та
- Інший
- Apache
- API
- Інтерфейси
- застосування
- прикладної
- підхід
- підходи
- наближається
- навколо
- масив
- асоційований
- автоматичний
- автоматично
- доступний
- середній
- ширина смуги
- Базова лінія
- оскільки
- перед тим
- буття
- нижче
- корисний
- Переваги
- КРАЩЕ
- між
- синій
- Пробій
- буфера
- будувати
- Створюємо
- Будує
- побудований
- C + +
- Каліфорнія
- call
- званий
- покликання
- Виклики
- не може
- випадок
- випадків
- викликаючи
- Зміни
- характер
- символи
- дитина
- клас
- близько
- код
- Колонка
- Колони
- об'єднувати
- порівняння
- повний
- Зроблено
- Компоненти
- обчислення
- обчислення
- Вважати
- Складається
- будувати
- містить
- конвертувати
- перероблений
- копіювання
- Відповідний
- Коштувати
- створювати
- створений
- створює
- створення
- виготовлений на замовлення
- дані
- обробка даних
- наука про дані
- Девід
- дефолт
- Ступінь
- постачає
- продемонстрований
- розгортання
- призначений
- проектування
- розробників
- розвивається
- розробка
- пристрій
- різний
- безпосередньо
- обговорювалися
- розділений
- Docker
- Падіння
- під час
- динамічний
- кожен
- легше
- ефект
- ефективний
- продуктивно
- електротехніка
- елементи
- усунутий
- включіть
- заохочувати
- кінець в кінець
- інженер
- Машинобудування
- Весь
- запис
- Ефір (ETH)
- Навіть
- все
- приклад
- Приклади
- відмінно
- Крім
- виконання
- очікуваний
- зовнішній
- додатково
- витяг
- завод
- ШВИДКО
- швидше
- особливість
- риси
- Рисунок
- фільтрація
- остаточний
- в кінці кінців
- Перший
- фіксованою
- стежити
- потім
- після
- форма
- формат
- Безкоштовна
- часто
- від
- перед
- повністю
- функція
- Функції
- далі
- Отримувати
- Загальне
- генерує
- отримати
- GitHub
- даний
- Глобальний
- добре
- GPU
- гарантований
- Ручки
- має
- тут
- вище
- найвищий
- тримає
- Як
- How To
- Однак
- HTML
- HTTPS
- ідеальний
- ідентифікує
- непорушний
- здійснювати
- реалізація
- реалізовані
- удосконалювати
- поліпшення
- поліпшується
- in
- включені
- У тому числі
- Augmenter
- зростаючий
- індекс
- індивідуальний
- інформація
- початковий
- вхід
- Інститут
- внутрішній
- IT
- сам
- Джонс Хопкінс
- Університет Джонса Хопкінса
- приєднання
- KDnuggets
- тримати
- ключ
- знання
- етикетка
- великий
- більше
- останній
- Затримка
- останній
- останній випуск
- запущений
- запуски
- запуск
- Веде за собою
- вивчення
- довжина
- бібліотека
- світло
- МЕЖА
- недоліки
- погрузка
- розташування
- машина
- навчання за допомогою машини
- головний
- підтримує
- зробити
- РОБОТИ
- Робить
- управляти
- управління
- менеджер
- управління
- багато
- майстер
- Освоєння
- матч
- засоби
- вимір
- заходи
- пам'ять
- метод
- може бути
- мільйона
- mind
- більше
- більш ефективний
- рухається
- MS
- множинний
- ім'я
- Імена
- Необхідність
- необхідний
- Нові
- номер
- Nvidia
- об'єкти
- зсув
- ONE
- відкриття
- працювати
- працює
- операції
- Можливість
- Інше
- оплачувану
- Паралельні
- параметр
- частина
- Пройшов
- Peak
- продуктивність
- виконанні
- виступає
- періодів
- дозвіл
- перспектива
- Фізика
- місце
- plato
- Інформація про дані Платона
- PlatoData
- плюс
- точка
- басейн
- заселений
- положення
- позиції
- пошта
- потужний
- повноваження
- попередній
- обробка
- виробляти
- профілювання
- пропонувати
- за умови
- забезпечує
- громадськість
- мета
- якість
- діапазон
- Досягає
- Читати
- розумний
- отримує
- запис
- Знижений
- знижує
- Рефактор
- Відображає
- райони
- звільнити
- Релізи
- решті
- представляє
- представляє
- ресурс
- результат
- повертати
- Умови повернення
- ROW
- прогін
- біг
- то ж
- наука
- другий
- старший
- Послідовність
- служить
- набори
- Поділитись
- Повинен
- показаний
- Шоу
- значний
- аналогічний
- просто
- з
- один
- Розмір
- розміри
- менше
- So
- Софтвер
- Інженер-програміст
- розробка програмного забезпечення
- solid
- рішення
- Рішення
- Source
- Простір
- конкретний
- конкретно
- зазначений
- мова
- швидкість
- відпрацьований
- розкол
- старт
- почалася
- Починаючи
- Статус
- заходи
- Як і раніше
- зберігати
- зберігати
- магазинів
- просто
- потік
- структура
- здивований
- Systems
- приймає
- команда
- Технологія
- тимчасовий
- тест
- Тестування
- Команда
- їх
- теоретичний
- отже
- через
- пропускна здатність
- час
- до
- разом
- інструмент
- Інструментарій
- інструменти
- Усього:
- Перетворення
- Перетворення
- перетворень
- перетворений
- перетворення
- tv
- Типи
- типовий
- що лежить в основі
- університет
- відімкнути
- розблокування
- us
- використання
- комунальні послуги
- Цінний
- Цінна інформація
- Проти
- видимість
- видимий
- життєво важливий
- який
- в той час як
- широкий
- Широкий діапазон
- волі
- в
- без
- Work
- робочий
- працює
- б
- запис
- лист
- X
- вашу
- зефірнет










