Цей допис написано спільно з Прамодом Наяком, ЛакшміКантхом Маннемом і Вівеком Аггарвалом із групи низької затримки LSEG.
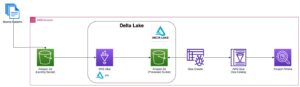
Аналіз транзакційних витрат (TCA) широко використовується трейдерами, портфельними менеджерами та брокерами для попереднього та постторгового аналізу та допомагає їм вимірювати й оптимізувати транзакційні витрати та ефективність їхніх торгових стратегій. У цьому дописі ми проаналізуємо спред опціонів між цінами та цінами Історія тиків LSEG – PCAP використання набору даних Amazon Athena для Apache Spark. Ми покажемо вам, як отримати доступ до даних, визначити спеціальні функції для застосування до даних, запитувати та фільтрувати набір даних, а також візуалізувати результати аналізу, і все це без необхідності турбуватися про налаштування інфраструктури чи налаштування Spark, навіть для великих наборів даних.
фон
Options Price Reporting Authority (OPRA) виконує функції важливого процесора інформації про цінні папери, збираючи, об’єднуючи та розповсюджуючи звіти про останні продажі, котирування та відповідну інформацію для опціонів США. Завдяки 18 активним біржам опціонів США та понад 1.5 мільйонам відповідних контрактів OPRA відіграє ключову роль у наданні вичерпних ринкових даних.
5 лютого 2024 року Securities Industry Automation Corporation (SIAC) збирається оновити канал OPRA з 48 до 96 багатоадресних каналів. Це вдосконалення спрямоване на оптимізацію розподілу символів і використання ємності лінії у відповідь на ескалацію торгової активності та нестабільність на ринку опціонів США. SIAC рекомендував компаніям підготуватися до пікових швидкостей передачі даних до 37.3 ГБіт на секунду.
Незважаючи на те, що оновлення не відразу змінює загальний обсяг опублікованих даних, воно дозволяє OPRA поширювати дані зі значно швидшою швидкістю. Цей перехід має вирішальне значення для задоволення потреб динамічного ринку опціонів.
OPRA виділяється як одна з найоб’ємніших інформаційних версій з піком у 150.4 мільярда повідомлень за один день у 3 кварталі 2023 року та вимогою до 400 мільярдів повідомлень за один день. Отримання кожного окремого повідомлення має вирішальне значення для аналізу транзакційних витрат, моніторингу ліквідності ринку, оцінки торгової стратегії та дослідження ринку.
Про дані
Історія тиків LSEG – PCAP це хмарне сховище, що перевищує 30 ПБ, у якому зберігаються надвисокоякісні глобальні ринкові дані. Ці дані ретельно збираються безпосередньо в центрах обробки даних обміну з використанням резервних процесів збору даних, стратегічно розташованих у основних основних і резервних центрах обробки даних обміну по всьому світу. Технологія захоплення LSEG забезпечує захоплення даних без втрат і використовує джерело часу GPS для наносекундної точності позначки часу. Крім того, використовуються складні методи арбітражу даних, щоб безперешкодно заповнити будь-які прогалини в даних. Після збору дані проходять ретельну обробку та арбітраж, а потім нормалізуються у форматі Parquet за допомогою Ультрапрямий режим реального часу LSEG (RTUD) обробники кормів.
Процес нормалізації, який є невід’ємною частиною підготовки даних для аналізу, генерує до 6 ТБ стиснутих файлів Parquet на день. Величезний обсяг даних пояснюється всеосяжною природою OPRA, яка охоплює кілька бірж і містить численні опціонні контракти, що характеризуються різними атрибутами. Підвищена волатильність ринку та активність створення ринку на опціонних біржах ще більше сприяють об’єму даних, опублікованих на OPRA.
Атрибути Tick History – PCAP дозволяють компаніям проводити різні аналізи, зокрема:
- Передторговий аналіз – Оцініть потенційний вплив на торгівлю та вивчіть різні стратегії виконання на основі історичних даних
- Постторгова оцінка – Вимірюйте фактичні витрати на виконання порівняно з контрольними показниками для оцінки ефективності стратегій виконання
- Оптимізований виконання – Точне налаштування стратегій виконання на основі історичних моделей ринку, щоб мінімізувати вплив на ринок і зменшити загальні витрати на торгівлю
- Управління ризиками – Визначайте моделі прослизання, визначайте викиди та проактивно керуйте ризиками, пов’язаними з торговою діяльністю
- Атрибуція продуктивності – Відокремлюйте вплив торгових рішень від інвестиційних рішень під час аналізу продуктивності портфеля
Набір даних LSEG Tick History – PCAP доступний у Обмін даними AWS і доступний на Торговий майданчик AWS. З Обмін даними AWS для Amazon S3, ви можете отримати доступ до даних PCAP безпосередньо з LSEG Служба простого зберігання Amazon (Amazon S3), що позбавляє фірм від необхідності зберігати власні копії даних. Цей підхід оптимізує керування та зберігання даних, надаючи клієнтам миттєвий доступ до високоякісного PCAP або нормалізованих даних із простотою використання, інтеграції та істотна економія при зберіганні даних.
Афіна для Apache Spark
Для аналітичних зусиль, Афіна для Apache Spark пропонує спрощену роботу ноутбука, доступну через консоль Athena або API Athena, що дозволяє створювати інтерактивні програми Apache Spark. Завдяки оптимізованому часу виконання Spark Athena допомагає аналізувати петабайти даних шляхом динамічного масштабування кількості механізмів Spark менш ніж за секунду. Крім того, загальні бібліотеки Python, такі як pandas і NumPy, легко інтегровані, що дозволяє створювати складну логіку додатків. Гнучкість поширюється на імпорт користувальницьких бібліотек для використання в блокнотах. Athena для Spark підтримує більшість відкритих форматів даних і повністю інтегрована з Клей AWS Каталог даних.
Набір даних
Для цього аналізу ми використали набір даних LSEG Tick History – PCAP OPRA від 17 травня 2023 року. Цей набір даних містить такі компоненти:
- Найкраща ставка та пропозиція (BBO) – Повідомляє про найвищу ставку та найнижчий запит на цінний папір на певній біржі
- Національна найкраща ставка та пропозиція (NBBO) – Повідомляє про найвищу ставку та найнижчий запит на цінний папір на всіх біржах
- Торги – Записує завершені операції на всіх біржах
Набір даних містить такі обсяги даних:
- Торги – 160 МБ, розподілених між приблизно 60 стисненими файлами Parquet
- ВВО – 2.4 ТБ, розподілених між приблизно 300 стисненими файлами Parquet
- НББО – 2.8 ТБ, розподілених між приблизно 200 стисненими файлами Parquet
Огляд аналізу
Аналіз даних OPRA Tick History для Transaction Cost Analysis (TCA) передбачає ретельний аналіз ринкових котирувань і торгів навколо конкретної торгової події. У рамках цього дослідження ми використовуємо такі показники:
- Котирований спред (QS) – Розраховується як різниця між запитом BBO та пропозицією BBO
- Ефективний спред (ES) – Розраховується як різниця між торговою ціною та серединою BBO (BBO bid + (BBO ask – BBO bid)/2)
- Ефективний/котирований спред (EQF) – Розраховується як (ES / QS) * 100
Ми обчислюємо ці спреди до угоди та додатково через чотири інтервали після угоди (відразу після, 1 секунду, 10 секунд і 60 секунд після угоди).
Налаштуйте Athena для Apache Spark
Щоб налаштувати Athena для Apache Spark, виконайте такі дії:
- На консолі Athena, під ПОЧАТИвиберіть Аналізуйте свої дані за допомогою PySpark і Spark SQL.
- Якщо ви вперше використовуєте Athena Spark, виберіть Створити робочу групу.

- для Назва робочої групи¸ введіть назву для робочої групи, наприклад
tca-analysis. - У Двигун аналітики розділ, виберіть Apache Spark.
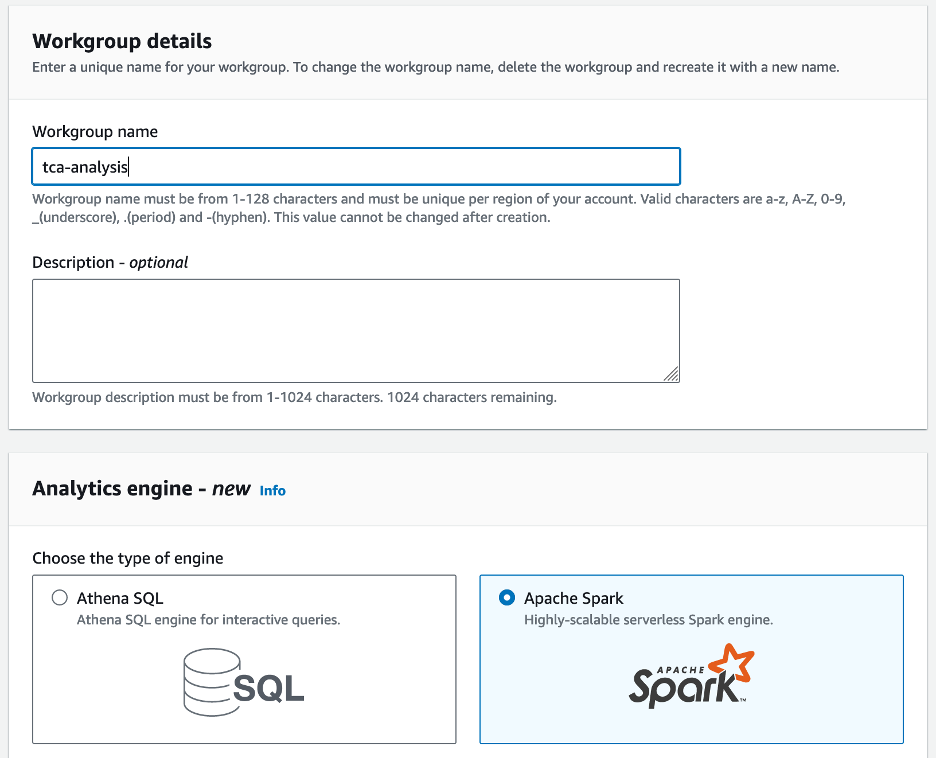
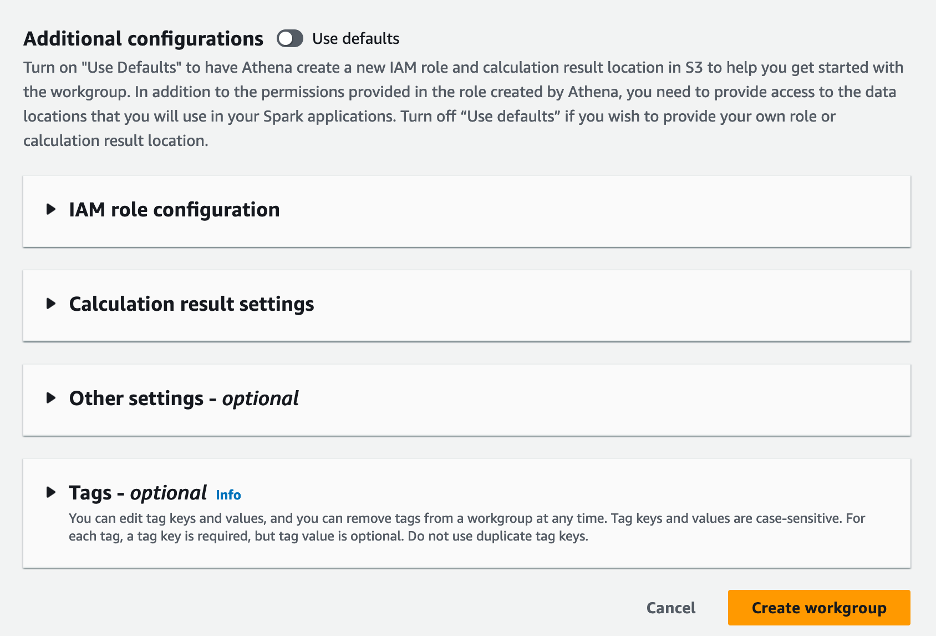
- У Додаткові конфігурації розділ, ви можете вибрати Використовуйте параметри за замовчуванням або надати звичай Управління ідентифікацією та доступом AWS (IAM) і розташування Amazon S3 для результатів обчислень.
- Вибирати Створити робочу групу.
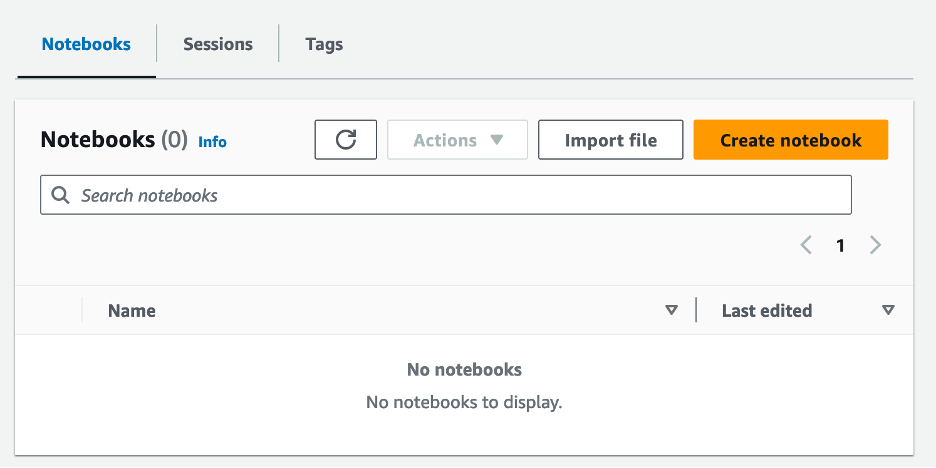
- Після створення робочої групи перейдіть до Ноутбуки та виберіть Створити блокнот.
- Введіть назву свого блокнота, наприклад
tca-analysis-with-tick-history. - Вибирати Створювати щоб створити свій блокнот.
Запустіть блокнот
Виберіть, якщо ви вже створили робочу групу Spark Запустіть редактор блокнота при ПОЧАТИ.
![]()
Після створення блокнота ви будете перенаправлені до інтерактивного редактора блокнотів.
![]()
Тепер ми можемо додати та запустити наступний код до нашого блокнота.
Створіть аналіз
Щоб створити аналіз, виконайте такі кроки:
- Імпорт загальних бібліотек:
- Створіть наші кадри даних для BBO, NBBO та угод:
- Тепер ми можемо визначити угоду для аналізу транзакційних витрат:
Ми отримуємо наступний результат:
Ми використовуємо виділену торгову інформацію надалі для торгового продукту (tp), торгової ціни (tpr) і часу торгівлі (tt).
- Тут ми створюємо ряд допоміжних функцій для нашого аналізу
- У наступній функції ми створюємо набір даних, який містить усі котирування до та після угоди. Athena Spark автоматично визначає, скільки DPU запускати для обробки нашого набору даних.
- Тепер давайте викличемо функцію аналізу TCA з інформацією з вибраної нами торгівлі:
Візуалізуйте результати аналізу
Тепер давайте створимо кадри даних, які ми використовуємо для візуалізації. Кожен кадр даних містить котирування для одного з п’яти часових інтервалів для кожного каналу даних (BBO, NBBO):
У наступних розділах ми надаємо приклад коду для створення різних візуалізацій.
Побудуйте QS і NBBO перед угодою
Використовуйте наступний код, щоб побудувати котирування спреду та NBBO перед угодою:
![]()
Побудуйте графік QS для кожного ринку та NBBO після угоди
Використовуйте наведений нижче код, щоб побудувати котирувальний спред для кожного ринку та NBBO одразу після угоди:
![]()
Побудуйте графік QS для кожного інтервалу часу та кожного ринку для BBO
Використовуйте наведений нижче код, щоб побудувати спред котирувань для кожного інтервалу часу та кожного ринку для BBO:
![]()
Побудуйте ES для кожного інтервалу часу та ринку для BBO
Використовуйте наступний код, щоб побудувати ефективний спред для кожного інтервалу часу та ринку для BBO:
Побудуйте EQF для кожного інтервалу часу та ринку для BBO
Використовуйте наведений нижче код, щоб побудувати ефективний/котирований спред для кожного інтервалу часу та ринку для BBO:
Продуктивність розрахунку Athena Spark
Коли ви запускаєте блок коду, Athena Spark автоматично визначає, скільки DPU потрібно для завершення обчислення. В останньому блоці коду, де ми викликаємо tca_analysis ми фактично наказуємо Spark обробити дані, а потім перетворюємо отримані кадри даних Spark у кадри даних Pandas. Це частина аналізу, пов’язана з найінтенсивнішою обробкою, і коли Athena Spark запускає цей блок, він показує індикатор виконання, час, що минув, і кількість DPU, які зараз обробляють дані. Наприклад, у наступному розрахунку Athena Spark використовує 18 DPU.
![]()
Під час налаштування ноутбука Athena Spark у вас є можливість установити максимальну кількість DPU, які він може використовувати. За замовчуванням 20 DPU, але ми протестували цей розрахунок із 10, 20 і 40 DPU, щоб продемонструвати, як Athena Spark автоматично масштабується для виконання нашого аналізу. Ми спостерігали, що Athena Spark лінійно масштабується, займаючи 15 хвилин і 21 секунду, коли ноутбук було налаштовано з максимум 10 DPU, 8 хвилин і 23 секунди, коли ноутбук було налаштовано з 20 DPU, і 4 хвилини і 44 секунди, коли ноутбук був налаштований. налаштований з 40 DPU. Оскільки Athena Spark стягує плату на основі використання DPU з деталізацією за секунду, вартість цих обчислень подібна, але якщо ви встановите більше максимальне значення DPU, Athena Spark може повернути результат аналізу набагато швидше. Щоб дізнатися більше про ціни на Athena Spark, натисніть тут.
Висновок
У цій публікації ми продемонстрували, як можна використовувати високоточні дані OPRA з Tick History-PCAP LSEG для проведення аналізу транзакційних витрат за допомогою Athena Spark. Своєчасна доступність даних OPRA, доповнена інноваціями доступності AWS Data Exchange для Amazon S3, стратегічно скорочує час на аналітику для компаній, які прагнуть створити практичну інформацію для критичних торгових рішень. OPRA щодня генерує близько 7 ТБ нормалізованих даних Parquet, і керування інфраструктурою для надання аналітики на основі даних OPRA є складним завданням.
Масштабованість Athena в обробці великомасштабних даних для Tick History – PCAP для даних OPRA робить її переконливим вибором для організацій, яким потрібні швидкі та масштабовані аналітичні рішення в AWS. У цьому дописі показано безперебійну взаємодію між екосистемою AWS і даними Tick History-PCAP, а також те, як фінансові установи можуть скористатися цією синергією для прийняття рішень на основі даних для критично важливих торгових та інвестиційних стратегій.
Про авторів
![]() Прамод Наяк є директором з управління продуктами групи низьких затримок у LSEG. Прамод має понад 10 років досвіду роботи в галузі фінансових технологій, зосереджуючись на розробці програмного забезпечення, аналітиці та управлінні даними. Прамод — колишній інженер програмного забезпечення, який захоплюється ринковими даними та кількісною торгівлею.
Прамод Наяк є директором з управління продуктами групи низьких затримок у LSEG. Прамод має понад 10 років досвіду роботи в галузі фінансових технологій, зосереджуючись на розробці програмного забезпечення, аналітиці та управлінні даними. Прамод — колишній інженер програмного забезпечення, який захоплюється ринковими даними та кількісною торгівлею.
![]() Лакшмі Кант Маннем є менеджером із продуктів у групі низьких затримок LSEG. Він зосереджується на даних і продуктах платформи для галузі ринкових даних з низькою затримкою. LakshmiKanth допомагає клієнтам створювати найбільш оптимальні рішення для їхніх потреб у ринкових даних.
Лакшмі Кант Маннем є менеджером із продуктів у групі низьких затримок LSEG. Він зосереджується на даних і продуктах платформи для галузі ринкових даних з низькою затримкою. LakshmiKanth допомагає клієнтам створювати найбільш оптимальні рішення для їхніх потреб у ринкових даних.
![]() Вівек Аггарвал є старшим інженером з обробки даних у групі низької затримки LSEG. Вівек працює над розробкою та підтримкою каналів даних для обробки та доставки отриманих каналів ринкових даних і каналів довідкових даних.
Вівек Аггарвал є старшим інженером з обробки даних у групі низької затримки LSEG. Вівек працює над розробкою та підтримкою каналів даних для обробки та доставки отриманих каналів ринкових даних і каналів довідкових даних.
![]() Алкет Мемушай є головним архітектором у групі розвитку ринку фінансових послуг AWS. Alket відповідає за технічну стратегію, співпрацюючи з партнерами та клієнтами, щоб розгорнути навіть найвибагливіші робочі навантаження ринків капіталу в AWS Cloud.
Алкет Мемушай є головним архітектором у групі розвитку ринку фінансових послуг AWS. Alket відповідає за технічну стратегію, співпрацюючи з партнерами та клієнтами, щоб розгорнути навіть найвибагливіші робочі навантаження ринків капіталу в AWS Cloud.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- : має
- :є
- : ні
- :де
- $UP
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- МЕНЮ
- доступ
- доступний
- доступність
- доступною
- через
- активний
- діяльність
- фактичний
- насправді
- додавати
- Додатково
- адресація
- Перевага
- після
- проти
- Аґгарвал
- Цілі
- ВСІ
- Дозволити
- вже
- Amazon
- Амазонка Афіна
- Amazon Web Services
- an
- аналізи
- аналіз
- Аналітичний
- аналітика
- аналізувати
- Аналізуючи
- та
- будь-який
- Apache
- Apache Spark
- Інтерфейси
- додаток
- застосування
- Застосовувати
- підхід
- приблизно
- арбітраж
- арбітраж
- ЕСТЬ
- навколо
- AS
- запитати
- оцінити
- асоційований
- At
- Атрибути
- влада
- автоматично
- Автоматизація
- наявність
- доступний
- AWS
- резервна копія
- бар
- заснований
- BE
- оскільки
- перед тим
- тести
- КРАЩЕ
- між
- пропозиція
- Мільярд
- Блокувати
- брокери
- будувати
- але
- by
- обчислювати
- розрахований
- розрахунок
- call
- CAN
- потужність
- капітал
- Ринки капіталу
- захоплення
- захоплений
- захопивши
- каталог
- Центри
- складні
- канали
- характеризується
- вантажі
- вибір
- Вибирати
- клієнтів
- хмара
- код
- Збір
- загальний
- переконливий
- повний
- Зроблено
- Компоненти
- всеосяжний
- включає
- Проводити
- налаштувати
- конфігурування
- Консоль
- консолідація
- містить
- контрактів
- сприяти
- конвертувати
- КОРПОРАЦІЯ
- Коштувати
- витрати
- написано співавтором
- створювати
- створений
- створення
- критичний
- вирішальне значення
- В даний час
- виготовлений на замовлення
- Клієнти
- Тире
- дані
- центрів обробки даних
- інженер даних
- Обмін даними
- управління даними
- обробка даних
- зберігання даних
- керовані даними
- набори даних
- день
- Прийняття рішень
- рішення
- дефолт
- визначати
- доставка
- вимогливий
- запити
- демонструвати
- продемонстрований
- розгортання
- деталі
- визначає
- розвивається
- розробка
- команда розвитку
- різниця
- різний
- безпосередньо
- Директор
- розподілений
- розподіл
- Різне
- подвійний
- управляти
- динамічний
- динамічно
- динаміка
- кожен
- простота
- простота використання
- екосистема
- редактор
- Ефективний
- ефективність
- має право
- усуваючи
- працевлаштований
- наймаючи
- включіть
- дозволяє
- охоплюючий
- зусиль
- двигун
- інженер
- Двигуни
- Посилення
- гарантує
- Що натомість? Створіть віртуальну версію себе у
- зростаючий
- Ефір (ETH)
- оцінювати
- оцінка
- Навіть
- Event
- Кожен
- приклад
- обмін
- Біржі
- виконання
- досвід
- дослідити
- експрес
- продовжується
- швидше
- Показуючи
- лютого
- Фіга
- Файли
- заповнювати
- фільтрувати
- фінансовий
- Фінансові установи
- фінансові послуги
- фінансові технології
- фірми
- Перший
- перший раз
- п'ять
- Гнучкість
- фокусується
- фокусування
- після
- для
- формат
- Колишній
- Вперед
- чотири
- FRAME
- від
- функція
- Функції
- далі
- прогалини
- генерує
- отримати
- даний
- Глобальний
- глобальний ринок
- Go
- буде
- GPS
- Group
- Обробка
- Мати
- має
- he
- гармонія
- допомагає
- високоякісний
- вище
- найвищий
- Виділено
- історичний
- історія
- житло
- Як
- How To
- HTTP
- HTTPS
- IAM
- ідентифікувати
- Особистість
- if
- Негайний
- негайно
- Impact
- імпорт
- in
- У тому числі
- збільшений
- промисловість
- інформація
- Інфраструктура
- інновації
- розуміння
- установи
- інтегральний
- інтегрований
- інтеграція
- взаємодія
- інтерактивний
- в
- складний
- інвестиції
- включає в себе
- IT
- JPG
- просто
- великий
- масштабний
- останній
- Затримка
- запуск
- менше
- libraries
- Лінія
- ліквідності
- розташування
- логіка
- шукати
- низький
- найнижчий
- збереження
- основний
- РОБОТИ
- Робить
- управляти
- управління
- менеджер
- Менеджери
- управління
- манера
- багато
- ринок
- дані ринку
- вплив на ринок
- дослідження ринку
- волатильності ринку
- маркетмейкерство
- ринки
- масивний
- Освоєння
- максимальний
- Може..
- вимір
- повідомлення
- повідомлення
- педантичний
- прискіпливо
- Метрика
- мільйона
- мінімізувати
- протокол
- моніторинг
- більше
- Більше того
- найбільш
- багато
- множинний
- ім'я
- природа
- Переміщення
- Необхідність
- потреби
- ніхто
- ноутбук
- ноутбуки
- номер
- численний
- нумпі
- спостерігається
- of
- пропонувати
- Пропозиції
- on
- ONE
- оптимальний
- Оптимізувати
- оптимізований
- варіант
- Опції
- or
- організації
- наші
- з
- вихід
- над
- загальний
- власний
- панди
- частина
- партнери
- пристрасний
- моделі
- Peak
- для
- виконувати
- продуктивність
- основний
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- відіграє
- будь ласка
- ділянку
- портфель
- портфельні менеджери
- розташовані
- пошта
- після торгівлі
- потенціал
- Точність
- Готувати
- підготовка
- price
- ціни без прихованих комісій
- первинний
- Головний
- процес
- процеси
- обробка
- процесор
- Product
- Управління продуктом
- менеджер по продукції
- Продукти
- прогрес
- забезпечувати
- забезпечення
- опублікований
- Python
- Q3
- кількісний
- кількість
- запит
- лапки
- ставка
- ставки
- Читати
- реальний
- реального часу
- рекомендований
- облік
- червоний
- зменшити
- знижує
- посилання
- рефінітив
- Звітність
- Звіти
- Сховище
- вимога
- Вимагається
- дослідження
- відповідь
- відповідальний
- результат
- в результаті
- результати
- повертати
- ризики
- Роль
- прогін
- пробіжки
- sale
- масштабованість
- масштабовані
- ваги
- Масштабування
- безшовні
- плавно
- другий
- seconds
- розділ
- розділам
- Securities
- безпеку
- пошук
- вибрати
- обраний
- старший
- окремий
- служить
- Послуги
- комплект
- установка
- Показувати
- Шоу
- істотно
- аналогічний
- простий
- спрощений
- один
- прослизання
- Софтвер
- розробка програмного забезпечення
- Інженер-програміст
- Рішення
- складний
- напруга
- Іскритися
- конкретний
- поширення
- Спреди
- стенди
- заходи
- зберігання
- зберігати
- Стратегічно
- стратегії
- Стратегія
- Спрощує
- Вивчення
- наступні
- такі
- SWIFT
- символ
- взаємодія
- Приймати
- взяття
- команда
- технічний
- методи
- Технологія
- перевірений
- ніж
- Що
- Команда
- інформація
- їх
- Їх
- потім
- Ці
- це
- через
- тик
- час
- своєчасно
- відмітка часу
- назва
- до
- Усього:
- tp
- TPR
- торгувати
- Traders
- торги
- торгові площі
- торгові стратегії
- Торгова стратегія
- угода
- трансакційні витрати
- перетворення
- перехід
- Ультра
- при
- зазнає
- модернізація
- us
- Використання
- використання
- використовуваний
- використовує
- використання
- використовує
- значення
- різний
- візуалізації
- візуалізувати
- Volatility
- обсяг
- Обсяги
- було
- we
- Web
- веб-сервіси
- коли
- який
- широко
- волі
- з
- в
- без
- Робоча група
- робочий
- працює
- світовий
- турбуватися
- X
- років
- ви
- вашу
- зефірнет