Апач Худі це формат відкритої таблиці, який надає можливості баз даних і сховищ даних до озер даних. Apache Hudi допомагає інженерам обробки даних керувати складними завданнями, наприклад, керувати наборами даних, що постійно розвиваються, за допомогою транзакцій, зберігаючи продуктивність запитів. Інженери обробки даних використовують Apache Hudi для потокової передачі робочих навантажень, а також для створення ефективних конвеєрів додаткових даних. Hudi забезпечує Таблиці, угод, ефективні вставки та видалення, розширені індекси, послуги потокового прийому, дані Кластеризація та ущільнення оптимізації та контроль одночасності, зберігаючи ваші дані у форматах файлів із відкритим кодом. Розширена оптимізація продуктивності Hudi робить аналітичні робочі навантаження швидшими за допомогою будь-якого з популярних механізмів запитів, включаючи Apache Spark, Presto, Trino, Hive тощо.
Багато клієнтів AWS застосували Apache Hudi на своїх озерах даних, створених на основі Amazon S3 Клей AWS, безсерверна служба інтеграції даних, яка полегшує пошук, підготовку, переміщення та інтеграцію даних із багатьох джерел для аналітики, машинного навчання (ML) і розробки додатків. AWS Glue Crawler є компонентом AWS Glue, який дозволяє автоматично створювати метадані таблиці з вмісту даних, не вимагаючи ручного визначення метаданих.
Роботи AWS Glue тепер підтримують таблиці Apache Hudi, що спрощує прийняття Каталог даних AWS Glue як каталог столів Hudi. Типовим випадком використання є реєстрація таблиць Hudi, які не мають визначення таблиці каталогу. Іншим типовим випадком використання є міграція з інших каталогів Hudi, таких як метасховище Hive. Під час міграції з інших каталогів Hudi ви можете створити та запланувати сканер AWS Glue і надати один або кілька шляхів Amazon S3, де розташовані файли таблиці Hudi. У вас є можливість надати максимальну глибину шляхів Amazon S3, які може пройти сканер AWS Glue. З кожним запуском сканери AWS Glue витягуватимуть інформацію про схему та розділи та оновлюватимуть каталог даних AWS Glue зі змінами схеми та розділів. Роботи AWS Glue оновлюють найновіше місце розташування файлу метаданих у каталозі даних AWS Glue, який можуть безпосередньо використовувати аналітичні механізми AWS.
Завдяки цьому запуску ви можете створити та запланувати сканер AWS Glue для реєстрації таблиць Hudi в каталозі даних AWS Glue. Потім ви можете надати один або кілька шляхів Amazon S3, де розташовані таблиці Hudi. У вас є можливість надати максимальну глибину шляхів Amazon S3, які можуть пройти сканери. Під час кожного запуску веб-сканера сканер перевіряє кожен із шляхів S3 і каталогізує інформацію про схему, таку як нові таблиці, видалення й оновлення схем у каталозі даних AWS Glue. Сканери перевіряють інформацію про розділи та додають нові додані розділи до каталогу даних AWS Glue. Роботи-сканери також оновлюють найновіше розташування файлу метаданих у каталозі даних AWS Glue, який можуть безпосередньо використовувати аналітичні механізми AWS.
Ця публікація демонструє, як працює нова можливість сканування таблиць Hudi.
Як сканер AWS Glue працює з таблицями Hudi
Таблиці Hudi мають дві категорії з певними наслідками для кожної:
- Копіювати під час запису (CoW) – Дані зберігаються в колонковому форматі (Parquet), і кожне оновлення створює нову версію файлів під час запису.
- Об’єднати під час читання (MoR) – Дані зберігаються за допомогою комбінації стовпчикового (Parquet) і рядкового (Avro) форматів. Оновлення реєструються на основі рядків
deltaфайли та стискаються за потреби для створення нових версій файлів у стовпцях.
У наборах даних CoW кожного разу, коли відбувається оновлення запису, файл, який містить запис, переписується з оновленими значеннями. У наборі даних MoR щоразу, коли відбувається оновлення, Hudi записує лише рядок для зміненого запису. MoR краще підходить для великих робочих навантажень запису або зміни з меншою кількістю читань. CoW краще підходить для інтенсивного читання даних, які змінюються рідше.
Hudi надає три типи запитів для доступу до даних:
- Запити на знімки – Запити, які бачать останній знімок таблиці за даним фіксуванням або стисненням. Для таблиць MoR запити на знімки відкривають останній стан таблиці шляхом об’єднання базового та дельта-файлів останнього фрагмента файлу на момент запиту.
- Інкрементні запити – Запити бачать лише нові дані, записані в таблицю, починаючи з певної фіксації або стиснення. Це фактично забезпечує потоки змін, щоб увімкнути конвеєри додаткових даних.
- Читайте оптимізовані запити – Для таблиць MoR у запитах відображаються стислі останні дані. Для таблиць CoW запити бачать останні передані дані.
Для таблиць копіювання під час запису сканери створюють одну таблицю в каталозі даних AWS Glue за допомогою ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
Для таблиць з об’єднанням під час читання сканери створюють дві таблиці в каталозі даних AWS Glue для одного розташування таблиці:
- Таблиця з суфіксом
_ro, який використовує ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - Таблиця з суфіксом
_rt, який використовує RealTime Serde, що дозволяє виконувати запити Snapshot:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Під час кожного сканування для кожного наданого шляху Hudi сканери здійснюють виклик API списку Amazon S3, фільтрують на основі .hoodie папки та знайдіть останній файл метаданих у цій папці метаданих таблиці Hudi.
Скануйте таблицю Hudi CoW за допомогою сканера AWS Glue
У цьому розділі розглянемо, як сканувати Hudi CoW за допомогою сканерів AWS Glue.
Передумови
Ось передумови для цього підручника:
- Встановити та настроїти Інтерфейс командного рядка AWS (AWS CLI).
- Створіть своє відро S3, якщо у вас його немає.
- Створіть свою роль IAM для AWS Glue якщо у вас його немає. Тобі потрібно
s3:GetObjectта цінностіs3://your_s3_bucket/data/sample_hudi_cow_table/. - Виконайте таку команду, щоб скопіювати зразок таблиці Hudi у сегмент S3. (Замінити
your_s3_bucketз назвою вашого відра S3.)
Ця інструкція допоможе вам скопіювати зразки даних, але ви можете легко створити будь-які таблиці Hudi за допомогою AWS Glue. Дізнайтеся більше в Представляємо власну підтримку Apache Hudi, Delta Lake та Apache Iceberg на AWS Glue для Apache Spark, частина 2: Візуальний редактор AWS Glue Studio.
Створіть сканер Hudi
У цій інструкції створіть сканер через консоль. Щоб створити сканер Hudi, виконайте такі кроки:
- На консолі AWS Glue виберіть Гусениці.
- Вибирати Створити сканер.
- для ІМ'Я, введіть
hudi_cow_crawler, Вибирати МАЙБУТНІ. - під Конфігурація джерела даних, вибрати Додати джерело даних.
- для Джерело данихвиберіть Худі.
- для Додайте шляхи до таблиці hudi, введіть
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Замінитиyour_s3_bucketз назвою вашого відра S3.) - Вибирати Додайте джерело даних Hudi.
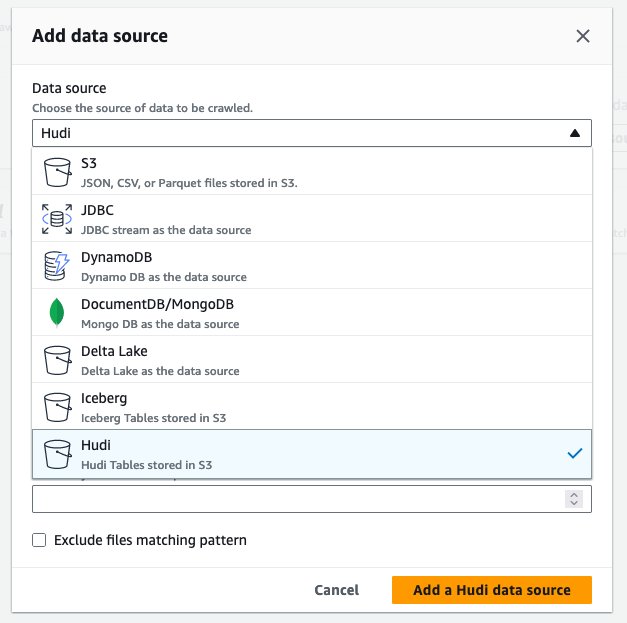
- Вибирати МАЙБУТНІ.
- для Існуюча роль IAM, виберіть свою роль IAM, а потім виберіть МАЙБУТНІ.
- для Цільова база данихвиберіть Додати базу даних, А потім Додати базу даних з'явиться діалогове вікно. для Назва бази даних, введіть
hudi_crawler_blog, Потім виберіть Створювати, Вибирати МАЙБУТНІ. - Вибирати Створити сканер.
Тепер новий сканер Hudi успішно створено. Роботу сканера можна запустити через консоль або через SDK або AWS CLI за допомогою StartCrawl API. Це також можна запланувати через консоль для запуску сканерів у певний час. У цій інструкції запустіть сканер через консоль.
- Вибирати Запустити сканер.
- Зачекайте, поки сканер завершить роботу.
Після запуску сканера ви можете побачити визначення таблиці Hudi на консолі AWS Glue:
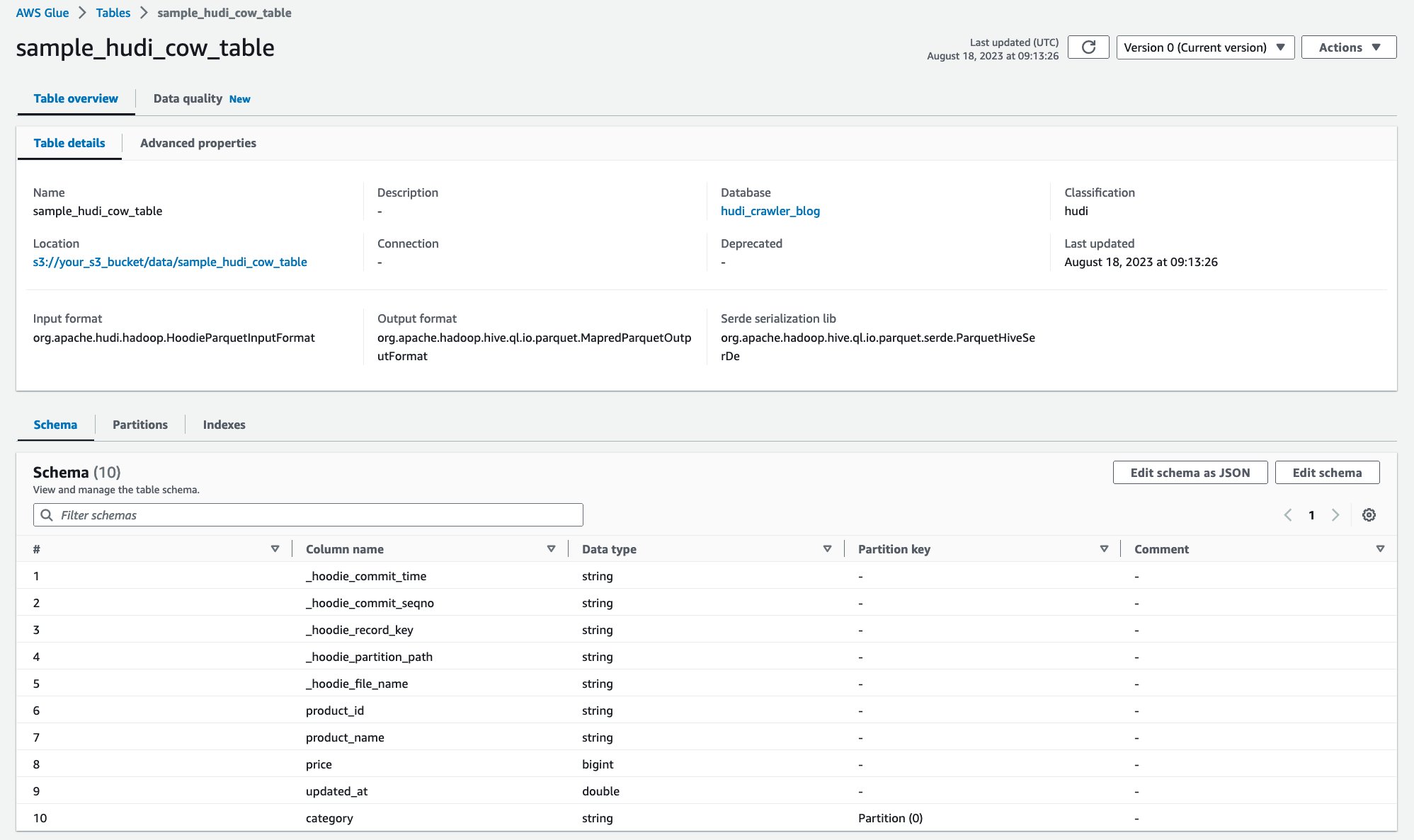
Ви успішно просканували таблицю Hudi CoR із даними на Amazon S3 і створили таблицю AWS Glue Data Catalog із заповненою схемою. Після створення визначення таблиці в AWS Glue Data Catalog аналітичні служби AWS, такі як Amazon Athena, можуть запитувати таблицю Hudi.
Виконайте наступні кроки, щоб почати запити на Athena:
- Відкрийте консоль Amazon Athena.
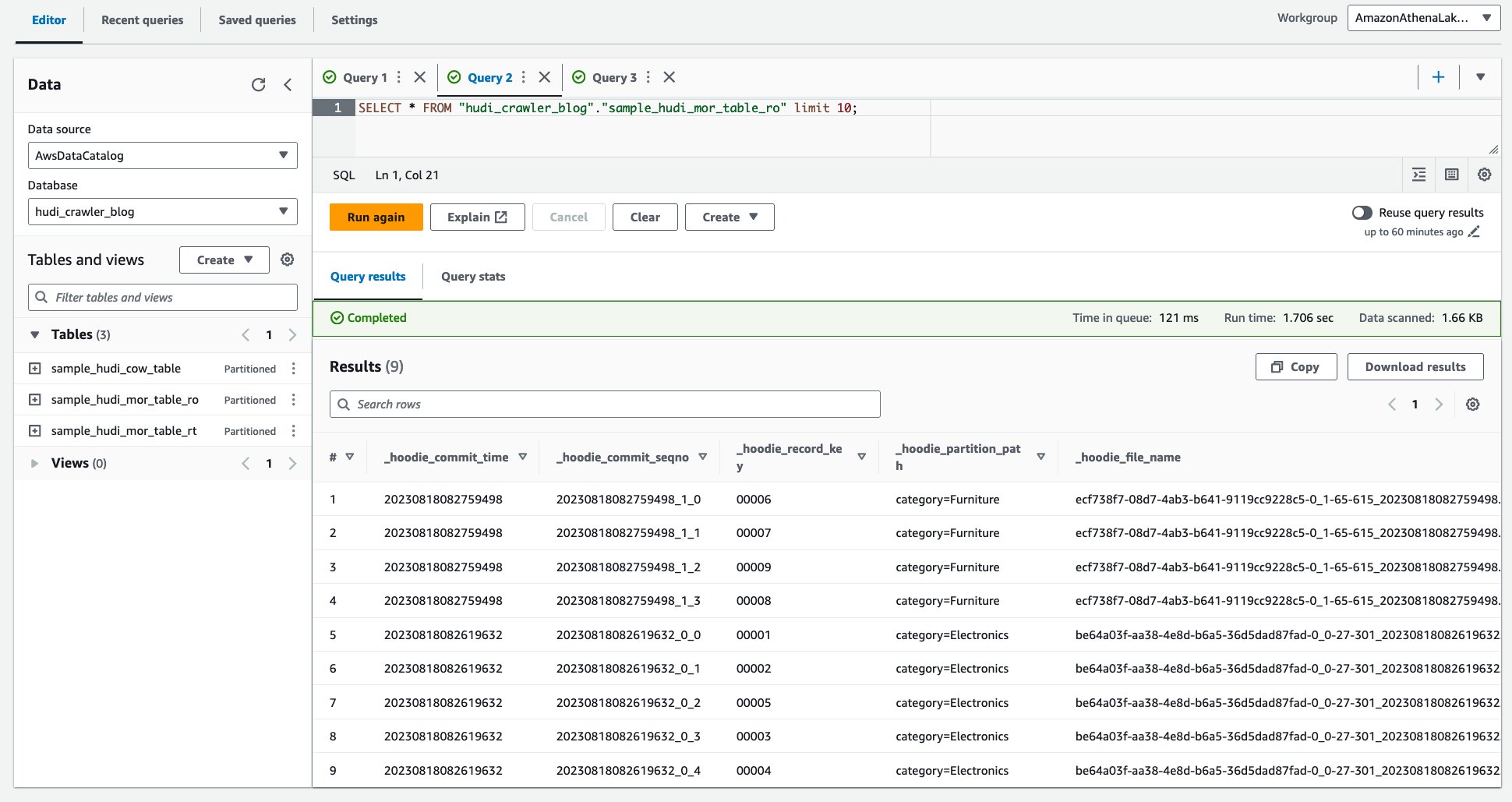
- Виконайте наступний запит.
Наступний знімок екрана показує наш результат:
Сканування таблиці Hudi MoR за допомогою сканера AWS Glue із дозволами на дані AWS Lake Formation
У цьому розділі розглянемо, як сканувати таблицю Hudi MoR за допомогою AWS Glue. Цього разу ви використовуєте дозвіл даних AWS Lake Formation для сканування джерел даних Amazon S3 замість дозволу IAM і Amazon S3. Це необов’язково, але це спрощує налаштування дозволів, коли вашим озером даних керують дозволи AWS Lake Formation.
Передумови
Ось передумови для цього підручника:
- Встановити та настроїти Інтерфейс командного рядка AWS (AWS CLI).
- Створіть своє відро S3, якщо у вас його немає.
- Створіть свою роль IAM для AWS Glue якщо у вас його немає. Тобі потрібно
lakeformation:GetDataAccess. Але вам не потрібноs3:GetObjectта цінностіs3://your_s3_bucket/data/sample_hudi_mor_table/тому що ми використовуємо дозвіл даних Lake Formation для доступу до файлів. - Виконайте таку команду, щоб скопіювати зразок таблиці Hudi у сегмент S3. (Замінити
your_s3_bucketз назвою вашого відра S3.)
Окрім етапів обробки, виконайте наступні кроки, щоб оновити налаштування каталогу даних AWS Glue, щоб використовувати дозволи Lake Formation для керування ресурсами каталогу замість контролю доступу на основі IAM:
- Увійдіть у консоль Lake Formation як адміністратор озера даних.
- Якщо ви вперше отримуєте доступ до консолі Lake Formation, додати себе як адміністратора озера даних.
- під адміністраціявиберіть Параметри каталогу даних.
- для Дозволи за замовчуванням для новостворених баз даних і таблиць, зніміть вибір Використовуйте лише контроль доступу IAM для нових баз даних та Використовуйте лише контроль доступу IAM для нових таблиць у нових базах даних.
- для Налаштування версії між обліковими записамивиберіть версія 3.
- Вибирати зберегти.
Наступним кроком є реєстрація вашого відра S3 у розташуваннях озер даних Lake Formation:
- На консолі Lake Formation виберіть Розташування озера даних, і вибрати Зареєструвати місцезнаходження.
- для Шлях Amazon S3, введіть
s3://your_s3_bucket/. (Замінитиyour_s3_bucketз назвою вашого відра S3.) - Вибирати Зареєструвати місцезнаходження.
Потім надайте роль сканеру Glue доступ до розташування даних, щоб сканер міг використовувати дозвіл Lake Formation для доступу до даних і створення таблиць у цьому місці:
- На консолі Lake Formation виберіть Розташування даних І вибирай Грант.
- для Користувачі та ролі IAMвиберіть роль IAM, яку ви використовували для сканера.
- для Місце зберігання, введіть
s3://your_s3_bucket/data/. (Замінитиyour_s3_bucketз назвою вашого відра S3.) - Вибирати Грант.
Потім надайте роль сканеру для створення таблиць у базі даних hudi_crawler_blog:
- На консолі Lake Formation виберіть Дозволи озера даних.
- Вибирати Грант.
- для Директоривиберіть Користувачі та ролі IAMі виберіть роль сканера.
- для Теги LF або ресурси каталогувиберіть Іменовані ресурси каталогу даних.
- для Database, виберіть базу даних
hudi_crawler_blog. - під Дозволи до бази данихвиберіть Створити таблицю.
- Вибирати Грант.
Створіть сканер Hudi з дозволами на дані Lake Formation
Щоб створити сканер Hudi, виконайте такі кроки:
- На консолі AWS Glue виберіть Гусениці.
- Вибирати Створити сканер.
- для ІМ'Я, введіть
hudi_mor_crawler, Вибирати МАЙБУТНІ. - під Конфігурація джерела даних, вибрати Додати джерело даних.
- для Джерело данихвиберіть Худі.
- для Додайте шляхи до таблиці hudi, введіть
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Замінитиyour_s3_bucketз назвою вашого відра S3.) - Вибирати Додайте джерело даних Hudi.
- Вибирати МАЙБУТНІ.
- для Існуюча роль IAM, виберіть свою роль IAM.
- під Конфігурація Lake Formation – необов’язковавиберіть Використовуйте облікові дані Lake Formation для сканування джерела даних S3.
- Вибирати МАЙБУТНІ.
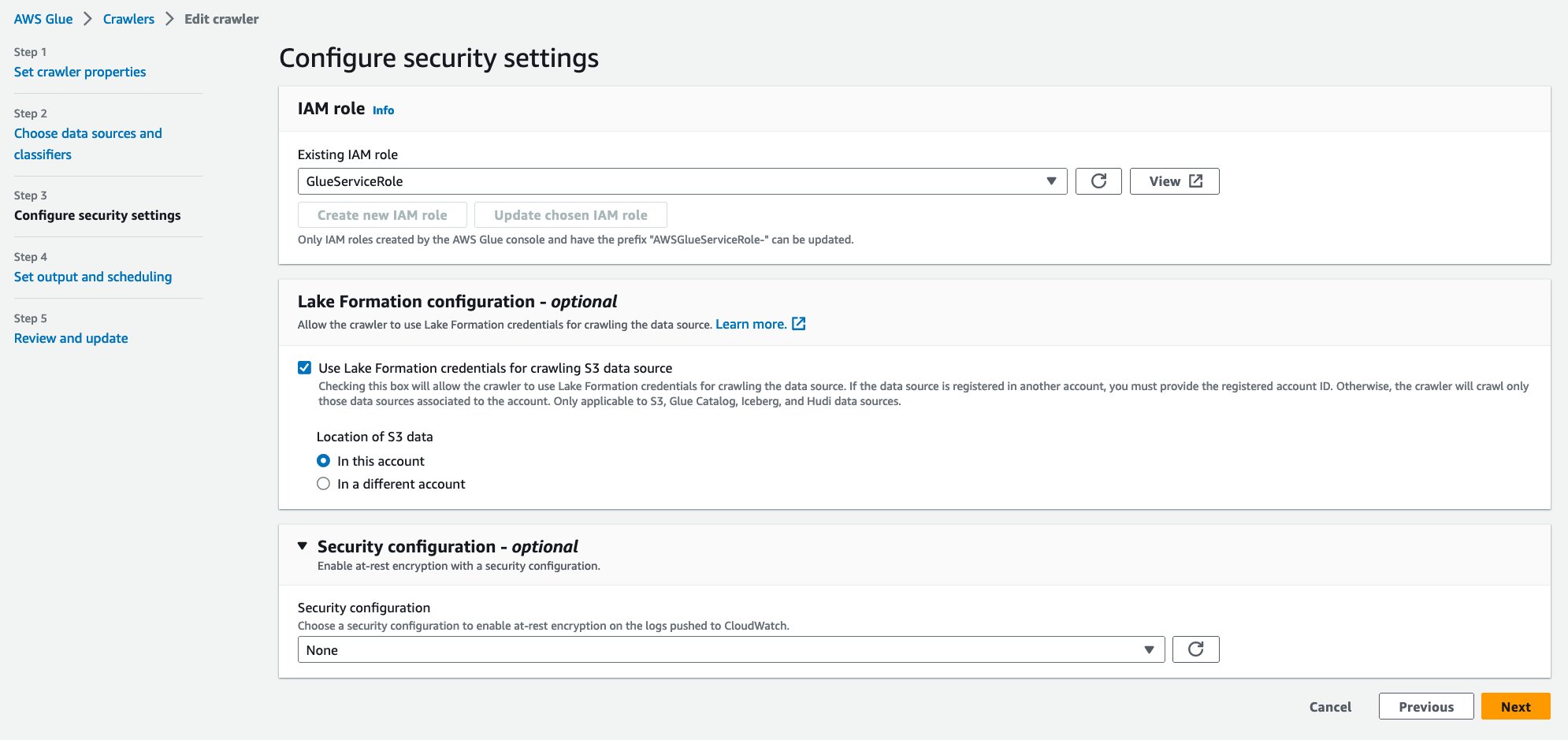
- для Цільова база данихвиберіть
hudi_crawler_blog, Вибирати МАЙБУТНІ. - Вибирати Створити сканер.
Тепер новий сканер Hudi успішно створено. Робот-сканер використовує облікові дані Lake Formation для сканування файлів Amazon S3. Давайте запустимо новий сканер:
- Вибирати Запустити сканер.
- Зачекайте, поки сканер завершить роботу.
Після запуску сканера ви можете побачити дві таблиці визначення таблиці Hudi на консолі AWS Glue:
sample_hudi_mor_table_ro(читати оптимізовану таблицю)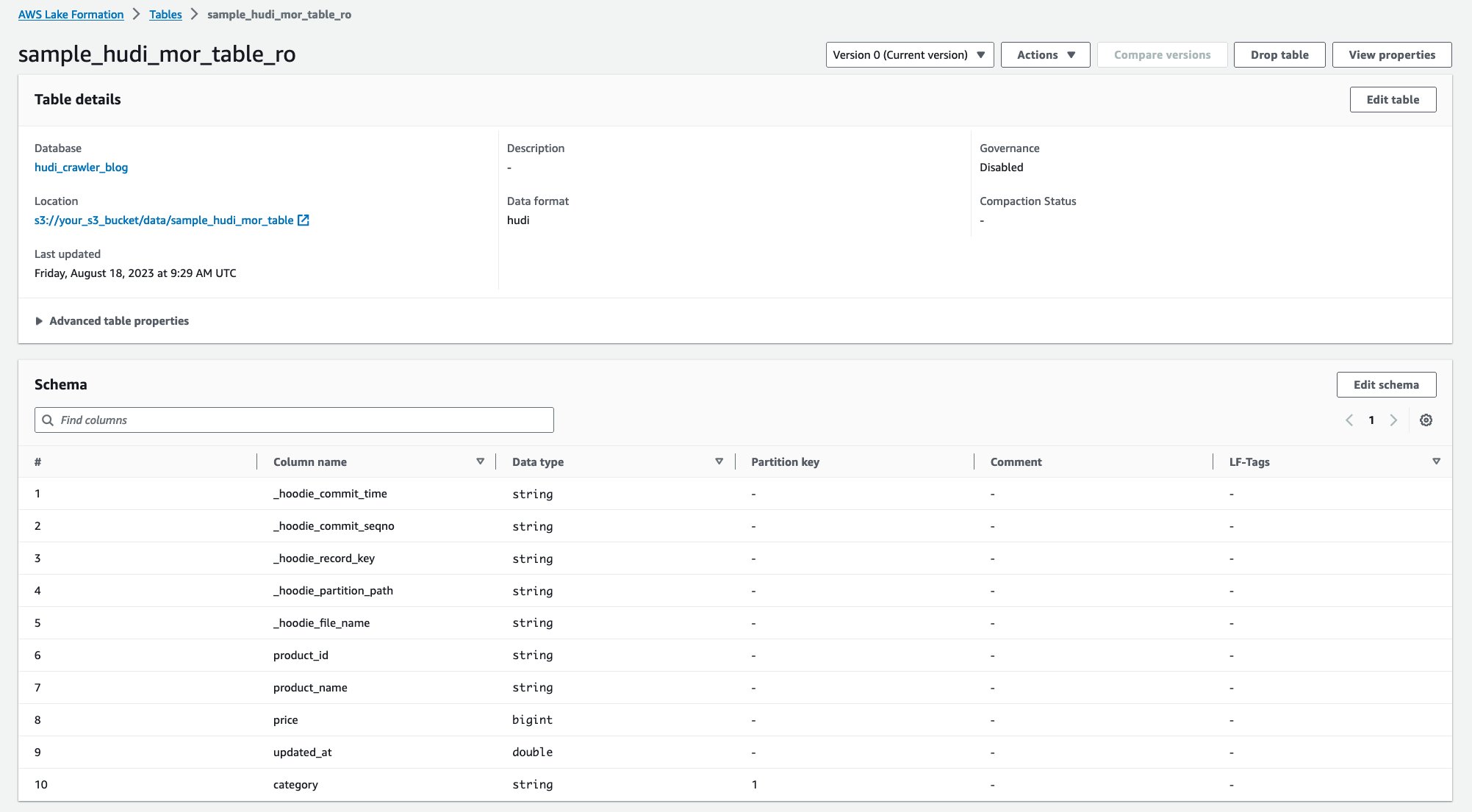
sample_hudi_mor_table_rt(таблиця реального часу)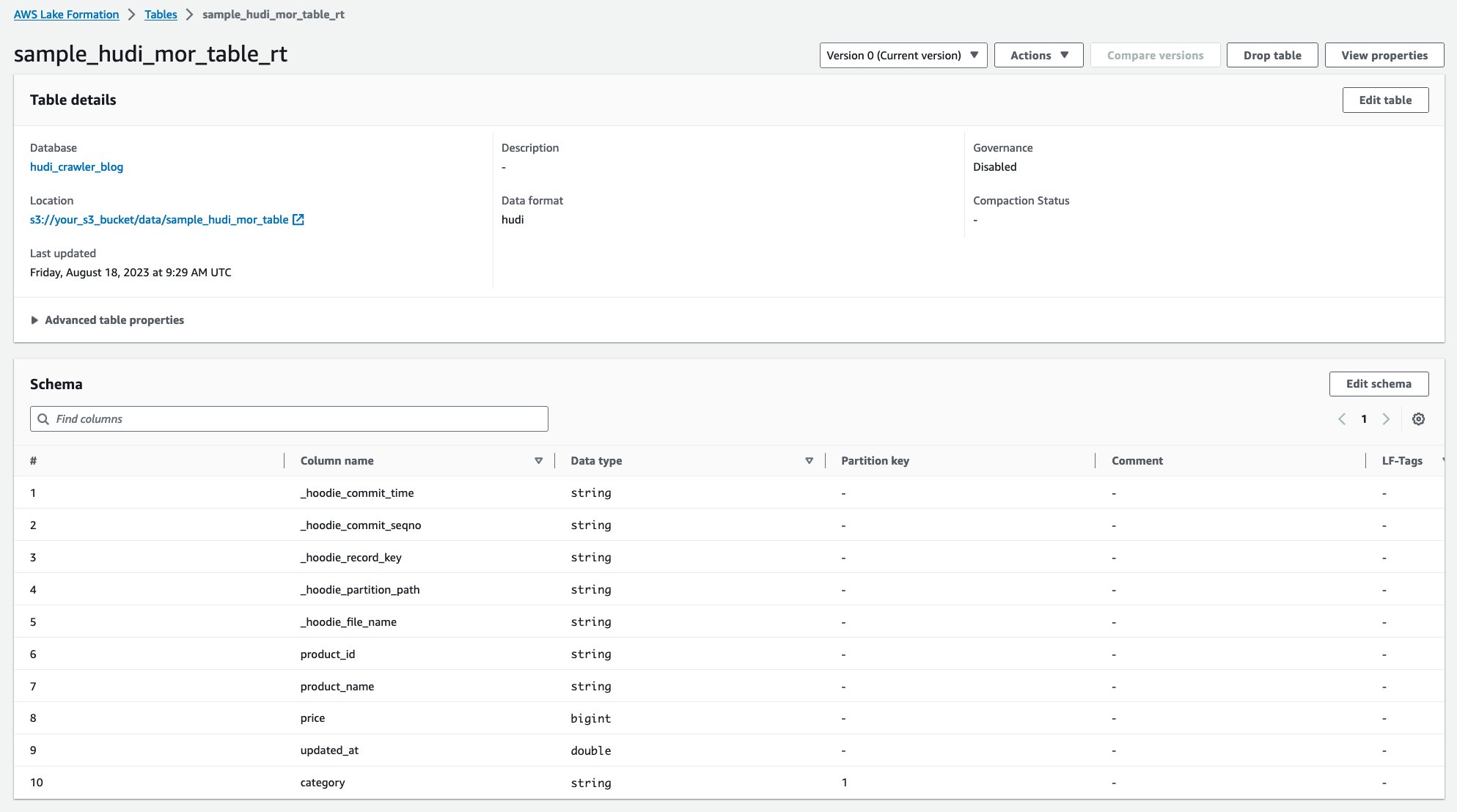
Ви зареєстрували сегмент озера даних у Lake Formation і ввімкнули скануючий доступ до озера даних за допомогою дозволів Lake Formation. Ви успішно просканували таблицю Hudi MoR із даними на Amazon S3 і створили таблицю AWS Glue Data Catalog із заповненою схемою. Після того, як ви створите визначення таблиці в AWS Glue Data Catalog, служби аналітики AWS, такі як Amazon Athena, зможуть запитувати таблицю Hudi.
Виконайте наступні кроки, щоб почати запити на Athena:
- Відкрийте консоль Amazon Athena.
- Виконайте наступний запит.
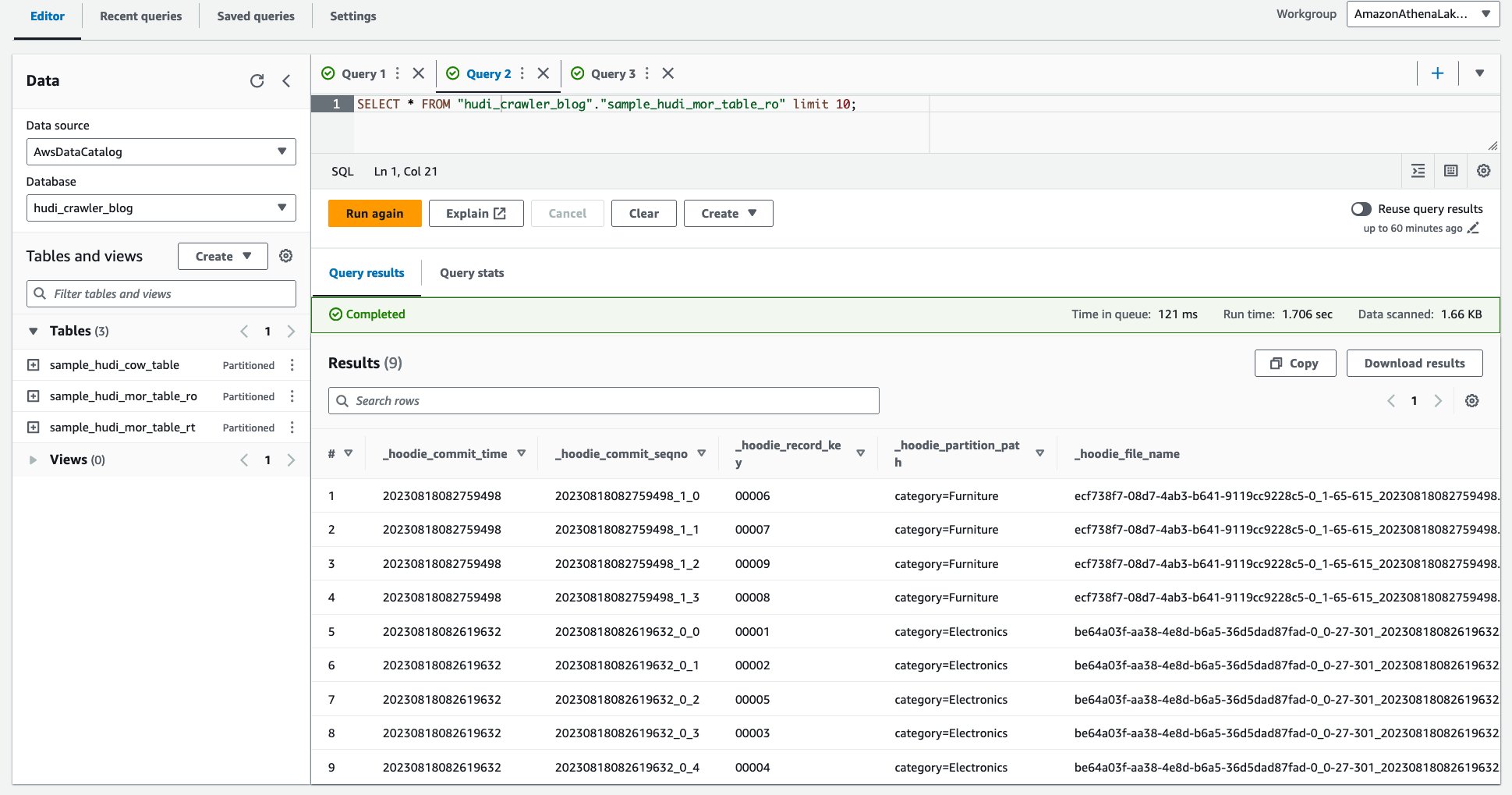
Наступний знімок екрана показує наш результат:
- Виконайте наступний запит.
Наступний знімок екрана показує наш результат:
Точне керування доступом за допомогою дозволів AWS Lake Formation
Щоб застосувати детальний контроль доступу до таблиці Hudi, ви можете скористатися дозволами AWS Lake Formation. Дозволи Lake Formation дозволяють обмежити доступ до певних таблиць, стовпців або рядків, а потім надсилати запити до таблиць Hudi через Amazon Athena з детальним контролем доступу. Давайте налаштуємо дозвіл Lake Formation для таблиці Hudi MoR.
Передумови
Ось передумови для цього підручника:
- Заповніть попередній розділ Сканування таблиці Hudi MoR за допомогою сканера AWS Glue із дозволами на дані AWS Lake Formation.
- Створіть користувача IAM DataAnalyst, який керує політикою AWS AmazonAthenaFullAccess.
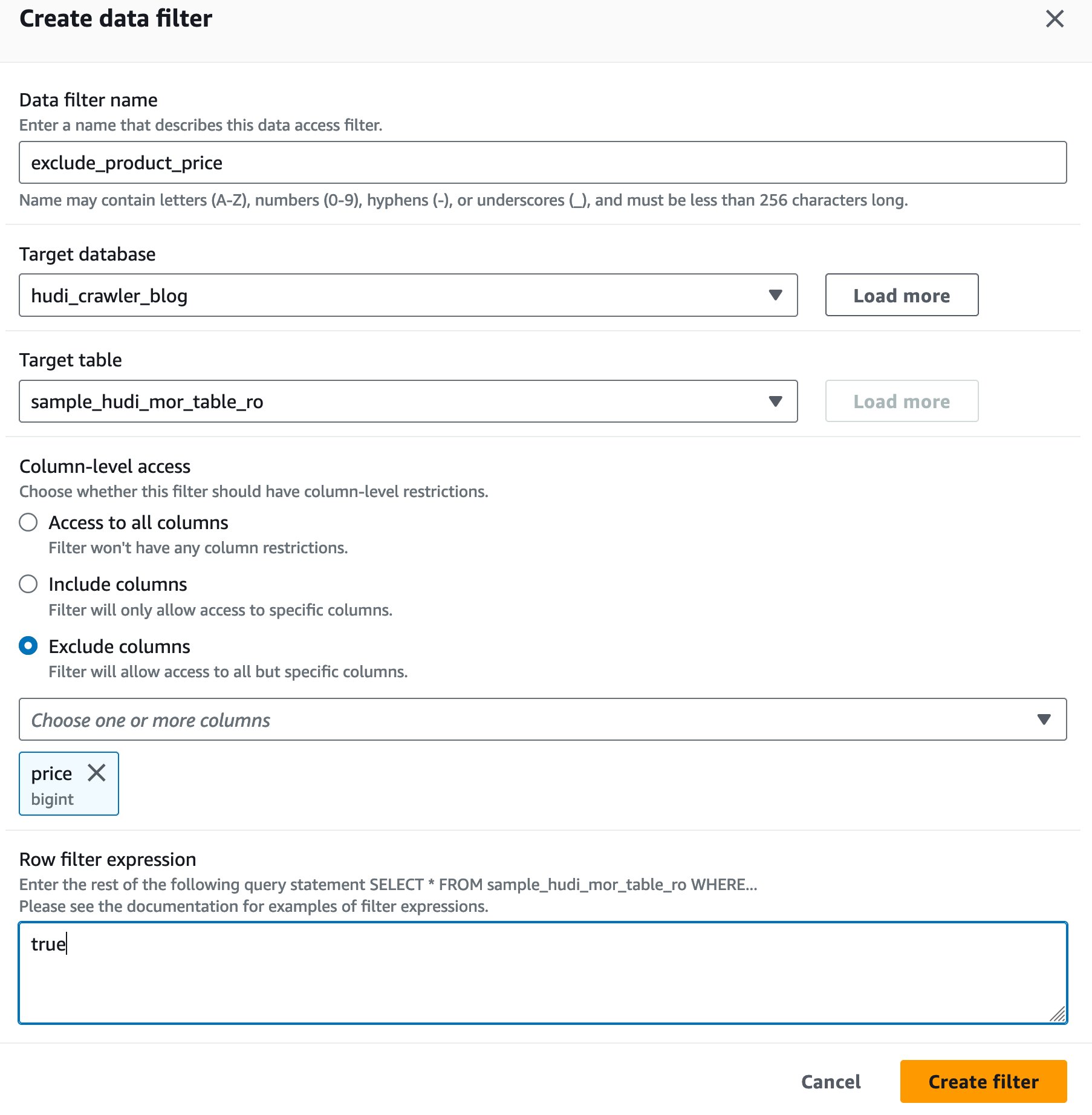
Створіть фільтр клітинок даних Lake Formation
Давайте спочатку налаштуємо фільтр для оптимізованої таблиці для читання MoR.
- Увійдіть у консоль Lake Formation як адміністратор озера даних.
- Вибирати Фільтри даних.
- Вибирати Створити новий фільтр.
- для Назва фільтра даних, введіть
exclude_product_price. - для Цільова база даних, виберіть базу даних
hudi_crawler_blog. - для Цільова таблиця, виберіть таблицю
sample_hudi_mor_table_ro. - для Стовпчастий рівень доступ, виберіть Виключити стовпці, і виберіть стовпець ціна.
- для Вираз фільтра рядка, введіть
true. - Вибирати Створіть фільтр.
Надайте користувачеві DataAnalyst дозволи на Lake Formation
Виконайте наступні кроки, щоб надати дозвіл на формування озера DataAnalyst користувач
- На консолі Lake Formation виберіть Дозволи озера даних.
- Вибирати Грант.
- для Директоривиберіть Користувачі та ролі IAMі виберіть користувача
DataAnalyst. - для Теги LF або ресурси каталогувиберіть Іменовані ресурси каталогу даних.
- для Database, виберіть базу даних
hudi_crawler_blog. - для Таблиця – за бажанням, виберіть таблицю
sample_hudi_mor_table_ro. - для Фільтри даних – за бажанням, виберіть
exclude_product_price. - для Дозволи фільтра данихвиберіть Select.
- Вибирати Грант.
Ви надали доступ до бази даних Lake Formation hudi_crawler_blog і стіл sample_hudi_mor_table_ro, за винятком колонки price для користувача DataAnalyst. Тепер перевіримо доступ користувача до даних за допомогою Athena.
- Увійдіть у консоль Athena як користувач DataAnalyst.
- У редакторі запитів виконайте такий запит:
Наступний знімок екрана показує наш результат:
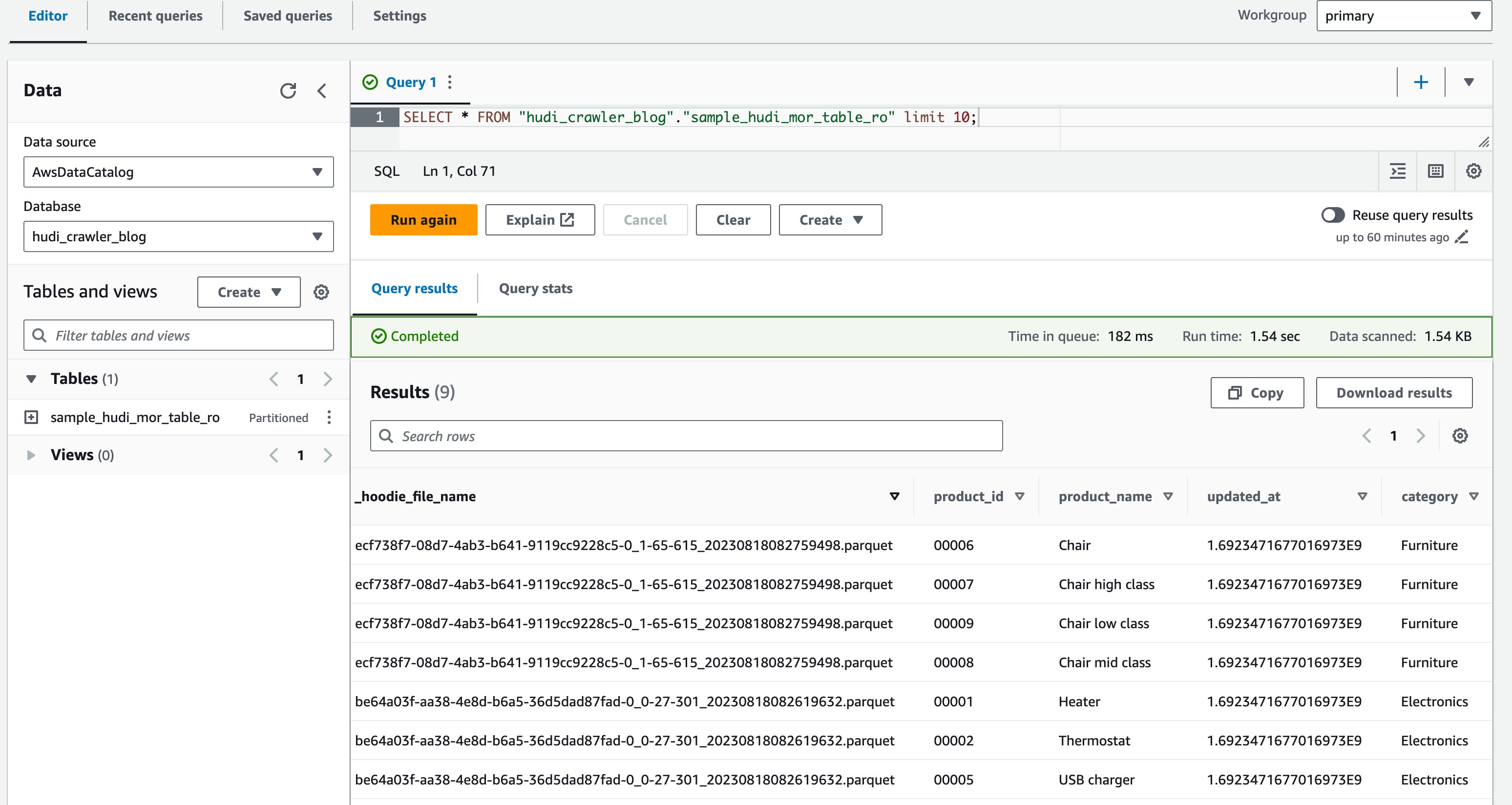
Тепер ви перевірили цей стовпець price не показано, але інші стовпці product_id, product_name, update_at та category відображаються.
Прибирати
Щоб уникнути небажаних стягнень з вашого облікового запису AWS, видаліть такі ресурси AWS:
- Видалити базу даних AWS Glue
hudi_crawler_blog. - Видаліть сканери AWS Glue
hudi_cow_crawlerтаhudi_mor_crawler. - Видаліть файли Amazon S3 під
s3://your_s3_bucket/data/sample_hudi_cow_table/таs3://your_s3_bucket/data/sample_hudi_mor_table/.
Висновок
Цей допис продемонстрував, як сканери AWS Glue працюють із таблицями Hudi. Завдяки підтримці сканера Hudi ви можете швидко перейти до використання AWS Glue Data Catalog як основного каталогу таблиць Hudi. Ви можете розпочати створення свого безсерверного озера транзакційних даних за допомогою Hudi на AWS, використовуючи AWS Glue, AWS Glue Data Catalog і детальний контроль доступу Lake Formation для таблиць і форматів, які підтримуються аналітичними механізмами AWS.
Про авторів
 Норітака Секіяма є головним архітектором великих даних у команді AWS Glue. Він працює в Токіо, Японія. Він відповідає за створення артефактів програмного забезпечення для допомоги клієнтам. У вільний час любить кататися на своєму шосейному велосипеді.
Норітака Секіяма є головним архітектором великих даних у команді AWS Glue. Він працює в Токіо, Японія. Він відповідає за створення артефактів програмного забезпечення для допомоги клієнтам. У вільний час любить кататися на своєму шосейному велосипеді.
 Кайл Дуонг є інженером із розробки програмного забезпечення в команді AWS Glue and Lake Formation. Він захоплений створенням технологій великих даних і розподілених систем.
Кайл Дуонг є інженером із розробки програмного забезпечення в команді AWS Glue and Lake Formation. Він захоплений створенням технологій великих даних і розподілених систем.
 Сандіп Адванкар є старшим менеджером із технічних продуктів в AWS. Перебуваючи в районі затоки Каліфорнії, він працює з клієнтами по всьому світу, щоб перетворити бізнес і технічні вимоги на продукти, які дозволяють клієнтам покращити спосіб керування, захисту та доступу до даних.
Сандіп Адванкар є старшим менеджером із технічних продуктів в AWS. Перебуваючи в районі затоки Каліфорнії, він працює з клієнтами по всьому світу, щоб перетворити бізнес і технічні вимоги на продукти, які дозволяють клієнтам покращити спосіб керування, захисту та доступу до даних.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- : має
- :є
- : ні
- :де
- $UP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- Здатний
- МЕНЮ
- доступ
- Доступ до даних
- доступ до
- рахунки
- дію
- додавати
- доданий
- доповнення
- прийнята
- Прийняття
- просунутий
- після
- ВСІ
- дозволяти
- Дозволити
- дозволяє
- Також
- Amazon
- Амазонка Афіна
- Amazon Web Services
- an
- Аналітичний
- аналітика
- та
- Інший
- будь-який
- Apache
- Apache Spark
- API
- з'являється
- додаток
- Розробка додатка
- Застосовувати
- ЕСТЬ
- ПЛОЩА
- навколо
- AS
- At
- автоматично
- уникнути
- AWS
- Клей AWS
- Формування озера AWS
- база
- заснований
- затока
- BE
- оскільки
- було
- користь
- Краще
- Великий
- Великий даних
- Приносить
- Створюємо
- побудований
- бізнес
- але
- by
- Каліфорнія
- call
- CAN
- можливості
- можливості
- випадок
- каталог
- каталоги
- категорії
- осередок
- проблеми
- зміна
- змінилися
- Зміни
- вантажі
- Вибирати
- Колонка
- Колони
- поєднання
- commit
- вчинено
- повний
- комплекс
- компонент
- конфігурація
- Консоль
- містить
- зміст
- постійно
- контроль
- управління
- може
- гусеничний
- створювати
- створений
- створює
- Повноваження
- Клієнти
- дані
- інтеграція даних
- Озеро даних
- сховище даних
- Database
- базами даних
- набори даних
- визначення
- Визначення
- Дельта
- продемонстрований
- демонструє
- глибина
- розробка
- безпосередньо
- відкрити
- розподілений
- розподілені системи
- do
- робить
- під час
- кожен
- легше
- легко
- редактор
- фактично
- ефективний
- включіть
- включений
- інженер
- Інженери
- Двигуни
- Що натомість? Створіть віртуальну версію себе у
- Ефір (ETH)
- еволюціонує
- виключення
- витяг
- швидше
- менше
- філе
- Файли
- фільтрувати
- Фільтри
- знайти
- Перший
- перший раз
- після
- для
- формат
- освіта
- часто
- від
- даний
- земну кулю
- Go
- надавати
- надається
- Гід
- Hadoop
- Мати
- he
- допомога
- допомагає
- його
- Вулик
- Як
- How To
- HTML
- HTTPS
- IAM
- if
- наслідки
- удосконалювати
- in
- У тому числі
- зростаючий
- інформація
- замість
- інтегрувати
- інтеграція
- інтерфейс
- в
- введення
- IT
- Japan
- JPG
- зберігання
- озеро
- озера
- останній
- запуск
- УЧИТЬСЯ
- вивчення
- менше
- МЕЖА
- Лінія
- список
- розташований
- розташування
- місць
- увійшли
- машина
- навчання за допомогою машини
- збереження
- зробити
- РОБОТИ
- управляти
- вдалося
- менеджер
- управління
- керівництво
- максимальний
- злиття
- метадані
- мігруючи
- міграція
- ML
- більше
- найбільш
- рухатися
- множинний
- ім'я
- рідний
- Необхідність
- необхідний
- Нові
- нещодавно
- наступний
- зараз
- of
- on
- ONE
- тільки
- відкрити
- з відкритим вихідним кодом
- оптимізований
- варіант
- or
- Інше
- наші
- вихід
- частина
- пристрасний
- шлях
- стежки
- продуктивність
- дозвіл
- Дозволи
- plato
- Інформація про дані Платона
- PlatoData
- популярний
- заселений
- пошта
- Готувати
- передумови
- попередній
- price
- первинний
- Головний
- обробка
- Product
- менеджер по продукції
- Продукти
- забезпечувати
- за умови
- забезпечує
- запити
- швидко
- Читати
- реальний
- реального часу
- реальному часі
- останній
- запис
- реєструвати
- зареєстрований
- замінювати
- Вимога
- ресурси
- відповідальний
- обмежити
- дорога
- Роль
- ROW
- прогін
- то ж
- розклад
- плановий
- Sdk
- розділ
- безпечний
- побачити
- вибрати
- старший
- Без сервера
- обслуговування
- Послуги
- комплект
- налаштування
- показаний
- Шоу
- спрощує
- з
- один
- Скибочка
- Знімок
- So
- Софтвер
- розробка програмного забезпечення
- Source
- Джерела
- Іскритися
- конкретний
- старт
- стан
- Крок
- заходи
- зберігати
- потоковий
- потоки
- студія
- Успішно
- такі
- підтримка
- Підтриманий
- синхронізація.
- Systems
- таблиця
- команда
- технічний
- Технології
- Що
- Команда
- їх
- потім
- Там.
- вони
- це
- три
- через
- час
- times
- до
- Токіо
- топ
- транзакційний
- Transactions
- переводити
- траверс
- викликати
- спрацьовує
- підручник
- два
- Типи
- типовий
- при
- небажаний
- Оновити
- оновлений
- Updates
- використання
- використання випадку
- використовуваний
- користувач
- користувачі
- використовує
- використання
- ПЕРЕВІР
- підтверджено
- Цінності
- версія
- візуальний
- Склад
- we
- Web
- веб-сервіси
- ДОБРЕ
- коли
- який
- в той час як
- ВООЗ
- волі
- з
- без
- Work
- працює
- запис
- письмовий
- ви
- вашу
- себе
- зефірнет