Амазонська червона зміна, широко використовуване хмарне сховище даних, значно вдосконалилося, щоб відповідати вимогам продуктивності для найвибагливіших робочих навантажень. Ця публікація охоплює одну з таких нових функцій — ключ сортування макета багатовимірних даних.
Тепер Amazon Redshift покращує продуктивність ваших запитів, підтримуючи ключі сортування багатовимірного макета даних, який є новим типом ключа сортування, який сортує дані таблиці за предикатами фільтрів замість фізичних стовпців таблиці. Ключі сортування макета багатовимірних даних значно підвищать продуктивність сканування таблиці, особливо якщо робоче навантаження запиту містить повторювані фільтри сканування.
Amazon Redshift уже надає можливість автоматична оптимізація таблиці (ATO), який автоматично оптимізує дизайн таблиць шляхом застосування ключів сортування та розподілу без втручання адміністратора. У цій публікації ми представляємо ключі сортування багатовимірного макета даних як додаткову можливість, надану ATO та посилену алгоритмом порадника ключів сортування Amazon Redshift.
Ключі сортування макета багатовимірних даних
Коли ви визначаєте таблицю за допомогою ключа сортування AUTO, Amazon Redshift ATO проаналізує вашу історію запитів і автоматично вибере для вашої таблиці ключ сортування в один стовпець або ключ сортування за макетом багатовимірних даних, залежно від того, який варіант краще підходить для вашого робочого навантаження. Якщо вибрано багатовимірний макет даних, Amazon Redshift створить функцію багатовимірного сортування, яка розміщує рядки, до яких зазвичай звертаються ті самі запити, а функція сортування згодом використовується під час виконання запиту, щоб пропускати блоки даних і навіть пропускати сканування окремого предикату. колонки.
Розглянемо наступний запит користувача, який є домінуючим шаблоном запитів у робочому навантаженні користувача:
Amazon Redshift зберігає дані для кожного стовпця в блоках диска по 1 МБ і зберігає мінімальні та максимальні значення в кожному блоці як частину метаданих таблиці. Якщо в запиті використовується a обмежений діапазоном предикат, Amazon Redshift може використовувати мінімальні та максимальні значення, щоб швидко пропускати велику кількість блоків під час сканування таблиці. Однак фільтр цього запиту в стовпці субрегіону не можна використовувати, щоб визначити, які блоки пропускати на основі мінімальних і максимальних значень, і в результаті Amazon Redshift сканує всі рядки з таблиці заголовків:
Коли запит користувача було запущено з titles за допомогою ключа сортування в один стовпець subregion, результат попереднього запиту такий:
Це показує, що сканування таблиці прочитало 2,164,081,640 XNUMX XNUMX XNUMX рядків.
Щоб покращити сканування на titles Amazon Redshift може автоматично прийняти рішення про використання ключа сортування макета багатовимірних даних. Усі рядки, які задовольняють lower(subregion) like '%United States%' предикат буде розміщено у виділеній області таблиці, тому Amazon Redshift скануватиме лише ті блоки даних, які задовольняють предикату.
Коли запит користувача виконується з titles за допомогою ключа сортування макета багатовимірних даних, який включає lower(subregion) like '%United States%' як предикат, результат дії sys_query_detail запит виглядає наступним чином:
Це показує, що під час сканування таблиці було прочитано 152,324,046 7 XNUMX рядків, що становить лише XNUMX% від оригіналу, і використовувався ключ сортування макета багатовимірних даних.
Зауважте, що в цьому прикладі використовується один запит для демонстрації функції макета багатовимірних даних, але Amazon Redshift розглядатиме всі запити, що виконуються до таблиці, і може створювати кілька регіонів, щоб задовольнити найпоширеніші предикати.
Давайте візьмемо інший приклад, цього разу зі складнішими предикатами та декількома запитами.
Уявіть собі стіл items (cost int, available int, demand int) з чотирма рядками, як показано в наступному прикладі.
| #ідентифікатор | коштувати | доступний | Попит |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Ваше домінуюче навантаження складається з двох запитів:
- 70% шаблон запитів:
- 20% шаблон запитів:
За допомогою традиційних методів сортування ви можете відсортувати таблицю за стовпцем вартості, щоб оцінка cost > 3 виграють від сортування. Отже, таблиця елементів після сортування за допомогою єдиного cost стовпець буде виглядати наступним чином.
| #ідентифікатор | коштувати | доступний | Попит |
| Регіон №1, з вартістю <= 3 | |||
| Регіон №2, вартість > 3 | |||
| #ідентифікатор | коштувати | доступний | Попит |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Використовуючи це традиційне сортування, ми можемо негайно виключити два верхні (сині) рядки з ID 4 та ID 2, оскільки вони не задовольняють cost > 3.
З іншого боку, за допомогою ключа сортування багатовимірного макета даних таблиця буде відсортована на основі комбінації двох найпоширеніших предикатів у робочому навантаженні користувача, які є cost > 3 та available < demand. У результаті рядки таблиці сортуються на чотири області.
| #ідентифікатор | коштувати | доступний | Попит |
| Регіон №1, з ціною <= 3 і наявністю < попиту | |||
| Регіон №2, вартість <= 3 і доступний >= попит | |||
| Регіон №3, вартість > 3 і наявність < попит | |||
| Регіон №4, вартість > 3 і наявність >= попит | |||
| #ідентифікатор | коштувати | доступний | Попит |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Ця концепція є ще потужнішою, коли її застосовують до цілих блоків замість окремих рядків, коли застосовують до складних предикатів, які використовують оператори, непридатні для традиційних методів сортування (таких як like), і коли застосовується до більш ніж двох предикатів.
Системні таблиці
Наступні системні таблиці Amazon Redshift покажуть користувачам, чи використовуються багатовимірні макети даних у їхніх таблицях і запитах:
- Щоб визначити, чи використовується певна таблиця ключ сортування макета багатовимірних даних, можна перевірити, чи використовується
sortkey1in svv_table_info дорівнюєAUTO(SORTKEY(padb_internal_mddl_key_col)). - Щоб визначити, чи використовує конкретний запит багатовимірний макет даних для прискорення сканування таблиці, ви можете перевірити
step_attributeв sys_query_detail переглянути. Значення буде дорівнюватиmulti-dimensionalякщо під час сканування використовувався ключ сортування макета багатовимірних даних таблиці.
Контрольні показники продуктивності
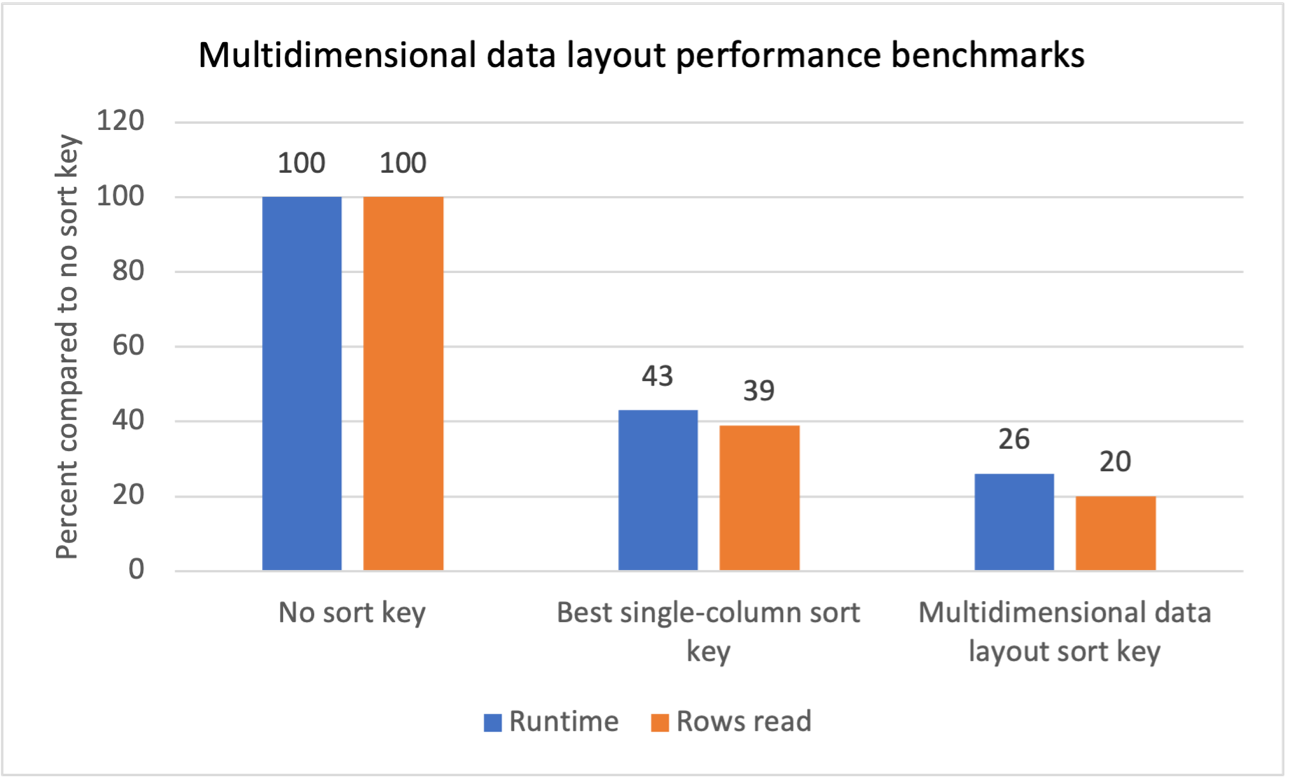
Ми провели внутрішнє порівняльне тестування для кількох робочих навантажень із повторюваними фільтрами сканування та побачили, що запровадження ключів сортування макета багатовимірних даних дало такі результати:
- Скорочення загального часу виконання на 74% порівняно з відсутністю ключа сортування.
- Загальний час виконання скорочено на 40% порівняно з використанням найкращого ключа сортування в одному стовпці для кожної таблиці.
- Зниження загальної кількості рядків, зчитаних із таблиць, на 80% порівняно з відсутністю ключа сортування.
- Зниження загальної кількості рядків, зчитаних із таблиць, на 47% порівняно з використанням найкращого ключа сортування в один стовпець у кожній таблиці.
Порівняння ознак
Завдяки введенню ключів сортування макета багатовимірних даних ваші таблиці тепер можна сортувати за виразами на основі найпоширеніших предикатів фільтрів у вашому робочому навантаженні. У наведеній нижче таблиці наведено порівняння функцій Amazon Redshift із двома конкурентами.
| особливість | Амазонська червона зміна | Конкурент А | Конкурент Б |
| Підтримка сортування по стовпцях | Так | Так | Так |
| Підтримка сортування за виразом | Так | Так | Немає |
| Автоматичний вибір стовпців для сортування | Так | Немає | Так |
| Автоматичний вибір виразів для сортування | Так | Немає | Немає |
| Автоматичний вибір між сортуванням стовпців або сортуванням виразів | Так | Немає | Немає |
| Автоматичне використання властивостей сортування для виразів під час сканування | Так | Немає | Немає |
Міркування
Під час використання багатовимірного макета даних пам’ятайте про таке:
- Багатовимірний макет даних увімкнено, якщо для таблиці встановлено значення SORTKEY AUTO.
- Amazon Redshift Advisor автоматично вибере ключ сортування в один стовпець або багатовимірний макет даних для таблиці, аналізуючи ваше історичне навантаження.
- Amazon Redshift ATO коригує результати сортування багатовимірного макета даних на основі того, як поточні запити взаємодіють із робочим навантаженням.
- Amazon Redshift ATO підтримує ключі сортування багатовимірного макета даних так само, як і для існуючих ключів сортування. Відноситься до Робота з автоматичною оптимізацією таблиці детальніше про АТО.
- Ключі сортування макета багатовимірних даних працюватимуть як із підготовленими кластерами, так і з безсерверними робочими групами.
- Ключі сортування макета багатовимірних даних працюватимуть із вашими наявними даними, доки у вашій таблиці ввімкнено AUTO SORTKEY і виявлено робоче навантаження з фільтрами повторного сканування. Таблиця буде реорганізована за результатами функції багатовимірного сортування.
- Щоб вимкнути ключі сортування макета багатовимірних даних для таблиці, скористайтеся alter table:
ALTER TABLE table_name ALTER SORTKEY NONE. Це вимикає функцію ключа АВТО сортування в таблиці. - Ключі сортування макета багатовимірних даних зберігаються під час відновлення або переміщення підготовленого кластера до безсерверного кластера або навпаки.
Висновок
У цьому дописі ми показали, що ключі сортування багатовимірних макетів даних можуть значно покращити продуктивність виконання запитів для робочих навантажень, де домінуючі запити мають повторювані фільтри сканування.
Щоб створити кластер попереднього перегляду з консолі Amazon Redshift, перейдіть до Кластери сторінку і виберіть Створити кластер попереднього перегляду. Ви можете створити кластер у регіонах Схід США (Огайо), Схід США (Північна Вірджинія), Захід США (Орегон), Азіатсько-Тихоокеанський регіон (Токіо), Європа (Ірландія) та Європа (Стокгольм) і перевірити робочі навантаження.
Ми хотіли б почути ваші відгуки про цю нову функцію та з нетерпінням чекаємо ваших коментарів до цієї публікації.
Про авторів
 Мілінд Оке є архітектором рішень спеціалістів зі сховища даних із Нью-Йорка. Він створює рішення для сховища даних понад 15 років і спеціалізується на Amazon Redshift.
Мілінд Оке є архітектором рішень спеціалістів зі сховища даних із Нью-Йорка. Він створює рішення для сховища даних понад 15 років і спеціалізується на Amazon Redshift.
 Цзялін Дін є прикладним науковцем у Learned Systems Group, який спеціалізується на застосуванні методів машинного навчання та оптимізації для покращення продуктивності систем даних, таких як Amazon Redshift.
Цзялін Дін є прикладним науковцем у Learned Systems Group, який спеціалізується на застосуванні методів машинного навчання та оптимізації для покращення продуктивності систем даних, таких як Amazon Redshift.
 Янчжу Цзі є менеджером із продуктів у команді Amazon Redshift. Вона має досвід у розробці бачення продукту та стратегії провідних у галузі продуктів і платформ даних. Вона має надзвичайні навички у створенні суттєвих програмних продуктів за допомогою веб-розробки, проектування системи, бази даних і методів розподіленого програмування. В особистому житті Яньчжу любить малювати, фотографувати та грати в теніс.
Янчжу Цзі є менеджером із продуктів у команді Amazon Redshift. Вона має досвід у розробці бачення продукту та стратегії провідних у галузі продуктів і платформ даних. Вона має надзвичайні навички у створенні суттєвих програмних продуктів за допомогою веб-розробки, проектування системи, бази даних і методів розподіленого програмування. В особистому житті Яньчжу любить малювати, фотографувати та грати в теніс.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- : має
- :є
- : ні
- :де
- 1
- 100
- 15 роки
- 15%
- 152
- 7
- 8
- 9
- a
- прискорювати
- доступний
- Додатковий
- радник
- після
- проти
- алгоритм
- ВСІ
- вже
- Amazon
- Amazon Web Services
- an
- аналізувати
- Аналізуючи
- та
- Інший
- прикладної
- Застосування
- ЕСТЬ
- AS
- Азія
- Азіатсько-Тихоокеанському регіоні
- автоматичний
- автоматичний
- автоматично
- доступний
- AWS
- заснований
- BE
- оскільки
- було
- еталонний тест
- користь
- КРАЩЕ
- Краще
- між
- Блокувати
- блоки
- синій
- обидва
- Створюємо
- але
- by
- CAN
- можливості
- перевірка
- Вибирати
- хмара
- кластер
- Колонка
- Колони
- поєднання
- коментарі
- зазвичай
- порівняний
- порівняння
- конкурентів
- комплекс
- концепція
- Вважати
- складається
- Консоль
- будувати
- містить
- Коштувати
- охоплює
- створювати
- В даний час
- дані
- сховище даних
- Database
- вирішувати
- присвячених
- визначати
- Попит
- вимогливий
- дизайн
- деталі
- виявлено
- Визначати
- розробка
- розподілений
- розподіл
- робить
- домінуючий
- Не знаю
- під час
- кожен
- Схід
- або
- включений
- Весь
- рівним
- особливо
- Ефір (ETH)
- Європа
- оцінка
- Навіть
- еволюціонували
- приклад
- існуючий
- досвід
- вирази
- особливість
- зворотний зв'язок
- фільтрувати
- Фільтри
- після
- слідує
- для
- Вперед
- чотири
- від
- функція
- Group
- рука
- Мати
- має
- he
- чути
- її
- історичний
- історія
- Однак
- HTML
- HTTPS
- ID
- if
- негайно
- удосконалювати
- поліпшується
- in
- includes
- індивідуальний
- провідний в галузі
- замість
- взаємодіяти
- внутрішній
- втручання
- в
- вводити
- введення
- Вступ
- Ірландія
- IT
- пунктів
- ключ
- ключі
- великий
- макет
- вчений
- вивчення
- життя
- як
- Сподобалося
- Довго
- подивитися
- виглядає як
- любов
- машина
- навчання за допомогою машини
- підтримує
- менеджер
- манера
- максимальний
- Зустрічатися
- метадані
- може бути
- мігруючи
- mind
- мінімальний
- більше
- найбільш
- множинний
- Переміщення
- Необхідність
- Нові
- Нова функція
- Нью-Йорк
- немає
- зараз
- номера
- трапляються
- of
- від
- запропонований
- Огайо
- on
- ONE
- постійний
- тільки
- Оператори
- оптимізація
- Оптимізує
- варіант
- or
- порядок
- Орегон
- оригінал
- Інше
- з
- видатний
- над
- Тихий океан
- Картина
- частина
- приватність
- Викрійки
- продуктивність
- виконується
- персонал
- малюнок
- фізичний
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- ігри
- пошта
- потужний
- збереглися
- попередній перегляд
- Вироблений
- Product
- менеджер по продукції
- Продукти
- Програмування
- властивості
- забезпечує
- запити
- швидко
- Читати
- скорочення
- послатися
- регіон
- райони
- повторювані
- Вимога
- відновлення
- результат
- результати
- прогін
- біг
- пробіжки
- то ж
- сканування
- сканування
- сканування
- вчений
- Сезон
- побачити
- вибрати
- обраний
- вибір
- Без сервера
- Послуги
- комплект
- вона
- Показувати
- демонстрації
- показав
- показаний
- Шоу
- істотно
- один
- майстерність
- So
- Софтвер
- Рішення
- спеціаліст
- спеціалізується
- спеціалізується
- магазинів
- Стратегія
- Згодом
- істотний
- такі
- підходящий
- Підтримуючий
- система
- Systems
- таблиця
- Приймати
- команда
- методи
- теніс
- тест
- Тестування
- ніж
- Що
- Команда
- їх
- отже
- вони
- це
- час
- назви
- до
- Токіо
- топ
- Усього:
- традиційний
- два
- тип
- типово
- us
- використання
- використовуваний
- користувач
- користувачі
- використовує
- використання
- значення
- Цінності
- віце
- вид
- Віргінія
- бачення
- Склад
- було
- шлях..
- we
- Web
- Веб-розробка
- веб-сервіси
- West
- коли
- Чи
- який
- широко
- волі
- з
- без
- Work
- б
- років
- йорк
- ви
- вашу
- зефірнет