У цій статті ми дізнаємося як розгорнути та використовувати модель GPT4All на вашому комп’ютері, що має лише ЦП (Я використовую a Macbook Pro без GPU!)

Використовуйте GPT4All на своєму комп’ютері — зображення автора
У цій статті ми збираємося встановити на наш локальний комп’ютер GPT4All (потужний LLM) і дізнаємося, як взаємодіяти з нашими документами за допомогою python. Колекція PDF-файлів або онлайн-статей стане базою знань для наших запитань/відповідей.
Від офіційний сайт GPT4All це описано як безкоштовний, локально запущений чат-бот, який підтримує конфіденційність. Графічний процесор чи Інтернет не потрібні.
GTP4All — це екосистема для навчання та розгортання потужний та налаштувати великі мовні моделі, які працюють локально на процесорах споживчого класу.
Наша модель GPT4All — це файл розміром 4 ГБ, який можна завантажити та підключити до програмного забезпечення екосистеми з відкритим кодом GPT4All. Nomic AI сприяє створенню високоякісних і безпечних екосистем програмного забезпечення, надаючи можливість окремим особам і організаціям легко навчатися та впроваджувати власні великі мовні моделі на локальному рівні.
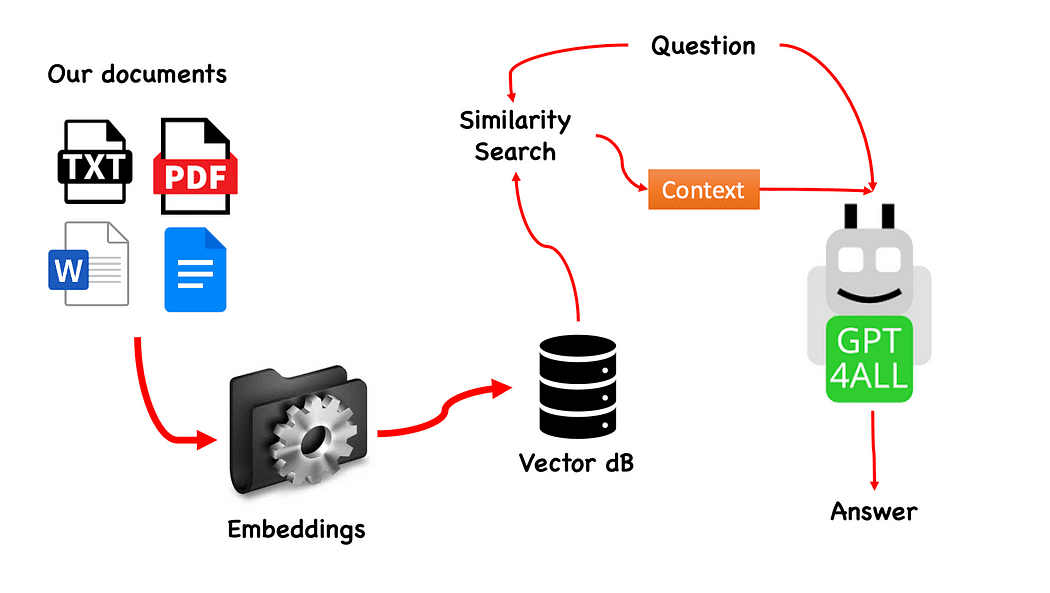
Робочий процес QnA з GPT4All — створений автором
Процес дуже простий (якщо ви це знаєте) і його можна повторити з іншими моделями. Кроки такі:
- завантажити модель GPT4All
- використання Лангчейн щоб отримати наші документи та завантажити їх
- розділіть документи на невеликі частини, які можна засвоїти Embeddings
- Використовуйте FAISS, щоб створити нашу векторну базу даних із вбудованими елементами
- Виконайте пошук подібності (семантичний пошук) у нашій векторній базі даних на основі запитання, яке ми хочемо передати GPT4All: це буде використано як контекст на наше запитання
- Додайте запитання та контекст до GPT4All Лангчейн і чекати відповіді.
Отже, нам потрібні вбудовування. Вбудовування — це числове представлення частини інформації, наприклад тексту, документів, зображень, аудіо тощо. Представлення фіксує семантичне значення того, що вбудовується, і це саме те, що нам потрібно. Для цього проекту ми не можемо покладатися на важкі моделі GPU: тому ми завантажимо нативну модель Alpaca та використаємо з Лангчейн LlamaCppEmbeddings. Не переживай! Все пояснюється крок за кроком
Створіть віртуальне середовище
Створіть нову папку для вашого нового проекту Python, наприклад GPT4ALL_Fabio (введіть своє ім’я…):
mkdir GPT4ALL_Fabio
cd GPT4ALL_FabioДалі створіть нове віртуальне середовище Python. Якщо у вас встановлено декілька версій python, вкажіть потрібну версію: у цьому випадку я використовуватиму свою основну інсталяцію, пов’язану з python 3.10.
python3 -m venv .venvКоманда python3 -m venv .venv створює нове віртуальне середовище під назвою .venv (крапка створить прихований каталог під назвою venv).
Віртуальне середовище забезпечує ізольовану інсталяцію Python, яка дозволяє встановлювати пакети та залежності лише для конкретного проекту, не впливаючи на загальносистемну інсталяцію Python або інші проекти. Ця ізоляція допомагає підтримувати послідовність і запобігати потенційним конфліктам між різними вимогами проекту.
Після створення віртуального середовища ви можете активувати його за допомогою такої команди:
source .venv/bin/activate 
Активоване віртуальне середовище
Бібліотеки для встановлення
Для проекту, який ми будуємо, нам не потрібно забагато пакетів. Нам потрібно лише:
- прив’язки python для GPT4All
- Langchain для взаємодії з нашими документами
LangChain — це платформа для розробки додатків на основі мовних моделей. Це дозволяє не тільки звертатися до мовної моделі через API, але й підключати мовну модель до інших джерел даних і дозволяти мовній моделі взаємодіяти з її середовищем.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4Для LangChain ви бачите, що ми вказали також версію. Останнім часом ця бібліотека отримує багато оновлень, тому, щоб бути впевненими, що наші налаштування працюватимуть і завтра, краще вказати версію, яка, як ми знаємо, працює добре. Unstructured є обов’язковою залежністю для завантажувача pdf та пітессеракт та pdf2 зображення а.
ПРИМІТКА: у репозиторії GitHub є файл requirements.txt (запропоновано jl adcr) з усіма версіями, пов’язаними з цим проектом. Ви можете виконати інсталяцію за один раз, завантаживши його в головний каталог файлів проекту за допомогою такої команди:
pip install -r requirements.txtНаприкінці статті я створив a розділ для усунення несправностей. У репо GitHub також є оновлений READ.ME з усією цією інформацією.
Майте на увазі, що деякі бібліотеки мають доступні версії залежно від версії python ви працюєте у своєму віртуальному середовищі.
Завантажте на свій ПК моделі
Це дійсно важливий крок.
Для проекту нам, звичайно, потрібен GPT4All. Процес, описаний на Nomic AI, справді складний і вимагає апаратного забезпечення, яке є не у всіх (як у мене). Так ось посилання на модель вже переобладнаний і готовий до використання. Просто натисніть на завантажити.
Завантажте модель GPT4All
Як коротко описано у вступі, нам також потрібна модель для вбудовування, модель, яку ми можемо запускати на нашому ЦП без руйнування. Натисніть на посилання тут, щоб завантажити alpaca-native-7B-ggml вже перетворено на 4-розрядний і готовий до використання як наша модель для вбудовування.

Натисніть стрілку завантаження поруч ggml-model-q4_0.bin
Навіщо нам вбудовування? Якщо ви пам’ятаєте з блок-схеми, перший необхідний крок після того, як ми збираємо документи для нашої бази знань, це зробити Вставляти їх. Вбудовування LLamaCPP цієї моделі Alpaca ідеально підходить для роботи, і ця модель також досить мала (4 Гб). До речі, ви також можете використовувати модель Alpaca для свого QnA!
Оновлення 2023.05.25: користувачі Mani Windows стикаються з проблемами використання вставок llamaCPP. В основному це відбувається тому, що під час інсталяції пакета python llama-cpp-python з:
pip install llama-cpp-pythonпакет pip збирається скомпілювати з вихідного коду бібліотеку. У Windows зазвичай на машині за замовчуванням не встановлено компілятор CMake або C. Але не лякайтеся, рішення є
Запуск інсталяції llama-cpp-python, необхідної для LangChain із llamaEmbeddings, у Windows Компілятор CMake C не інстальовано за замовчуванням, тому ви не можете створювати з джерела.
Для користувачів Mac з Xtools і Linux, як правило, компілятор C уже доступний в ОС.
Щоб уникнути проблеми ви ПОВИННІ використовувати попередньо відповідне колесо.
Зайдіть сюди https://github.com/abetlen/llama-cpp-python/releases
і шукайте відповідне колесо для вашої архітектури та версії python — ви ПОВИННІ взяти Weels версії 0.1.49 тому що нові версії несумісні.
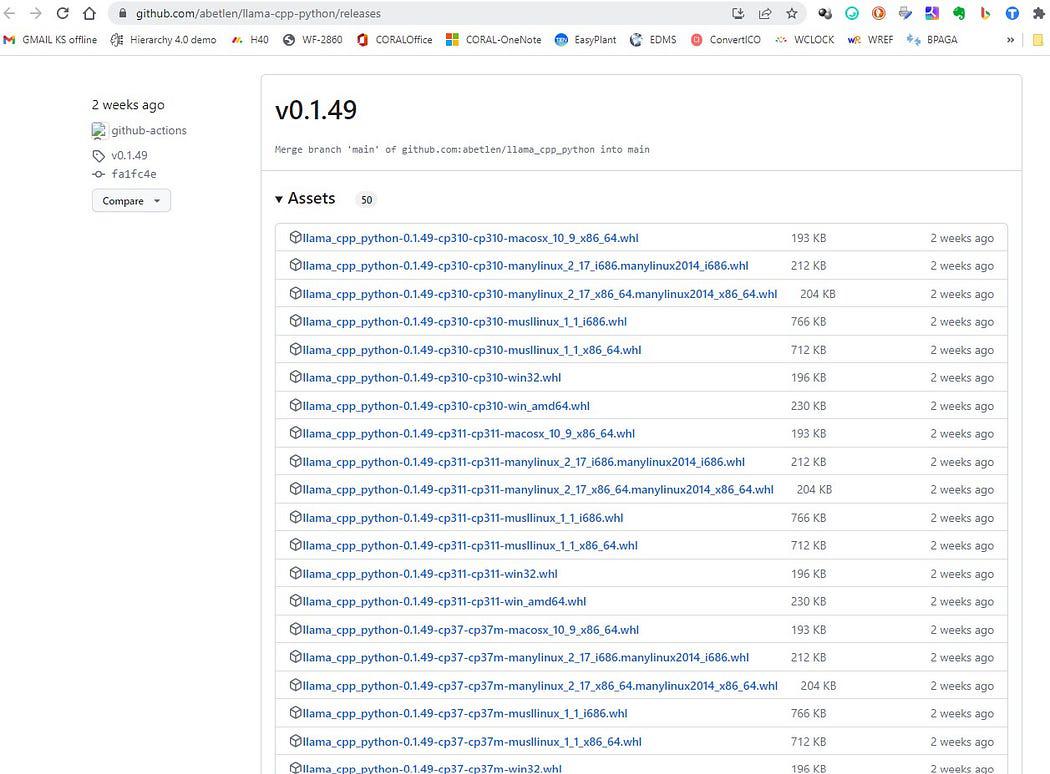
Знімок екрана з https://github.com/abetlen/llama-cpp-python/releases
У моєму випадку у мене Windows 10, 64 bit, python 3.10
тому мій файл llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
це проблема відстежується в репозиторії GitHub
Після завантаження вам потрібно помістити дві моделі в каталог моделей, як показано нижче.

Структура каталогів і місця розміщення файлів моделі
Оскільки ми хочемо контролювати нашу взаємодію з моделлю GPT, нам потрібно створити файл python (назвемо його pygpt4all_test.py), імпортуйте залежності та дайте інструкцію моделі. Ви побачите, що це досить легко.
from pygpt4all.models.gpt4all import GPT4AllЦе прив’язка python для нашої моделі. Тепер ми можемо зателефонувати і почати запитувати. Давайте спробуємо креатив.
Ми створюємо функцію, яка читає зворотний виклик з моделі, і просимо GPT4All завершити наше речення.
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)Перший оператор повідомляє нашій програмі, де знайти модель (пам’ятайте, що ми робили в розділі вище)
Другий оператор просить модель згенерувати відповідь і завершити нашу підказку «Одного разу».
Щоб запустити його, переконайтеся, що віртуальне середовище все ще активовано, і просто запустіть:
python3 pygpt4all_test.pyВи повинні побачити завантажувальний текст моделі та завершення речення. Залежно від ваших апаратних ресурсів це може зайняти трохи часу.
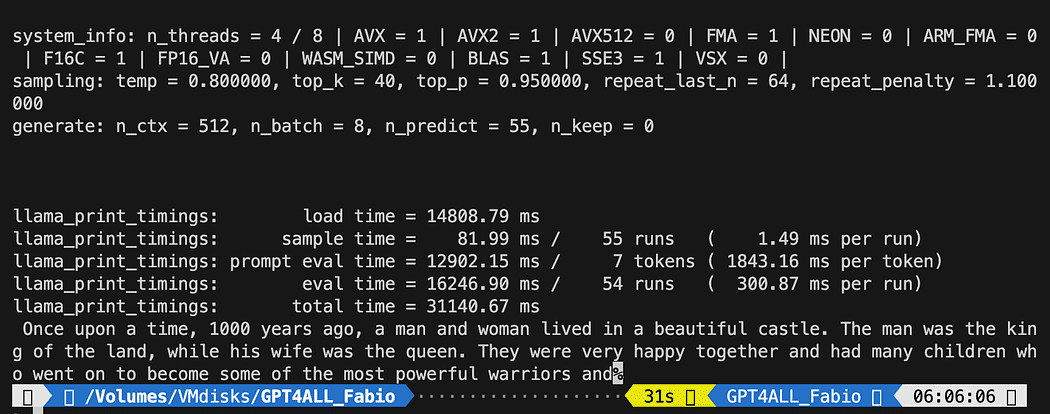
Результат може відрізнятися від вашого… Але для нас важливо, щоб він працював, і ми можемо продовжити роботу з LangChain, щоб створити деякі вдосконалені речі.
ПРИМІТКА (оновлено 2023.05.23): якщо ви зіткнулися з помилкою, пов’язаною з pygpt4all, перевірте розділ усунення несправностей у цій темі з рішенням, наданим Раджніш Аггарвал or автор Оскар Чон.
Фреймворк LangChain — справді дивовижна бібліотека. Це забезпечує компоненти працювати з мовними моделями простим у використанні способом, а також надає Ланцюги. Ланцюги можна розглядати як збірку цих компонентів певним чином для найкращого досягнення певного випадку використання. Вони призначені для створення інтерфейсу вищого рівня, за допомогою якого люди можуть легко розпочати роботу з конкретного випадку використання. Ці ланцюги також розроблені для налаштування.
У нашому наступному тесті Python ми будемо використовувати a Шаблон запиту. Мовні моделі приймають текст як вхідні дані — цей текст зазвичай називають підказкою. Як правило, це не просто жорстко закодований рядок, а скоріше комбінація шаблону, деяких прикладів і даних користувача. LangChain надає кілька класів і функцій, щоб полегшити створення підказок і роботу з ними. Давайте подивимося, як ми можемо це зробити.
Створіть новий файл python і викличте його my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])Ми імпортували з LangChain шаблон підказки та ланцюжок і клас GPT4All llm, щоб мати можливість безпосередньо взаємодіяти з нашою моделлю GPT.
Потім, після встановлення нашого шляху llm (як ми робили раніше), ми створюємо екземпляри менеджерів зворотного виклику, щоб ми могли ловити відповіді на наш запит.
Створити шаблон дуже просто: слідуючи підручник з документації ми можемо використати щось подібне...
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])Команда шаблон змінна – це багаторядковий рядок, який містить нашу структуру взаємодії з моделлю: у фігурних дужках ми вставляємо зовнішні змінні до шаблону, у нашому сценарії це наша питання.
Оскільки це змінна, ви можете вирішити, чи є це жорстко закодованим запитанням чи запитанням, введеним користувачем: ось два приклади.
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")Для нашого тестового запуску ми будемо коментувати введення користувача. Тепер нам потрібно лише зв’язати наш шаблон, питання та мовну модель.
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)Переконайтеся, що ваше віртуальне середовище все ще активовано, і виконайте команду:
python3 my_langchain.pyВи можете отримати результати, відмінні від моїх. Дивовижно те, що ви можете побачити всі міркування, а потім GPT4All намагається отримати відповідь для вас. Коригування питання також може дати кращі результати.
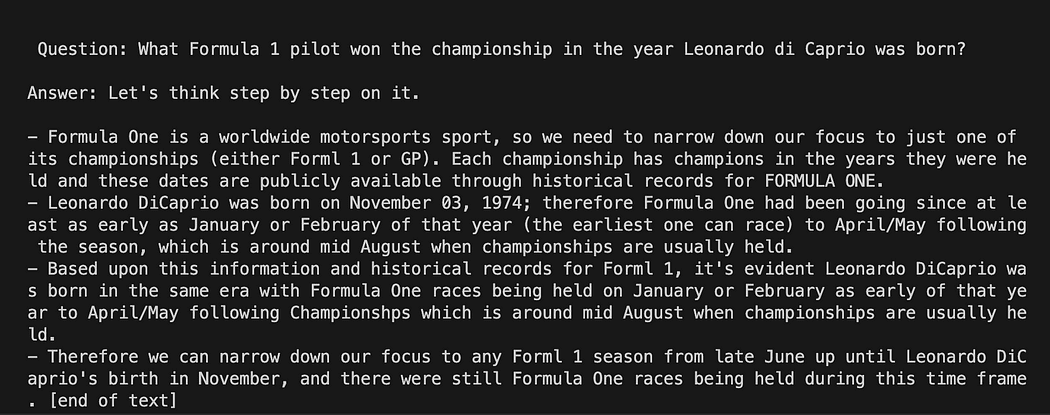
Langchain із шаблоном запиту на GPT4All
Тут ми починаємо дивовижну частину, тому що ми будемо спілкуватися з нашими документами за допомогою GPT4All як чат-бота, який відповідає на наші запитання.
Послідовність кроків, посилаючись на Робочий процес QnA з GPT4All, це завантажити наші PDF-файли, розділити їх на частини. Після цього нам знадобиться Vector Store для наших вбудовувань. Нам потрібно помістити наші фрагментовані документи у векторне сховище для пошуку інформації, а потім ми вставимо їх разом із пошуком схожості в цю базу даних як контекст для нашого запиту LLM.
Для цього ми будемо використовувати FAISS безпосередньо з Лангчейн бібліотека. FAISS — це бібліотека з відкритим вихідним кодом від Facebook AI Research, призначена для швидкого пошуку подібних елементів у великих колекціях багатовимірних даних. Він пропонує методи індексування та пошуку, щоб легше та швидше знаходити найбільш схожі елементи в наборі даних. Для нас це особливо зручно, тому що спрощує інформаційний пошук і дозволяє нам локально зберігати створену базу даних: це означає, що після першого створення вона буде завантажена дуже швидко для подальшого використання.
Створення векторного індексу db
Створіть новий файл і викличте його my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimeПерші бібліотеки ті самі, що ми використовували раніше: додатково ми використовуємо Лангчейн для створення індексу векторного сховища, the LlamaCppEmbeddings для взаємодії з нашою моделлю Alpaca (квантованою до 4 бітів і скомпільованою за допомогою бібліотеки cpp) і завантажувачем PDF.
Давайте також завантажимо наші LLM з їхніми власними шляхами: один для вбудовування та один для генерації тексту.
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)Для перевірки давайте перевіримо, чи вдалося нам прочитати всі файли pfd: перший крок — оголосити 3 функції, які використовуватимуться для кожного окремого документа. Перший — розділити витягнутий текст на частини, другий — створити векторний індекс із метаданими (як-от номери сторінок тощо), а останній — для перевірки пошуку подібності (я поясню краще пізніше).
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesТепер ми можемо протестувати створення індексу для документів у Документи каталог: нам потрібно помістити туди всі наші PDF-файли. Лангчейн також має метод завантаження всієї папки, незалежно від типу файлу: оскільки це складний постпроцес, я розповім про це в наступній статті про моделі LaMini.

мій каталог документів містить 4 файли pdf
Ми застосуємо наші функції до першого документа в списку
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)У перших рядках ми використовуємо бібліотеку os для отримання список файлів pdf всередині каталогу документів. Потім ми завантажуємо перший документ (doc_list[0]) з папки документів з Лангчейн, розбиваємо на частини, а потім створюємо векторну базу даних за допомогою Лама вбудовування.
Як ви бачили, ми використовуємо метод pyPDF. Це трохи довше у використанні, оскільки ви повинні завантажувати файли один за одним, але завантажувати PDF за допомогою pypdf у масив документів дозволяє створити масив, у якому кожен документ містить вміст сторінки та метадані page номер. Це дуже зручно, коли ви хочете знати джерела контексту, який ми надамо GPT4All у нашому запиті. Ось приклад із readthedocs:
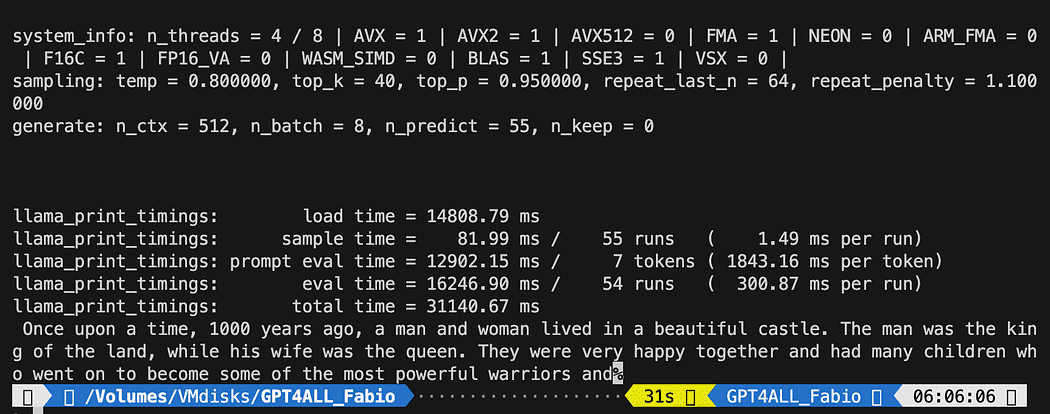
Знімок екрана з Документація Langchain
Ми можемо запустити файл python за допомогою команди з терміналу:
python3 my_knowledge_qna.pyПісля завантаження моделі для вбудовування ви побачите, що токени працюють для індексування: не лякайтеся, оскільки це займе час, особливо якщо ви працюєте лише на ЦП, як я (це зайняло 8 хвилин).
Завершення першого вектора db
Як я вже пояснював, метод pyPDF повільніший, але дає нам додаткові дані для пошуку подібності. Щоб переглянути всі наші файли, ми будемо використовувати зручний метод від FAISS, який дозволяє нам об’єднувати різні бази даних. Що ми робимо зараз, так це те, що ми використовуємо код вище, щоб створити першу базу даних (ми будемо називати її db0) і за допомогою циклу for ми створюємо індекс наступного файлу в списку та негайно об’єднуємо його з db0.
Ось код: зауважте, що я додав кілька журналів, щоб надати вам статус прогресу використання datetime.datetime.now() і друк дельти часу завершення та часу початку, щоб обчислити, скільки часу тривала операція (ви можете видалити її, якщо вона вам не подобається).
Інструкція злиття така
# merge dbi with the existing db0
db0.merge_from(dbi)Однією з останніх інструкцій є локальне збереження нашої бази даних: повне створення може зайняти навіть години (залежно від того, скільки документів у вас є), тому дуже добре, що ми повинні зробити це лише один раз!
# Save the databasae locally
db0.save_local("my_faiss_index")Ось весь код. Ми прокоментуємо багато його частин під час взаємодії з GPT4All, завантажуючи індекс безпосередньо з нашої папки.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  Запуск файлу python зайняв 22 хвилини
Запуск файлу python зайняв 22 хвилини
Ставте запитання до GPT4All щодо ваших документів
Тепер ми тут. У нас є наш індекс, ми можемо завантажити його, а за допомогою шаблону запиту ми можемо попросити GPT4All відповісти на наші запитання. Ми починаємо з жорстко закодованого запитання, а потім перебираємо запитання для введення.
Помістіть наступний код у файл python db_loading.py і запустіть його за допомогою команди з терміналу python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])Друкований текст — це список із 3 джерел, які найкраще відповідають запиту, а також назва документа та номер сторінки.
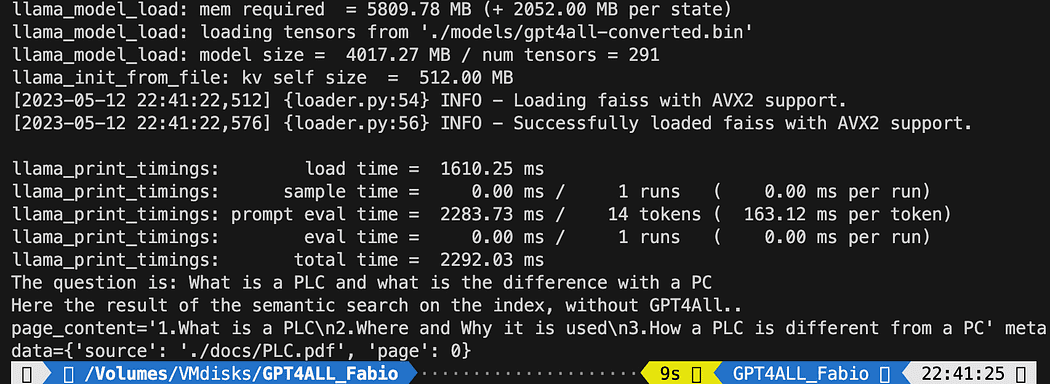
Результати семантичного пошуку під час запуску файлу db_loading.py
Тепер ми можемо використовувати пошук схожості як контекст для нашого запиту за допомогою шаблону запиту. Після 3 функцій просто замініть весь код наступним:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))Після запуску ви отримаєте такий результат (але він може відрізнятися). Дивно ні!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.Якщо ви хочете, щоб замість рядка було введене користувачем запитання
question = "What is a PLC and what is the difference with a PC"приблизно так:
question = input("Your question: ")Тобі пора експериментувати. Ставте різні запитання на всі теми, що стосуються ваших документів, і дивіться результати. Є великий простір для вдосконалення, звичайно, щодо підказки та шаблону: ви можете подивитися тут для натхнення. Але Лангчейн документація дійсно дивовижна (я міг би слідкувати за нею!!).
Ви можете слідувати коду зі статті або перевірити його мій репозиторій github.
Фабіо Матрікарді вихователь, учитель, інженер і ентузіаст навчання. Він 15 років викладає молодим студентам, а зараз навчає нових співробітників у Key Solution Srl. Він розпочав мою кар’єру інженера з промислової автоматизації у 2010 році. Захоплюючись програмуванням з підліткового віку, він відкрив для себе красу створення програмного забезпечення та інтерфейсів «людина-машина», щоб втілити щось у життя. Викладання та коучинг є частиною мого щоденного розпорядку, а також навчання та навчання, як бути пристрасним лідером із сучасними навичками управління. Приєднуйтесь до мене у подорожі до кращого дизайну, передбачуваної системної інтеграції з використанням машинного навчання та штучного інтелекту протягом усього життєвого циклу розробки.
Оригінал. Повідомлено з дозволу.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- EVM Фінанси. Уніфікований інтерфейс для децентралізованих фінансів. Доступ тут.
- Quantum Media Group. ІЧ/ПР посилений. Доступ тут.
- PlatoAiStream. Web3 Data Intelligence. Розширення знань. Доступ тут.
- джерело: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- : має
- :є
- : ні
- :де
- $UP
- 1
- 10
- 11
- 12
- 13
- 14
- 15 роки
- 15%
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- здатність
- Здатний
- МЕНЮ
- вище
- виконувати
- Діяти
- активоване
- доданий
- доповнення
- Додатковий
- просунутий
- зачіпає
- після
- AI
- ai дослідження
- ВСІ
- дозволяти
- дозволяє
- вже
- Також
- am
- дивовижний
- an
- аналіз
- та
- відповідь
- будь-який
- API
- застосування
- Застосовувати
- архітектура
- ЕСТЬ
- масив
- стаття
- статті
- штучний
- штучний інтелект
- AS
- асоційований
- At
- аудіо
- Автоматизований
- автоматично
- Автоматизація
- доступний
- уникнути
- база
- заснований
- BE
- Краса
- оскільки
- було
- перед тим
- буття
- нижче
- КРАЩЕ
- Краще
- між
- За
- Великий
- BIN
- обов'язковий
- Біт
- народжений
- коротко
- приносити
- будувати
- Створюємо
- вбудований
- автобусів
- але
- by
- обчислювати
- call
- званий
- Виклики
- CAN
- не може
- потужність
- захвати
- кар'єра
- нести
- випадок
- Залучайте
- CD
- певний
- звичайно
- ланцюг
- ланцюга
- чемпіонат
- Chatbot
- ChatGPT
- перевірка
- хімічний
- клас
- класів
- клацання
- тренування
- код
- Коди
- збирати
- збір
- Колекції
- поєднання
- коментар
- зазвичай
- спілкуватися
- Комунікація
- сумісний
- повний
- Зроблено
- завершення
- комплекс
- складний
- Компоненти
- комп'ютер
- комп'ютери
- З'єднуватися
- підключений
- будівництво
- споживач
- містить
- зміст
- контекст
- контроль
- контролер
- управління
- Зручний
- перероблений
- може
- обкладинка
- центральний процесор
- створювати
- створений
- створює
- створення
- створення
- Креатив
- критичний
- настроюється
- щодня
- дані
- Database
- базами даних
- Дата
- дата, час
- вирішувати
- дефолт
- певний
- Дельта
- Залежність
- Залежно
- залежить
- розгортання
- описаний
- дизайн
- призначений
- бажаний
- розвивається
- пристрій
- прилади
- DID
- різниця
- різний
- засвоюється
- цифровий
- безпосередньо
- відкрити
- відкритий
- do
- документ
- документація
- документація
- робить
- байдуже
- зроблений
- Не знаю
- DOT
- скачати
- водіння
- під час
- кожен
- легше
- легко
- легко
- екосистема
- екосистеми
- зусилля
- Вставляти
- вбудований
- вбудовування
- співробітників
- включіть
- кінець
- інженер
- Машинобудування
- Що натомість? Створіть віртуальну версію себе у
- ентузіаст
- Весь
- Навколишнє середовище
- помилка
- особливо
- і т.д.
- Ефір (ETH)
- Навіть
- все
- точно
- приклад
- Приклади
- виконання
- існуючий
- експеримент
- Пояснювати
- пояснені
- пояснюючи
- зовнішній
- Face
- полегшує
- облицювання
- ШВИДКО
- швидше
- філе
- Файли
- знайти
- кінець
- Перший
- відповідати
- потік
- стежити
- потім
- після
- слідує
- для
- форма
- формат
- формула
- формула 1
- Рамки
- від
- функція
- Функції
- далі
- породжувати
- породжує
- покоління
- отримати
- GitHub
- Давати
- даний
- дає
- дає
- буде
- добре
- GPU
- клас
- Обробка
- відбувається
- Жорсткий
- апаратні засоби
- Мати
- he
- важкий
- допомагає
- тут
- прихований
- Високий
- вище
- ГОДИННИК
- Як
- How To
- HTML
- HTTP
- HTTPS
- людина
- i
- ICS
- if
- зображень
- негайно
- здійснювати
- імпорт
- важливо
- поліпшення
- in
- включати
- індекс
- покажчики
- осіб
- промислові
- промислова автоматизація
- промисловості
- інформація
- вхід
- введення-виведення
- витрати
- встановлювати
- установка
- екземпляр
- інструкції
- інтеграція
- Інтелект
- призначених
- взаємодіяти
- взаємодія
- інтерфейс
- Інтерфейси
- інтернет
- в
- Вступ
- ізольований
- ізоляція
- IT
- пунктів
- ітерація
- ЙОГО
- робота
- приєднатися
- подорож
- просто
- KDnuggets
- ключ
- Знати
- знання
- мова
- великий
- останній
- пізніше
- лідер
- вивчення
- рівень
- libraries
- бібліотека
- життя
- Життєвий цикл
- як
- ліній
- LINK
- Linux
- список
- трохи
- загрузка
- завантажувач
- погрузка
- місцевий
- локально
- логіка
- Довго
- довше
- подивитися
- серія
- макінтош
- машина
- навчання за допомогою машини
- машини
- головний
- головним чином
- підтримувати
- зробити
- вдалося
- управління
- менеджер
- Менеджери
- виробництво
- багато
- Може..
- сенс
- засоби
- пам'ять
- Злиття
- злиття
- метадані
- метод
- методика
- mind
- протокол
- модель
- Моделі
- більше
- найбільш
- множинний
- повинен
- my
- ім'я
- рідний
- Необхідність
- мереж
- Нові
- наступний
- зараз
- номер
- номера
- об'єкт
- of
- Пропозиції
- on
- один раз
- ONE
- онлайн
- тільки
- з відкритим вихідним кодом
- операція
- операції
- or
- порядок
- організації
- OS
- Інше
- наші
- з
- вихід
- над
- власний
- пакет
- пакети
- сторінка
- Паралельні
- частина
- приватність
- особливо
- проходити
- пристрасний
- шлях
- PC
- Люди
- виконувати
- дозвіл
- персонал
- картина
- частина
- пілот
- рослин
- plato
- Інформація про дані Платона
- PlatoData
- PLC
- будь ласка
- штекер
- Порти
- положення
- пошта
- потенціал
- влада
- електростанції
- Харчування
- потужний
- попередньо
- запобігати
- друк
- друк
- проблеми
- процес
- оброблена
- процеси
- програма
- запрограмований
- Програмування
- прогрес
- проект
- проектів
- протоколи
- забезпечує
- цілей
- put
- Python
- якість
- питання
- питань
- швидко
- швидше
- Читати
- готовий
- насправді
- отримання
- нещодавно
- називають
- відноситься
- Незалежно
- регістри
- пов'язаний
- надійність
- покладатися
- запам'ятати
- видаляти
- повторний
- замінювати
- звітом
- Сховище
- подання
- вимагається
- Вимога
- Вимагається
- дослідження
- ресурси
- відповідь
- відповіді
- результат
- результати
- повертати
- Кімната
- прогін
- біг
- s
- Безпека
- то ж
- зберегти
- економія
- сценарій
- Пошук
- Грати короля карти - безкоштовно Nijumi логічна гра гри
- другий
- розділ
- безпечний
- побачити
- датчиків
- пропозиція
- Послідовність
- послідовний
- установка
- установка
- кілька
- постріл
- Повинен
- показаний
- аналогічний
- простий
- просто
- з
- один
- навички
- невеликий
- So
- Софтвер
- рішення
- деякі
- що в сім'ї щось
- Source
- Джерела
- спеціалізований
- спеціально
- конкретний
- зазначений
- розкол
- Spot
- старт
- почалася
- Починаючи
- Заява
- Статус
- Крок
- заходи
- Як і раніше
- зберігати
- рядок
- структура
- Студентам
- вивчення
- такі
- система
- Приймати
- балаканина
- завдання
- учитель
- Навчання
- підліток
- шаблон
- термінал
- тест
- Тестовий пробіг
- Тестування
- генерація тексту
- ніж
- Що
- Команда
- їх
- Їх
- потім
- Там.
- Ці
- вони
- думати
- це
- думка
- через
- по всьому
- час
- до
- разом
- Жетони
- завтра
- занадто
- прийняли
- тема
- теми
- до
- поїзд
- намагатися
- два
- тип
- типовий
- типово
- оновлений
- Updates
- на
- us
- Використання
- USB
- використання
- використання випадку
- використовуваний
- користувач
- користувачі
- використання
- зазвичай
- використовувати
- різний
- перевірити
- версія
- дуже
- через
- Віртуальний
- W3
- чекати
- хотіти
- було
- шлях..
- способи
- we
- веб-сайт
- ДОБРЕ
- Що
- Що таке
- Колесо
- коли
- який
- ВООЗ
- чому
- широко
- волі
- windows
- Користувачі Windows
- з
- в
- без
- Виграв
- Work
- робочий
- рік
- років
- ви
- молодий
- вашу
- зефірнет










