
Вересень 20, 2023
Основні моделі (FM) знаменують собою початок нової ери в машинне навчання (ML) та штучний інтелект (ШІ), що призводить до швидшої розробки штучного інтелекту, який можна адаптувати до широкого спектру подальших завдань і точно налаштувати для низки програм.
У зв’язку зі зростаючою важливістю обробки даних там, де виконується робота, обслуговування моделей штучного інтелекту на межі підприємства дозволяє прогнозувати майже в реальному часі, дотримуючись при цьому вимог щодо суверенітету даних і конфіденційності. Поєднуючи в IBM watsonx можливості платформи даних і штучного інтелекту для FM з периферійними обчисленнями, підприємства можуть запускати робочі навантаження штучного інтелекту для тонкого налаштування FM і висновків на операційній межі. Це дає змогу підприємствам масштабувати розгортання штучного інтелекту на межі, скорочуючи час і витрати на розгортання та швидший час відгуку.
Обов’язково ознайомтеся з усіма частинами цієї серії публікацій блогу про периферійні обчислення:
Що таке фундаментальні моделі?
Основні моделі (FM), які навчаються на широкому наборі немаркованих даних у масштабі, керують найсучаснішими програмами штучного інтелекту (AI). Вони можуть бути адаптовані до широкого спектру подальших завдань і точно налаштовані для низки програм. Сучасні моделі штучного інтелекту, які виконують конкретні завдання в одному домені, поступаються місцем FM, оскільки вони навчаються більш загально і працюють у різних областях і проблемах. Як випливає з назви, FM може бути основою для багатьох застосувань моделі ШІ.
FMs вирішують дві ключові проблеми, які заважають підприємствам масштабувати впровадження ШІ. По-перше, підприємства виробляють величезну кількість немаркованих даних, лише частина яких позначена для навчання моделі ШІ. По-друге, це завдання маркування та анотації є надзвичайно трудомістким, часто вимагаючи кількох сотень годин часу експерта з тематики (SME). Це робить масштабування за різними варіантами використання надзвичайно дорогим, оскільки для цього знадобляться армії малих і середніх підприємств та експертів із даних. Поглинаючи величезні обсяги немаркованих даних і використовуючи методи самоконтролю для навчання моделей, FM усунули ці вузькі місця та відкрили шлях для широкомасштабного впровадження штучного інтелекту на підприємстві. Ці величезні обсяги даних, які існують у кожному бізнесі, чекають, щоб їх оприлюднили, щоб отримати розуміння.
Що таке великі мовні моделі?
Великі мовні моделі (LLM) — це клас фундаментальних моделей (FM), які складаються з шарів нейронні мережі які пройшли навчання на цих величезних обсягах немаркованих даних. Вони використовують алгоритми самоконтрольованого навчання для виконання різноманітних завдань обробка природної мови (НЛП) завдання способами, подібними до того, як люди використовують мову (див. рис. 1).
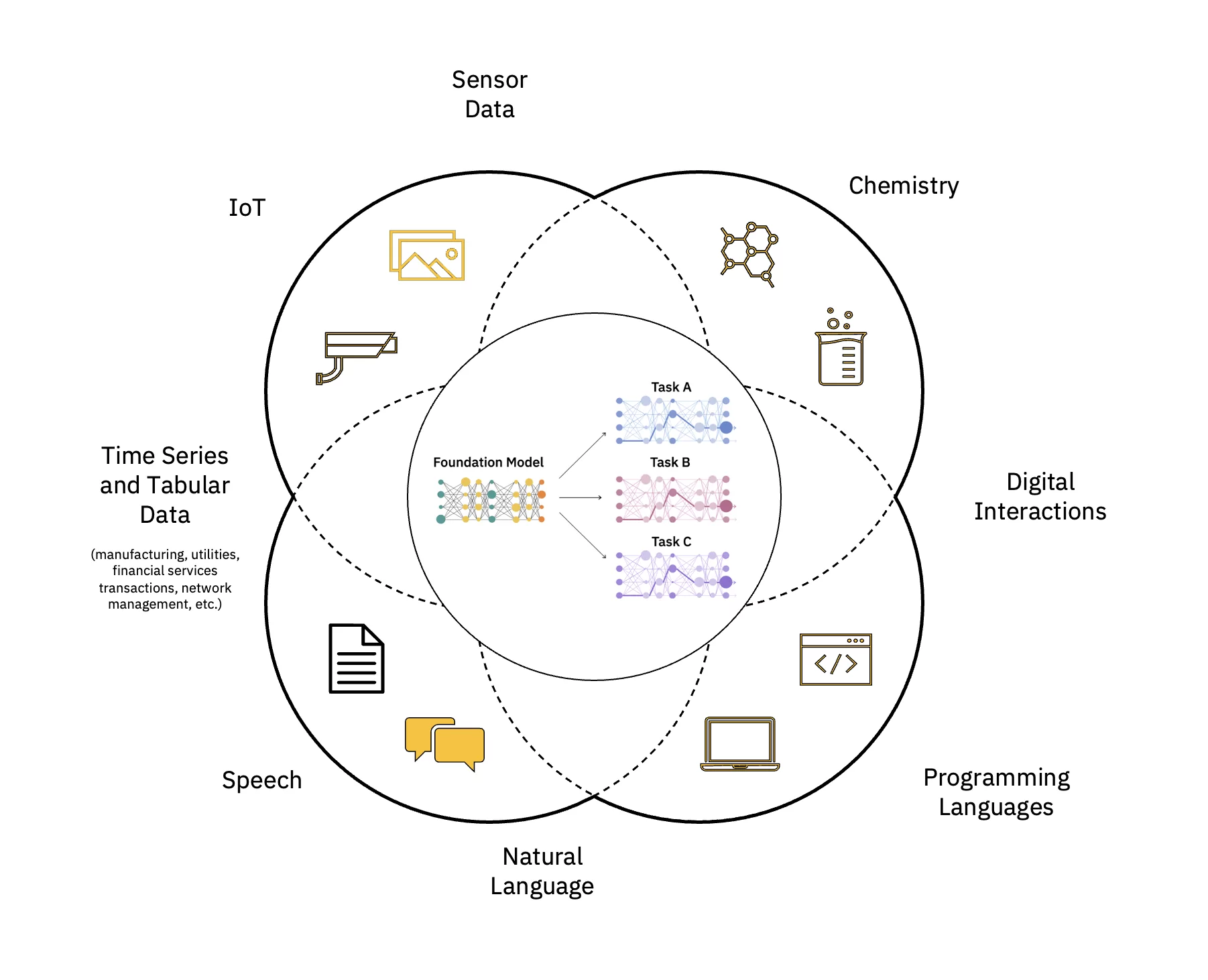
Масштабуйте та прискорюйте вплив ШІ
Існує кілька кроків для створення та розгортання базової моделі (FM). До них належать прийом даних, вибір даних, попередня обробка даних, попереднє навчання FM, налаштування моделі для одного або кількох наступних завдань, обслуговування висновків, а також управління даними та моделлю AI та керування життєвим циклом — усе це можна описати як FMOps.
Щоб допомогти з усім цим, IBM пропонує підприємствам необхідні інструменти та можливості для використання потужності цих FM через IBM watsonx, готова для підприємства платформа штучного інтелекту та даних, розроблена для збільшення впливу ШІ на підприємство. IBM watsonx складається з наступного:
- IBM watsonx.ai приносить нове генеративний ШІ можливості — на основі FM і традиційного машинного навчання (ML) — у потужну студію, що охоплює життєвий цикл ШІ.
- IBM watsonx.data це придатне для цілей сховище даних, побудоване на відкритій архітектурі lakehouse для масштабування робочих навантажень ШІ для всіх ваших даних у будь-якому місці.
- IBM watsonx.governance це наскрізний автоматизований набір інструментів управління життєвим циклом штучного інтелекту, створений для забезпечення відповідальних, прозорих і зрозумілих робочих процесів ШІ.
Іншим ключовим вектором є зростаюча важливість обчислень на периферії підприємства, наприклад, промислові місця, виробничі цехи, роздрібні магазини, периферійні сайти телекомунікацій тощо. Більш конкретно, штучний інтелект на межі підприємства дозволяє обробляти дані там, де виконується робота для аналіз майже в реальному часі. Підприємство — це місце, де генеруються величезні обсяги корпоративних даних і де штучний інтелект може надавати цінну, своєчасну та дієву інформацію про бізнес.
Обслуговування моделей штучного інтелекту на межі дозволяє робити прогнози майже в реальному часі, дотримуючись вимог суверенітету даних і конфіденційності. Це значно зменшує затримку, яка часто пов’язана із отриманням, передачею, перетворенням і обробкою даних перевірки. Робота на межі дозволяє нам захистити конфіденційні корпоративні дані та скоротити витрати на передачу даних за рахунок швидшого часу відповіді.
Проте масштабування розгортання штучного інтелекту на межі – це непросте завдання через проблеми, пов’язані з даними (неоднорідністю, обсягом і нормативними вимогами) і обмеженими ресурсами (обчислювальними ресурсами, підключенням до мережі, сховищем і навіть ІТ-навички). Узагальнено їх можна описати в двох категоріях:
- Час/вартість розгортання: Кожне розгортання складається з кількох рівнів апаратного та програмного забезпечення, які необхідно встановити, налаштувати та протестувати перед розгортанням. Сьогодні фахівець з обслуговування може зайняти тиждень або два для встановлення у кожному місці, суттєво обмежуючи швидкість і економічність підприємств, які можуть розгорнути розгортання в межах своєї організації.
- День 2 управління: Величезна кількість розгорнутих країв і географічне розташування кожного розгортання часто можуть призвести до надто високої вартості надання локальної ІТ-підтримки в кожному місці для моніторингу, підтримки та оновлення цих розгортань.
Розгортання Edge AI
IBM розробила периферійну архітектуру, яка вирішує ці проблеми, додаючи інтегровану апаратно-програмну (HW/SW) модель пристрою до периферійних розгортань ШІ. Він складається з кількох ключових парадигм, які сприяють масштабованості розгортань ШІ:
- Автоматичне надання повного програмного забезпечення на основі політики.
- Постійний моніторинг працездатності периферійної системи
- Можливості керування та надсилання оновлень програмного забезпечення/безпеки/конфігурації в численні периферійні місця — усе з центрального хмарного розташування для керування протягом другого дня.
Розподілену архітектуру «хаб-і-шпиль» можна використовувати для масштабування корпоративного розгортання штучного інтелекту на периферії, де центральна хмара або корпоративний центр обробки даних діє як концентратор, а пристрій «край у коробці» діє як «спиця» на межі.. Ця модель концентратора та спіці, яка поширюється на гібридні хмарні та периферійні середовища, найкраще ілюструє баланс, необхідний для оптимального використання ресурсів, необхідних для роботи FM (див. рис. 2).
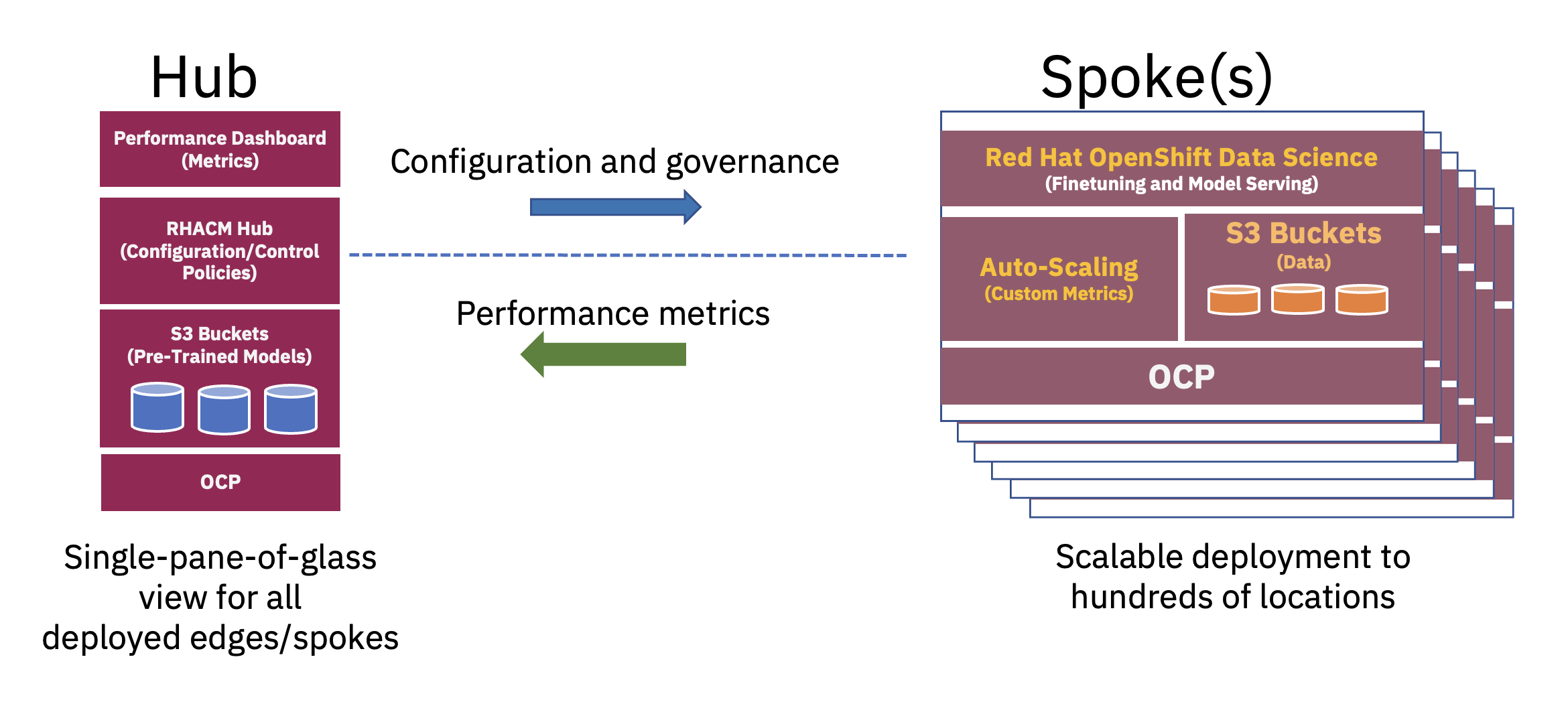
Попереднє навчання цих базових великих мовних моделей (LLM) та інших типів базових моделей з використанням самоконтрольованих методів на величезних наборах даних без міток часто потребує значних обчислювальних (GPU) ресурсів і найкраще проводити в концентраторі. Практично необмежені обчислювальні ресурси та великі купи даних, які часто зберігаються в хмарі, дозволяють проводити попереднє навчання моделям великих параметрів і постійно підвищувати точність цих базових моделей.
З іншого боку, налаштування цих базових FM для подальших завдань, які вимагають лише кількох десятків чи сотень мічених зразків даних і обслуговування висновків, можна виконати лише за допомогою кількох GPU на межі підприємства. Це дозволяє конфіденційним міченим даним (або корпоративним корпоративним даним) безпечно зберігатися в робочому середовищі підприємства, а також зменшує витрати на передачу даних.
Використовуючи повний стек для розгортання додатків на межі, фахівець із обробки даних може виконувати точне налаштування, тестування та розгортання моделей. Це можна зробити в єдиному середовищі, скорочуючи життєвий цикл розробки для надання нових моделей ШІ кінцевим користувачам. Такі платформи, як Red Hat OpenShift Data Science (RHODS) і нещодавно анонсований Red Hat OpenShift AI, надають інструменти для швидкої розробки та розгортання готових до виробництва моделей ШІ в розподілена хмара і крайові середовища.
Нарешті, обслуговування точно налаштованої моделі ШІ на межі підприємства значно зменшує затримку, яка часто пов’язана із отриманням, передачею, перетворенням і обробкою даних. Відокремлення попереднього навчання в хмарі від тонкого налаштування та логічного висновку на межі знижує загальні операційні витрати за рахунок зменшення необхідного часу та витрат на переміщення даних, пов’язаних із будь-яким завданням логічного висновку (див. рис. 3).
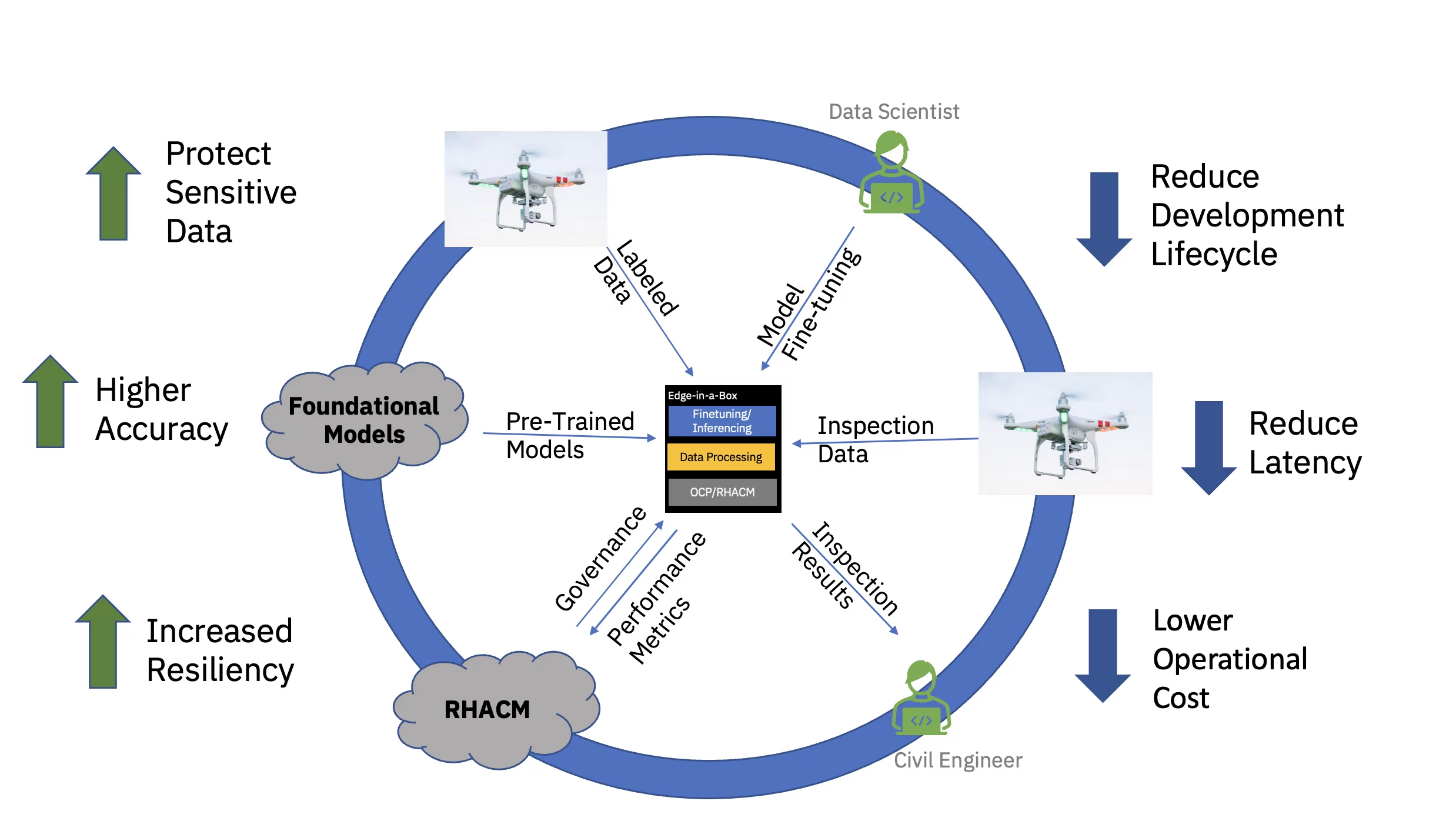
Щоб наскрізно продемонструвати цю ціннісну пропозицію, типову базову модель цивільної інфраструктури на основі трансформатора бачення (попередньо навчену з використанням загальнодоступних і спеціальних галузевих наборів даних) було налаштовано та розгорнуто для висновку на межі з трьома вузлами (спиця) скупчення. Стек програмного забезпечення включав Red Hat OpenShift Container Platform і Red Hat OpenShift Data Science. Цей крайовий кластер також був підключений до примірника Red Hat Advanced Cluster Management for Kubernetes (RHACM), що працює в хмарі.
Ініціалізація без дотику
Ініціалізація на основі правил без дотику була здійснена за допомогою Red Hat Advanced Cluster Management for Kubernetes (RHACM) за допомогою політик і тегів розміщення, які прив’язують конкретні крайові кластери до набору програмних компонентів і конфігурацій. Ці програмні компоненти, які поширюються на весь стек і охоплюють обчислення, сховище, мережу та робоче навантаження AI, були встановлені за допомогою різних операторів OpenShift, надання необхідних служб додатків і S3 Bucket (сховище).
Попередньо підготовлену фундаментальну модель (FM) для цивільної інфраструктури було налаштовано за допомогою Jupyter Notebook у Red Hat OpenShift Data Science (RHODS) з використанням позначених даних для класифікації шести типів дефектів, виявлених на бетонних мостах. Обслуговування цього точно налаштованого FM також було продемонстровано за допомогою сервера Triton. Крім того, моніторинг працездатності цієї периферійної системи став можливим завдяки агрегації показників спостережуваності з апаратних і програмних компонентів через Prometheus на центральну інформаційну панель RHACM у хмарі. Підприємства цивільної інфраструктури можуть розгортати ці FM на своїх периферійних локаціях і використовувати зображення з дронів для виявлення дефектів майже в режимі реального часу, прискорюючи час до аналізу та знижуючи вартість переміщення великих обсягів даних високої чіткості до та з хмари.
Підсумки
Об'єднання IBM watsonx Можливості платформи даних і штучного інтелекту для базових моделей (FM) із вбудованим пристроєм дозволяють підприємствам запускати робочі навантаження штучного інтелекту для тонкого налаштування FM і висновків на операційній межі. Цей пристрій може обробляти складні сценарії використання з коробки, і він створює інфраструктуру концентратора та спиці для централізованого керування, автоматизації та самообслуговування. Розгортання Edge FM можна скоротити від тижнів до годин із стабільним успіхом, вищою стійкістю та безпекою.
Дізнайтеся більше про базові моделі
Обов’язково ознайомтеся з усіма частинами цієї серії публікацій блогу про периферійні обчислення:
Більше від Cloud




- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.ibm.com/blog/foundational-models-at-the-edge/
- : має
- :є
- : ні
- :де
- $UP
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- МЕНЮ
- прискорювати
- доступ
- виконано
- точність
- придбання
- через
- акти
- пристосований
- Додатково
- адреса
- адреси
- Прийняття
- просунутий
- досягнення
- реклама
- AI
- Прийняття ШІ
- Моделі AI
- Платформа AI
- Aid
- алгоритми
- ВСІ
- дозволяти
- дозволяє
- Також
- Серед
- кількість
- суми
- amp
- an
- аналіз
- аналітика
- та
- оголошений
- будь-який
- де-небудь
- додаток
- застосування
- підхід
- архітектура
- ЕСТЬ
- масив
- стаття
- штучний
- штучний інтелект
- Штучний інтелект (AI)
- AS
- асоційований
- At
- автор
- Автоматизований
- Автоматизація
- доступний
- Проспект
- назад
- Balance
- Банк
- Банки
- база
- BE
- оскільки
- ставати
- становлення
- було
- початок
- буття
- Вірити
- КРАЩЕ
- пов'язувати
- Блог
- Повідомлення в блозі
- блоги
- обидва
- Box
- мости
- Приведення
- Приносить
- широкий
- широко
- Створюємо
- Будує
- побудований
- бізнес
- by
- CAN
- можливості
- капітал
- захопивши
- вуглець
- карта
- Cards
- випадків
- КПП
- категорії
- Викликати
- Центр
- центральний
- Центральний банк
- цифрові валюти центрального банку
- централізована
- ланцюг
- проблеми
- зміна
- заміна
- перевірка
- вибір
- кола
- СНД
- громадянський
- клас
- Класифікувати
- ясно
- клієнтів
- тісно
- хмара
- кластер
- color
- барвистий
- об'єднання
- конкурентоспроможний
- комплекс
- складність
- дотримання
- Компоненти
- обчислення
- обчислення
- конфігурація
- налаштувати
- підключений
- зв'язок
- складається
- Контейнер
- продовжувати
- контроль
- Коштувати
- витрати
- може
- покриття
- криптовалюта
- CSS
- валюти
- виготовлений на замовлення
- клієнт
- Досвід клієнтів
- Клієнти
- приладова панель
- дані
- Центр обробки даних
- Платформа даних
- наука про дані
- вчений даних
- набори даних
- Дата
- присвячених
- дефолт
- Визначення
- доставляти
- демонструвати
- продемонстрований
- розгортання
- розгорнути
- розгортання
- розгортання
- розгортання
- описаний
- description
- призначений
- розвивати
- розвиненою
- розробка
- цифровий
- цифрові валюти
- оцифрування
- Зрив
- руйнівний
- Руйнівники
- розподілений
- район
- домен
- домени
- зроблений
- управляти
- водіння
- трутень
- кожен
- легко
- екосистема
- край
- краю обчислень
- ПОВЕРНЕНО
- піднесений
- включіть
- дозволяє
- кінець
- кінець в кінець
- інженер
- Машинобудування
- Що натомість? Створіть віртуальну версію себе у
- підприємство
- підприємств
- що входить
- Навколишнє середовище
- середовищах
- Епоха
- особливо
- і т.д.
- Ефір (ETH)
- Навіть
- Події
- Кожен
- еволюціонували
- Вивчення
- Приклади
- виконувати
- існувати
- вихід
- дорогий
- досвід
- experts
- Пояснюваний ШІ
- пояснюючи
- розширення
- надзвичайно
- фактори
- ШВИДКО
- швидше
- кілька
- поле
- Рисунок
- фінансовий
- Фінансові установи
- фінансування
- Перший
- поверхи
- стежити
- після
- Шрифти
- для
- передній край
- знайдений
- фонд
- фракція
- Рамки
- від
- Повний
- Повний стек
- Крім того
- в цілому
- генерується
- generator
- географічні
- Геополітика
- дає
- Глобальний
- світової торгівлі
- управління
- GPU
- Графічні процесори
- сітка
- рука
- обробляти
- апаратні засоби
- hat
- Мати
- здоров'я
- висота
- допомога
- допомогу
- допомагає
- висока роздільна здатність
- вище
- дуже
- історія
- господар
- ГОДИННИК
- Як
- How To
- Однак
- HTTPS
- Концентратор
- Людей
- Сотні
- гібрид
- гібридна хмара
- IBM
- IBM Cloud
- ICO
- ICON
- ілюструє
- зображення
- Impact
- значення
- поліпшення
- in
- включати
- включені
- зростаючий
- все більше і більше
- індекс
- промислові
- промисловості
- промисловість
- галузевий
- інфляція
- Перегин
- Точка перегину
- під впливом
- Інфраструктура
- Ініціатива
- інновація
- інноваційний
- витрати
- розуміння
- екземпляр
- установи
- інтегрований
- Інтелект
- сутнісний
- введення
- IT
- ІТ-підтримка
- Подорожі
- JPG
- стрибати
- Jupyter Notebook
- просто
- тільки один
- збережений
- ключ
- Кубернетес
- маркування
- мова
- великий
- в значній мірі
- Затримка
- останній
- шарів
- провідний
- УЧИТЬСЯ
- вивчення
- Важіль
- Життєвий цикл
- як
- безмежний
- Linux
- місцевий
- місце дії
- розташування
- місць
- Довго
- подивитися
- машина
- навчання за допомогою машини
- made
- підтримувати
- зробити
- РОБОТИ
- управляти
- управління
- виробництво
- багато
- маркування
- масивний
- майстер
- Матерія
- макс-ширина
- механізми
- методика
- Метрика
- хвилин
- мінімізація
- протокол
- ML
- Mobile
- модель
- Моделі
- сучасний
- модернізація
- модернізувати
- монітор
- моніторинг
- більше
- руху
- переміщення
- ім'я
- навігація
- Близько
- необхідно
- Необхідність
- необхідний
- потреби
- мережу
- Нові
- наступний
- nlp
- ноутбук
- нічого
- зараз
- номер
- численний
- of
- пропонує
- часто
- on
- ONE
- тільки
- відкрити
- відкритий
- оперативний
- операції
- Оператори
- оптимізований
- or
- організація
- Інше
- наші
- з
- загальний
- пакети
- сторінка
- параметр
- оплата
- способи оплати
- платежі
- виконувати
- виконується
- PHP
- розміщення
- платформа
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- підключати
- точка
- Політика
- політика
- положення
- це можливо
- пошта
- Пости
- потенціал
- влада
- потужний
- Прогнози
- попередній
- недоторканність приватного життя
- приватний
- проблеми
- обробка
- виробляти
- професійний
- пропозиція
- забезпечувати
- громадськість
- Штовхати
- діапазон
- швидко
- читання
- реального часу
- нещодавно
- запис
- запис
- червоний
- Red Hat
- зменшити
- Знижений
- знижує
- зниження
- правила
- Регулятори
- регуляторні
- пов'язаний
- Вилучено
- повторюваний
- вимагати
- вимагається
- Вимога
- необхідний
- дослідження
- ресурси
- відповідь
- відповідальний
- реагувати
- роздрібна торгівля
- Зростання
- роботи
- прогін
- біг
- безпечно
- то ж
- масштабованість
- шкала
- масштаб ai
- Масштабування
- наука
- вчений
- Екран
- scripts
- другий
- безпечно
- безпеку
- побачити
- бачачи
- вибір
- Самообслуговування
- чутливий
- пошукова оптимізація
- Вересень
- Серія
- сервер
- обслуговування
- Послуги
- виступаючої
- Сесія
- сесіях
- комплект
- кілька
- Поділитись
- Показувати
- значний
- істотно
- аналогічний
- з
- Сінгапур
- один
- єдине середовище
- сайт
- сайти
- SIX
- навички
- невеликий
- EMS
- МСП
- Софтвер
- програмні компоненти
- рішення
- суверенітет
- Простір
- напруга
- конкретний
- конкретно
- Рекламні
- стек
- старт
- впроваджений
- залишатися
- заходи
- зберігання
- зберігати
- зберігати
- магазинів
- буря
- студія
- тема
- успіх
- такі
- Запропонує
- поставка
- ланцюжка поставок
- підтримка
- Переконайтеся
- система
- Приймати
- прийняті
- Завдання
- завдання
- методи
- Технологія
- Telco
- Temenos
- тензор
- Terraform
- перевірений
- Тестування
- Що
- Команда
- їх
- тема
- Там.
- Ці
- вони
- це
- через
- час
- своєчасно
- times
- назва
- до
- сьогодні
- разом
- Інструментарій
- інструменти
- топ
- торгувати
- традиційний
- поїзд
- навчений
- Навчання
- переклад
- Перетворення
- Перетворення
- перетворень
- прозорий
- Triton
- два
- тип
- Типи
- розв’язаний
- Оновити
- Updates
- URL
- us
- використання
- використовуваний
- користувачі
- використання
- використовувати
- використовувати
- Цінний
- значення
- ціннісне пропозицію
- різноманітність
- різний
- величезний
- через
- вид
- фактично
- обсяг
- Обсяги
- W
- Очікування
- Wallet
- було
- хвиля
- шлях..
- способи
- we
- week
- тижня
- Що
- Що таке
- коли
- який
- в той час як
- ВООЗ
- чому
- широкий
- Широкий діапазон
- з
- в
- жінка
- WordPress
- Work
- Робочі процеси
- робочий
- б
- письмовий
- вашу
- зефірнет











