Амазонська червона зміна це повністю кероване хмарне сховище даних розміром у петабайти, яке використовується десятками тисяч клієнтів для обробки ексабайтів даних щодня, щоб збільшити навантаження на аналітику. Ви можете структурувати свої дані, вимірювати бізнес-процеси та швидко отримувати цінну інформацію за допомогою розмірної моделі. Amazon Redshift надає вбудовані функції для прискорення процесу моделювання, оркестрування та створення звітів із багатовимірної моделі.
У цій публікації ми обговорюємо, як реалізувати розмірну модель, зокрема Методика Кімбола. Ми обговорюємо впровадження параметрів і фактів у Amazon Redshift. Ми показуємо, як виконати вилучення, перетворення та завантаження (ELT), процес інтеграції, зосереджений на передачі необроблених даних із озера даних у проміжний рівень для виконання моделювання. Загалом, публікація дасть вам чітке розуміння того, як використовувати розмірне моделювання в Amazon Redshift.
Огляд рішення
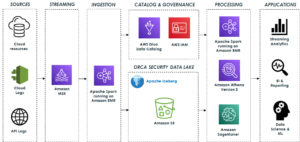
Наступна діаграма ілюструє архітектуру рішення.

У наступних розділах ми спочатку обговорюємо та демонструємо ключові аспекти розмірної моделі. Після цього ми створюємо вітрину даних за допомогою Amazon Redshift із розмірною моделлю даних, включаючи таблиці розмірів і фактів. Дані завантажуються та розподіляються за допомогою КОПІЯ дані в розмірах завантажуються за допомогою ВЕЛИКИЙ твердження, і факти будуть приєднані до вимірів, з яких випливають ідеї. Ми плануємо завантаження розмірів і фактів за допомогою Редактор запитів Amazon Redshift V2. Нарешті, ми використовуємо Amazon QuickSight щоб отримати уявлення про змодельовані дані у формі інформаційної панелі QuickSight.
Для цього рішення ми використовуємо зразок набору даних (нормалізований), наданий Amazon Redshift для продажу квитків на події. Для цієї публікації ми звузили набір даних для простоти та демонстрації. У наступних таблицях наведено приклади даних про продаж квитків і місця проведення.


Згідно зі Методологія розмірного моделювання Кімболає чотири ключові етапи розробки розмірної моделі:
- Визначте бізнес-процес.
- Оголошення зерна ваших даних.
- Визначте та застосуйте розміри.
- Визначте та запровадьте факти.
Крім того, ми додаємо п’ятий крок для демонстрації, який полягає у звітуванні та аналізі бізнес-подій.
Передумови
Для цього покрокового керівництва ви повинні мати такі передумови:
Визначте бізнес-процес
Простіше кажучи, ідентифікація бізнес-процесу означає ідентифікацію вимірної події, яка генерує дані в організації. Зазвичай компанії мають якусь операційну вихідну систему, яка генерує їхні дані у необробленому форматі. Це хороша відправна точка для визначення різних джерел для бізнес-процесу.
Потім бізнес-процес зберігається як a март даних у формі вимірів і фактів. Дивлячись на наш зразковий набір даних, згаданий раніше, ми можемо чітко побачити бізнес-процес — це продажі, здійснені для певної події.
Поширеною помилкою є використання відділів компанії як бізнес-процесу. Дані (бізнес-процес) потрібно інтегрувати між різними відділами, у цьому випадку маркетинг може отримати доступ до даних про продажі. Визначення правильного бізнес-процесу є критично важливим — неправильне виконання цього кроку може вплинути на всю вітрину даних (це може призвести до дублювання зерна та неправильних показників у остаточних звітах).
Оголошення зерна ваших даних
Оголошення зерна — це дія унікальної ідентифікації запису у вашому джерелі даних. Зернистість використовується в таблиці фактів, щоб точно виміряти дані та дозволити вам згортати їх далі. У нашому прикладі це може бути позиція в бізнес-процесі продажів.
У нашому випадку використання продаж можна однозначно ідентифікувати, дивлячись на час транзакції, коли відбувся продаж; це буде найбільш атомарний рівень.

Визначте та застосуйте розміри
Таблиця розмірів описує таблицю фактів і її атрибути. Визначаючи описовий контекст вашого бізнес-процесу, ви зберігаєте текст в окремій таблиці, пам’ятаючи про зернистість таблиці фактів. Під час приєднання таблиці розмірів до таблиці фактів має бути лише один рядок, пов’язаний із таблицею фактів. У нашому прикладі ми використовуємо наступну таблицю, щоб розділити її на таблицю розмірів; ці поля описують факти, які ми вимірюватимемо.
Під час проектування структури розмірної моделі (схеми) ви можете або створити a зірка or сніжинка схема. Структура повинна тісно відповідати бізнес-процесу; отже, зіркова схема найкраще підходить для нашого прикладу. На наступному малюнку показано нашу діаграму зв’язків сутностей (ERD).

У наступних розділах ми детально описуємо кроки для впровадження розмірів.
Сценалізуйте вихідні дані
Перш ніж ми зможемо створити та завантажити таблицю розмірів, нам потрібні вихідні дані. Тому ми розподіляємо вихідні дані в проміжну або тимчасову таблицю. Це часто називають постановочний шар, яка є необробленою копією вихідних даних. Для цього в Amazon Redshift ми використовуємо Команда COPY щоб завантажити дані з публічного відра S3 dimensional-modeling-in-amazon-redshift, розташованого на us-east-1 Регіон. Зверніть увагу, що команда COPY використовує Управління ідентифікацією та доступом AWS (ІАМ) роль с доступ до Amazon S3. Роль повинна бути пов'язані з кластером. Виконайте наведені нижче дії, щоб підготувати вихідні дані:
- створіть
venueвихідна таблиця:
- Завантажте дані про місце проведення:
- створіть
salesвихідна таблиця:
- Завантажте вихідні дані про продажі:
- створіть
calendarстіл:
- Завантажте дані календаря:
Створіть таблицю розмірів
Розробка таблиці розмірів може залежати від ваших бізнес-вимог — наприклад, чи потрібно вам відстежувати зміни даних з часом? Є сім різних типів розмірів. Для нашого прикладу ми використовуємо Тип 1 оскільки нам не потрібно відстежувати історичні зміни. Додаткову інформацію про тип 2 див Спростіть завантаження даних у повільно змінювані розміри типу 2 в Amazon Redshift. Таблицю розмірів буде денормализовано за допомогою первинного ключа, сурогатного ключа та кількох доданих полів для позначення змін у таблиці. Перегляньте наступний код:
Кілька зауважень щодо створення таблиці розмірів:
- Назви полів перетворюються на зручні для бізнесу назви
- Наш первинний ключ
VenueID, який ми використовуємо для унікальної ідентифікації місця, де відбувся продаж - Буде додано два додаткові рядки, що вказують, коли запис було вставлено та оновлено (для відстеження змін)
- Ми використовуємо Стиль розповсюдження AUTO щоб передати Amazon Redshift відповідальність за вибір і коригування стилю розповсюдження
Ще один важливий фактор, який слід враховувати при розмірному моделюванні, - це використання сурогатні ключі. Сурогатні ключі — це штучні ключі, які використовуються в розмірному моделюванні для унікальної ідентифікації кожного запису в таблиці розмірностей. Зазвичай вони генеруються як послідовне ціле число, і вони не мають жодного значення в бізнес-доміні. Вони пропонують кілька переваг, як-от забезпечення унікальності та підвищення продуктивності в об’єднаннях, оскільки зазвичай вони менші за природні ключі, і як сурогатні ключі вони не змінюються з часом. Це дозволяє нам бути послідовними та легше поєднувати факти та розміри.
В Amazon Redshift сурогатні ключі зазвичай створюються за допомогою ключового слова IDENTITY. Наприклад, попередній оператор CREATE створює таблицю розмірів з a VenueSkey сурогатний ключ. The VenueSkey стовпець автоматично заповнюється унікальними значеннями, коли до таблиці додаються нові рядки. Потім цей стовпець можна використовувати для приєднання таблиці місця проведення до FactSaleTransactions таблиці.
Кілька порад щодо створення сурогатних ключів:
- Використовуйте невеликий тип даних із фіксованою шириною для сурогатного ключа. Це покращить продуктивність і зменшить простір для зберігання.
- Використовуйте ключове слово IDENTITY або згенеруйте сурогатний ключ за допомогою послідовного значення або значення GUID. Це гарантує, що сурогатний ключ є унікальним і не може бути змінений.
Завантажте таблицю dim за допомогою MERGE
Є багато способів завантажити ваш dim table. Необхідно враховувати певні фактори, наприклад, продуктивність, обсяг даних і, можливо, час завантаження за угодою про рівень обслуговування. З ВЕЛИКИЙ ми виконуємо upsert без необхідності вказувати кілька команд вставки та оновлення. Ви можете налаштувати ВЕЛИКИЙ заява в а збережена процедура для заповнення даних. Потім ви плануєте програмний запуск збереженої процедури за допомогою редактора запитів, який ми продемонструємо далі в статті. Наступний код створює збережену процедуру під назвою SalesMart.DimVenueLoad:
Кілька зауважень щодо завантаження розмірів:
- Коли запис вставляється вперше, буде заповнено вставлену дату та оновлену дату. Коли будь-які значення змінюються, дані оновлюються, а оновлена дата відображає дату зміни. Вставлена дата залишається.
- Оскільки дані використовуватимуться бізнес-користувачами, нам потрібно замінити значення NULL, якщо такі є, на більш відповідні для бізнесу значення.
Визначте та запровадьте факти
Тепер, коли ми оголосили наше зерно як подію продажу, що відбулася в певний час, наша таблиця фактів зберігатиме числові факти для нашого бізнес-процесу.
Ми визначили такі чисельні факти для вимірювання:
- Кількість проданих квитків за один продаж
- Комісія за продаж
Реалізація факту
Існує три типи таблиць фактів (таблиця фактів транзакцій, періодична таблиця фактів знімків і накопичувальна таблиця фактів знімків). Кожен з них надає різний погляд на бізнес-процес. Для нашого прикладу ми використовуємо таблицю фактів транзакцій. Виконайте наступні дії:
- Створіть таблицю фактів
Додається вставлена дата зі значенням за замовчуванням, яка вказує, чи було завантажено запис і коли він був завантажений. Ви можете використовувати це під час перезавантаження таблиці фактів, щоб видалити вже завантажені дані, щоб уникнути дублікатів.
Завантаження таблиці фактів складається з простого оператора вставки, який об’єднує ваші пов’язані розміри. Приєднуємося від DimVenue створена таблиця, яка описує наші факти. Це найкраща практика, але необов’язкова календарна дата розміри, які дозволяють кінцевому користувачеві орієнтуватися в таблиці фактів. Дані можуть завантажуватися під час нового продажу або щодня; тут стане в нагоді вставлена дата або дата завантаження.
Ми завантажуємо таблицю фактів за допомогою збереженої процедури та використовуємо параметр дати.
- Створіть збережену процедуру за допомогою наступного коду. Щоб зберегти ту саму цілісність даних, яку ми застосували під час завантаження вимірів, ми замінюємо значення NULL, якщо такі є, на більш прийнятні для бізнесу значення:
- Завантажте дані, викликавши процедуру за допомогою такої команди:
Заплануйте завантаження даних
Тепер ми можемо автоматизувати процес моделювання, плануючи збережені процедури в Amazon Redshift Query Editor V2. Виконайте наступні дії:
- Спочатку ми викликаємо завантаження розміру, а після успішного виконання завантаження розміру починається завантаження факту:
Якщо завантаження розміру не вдасться, завантаження факту не запуститься. Це забезпечує узгодженість даних, оскільки ми не хочемо завантажувати таблицю фактів застарілими параметрами.
- Щоб запланувати завантаження, виберіть Розклад у редакторі запитів V2.

- Ми плануємо виконання запиту щодня о 5:00 ранку.
- За бажанням ви можете додати сповіщення про помилки, увімкнувши Служба простих сповіщень Amazon (Amazon SNS) сповіщення.

Звітуйте та аналізуйте дані в Amazon Quicksight
QuickSight — це служба бізнес-аналітики, яка спрощує надання інформації. Будучи повністю керованою службою, QuickSight дозволяє легко створювати та публікувати інтерактивні інформаційні панелі, доступ до яких можна отримати з будь-якого пристрою та вбудовувати у ваші програми, портали та веб-сайти.
Ми використовуємо наш вітрин даних, щоб візуально представити факти у формі інформаційної панелі. Щоб розпочати роботу та налаштувати QuickSight, див Створення набору даних за допомогою бази даних, яка не виявляється автоматично.
Після створення джерела даних у QuickSight ми об’єднуємо змодельовані дані (вітрину даних) на основі нашого сурогатного ключа skey. Ми використовуємо цей набір даних для візуалізації вітрини даних.

Наша кінцева інформаційна панель міститиме статистику вітрини даних і відповідатиме на важливі бізнес-запитання, такі як загальна комісія на місце та дати з найвищими продажами. На наступному знімку екрана показано кінцевий продукт вітрини даних.

Прибирати
Щоб уникнути майбутніх витрат, видаліть усі ресурси, створені вами в рамках цієї публікації.
Висновок
Зараз ми успішно впровадили вітрину даних за допомогою нашого DimVenue, DimCalendar та FactSaleTransactions таблиці. Наш склад не повний; оскільки ми можемо розширити вітрину даних за допомогою більшої кількості фактів і запровадити більше вітрин, а оскільки бізнес-процеси та вимоги з часом зростатимуть, то й сховище даних зростатиме. У цій публікації ми надали комплексний погляд на розуміння та впровадження розмірного моделювання в Amazon Redshift.
Почніть роботу зі своїм Амазонська червона зміна габаритна модель сьогодні.
Про авторів
 Бернард Верстер є досвідченим хмарним інженером із багаторічним досвідом у створенні масштабованих та ефективних моделей даних, визначенні стратегій інтеграції даних і забезпеченні управління даними та безпеки. Він захоплений використанням даних для формування розуміння, узгоджуючи його з вимогами та цілями бізнесу.
Бернард Верстер є досвідченим хмарним інженером із багаторічним досвідом у створенні масштабованих та ефективних моделей даних, визначенні стратегій інтеграції даних і забезпеченні управління даними та безпеки. Він захоплений використанням даних для формування розуміння, узгоджуючи його з вимогами та цілями бізнесу.
 Абхішек Пан є спеціалістом WWSO SA-Analytics, який працює з клієнтами AWS India у державному секторі. Він взаємодіє з клієнтами, щоб визначити стратегію на основі даних, провести глибокі сеанси аналізу випадків використання аналітики та розробити масштабовані та ефективні аналітичні програми. Він має 12 років досвіду та захоплюється базами даних, аналітикою та AI/ML. Він завзятий мандрівник і намагається зафіксувати світ через об’єктив фотоапарата.
Абхішек Пан є спеціалістом WWSO SA-Analytics, який працює з клієнтами AWS India у державному секторі. Він взаємодіє з клієнтами, щоб визначити стратегію на основі даних, провести глибокі сеанси аналізу випадків використання аналітики та розробити масштабовані та ефективні аналітичні програми. Він має 12 років досвіду та захоплюється базами даних, аналітикою та AI/ML. Він завзятий мандрівник і намагається зафіксувати світ через об’єктив фотоапарата.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. Автомобільні / електромобілі, вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- BlockOffsets. Модернізація екологічної компенсаційної власності. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- : має
- :є
- : ні
- :де
- $UP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- МЕНЮ
- прискорювати
- доступ
- доступний
- точно
- через
- Діяти
- додавати
- доданий
- Додатковий
- після
- AI / ML
- вирівнювати
- вирівнювання
- дозволяти
- дозволяє
- вже
- am
- Amazon
- Amazon Web Services
- an
- аналіз
- Аналітичний
- аналітика
- аналізувати
- та
- відповідь
- будь-який
- застосування
- прикладної
- відповідний
- архітектура
- ЕСТЬ
- штучний
- AS
- аспекти
- асоційований
- At
- Атрибути
- автоматичний
- автоматизувати
- автоматично
- уникнути
- AWS
- b
- заснований
- BE
- оскільки
- починати
- Переваги
- КРАЩЕ
- вбудований
- бізнес
- бізнес-аналітика
- Бізнес-процес
- ділові процеси
- але
- by
- Календар
- call
- званий
- покликання
- кімната
- CAN
- захоплення
- випадок
- випадків
- Викликати
- певний
- зміна
- змінилися
- Зміни
- заміна
- характер
- вантажі
- Вибирати
- ясно
- очевидно
- тісно
- хмара
- код
- Колонка
- приходить
- комісія
- загальний
- Компанії
- компанія
- повний
- Вважати
- послідовний
- складається
- контекст
- виправити
- може
- створювати
- створений
- створює
- створення
- створення
- критичний
- Клієнти
- щодня
- приладова панель
- інформаційні панелі
- дані
- інтеграція даних
- Озеро даних
- сховище даних
- керовані даними
- Стратегія, керована даними
- Database
- базами даних
- Дата
- Дати
- дата, час
- день
- глибокий
- глибоке занурення
- дефолт
- визначаючи
- доставляти
- демонструвати
- відомства
- Отриманий
- описувати
- дизайн
- проектування
- деталь
- пристрій
- різний
- Розмір
- розміри
- обговорювати
- чіткий
- розподіл
- do
- домен
- зроблений
- Не знаю
- вниз
- управляти
- дублікати
- кожен
- Раніше
- легко
- легко
- редактор
- ефективний
- або
- вбудований
- включіть
- дозволяє
- кінець
- кінець в кінець
- займається
- інженер
- забезпечувати
- гарантує
- забезпечення
- Весь
- суб'єкта
- Ефір (ETH)
- Event
- Події
- Кожен
- кожен день
- приклад
- Приклади
- Розширювати
- досвід
- досвідчений
- експонування
- витяг
- факт
- фактор
- фактори
- Факти
- зазнає невдачі
- Провал
- риси
- кілька
- поле
- Поля
- п'ятий
- Рисунок
- фільтрувати
- остаточний
- Перший
- перший раз
- відповідати
- увагу
- після
- для
- форма
- формат
- чотири
- від
- повністю
- далі
- майбутнє
- Отримувати
- породжувати
- генерується
- генерує
- отримати
- отримання
- Давати
- даний
- добре
- управління
- Рости
- мобільний
- Мати
- he
- найвищий
- його
- історичний
- свято
- Як
- How To
- HTML
- HTTP
- HTTPS
- IAM
- ідентифікований
- ідентифікувати
- ідентифікує
- Особистість
- if
- ілюструє
- Impact
- здійснювати
- реалізовані
- реалізації
- важливо
- удосконалювати
- поліпшення
- in
- У тому числі
- Індію
- вказувати
- вказуючи
- інформація
- розуміння
- інтегрований
- інтеграція
- цілісність
- Інтелект
- інтерактивний
- в
- IT
- ЙОГО
- приєднатися
- приєднався
- приєднання
- з'єднання
- JPG
- тримати
- зберігання
- ключ
- ключі
- озеро
- мова
- пізніше
- останній
- шар
- залишити
- об'єктив
- дозволяє
- рівень
- Лінія
- загрузка
- погрузка
- вантажі
- розташований
- шукати
- made
- РОБОТИ
- вдалося
- Маркетинг
- відповідає
- сенс
- вимір
- згаданий
- Злиття
- Метрика
- mind
- помилка
- модель
- моделювання
- моделювання
- Моделі
- місяць
- більше
- найбільш
- множинний
- Імена
- Природний
- Переміщення
- Необхідність
- нужденних
- потреби
- Нові
- примітки
- сповіщення
- Повідомлення
- зараз
- численний
- цілей
- of
- пропонувати
- часто
- on
- тільки
- оперативний
- or
- організація
- наші
- над
- загальний
- параметр
- частина
- пристрасний
- для
- виконувати
- продуктивність
- може бути
- періодичний
- місце
- plato
- Інформація про дані Платона
- PlatoData
- точка
- заселений
- пошта
- влада
- практика
- передумови
- представити
- первинний
- процедура
- Процедури
- процес
- процеси
- Product
- забезпечувати
- за умови
- забезпечує
- громадськість
- публікувати
- цілей
- питань
- швидко
- підвищення
- Сировина
- необроблені дані
- запис
- облік
- зменшити
- називають
- Відображає
- регіон
- відносини
- залишається
- видаляти
- замінювати
- звітом
- Звітність
- Звіти
- Вимога
- ресурси
- відповідальність
- Роль
- Котити
- ROW
- прогін
- пробіжки
- sale
- продажів
- то ж
- Зразок набору даних
- масштабовані
- розклад
- планування
- розділам
- сектор
- безпеку
- побачити
- окремий
- служить
- обслуговування
- Послуги
- сесіях
- комплект
- кілька
- Повинен
- Показувати
- Шоу
- простий
- простота
- один
- Повільно
- невеликий
- менше
- Знімок
- So
- проданий
- рішення
- деякі
- Source
- Джерела
- Простір
- спеціаліст
- конкретний
- конкретно
- Стажування
- інсценування
- Star
- почалася
- Починаючи
- Заява
- Крок
- заходи
- зберігання
- зберігати
- зберігати
- стратегії
- Стратегія
- структура
- успішний
- Успішно
- такі
- система
- таблиця
- тимчасовий
- тензор
- terms
- ніж
- Що
- Команда
- Джерело
- світ
- їх
- потім
- Там.
- отже
- Ці
- вони
- це
- тисячі
- через
- квиток
- продаж квитків
- квитки
- час
- times
- відмітка часу
- Поради
- до
- сьогодні
- разом
- прийняли
- Усього:
- трек
- угода
- Перетворення
- перетворений
- мандрівник
- тип
- Типи
- типово
- розуміння
- створеного
- однозначно
- унікальність
- невідомий
- Оновити
- оновлений
- us
- Використання
- використання
- використання випадку
- використовуваний
- користувачі
- використовує
- використання
- зазвичай
- Цінний
- значення
- Цінності
- різний
- Місце зустрічі
- місця проведення
- через
- вид
- обсяг
- покрокове керівництво
- хотіти
- Склад
- було
- способи
- we
- Web
- веб-сервіси
- веб-сайти
- week
- коли
- який
- в той час як
- волі
- з
- в
- без
- робочий
- світ
- Неправильно
- рік
- років
- ви
- вашу
- зефірнет