Це спільний допис, написаний спільно AWS і Voxel51. Voxel51 — це компанія, що стоїть за FiftyOne, набором інструментів із відкритим кодом для створення високоякісних наборів даних і моделей комп’ютерного зору.
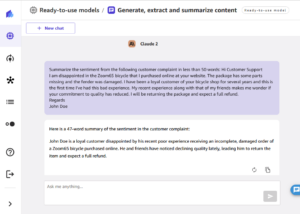
Роздрібна компанія створює мобільний додаток, щоб допомогти клієнтам купувати одяг. Щоб створити цю програму, їм потрібен високоякісний набір даних із зображеннями одягу, позначених різними категоріями. У цій публікації ми покажемо, як змінити призначення існуючого набору даних за допомогою очищення даних, попередньої обробки та попереднього маркування за допомогою моделі класифікації з нульовим випадком у П'ятьдесят-одині коригування цих міток за допомогою Основна правда Amazon SageMaker.
Ви можете використовувати Ground Truth і FiftyOne, щоб прискорити свій проект маркування даних. Ми показуємо, як бездоганно використовувати обидві програми разом для створення високоякісних мічених наборів даних. Для нашого прикладу використання ми працюємо з Набір даних Fashion200K, випущений на ICCV 2017.
Огляд рішення
Ground Truth — це повністю самообслуговувана та керована служба маркування даних, яка дає змогу спеціалістам з обробки даних, інженерам машинного навчання (ML) і дослідникам створювати високоякісні набори даних. П'ятьдесят-один by Воксель51 це набір інструментів з відкритим вихідним кодом для курування, візуалізації та оцінки наборів даних комп’ютерного зору, щоб ви могли тренувати та аналізувати кращі моделі, прискорюючи випадки використання.
У наступних розділах ми демонструємо, як зробити наступне:
- Візуалізуйте набір даних у FiftyOne
- Очистіть набір даних за допомогою фільтрації та дедуплікації зображень у FiftyOne
- Попередньо позначте очищені дані класифікацією нульового удару в FiftyOne
- Позначте менший набір даних Ground Truth
- Вставте позначені результати з Ground Truth у FiftyOne та перегляньте позначені результати в FiftyOne
Огляд варіантів використання
Припустімо, ви володієте компанією роздрібної торгівлі та хочете створити мобільну програму, щоб надавати персоналізовані рекомендації, щоб допомогти користувачам вирішити, що одягнути. Ваші потенційні користувачі шукають програму, яка повідомляє їм, які предмети одягу в їхній шафі добре поєднуються. Тут ви бачите можливість: якщо ви можете визначити гарний одяг, ви можете використовувати це, щоб рекомендувати нові предмети одягу, які доповнюють одяг, який клієнт уже має.
Ви хочете максимально спростити роботу кінцевого користувача. В ідеалі, комусь, хто використовує вашу програму, потрібно лише сфотографувати одяг у своєму гардеробі, а ваші моделі ML творять свою магію за лаштунками. Ви можете навчити модель загального призначення або точно налаштувати модель відповідно до унікального стилю кожного користувача за допомогою певної форми зворотного зв’язку.
Однак спочатку вам потрібно визначити, який тип одягу знімає користувач. Це сорочка? Пара штанів? Або щось інше? Зрештою, ви, ймовірно, не захочете рекомендувати вбрання з кількома сукнями чи кількома капелюшками.
Щоб вирішити цю початкову проблему, ви хочете створити навчальний набір даних, що складається із зображень різних предметів одягу з різними візерунками та стилями. Щоб прототипувати з обмеженим бюджетом, ви хочете запустити за допомогою існуючого набору даних.
Щоб проілюструвати та провести вас через процес у цій публікації, ми використовуємо набір даних Fashion200K, опублікований на ICCV 2017. Це встановлений і добре цитований набір даних, але він не підходить безпосередньо для вашого випадку використання.
Хоча предмети одягу позначені категоріями (і підкатегоріями) і містять різноманітні корисні теги, взяті з оригінальних описів продукту, дані не систематично позначаються інформацією про візерунок або стиль. Ваша мета — перетворити цей існуючий набір даних на надійний навчальний набір даних для ваших моделей класифікації одягу. Вам потрібно очистити дані, доповнивши схему маркування мітками стилю. І ви хочете зробити це швидко та з якомога меншими витратами.
Завантажте дані локально
Спочатку завантажте zip-файл women.tar і папку labels (з усіма її вкладеними папками), дотримуючись інструкцій, наданих у Репозиторій набору даних Fashion200K GitHub. Після того, як ви розпакували їх обидва, створіть батьківський каталог fashion200k і перемістіть туди папки з етикетками та жінками. На щастя, ці зображення вже обрізано до обмежувальних рамок виявлення об’єктів, тому ми можемо зосередитися на класифікації, а не турбуватися про виявлення об’єктів.
Незважаючи на «200K» у його назві, жіночий каталог, який ми витягли, містить 338,339 200 зображень. Щоб створити офіційний набір даних Fashion300,000K, автори набору даних просканували понад XNUMX XNUMX продуктів в Інтернеті, і лише ті продукти, описи яких містять більше чотирьох слів, потрапили в розріз. Для наших цілей, де опис продукту не важливий, ми можемо використовувати всі проскановані зображення.
Давайте подивимося, як упорядковано ці дані: у папці «Жінки» зображення впорядковано за типом статті верхнього рівня (спідниці, топи, штани, жакети та сукні) та підкатегорією типу статті (блузки, футболки, з довгими рукавами). вершини).
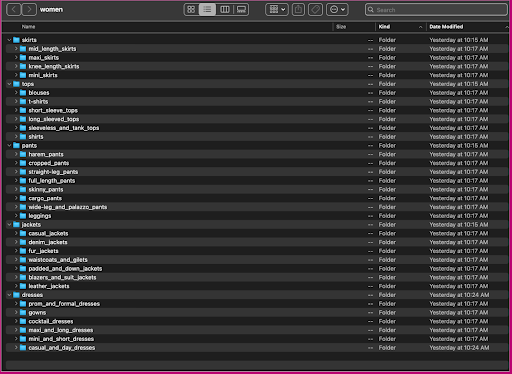
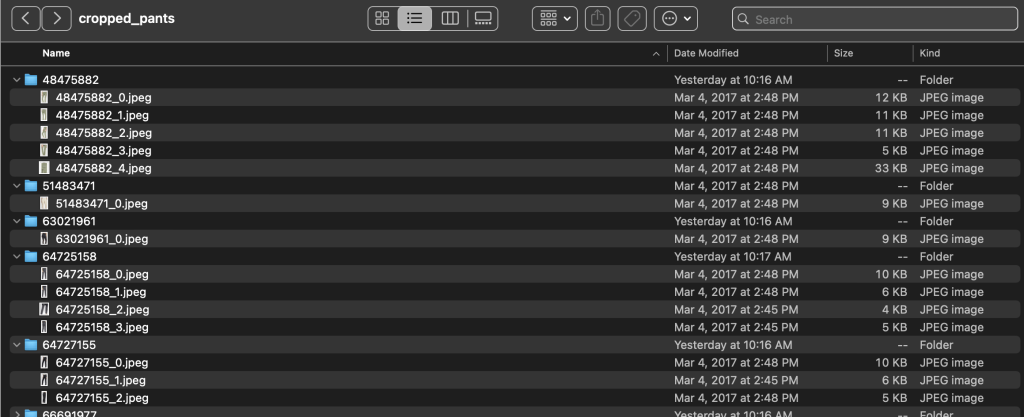
У каталогах підкатегорій є підкаталог для кожного списку продуктів. Кожен із них містить змінну кількість зображень. Підкатегорія cropped_pants, наприклад, містить такі списки продуктів і відповідні зображення.
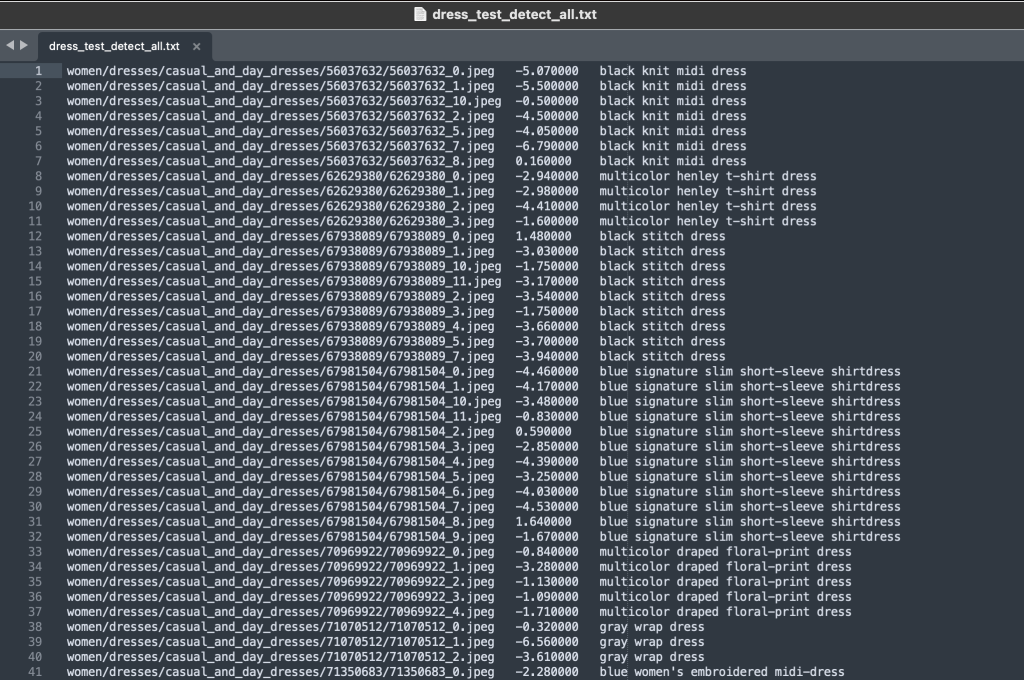
Папка з мітками містить текстовий файл для кожного типу статті верхнього рівня, як для навчання, так і для тестування. У кожному з цих текстових файлів є окремий рядок для кожного зображення, у якому вказується відносний шлях до файлу, оцінка та теги з опису продукту.
Оскільки ми перепрофільовуємо набір даних, ми об’єднуємо всі зображення поїзда та тестування. Ми використовуємо їх для створення високоякісного набору даних для конкретної програми. Після завершення цього процесу ми можемо випадковим чином розділити отриманий набір даних на нові потяги та тести.
Впроваджуйте, переглядайте та керуйте набором даних у FiftyOne
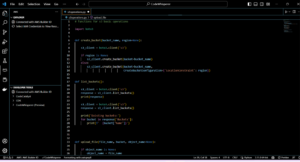
Якщо ви ще цього не зробили, установіть FiftyOne з відкритим кодом за допомогою pip:
Найкраще робити це в новому віртуальному середовищі (venv або conda). Потім імпортуйте відповідні модулі. Імпортуйте базову бібліотеку fiftyone, FiftyOne Brain, яка має вбудовані методи ML, FiftyOne Zoo, з якої ми завантажимо модель, яка генеруватиме для нас мітки нульового знімку, і ViewField, який дозволяє ефективно фільтрувати дані в нашому наборі даних:
Ви також бажаєте імпортувати модулі glob і os Python, які допоможуть нам працювати зі шляхами та збігом шаблонів у вмісті каталогу:
Тепер ми готові завантажити набір даних у FiftyOne. По-перше, ми створюємо набір даних під назвою fashion200k і робимо його постійним, що дозволяє нам зберігати результати інтенсивних обчислювальних операцій, тому нам потрібно обчислити зазначені величини лише один раз.
Тепер ми можемо перебирати всі каталоги підкатегорій, додаючи всі зображення в каталогах продуктів. Ми додаємо мітку класифікації FiftyOne до кожного зразка з ім’ям поля article_type, заповненим категорією статті верхнього рівня зображення. Ми також додаємо інформацію про категорію та підкатегорію як теги:
На цьому етапі ми можемо візуалізувати наш набір даних у програмі FiftyOne, запустивши сеанс:
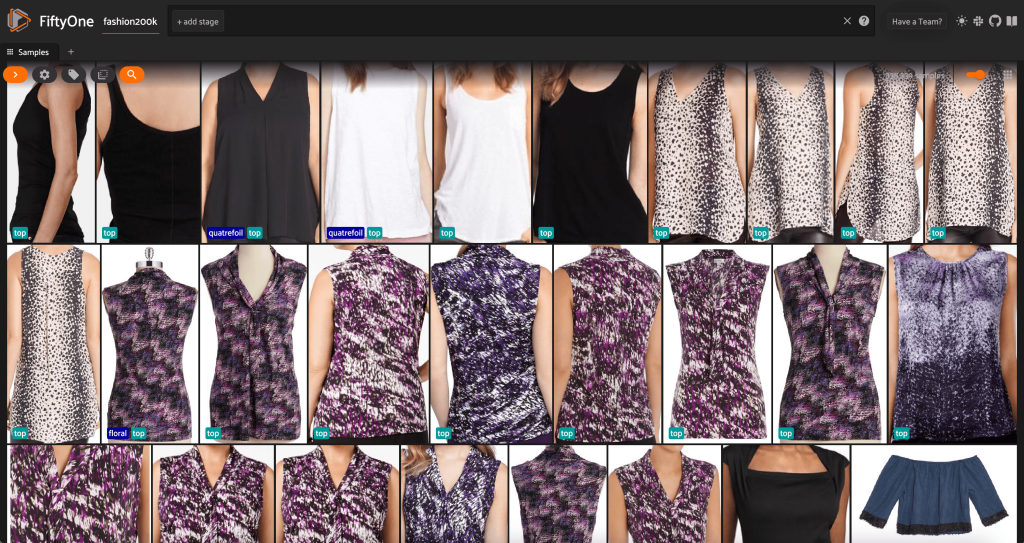
Ми також можемо роздрукувати підсумок набору даних у Python, запустивши print(dataset):
Ми також можемо додати теги з labels каталог зразків у нашому наборі даних:
Переглядаючи дані, стає зрозуміло кілька речей:
- Деякі зображення досить зернисті з низькою роздільною здатністю. Ймовірно, це пов’язано з тим, що ці зображення були створені шляхом обрізання початкових зображень у обмежувальних рамках виявлення об’єктів.
- Деякий одяг одягнена на людину, а дещо фотографується самостійно. Ці деталі інкапсульовані
viewpointвласність - Багато зображень того самого продукту дуже схожі, тому, принаймні спочатку, додавання кількох зображень для кожного продукту може не додати значної передбачуваної сили. Здебільшого перше зображення кожного продукту (закінчується на
_0.jpeg) є найчистішим.
Спочатку ми можемо захотіти навчити нашу модель класифікації стилю одягу на контрольованій підмножині цих зображень. З цією метою ми використовуємо зображення наших продуктів із високою роздільною здатністю та обмежуємо перегляд одним репрезентативним зразком для кожного продукту.
Спочатку ми відфільтровуємо зображення з низькою роздільною здатністю. Ми використовуємо compute_metadata() метод для обчислення та збереження ширини та висоти зображення в пікселях для кожного зображення в наборі даних. Потім ми використовуємо FiftyOne ViewField щоб відфільтрувати зображення на основі мінімально дозволених значень ширини та висоти. Перегляньте наступний код:
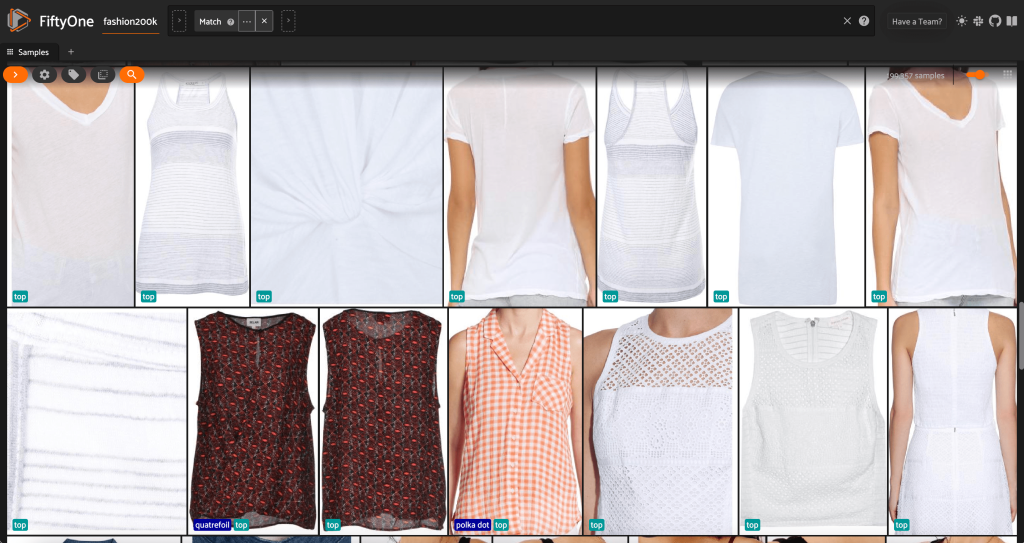
Ця підмножина високої роздільної здатності містить трохи менше 200,000 XNUMX зразків.
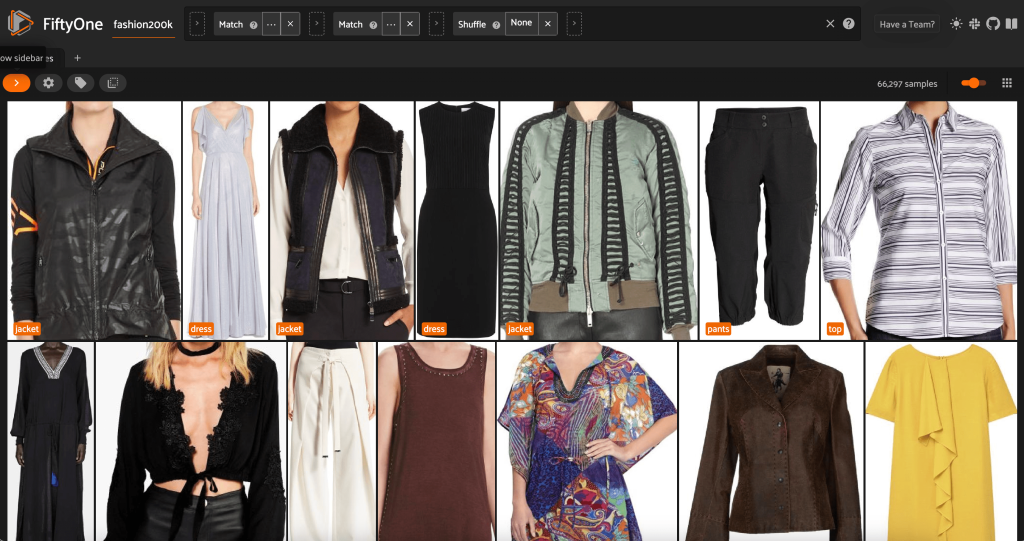
З цього подання ми можемо створити нове подання в нашому наборі даних, що містить лише один репрезентативний зразок (не більше) для кожного продукту. Ми використовуємо ViewField ще раз, зіставлення шаблонів для шляхів файлів, які закінчуються на _0.jpeg:
Давайте переглянемо випадково перетасований порядок зображень у цій підмножині:
Видаліть зайві зображення в наборі даних
Цей перегляд містить 66,297 19 зображень, або трохи більше XNUMX% вихідного набору даних. Однак, коли ми дивимося на вигляд, ми бачимо, що є багато дуже схожих продуктів. Зберігання всіх цих копій, ймовірно, лише збільшить витрати на наше маркування та навчання моделі, без помітного покращення продуктивності. Натомість давайте позбудемося майже дублікатів, щоб створити менший набір даних, який все ще має таку саму потужність.
Оскільки ці зображення не є точними дублікатами, ми не можемо перевірити піксельну рівність. На щастя, ми можемо використовувати FiftyOne Brain, щоб допомогти нам очистити наш набір даних. Зокрема, ми обчислимо вбудовування для кожного зображення — вектор нижчої розмірності, що представляє зображення, — а потім шукатимемо зображення, вектори вбудовування яких близькі один до одного. Чим ближче вектори, тим більше схожі зображення.
Ми використовуємо модель CLIP для створення 512-вимірного вектора вбудовування для кожного зображення та зберігаємо ці вбудовування в полях вбудовування на зразках у нашому наборі даних:
Потім ми обчислюємо близькість між вкладеннями, використовуючи косинусова подібність, і стверджувати, що будь-які два вектори, схожість яких перевищує певний поріг, ймовірно, будуть майже дублікатами. Оцінки косинусної подібності знаходяться в діапазоні [0, 1], і, дивлячись на дані, пороговий показник thresh=0.5 здається приблизно правильним. Знову ж таки, це не має бути ідеальним. Кілька майже повторюваних зображень навряд чи знищать нашу передбачувану здатність, а викидання кількох недубльованих зображень суттєво не вплине на продуктивність моделі.
Ми можемо переглянути ймовірні дублікати, щоб переконатися, що вони справді зайві:
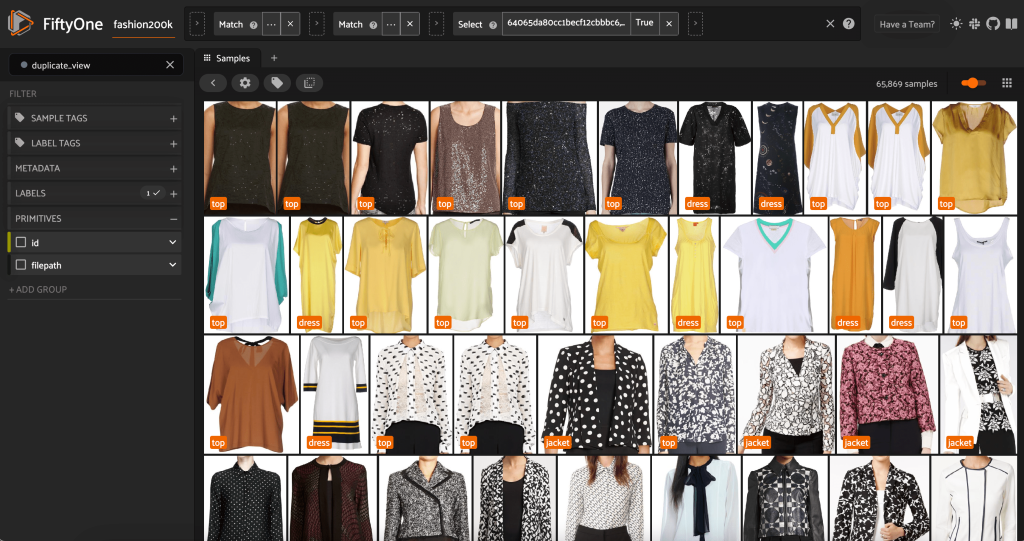
Коли ми задоволені результатом і вважаємо, що ці зображення справді є майже дублікатами, ми можемо вибрати один зразок із кожного набору подібних зразків, щоб зберегти, і ігнорувати інші:
Зараз у цьому перегляді 3,729 зображень. Очищаючи дані та визначаючи високоякісну підмножину набору даних Fashion200K, FiftyOne дозволяє нам обмежити увагу з більш ніж 300,000 4,000 зображень до трохи менше 98 90, що означає зменшення на XNUMX%. Лише використання вставок для видалення майже повторюваних зображень зменшило загальну кількість зображень, які ми розглядаємо, більш ніж на XNUMX%, майже не вплинувши на будь-які моделі, які потрібно навчати на цих даних.
Перш ніж попередньо позначити цю підмножину, ми можемо краще зрозуміти дані, візуалізувавши вбудовані елементи, які ми вже обчислили. Ми можемо використовувати вбудований у FiftyOne Brain compute_visualization(), який використовує техніку рівномірної апроксимації різноманітності (UMAP) для проектування 512-вимірних векторів вбудовування у двовимірний простір, щоб ми могли їх візуалізувати:
Відкриваємо новий Панель вбудовування у програмі FiftyOne і розфарбування за типом статті, і ми бачимо, що ці вбудовування приблизно кодують поняття типу статті (серед іншого!).
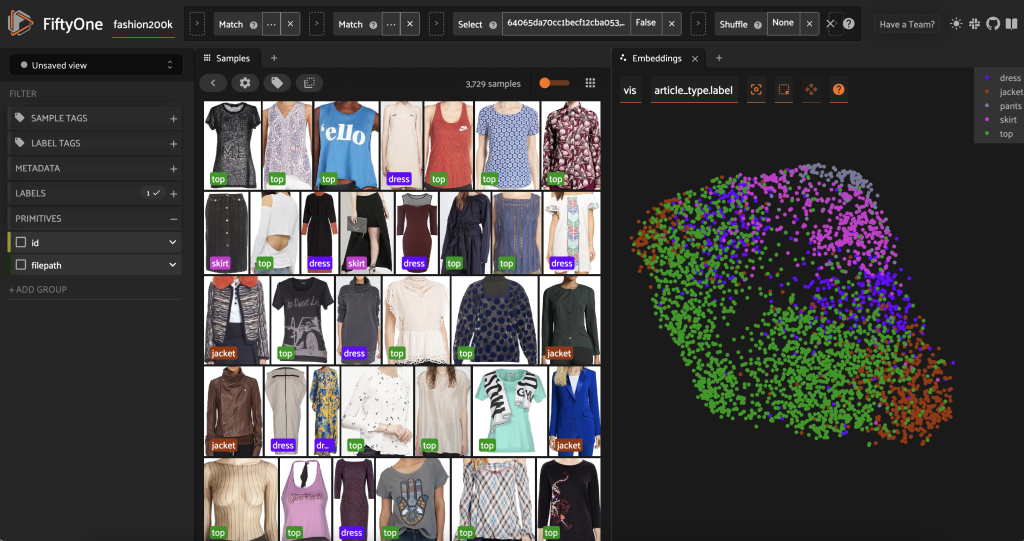
Тепер ми готові попередньо позначити ці дані.
Перевіряючи ці дуже унікальні зображення з високою роздільною здатністю, ми можемо сформувати пристойний початковий список стилів для використання в якості класів у нашій класифікації з нульовим випадком перед маркуванням. Наша мета попереднього позначення цих зображень не полягає в обов’язковому правильному позначенні кожного зображення. Скоріше наша мета — створити гарну відправну точку для людей-анотаторів, щоб ми могли скоротити час і вартість маркування.
Потім ми можемо створити екземпляр моделі класифікації нульового удару для цієї програми. Ми використовуємо модель CLIP, яка є моделлю загального призначення, навченою як на зображеннях, так і на природній мові. Ми створюємо екземпляр моделі CLIP із текстовою підказкою «Одяг у стилі», щоб за допомогою зображення модель виводила клас, для якого найкраще підходить «Одяг у стилі [клас]». CLIP не навчається на даних роздрібної торгівлі чи моді, тому це не буде ідеальним, але це може заощадити вам на маркуваннях і анотаціях.
Потім ми застосовуємо цю модель до нашої зменшеної підмножини та зберігаємо результати в article_style поле:
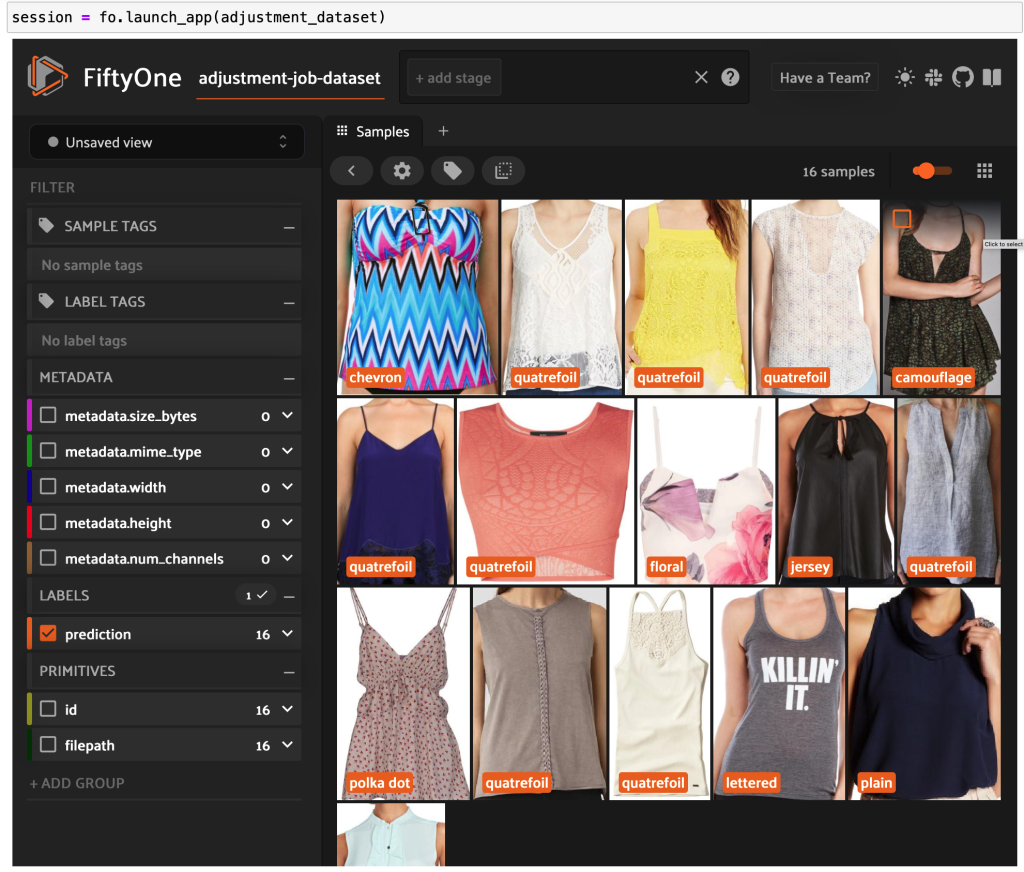
Знову запустивши програму FiftyOne, ми зможемо візуалізувати зображення з цими передбаченими мітками стилю. Ми сортуємо за достовірністю прогнозів, тому спочатку переглядаємо найбільш впевнені прогнози стилю:
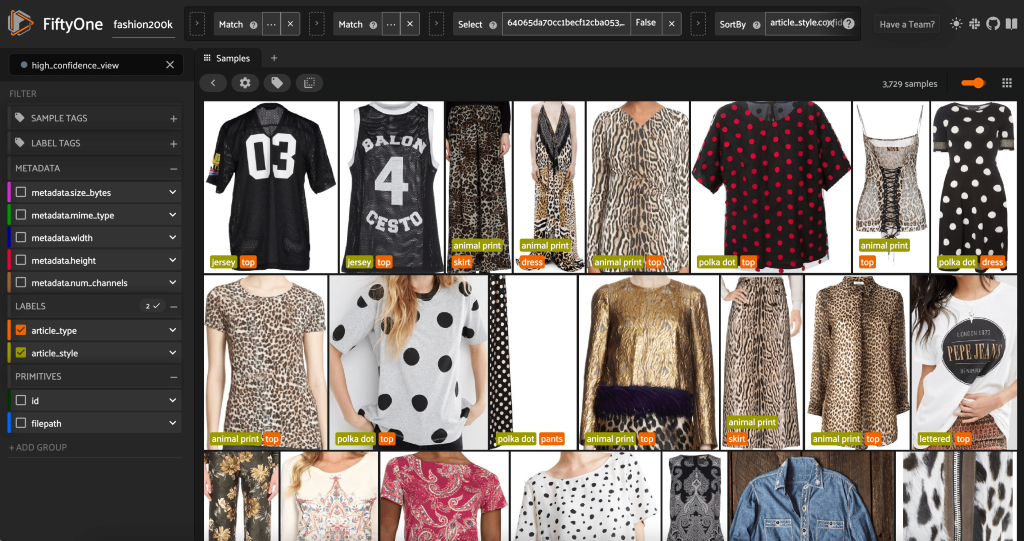
Ми бачимо, що прогнози з найвищою достовірністю стосуються стилів «джерсі», «тваринний принт», «горошок» і «букви». Це має сенс, оскільки ці стилі відносно різні. Також здається, що здебільшого передбачені мітки стилю точні.
Ми також можемо переглянути прогнози стилю з найнижчою достовірністю:
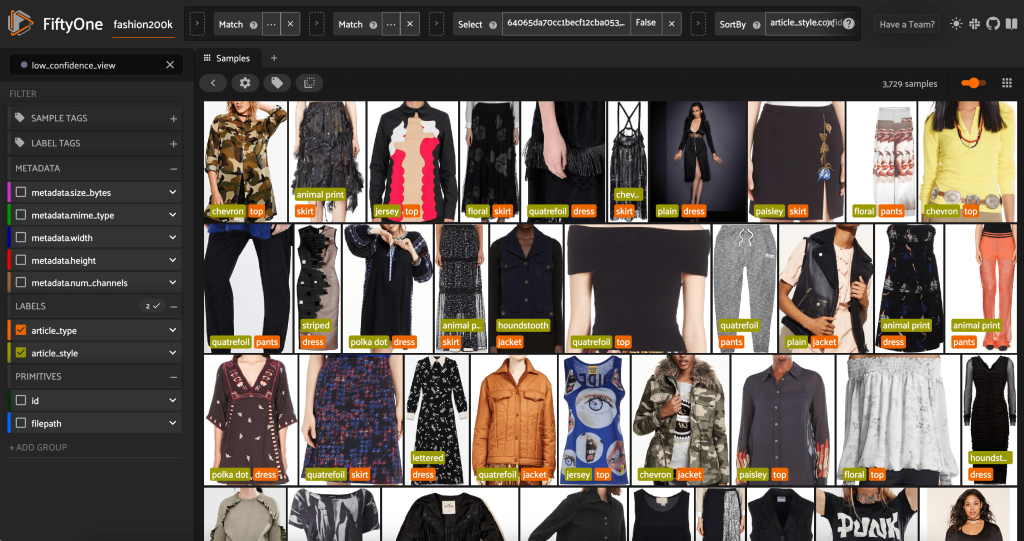
Для деяких із цих зображень у наданому списку є відповідна категорія стилю, а предмет одягу позначено неправильно. Перше зображення в сітці, наприклад, має бути чітко «камуфляж», а не «шеврон». Однак в інших випадках продукти не відповідають категоріям стилю. Сукня на другому зображенні у другому рядку, наприклад, не зовсім «смугаста», але враховуючи однакові параметри маркування, людина-анотатор також міг конфліктувати. Коли ми створюємо наш набір даних, нам потрібно вирішити, чи потрібно видалити крайові випадки, як ці, додати нові категорії стилів або розширити набір даних.
Експортуйте остаточний набір даних із FiftyOne
Експортуйте остаточний набір даних за допомогою такого коду:
Ми можемо експортувати менший набір даних, наприклад, 16 зображень, до папки 200kFashionDatasetExportResult-16Images. Ми створюємо завдання коригування Ground Truth, використовуючи його:
Завантажте виправлений набір даних, перетворіть формат мітки на Ground Truth, завантажте в Amazon S3 і створіть файл маніфесту для коригувального завдання
Ми можемо конвертувати мітки в наборі даних відповідно до вихідна схема маніфесту завдання обмежувальної рамки Ground Truth і завантажте зображення в Служба простого зберігання Amazon (Amazon S3) відро для запуску a Робота з коригування Ground Truth:
Завантажте файл маніфесту в Amazon S3 із таким кодом:
Створюйте виправлені стилізовані мітки за допомогою Ground Truth
Щоб анотувати свої дані мітками стилю за допомогою Ground Truth, виконайте необхідні кроки, щоб розпочати завдання міток обмежувальної рамки, дотримуючись процедури, описаної в Початок роботи з Ground Truth керівництво з набором даних у тому самому сегменті S3.
- На консолі SageMaker створіть завдання маркування Ground Truth.
- Встановіть Розташування вхідного набору даних бути маніфестом, який ми створили на попередніх кроках.
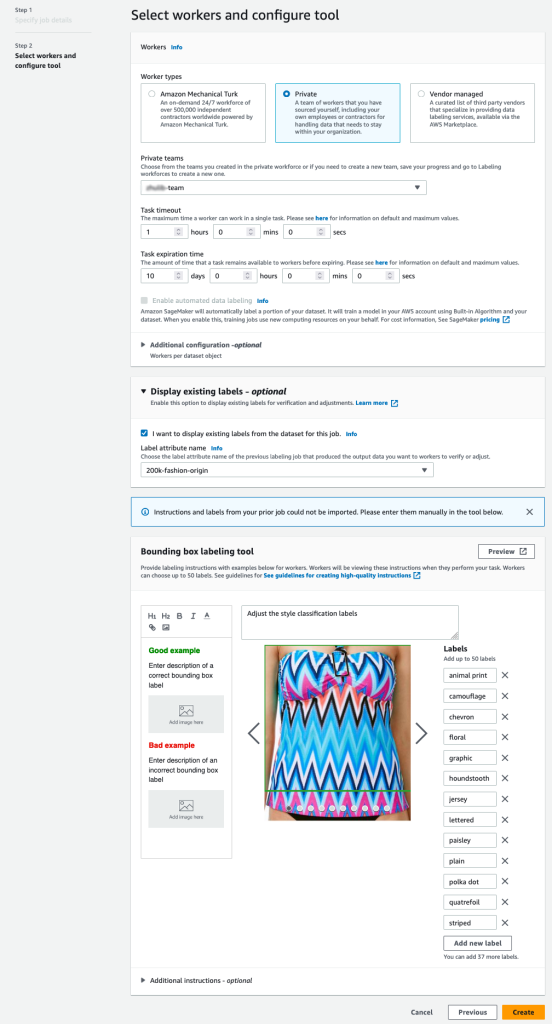
- Укажіть шлях S3 для Розташування набору вихідних даних.
- для Роль IAMвиберіть Введіть спеціальну роль IAM ARN, потім введіть роль ARN.
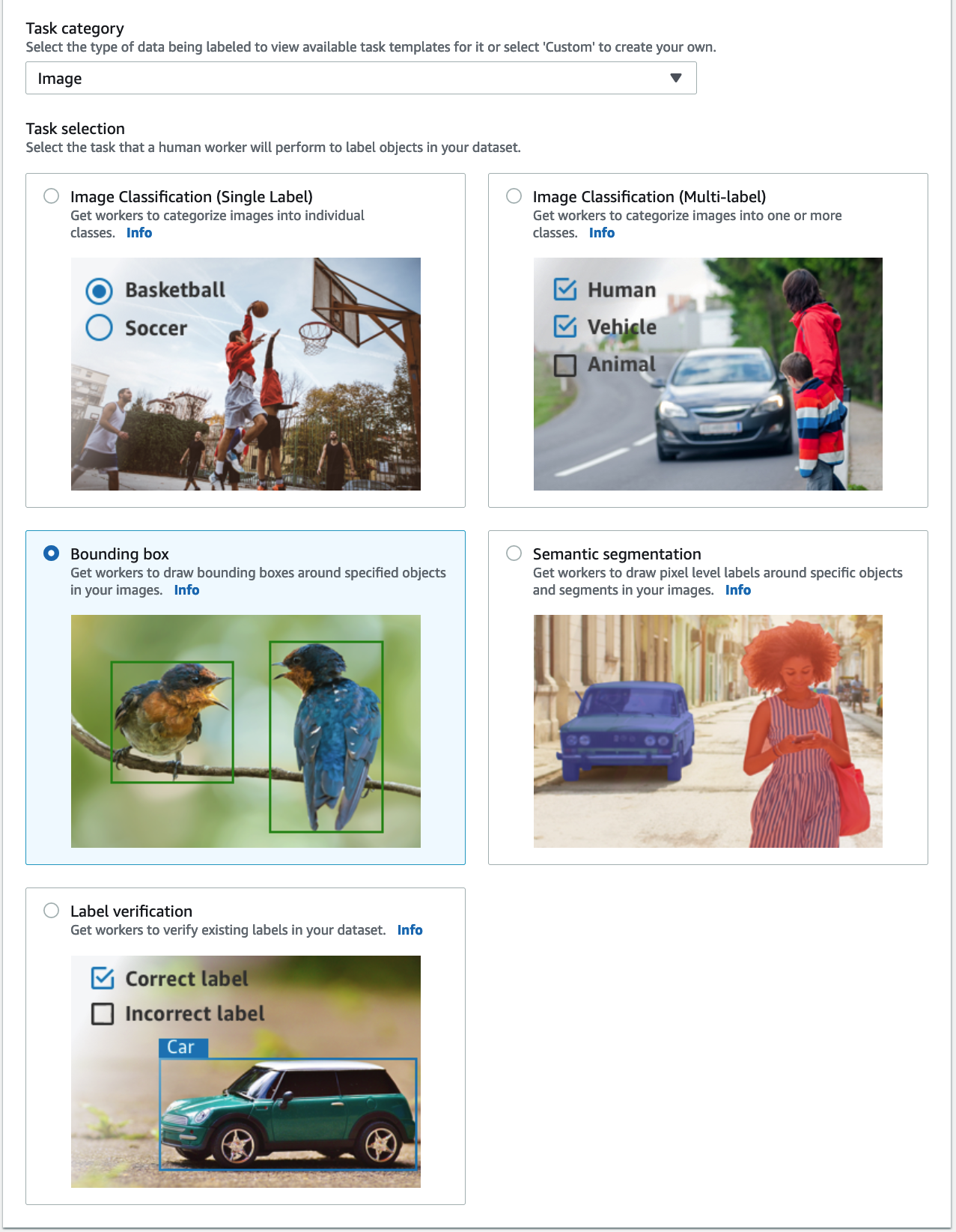
- для Категорія завданьвиберіть зображення і виберіть Обмежувальна рамка.
- Вибирати МАЙБУТНІ.
- У Робітники виберіть тип робочої сили, яку ви б хотіли використовувати.
Ви можете вибрати робочу силу через Amazon Mechanical Turk, сторонніх постачальників або вашої власної приватної робочої сили. Додаткову інформацію про ваші варіанти робочої сили див Створюйте та керуйте робочими силами. - Розширювати Параметри відображення наявних міток і виберіть Я хочу відобразити наявні мітки з набору даних для цієї роботи.
- для Атрибут мітки ім'я, виберіть назву зі свого маніфесту, яка відповідає міткам, які ви хочете відобразити для коригування.
Ви побачите назви атрибутів міток лише для міток, які відповідають типу завдання, вибраному на попередніх кроках. - Вручну введіть мітки для Інструмент маркування обмежувальної рамки.
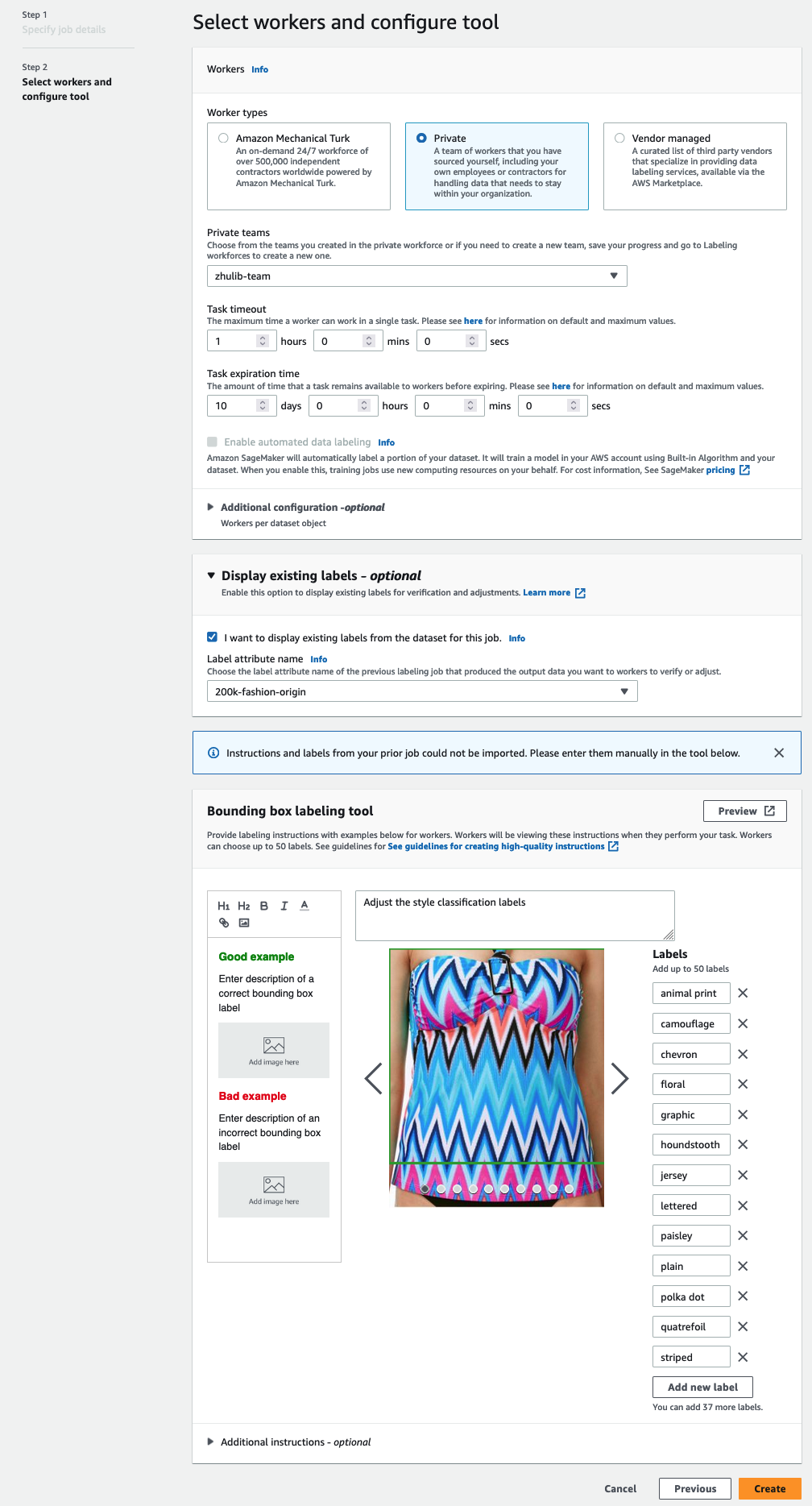 Мітки мають містити ті самі мітки, які використовуються в загальнодоступному наборі даних. Ви можете додавати нові мітки. На наступному знімку екрана показано, як ви можете вибрати працівників і налаштувати інструмент для завдання маркування.
Мітки мають містити ті самі мітки, які використовуються в загальнодоступному наборі даних. Ви можете додавати нові мітки. На наступному знімку екрана показано, як ви можете вибрати працівників і налаштувати інструмент для завдання маркування.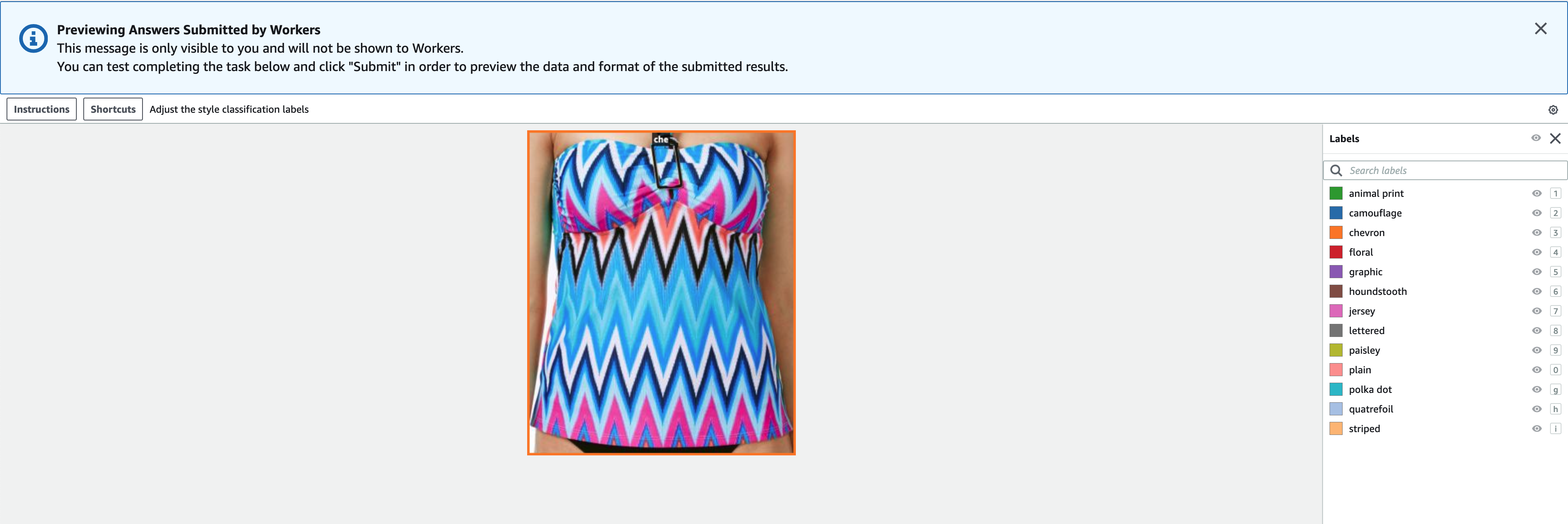
- Вибирати попередній перегляд для попереднього перегляду зображення та оригінальних анотацій.
Зараз ми створили завдання для маркування в Ground Truth. Після завершення нашої роботи ми можемо завантажити щойно згенеровані дані з мітками в FiftyOne. Ground Truth створює вихідні дані у вихідному маніфесті Ground Truth. Додаткову інформацію про вихідний файл маніфесту див Вихід завдання обмежувальної рамки. У наведеному нижче коді показано приклад цього формату вихідного маніфесту:
Перегляньте позначені результати з Ground Truth у FiftyOne
Після завершення завдання завантажте вихідний маніфест завдання маркування з Amazon S3.
Прочитайте вихідний файл маніфесту:
Створіть набір даних FiftyOne і перетворіть рядки маніфесту на зразки в наборі даних:
Тепер ви можете переглядати високоякісні мічені дані з Ground Truth у FiftyOne.
Висновок
У цьому дописі ми показали, як створювати високоякісні набори даних, поєднуючи потужність П'ятьдесят-один by Воксель51, набір інструментів із відкритим вихідним кодом, який дозволяє вам керувати, відстежувати, візуалізувати та контролювати свій набір даних, а також Ground Truth, службу маркування даних, яка дозволяє ефективно та точно позначати набори даних, необхідні для навчання систем машинного навчання, надаючи доступ до кількох вбудованих - у шаблонах завдань і доступ до різноманітної робочої сили через Mechanical Turk, сторонніх постачальників або власну приватну робочу силу.
Ми рекомендуємо вам випробувати цю нову функцію, встановивши примірник FiftyOne і скориставшись консоллю Ground Truth, щоб розпочати роботу. Щоб дізнатися більше про Ground Truth, див Дані етикетки, Поширені запитання щодо маркування даних Amazon SageMaker, А Блог машинного навчання AWS.
Підключіться до Спільнота машинного навчання та ШІ якщо у вас є запитання чи відгуки!
Приєднуйтесь до спільноти FiftyOne!
Приєднуйтеся до тисяч інженерів і спеціалістів із обробки даних, які вже використовують FiftyOne для вирішення деяких із найскладніших проблем комп’ютерного зору сьогодні!
Про авторів
Шалендра Чхабра наразі є керівником відділу управління продуктами Amazon SageMaker Human-in-the-Loop (HIL). Раніше Шалендра інкубував і керував мовним і розмовним аналізом для Microsoft Teams Meetings, був EIR в Amazon Alexa Techstars Startup Accelerator, віце-президентом із продуктів і маркетингу в Discuss.io, керівник відділу продуктів і маркетингу в Clipboard (придбаний Salesforce) і провідний менеджер із продуктів у Swype (придбаний Nuance). Загалом Shalendra допомогла створити, відвантажити та продати продукти, які торкнулися понад мільярд життів.
Яків Маркс є інженером машинного навчання та євангелістом розробників у Voxel51, де він допомагає забезпечити прозорість і ясність світових даних. До того як приєднатися до Voxel51, Джейкоб заснував стартап, щоб допомогти музикантам-початківцям спілкуватися та ділитися творчим контентом із шанувальниками. До цього він працював у Google X, Samsung Research і Wolfram Research. У минулому житті Джейкоб був фізиком-теоретиком, отримав ступінь доктора філософії в Стенфорді, де досліджував квантові фази матерії. У вільний час Джейкоб любить скелелазіти, бігати та читати науково-фантастичні романи.
Джейсон Корсо є співзасновником і генеральним директором Voxel51, де він керує стратегією, щоб допомогти забезпечити прозорість і ясність світових даних за допомогою найсучаснішого гнучкого програмного забезпечення. Він також є професором робототехніки, електротехніки та комп’ютерних наук в Мічиганському університеті, де він зосереджується на найсучасніших проблемах на перетині комп’ютерного зору, природної мови та фізичних платформ. У вільний час Джейсон любить проводити час із сім’єю, читати, бути на природі, грати в настільні ігри та займатися всілякою творчістю.
Браян Мур є співзасновником і технічним директором Voxel51, де він керує технічною стратегією та баченням. Він має ступінь доктора філософії з електротехніки в Мічиганському університеті, де його дослідження були зосереджені на ефективних алгоритмах для великомасштабних проблем машинного навчання, з особливим наголосом на програмах комп’ютерного зору. У вільний час він захоплюється бадмінтоном, гольфом, пішим туризмом і грою зі своїми близнюками йоркширськими тер’єрами.
Чжулінг Бай є інженером із розробки програмного забезпечення в Amazon Web Services. Вона працює над розробкою великомасштабних розподілених систем для вирішення проблем машинного навчання.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoAiStream. Web3 Data Intelligence. Розширення знань. Доступ тут.
- Карбування майбутнього з Адріенн Ешлі. Доступ тут.
- Купуйте та продавайте акції компаній, які вийшли на IPO, за допомогою PREIPO®. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- : має
- :є
- : ні
- :де
- $UP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- МЕНЮ
- прискорювати
- прискорення
- прискорювач
- доступ
- точний
- точно
- придбаний
- діяльності
- додавати
- додати
- адреса
- Відрегульований
- Регулювання
- після
- знову
- AI
- Alexa
- алгоритми
- ВСІ
- дозволяє
- тільки
- вже
- Також
- Amazon
- Amazon alexa
- Amazon SageMaker
- Основна правда Amazon SageMaker
- Amazon Web Services
- серед
- an
- аналізувати
- та
- тварина
- будь-який
- додаток
- додаток
- застосування
- Застосовувати
- відповідний
- ЕСТЬ
- влаштований
- стаття
- статті
- AS
- асоційований
- At
- authors
- геть
- AWS
- база
- заснований
- BE
- оскільки
- ставати
- було
- перед тим
- за
- за лаштунками
- буття
- Вірити
- КРАЩЕ
- Краще
- між
- Мільярд
- рада
- Настільні ігри
- КОСТАНО
- Bootstrap
- обидва
- Box
- коробки
- Brain
- Перерва
- приносити
- приніс
- бюджет
- будувати
- Створюємо
- вбудований
- але
- купити
- by
- CAN
- захопивши
- випадок
- випадків
- категорії
- Категорія
- Генеральний директор
- виклик
- складні
- перевірка
- Вибирати
- ясність
- клас
- класів
- класифікація
- Очищення
- ясно
- очевидно
- клієнт
- сходження
- близько
- ближче
- одяг
- одяг
- Співзасновник
- код
- об'єднувати
- об'єднання
- компанія
- Доповнення
- повний
- завершення
- обчислення
- комп'ютер
- Інформатика
- Комп'ютерне бачення
- Програми комп'ютерного зору
- довіра
- впевнений
- З'єднуватися
- розгляду
- Складається
- Консоль
- містить
- зміст
- зміст
- контроль
- діалоговий
- конвертувати
- copies
- Core
- виправлений
- відповідає
- Коштувати
- витрати
- створювати
- створений
- Креатив
- Повноваження
- CTO
- Куратор
- кураторство
- В даний час
- виготовлений на замовлення
- клієнт
- Клієнти
- Вирізати
- передовий
- дані
- набори даних
- вирішувати
- демонструвати
- Denim
- глибина
- description
- деталі
- Виявлення
- Розробник
- розвивається
- розробка
- різний
- безпосередньо
- каталоги
- дисплей
- чіткий
- розподілений
- розподілені системи
- Різне
- do
- Ні
- Пес
- справи
- зроблений
- Не знаю
- DOT
- вниз
- скачати
- дублікати
- e
- кожен
- легко
- край
- ефект
- ефективний
- продуктивно
- електротехніка
- вбудовування
- з'являються
- акцент
- працює
- повноваження
- інкапсульований
- заохочувати
- кінець
- інженер
- Машинобудування
- Інженери
- Що натомість? Створіть віртуальну версію себе у
- Навколишнє середовище
- рівність
- істотний
- встановлений
- Ефір (ETH)
- оцінки
- Євангеліст
- точно
- приклад
- існуючий
- експорт
- достатньо
- сім'я
- вентилятори
- зворотний зв'язок
- кілька
- Художня література
- поле
- Поля
- філе
- Файли
- фільтрувати
- фільтрація
- остаточний
- Перший
- відповідати
- гнучкий
- Сфокусувати
- увагу
- фокусується
- після
- для
- форма
- формат
- На щастя
- Заснований
- чотири
- Безкоштовна
- від
- повністю
- функціональність
- Games
- Головна мета
- породжувати
- генерується
- отримати
- GitHub
- Давати
- даний
- мета
- гольф
- добре
- великий
- сітка
- Земля
- Group
- керівництво
- щасливий
- Мати
- he
- голова
- висота
- допомога
- допоміг
- корисний
- допомагає
- тут
- високоякісний
- висока роздільна здатність
- найвищий
- дуже
- піший туризм
- його
- тримає
- Як
- How To
- Однак
- HTML
- HTTP
- HTTPS
- людина
- i
- IAM
- ID
- ідентифікувати
- ідентифікує
- ідентифікатори
- if
- зображення
- зображень
- Impact
- імпорт
- поліпшення
- in
- В інших
- У тому числі
- невірно
- інкубований
- інформація
- початковий
- спочатку
- встановлювати
- установка
- екземпляр
- замість
- інструкції
- Інтелект
- перетин
- в
- IT
- ЙОГО
- Джерсі
- робота
- приєднання
- спільна
- json
- просто
- тримати
- зберігання
- етикетка
- маркування
- етикетки
- мова
- масштабний
- запуск
- запуск
- вести
- Веде за собою
- УЧИТЬСЯ
- вивчення
- найменш
- Led
- залишити
- дозволяє
- бібліотека
- життя
- як
- Ймовірно
- МЕЖА
- обмеженою
- Лінія
- ліній
- список
- список
- оголошення
- трохи
- Місце проживання
- загрузка
- подивитися
- шукати
- серія
- низький
- машина
- навчання за допомогою машини
- made
- магія
- зробити
- РОБОТИ
- управляти
- вдалося
- управління
- менеджер
- багато
- карта
- ринок
- Маркетинг
- матч
- узгодження
- матеріально
- Матерія
- Може..
- механічний
- Медіа
- зустрічі
- Meta
- метадані
- метод
- методика
- Мічиган
- Microsoft
- команди мікрософт
- може бути
- мінімальний
- ML
- Mobile
- Мобільний додаток
- модель
- Моделі
- Модулі
- більше
- найбільш
- рухатися
- багато
- множинний
- музиканти
- повинен
- ім'я
- Названий
- Імена
- Природний
- Природна мова
- природа
- Близько
- обов'язково
- необхідно
- Необхідність
- потреби
- Нові
- помітно
- поняття
- зараз
- Nuance
- номер
- об'єкт
- Виявлення об'єктів
- об'єкти
- of
- офіційний
- on
- один раз
- ONE
- онлайн
- тільки
- відкрити
- з відкритим вихідним кодом
- операції
- Можливість
- Опції
- or
- Організований
- оригінал
- OS
- Інше
- інші
- наші
- з
- викладені
- вихід
- над
- власний
- володіє
- Пакети
- парний
- частина
- приватність
- Минуле
- шлях
- Викрійки
- моделі
- ідеальний
- продуктивність
- людина
- Персоналізовані
- Фази матерії
- фізичний
- вибирати
- фотографії
- PLAID
- одноколірний
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- ігри
- точка
- заселений
- це можливо
- пошта
- влада
- практика
- передвіщений
- прогноз
- Прогнози
- попередній перегляд
- попередній
- раніше
- друк
- попередній
- приватний
- ймовірно
- проблеми
- процес
- Product
- Управління продуктом
- менеджер по продукції
- Продукти
- Професор
- проект
- власність
- передбачуваний
- прототип
- забезпечувати
- за умови
- забезпечення
- громадськість
- перфоратор
- цілей
- Python
- Квантовий
- питань
- швидко
- діапазон
- швидше
- читання
- готовий
- рекомендувати
- рекомендації
- зменшити
- Знижений
- скорочення
- щодо
- випущений
- доречний
- видаляти
- представник
- представляє
- вимагається
- дослідження
- Дослідники
- дозвіл
- обмежити
- результат
- в результаті
- результати
- роздрібна торгівля
- повертати
- огляд
- позбавитися
- робототехніка
- міцний
- Роль
- грубо
- ROW
- губити
- біг
- мудрець
- Зазначений
- Salesforce
- то ж
- Samsung
- зберегти
- сцени
- наука
- Наукова фантастика
- Вчені
- рахунок
- плавно
- другий
- розділ
- розділам
- побачити
- здається
- Здається,
- обраний
- сенс
- окремий
- обслуговування
- Послуги
- Сесія
- комплект
- Поділитись
- вона
- Повинен
- Показувати
- Шоу
- ТАК
- аналогічний
- простий
- менше
- So
- Софтвер
- розробка програмного забезпечення
- ВИРІШИТИ
- деякі
- Хтось
- що в сім'ї щось
- Простір
- витрачати
- Витрати
- розкол
- Розколи
- Станфорд
- старт
- почалася
- Починаючи
- введення в експлуатацію
- прискорювач запуску
- впроваджений
- заходи
- Як і раніше
- зберігання
- зберігати
- Стратегія
- стиль
- Стилі
- РЕЗЮМЕ
- Підтриманий
- Systems
- Приймати
- Завдання
- команди
- технічний
- TechStars
- розповідає
- Шаблони
- тест
- ніж
- Що
- Команда
- їх
- Їх
- потім
- теоретичний
- Там.
- Ці
- вони
- речі
- думати
- третя сторона
- це
- тисячі
- поріг
- через
- Кидання
- час
- до
- разом
- інструмент
- Інструментарій
- топ
- верхній рівень
- верхівки
- Усього:
- торкнувся
- трек
- поїзд
- навчений
- Навчання
- Перетворення
- прозорість
- правда
- Правда
- ПЕРЕГЛЯД
- два
- тип
- Типи
- при
- розуміти
- створеного
- університет
- Мічиганський університет
- Оновити
- us
- використання
- використання випадку
- використовуваний
- користувач
- користувачі
- використання
- Цінності
- різноманітність
- різний
- постачальники
- перевірити
- дуже
- через
- вид
- Віртуальний
- бачення
- хотіти
- було
- we
- Web
- веб-сервіси
- ДОБРЕ
- були
- Що
- коли
- Чи
- який
- Вікіпедія
- волі
- з
- в
- без
- жінки
- слова
- Work
- працював
- робочі
- Трудові ресурси
- працює
- світі
- турбуватися
- б
- запис
- X
- ви
- вашу
- зефірнет
- Zip
- ZOO