У сучасному бізнес-середовищі, що керується даними, організації стикаються з проблемою ефективної підготовки та перетворення великих обсягів даних для цілей аналітики та науки про дані. Компанії повинні створювати сховища даних і озера даних на основі оперативних даних. Це зумовлено необхідністю централізації та інтеграції даних, що надходять із різних джерел.
У той же час оперативні дані часто надходять із програм, які підтримуються застарілими сховищами даних. Для модернізації додатків потрібна архітектура мікросервісу, яка, у свою чергу, вимагає консолідації даних із багатьох джерел для створення оперативного сховища даних. Без модернізації застарілі програми можуть спричинити збільшення витрат на обслуговування. Модернізація додатків передбачає зміну основної бази даних на сучасну документну базу даних, як-от MongoDB.
Ці два завдання (створення озер даних або сховищ даних і модернізація додатків) передбачають переміщення даних, яке використовує процес вилучення, перетворення та завантаження (ETL). Робота ETL є ключовою функціональністю для мати добре структурований процес для досягнення успіху.
Клей AWS це безсерверна служба інтеграції даних, яка дозволяє легко знаходити, готувати, переміщувати та інтегрувати дані з багатьох джерел для аналітики, машинного навчання (ML) і розробки програм. Атлас MongoDB це інтегрований набір хмарних баз даних і служб даних, який поєднує обробку транзакцій, пошук на основі релевантності, аналітику в реальному часі та синхронізацію мобільних даних із хмарою в елегантній інтегрованій архітектурі.
Використовуючи AWS Glue з MongoDB Atlas, організації можуть оптимізувати свої процеси ETL. Завдяки повністю керованому, масштабованому та безпечному базі даних MongoDB Atlas забезпечує гнучке та надійне середовище для зберігання та керування оперативними даними. Разом AWS Glue ETL і MongoDB Atlas є потужним рішенням для організацій, які прагнуть оптимізувати те, як вони створюють озера даних і сховища даних, а також модернізувати свої програми, щоб покращити ефективність бізнесу, зменшити витрати та сприяти зростанню та успіху.
У цій публікації ми покажемо, як перенести дані з Служба простого зберігання Amazon (Amazon S3) відра до MongoDB Atlas за допомогою AWS Glue ETL і як витягти дані з MongoDB Atlas до озера даних на основі Amazon S3.
Огляд рішення
У цій публікації ми досліджуємо такі випадки використання:
- Вилучення даних з MongoDB – MongoDB — це популярна база даних, яка використовується тисячами клієнтів для зберігання даних додатків у масштабі. Корпоративні клієнти можуть централізувати та інтегрувати дані, що надходять із кількох сховищ даних, створюючи озера та сховища даних. Цей процес передбачає вилучення даних із сховищ оперативних даних. Коли дані знаходяться в одному місці, клієнти можуть швидко використовувати їх для потреб бізнес-аналітики або для ML.
- Введення даних у MongoDB – MongoDB також служить базою даних без SQL для зберігання даних додатків і створення оперативних сховищ даних. Модернізація додатків часто передбачає перенесення операційного сховища до MongoDB. Клієнтам потрібно буде витягти наявні дані з реляційних баз даних або з плоских файлів. Мобільні та веб-програми часто вимагають від інженерів обробки даних створювати конвеєри даних, щоб створити єдине представлення даних в Atlas, надаючи дані з кількох ізольованих джерел. Під час цієї міграції їм потрібно буде приєднатися до різних баз даних для створення документів. Ця складна операція об’єднання потребує значної одноразової обчислювальної потужності. Розробникам також потрібно буде швидко створити це, щоб перенести дані.
У цих випадках AWS Glue стане в пригоді завдяки моделі оплати за використання та її здатності виконувати складні перетворення величезних наборів даних. Розробники можуть використовувати AWS Glue Studio для ефективного створення таких конвеєрів даних.
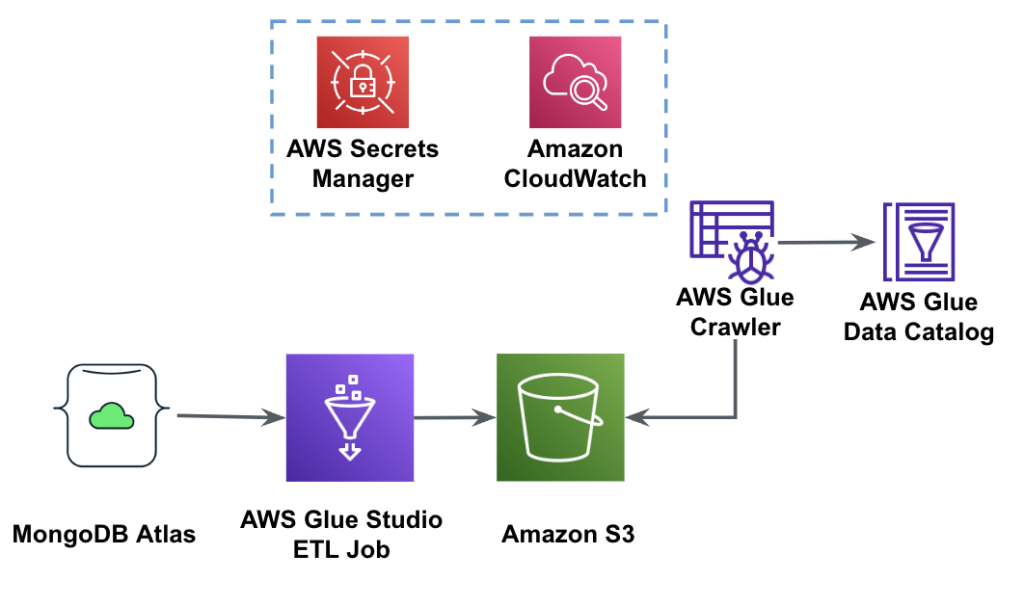
На наступній діаграмі показано робочий процес вилучення даних із MongoDB Atlas у сегмент S3 за допомогою AWS Glue Studio.
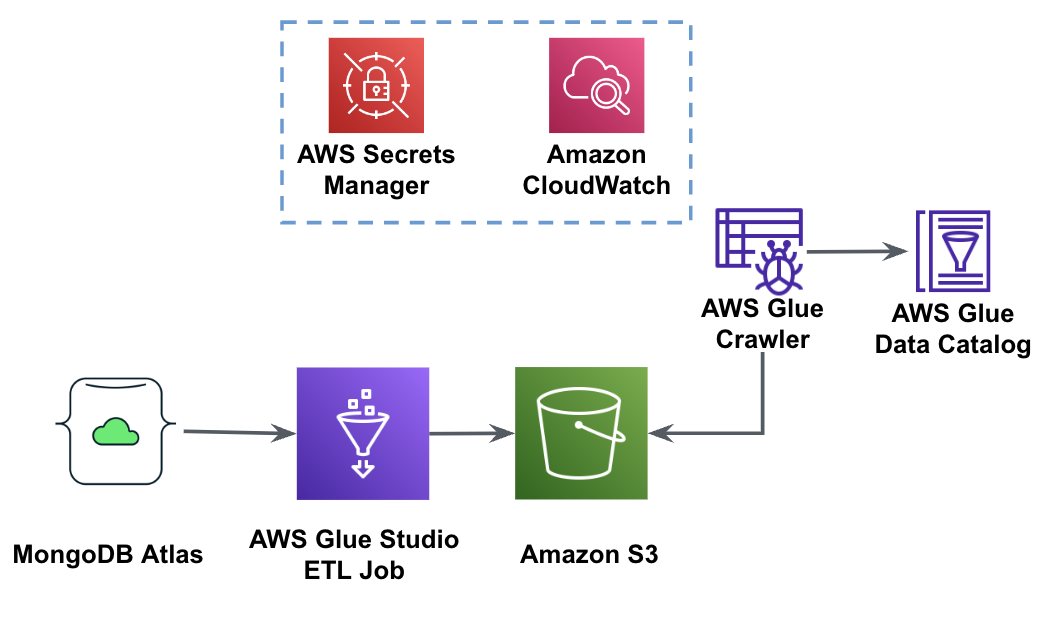
Щоб реалізувати цю архітектуру, вам знадобиться кластер MongoDB Atlas, сегмент S3 і Управління ідентифікацією та доступом AWS (IAM) для AWS Glue. Щоб налаштувати ці ресурси, зверніться до попередніх кроків, наведених нижче GitHub репо.
На наступному малюнку показано робочий процес завантаження даних із сегмента S3 в MongoDB Atlas за допомогою AWS Glue.
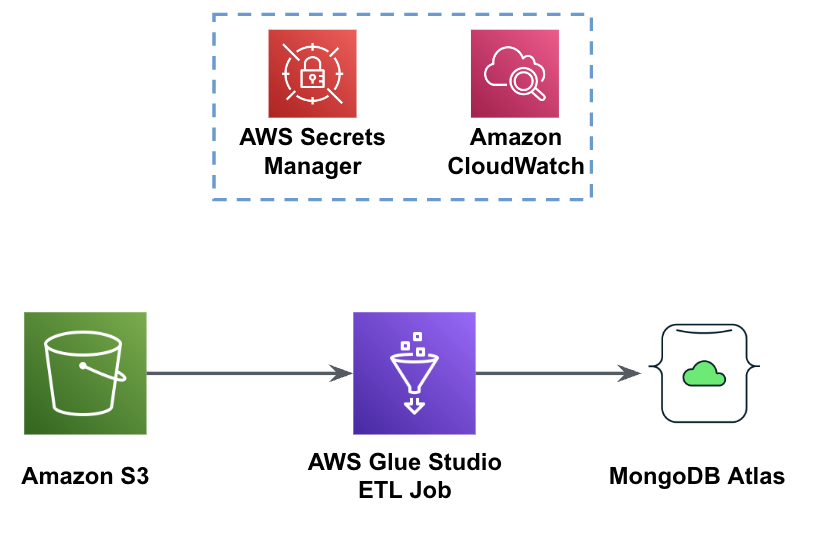
Тут необхідні ті самі передумови: сегмент S3, роль IAM і кластер MongoDB Atlas.
Завантажте дані з Amazon S3 до MongoDB Atlas за допомогою AWS Glue
Наступні кроки описують, як завантажити дані з сегмента S3 в MongoDB Atlas за допомогою завдання AWS Glue. Процес вилучення з MongoDB Atlas до Amazon S3 дуже схожий, за винятком використовуваного сценарію. Ми називаємо відмінності між двома процесами.
- Створіть вільний кластер в MongoDB Atlas.
- Завантажте зразок файлу JSON до вашого відра S3.
- Створіть нове завдання AWS Glue Studio за допомогою Редактор сценаріїв Spark варіант.

- Залежно від того, чи хочете ви завантажити або витягти дані з кластера MongoDB Atlas, введіть завантажити скрипт or витягти сценарій у редакторі сценаріїв AWS Glue Studio.
На наступному знімку екрана показано фрагмент коду для завантаження даних у кластер MongoDB Atlas.

Код використовує Менеджер секретів AWS щоб отримати назву кластера MongoDB Atlas, ім’я користувача та пароль. Потім створюється a DynamicFrame для сегмента S3 і ім’я файлу, передане в сценарій як параметри. Код отримує базу даних і назви колекцій із конфігурації параметрів завдання. Нарешті, код записує DynamicFrame до кластера MongoDB Atlas, використовуючи отримані параметри.
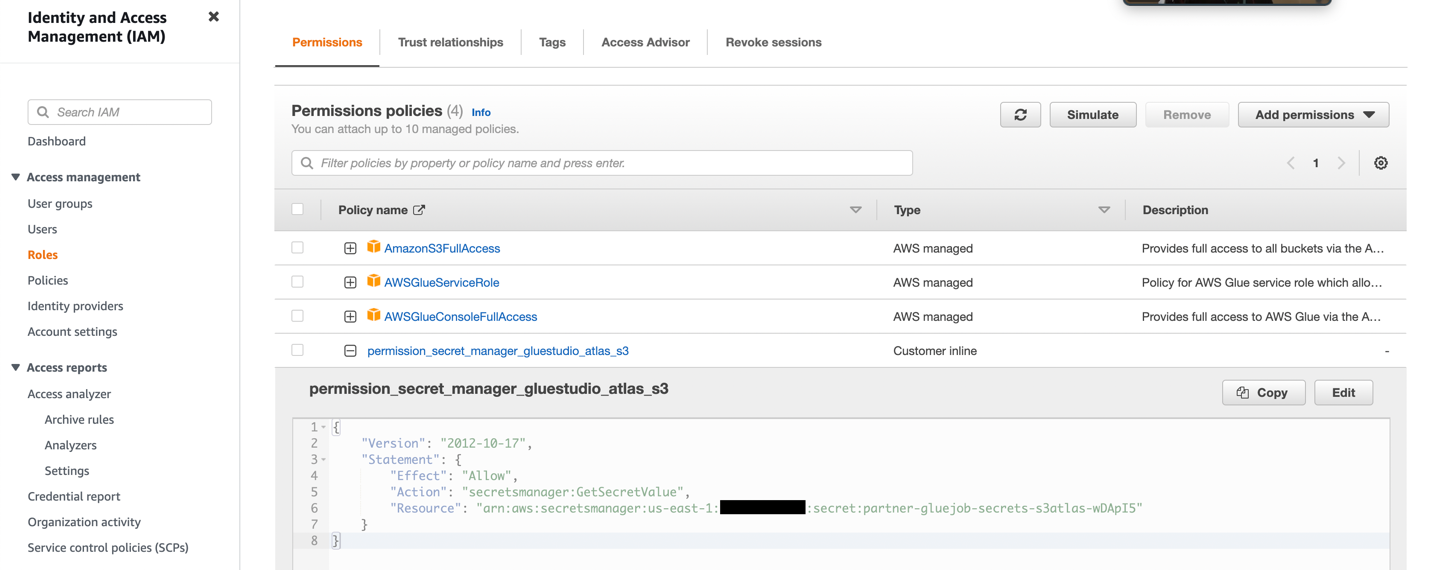
- Створіть роль IAM із дозволами, як показано на знімку екрана нижче.
Детальніше див Налаштуйте роль IAM для завдання ETL.
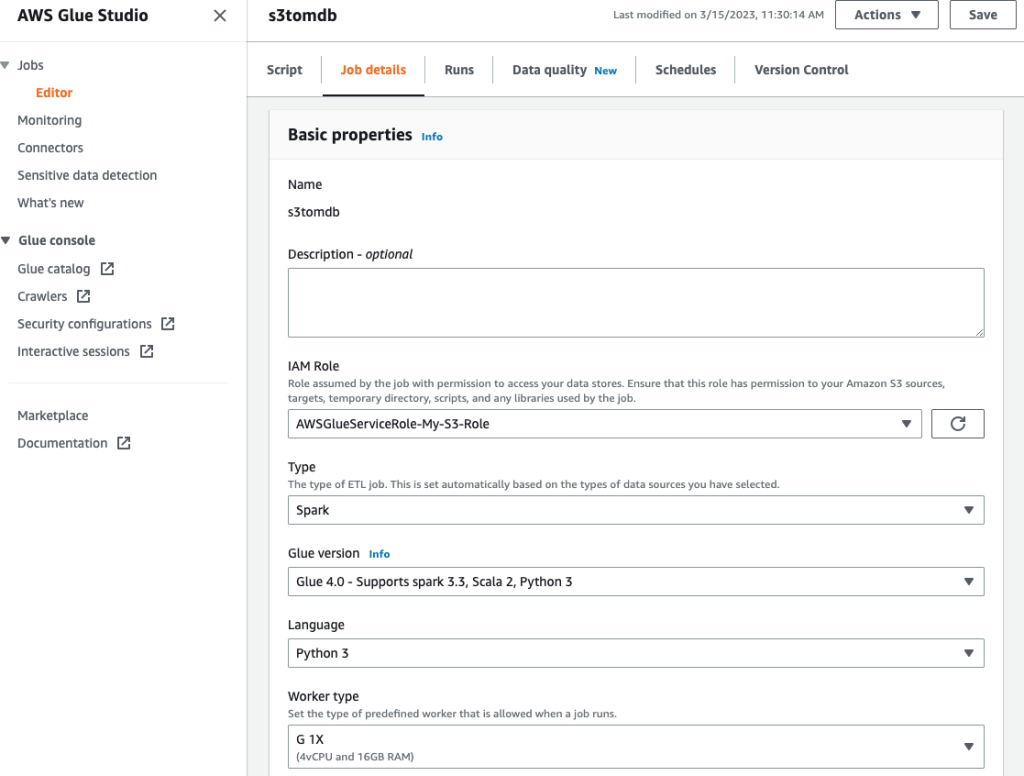
- Назвіть завдання та вкажіть роль IAM, створену на попередньому кроці Деталі роботи Вкладка.
- Ви можете залишити решту параметрів за замовчуванням, як показано на наступних знімках екрана.
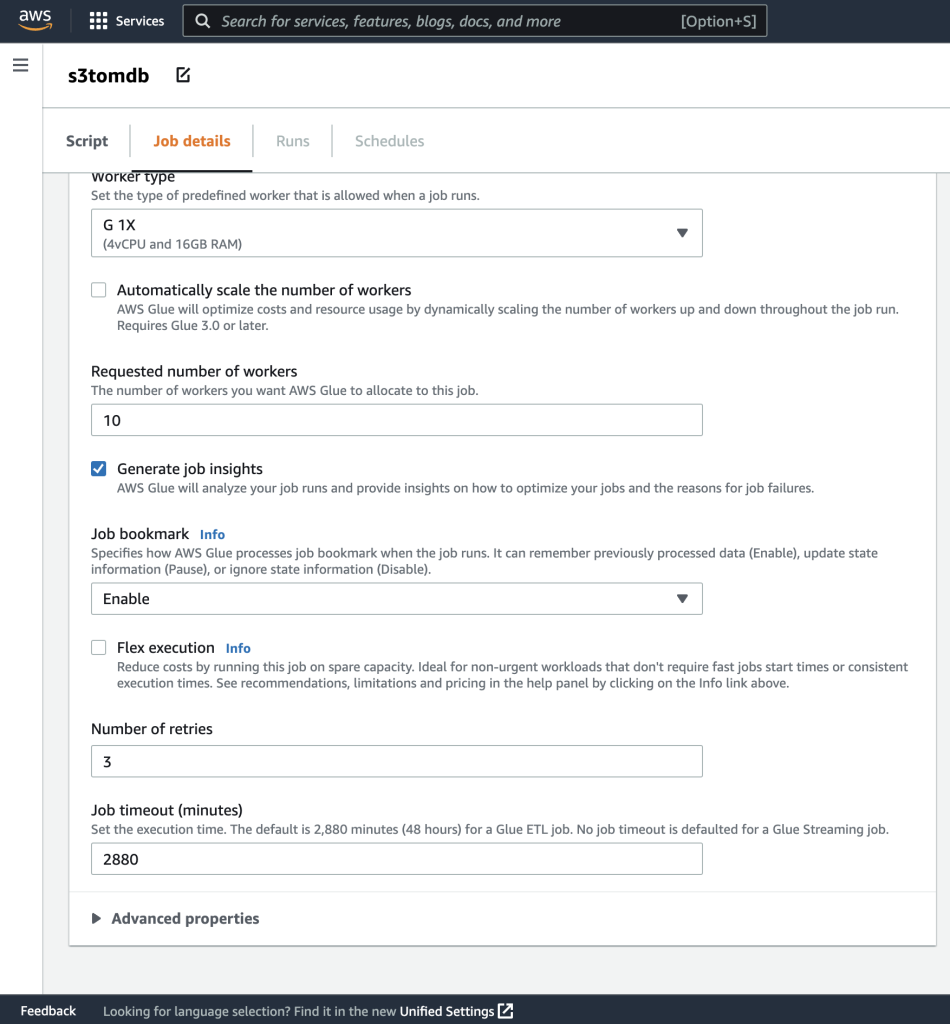
- Далі визначте параметри завдання, які використовує сценарій, і вкажіть значення за замовчуванням.
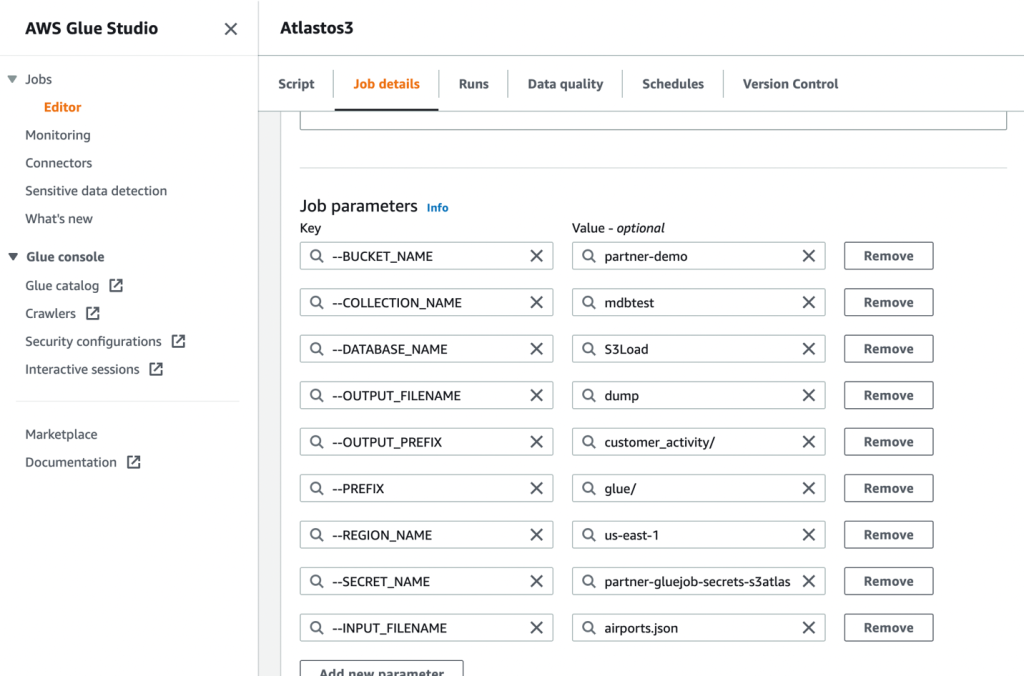
- Збережіть завдання та запустіть його.
- Щоб підтвердити успішний запуск, спостерігайте за вмістом колекції бази даних MongoDB Atlas під час завантаження даних або сегмента S3, якщо ви виконували вилучення.



На наступному знімку екрана показано результати успішного завантаження даних із сегмента Amazon S3 у кластер MongoDB Atlas. Дані тепер доступні для запитів в інтерфейсі MongoDB Atlas.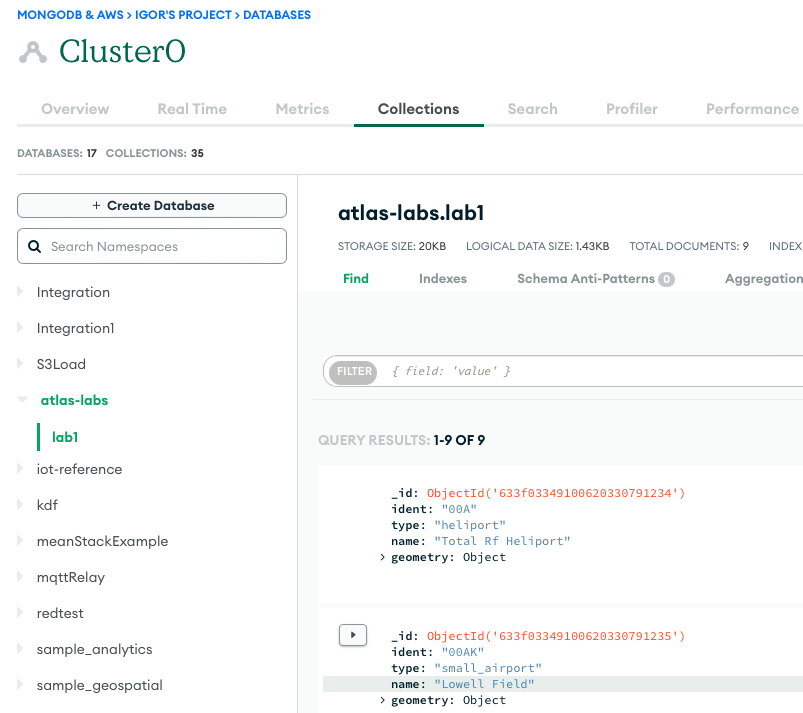
- Щоб усунути несправності, перегляньте Amazon CloudWatch журнали за допомогою посилання на роботу прогін Вкладка.
На наступному знімку екрана показано, що завдання виконано успішно, з додатковими відомостями, наприклад посиланнями на журнали CloudWatch.

Висновок
У цьому дописі ми описали, як видобувати та завантажувати дані в MongoDB Atlas за допомогою AWS Glue.
Завдяки завданням AWS Glue ETL ми тепер можемо передавати дані з MongoDB Atlas у джерела, сумісні з AWS Glue, і навпаки. Ви також можете розширити рішення для створення аналітики за допомогою служб AWS AI та ML.
Щоб дізнатися більше, зверніться до GitHub сховище для отримання покрокових інструкцій і прикладу коду. Ви можете придбати Атлас MongoDB на AWS Marketplace.
Про авторів

Ігор Алексєєв є старшим архітектором партнерських рішень в AWS у сфері даних і аналітики. У своїй ролі Ігор працює зі стратегічними партнерами, допомагаючи їм створювати складні архітектури, оптимізовані для AWS. До приходу в AWS як архітектор даних/рішень він реалізував багато проектів у сфері великих даних, зокрема кілька озер даних в екосистемі Hadoop. Як інженер з даних він брав участь у застосуванні AI/ML для виявлення шахрайства та автоматизації офісу.
 Бабу Шрінівасан є старшим архітектором партнерських рішень у MongoDB. На своїй поточній посаді він працює з AWS над створенням технічної інтеграції та еталонних архітектур для рішень AWS і MongoDB. Він має понад два десятиліття досвіду роботи з базами даних і хмарними технологіями. Він захоплений наданням технічних рішень клієнтам, які працюють із кількома глобальними системними інтеграторами (GSI) у різних регіонах.
Бабу Шрінівасан є старшим архітектором партнерських рішень у MongoDB. На своїй поточній посаді він працює з AWS над створенням технічної інтеграції та еталонних архітектур для рішень AWS і MongoDB. Він має понад два десятиліття досвіду роботи з базами даних і хмарними технологіями. Він захоплений наданням технічних рішень клієнтам, які працюють із кількома глобальними системними інтеграторами (GSI) у різних регіонах.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoAiStream. Web3 Data Intelligence. Розширення знань. Доступ тут.
- Карбування майбутнього з Адріенн Ешлі. Доступ тут.
- Купуйте та продавайте акції компаній, які вийшли на IPO, за допомогою PREIPO®. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- : має
- :є
- 100
- 11
- a
- здатність
- МЕНЮ
- доступ
- через
- Додатковий
- AI
- AI / ML
- Також
- Amazon
- суми
- an
- аналітика
- та
- додаток
- Розробка додатка
- застосування
- Застосування
- додатка
- архітектура
- ЕСТЬ
- AS
- At
- Атлант
- Автоматизація
- доступний
- AWS
- Клей AWS
- Торговий майданчик AWS
- підтриманий
- заснований
- буття
- між
- Великий
- Великий даних
- будувати
- Створюємо
- бізнес
- бізнес-аналітика
- результати діяльності
- підприємства
- by
- call
- CAN
- випадків
- виклик
- заміна
- хмара
- кластер
- код
- збір
- комбінати
- приходить
- майбутній
- комплекс
- обчислення
- конфігурація
- підтвердити
- консолідація
- будувати
- зміст
- триває
- витрати
- створювати
- створений
- створює
- створення
- Поточний
- Клієнти
- дані
- інженер даних
- інтеграція даних
- Озеро даних
- наука про дані
- сховища даних
- керовані даними
- Database
- базами даних
- набори даних
- десятиліття
- дефолт
- демонструвати
- описувати
- описаний
- деталі
- Виявлення
- розробників
- розробка
- Відмінності
- різний
- відкрити
- розрізнені
- документація
- домен
- управляти
- керований
- під час
- екосистема
- редактор
- продуктивно
- двигун
- інженер
- Інженери
- Що натомість? Створіть віртуальну версію себе у
- підприємство
- корпоративні клієнти
- Навколишнє середовище
- Ефір (ETH)
- виняток
- існуючий
- досвід
- дослідити
- продовжити
- витяг
- видобуток
- Face
- Рисунок
- філе
- Файли
- в кінці кінців
- плоский
- гнучкий
- після
- для
- шахрайство
- виявлення шахрайства
- Безкоштовна
- від
- повністю
- функціональність
- географії
- Глобальний
- Зростання
- Hadoop
- мобільний
- має
- he
- допомогу
- тут
- його
- Як
- How To
- HTML
- HTTP
- HTTPS
- величезний
- IAM
- Особистість
- if
- здійснювати
- реалізовані
- удосконалювати
- in
- У тому числі
- зростаючий
- вхід
- інструкції
- інтегрувати
- інтегрований
- інтеграція
- інтеграцій
- Інтелект
- в
- залучати
- залучений
- IT
- ЙОГО
- робота
- Джобс
- приєднатися
- приєднання
- json
- ключ
- озеро
- великий
- УЧИТЬСЯ
- вивчення
- Залишати
- Legacy
- як
- LINK
- зв'язку
- загрузка
- погрузка
- шукати
- машина
- навчання за допомогою машини
- обслуговування
- РОБОТИ
- вдалося
- управління
- багато
- ринку
- Може..
- мігрувати
- міграція
- ML
- Mobile
- модель
- сучасний
- модернізація
- модернізувати
- MongoDB
- більше
- рухатися
- руху
- множинний
- ім'я
- Імена
- Необхідність
- необхідний
- потреби
- Нові
- зараз
- спостерігати
- of
- Office
- часто
- on
- ONE
- операція
- оперативний
- Оптимізувати
- варіант
- or
- порядок
- організації
- з
- параметри
- партнер
- партнери
- Пройшов
- пристрасний
- Пароль
- продуктивність
- виконанні
- Дозволи
- місце
- plato
- Інформація про дані Платона
- PlatoData
- популярний
- пошта
- влада
- потужний
- Готувати
- підготовка
- передумови
- попередній
- попередній
- процес
- процеси
- обробка
- проектів
- забезпечує
- забезпечення
- цілей
- запити
- швидко
- реального часу
- зменшити
- надійний
- вимагати
- Вимагається
- ресурси
- REST
- результати
- огляд
- Роль
- прогін
- то ж
- масштабовані
- шкала
- наука
- скріншоти
- Пошук
- безпечний
- старший
- Без сервера
- служить
- обслуговування
- Послуги
- кілька
- показаний
- Шоу
- значний
- аналогічний
- простий
- один
- рішення
- Рішення
- Джерела
- Крок
- заходи
- зберігання
- зберігати
- магазинів
- просто
- Стратегічний
- стратегічні партнери
- раціоналізувати
- студія
- процвітати
- успіх
- успішний
- Успішно
- такі
- набір
- поставка
- синхронізація
- система
- завдання
- технічний
- Технології
- ніж
- Що
- Команда
- їх
- Їх
- потім
- Ці
- вони
- це
- тисячі
- час
- до
- сьогоднішній
- разом
- транзакційний
- переклад
- Перетворення
- перетворень
- перетворення
- ПЕРЕГЛЯД
- два
- ui
- що лежить в основі
- використання
- використовуваний
- користувач
- використання
- Цінності
- дуже
- вид
- хотіти
- було
- we
- Web
- були
- коли
- Чи
- який
- в той час як
- волі
- з
- без
- робочий
- робочий
- б
- ви
- вашу
- зефірнет