Пошук подібних стовпців у a озеро даних має важливі програми для очищення та анотації даних, зіставлення схем, виявлення даних та аналітики в багатьох джерелах даних. Неможливість точно знайти та проаналізувати дані з різних джерел є потенційним вбивцею ефективності для всіх: від спеціалістів із обробки даних, медичних дослідників, науковців до фінансових і державних аналітиків.
Звичайні рішення передбачають пошук за лексичним ключовим словом або зіставлення регулярного виразу, які можуть бути чутливими до проблем якості даних, таких як відсутність імен стовпців або різні домовленості про іменування стовпців у різних наборах даних (наприклад, zip_code, zcode, postalcode).
У цій публікації ми демонструємо рішення для пошуку схожих стовпців на основі назви стовпця, вмісту стовпця або обох. Розчин використовує алгоритми наближених найближчих сусідів доступні в Служба Amazon OpenSearch для пошуку семантично схожих стовпців. Щоб полегшити пошук, ми створюємо представлення функцій (вбудовування) для окремих стовпців в озері даних, використовуючи попередньо підготовлені моделі Transformer з бібліотека трансформаторів речень in Amazon SageMaker. Нарешті, щоб взаємодіяти з нашим рішенням і візуалізувати його результати, ми створюємо інтерактив Стрітліт працює веб-додаток AWS Fargate.
Ми включаємо а підручник з кодом щоб ви могли розгорнути ресурси для запуску рішення на зразках даних або ваших власних даних.
Огляд рішення
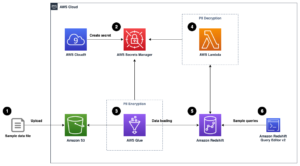
Наступна діаграма архітектури ілюструє двоетапний робочий процес для пошуку семантично подібних стовпців. Перший етап запускає Функції кроку AWS робочий процес, який створює вбудовування зі стовпців таблиці та створює індекс пошуку OpenSearch Service. Другий етап, або етап онлайн-виводу, запускає програму Streamlit через Fargate. Веб-програма збирає вхідні пошукові запити та отримує з індексу OpenSearch Service приблизні k-найбільш схожих стовпців для запиту.

Рисунок 1. Архітектура рішення
Автоматизований робочий процес складається з наступних кроків:
- Користувач завантажує табличні набори даних у Служба простого зберігання Amazon (Amazon S3) відро, яке викликає an AWS Lambda функція, яка ініціює робочий процес крокових функцій.
- Робочий процес починається з Клей AWS завдання, яке перетворює файли CSV у Паркет Apache формат даних.
- Завдання SageMaker Processing створює вбудовування для кожного стовпця за допомогою попередньо навчених моделей або спеціальних моделей вбудовування стовпців. Завдання SageMaker Processing зберігає вбудовані стовпці для кожної таблиці в Amazon S3.
- Функція Lambda створює домен і кластер OpenSearch Service для індексування вставок стовпців, створених на попередньому кроці.
- Нарешті, інтерактивний веб-додаток Streamlit розгорнуто з Fargate. Веб-програма надає користувачеві інтерфейс для введення запитів для пошуку в домені OpenSearch Service подібних стовпців.
Ви можете завантажити підручник з коду з GitHub щоб спробувати це рішення на зразках даних або ваших власних даних. Інструкції щодо розгортання необхідних ресурсів для цього підручника доступні на Github.
Передумови
Щоб реалізувати це рішення, необхідно:
- An Обліковий запис AWS.
- Базове знайомство з сервісами AWS, такими як Набір хмарних розробок AWS (AWS CDK), Lambda, OpenSearch Service і SageMaker Processing.
- Табличний набір даних для створення пошукового індексу. Ви можете принести власні табличні дані або завантажити зразки наборів даних GitHub.
Створіть пошуковий індекс
На першому етапі створюється індекс пошукової системи стовпців. На наступному малюнку показано робочий процес крокових функцій, який виконує цей етап.

Рисунок 2 – Робочий процес крокових функцій – кілька моделей вбудовування
Набори даних
У цій публікації ми створюємо пошуковий індекс, який включає понад 400 стовпців із понад 25 табличних наборів даних. Набори даних походять із таких загальнодоступних джерел:
Щоб отримати повний список таблиць, включених до покажчика, перегляньте навчальний посібник із коду GitHub.
Ви можете додати свій власний набір табличних даних, щоб розширити зразки даних або створити власний пошуковий індекс. Ми включаємо дві функції Lambda, які ініціюють робочий процес Step Functions для створення пошукового індексу для окремих файлів CSV або групи файлів CSV відповідно.
Перетворення CSV на Parquet
Необроблені файли CSV перетворюються у формат даних Parquet за допомогою AWS Glue. Parquet — це формат файлу, орієнтованого на стовпці, якому віддається перевага в аналітиці великих даних і забезпечує ефективне стиснення та кодування. У наших експериментах формат даних Parquet запропонував значне зменшення розміру пам’яті порівняно з необробленими файлами CSV. Ми також використовували Parquet як поширений формат даних для перетворення інших форматів даних (наприклад, JSON і NDJSON), оскільки він підтримує розширені вкладені структури даних.
Створення вставок стовпців таблиці
Щоб витягти вбудовування для окремих стовпців таблиці в зразки табличних наборів даних у цій публікації, ми використовуємо такі попередньо навчені моделі з sentence-transformers бібліотека. Додаткові моделі див Попередньо підготовлені моделі.
Виконується завдання обробки SageMaker create_embeddings.py(код) для однієї моделі. Для вилучення вбудовування з кількох моделей робочий цикл виконує паралельні завдання SageMaker Processing, як показано в робочому процесі крокових функцій. Ми використовуємо модель для створення двох наборів вбудовування:
- ім'я_стовпця_вбудовування – Вбудовані імена стовпців (заголовки)
- вбудовування вмісту стовпця – Середнє вбудовування всіх рядків у стовпець
Щоб отримати додаткові відомості про процес вбудовування стовпців, перегляньте навчальний посібник із коду GitHub.
Альтернативою етапу обробки SageMaker є створення пакетного перетворення SageMaker для отримання вбудовування стовпців у великі набори даних. Це вимагатиме розгортання моделі на кінцевій точці SageMaker. Для отримання додаткової інформації див Використовуйте пакетне перетворення.
Індексуйте вбудовування за допомогою служби OpenSearch
На останньому етапі цього етапу функція лямбда додає вбудовування стовпців до наближеного k-найближчого сусіда служби OpenSearch (kNN) пошуковий індекс. Кожній моделі присвоюється власний індекс пошуку. Для отримання додаткової інформації про приблизні параметри індексу пошуку kNN див k-NN.
Онлайновий висновок і семантичний пошук за допомогою веб-програми
На другому етапі робочого процесу виконується a Стрітліт веб-додаток, де можна вводити дані та шукати семантично подібні стовпці, проіндексовані в OpenSearch Service. Прикладний рівень використовує an Балансувальник навантаження програми, Фаргейт і Лямбда. Інфраструктура програми автоматично розгортається як частина рішення.
Програма дозволяє вводити та шукати семантично схожі назви стовпців, вміст стовпців або обидва. Крім того, ви можете вибрати модель вбудовування та кількість найближчих сусідів для повернення з пошуку. Програма отримує вхідні дані, вбудовує введені дані в указану модель і використовує Пошук kNN у OpenSearch Service для пошуку вбудованих індексованих стовпців і пошуку стовпців, найбільш схожих на заданий вхід. Відображені результати пошуку включають назви таблиць, назви стовпців і показники подібності для виявлених стовпців, а також розташування даних в Amazon S3 для подальшого вивчення.
На наступному малюнку показано приклад веб-додатку. У цьому прикладі ми шукали подібні стовпці в нашому озері даних Column Names (тип корисного навантаження), Щоб district (корисне навантаження). Використовуваний додаток all-MiniLM-L6-v2 в якості модель вбудовування і повернувся 10 (k) найближчі сусіди з нашого індексу OpenSearch Service.
Заява повернулася transit_district, city, borough та location як чотири найбільш схожі стовпці на основі даних, проіндексованих у службі OpenSearch. Цей приклад демонструє здатність пошукового підходу ідентифікувати семантично схожі стовпці в наборах даних.

Рисунок 3: Інтерфейс користувача веб-додатку
Прибирати
Щоб видалити ресурси, створені AWS CDK у цьому посібнику, виконайте таку команду:
cdk destroy --allВисновок
У цій публікації ми представили наскрізний робочий процес для створення семантичного пошукового механізму для стовпців таблиці.
Почніть сьогодні працювати зі своїми власними даними за допомогою нашого посібника з коду, доступного на сайті GitHub. Якщо вам потрібна допомога у прискоренні використання ML у ваших продуктах і процесах, зверніться до Лабораторія рішень машинного навчання Amazon.
Про авторів
![]() Качі Одоемене є прикладним науковцем в AWS AI. Він створює рішення AI/ML для вирішення бізнес-проблем для клієнтів AWS.
Качі Одоемене є прикладним науковцем в AWS AI. Він створює рішення AI/ML для вирішення бізнес-проблем для клієнтів AWS.
![]() Тейлор Макнеллі є архітектором глибокого навчання в Amazon Machine Learning Solutions Lab. Він допомагає клієнтам із різних галузей створювати рішення з використанням AI/ML на AWS. Він любить випити гарну каву, відпочити на свіжому повітрі та провести час із сім’єю та енергійною собакою.
Тейлор Макнеллі є архітектором глибокого навчання в Amazon Machine Learning Solutions Lab. Він допомагає клієнтам із різних галузей створювати рішення з використанням AI/ML на AWS. Він любить випити гарну каву, відпочити на свіжому повітрі та провести час із сім’єю та енергійною собакою.
![]() Остін Уелч є спеціалістом з обробки даних у Amazon ML Solutions Lab. Він розробляє спеціальні моделі глибокого навчання, щоб допомогти клієнтам AWS у державному секторі прискорити впровадження ШІ та хмари. У вільний час він захоплюється читанням, подорожами та джиу-джитсу.
Остін Уелч є спеціалістом з обробки даних у Amazon ML Solutions Lab. Він розробляє спеціальні моделі глибокого навчання, щоб допомогти клієнтам AWS у державному секторі прискорити впровадження ШІ та хмари. У вільний час він захоплюється читанням, подорожами та джиу-джитсу.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- Платоблокчейн. Web3 Metaverse Intelligence. Розширені знання. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- здатність
- МЕНЮ
- відсутнім
- прискорювати
- прискорення
- точно
- через
- Додатковий
- Додатково
- Додає
- Прийняття
- просунутий
- AI
- AI / ML
- ВСІ
- дозволяє
- альтернатива
- Amazon
- Амазонське машинне навчання
- Лабораторія рішень Amazon ML
- аналітики
- аналітика
- аналізувати
- та
- Apache
- додаток
- застосування
- прикладної
- підхід
- архітектура
- призначений
- Автоматизований
- автоматично
- доступний
- середній
- AWS
- Клей AWS
- заснований
- оскільки
- Великий
- Великий даних
- приносити
- будувати
- Створюємо
- Будує
- бізнес
- Очищення
- хмара
- прийняття хмари
- кластер
- код
- кави
- збирає
- Колонка
- Колони
- загальний
- порівняний
- контакт
- зміст
- Умовні
- конвертувати
- перероблений
- створювати
- створений
- створює
- Чашка
- виготовлений на замовлення
- Клієнти
- дані
- Analytics даних
- Озеро даних
- якість даних
- вчений даних
- набори даних
- глибокий
- глибоке навчання
- демонструвати
- демонструє
- розгортання
- розгорнути
- розгортання
- знищити
- розробка
- розвивається
- різний
- відкриття
- розрізнені
- Різне
- Пес
- домен
- скачати
- кожен
- ефективність
- ефективний
- кінець в кінець
- Кінцева точка
- двигун
- Ефір (ETH)
- все
- приклад
- дослідження
- витяг
- фасилітувати
- Знайомство
- сім'я
- риси
- Рисунок
- філе
- Файли
- остаточний
- в кінці кінців
- фінансовий
- знайти
- виявлення
- Перший
- після
- формат
- від
- Повний
- функція
- Функції
- далі
- отримати
- даний
- добре
- Уряд
- Заголовки
- допомога
- допомагає
- Як
- How To
- HTML
- HTTPS
- ідентифікований
- ідентифікувати
- здійснювати
- важливо
- in
- нездатність
- включати
- включені
- індекс
- індивідуальний
- промисловості
- інформація
- Інфраструктура
- ініціювати
- Посвячені
- вхід
- інструкції
- взаємодіяти
- інтерактивний
- інтерфейс
- викликає
- залучати
- питання
- IT
- робота
- Джобс
- json
- lab
- озеро
- великий
- шар
- вивчення
- використання
- бібліотека
- список
- загрузка
- місць
- машина
- навчання за допомогою машини
- узгодження
- медичний
- ML
- модель
- Моделі
- більше
- найбільш
- множинний
- ім'я
- Імена
- іменування
- Необхідність
- сусіди
- номер
- запропонований
- онлайн
- Інше
- на відкритому повітрі
- власний
- Паралельні
- параметри
- частина
- plato
- Інформація про дані Платона
- PlatoData
- будь ласка
- пошта
- потенціал
- переважним
- представлений
- попередній
- проблеми
- надходження
- процес
- процеси
- обробка
- Вироблений
- Продукти
- забезпечувати
- забезпечує
- громадськість
- якість
- Сировина
- читання
- отримує
- регулярний
- представляє
- вимагати
- вимагається
- Дослідники
- ресурси
- відповідно
- результати
- повертати
- прогін
- біг
- мудрець
- вчений
- Вчені
- Пошук
- Пошукова система
- Грати короля карти - безкоштовно Nijumi логічна гра гри
- другий
- сектор
- обслуговування
- Послуги
- набори
- показаний
- Шоу
- значний
- аналогічний
- простий
- один
- Розмір
- рішення
- Рішення
- ВИРІШИТИ
- Джерела
- зазначений
- Стажування
- почалася
- Крок
- заходи
- зберігання
- такі
- Опори
- схильний
- таблиця
- Команда
- їх
- через
- час
- до
- сьогодні
- Перетворення
- Трансформатори
- Подорож
- підручник
- використання
- користувач
- Інтерфейс користувача
- різний
- Web
- Веб-додаток
- який
- робочий
- б
- вашу
- зефірнет