Ми живемо в епоху даних і статистичних даних у режимі реального часу, які керуються програмами для потокової передачі даних із низькою затримкою. Сьогодні кожен очікує персоналізованого досвіду в будь-якій програмі, і організації постійно впроваджують інновації, щоб збільшити швидкість ведення бізнесу та прийняття рішень. Обсяг чутливих до часу даних, що створюються, швидко зростає, у нових бізнесах і випадках використання клієнтами впроваджуються різні формати даних. Тому для організацій надзвичайно важливо використовувати масштабовану та надійну інфраструктуру потокового передавання даних із низькою затримкою, щоб надавати бізнес-додатки в режимі реального часу та покращувати взаємодію з клієнтами.
Це перша публікація в серії блогів, яка пропонує загальні архітектурні моделі створення інфраструктур потокового передавання даних у реальному часі з використанням Kinesis Data Streams для широкого спектру випадків використання. Він має на меті забезпечити структуру для створення потокових програм із низькою затримкою в хмарі AWS Потоки даних Amazon Kinesis та Спеціальні служби аналізу даних AWS.
У цій публікації ми розглянемо загальні архітектурні шаблони двох варіантів використання: аналіз даних часових рядів і мікросервіси, керовані подіями. У наступній публікації нашої серії ми досліджуємо архітектурні шаблони побудови потокових конвеєрів для інформаційних панелей BI в реальному часі, агента контакт-центру, даних реєстру, персоналізованих рекомендацій у реальному часі, аналітики журналів, даних IoT, збору змінених даних і реальних -часові маркетингові дані. Усі ці шаблони архітектури інтегровано з Amazon Kinesis Data Streams.
Трансляція в реальному часі за допомогою Kinesis Data Streams
Amazon Kinesis Data Streams — це хмарна безсерверна служба потокового передавання даних, яка дозволяє легко отримувати, обробляти та зберігати дані в реальному часі в будь-якому масштабі. За допомогою Kinesis Data Streams ви можете збирати й обробляти сотні гігабайт даних за секунду із сотень тисяч джерел, що дозволяє легко писати програми, які обробляють інформацію в режимі реального часу. Зібрані дані доступні за мілісекунди, що дозволяє використовувати аналітику в реальному часі, наприклад інформаційні панелі в реальному часі, виявлення аномалій у реальному часі та динамічне ціноутворення. За замовчуванням дані в потокі даних Kinesis зберігаються протягом 24 годин із можливістю збільшення терміну зберігання даних до 365 днів. Якщо клієнти хочуть обробляти ті самі дані в режимі реального часу за допомогою кількох програм, вони можуть скористатися функцією Enhanced Fan-Out (EFO). До цієї функції кожна програма, яка споживала дані з потоку, спільно використовувала вихідні дані 2 МБ/с/фрагмент. Налаштувавши споживачів потоку на використання розширеного розгалуження, кожен споживач даних отримує спеціальну пропускну здатність читання зі швидкістю 2 МБ/с на шард, щоб ще більше зменшити затримку під час отримання даних.
Для високої доступності та довговічності Kinesis Data Streams забезпечує високу надійність завдяки синхронній реплікації потокових даних у трьох зонах доступності в регіоні AWS і дає вам можливість зберігати дані до 365 днів. Для безпеки Kinesis Data Streams забезпечує шифрування на стороні сервера, щоб ви могли відповідати суворим вимогам до керування даними, шифруючи свої дані в стані спокою та кінцеві точки інтерфейсу Amazon Virtual Private Cloud (VPC), щоб зберегти конфіденційність трафіку між вашим Amazon VPC і Kinesis Data Streams.
Kinesis Data Streams має вбудовану інтеграцію з іншими службами AWS, такими як Клей AWS та Amazon EventBridge створювати потокові програми в реальному часі на AWS. Щоб отримати додаткові відомості, зверніться до інтеграції Amazon Kinesis Data Streams.
Сучасна архітектура потокового передавання даних із Kinesis Data Streams
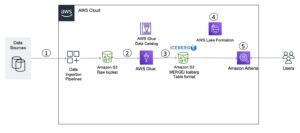
Сучасну архітектуру потокових даних із Kinesis Data Streams можна спроектувати як стек із п’яти логічних рівнів; кожен рівень складається з кількох спеціально створених компонентів, які відповідають конкретним вимогам, як показано на наступній схемі:
Архітектура складається з таких ключових компонентів:
- Джерела потокового передавання – Ваше джерело потокових даних включає такі джерела даних, як дані потоку кліків, датчики, соціальні мережі, пристрої Інтернету речей (IoT), файли журналів, створені за допомогою ваших веб- і мобільних програм, а також мобільні пристрої, які генерують напівструктуровані та неструктуровані дані як безперервні потоки. на високій швидкості.
- Передача потоку – Рівень прийому потоку відповідає за прийом даних у рівень зберігання потоку. Він надає можливість збирати дані з десятків тисяч джерел даних і завантажувати їх у режимі реального часу. Ви можете використовувати Kinesis SDK для отримання потокових даних через API, Бібліотека Kinesis Producer для створення високопродуктивних і довготривалих потокових виробників, або a Kinesis агент для збору набору файлів і введення їх у потоки даних Kinesis. Крім того, ви можете використовувати багато інтеграцій перед збіркою, наприклад Служба міграції бази даних AWS (AWS DMS), Amazon DynamoDB та Ядро AWS IoT завантажувати дані без використання коду. Ви також можете отримати дані зі сторонніх платформ, таких як Apache Spark і Apache Kafka Connect
- Зберігання потоку – Kinesis Data Streams пропонує два режими для підтримки пропускної здатності даних: On-Demand і Provisioned. Режим On-Demand, який тепер є вибором за замовчуванням, може пружно масштабуватися для поглинання змінної пропускної здатності, тож клієнтам не потрібно турбуватися про керування потужністю та платити за пропускну здатність даних. Режим On-Demand автоматично вдвічі збільшує пропускну здатність потоку в порівнянні з історичним максимальним надходженням даних, щоб забезпечити достатню пропускну здатність для неочікуваних різких скачків надходження даних. Крім того, клієнти, яким потрібен детальний контроль над потоковими ресурсами, можуть використовувати режим Provisioned і завчасно збільшувати та зменшувати кількість сегментів відповідно до своїх вимог щодо пропускної здатності. Крім того, Kinesis Data Streams може зберігати потокові дані до 2 годин за замовчуванням, але може продовжуватися до 24 або 7 днів залежно від випадків використання. Кілька додатків можуть споживати той самий потік.
- Обробка потоку – Рівень потокової обробки відповідає за перетворення даних у споживаний стан за допомогою перевірки даних, очищення, нормалізації, трансформації та збагачення. Потокові записи зчитуються в тому порядку, в якому вони були створені, що дозволяє проводити аналітику в реальному часі, створювати додатки, керовані подіями, або потокову передачу ETL (вилучення, перетворення та завантаження). Ви можете використовувати Керована служба Amazon для Apache Flink для обробки складних потокових даних, AWS Lambda для обробки потокових даних без збереження стану та Клей AWS & Amazon EMR для обчислень майже в реальному часі. Ви також можете створювати індивідуальні споживчі програми за допомогою Споживча бібліотека Kinesis, який вирішуватиме багато складних завдань, пов’язаних із розподіленими обчисленнями.
- Пункт призначення – Цільовий рівень подібний до спеціально створеного призначення залежно від вашого випадку використання. Ви можете передавати дані безпосередньо на Амазонська червона зміна для сховищ даних і Amazon EventBridge для створення програм, керованих подіями. Ви також можете використовувати Amazon Kinesis Data Firehose для потокової інтеграції, де ви можете легко потоково обробляти за допомогою AWS Lambda, а потім доставляти оброблену потокову передачу в такі пункти призначення Amazon S3 озеро даних, служба OpenSearch для операційної аналітики, сховище даних Redshift, бази даних без SQL, такі як Amazon DynamoDB, і реляційні бази даних, такі як Amazon RDS використовувати потоки в реальному часі для бізнес-додатків. Місцем призначення може бути керована подіями програма для інформаційних панелей у реальному часі, автоматичні рішення на основі оброблених потокових даних, зміни в реальному часі тощо.
Архітектура аналітики в реальному часі для часових рядів
Дані часових рядів – це послідовність точок даних, записаних протягом певного інтервалу часу для вимірювання подій, які змінюються з часом. Прикладами є курси акцій у часі, кліки веб-сторінок і журнали пристроїв у часі. Клієнти можуть використовувати дані часових рядів для моніторингу змін у часі, щоб вони могли виявляти аномалії, визначати закономірності та аналізувати вплив певних змінних з часом. Дані часових рядів, як правило, генеруються з кількох джерел у великих обсягах, і їх потрібно збирати в режимі майже реального часу з економічною ефективністю.
Як правило, є три основні цілі, яких клієнти хочуть досягти під час обробки даних часових рядів:
- Отримуйте статистичні дані в реальному часі про продуктивність системи та виявляйте аномалії
- Зрозумійте поведінку кінцевих користувачів, щоб відстежувати тенденції та створювати запити та візуалізації на основі цих статистичних даних.
- Майте надійне рішення для зберігання та зберігання як архівних, так і часто використовуваних даних.
За допомогою Kinesis Data Streams клієнти можуть безперервно отримувати терабайти даних часових рядів із тисяч джерел для очищення, збагачення, зберігання, аналізу та візуалізації.
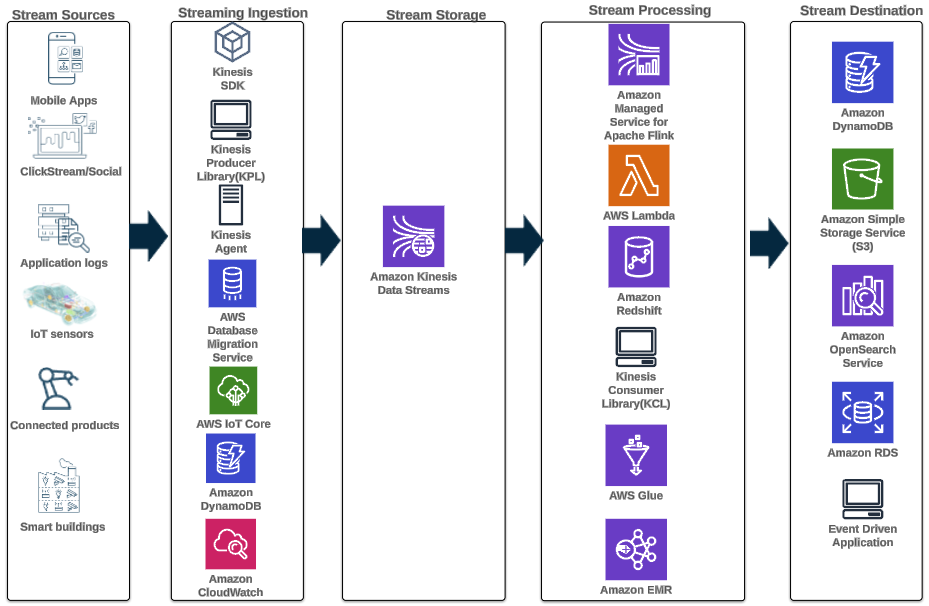
Наступний шаблон архітектури ілюструє, як можна досягти аналітики в реальному часі для даних часових рядів за допомогою потоків даних Kinesis:
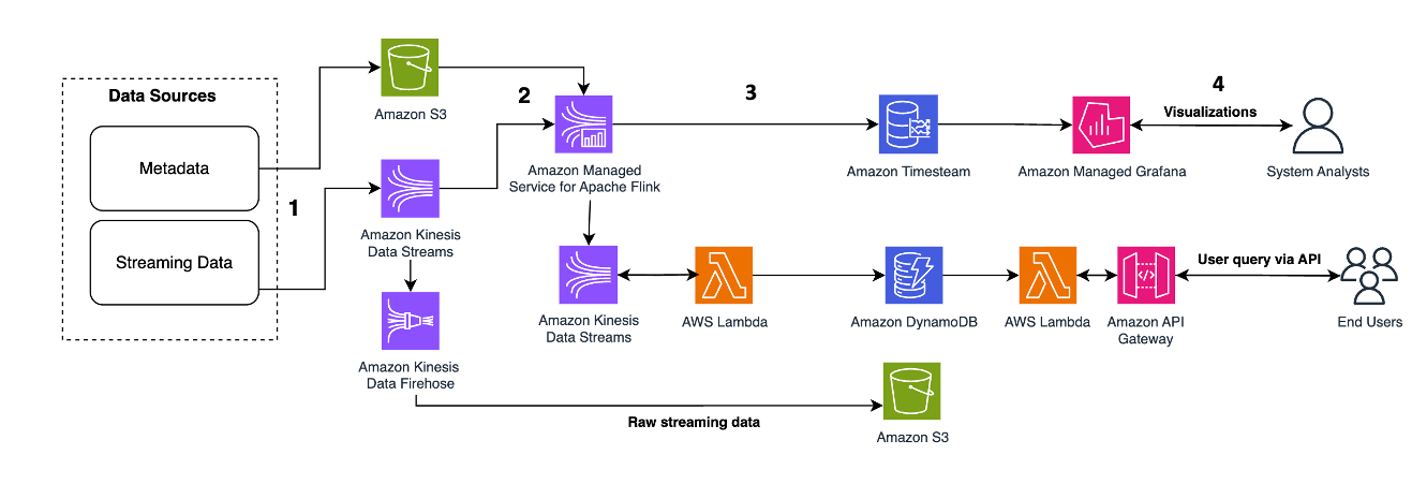
Етапи робочого процесу такі:
- Приймання та зберігання даних – Kinesis Data Streams може постійно отримувати та зберігати терабайти даних із тисяч джерел.
- Обробка потоку – Додаток, створений за допомогою Керована служба Amazon для Apache Flink може зчитувати записи з потоку даних, щоб виявити та усунути будь-які помилки в даних часових рядів і збагатити дані певними метаданими для оптимізації операційної аналітики. Використання потоку даних посередині забезпечує перевагу використання даних часових рядів в інших процесах і рішеннях одночасно. Потім з цими подіями викликається лямбда-функція, яка може виконувати обчислення часових рядів у пам’яті.
- напрями – Після очищення та збагачення оброблені дані часового ряду можна передавати в потік Amazon Timestream база даних для панелі керування та аналізу в реальному часі або зберігається в базах даних, таких як DynamoDB для запитів кінцевого користувача. Необроблені дані можна передавати на Amazon S3 для архівування.
- Візуалізація та отримання інформації – Клієнти можуть запитувати, візуалізувати та створювати сповіщення за допомогою Керована служба Amazon для Grafana. Grafana підтримує джерела даних, які є сховищем даних часових рядів. Щоб отримати доступ до своїх даних із Timestream, вам потрібно встановити плагін Timestream для Grafana. Кінцеві користувачі можуть запитувати дані з таблиці DynamoDB за допомогою API -шлюз Amazon діючи як довірена особа.
Відноситься до Обробка майже в реальному часі за допомогою Amazon Kinesis, Amazon Timestream і Grafana демонстрація безсерверного потокового конвеєра для обробки та зберігання телеметричних даних пристрою IoT в оптимізованому часовому ряду сховищі даних, такому як Amazon Timestream.
Збагачення та відтворення даних у режимі реального часу для мікросервісів джерела подій
Мікросервіси — це архітектурний та організаційний підхід до розробки програмного забезпечення, де програмне забезпечення складається з невеликих незалежних служб, які спілкуються через чітко визначені API. Створюючи керовані подіями мікросервіси, клієнти хочуть досягти 1. високої масштабованості для обробки обсягу вхідних подій і 2. надійності обробки подій і підтримки функціональності системи в умовах збоїв.
Клієнти використовують шаблони архітектури мікросервісів, щоб пришвидшити інновації та час виходу на ринок нових функцій, оскільки це полегшує масштабування додатків і прискорює розробку. Однак складно збагачувати та відтворювати дані під час мережевого виклику до іншого мікросервісу, оскільки це може вплинути на надійність програми та ускладнити налагодження та відстеження помилок. Щоб вирішити цю проблему, пошук подій є ефективним шаблоном проектування, який централізує історичні записи всіх змін стану для збагачення та відтворення, а також відокремлює навантаження читання від запису. Клієнти можуть використовувати Kinesis Data Streams як централізоване сховище подій для мікросервісів джерела подій, оскільки KDS може 1/ обробляти пропускну здатність гігабайтів даних на секунду на потік і передавати дані за мілісекунди, щоб відповідати вимогам щодо високої масштабованості та майже в реальному часі. затримка, 2/ інтеграція з Flink і S3 для збагачення даних і досягнення результатів, будучи повністю від’єднаною від мікросервісів, і 3/ дозволити повторну спробу й асинхронне читання пізніше, оскільки KDS зберігає запис даних протягом 24 годин за замовчуванням, і за бажанням до 365 днів.
Наступний архітектурний шаблон є загальною ілюстрацією того, як потоки даних Kinesis можна використовувати для мікросервісів джерела подій:
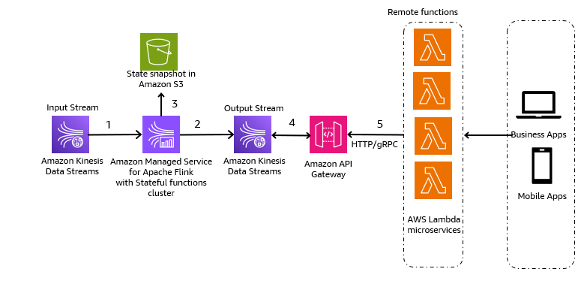
Етапи робочого процесу такі:
- Приймання та зберігання даних – Ви можете агрегувати вхідні дані від своїх мікросервісів у потоки даних Kinesis для зберігання.
- Потокова обробка - Функції визначення стану Apache Flink спрощує створення розподілених програм, керованих подіями. Він може отримувати події з вхідного потоку даних Kinesis і направляти отриманий потік до вихідного потоку даних. Ви можете створити кластер функцій із збереженням стану за допомогою Apache Flink на основі бізнес-логіки програми.
- Знімок стану в Amazon S3 – Ви можете зберегти знімок стану в Amazon S3 для відстеження.
- Вихідні потоки – Вихідні потоки можуть використовуватися через віддалені функції Lambda через протокол HTTP/gRPC через шлюз API.
- Лямбда дистанційні функції – Лямбда-функції можуть діяти як мікросервіси для різних додатків і бізнес-логіки для обслуговування бізнес-додатків і мобільних додатків.
Щоб дізнатися, як інші клієнти створили свої мікросервіси на основі подій за допомогою потоків даних Kinesis, зверніться до наступного:
Основні міркування та найкращі практики
Нижче наведено міркування та найкращі практики, про які слід пам’ятати.
- Виявлення даних має бути вашим першим кроком у створенні сучасних програм потокового передавання даних. Щоб досягти бажаних бізнес-результатів, ви повинні визначити бізнес-цінність, а потім визначити джерела потокових даних і особи користувачів.
- Виберіть інструмент прийому потокових даних на основі вашого джерела даних. Наприклад, ви можете використовувати Kinesis SDK для отримання потокових даних через API, Бібліотека Kinesis Producer для створення високопродуктивних і довгострокових потокових виробників, a Kinesis агент для збору набору файлів і введення їх у потоки даних Kinesis, AWS DMS для сценаріїв потокового використання CDC і Ядро AWS IoT для передачі даних пристрою IoT у потоки даних Kinesis. Ви можете завантажувати потокові дані безпосередньо в Amazon Redshift, щоб створювати потокові програми з низькою затримкою. Ви також можете використовувати бібліотеки сторонніх розробників, такі як Apache Spark і Apache Kafka, щоб завантажувати потокові дані в Kinesis Data Streams.
- Вам потрібно вибрати послуги обробки потокових даних на основі конкретного випадку використання та бізнес-вимог. Наприклад, ви можете використовувати керовану службу Amazon Kinesis для Apache Flink для розширених сценаріїв використання потокової передачі з кількома напрямками потокової передачі та складною обробкою потоку з відстеженням стану або якщо ви хочете відстежувати бізнес-метрики в режимі реального часу (наприклад, щогодини). Lambda добре підходить для обробки на основі подій і без збереження стану. Ви можете використовувати Amazon EMR для потокової обробки даних, щоб використовувати ваші улюблені фреймворки великих даних з відкритим кодом. AWS Glue добре підходить для обробки потокових даних майже в реальному часі для таких випадків використання, як потокове ETL.
- У режимі Kinesis Data Streams on demand стягується плата за використання та автоматично збільшується ємність ресурсів, тому він підходить для стрімкого потокового навантаження та обслуговування без використання рук. Наданий режим оплачується залежно від потужності та вимагає проактивного керування потужністю, тому він підходить для передбачуваних потокових навантажень.
- Ви можете використовувати Спільний калькулятор Kinesis щоб обчислити кількість фрагментів, необхідних для режиму підготовки. Вам не потрібно турбуватися про шарди в режимі на вимогу.
- Надаючи дозволи, ви вирішуєте, хто отримає які дозволи на які ресурси Kinesis Data Streams. Ви вмикаєте певні дії, які хочете дозволити на цих ресурсах. Тому слід надавати лише ті дозволи, які необхідні для виконання завдання. Ви також можете зашифрувати дані в стані спокою за допомогою ключа KMS, керованого клієнтом (CMK).
- Ти можеш оновити термін зберігання через консоль Kinesis Data Streams або за допомогою ЗбільшитиStreamRetentionPeriod і DecreaseStreamRetentionPeriod операції на основі ваших конкретних випадків використання.
- Підтримує Kinesis Data Streams перешардинг. Рекомендований API для цієї функції UpdateHardCount, що дозволяє змінювати кількість сегментів у вашому потоці, щоб адаптуватися до змін у швидкості потоку даних через потік. API повторного шардування (Split і Merge) зазвичай використовуються для обробки гарячих фрагментів.
Висновок
У цьому дописі продемонстровано різні архітектурні моделі для створення потокових програм із низькою затримкою за допомогою потоків даних Kinesis. Ви можете створювати власні додатки для обробки з низькою затримкою за допомогою Kinesis Data Streams, використовуючи інформацію в цій публікації.
Щоб отримати докладні архітектурні шаблони, зверніться до таких ресурсів:
Якщо ви хочете побудувати бачення даних і стратегію, перегляньте Все, кероване даними AWS (D2E) програма.
Про авторів
 Рагхаварао Содабатіна є головним архітектором рішень в AWS, який спеціалізується на аналітиці даних, AI/ML і хмарній безпеці. Він співпрацює з клієнтами, щоб створювати інноваційні рішення, які вирішують бізнес-проблеми клієнтів і прискорюють впровадження послуг AWS. У вільний час Рагхаварао любить проводити час із сім’єю, читати книги та дивитися фільми.
Рагхаварао Содабатіна є головним архітектором рішень в AWS, який спеціалізується на аналітиці даних, AI/ML і хмарній безпеці. Він співпрацює з клієнтами, щоб створювати інноваційні рішення, які вирішують бізнес-проблеми клієнтів і прискорюють впровадження послуг AWS. У вільний час Рагхаварао любить проводити час із сім’єю, читати книги та дивитися фільми.
 Хан Цзо є старшим менеджером із продуктів у команді Amazon Kinesis Data Streams у Amazon Web Services. Він захоплений розробкою інтуїтивно зрозумілих продуктів, які вирішують складні проблеми клієнтів і дозволяють клієнтам досягати своїх бізнес-цілей.
Хан Цзо є старшим менеджером із продуктів у команді Amazon Kinesis Data Streams у Amazon Web Services. Він захоплений розробкою інтуїтивно зрозумілих продуктів, які вирішують складні проблеми клієнтів і дозволяють клієнтам досягати своїх бізнес-цілей.
 Швета Радхакрішнан є архітектором рішень для AWS і спеціалізується на аналізі даних. Вона розробляє рішення, які сприяють впровадження хмарних технологій і допомагають організаціям приймати рішення на основі даних у державному секторі. Поза роботою вона любить танцювати, проводити час з друзями та родиною та подорожувати.
Швета Радхакрішнан є архітектором рішень для AWS і спеціалізується на аналізі даних. Вона розробляє рішення, які сприяють впровадження хмарних технологій і допомагають організаціям приймати рішення на основі даних у державному секторі. Поза роботою вона любить танцювати, проводити час з друзями та родиною та подорожувати.
 Бріттані Лі є архітектором рішень в AWS. Вона зосереджена на тому, щоб допомогти корпоративним клієнтам із впровадженням і модернізацією хмарних технологій, а також цікавиться сферою безпеки та аналітики. Поза роботою вона любить проводити час зі своїм собакою та грати в піклбол.
Бріттані Лі є архітектором рішень в AWS. Вона зосереджена на тому, щоб допомогти корпоративним клієнтам із впровадженням і модернізацією хмарних технологій, а також цікавиться сферою безпеки та аналітики. Поза роботою вона любить проводити час зі своїм собакою та грати в піклбол.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/
- : має
- :є
- : ні
- :де
- $UP
- 1
- 100
- 24
- 7
- a
- здатність
- МЕНЮ
- прискорювати
- доступ
- доступний
- Achieve
- досягнутий
- Досягає
- досягнення
- через
- Діяти
- діючий
- дії
- пристосовувати
- доповнення
- Додатковий
- Додатково
- адреса
- Прийняття
- просунутий
- Перевага
- після
- вік
- Агент
- сукупність
- AI / ML
- Цілі
- оповіщень
- ВСІ
- дозволяти
- Дозволити
- дозволяє
- Також
- Amazon
- Амазонський кінезіс
- Amazon Timestream
- Amazon Web Services
- an
- аналіз
- аналітика
- аналізувати
- та
- виявлення аномалії
- Інший
- будь-який
- Apache
- Апач Кафка
- Apache Spark
- API
- Інтерфейси
- додаток
- застосування
- підхід
- додатка
- архітектурний
- архітектура
- ЕСТЬ
- AS
- асоційований
- At
- автоматичний
- автоматично
- наявність
- доступний
- AWS
- Клей AWS
- AWS Lambda
- заснований
- BE
- оскільки
- було
- поведінка
- буття
- КРАЩЕ
- передового досвіду
- Краще
- між
- Великий
- Великий даних
- Блог
- книги
- обидва
- будувати
- Створюємо
- побудований
- бізнес
- Бізнес-додатки
- підприємства
- але
- by
- обчислювати
- call
- CAN
- потужність
- захоплення
- який
- випадок
- випадків
- CDC
- Центр
- централізована
- певний
- складні
- зміна
- Зміни
- вантажі
- перевірка
- вибір
- Вибирати
- очистити
- Очищення
- хмара
- прийняття хмари
- Хмара безпеки
- кластер
- збирати
- Збір
- загальний
- спілкуватися
- повністю
- комплекс
- Компоненти
- складається
- обчислення
- обчислення
- стурбований
- конфігурування
- міркування
- складається
- Консоль
- постійно
- споживати
- спожитий
- споживач
- Споживачі
- контакт
- контакт-центр
- безперервний
- постійно
- контроль
- створювати
- створений
- критичний
- клієнт
- Клієнти
- налаштувати
- танці
- інформаційні панелі
- дані
- аналіз даних
- Analytics даних
- збагачення даних
- Озеро даних
- управління даними
- точки даних
- обробка даних
- сховище даних
- керовані даними
- Database
- базами даних
- Днів
- вирішувати
- рішення
- Прийняття рішень
- рішення
- відокремлені
- присвячених
- дефолт
- визначати
- доставляти
- продемонстрований
- Залежно
- дизайн
- призначений
- бажаний
- призначення
- напрямки
- докладно
- деталі
- виявляти
- Виявлення
- розвивати
- розвивається
- розробка
- пристрій
- прилади
- різний
- важкий
- безпосередньо
- відкриття
- розподілений
- розподілені обчислення
- do
- Пес
- Не знаю
- вниз
- управляти
- керований
- довговічність
- динамічний
- кожен
- легше
- легко
- легко
- Ефективний
- обійняти
- включіть
- шифрування
- кінцеві точки
- займається
- підвищена
- збагачувати
- підприємство
- корпоративні клієнти
- помилки
- Ефір (ETH)
- Event
- Події
- Кожен
- все
- приклад
- Приклади
- чекає
- досвід
- Досліди
- дослідити
- продовжити
- витяг
- Face
- збої
- сім'я
- мода
- швидше
- Улюблений
- особливість
- риси
- поле
- Файли
- Перший
- п'ять
- потік
- Сфокусувати
- увагу
- фокусування
- після
- слідує
- для
- Рамки
- каркаси
- часто
- друзі
- від
- функція
- функціональність
- Функції
- далі
- Отримувати
- шлюз
- породжувати
- генерується
- отримання
- GitHub
- дає
- Цілі
- добре
- надавати
- Надання
- обробляти
- Вішати
- he
- допомога
- допомогу
- її
- Високий
- висока продуктивність
- його
- історичний
- ГАРЯЧА
- годину
- ГОДИННИК
- Як
- Однак
- HTML
- HTTP
- HTTPS
- Сотні
- ідентифікувати
- if
- ілюструє
- Impact
- in
- В інших
- includes
- Вхідний
- Augmenter
- зростаючий
- незалежний
- під впливом
- інформація
- Інфраструктура
- інфраструктура
- інноваційний
- інновація
- інноваційний
- вхід
- розуміння
- встановлювати
- інтегрувати
- інтегрований
- інтеграція
- інтеграцій
- інтерес
- інтерфейс
- інтернет
- Інтернет речей
- в
- введені
- інтуїтивний
- викликали
- КАТО
- Пристрій IoT
- IT
- ЙОГО
- подорож
- JPG
- кафка
- тримати
- ключ
- Потоки даних Kinesis
- озеро
- Затримка
- пізніше
- шар
- шарів
- УЧИТЬСЯ
- Гросбух
- libraries
- бібліотека
- світло
- як
- життя
- загрузка
- журнал
- логіка
- логічний
- любить
- підтримувати
- обслуговування
- зробити
- РОБОТИ
- Робить
- вдалося
- управління
- менеджер
- багато
- Маркетинг
- максимальний
- вимір
- Медіа
- Зустрічатися
- пам'ять
- Злиття
- метадані
- Метрика
- мікросервіс
- Середній
- міграція
- мілісекунд
- mind
- Mobile
- Мобільні програми
- мобільні пристрої
- мобільні Програми-
- режим
- сучасний
- модернізація
- Режими
- змінювати
- монітор
- більше
- кіно
- множинний
- повинен
- рідний
- Близько
- Необхідність
- необхідний
- потреби
- мережу
- Нові
- Нові можливості
- зараз
- номер
- of
- пропонувати
- Пропозиції
- on
- On-Demand
- тільки
- відкрити
- з відкритим вихідним кодом
- операція
- оперативний
- операції
- Оптимізувати
- оптимізований
- варіант
- or
- порядок
- організаційної
- організації
- Інше
- наші
- з
- Результати
- вихід
- поза
- над
- власний
- частина
- пристрасний
- Викрійки
- моделі
- Платити
- для
- виконувати
- продуктивність
- Дозволи
- Персоналізовані
- труба
- трубопровід
- Платформи
- plato
- Інформація про дані Платона
- PlatoData
- Play
- підключати
- точок
- пошта
- практики
- Передбачуваний
- ціни
- ціни без прихованих комісій
- первинний
- Головний
- попередній
- приватний
- Проактивний
- Проблема
- проблеми
- процес
- оброблена
- процеси
- обробка
- Вироблений
- виробник
- Виробники
- Product
- менеджер по продукції
- програма
- протокол
- забезпечувати
- забезпечує
- повноваження
- громадськість
- діапазон
- швидко
- ставка
- Сировина
- необроблені дані
- Читати
- читання
- реальний
- реального часу
- дані в режимі реального часу
- отримати
- отримує
- Рекомендація
- рекомендований
- запис
- записаний
- облік
- зменшити
- послатися
- регіон
- надійність
- надійний
- віддалений
- вимагається
- вимога
- Вимога
- Вимагається
- ресурс
- ресурси
- відповідальний
- REST
- в результаті
- зберігати
- зберігає
- утримання
- огляд
- Маршрут
- то ж
- масштабованість
- масштабовані
- шкала
- ваги
- другий
- сектор
- безпеку
- старший
- датчиків
- Послідовність
- Серія
- служити
- Без сервера
- обслуговування
- Послуги
- комплект
- загальні
- вона
- Повинен
- демонстрація
- спрощує
- невеликий
- Знімок
- So
- соціальна
- соціальні медіа
- Софтвер
- розробка програмного забезпечення
- рішення
- Рішення
- ВИРІШИТИ
- Source
- Джерела
- Іскритися
- конкретний
- швидкість
- витрачати
- Витрати
- шипи
- розкол
- стек
- стан
- Крок
- заходи
- акції
- зберігання
- зберігати
- зберігати
- Стратегія
- потік
- потоковий
- потоковий
- потоки
- строгий
- наступні
- такі
- достатній
- підтримка
- Опори
- система
- таблиця
- Приймати
- Завдання
- завдання
- команда
- тензор
- Що
- Команда
- інформація
- Держава
- їх
- Їх
- потім
- Там.
- отже
- Ці
- вони
- речі
- третя сторона
- це
- ті
- тисячі
- три
- через
- пропускна здатність
- час
- Часовий ряд
- чутливий до часу
- до
- сьогодні
- інструмент
- простежувати
- трек
- Відстеження
- трафік
- Перетворення
- Перетворення
- перетворення
- Подорож
- Тенденції
- два
- типово
- Unexpected
- на
- Використання
- використання
- використання випадку
- використовуваний
- користувач
- використання
- використовувати
- перевірка достовірності
- значення
- змінна
- різний
- VeloCity
- через
- Віртуальний
- бачення
- візуалізації
- візуалізувати
- обсяг
- Обсяги
- хотіти
- Склад
- Складування
- спостереження
- we
- Web
- веб-сервіси
- добре визначений
- Що
- коли
- який
- в той час як
- ВООЗ
- широкий
- Широкий діапазон
- волі
- з
- в
- Work
- робочий
- турбуватися
- запис
- ви
- вашу
- зефірнет
- зони