Це гостьовий допис А. К. Роя з Qualcomm AI.
Amazon Elastic Compute Cloud (Amazon EC2) Екземпляри DL2q на базі прискорювачів Qualcomm AI 100 Standard можна використовувати для економічно ефективного розгортання робочих навантажень глибокого навчання (DL) у хмарі. Їх також можна використовувати для розробки та перевірки продуктивності та точності робочих навантажень DL, які будуть розгорнуті на пристроях Qualcomm. Екземпляри DL2q — це перші екземпляри, які перенесли технологію штучного інтелекту (AI) Qualcomm у хмару.
Завдяки восьми прискорювачам Qualcomm AI 100 Standard і загальній пам’яті прискорювача 128 ГіБ клієнти також можуть використовувати екземпляри DL2q для запуску популярних генеративних програм штучного інтелекту, таких як генерація вмісту, узагальнення тексту та віртуальних помічників, а також класичних програм штучного інтелекту для обробки природної мови. і комп'ютерний зір. Крім того, прискорювачі Qualcomm AI 100 використовують ту саму технологію штучного інтелекту, що використовується для смартфонів, автономного водіння, персональних комп’ютерів і гарнітур розширеної реальності, тому екземпляри DL2q можна використовувати для розробки та перевірки цих робочих навантажень штучного інтелекту перед розгортанням.
Основні моменти нового екземпляра DL2q
Кожен екземпляр DL2q включає вісім прискорювачів Qualcomm Cloud AI100 із сукупною продуктивністю понад 2.8 PetaOps продуктивності логічного висновку Int8 і 1.4 PetaFlop продуктивності висновку FP16. Екземпляр має сукупність 112 ядер ШІ, ємність пам’яті прискорювача 128 ГБ і пропускну здатність пам’яті 1.1 ТБ в секунду.
Кожен екземпляр DL2q має 96 vCPU, ємність системної пам’яті 768 ГБ і підтримує пропускну здатність мережі 100 Гбіт/с, а також Amazon Elastic Block Store (Amazon EBS) зберігання 19 Гбіт/с.
| Ім'я екземпляра | vCPU | Хмарні прискорювачі AI100 | Прискорювач пам'яті | Прискорювач пам'яті BW (агрегований) | Пам'ять примірників | Мережа екземплярів | Пропускна здатність сховища (Amazon EBS). |
| DL2q.24xlarge | 96 | 8 | 128 GB | 1.088 TB / с | 768 GB | 100 Gbps | 19 Gbps |
Інноваційний прискорювач Qualcomm Cloud AI100
Прискорювальна система Cloud AI100 на чіпі (SoC) — це спеціально створена масштабована багатоядерна архітектура, яка підтримує широкий спектр сценаріїв використання глибокого навчання від центру обробки даних до периферії. SoC використовує скалярні, векторні та тензорні обчислювальні ядра з провідною в галузі вбудованою SRAM ємністю 126 МБ. Ядра з’єднані між собою високошвидкісною сіткою мережі на кристалі (NoC) з низькою затримкою.
Прискорювач AI100 підтримує широкий і повний діапазон моделей і варіантів використання. У таблиці нижче показано діапазон підтримки моделі.
| Категорія моделі | кількість моделей | Приклади |
| НЛП | 157 | BERT, BART, FasterTransformer, T5, Z-код MOE |
| Генеративний ШІ – НЛП | 40 | LLaMA, CodeGen, GPT, OPT, BLOOM, Jais, Luminous, StarCoder, XGen |
| Generative AI – Image | 3 | Стабільна дифузія v1.5 і v2.1, OpenAI CLIP |
| CV – Класифікація зображень | 45 | ViT, ResNet, ResNext, MobileNet, EfficientNet |
| CV – виявлення об’єктів | 23 | YOLO v2, v3, v4, v5 і v7, SSD-ResNet, RetinaNet |
| CV – інше | 15 | LPRNet, Супер-роздільна здатність/SRGAN, ByteTrack |
| Автомобільні мережі* | 53 | Сприйняття та LIDAR, виявлення пішоходів, смуг і світлофорів |
| Всього | > 300 | |
* Більшість автомобільних мереж є складеними мережами, що складаються із злиття окремих мереж.
Велика вбудована пам’ять SRAM на прискорювачі DL2q дозволяє ефективно впроваджувати передові методи продуктивності, такі як точність мікроекспоненти MX6 для збереження вагових коефіцієнтів і точність мікроекспоненти MX9 для зв’язку між прискорювачем. Технологія micro-exponent описана в наступному галузевому оголошенні Open Compute Project (OCP): AMD, Arm, Intel, Meta, Microsoft, NVIDIA та Qualcomm стандартизують вузькі формати даних наступного покоління для штучного інтелекту » Open Compute Project.
Користувач екземпляра може використовувати таку стратегію, щоб максимізувати ефективність за вартість:
- Зберігайте ваги за допомогою точності мікроекспоненти MX6 у вбудованій пам’яті DDR прискорювача. Використання MX6 precision максимізує використання доступної ємності та пропускної здатності пам’яті, щоб забезпечити найкращу в своєму класі пропускну здатність і затримку.
- Обчислюйте в FP16, щоб забезпечити необхідну точність варіантів використання, використовуючи чудову вбудовану SRAM і запасні TOP на карті, щоб реалізувати високопродуктивні ядра з низькою затримкою від MX6 до FP16.
- Використовуйте оптимізовану стратегію пакетування та більший розмір пакету, використовуючи доступну велику вбудовану пам’ять SRAM, щоб максимізувати повторне використання вагових коефіцієнтів, максимально зберігаючи активації на кристалі.
Стек і інструментальний ланцюжок DL2q AI
Екземпляр DL2q супроводжується Qualcomm AI Stack, який забезпечує узгоджену роботу розробника в Qualcomm AI у хмарі та інших продуктах Qualcomm. Той самий стек і базова технологія штучного інтелекту Qualcomm працюють на екземплярах DL2q і крайніх пристроях Qualcomm, забезпечуючи клієнтам узгоджену роботу розробника з уніфікованим API для хмарних середовищ, середовищ розробки автомобілів, персональних комп’ютерів, розширеної реальності та смартфонів.
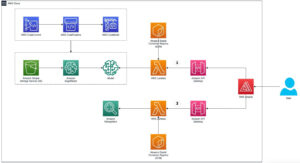
Ланцюжок інструментів дозволяє користувачеві екземпляра швидко ввімкнути попередньо навчену модель, скомпілювати та оптимізувати модель для можливостей екземпляра, а потім розгорнути скомпільовані моделі для сценаріїв використання виробничого висновку за три етапи, показані на малюнку нижче.

Щоб дізнатися більше про налаштування продуктивності моделі, див Ключові параметри продуктивності Cloud AI 100 Документація.
Почніть роботу з екземплярами DL2q
У цьому прикладі ви компілюєте та розгортаєте попередньо навчений Модель BERT від Обіймати обличчя на екземплярі EC2 DL2q, використовуючи попередньо зібраний доступний DL2q AMI, у чотири кроки.
Ви можете використовувати будь-який готовий Qualcomm DLAMI на екземплярі або почніть з Amazon Linux2 AMI і створіть власний DL2q AMI за допомогою Cloud AI 100 Platform and Apps SDK, доступного в цьому Служба простого зберігання Amazon (Amazon S3) відро: s3://ec2-linux-qualcomm-ai100-sdks/latest/.
У наступних кроках використовується попередньо зібраний DL2q AMI, База Qualcomm AL2 DLAMI.
Використовуйте SSH для доступу до екземпляра DL2q за допомогою Qualcomm Base AL2 DLAMI AMI та виконайте кроки з 1 по 4.
Крок 1. Налаштуйте середовище та встановіть необхідні пакети
- Встановіть Python 3.8.
- Налаштуйте віртуальне середовище Python 3.8.
- Активуйте віртуальне середовище Python 3.8.
- Встановіть необхідні пакети, показані в документ requirements.txt доступний на загальнодоступному сайті Github Qualcomm.
- Імпортуйте необхідні бібліотеки.
Крок 2. Імпортуйте модель
- Імпортуйте та токенізувати модель.
- Визначте зразок введення та витягніть
inputIdsтаattentionMask. - Перетворіть модель на ONNX, яку потім можна передати компілятору.
- Ви запустите модель із точністю FP16. Отже, вам потрібно перевірити, чи модель містить константи за межами діапазону FP16. Передайте модель
fix_onnx_fp16для створення нового файлу ONNX із потрібними виправленнями.
Крок 3. Скомпілюйте модель
Команда qaic-exec Інструмент компілятора інтерфейсу командного рядка (CLI) використовується для компіляції моделі. Вхідними даними для цього компілятора є файл ONNX, згенерований на кроці 2. Компілятор створює двійковий файл (званий QPC, Для Контейнер програм Qualcomm) у шляху, визначеному -aic-binary-dir аргумент.
У наведеній нижче команді компіляції ви використовуєте чотири обчислювальних ядра штучного інтелекту та розмір пакету в одне для компіляції моделі.
QPC генерується в bert-base-cased/generatedModels/bert-base-cased_fix_outofrange_fp16_qpc папку.
Крок 4. Запустіть модель
Налаштуйте сеанс для запуску висновку на прискорювачі Qualcomm Cloud AI100 в екземплярі DL2q.
Бібліотека Qualcomm qaic Python — це набір API, який забезпечує підтримку запуску висновків у прискорювачі Cloud AI100.
- Використовуйте виклик API сеансу, щоб створити екземпляр сеансу. Виклик API сеансу є точкою входу до використання бібліотеки qaic Python.
- Реструктуруйте дані з вихідного буфера за допомогою
output_shapeтаoutput_type. - Розшифруйте отриманий результат.
Ось вихідні дані для вхідного речення «Собака [МАСКА] на килимку».
Це воно. Лише за кілька кроків ви скомпілювали та запустили модель PyTorch на примірнику Amazon EC2 DL2q. Щоб дізнатися більше про адаптацію та компіляцію моделей на екземплярі DL2q, див Навчальна документація Cloud AI100.
Щоб дізнатися більше про те, які архітектури моделі DL добре підходять для екземплярів AWS DL2q, а також про поточну матрицю підтримки моделі, див. Документація Qualcomm Cloud AI100.
Доступний зараз
Ви можете запустити екземпляри DL2q сьогодні в регіонах Захід США (Орегон) і Європа (Франкфурт) AWS як На вимогу, Зарезервований та Точкові екземпляри, або як частина a План заощаджень. Як завжди з Amazon EC2, ви платите лише за те, що використовуєте. Для отримання додаткової інформації див Ціни на Amazon EC2.
Екземпляри DL2q можна розгорнути за допомогою AWS Deep Learning AMI (DLAMI), а зображення контейнерів доступні через керовані служби, такі як Amazon SageMaker, Служба Amazon Elastic Kubernetes (Amazon EKS), Amazon Elastic Container Service (Amazon ECS) та AWS ParallelCluster.
Щоб дізнатися більше, відвідайте сторінку Екземпляр Amazon EC2 DL2q і надішліть відгук на AWS re:Post для EC2 або через звичайні контакти служби підтримки AWS.
Про авторів
 А. К. Рой є директором із управління продуктами компанії Qualcomm для продуктів і рішень для хмарних технологій і центрів обробки даних. Він має більш ніж 20-річний досвід у стратегії та розробці продукту, приділяючи особливу увагу кращим у своєму класі наскрізним рішенням щодо продуктивності та ефективності/$ для висновків ШІ в хмарі для широкого спектру випадків використання, включаючи GenAI, LLMs, Auto та Hybrid AI.
А. К. Рой є директором із управління продуктами компанії Qualcomm для продуктів і рішень для хмарних технологій і центрів обробки даних. Він має більш ніж 20-річний досвід у стратегії та розробці продукту, приділяючи особливу увагу кращим у своєму класі наскрізним рішенням щодо продуктивності та ефективності/$ для висновків ШІ в хмарі для широкого спектру випадків використання, включаючи GenAI, LLMs, Auto та Hybrid AI.
 Цзяньїн Ланг є головним архітектором рішень у Всесвітній спеціалізованій організації AWS (WWSO). Вона має понад 15 років досвіду роботи в галузі HPC та AI. В AWS вона зосереджується на допомозі клієнтам розгортати, оптимізувати та масштабувати робочі навантаження AI/ML на прискорених обчислювальних пристроях. Вона захоплена поєднанням технологій HPC та AI. Цзяньїн має ступінь доктора філософії з обчислювальної фізики в Університеті Колорадо в Боулдері.
Цзяньїн Ланг є головним архітектором рішень у Всесвітній спеціалізованій організації AWS (WWSO). Вона має понад 15 років досвіду роботи в галузі HPC та AI. В AWS вона зосереджується на допомозі клієнтам розгортати, оптимізувати та масштабувати робочі навантаження AI/ML на прискорених обчислювальних пристроях. Вона захоплена поєднанням технологій HPC та AI. Цзяньїн має ступінь доктора філософії з обчислювальної фізики в Університеті Колорадо в Боулдері.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/amazon-ec2-dl2q-instance-for-cost-efficient-high-performance-ai-inference-is-now-generally-available/
- : має
- :є
- $UP
- 1
- 1 ТБ
- 10
- 100
- 11
- 12
- 13
- 15 роки
- 15%
- 17
- 19
- 20
- 20 роки
- 22
- 23
- 46
- 7
- 75
- 8
- 84
- a
- МЕНЮ
- вище
- прискорений
- прискорювач
- прискорювачі
- доступ
- супроводжується
- точність
- через
- активації
- Додатково
- просунутий
- сукупність
- AI
- AI / ML
- ВСІ
- Також
- Amazon
- Amazon EC2
- Amazon Web Services
- an
- та
- Оголошення
- будь-який
- API
- Інтерфейси
- застосування
- додатка
- архітектура
- ЕСТЬ
- аргумент
- ARM
- штучний
- AS
- помічники
- At
- автоматичний
- автомобільний
- автономний
- доступний
- AWS
- Оси
- ширина смуги
- база
- дозування
- BE
- перед тим
- нижче
- За
- BIN
- Блокувати
- Цвісти
- приносити
- широкий
- буфера
- будувати
- by
- call
- званий
- CAN
- можливості
- потужність
- карта
- випадок
- перевірка
- classic
- хмара
- Колорадо
- об'єднання
- Комунікація
- скомпільований
- всеосяжний
- обчислювальна
- обчислення
- комп'ютер
- Комп'ютерне бачення
- комп'ютери
- обчислення
- послідовний
- Складається
- Наші контакти
- Контейнер
- містить
- зміст
- створювати
- Поточний
- Клієнти
- дані
- Дата-центр
- глибокий
- глибоке навчання
- певний
- Ступінь
- доставляти
- постачає
- розгортання
- розгорнути
- розгортання
- описаний
- розвивати
- Розробник
- розробка
- пристрій
- прилади
- радіомовлення
- Директор
- документація
- Пес
- водіння
- динамічний
- відливи
- край
- ефективний
- або
- працює
- дозволяє
- кінець в кінець
- запис
- Навколишнє середовище
- середовищах
- Ефір (ETH)
- Європа
- приклад
- досвід
- розширена реальність
- витяг
- false
- особливість
- зворотний зв'язок
- кілька
- поле
- Поля
- Рисунок
- філе
- Перший
- відповідати
- фіксований
- Сфокусувати
- фокусується
- стежити
- після
- для
- знайдений
- чотири
- Франкфурт
- від
- функція
- злиття
- в цілому
- породжувати
- генерується
- покоління
- генеративний
- Генеративний ШІ
- GitHub
- даний
- добре
- гість
- Guest Post
- he
- гарнітури
- допомогу
- тут
- висока продуктивність
- вище
- основний момент
- тримає
- к.с.
- HTML
- HTTPS
- гібрид
- i
- IDX
- if
- зображення
- зображень
- здійснювати
- реалізація
- імпорт
- in
- У тому числі
- об'єднує
- індивідуальний
- промисловість
- провідний в галузі
- інформація
- вхід
- встановлювати
- екземпляр
- випадки
- Intel
- Розумний
- взаємопов'язані
- інтерфейс
- IT
- JPG
- просто
- ключ
- Кубернетес
- Lane
- мова
- великий
- Затримка
- запуск
- УЧИТЬСЯ
- вивчення
- libraries
- бібліотека
- справа
- світло
- Лінія
- вантажі
- вдалося
- управління
- маска
- Матриця
- Макс
- Максимізувати
- максимізує
- максимальний
- пам'ять
- сітці
- Meta
- Microsoft
- хвилин
- модель
- Моделі
- модифікований
- більше
- найбільш
- ім'я
- Природний
- Природна мова
- Обробка природних мов
- необхідно
- Необхідність
- мережу
- мережа
- мереж
- Нові
- наступне покоління
- зараз
- нумпі
- Nvidia
- об'єкт
- of
- on
- Onboard
- На борту
- ONE
- тільки
- відкрити
- OpenAI
- Оптимізувати
- оптимізований
- or
- Орегон
- організація
- OS
- Інше
- з
- вихід
- виходи
- над
- власний
- пакети
- сторінка
- частина
- проходити
- Пройшов
- пристрасний
- шлях
- Платити
- для
- продуктивність
- персонал
- Персональні комп'ютери
- Вчений ступінь
- Фізика
- платформа
- plato
- Інформація про дані Платона
- PlatoData
- точка
- популярний
- це можливо
- пошта
- Харчування
- Точність
- раніше
- Головний
- обробка
- Вироблений
- випускає
- Product
- Управління продуктом
- Production
- Продукти
- програма
- проект
- забезпечує
- забезпечення
- громадськість
- Python
- піторх
- Qualcomm
- швидко
- діапазон
- RE
- читання
- Реальність
- райони
- вимагається
- Вимога
- утримує
- повертати
- знову використовувати
- Рой
- прогін
- біг
- пробіжки
- то ж
- зберегти
- економія
- масштабовані
- шкала
- Sdk
- другий
- побачити
- послати
- пропозиція
- Послідовність
- обслуговування
- Послуги
- Сесія
- комплект
- вона
- показаний
- простий
- спростити
- сайт
- Розмір
- смартфон
- смартфонів
- So
- Рішення
- напруга
- спеціаліст
- стек
- standard
- старт
- почалася
- Крок
- заходи
- зберігання
- зберігати
- Стратегія
- Згодом
- такі
- чудовий
- підтримка
- Підтримуючий
- Опори
- система
- таблиця
- методи
- Технологія
- текст
- Що
- Команда
- їх
- потім
- Ці
- вони
- це
- три
- через
- пропускна здатність
- через
- до
- сьогодні
- токенізувати
- інструмент
- верхівки
- факел
- Усього:
- трафік
- навчений
- Трансформатори
- правда
- підручник
- єдиний
- університет
- us
- використання
- використання випадку
- випадки використання
- використовуваний
- користувач
- використання
- звичайний
- v1
- VAL
- ПЕРЕВІР
- значення
- Віртуальний
- бачення
- візит
- we
- Web
- веб-сервіси
- ДОБРЕ
- West
- Що
- який
- в той час як
- широкий
- Широкий діапазон
- волі
- з
- слово
- робочий
- світовий
- років
- ви
- вашу
- зефірнет