- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://www.nanowerk.com/news2/robotics/newsid=63842.php
- :є
- 10
- 100
- 15%
- 2023
- 7
- a
- Здатний
- через
- Прийняття
- AI
- так
- ВСІ
- хоча
- серед
- an
- та
- Відповіді
- прикладної
- ЕСТЬ
- AS
- запитувач
- аспекти
- помічники
- асоційований
- At
- атака
- нападки
- доступний
- геть
- BE
- буття
- між
- мільярди
- будувати
- підприємства
- але
- by
- CAN
- обережно
- Генеральний директор
- chatbots
- ChatGPT
- ясно
- закрито
- загальний
- Компанії
- комп'ютер
- Занепокоєння
- щодо
- конференція
- може
- створювати
- створення
- критичний
- В даний час
- кібер-
- Дата
- демонструвати
- продемонстрований
- розгортання
- докладно
- Виявлення
- розвивати
- різний
- цифровий
- відкритий
- dr
- підприємств
- Весь
- Навіть
- докази
- існувати
- існуючий
- Експлуатувати
- видобуток
- надзвичайно
- захоплюючий
- фінансовий
- фінансові послуги
- Перший
- увагу
- для
- від
- далі
- отримала
- даний
- дає
- Земля
- Мати
- прихований
- основний момент
- відбувся
- Як
- How To
- Однак
- HTTPS
- HuggingFace
- важливо
- in
- збільшений
- все більше і більше
- промисловість
- повідомити
- інформація
- інформаційна безпека
- проникливий
- інтернет
- Invest
- інвестування
- IT
- JPG
- ключ
- знання
- відомий
- мова
- великий
- Великі підприємства
- запуск
- провідний
- УЧИТЬСЯ
- вивчення
- менше
- трохи
- машина
- навчання за допомогою машини
- основний
- Може..
- вимір
- мільйони
- модель
- Моделі
- багато
- Нові
- of
- on
- відкрити
- з відкритим вихідним кодом
- or
- з
- власний
- Папір
- партія
- Пітер
- місця
- планування
- plato
- Інформація про дані Платона
- PlatoData
- це можливо
- потенційно
- потужний
- підготовка
- представлений
- Головний
- приватний
- забезпечувати
- публічно
- діапазон
- ставка
- тиражувати
- запитів
- дослідження
- Дослідники
- показувати
- ризики
- Зазначений
- say
- Вчені
- безпеку
- Послуги
- комплект
- Повинен
- Показувати
- менше
- розумний
- So
- деякі
- Source
- Стажування
- Пуск в експлуатацію
- буря
- Вивчення
- успіх
- Успішно
- такі
- прийняті
- говорити
- цільове
- націлювання
- завдання
- команда
- Технології
- Технологія
- Тестування
- ніж
- Що
- Команда
- інформація
- Великобританія
- світ
- їх
- потім
- Там.
- Ці
- вони
- думати
- третій
- це
- У цьому році
- times
- до
- інструменти
- передані
- перетворювальний
- Uk
- розуміння
- вживати
- університет
- використання
- використовуваний
- використовує
- цінний
- дуже
- Уразливості
- було
- шлях..
- we
- week
- були
- який
- широкий
- Широкий діапазон
- волі
- з
- в
- без
- Work
- тренування
- працює
- світ
- турбуватися
- рік
- зефірнет
Більше від Нановерк
Відкриваємо нову еру нанопристроїв із можливістю налаштування кольору – найменше джерело світла з можливістю перемикання кольорів
Вихідний вузол: 2801585
Часова мітка: Серпень 3, 2023

«Чарівний» розчинник створює більш міцні тонкі плівки
Вихідний вузол: 1957849
Часова мітка: Лютий 14, 2023
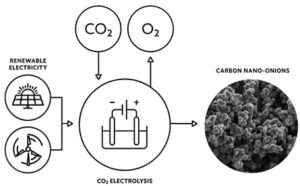
Вуглецеві нанотрубки можуть відігравати значну роль у зв'язуванні атмосферного вуглекислого газу
Вихідний вузол: 2836729
Часова мітка: Серпень 21, 2023

Розрізнення правого та лівого за допомогою магнітів
Вихідний вузол: 1907121
Часова мітка: Січень 18, 2023
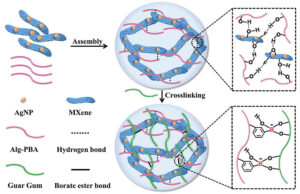
Антибактеріальні епідермальні сенсори на основі гідрогелю MXene
Вихідний вузол: 2661017
Часова мітка: Травень 18, 2023
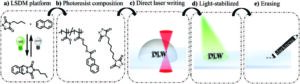
3D-принти приєднуються до темної сторони та зникають
Вихідний вузол: 2903619
Часова мітка: Вересень 27, 2023
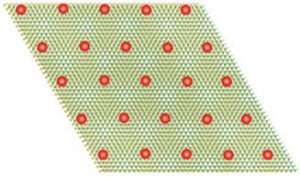
Коли матеріал стає квантовим, електрони сповільнюються і утворюють кристал
Вихідний вузол: 1975767
Часова мітка: Лютий 23, 2023

Інженери розробили ефективний процес виробництва палива з вуглекислого газу
Вихідний вузол: 2963812
Часова мітка: Жовтень 30, 2023

«Оптичні відбитки пальців» на електронному пучку
Вихідний вузол: 3062609
Часова мітка: Січень 15, 2024