Giriş
Transformers ve Büyük Dil Modelleri, bilişim alanında tanıtıldıktan sonra dünyayı kasıp kavurdu. Doğal Dil İşleme (NLP). Kuruluşundan bu yana bu alan, bu Yüksek Lisans Programlarını daha verimli hale getiren yenilikler ve araştırmalarla hızla gelişmektedir. Bunlar arasında LoRA (Düşük Sıralı Uyarlama), Flash Attention, Quantizasyon ve önemli LLM'lerin yakın zamandaki Birleştirme yaklaşımı yer alıyor. Bu kılavuzda birleştirme konusunda yeni bir yaklaşıma bakacağız LLM'ler (Solar 10.7B) Upstage AI tarafından tanıtıldı.

Öğrenme hedefleri
- Solar 10.7B'nin benzersiz mimarisini ve yenilikçi "derinlik yükseltmesini" anlayın
- Modelin eğitim öncesi sürecini ve tükettiği çeşitli verileri keşfedin
- Solar 10.7B'nin farklı NLP görevlerindeki etkileyici performans ölçütlerini analiz edin
- Solar 10.7B'yi Mixtral MoE gibi diğer önemli LLM'lerle karşılaştırın ve karşılaştırın
- Projeleriniz için Solar 10.7B'ye nasıl erişeceğinizi ve onunla nasıl çalışacağınızı öğrenin
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
SOLAR 10.7B nedir?
Upstange AI, yeni 10.7 Milyar Parametre modeli SOLAR 10.7B'yi tanıttı. Bu model, SOLAR 7B'yi oluşturmak için önceden eğitilmiş iki 2 Milyar Parametre Modelinin, özellikle iki Llama 7 10.7 Milyar modelinin birleştirilmesinin bir sonucudur. Bu birleşmenin benzersiz yönü, uzmanlardan oluşan bir karışımın kullanıldığı Mixtral yönteminin aksine, Derinlik Arttırma (DUS) adı verilen yeni bir yaklaşımın uygulanmasıdır.
Yeni 10.7B Modeli Mistral 7B ve Qwen 14B'den daha iyi performans gösterdi. SOLAR 10.7B Instruct adlı bir Instruct sürümü yayınlandı ve piyasaya sürülmesinin ardından hem Qwen 72B'yi hem de Mixtral 8x7B Büyük Dil Modelini geride bırakarak liderlik sıralamasında zirveye yerleşti. 10.7 Milyar Parametreli bir model olmasına rağmen SOLAR, boyutunun birkaç katı olan LLM'lerden daha iyi performans göstermeyi başardı.
Derinlik Arttırma Ölçeklendirmesi nedir?
Her şeyin nasıl başladığını ve SOLAR 10.7B'nin oluşumunu anlayalım. Her şey tek bir Temel Modelle başlar. Upstage, Açık Kaynak Katkıda Bulunanlarının daha geniş olması nedeniyle Temel Modeli için 2 Transformer Katmanı içeren Llama 32'yi seçti. Daha sonra bu Temel Modelin bir kopyası oluşturuldu

Daha sonra iki Temel Model elde ederiz. Ağırlıklara gelince, Upstage o dönemde en iyi performansı sergilediği için önceden eğitilmiş ağırlıkları Mistral 7B'den aldı. Şimdi derinlemesine ölçeklendirmeye başlıyoruz. Temel Modellerin her biri 32 Katman içerir. Bu 32 Katmandan m Katmanı, yani Orijinal Modelin son m Katmanını ve kopya versiyonundan ilk m katmanını kaldırıyoruz. Bu, her birinde 24 Katmana kadar ekler. Daha sonra bu iki modeli birleştiriyoruz:
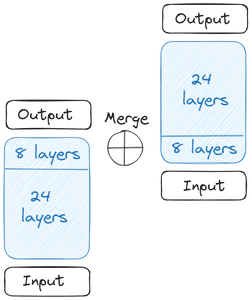
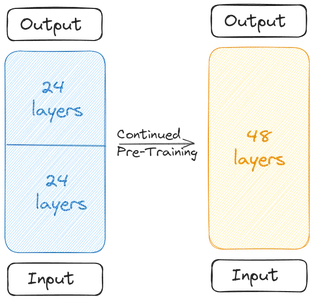
İki Temel Model, ölçekli modeli oluşturmak için birleştirilir. Ölçeklendirilmiş model artık 48 Katman içermektedir. Ölçeklendirilmiş model, birleştirme nedeniyle düşük performans gösteriyor. Bu nedenle ölçekli model ön eğitime tabi tutulur. Bu Derinlemesine Ölçeklendirme ve ardından devam eden Ön Eğitim birlikte Derinlik Arttırma (DUS) oluşturur.
SOLAR 10.7B'nin eğitimi
Birleştirme nedeniyle performansın düşmesi nedeniyle ölçeklenen modelin önceden eğitilmesi gerekir. Yapımcılar, ön eğitimle performansın hızla arttığını söyledi. Ön eğitim / ince ayar iki aşamadan oluşuyordu
İlk aşama Öğretimin İnce Ayarıydı. Bu tür İnce Ayarda model, talimatlarla uyum sağlamak için veri kümeleri üzerinde eğitime tabi tutuldu. İnce ayar süreci, Alpaca-GPT4 ve OpenOrca gibi popüler Açık Kaynak veri kümeleriyle çalışmayı içeriyordu. Makale, birleştirilmiş modelin ince ayarının yapılmasında veri kümesinin yalnızca bir alt kümesinin kullanıldığını kaydetti. Açık Kaynak verilerinin yanı sıra Upstage, onu bazı kapalı kaynak Matematik verileriyle bile eğitti.
İkinci aşamada Hizalama Ayarı gerçekleştirilir. Hizalama Ayarlamasında, ince ayarlı bir modelin aşamasını alıyoruz ve insanlarla veya GPT4 gibi güçlü yapay zekalarla daha uyumlu olması için daha da ince ayar yapıyoruz. Bu, RLHF (İnsan Geri Bildirimiyle Takviyeli Öğrenme) benzeri bir teknik olan DPOTrainer (Doğrudan Tercih Optimizasyonu) aracılığıyla yapıldı.
Doğrudan Tercih Optimizasyonunda, üç sütun, bir Bilgi İstemi, bir tercih edilen yanıt sütunu ve bir reddedilen yanıt sütunu içeren bir veri kümemiz var. Bu daha sonra ölçekli modeli, üretmemiz gereken yanıtları üretmesini sağlayacak şekilde eğitmek için kullanılır. Talimatlarda ince ayar için eğitilen aynı veri kümeleri burada kullanılır.
Değerlendirme ve Karşılaştırma Sonuçları
Hugging Face OpenLLM Liderlik Tablosu, Büyük Dil Modellerinin (LLM'ler) yeteneklerini değerlendirmek için çeşitli kriterler kullanır. Her kıyaslama, bir LLM'nin performansının farklı yönlerini değerlendirir:
- ARC (AI2 Muhakeme Mücadelesi): Bu kıyaslama, bir LLM'nin temel düzeydeki fen sorularını yanıtlama yeteneğini test ederek, modelin bilimsel kavramları anlama ve akıl yürütmesine ilişkin içgörüler sağlar.
- MMLU (Devasa Çok Görevli Dil Anlama): MMLU, temel matematik, tarih, hukuk, bilgisayar bilimi ve diğer konularla ilgili sorular da dahil olmak üzere 57 farklı görevi kapsayan çok çeşitli bir kıyaslamadır. LLM'nin birden fazla disiplindeki bilgileri işleme ve anlama yeteneğini değerlendirir.
- Merhaba! Bir Yüksek Lisans'ın sağduyulu muhakemesini test etmeyi amaçlayan HellaSwag, modellerin günlük mantığı çeşitli senaryolara uygulamalarına meydan okuyor ve onların insan düşünce süreçlerine benzer sezgisel kararlar verme yeteneklerini değerlendiriyor.
- Winogrande: HellaSwag'e benzeyen bu kıyaslama, sağduyulu akıl yürütmeye odaklanır ancak HellaSwag'a kıyasla farklı nüanslara sahiptir. Yüksek Lisans'ın karmaşık düzeyde bir anlayış ve mantıksal akıl yürütme göstermesini gerektirir.
- DoğrulukQA: TruthfulQA, LLM'ler tarafından sağlanan bilgilerin doğruluğunu ve güvenilirliğini değerlendirir. Bilim, hukuk, siyaset ve daha fazlasını içeren farklı alanlardan sorular içerir ve modelin doğru ve gerçekçi yanıtlar üretme yeteneğini test eder.
- GSM8K: Matematik yeteneklerini test etmek için özel olarak tasarlanan GSM8K, mantıksal akıl yürütme ve hesaplamalı düşünme gerektiren çok adımlı matematik problemlerini içerir ve yüksek lisans öğrencilerini matematikteki problem çözme becerilerini değerlendirmeye zorlar.
Temel SOLAR 10.7B Modeli, Mistral 7B Instruct v0.2 modeli ve Qwen 14B modeli gibi modellerden daha iyi performans gösterdi. SOLAR 10.7B'nin Instruct sürümü, Mistral 8x7B, Qwen 72B, Falcon 180B ve diğer devasa Büyük Dil Modelleri gibi Çok Büyük Dil Modellerini bile geçmeyi başardı. ARC ve TruthfulQA kriterlerindeki tüm modellerin önündeydi
SOLAR 10.7B'ye Başlarken
SOLAR 10.7B Modeli, transformatör kütüphanesiyle çalışmak üzere HuggingFace Hub'da hazır olarak mevcuttur. SOLAR 10.7B'nin nicelenmiş modelleriyle bile çalışmak mümkündür. Bu bölümde nicelenmiş versiyonu indireceğiz ve modeli farklı görevlerle girmeyi ve oluşturulan çıktıyı görmeyi deneyeceğiz.
SOLAR 10.7B'nin nicelenmiş sürümünü test etmek için, nicelenmiş Büyük Dil Modellerini çalıştırmamıza olanak tanıyan Python'un llama_cpp_python kütüphanesi ile çalışacağız. Bu demo için Google Colab'ın ücretsiz sürümüyle çalışacağız.
Paketi İndir
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip3 install llama-cpp-python
!pip3 install huggingface-hub- The CMAKE_ARGS=”-DLLAMA_CUBLAS=açık” ve FORCE_CMAKE=1, izin verecek llama_cpp_python ücretsiz colab sürümünde bulunan Nvidia GPU'yu çalıştırmak için
- Daha sonra kurulumu gerçekleştiriyoruz llama_cpp_python pip3 aracılığıyla paket
- Hatta indiriyoruz sarılma yüz merkezi, bununla nicelenmiş SOLAR 10.7B modelini indireceğiz
SOLAR 10.7B modeliyle çalışmak için öncelikle onun nicelenmiş versiyonunu indirmemiz gerekiyor. İndirmek için aşağıdaki kodu çalıştıracağız:
from huggingface_hub import hf_hub_download
# specifying the model name
model_name = "TheBloke/SOLAR-10.7B-Instruct-v1.0-GGUF"
# specifying the type of quantization of the model
model_file = "solar-10.7b-instruct-v1.0.Q2_K.gguf"
# download the model by specifying the model name and quantized model name
model_path = hf_hub_download(model_name, filename=model_file)
Hugging Face Hub'la Çalışmak
Burada şu kişilerle çalışıyoruz: Hugging_face_hub Nicelenmiş modeli indirmek için. Bunun için ithal ediyoruz hf_hub_download aşağıdaki parametreleri alır
- model adı: Bu, indirmek istediğimiz model türüdür. Burada SOLAR 10.7B Instruct GGUF modelini indirmek istiyoruz
- model_dosyası: Burada hangi sayısallaştırılmış versiyonu indirmek istediğimizi söylüyoruz. Burada SOLAR 2B Instruct'ın 10.7 bitlik nicemlenmiş versiyonunu indireceğiz.
- Daha sonra bu parametreleri sunucuya aktarıyoruz. hf_hub_downloadBu parametreleri alır ve belirtilen modeli indirir. İndirdikten sonra modelin indirildiği yolu döndürür
- Döndürülen bu yol şuraya kaydediliyor: model_yolu değişken
Artık bu modeli lama aracılığıyla yükleyebiliriz._cpp_python kütüphane. Modeli yükleme kodu aşağıdaki gibi olacaktır
from llama_cpp import Llama
llm = Llama(
model_path=model_path,
n_ctx=512, # the number of i/p tokens the model can take
n_threads=8, # the number of threads to use
n_gpu_layers=110 # how many layers of the model to offload to the GPU
)
Lama Sınıfını İçe Aktarın
Llama sınıfını şuradan içe aktarıyoruz: lama_cppaşağıdaki parametreleri alan
- model_yolu: Bu değişken modelimizin saklandığı yolu alır. Burada sağlayacağımız önceki adımdaki yolu bulduk
- n_ctx: Burada modelin bağlam uzunluğunu veriyoruz. Şimdilik bağlam uzunluğu için 512 jeton sağlıyoruz
- n_konu: Burada Llama sınıfının kullanacağı thread sayısından bahsediyoruz. Şimdilik 8'i geçiyoruz çünkü her çekirdeğin aynı anda 4 iş parçacığını çalıştırabildiği 2 çekirdekli CPU'muz var.
- n_gpu_layers: Çalışan bir GPU'muz varsa bunu veriyoruz, çünkü ücretsiz ortak çalışmayla çalışıyoruz. Bunun için tüm modeli GPU'ya boşaltmak istediğimizi ve bir kısmının sistem RAM'inde çalışmasını istemediğimizi söyleyen 110'u geçiyoruz.
- Son olarak bu Llama sınıfından bir nesne oluşturup onu llm değişkenine veriyoruz.
Bu kodu çalıştırmak, SOLAR 10.7B nicelenmiş modelini GPU'ya yükleyecek ve uygun bağlam uzunluğunu ayarlayacaktır. Şimdi bu model üzerinde bazı çıkarımlar yapmanın zamanı geldi. Bunun için aşağıdaki kodla çalışıyoruz
output = llm(
"### User:nWho are you?nn### Assistant:", # User Prompt
max_tokens=512, # the number of output tokens generated
stop=["</s>"], # the token which tells the LLM to stop
)
print(output['choices'][0]['text']) # llm generated text
Model Çıkarımı
Modeli çıkarmak için aşağıdaki parametreleri LLM'lere iletiyoruz:
- İstem/sohbet şablonu: Bu, modelle sohbet etmek için gereken şablondur. Yukarıda belirtilen şablon(### User:n{user_prompt}?nn### Assistant:), SOLAR 10.7B modeli için çalışan şablondur. Şablonda, cümleden sonra gelen cümle kullanıcı Kullanıcı İstemidir ve nesil, Asistan
- max_tokens: Bu, bir İstem verildiğinde Büyük Dil Modelinin üretebileceği maksimum belirteç miktarıdır. Şimdilik bunu 512 jetonla sınırlıyoruz
- durdurmak: Bu durdurma jetonu. Durdurma jetonu, Büyük Dil Modeline daha fazla jeton üretmeyi durdurması gerektiğini bildirir. SOLAR 10.7B için durdurma jetonu:
Bunu çalıştırmak, sonuçları çıktı değişken. Oluşturulan sonuç OpenAI API çağrısına benzer. Dolayısıyla, OpenAI yanıtlarından nesile erişme şeklimize benzer şekilde, verilen print ifadesi aracılığıyla nesile erişebiliriz. Oluşturulan çıktı aşağıda görülebilir

Oluşturulan cümle, büyük gramer hataları olmadan yeterince iyi görünüyor. Aşağıdaki İstemleri vererek modelin sağduyulu kısmını deneyelim.
output = llm(
"### User:nHow many eggs can a monkey lay in its lifetime?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

output = llm(
"### User:nHow many smartphones can a human eat?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

Burada sağduyuyla ilgili iki örnek görüyoruz ve şaşırtıcı bir şekilde SOLAR 10.7B bu durumu çok iyi idare ediyor. Büyük Dil Modeli, bazı yararlı içeriklerle doğru yanıtları sunmayı başardı. Aşağıdaki İstemler aracılığıyla modelin matematik ve Muhakeme Yeteneklerini test etmeyi deneyelim
output = llm(
"### User:nLook at this series: 80, 10, 70, 15, 60, ...
What number should come next?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])
output = llm(
"### User:nJohn runs faster than Ken. Magnus runs faster than John.
Does Ken run faster than Magnus?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

Verilen örnek İstemlerden, SOLAR 10.7B iyi bir yanıt üretti. Verilen matematiksel ve mantıksal akıl yürütmeye, hatta sağduyuyla ilgili sorulara bile doğru cevap verebildi. Genel olarak SOLAR 10.7B Büyük Dil Modelinin iyi yanıtlar ürettiği sonucuna varabiliriz.
SOLAR 10.7B ve Mixtral MoE karşılaştırması
Mixtral 8x7B MoE, Mistral AI tarafından Uzmanların Karması mimarisiyle oluşturulmuştur. Kısaca, bu Uzmanlar Karması olan Mistral, 8 adet 7 Milyar Parametreli Model kullanmaktadır. Bu modellerin her birinin ileri besleme ağlarından bazıları, uzman adı verilen diğer katmanlarla değiştirilmiştir. Dolayısıyla Mixtral 8x7B'nin 8 uzmana sahip olduğu kabul edilmektedir. Ve modelin Giriş İstemine aldığı herkeste, 2 uzman arasından bu uzmanlardan yalnızca 8'sini seçen bir geçiş mekanizması olacaktır. 2 uzman daha sonra bu Giriş İstemini alır ve nihai çıktı jetonlarını oluşturur. Dolayısıyla, ileri beslemeli katmanları diğer katmanlarla değiştirmemiz ve bu uzmanlar arasında seçim yapan bir geçit mekanizması tanıtmamız gereken bu tür birleştirmede biraz karmaşıklık olduğunu görebiliriz.
Upstage'in SOLAR 10.7B Modeli, Derinlik Arttırma yöntemini kullanır. Derinlik Arttırmada, Temel Modelden yalnızca bir miktar başlangıç katmanını ve kopya versiyonundan da aynı sayıda son katmanı kaldırıyoruz. Daha sonra modelleri üst üste istifleyerek birleştiriyoruz. Ve yalnızca birkaç dönem ince ayar yapılmasıyla birleştirilmiş model, performansta hızlı bir büyüme gösterebilir. Burada mevcut katmanları başka katmanlarla değiştirmiyoruz. Ayrıca burada bir geçit mekanizmamız yok. Genel olarak Derinlik Arttırma, karmaşıklık içermeyen modelleri birleştirmenin basit ve etkili bir yoludur.
Ayrıca performansları karşılaştıran Derinlik Arttırma Ölçeklendirmesi, yalnızca iki adet 7 Milyar Modeli birleştirerek, SOLAR 10.7B'nin, kıyaslandığında çok daha büyük bir model olan Mixtral 8x7B'den açıkça daha iyi performans göstermesini sağladı. Bu, basit bir birleştirme yönteminin Uzmanların Karışımı gibi karmaşık bir yönteme göre etkinliğini kanıtlıyor
Sınırlamalar ve Hususlar
- Hiperparametre Araştırması: Önemli bir sınırlama, DUS yaklaşımında hiperparametrelerin yetersiz araştırılmasıdır. Donanım sınırlamaları nedeniyle, bu sayının en iyi performansı elde etmek için ideal olup olmadığı doğrulanmadan Temel Modelin her iki ucundan 8 katman kaldırıldı. Gelecekteki çalışmalar daha titiz deneyler yapmayı ve bunu ele alacak bir analiz yapmayı amaçlıyor.
- Hesaplamalı Talepler: Modelin eğitim ve çıkarım için büyük miktarda hesaplama kaynağına ihtiyacı vardır. Bu, özellikle sınırlı hesaplama yeteneklerine sahip olanlar için kullanımını sınırlayabilir.
- Eğitim Verilerindeki Önyargılar: Tüm makine öğrenimi modelleri gibi, eğitim verilerinde mevcut önyargılara karşı hassastır ve potansiyel olarak belirli senaryolarda çarpık sonuçlara yol açabilir.
- Çevresel Etki: Modelin eğitimi ve çalıştırılması için gerekli olan enerji tüketimi bile çevresel kaygılar doğurmakta ve sürdürülebilir yapay zeka gelişiminin önemini vurgulamaktadır.
- Modelin Daha Geniş Etkileri: Model, aşağıdaki talimatlarda gelişmiş performans gösterse de, özel uygulamalarda en iyi performansı elde etmek için yine de göreve özel ince ayar yapılması gerekmektedir. Bu ince ayar süreci kaynak yoğundur ve her zaman etkili olmayabilir.
Sonuç
Bu kılavuzda, Upstage AI tarafından yakın zamanda piyasaya sürülen SOLAR 10.7 Milyar Parametre modeline bir göz attık. Upstage AI, modelleri birleştirmek ve ölçeklendirmek için yeni bir yaklaşım benimsedi. Makale, başlangıç ve son transformatör katmanlarından bazılarını kaldırarak iki Llama-2 7 Milyar Parametre modelini birleştirmek için Derinlik Arttırma Ölçeklendirmesi adı verilen yeni bir yaklaşım kullandı. Daha sonra modele Açık Kaynak veri kümelerinde ince ayar yaptı ve OpenLLM Liderlik Tablosunda test ederek en yüksek H6 puanını elde etti ve liderlik tablosunda zirveye yerleşti.
Önemli Noktalar
- SOLAR 10.7B, geleneksel yöntemlere meydan okuyan ve model mimarisindeki ilerlemeleri gösteren benzersiz bir birleştirme yaklaşımı olan Derinlik Arttırma Ölçeklendirmesini tanıtıyor
- 10.7 milyar parametresine rağmen SOLAR 10.7B, daha büyük modelleri gölgede bırakarak Mistral 7B ve Qwen 14B'yi geride bırakıyor ve hatta SOLAR 10.7B gibi versiyonlarla lider tablolarının zirvesine çıkıyor.
- Talimat ve Hizalama Ayarlama'yı içeren iki aşamalı ince ayar süreci, modelin farklı görevlere uyarlanabilirliğini sağlayarak, talimatları takip etme ve insan tercihlerine uyum sağlama konusunda çok iyi olmasını sağlar.
- SOLAR 10.7B, çeşitli kriterlerde üstün performans göstererek Temel Matematik ve dil anlayışından sağduyulu muhakeme ve doğruluk değerlendirmesine kadar çeşitli görevlerde yetkinliğini göstermektedir.
- HuggingFace Hub'da kolayca bulunabilen SOLAR 10.7B, geliştiricilere ve araştırmacılara dil işleme uygulamaları için etkili ve kullanılabilir bir araç sağlar
- Büyük dil modellerinde ince ayar yapmak için kullanılan normal yöntemleri kullanarak modelde ince ayar yapabilirsiniz. Örneğin, SOLAR 10.7B Modeline ince ayar yapmak için Hugging Face'in Denetimli İnce Ayar Eğiticisini (SFTrainer) kullanabilirsiniz.
Sıkça Sorulan Sorular
A. SOLAR 10.7B, Upstage AI tarafından geliştirilen ve Derinlik Arttırma Ölçeklendirmesi adı verilen benzersiz bir birleştirme tekniğini kullanan 10.7 milyar parametreli bir modeldir. Daha büyük LLM'lerden daha iyi performans göstererek ve modellerin birleştirilmesindeki ilerlemeleri sergileyerek kendisini farklılaştırıyor.
A. Derinlemesine Ölçeklendirme iki temel modeli içerir. Süreç, bu iki temel modeli üst üste istifleyerek doğrudan birleştirmeyi içeriyor. Birleştirme gerçekleşmeden önce bir modelin başlangıç katmanları ve diğer modelin son katmanları kaldırılır.
A. SOLAR 10.7B, iki aşamalı bir ön eğitim sürecinden geçer. Talimatlarda ince ayar yapılması, modelin talimat takibini vurgulayan veri kümeleri üzerinde eğitilmesini içerir. Hizalama ayarı, Doğrudan Tercih Optimizasyonu (DPO) adı verilen bir teknik kullanılarak modelin insan tercihleriyle uyumunu iyileştirir.
C. SOLAR 10.7B, ARC (AI2 Reasoning Challenge), MMLU (Massive MultiTask Language Understanding), HellaSwag, Winogrande, TruthfulQA ve GSM8K dahil olmak üzere çeşitli kriterlerde üstün performans sergiliyor. Farklı dil görevlerini yerine getirmedeki çok yönlülüğünü gösteren yüksek puanlar elde ediyor.
A. SOLAR 10.7B, daha az parametreye sahip olmasına rağmen üstün performans sergileyerek Mistral 7B ve Qwen 14B gibi modelleri geride bırakıyor. Talimat sürümü, çeşitli kıyaslamalarda Mistral 8x7B ve Qwen 72B dahil olmak üzere çok büyük modellerle rekabet eder ve onlardan daha iyi performans gösterir.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2024/01/solar-10-7b-comparing-its-performance-to-other-notable-llms/
- :vardır
- :dır-dir
- :olumsuzluk
- :Neresi
- $UP
- 10
- 110
- 12
- İNDİRİM
- 16
- 24
- 300
- 32
- 60
- 7
- 70
- 8
- 80
- 9
- a
- yeteneklerini
- kabiliyet
- Yapabilmek
- erişim
- doğruluk
- Elde Ediyor
- elde
- karşısında
- adres
- Ekler
- gelişmeler
- Sonra
- önde
- AI
- AI2
- Hedeflenen
- Amaçları
- hizalamak
- hizalı
- dizme
- hiza
- Türkiye
- izin vermek
- boyunca
- Ayrıca
- her zaman
- miktar
- an
- analiz
- analytics
- Analitik Vidhya
- ve
- Başka
- cevap
- cevaplar
- api
- Uygulama
- uygulamaları
- Tamam
- yaklaşım
- uygun
- yay
- mimari
- ARE
- alanlar
- göre
- AS
- boy
- yönleri
- değerlendirilirler
- Değerlendirme
- Asistan
- At
- Dikkat
- mevcut
- baz
- temel
- BE
- dövmek
- Çünkü
- olmuştur
- önce
- başladı
- olmak
- altında
- kıyaslama
- kriterler
- İYİ
- arasında
- önyargıları
- Milyar
- Bit
- blogathon
- her ikisi de
- Daha geniş
- fakat
- by
- çağrı
- denilen
- CAN
- yetenekleri
- belli
- meydan okuma
- zorluklar
- zor
- sohbet
- choices
- seçilmiş
- sınıf
- Açıkça
- kapalı
- kod
- Sütun
- Sütunlar
- birleştirme
- nasıl
- ortak
- Sağduyu
- karşılaştırmak
- karşılaştırıldığında
- karşılaştırarak
- karşılaştırma
- rekabet
- karmaşık
- karmaşıklıklar
- karmaşıklık
- bilişimsel
- bilgisayar
- Bilgisayar Bilimleri
- kavramlar
- Endişeler
- sonucuna
- Davranış
- kabul
- tüketim
- içeren
- içerik
- bağlam
- devam
- kontrast
- katkıda
- çekirdek
- doğru
- olabilir
- kapaklar
- işlemci
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- çok önemli
- veri
- veri kümeleri
- azaltmak
- teslim etmek
- talepleri
- Gösteri
- göstermek
- tasviridir
- derinlik
- tasarlanmış
- Rağmen
- geliştiriciler
- gelişme
- farklı
- direkt
- direkt olarak
- disiplinler
- takdir
- farklılaşacaktır
- çeşitli
- do
- yok
- yapılmış
- indir
- indirme
- gereken
- her
- yemek
- Etkili
- etki
- verimli
- Yumurta
- vurgulayan
- istihdam
- istihdam
- uçları
- enerji
- Enerji Tüketimi
- yeterli
- olmasını sağlar
- Tüm
- çevre
- çevresel kaygılar
- devirler
- Eter (ETH)
- değerlendirmek
- değerlendirmeler
- Hatta
- her gün
- herkes
- gelişen
- örnek
- örnekler
- mevcut
- deneyler
- uzmanlara göre
- keşif
- Yüz
- gerçek
- şahin
- uzak
- Daha hızlı
- geribesleme
- az
- daha az
- alan
- son
- Ad
- flaş
- odaklanır
- takip
- takip etme
- İçin
- Airdrop Formu
- oluşum
- Ücretsiz
- itibaren
- daha fazla
- gelecek
- oluşturmak
- oluşturulan
- üreten
- nesil
- almak
- alma
- Vermek
- verilmiş
- Verilmesi
- Tercih Etmenizin
- var
- GPU
- Büyüme
- rehberlik
- Kolları
- kullanma
- donanım
- Var
- sahip olan
- bundan dolayı
- okuyun
- Yüksek
- en yüksek
- vurgulayarak
- tarih
- Ne kadar
- Nasıl Yapılır
- HTTPS
- merkez
- Kocaman
- SarılmaYüz
- insan
- İnsanlar
- if
- darbe
- etkileri
- ithalat
- önem
- etkileyici
- gelişmiş
- in
- başlangıç
- dahil
- içerir
- Dahil olmak üzere
- bilgi
- ilk
- yenilikler
- yenilikçi
- giriş
- anlayışlar
- kurmak
- örnek
- talimatlar
- içine
- tanıtmak
- tanıttı
- Tanıtımlar
- sezgisel
- dahil
- ilgili
- içerir
- içeren
- IT
- ONUN
- kendisi
- John
- yargılar
- sadece
- kumar
- dil
- büyük
- büyük
- Kanun
- koymak
- katmanları
- skor
- önemli
- öğrenme
- uzunluk
- Lets
- seviye
- leverages
- Kütüphane
- ömür
- sevmek
- LİMİT
- sınırlama
- sınırlamaları
- Sınırlı
- lama
- yük
- yükleme
- mantık
- mantıksal
- Bakın
- makine
- makine öğrenme
- ağırlıklı olarak
- büyük
- yapmak
- Makineleri
- YAPAR
- Yapımı
- çok
- masif
- matematik
- matematiksel
- matematik
- maksimum genişlik
- maksimum
- en yüksek miktar
- Mayıs..
- mekanizma
- medya
- anma
- gitmek
- birleştirme
- yöntem
- yöntemleri
- hataları
- karışım
- model
- modelleri
- Daha
- daha verimli
- çoklu
- isim
- gerekli
- gerek
- gerekli
- ihtiyaçlar
- ağlar
- yeni
- sonraki
- nlp
- dikkate değer
- ünlü
- şimdi
- gölgeleme
- numara
- Nvidia
- nesne
- of
- on
- ONE
- bir tek
- açık
- açık kaynak
- OpenAI
- işletme
- optimum
- optimizasyon
- or
- orijinal
- Diğer
- Diğer
- bizim
- dışarı
- sonuçlar
- daha iyi çalmak
- daha iyi performans
- bir üstün
- Mağazasından
- çıktı
- tekrar
- tüm
- Sahip olunan
- kâğıt
- parametre
- parametreler
- Bölüm
- geçmek
- yol
- yapmak
- performans
- performansları
- yapılan
- icra
- gerçekleştirir
- yer
- Platon
- Plato Veri Zekası
- PlatoVeri
- siyaset
- Popüler
- pozlar
- potansiyel
- güçlü
- tercihleri
- tercihli
- mevcut
- önceki
- problem çözme
- sorunlar
- süreç
- Süreçler
- istemleri
- kanıtlıyor
- sağlanan
- sağlar
- sağlama
- yayınlanan
- Python
- Sorular
- hızla
- değişen
- hızlı
- kolayca
- son
- geçenlerde
- düzenli
- takviye öğrenme
- Reddedilmiş..
- ilgili
- serbest
- serbest
- güvenilirlik
- Kaldır
- çıkarıldı
- kaldırma
- değiştirmek
- yerine
- gerektirir
- araştırma
- Araştırmacılar
- yoğun kaynak
- Kaynaklar
- yanıt
- yanıtları
- sonuç
- Sonuçlar
- İade
- krallar gibi yaşamaya
- titiz
- Risen
- koşmak
- koşu
- ishal
- Adı geçen
- aynı
- kaydedilmiş
- ölçek
- ölçekleme
- senaryolar
- Bilim
- bilimsel
- Gol
- skorları
- İkinci
- Bölüm
- görmek
- görme
- görünüyor
- görüldü
- duyu
- cümle
- Dizi
- set
- birkaç
- meli
- şov
- vitrine
- gösterme
- gösterilen
- Gösteriler
- benzer
- Basit
- beri
- tek
- becerileri
- akıllı telefonlar
- So
- güneş
- biraz
- sofistike
- Kaynak
- özel
- özellikle
- Belirtilen
- istif
- Aşama
- durmak
- başlama
- başladı
- XNUMX dakika içinde!
- başlar
- Açıklama
- adım
- Yine
- dur
- mağaza
- saklı
- Storm
- böyle
- üstün
- aşan
- aşarak
- eğilimli
- sürdürülebilir
- SVG
- sistem
- Bizi daha iyi tanımak için
- alınan
- alır
- görevleri
- teknik
- söylemek
- anlatır
- şablon
- test
- test edilmiş
- Test yapmak
- testleri
- metin
- göre
- o
- The
- Dünya
- ve bazı Asya
- Onları
- sonra
- Orada.
- Bunlar
- onlar
- Düşünme
- Re-Tweet
- Bu
- gerçi?
- düşünce
- üç
- İçinden
- Böylece
- zaman
- zamanlar
- için
- birlikte
- simge
- Jeton
- araç
- üst
- tepesinde
- geleneksel
- Tren
- eğitilmiş
- Eğitim
- transformatör
- transformatörler
- denemek
- iki
- tip
- uğrar
- anlamak
- anlayış
- hastaya
- benzersiz
- üzerine
- us
- kullanım
- kullanım
- Kullanılmış
- işe yarar
- kullanıcı
- kullanım
- kullanma
- kullanmak
- kullanılan
- Kullanılması
- değişken
- çeşitlilik
- çeşitli
- doğrulama
- çok yönlülük
- versiyon
- çok
- vs
- istemek
- oldu
- Yol..
- we
- webp
- İYİ
- vardı
- Ne
- Nedir
- ne zaman
- hangi
- süre
- Daha geniş
- irade
- ile
- olmadan
- İş
- çalışma
- çalışır
- Dünya
- sen
- zefirnet