Pandas, Python kullanarak veri işleme ve analizi için güçlü ve yaygın olarak kullanılan bir açık kaynak kitaplığıdır. Temel özelliklerinden biri, bir DataFrame'i bir veya daha fazla sütuna göre gruplara bölerek ve ardından bunların her birine çeşitli toplama işlevleri uygulayarak groupby işlevini kullanarak verileri gruplandırma yeteneğidir.

Image Unsplash
The groupby işlevi, büyük veri kümelerini hızlı bir şekilde özetlemenize ve analiz etmenize izin verdiği için inanılmaz derecede güçlüdür. Örneğin, bir veri kümesini belirli bir sütuna göre gruplayabilir ve her grup için kalan sütunların ortalamasını, toplamını veya sayısını hesaplayabilirsiniz. Ayrıca, verilerinizi daha ayrıntılı bir şekilde anlamak için birden çok sütuna göre gruplandırabilirsiniz. Ek olarak, karmaşık veri analizi görevleri için çok güçlü bir araç olabilen özel toplama işlevlerini uygulamanıza olanak tanır.
Bu eğitimde, farklı veri türlerini gruplandırmak ve farklı toplama işlemleri gerçekleştirmek için Pandas'ta groupby işlevini nasıl kullanacağınızı öğreneceksiniz. Bu eğitimin sonunda, verileri çeşitli şekillerde analiz etmek ve özetlemek için bu işlevi kullanabilmeniz gerekir.
Kavramlar iyi uygulandığında içselleştirilir ve bundan sonra yapacağımız şey budur, yani Pandas groupby işlevini uygulamalı hale getirmek. kullanılması tavsiye edilir Jupyter Not Defteri Bu eğitim için, her adımda çıktıyı görebildiğiniz için.
Örnek Veri Oluştur
Aşağıdaki kitaplıkları içe aktarın:
- Pandalar: Bir veri çerçevesi oluşturmak ve grubu şuna göre uygulamak için:
- Rastgele – Rastgele veriler oluşturmak için
- Pprint – Sözlükleri yazdırmak için
import pandas as pd
import random
import pprint
Ardından, boş bir veri çerçevesini başlatacağız ve aşağıda gösterildiği gibi her sütun için değerleri dolduracağız:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
Bonus ipucu – aynı görevi gerçekleştirmenin daha temiz bir yolu, tüm değişkenlerin ve değerlerin bir sözlüğünü oluşturmak ve daha sonra bunu bir veri çerçevesine dönüştürmektir.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
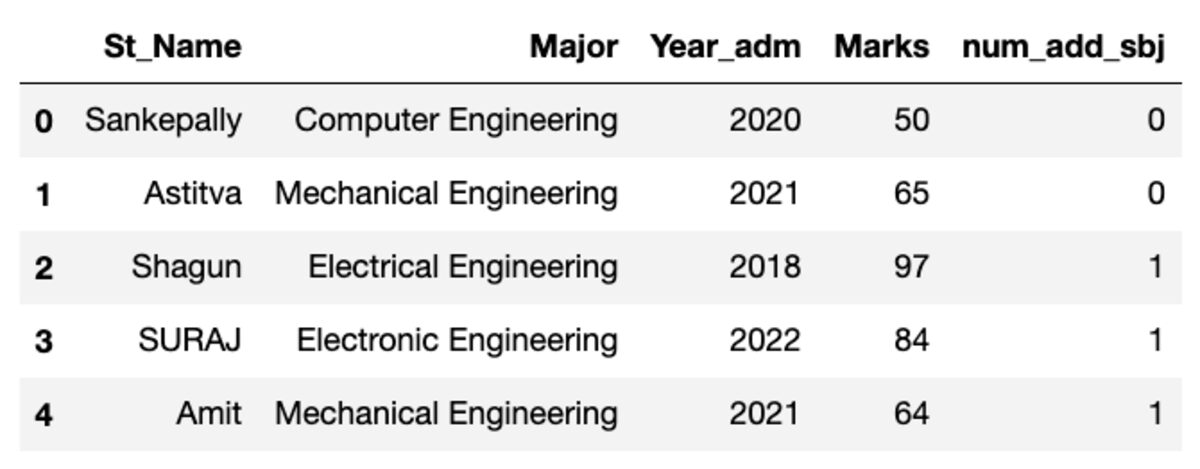
Veri çerçevesi aşağıda gösterilene benziyor. Bu kodu çalıştırırken, rastgele bir örnek kullandığımız için bazı değerler eşleşmeyecektir.
Grup Oluşturma
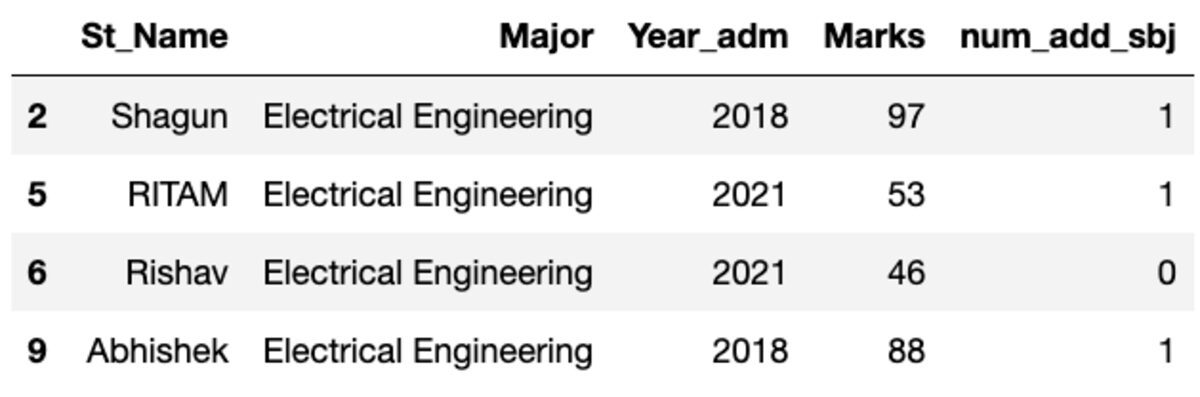
Verileri “Ana” konuya göre gruplandıralım ve bu gruba kaç kayıt düştüğünü görmek için grup filtresini uygulayalım.
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
Yani, dört öğrenci Elektrik Mühendisliği ana dalına aittir.
Birden fazla sütuna göre de gruplandırabilirsiniz (bu durumda Majör ve num_add_sbj).
groups = df.groupby(['Major', 'num_add_sbj'])
Tek sütunlu gruplara uygulanabilen tüm toplama işlevlerinin birden çok sütunlu gruplara da uygulanabileceğini unutmayın. Eğitimin geri kalanında, örnek olarak tek bir sütun kullanarak farklı toplama türlerine odaklanalım.
“Major” kolonunda groupby kullanarak gruplar oluşturalım.
groups = df.groupby('Major')Doğrudan İşlevleri Uygulama
Diyelim ki her bir Ana Daldaki ortalama notları bulmak istiyorsunuz. Sen ne yapardın?
- İşaretler sütununu seçin
- Ortalama işlevi uygula
- İşaretleri iki ondalık basamağa yuvarlamak için yuvarlama işlevini uygulayın (isteğe bağlı)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
toplam
Aynı sonucu elde etmenin başka bir yolu, aşağıda gösterildiği gibi bir toplama işlevi kullanmaktır:
groups['Marks'].aggregate('mean').round(2)
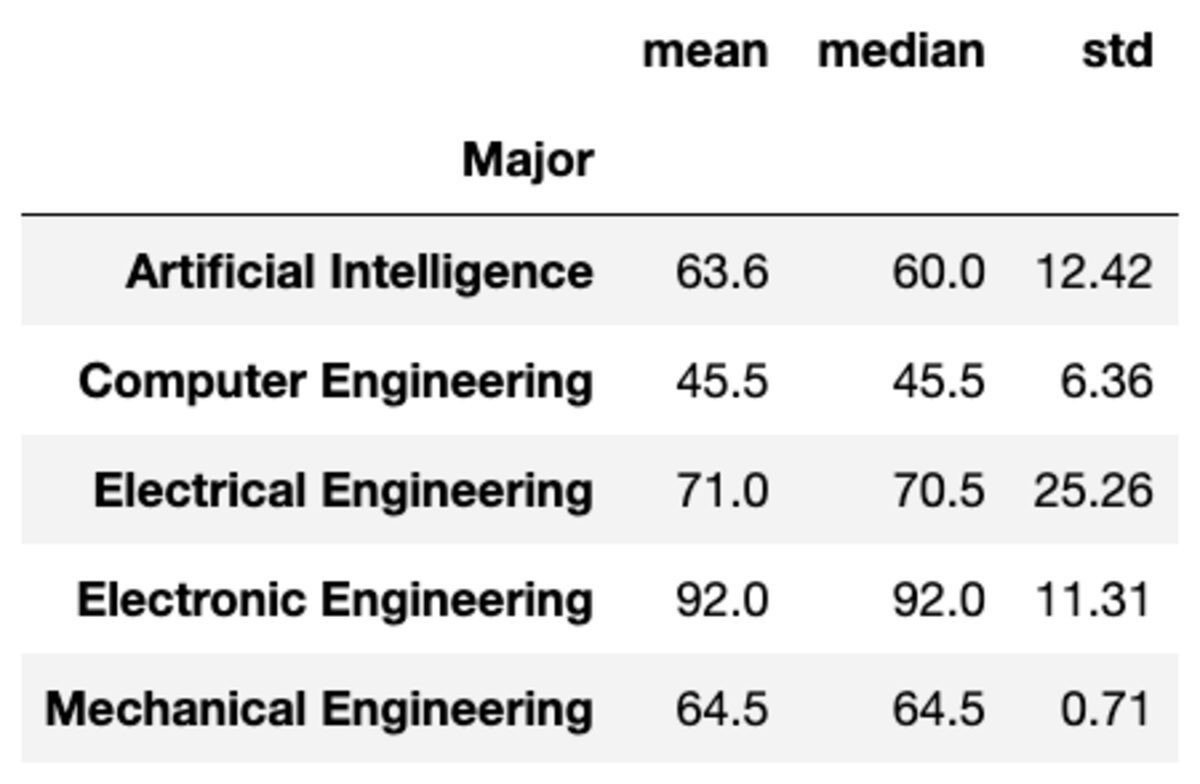
İşlevleri bir dize listesi olarak ileterek gruplara birden çok toplama da uygulayabilirsiniz.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
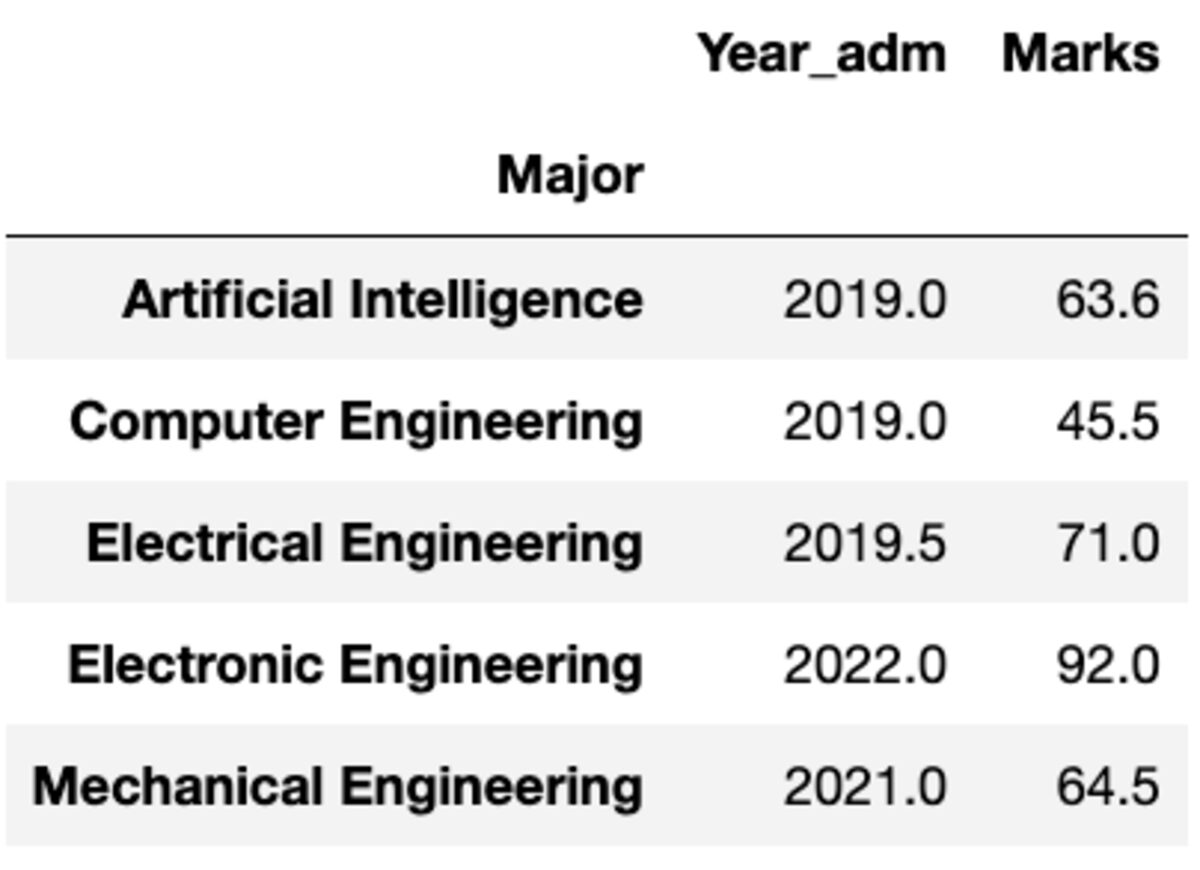
Ancak, farklı bir sütuna farklı bir işlev uygulamanız gerekirse ne olur? Merak etme. Bunu {column: function} çiftini ileterek de yapabilirsiniz.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
Dönüşümler
Belirli bir sütunda groupby() kullanılarak kolayca elde edilebilecek özel dönüşümler gerçekleştirmeniz çok iyi bir şekilde gerekebilir. Sklearn'ün ön işleme modülünde bulunana benzer bir standart skaler tanımlayalım. transform yöntemini çağırarak ve özel işlevi geçerek tüm sütunları dönüştürebilirsiniz.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
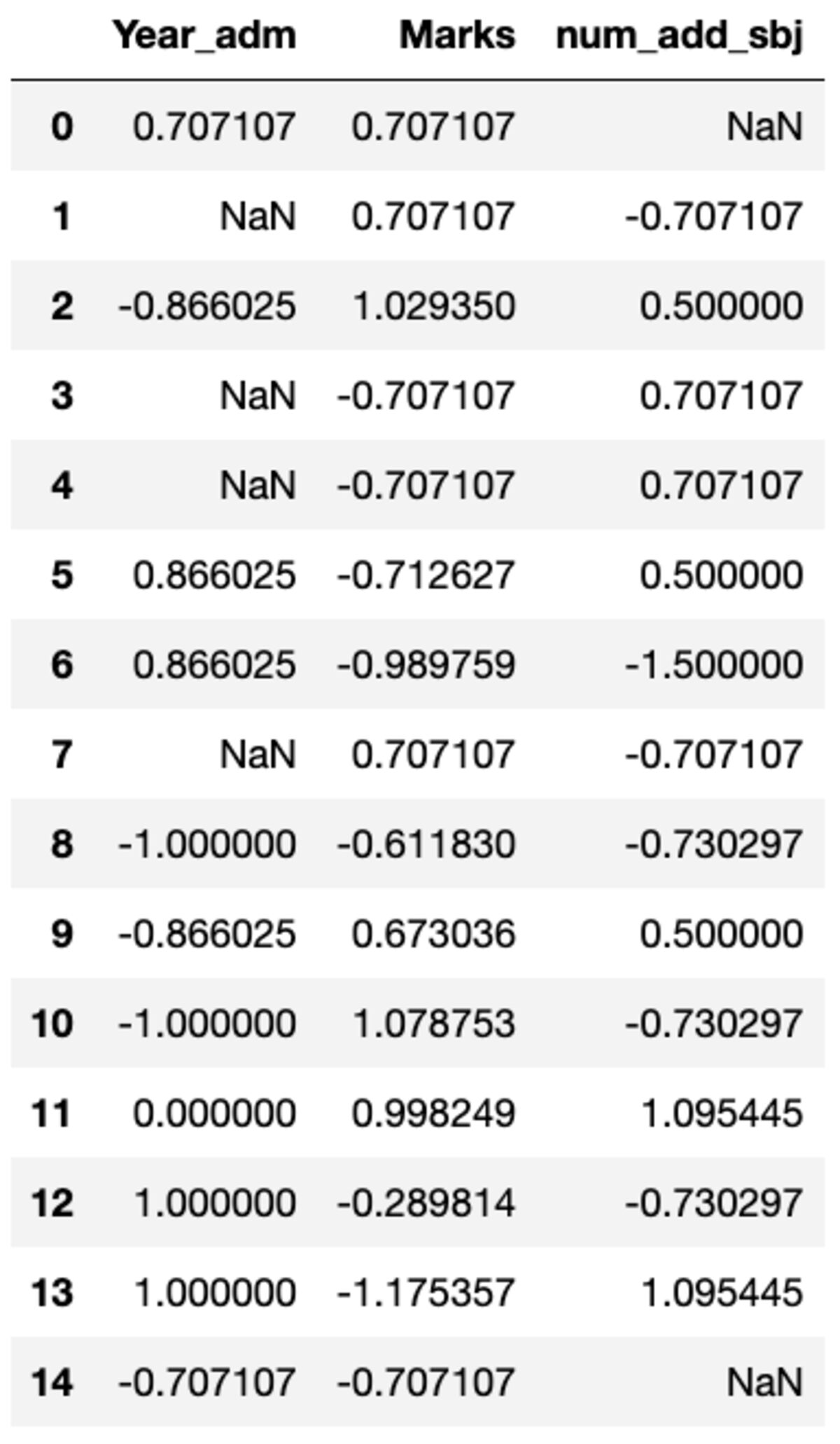
"NaN"nin sıfır standart sapmalı grupları temsil ettiğini unutmayın.
filtre
Hangi "Bölümün" düşük performans gösterdiğini kontrol etmek isteyebilirsiniz, yani ortalama öğrenci "Puanlarının" 60'ın altında olduğu bölüm. Bu, içinde bir işlevi olan gruplara bir filtre yöntemi uygulamanızı gerektirir. Aşağıdaki kod bir kullanır lambda işlevi filtrelenmiş sonuçlara ulaşmak için.
groups.filter(lambda x: x['Marks'].mean() 60)

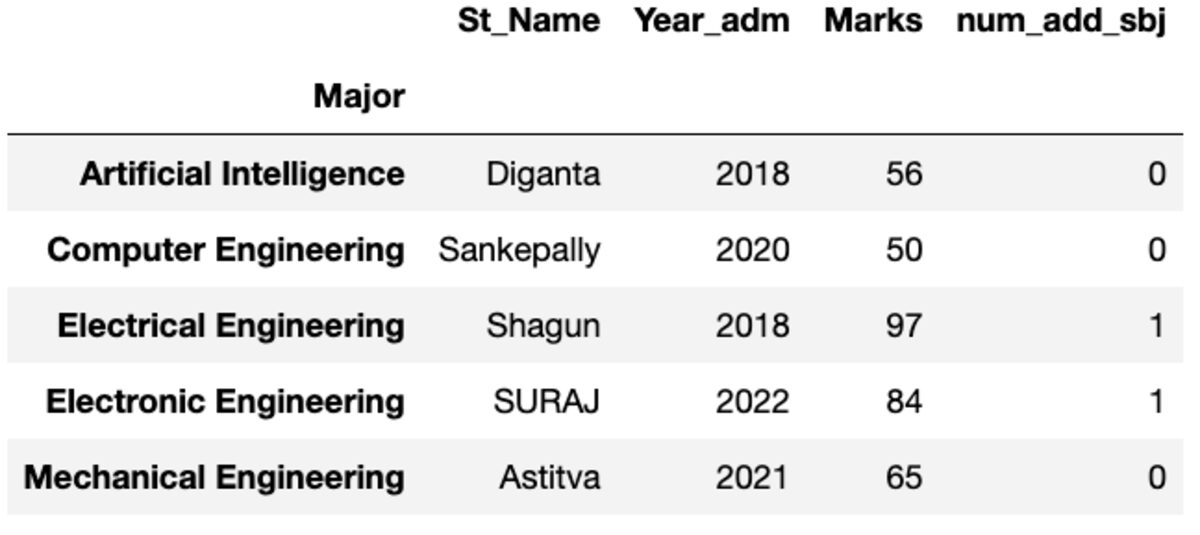
Ad
Size dizine göre sıralanmış ilk örneğini verir.
groups.first()
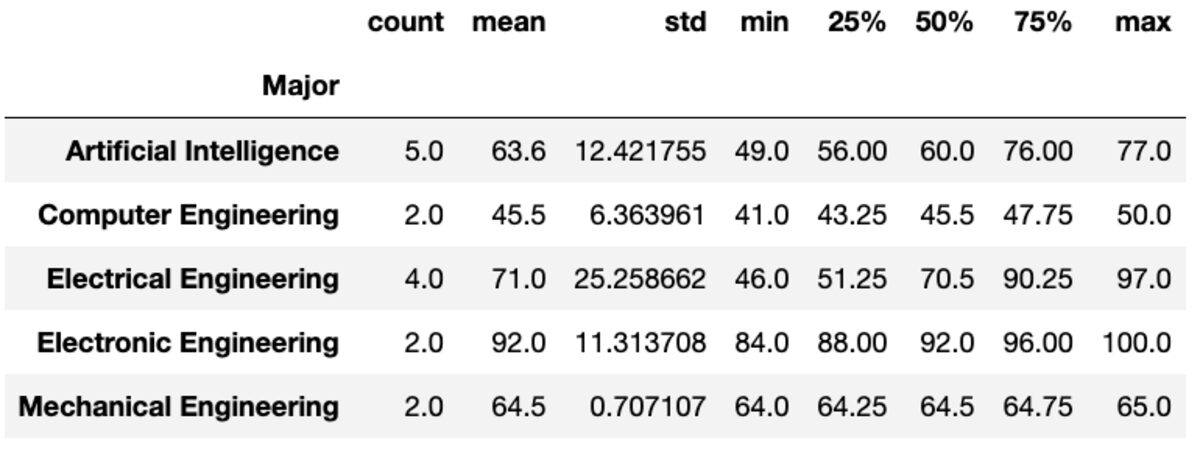
Tanımlamak
"Tanımla" yöntemi, verilen sütunlar için sayım, ortalama, std, min, maksimum vb. gibi temel istatistikleri döndürür.
groups['Marks'].describe()
beden
Boyut, adından da anlaşılacağı gibi, her grubun boyutunu kayıt sayısı cinsinden verir.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
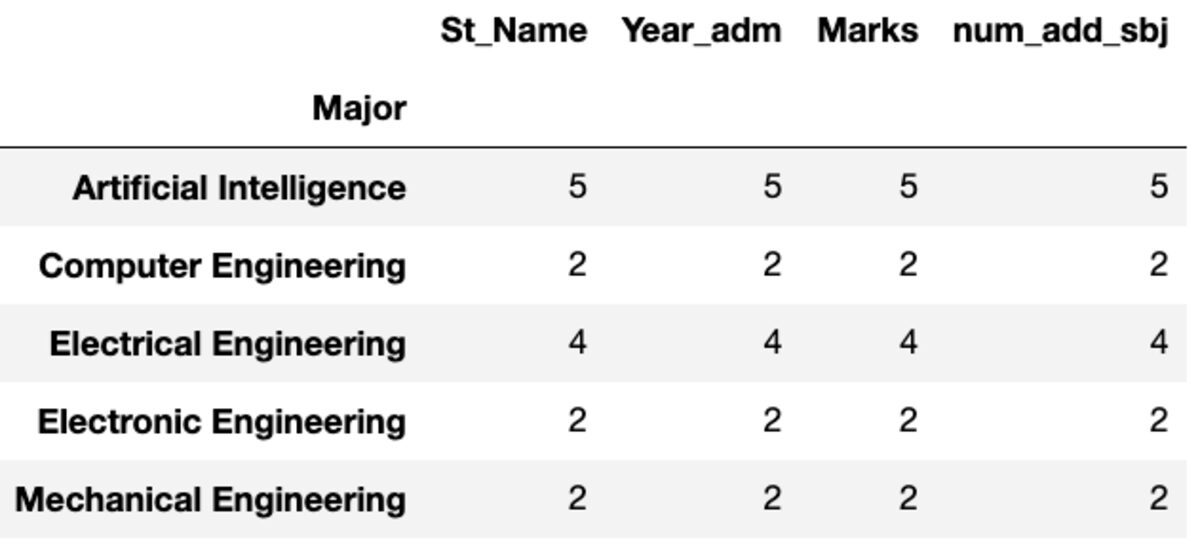
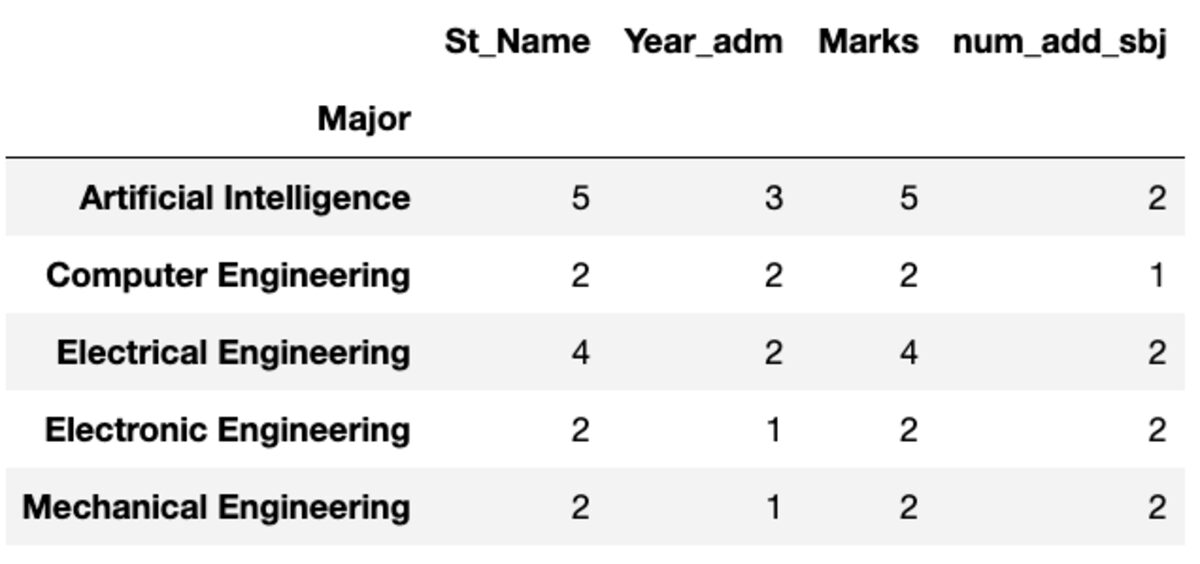
dtype: int64Kont ve Nunique
"Count" tüm değerleri döndürürken "Nunique" yalnızca o gruptaki benzersiz değerleri döndürür.
groups.count()
groups.nunique()
adını değiştirmek
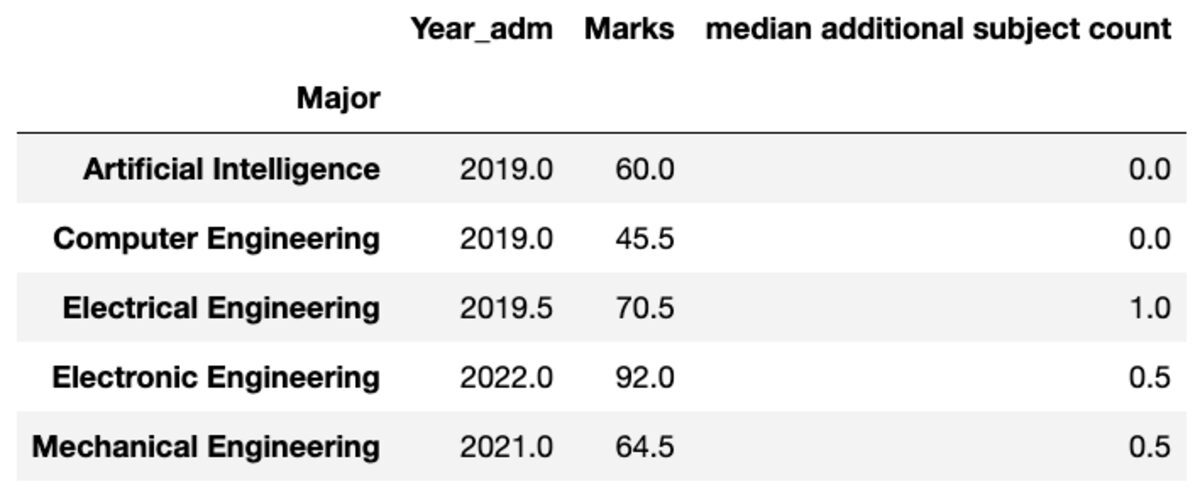
Toplanan sütunların adını da tercihinize göre yeniden adlandırabilirsiniz.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- Gruplandırmanın amacı konusunda net olun: Başka bir sütunun ortalamasını almak için verileri bir sütuna göre gruplandırmaya mı çalışıyorsunuz? Yoksa her gruptaki satırların sayısını almak için verileri birden çok sütuna göre gruplandırmaya mı çalışıyorsunuz?
- Veri çerçevesinin indekslenmesini anlayın: groupby işlevi, verileri gruplandırmak için dizini kullanır. Verileri bir sütuna göre gruplandırmak istiyorsanız, sütunun dizin olarak ayarlandığından emin olun veya .set_index() işlevini kullanabilirsiniz.
- Uygun toplama işlevini kullanın: Mean(), sum(), count(), min(), max() gibi çeşitli toplama işlevleriyle birlikte kullanılabilir.
- as_index parametresini kullanın: False olarak ayarlandığında, bu parametre pandalara gruplandırılmış sütunları dizin yerine normal sütunlar olarak kullanmalarını söyler.
Verilerinizden daha fazla içgörü elde etmek için groupby() işlevini pivot_table(), crosstab() ve cut() gibi diğer panda işlevleriyle birlikte de kullanabilirsiniz.
Groupby işlevi, veri satırlarını bir veya daha fazla sütuna göre gruplandırmanıza ve ardından gruplar üzerinde toplu hesaplamalar yapmanıza olanak tanıdığından, veri analizi ve işleme için güçlü bir araçtır. Öğretici, kod örneklerinin yardımıyla groupby işlevini kullanmanın çeşitli yollarını gösterdi. Umarız, beraberinde gelen farklı seçenekleri ve bunların veri analizinde nasıl yardımcı olduğunu anlamanızı sağlar.
Vidhi Chugh ölçeklenebilir makine öğrenimi sistemleri oluşturmak için ürün, bilim ve mühendisliğin kesiştiği noktada çalışan bir yapay zeka stratejisti ve dijital dönüşüm lideridir. Ödüllü bir inovasyon lideri, yazar ve uluslararası bir konuşmacıdır. Makine öğrenimini demokratikleştirme ve herkesin bu dönüşümün bir parçası olması için jargonu kırma misyonunda.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- kabiliyet
- Yapabilmek
- Başarmak
- elde
- Ek
- Ayrıca
- toplanma
- AI
- Türkiye
- veriyor
- analiz
- çözümlemek
- ve
- Başka
- uygulamalı
- Tamam
- Uygulanması
- uygun
- yapay
- yapay zeka
- yazar
- mevcut
- ortalama
- Ödüllü
- merkezli
- temel
- altında
- biyoteknoloji
- mola
- inşa etmek
- hesaplamak
- çağrı
- dava
- Kontrol
- açık
- kod
- Sütun
- Sütunlar
- nasıl
- karmaşık
- bilgisayar
- Bilgisayar Mühendisliği
- yaratmak
- Oluşturma
- görenek
- veri
- veri analizi
- veri kümeleri
- demokratikleştirmek
- gösterdi
- sapma
- farklı
- dijital
- dijital Dönüşüm
- direkt
- Dont
- her
- kolayca
- etkili bir şekilde
- elektrik Mühendisliği
- Elektronik
- Mühendislik
- vb
- herkes
- örnek
- örnekler
- çıkarmak
- Düşmek
- Özellikler
- doldurmak
- filtre
- bulmak
- Ad
- odak
- takip etme
- ÇERÇEVE
- itibaren
- işlev
- fonksiyonlar
- oluşturmak
- almak
- verilmiş
- verir
- gidiş
- grup
- Grubun
- hands-on
- yardım et
- umut
- Ne kadar
- Nasıl Yapılır
- HTML
- HTTPS
- ithalat
- in
- inanılmaz
- indeks
- Yenilikçilik
- anlayışlar
- örnek
- yerine
- İstihbarat
- Uluslararası
- kavşak
- IT
- jargon
- KDNuggets
- anahtar
- büyük
- lider
- ÖĞRENİN
- öğrenme
- kütüphaneler
- Kütüphane
- Liste
- GÖRÜNÜYOR
- makine
- makine öğrenme
- büyük
- yapmak
- hile
- çok
- Maç
- maksimum
- mekanik
- Makine mühendisliği
- orta
- yöntem
- Misyonumuz
- modül
- Daha
- çoklu
- isim
- isimleri
- gerek
- sonraki
- numara
- ONE
- açık kaynak
- Operasyon
- Opsiyonlar
- Diğer
- pandalar
- parametre
- Bölüm
- belirli
- Geçen
- yapmak
- Yerler
- Platon
- Plato Veri Zekası
- PlatoVeri
- güçlü
- PLATFORM
- sağlar
- amaç
- Python
- hızla
- rasgele
- Tavsiye edilen
- kayıtlar
- düzenli
- kalan
- temsil
- gerektirir
- DİNLENME
- sonuç
- Sonuçlar
- dönüş
- İade
- Richard
- yuvarlak
- koşu
- aynı
- ölçeklenebilir
- BİLİMLERİ
- set
- meli
- gösterilen
- benzer
- tek
- beden
- biraz
- konuşmacı
- özel
- standart
- istatistik
- adım
- Stratejist
- Öğrenci
- Öğrenciler
- konu
- Önerdi
- özetlemek
- Sistemler
- Görev
- görevleri
- anlatır
- şartlar
- The
- tip
- için
- araç
- Dönüştürmek
- Dönüşüm
- dönüşümler
- öğretici
- türleri
- anlayış
- benzersiz
- kullanım
- Değerler
- çeşitli
- yolları
- Ne
- hangi
- irade
- çalışma
- olur
- X
- yıl
- zefirnet
- sıfır






