Modern dünyada çoğu işletme, büyümelerini, stratejik yatırımlarını ve müşteri bağlılığını artırmak için büyük verinin ve analitiğin gücüne güveniyor. Büyük veri, hedeflenen reklam, kişiselleştirilmiş pazarlama, ürün önerileri, içgörü üretimi, fiyat optimizasyonları, duyarlılık analizi, tahmine dayalı analitik ve çok daha fazlasının temelinde yatan sabittir.
Veriler genellikle birden çok kaynaktan toplanır, şirket içi veya bulut üzerindeki veri göllerinde dönüştürülür, depolanır ve işlenir. Verilerin ilk alımı nispeten önemsiz olsa da ve kurum içinde geliştirilen özel komut dosyaları veya geleneksel ETL (Dönüşüm Yükünü Çıkart) araçlarıyla elde edilebilse de, şirketlerin aşağıdakileri yapması gerektiğinden, sorun kısa sürede engelleyici derecede karmaşık ve çözülmesi pahalı hale gelir:
- Tüm veri yaşam döngüsünü yönetin – temizlik ve uyumluluk amaçları için
- Depolamayı optimize edin – ilişkili maliyetleri azaltmak için
- Bilgi işlem altyapısının yeniden kullanımı yoluyla Mimariyi Basitleştirin
- Verileri kademeli olarak işleyin – güçlü durum yönetimi aracılığıyla
- Toplu iş ve akış verilerine aynı politikaları uygulayın – aynı çabayı tekrarlamadan
- Şirket İçi ve Bulut arasında en az çabayla geçiş yapın
O nerede Apaçi Goblini, açık kaynaklı bir veri yönetimi ve entegrasyon sistemi devreye giriyor. Apache Gobblin, işletmenin ihtiyaçlarına göre kısmen veya tamamen kullanılabilen benzersiz yetenekler sunuyor.
Bu bölümde, Apache Gobblin'in daha önce özetlenen zorlukların üstesinden gelmeye yardımcı olan çeşitli yeteneklerini inceleyeceğiz.
Tam veri yaşam döngüsünü yönetme
Apache Gobblin, veri kümelerinde tüm veri yaşam döngüsü işlemlerini destekleyen veri ardışık düzenleri oluşturmak için çeşitli yetenekler sağlar.
- Birden çok kaynaktan Veritabanları, Rest API'leri, FTP/SFTP sunucuları, Dosyalayıcılar, Salesforce ve Dynamics gibi CRM'ler ve daha fazlası gibi havuzlara veri alın.
- Distcp-NG aracılığıyla Hadoop Dağıtılmış Dosya Sistemi için özel yeteneklere sahip birden çok veri gölü arasında verileri çoğaltın.
- Verileri Temizle – Zamana Dayalı, En Yeni K, Sürümlü veya ilkelerin bir kombinasyonu gibi saklama ilkelerini kullanarak.
Gobblin'in mantıksal ardışık düzeni, iş dağıtımını belirleyen ve 'Çalışma Birimleri' oluşturan bir 'Kaynak'tan oluşur. Bu "Çalışma Birimleri" daha sonra, çıkarma, dönüştürme, kalite kontrolü ve verilerin hedefe yazılmasını içeren "Görevler" olarak yürütülmek üzere alınır. Son adım olan 'Veri Yayınlama', ardışık düzenin başarılı bir şekilde yürütüldüğünü doğrular ve hedef destekliyorsa çıktı verilerini atomik olarak işler.
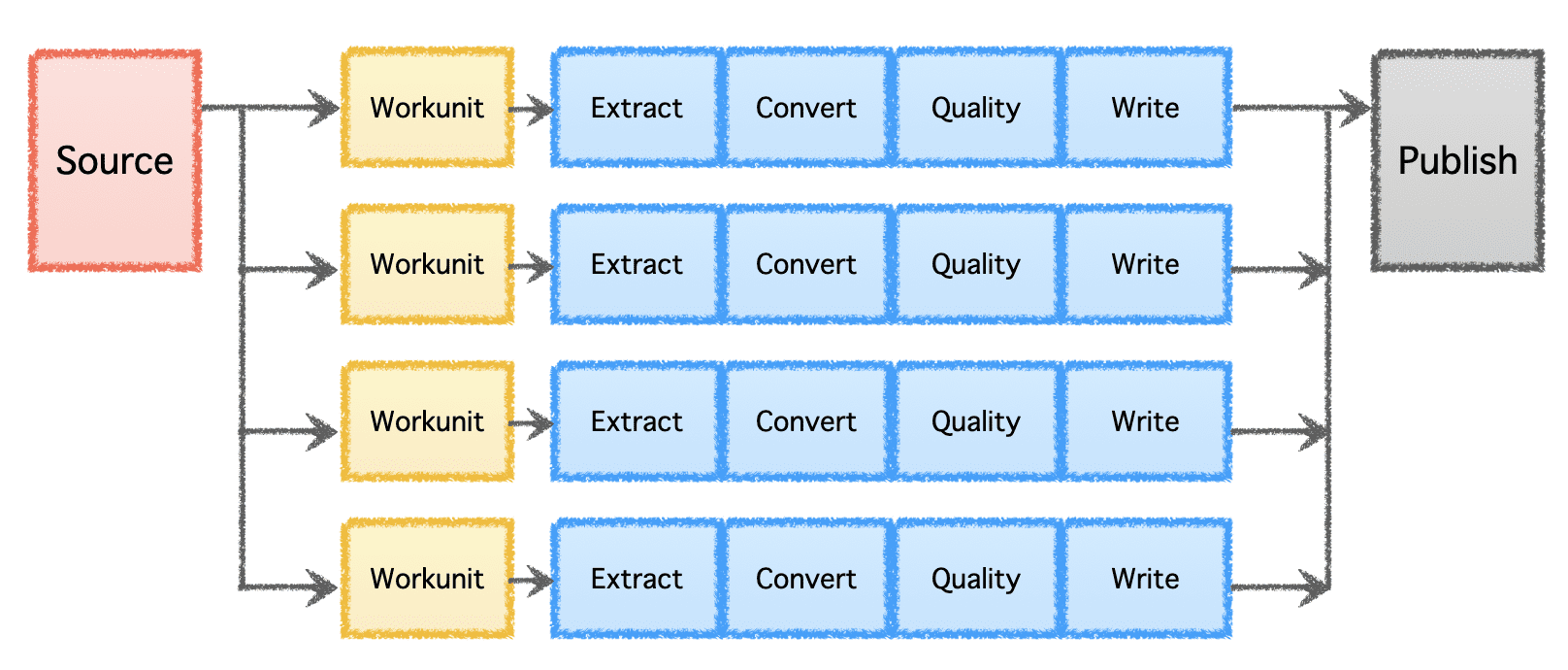
Yazara göre resim
Depolama alanını optimize et
Apache Gobblin, sıkıştırma veya format dönüştürme yoluyla alma veya çoğaltma sonrasında verilerin sonradan işlenmesi yoluyla veriler için gereken depolama miktarının azaltılmasına yardımcı olabilir.
- Sıkıştırma – kayıtların tüm alanlarına veya anahtar alanlarına dayalı olarak yinelenenleri kaldırmak için son işleme verileri, aynı anahtarla en son zaman damgasına sahip yalnızca bir kaydı tutmak için verileri kırpın.
- Avro'dan ORC'ye – popüler satır tabanlı Avro biçimini hiper optimize edilmiş sütun tabanlı ORC biçimine dönüştürmek için özel bir biçim dönüştürme mekanizması olarak.
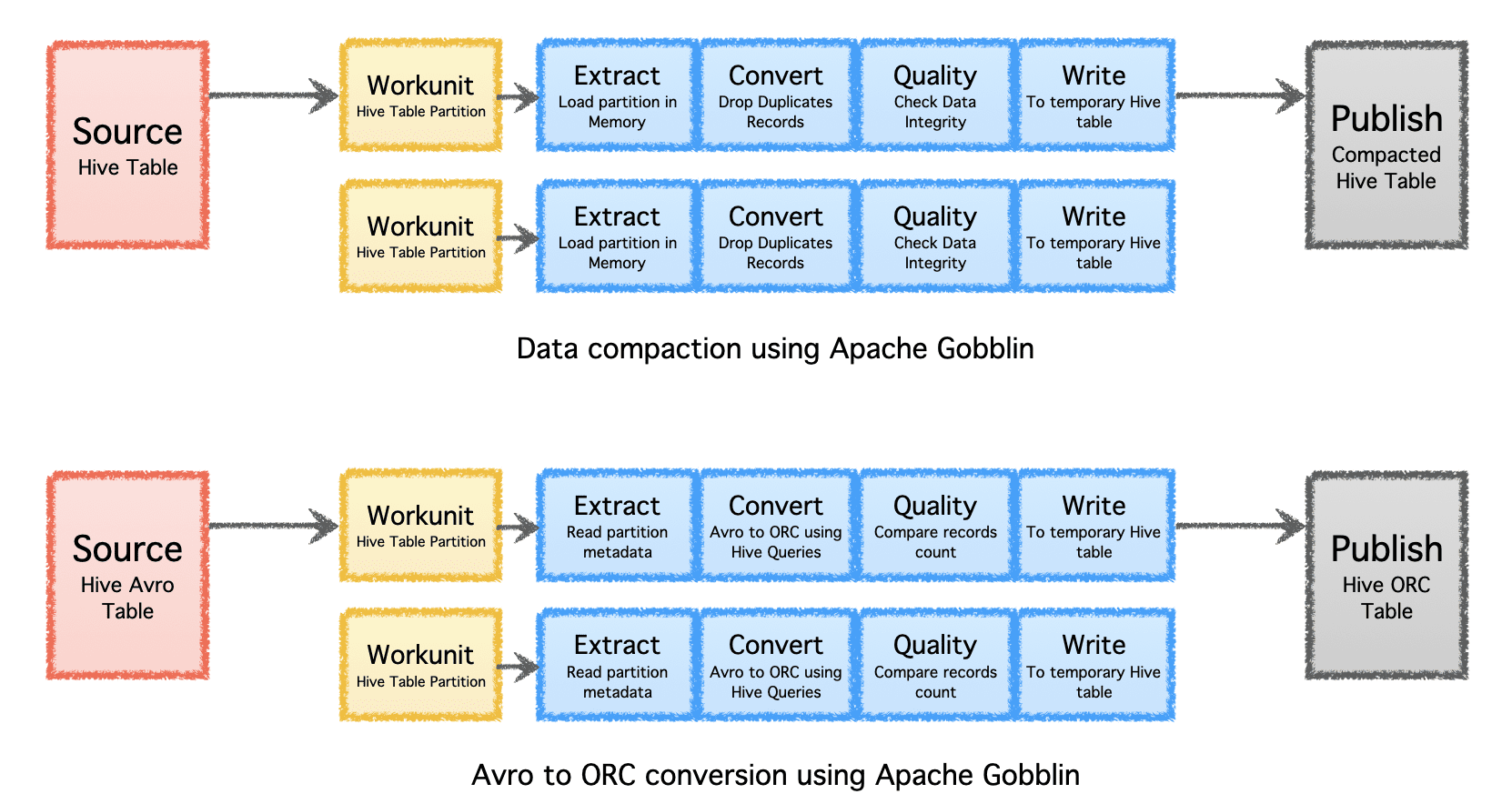
Yazara göre resim
Mimariyi Basitleştirin
Şirketin aşamasına (başlangıçtan işletmeye), ölçek gereksinimlerine ve ilgili mimarilerine bağlı olarak, şirketler veri altyapılarını kurmayı veya geliştirmeyi tercih eder. Apache Gobblin çok esnektir ve çoklu yürütme modellerini destekler.
- Bağımsız Mod – çıplak bir metal kutu üzerinde bağımsız bir süreç olarak çalışmak için, yani basit kullanım durumları ve düşük talep gerektiren durumlar için tek ana bilgisayar.
- MapReduce Modu – Petabayt ölçeğinde değişen veri kümelerini işlemek üzere büyük veri vakaları için Hadoop altyapısında bir MapReduce işi olarak çalışmak üzere.
- Küme Modu: Bağımsız – Hadoop MR çerçevesinden bağımsız olarak büyük ölçekte işlem yapmak için bir dizi çıplak metal makine veya ana bilgisayarda Apache Helix ve Apache Zookeeper tarafından desteklenen bir küme olarak çalışmak üzere.
- Küme Modu: Yarn – Hadoop MR çerçevesi olmadan yerel Yarn üzerinde bir küme olarak çalışmak için.
- Küme Modu: AWS – Amazon'un genel bulut teklifinde bir küme olarak çalışmak için, örn. AWS'de barındırılan altyapılar için AWS.
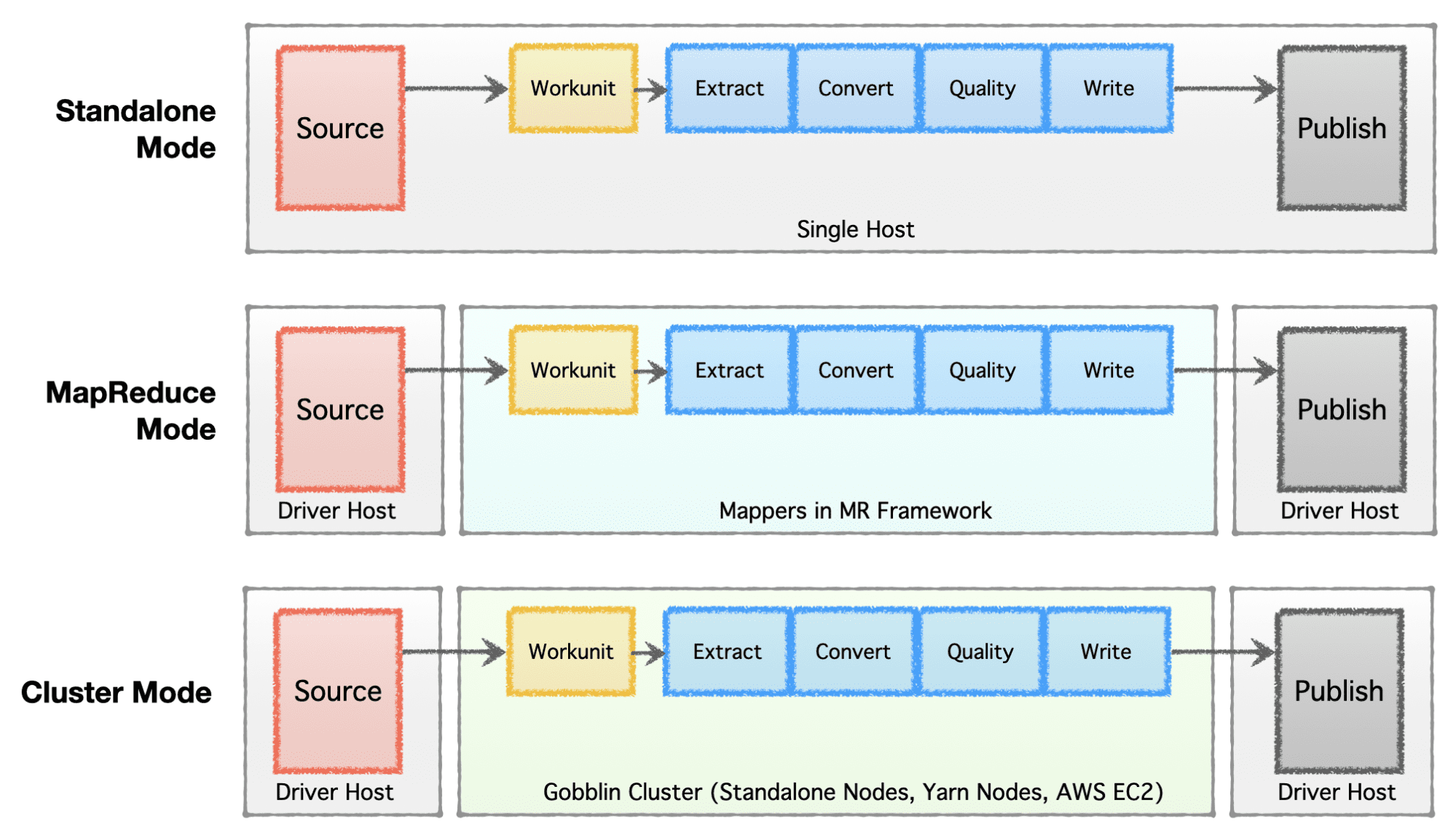
Yazara göre resim
Kademeli olarak verileri işleyin
Birden çok veri ardışık düzeni ve yüksek hacimli önemli bir ölçekte, verilerin toplu olarak ve zaman içinde işlenmesi gerekir. Bu nedenle, veri boru hatlarının en son kaldığı yerden devam edebilmesi ve devam edebilmesi için kontrol noktası oluşturmayı gerektirir. Apache Gobblin düşük ve yüksek filigranları destekler ve HDFS, AWS S3, MySQL ve daha şeffaf bir şekilde State Store aracılığıyla güçlü durum yönetimi semantiğini destekler.
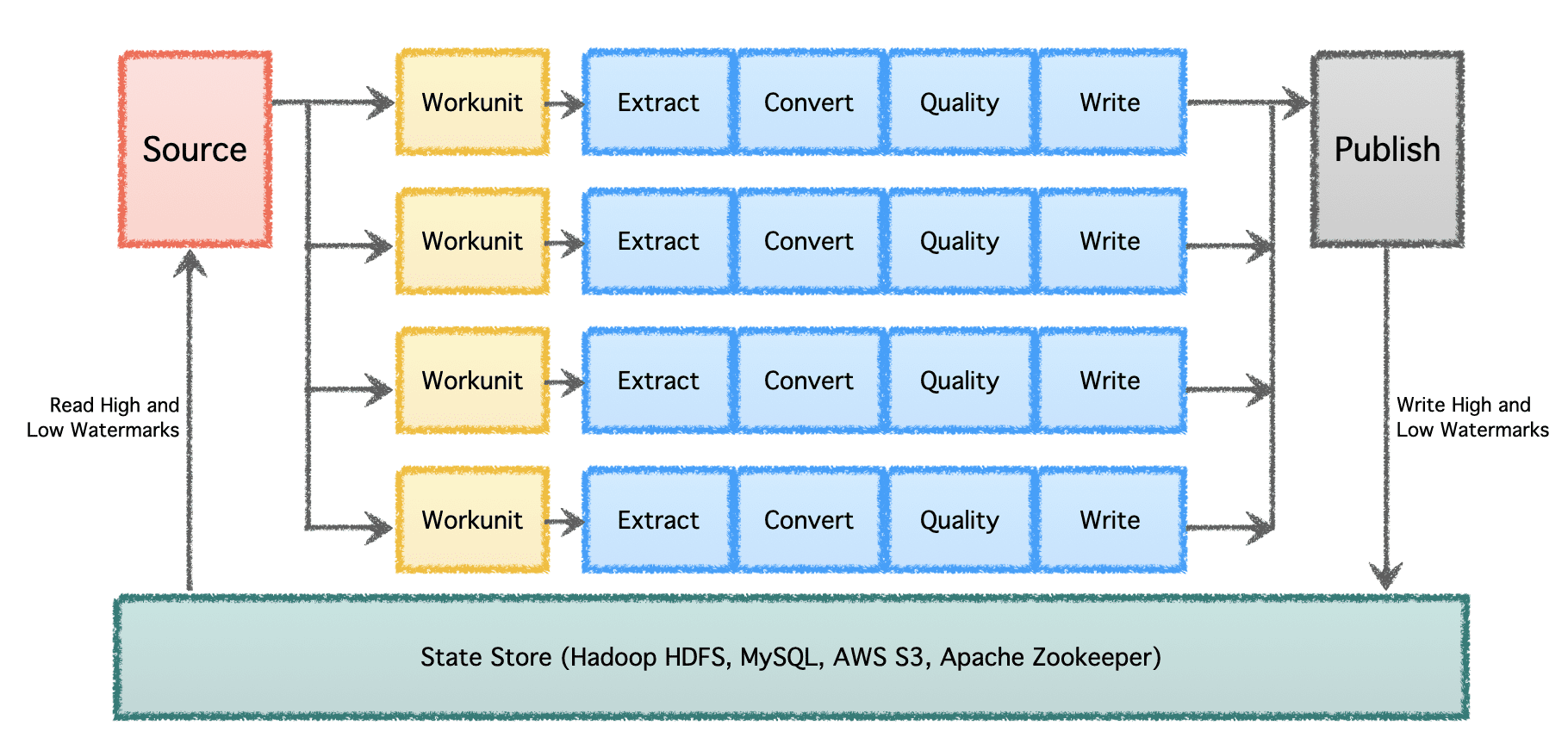
Yazara göre resim
Toplu iş ve akış verilerinde aynı politikalar
Günümüzde çoğu veri ardışık düzeni, bir kez toplu veriler için ve yine yakın hat veya akış verileri için olmak üzere iki kez yazılmalıdır. Çabayı iki katına çıkarır ve farklı işlem hattı türlerine uygulanan politikalarda ve algoritmalarda tutarsızlıklar ortaya çıkarır. Apache Gobblin, Gobblin Cluster modunda, Gobblin AWS modunda veya Gobblin on Yarn modunda kullanılıyorsa kullanıcıların bir ardışık düzen yazmasına ve bunu hem toplu iş hem de akış verilerinde çalıştırmasına izin vererek bu sorunu çözer.
Şirket İçi ve Bulut arasında geçiş yapın
Tek bir kutuda, bir düğüm kümesinde veya bulutta şirket içinde çalışabilen çok yönlü modları sayesinde Apache Gobblin şirket içinde ve bulutta dağıtılabilir ve kullanılabilir. Bu nedenle, kullanıcıların veri boru hatlarını bir kez yazmalarına ve belirli ihtiyaçlara dayalı olarak Gobblin dağıtımlarıyla birlikte kurum içi ve bulut arasında kolayca taşımalarına olanak tanır.
Son derece esnek mimarisi, güçlü özellikleri ve destekleyebileceği ve işleyebileceği aşırı veri hacimleri ölçeği nedeniyle Apache Gobblin, üretim altyapısında kullanılmaktadır. büyük teknoloji şirketleri ve günümüzde herhangi bir büyük veri altyapısı dağıtımı için olmazsa olmazdır.
Apache Gobblin ve nasıl kullanılacağı hakkında daha fazla ayrıntı şu adreste bulunabilir: https://gobblin.apache.org
Abhishek Tiwari LinkedIn'de şirketin Büyük Veri Boru Hatları organizasyonuna liderlik eden Kıdemli Yöneticisidir. Aynı zamanda Apache Software Foundation'da Apache Gobblin'in Başkan Yardımcısı ve British Computer Society üyesidir.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- elde
- adresleme
- reklâm
- Sonra
- Yardım
- algoritmalar
- Türkiye
- Izin
- miktar
- analiz
- analytics
- ve
- Apache
- API'ler
- uygulamalı
- mimari
- ilişkili
- yazar
- AWS
- arka çıkılmış
- merkezli
- olur
- arasında
- Büyük
- büyük Veri
- kutu
- ingiliz
- iş
- işletmeler
- yetenekleri
- durumlarda
- zorluklar
- denetleme
- bulut
- Küme
- kombinasyon
- Şirketler
- şirket
- karmaşık
- uyma
- bilgisayar
- bilgisayar
- sabit
- kurmak
- devam etmek
- Dönüştürme
- dönüştürmek
- oluşturur
- görenek
- müşteri
- Müşteri katılımı
- veri
- veri altyapısı
- veri yönetimi
- veritabanları
- veri kümeleri
- bağlı
- konuşlandırılmış
- açılma
- dağıtımları
- hedef
- ayrıntılar
- belirleyen
- gelişmiş
- farklı
- dağıtıldı
- dağıtım
- dinamik
- kolayca
- çaba
- nişan
- kuruluş
- Eter (ETH)
- gelişmek
- infaz
- pahalı
- çıkarmak
- çıkarma
- aşırı
- Özellikler
- adam
- Alanlar
- fileto
- son
- esnek
- biçim
- bulundu
- vakıf
- iskelet
- itibaren
- Yakıt
- tam
- nesil
- Büyüme
- Hadoop'un
- sap
- yardım et
- Yüksek
- büyük ölçüde
- ev sahibi
- ev sahipliği yaptı
- Ne kadar
- Nasıl Yapılır
- HTTPS
- in
- dahil
- bağımsız
- Altyapı
- altyapı
- ilk
- anlayışlar
- bütünleşme
- Tanıtımlar
- Yatırımlar
- IT
- İş
- KDNuggets
- tutmak
- anahtar
- büyük
- Soyad
- son
- önemli
- yük
- Düşük
- Makineler
- yönetim
- müdür
- Pazarlama
- mekanizma
- metal
- göç
- Moda
- modelleri
- Modern
- modları
- Daha
- çoğu
- çoklu
- Olması Gereken
- MySQL
- yerli
- gerekli
- ihtiyaçlar
- en yeni
- düğümler
- teklif
- ONE
- açık kaynak
- Operasyon
- kuruluşlar
- özetlenen
- parçalar
- Kişiselleştirilmiş
- seçilmiş
- boru hattı
- Platon
- Plato Veri Zekası
- PlatoVeri
- politikaları
- Popüler
- güç kelimesini seçerim
- güçlü
- Akıllı Analytics
- tercih
- başkan
- Önceden
- fiyat
- Sorun
- süreç
- PLATFORM
- üretim
- sağlar
- halka açık
- Genel bulut
- yayınlamak
- kalite
- hızla
- değişen
- tavsiyeler
- kayıt
- kayıtlar
- azaltmak
- Nispeten
- kopya
- Yer Alan Kurallar
- bu
- DİNLENME
- devam et
- tutma
- gürbüz
- koşmak
- satış ekibi
- aynı
- ölçek
- ölçekleme
- scriptler
- Bölüm
- semantik
- kıdemli
- duygu
- set
- önemli
- Basit
- tek
- durumlar
- So
- Toplum
- Yazılım
- ÇÖZMEK
- çözer
- Kaynak
- kaynaklar
- özel
- özel
- Aşama
- bağımsız
- başlangıç
- Eyalet
- adım
- hafızası
- mağaza
- saklı
- Stratejik
- dere
- akış
- başarılı
- süit
- destek
- Destekler
- sistem
- Hedeflenen
- görevleri
- Teknoloji
- The
- ve bazı Asya
- bu nedenle
- İçinden
- zaman
- zaman damgası
- için
- bugün
- araçlar
- geleneksel
- Dönüştürmek
- transforme
- türleri
- altında yatan
- benzersiz
- kullanım
- kullanıcılar
- çeşitli
- çok yönlü
- üzerinden
- Başkan Yardımcısı
- hacim
- hacimleri
- hangi
- süre
- irade
- olmadan
- İş
- Dünya
- yazmak
- yazı yazıyor
- yazılı
- zefirnet