Bu yazı LSEG'in Düşük Gecikme Grubundan Pramod Nayak, LakshmiKanth Mannem ve Vivek Aggarwal ile birlikte yazılmıştır.
İşlem maliyeti analizi (TCA), yatırımcılar, portföy yöneticileri ve komisyoncular tarafından işlem öncesi ve işlem sonrası analiz için yaygın olarak kullanılır ve işlem maliyetlerini ve işlem stratejilerinin etkinliğini ölçmelerine ve optimize etmelerine yardımcı olur. Bu yazıda, opsiyonların teklif-ask spreadlerini analiz ediyoruz. LSEG Kene Geçmişi – PCAP veri kümesi kullanılarak Apache Spark için Amazon Athena. Büyük veri kümeleri için bile altyapı kurma veya Spark'ı yapılandırma konusunda endişelenmenize gerek kalmadan verilere nasıl erişeceğinizi, verilere nasıl uygulayacağınızı, veri kümesini sorgulayıp filtreleyeceğinizi ve analiz sonuçlarını nasıl görselleştireceğinizi gösteriyoruz.
Olayın Arka Planı
Opsiyon Fiyat Raporlama Otoritesi (OPRA), ABD Opsiyonları için son satış raporlarını, fiyat tekliflerini ve ilgili bilgileri toplayan, birleştiren ve dağıtan önemli bir menkul kıymet bilgi işlemcisi olarak hizmet vermektedir. 18 aktif ABD Opsiyon borsası ve 1.5 milyondan fazla uygun sözleşmeyle OPRA, kapsamlı piyasa verileri sağlamada önemli bir rol oynamaktadır.
5 Şubat 2024'te Menkul Kıymetler Endüstrisi Otomasyon Şirketi (SIAC), OPRA feed'ini 48'den 96'ya çok noktaya yayın kanalına yükseltmeye hazırlanıyor. Bu geliştirme, ABD opsiyon piyasasında artan ticaret faaliyeti ve oynaklığa yanıt olarak sembol dağıtımını ve hat kapasitesi kullanımını optimize etmeyi amaçlıyor. SIAC, firmaların saniyede 37.3 GBit'e kadar en yüksek veri hızlarına hazırlanmalarını önerdi.
Yükseltme, yayınlanan verilerin toplam hacmini anında değiştirmese de OPRA'nın verileri çok daha hızlı bir şekilde yaymasını sağlıyor. Bu geçiş, dinamik opsiyon piyasasının taleplerini karşılamak açısından çok önemlidir.
OPRA, 150.4'ün üçüncü çeyreğinde tek günde 3 milyar mesaja ulaşarak zirveye ulaşarak ve tek bir günde 2023 milyar mesajlık kapasite boşluğu gereksinimiyle en hacimli yayınlardan biri olarak öne çıkıyor. Her bir mesajın yakalanması, işlem maliyeti analitiği, piyasa likiditesinin izlenmesi, ticaret stratejisi değerlendirmesi ve pazar araştırması için kritik öneme sahiptir.
Veriler hakkında
LSEG Kene Geçmişi – PCAP 30 PB'yi aşan, ultra yüksek kaliteli küresel pazar verilerini barındıran bulut tabanlı bir depodur. Bu veriler, dünya çapındaki büyük birincil ve yedek değişim veri merkezlerinde stratejik olarak konumlandırılmış yedekli yakalama süreçleri kullanılarak, doğrudan değişim veri merkezlerinde titizlikle yakalanır. LSEG'nin yakalama teknolojisi, kayıpsız veri yakalamayı sağlar ve nanosaniye zaman damgası hassasiyeti için bir GPS zaman kaynağı kullanır. Ek olarak, veri boşluklarını sorunsuz bir şekilde doldurmak için gelişmiş veri arbitraj teknikleri kullanılır. Yakalamanın ardından veriler titiz bir işleme ve tahkime tabi tutulur ve daha sonra kullanılarak Parke formatına normalleştirilir. LSEG'nin Gerçek Zamanlı Ultra Doğrudan özelliği (RTUD) besleme işleyicileri.
Verileri analize hazırlamanın ayrılmaz bir parçası olan normalleştirme süreci, günde 6 TB'a kadar sıkıştırılmış Parke dosyası oluşturur. Büyük miktarda veri, OPRA'nın kapsayıcı doğasına, birden fazla borsaya yayılmasına ve farklı niteliklerle karakterize edilen çok sayıda opsiyon sözleşmesi içermesine bağlanıyor. Opsiyon borsalarında artan piyasa oynaklığı ve piyasa yapıcılık faaliyeti, OPRA'da yayınlanan veri hacmine daha da katkıda bulunmaktadır.
Kene Geçmişi – PCAP'ın özellikleri, firmaların aşağıdakiler de dahil olmak üzere çeşitli analizler yürütmesine olanak tanır:
- İşlem öncesi analiz – Potansiyel ticaret etkisini değerlendirin ve geçmiş verilere dayalı farklı uygulama stratejilerini keşfedin
- İşlem sonrası değerlendirme – Yürütme stratejilerinin performansını değerlendirmek için karşılaştırmalı değerlendirmelere göre fiili yürütme maliyetlerini ölçün
- Optimize infaz – Piyasa etkisini en aza indirmek ve genel işlem maliyetlerini azaltmak için geçmiş piyasa modellerine dayalı uygulama stratejilerine ince ayar yapın
- Risk yönetimi – Kayma modellerini belirleyin, aykırı değerleri belirleyin ve ticari faaliyetlerle ilişkili riskleri proaktif olarak yönetin
- performans ilişkilendirme – Portföy performansını analiz ederken alım satım kararlarının etkisini yatırım kararlarından ayırın
LSEG Onay Geçmişi – PCAP veri seti şu adreste mevcuttur: AWS Veri Değişimi ve şu adresten erişilebilir: AWS Pazar Yeri. Ile Amazon S3 için AWS Veri DeğişimiPCAP verilerine doğrudan LSEG'lerden erişebilirsiniz. Amazon Basit Depolama Hizmeti (Amazon S3) paketlerini kullanarak firmaların kendi veri kopyalarını saklama ihtiyacını ortadan kaldırır. Bu yaklaşım, müşterilerin yüksek kaliteli PCAP'ye veya normalleştirilmiş verilere kullanım, entegrasyon ve kolaylık ile anında erişmesini sağlayarak veri yönetimini ve depolamayı kolaylaştırır. önemli miktarda veri depolama tasarrufu.
Apache Spark için Athena
Analitik çabalar için, Apache Spark için Athena Athena konsolu veya Athena API'leri aracılığıyla erişilebilen basitleştirilmiş bir dizüstü bilgisayar deneyimi sunarak etkileşimli Apache Spark uygulamaları oluşturmanıza olanak tanır. Optimize edilmiş Spark çalışma süresiyle Athena, Spark motorlarının sayısını bir saniyeden daha kısa sürede dinamik olarak ölçeklendirerek petabaytlarca verinin analizine yardımcı olur. Dahası, pandas ve NumPy gibi yaygın Python kitaplıkları sorunsuz bir şekilde entegre edilerek karmaşık uygulama mantığının oluşturulmasına olanak tanır. Esneklik, not defterlerinde kullanılmak üzere özel kitaplıkların içe aktarılmasına kadar uzanır. Athena for Spark, çoğu açık veri formatını barındırır ve AWS Tutkal Veri Kataloğu.
Veri kümesi
Bu analiz için 17 Mayıs 2023 tarihli LSEG Tick History – PCAP OPRA veri kümesini kullandık. Bu veri kümesi aşağıdaki bileşenlerden oluşur:
- En iyi teklif ve teklif (BBO) – Belirli bir borsadaki en yüksek teklifi ve en düşük menkul kıymet talebini raporlar
- Ulusal en iyi teklif ve teklif (NBBO) – Tüm borsalarda en yüksek teklifi ve en düşük menkul kıymet talebini raporlar
- İşlemler – Tüm borsalarda tamamlanan işlemleri kaydeder
Veri kümesi aşağıdaki veri hacimlerini içerir:
- İşlemler – Yaklaşık 160 sıkıştırılmış Parke dosyasına dağıtılan 60 MB
- BBO – Yaklaşık 2.4 sıkıştırılmış Parke dosyasına dağıtılan 300 TB
- NBBO – Yaklaşık 2.8 sıkıştırılmış Parke dosyasına dağıtılan 200 TB
Analize genel bakış
İşlem Maliyeti Analizi (TCA) için OPRA Onay Geçmişi verilerinin analiz edilmesi, belirli bir ticari olay etrafındaki piyasa fiyatlarının ve işlemlerin incelenmesini içerir. Bu çalışmanın bir parçası olarak aşağıdaki ölçümleri kullanıyoruz:
- Alıntılanan spread (QS) – BBO talebi ile BBO teklifi arasındaki fark olarak hesaplanır
- Etkili yayılma (ES) – İşlem fiyatı ile BBO'nun orta noktası arasındaki fark olarak hesaplanır (BBO teklifi + (BBO teklifi – BBO teklifi)/2)
- Efektif/kotalı spread (EQF) – (ES/QS)*100 olarak hesaplanır
Bu spreadleri işlemden önce ve ayrıca işlemden sonra dört aralıklarla (işlemden hemen sonra, 1 saniye, 10 saniye ve 60 saniye sonra) hesaplıyoruz.
Athena'yı Apache Spark için Yapılandırma
Athena'yı Apache Spark için yapılandırmak için aşağıdaki adımları tamamlayın:
- Athena konsolunda, altında BAŞLAYINseçin PySpark ve Spark SQL'i kullanarak verilerinizi analiz edin.
- Athena Spark'ı ilk kez kullanıyorsanız, Çalışma grubu oluştur.

- İçin Çalışma grubu adı¸ çalışma grubu için bir ad girin, örneğin
tca-analysis. - içinde Analiz motoru bölümünde, seçin Apache Spark.
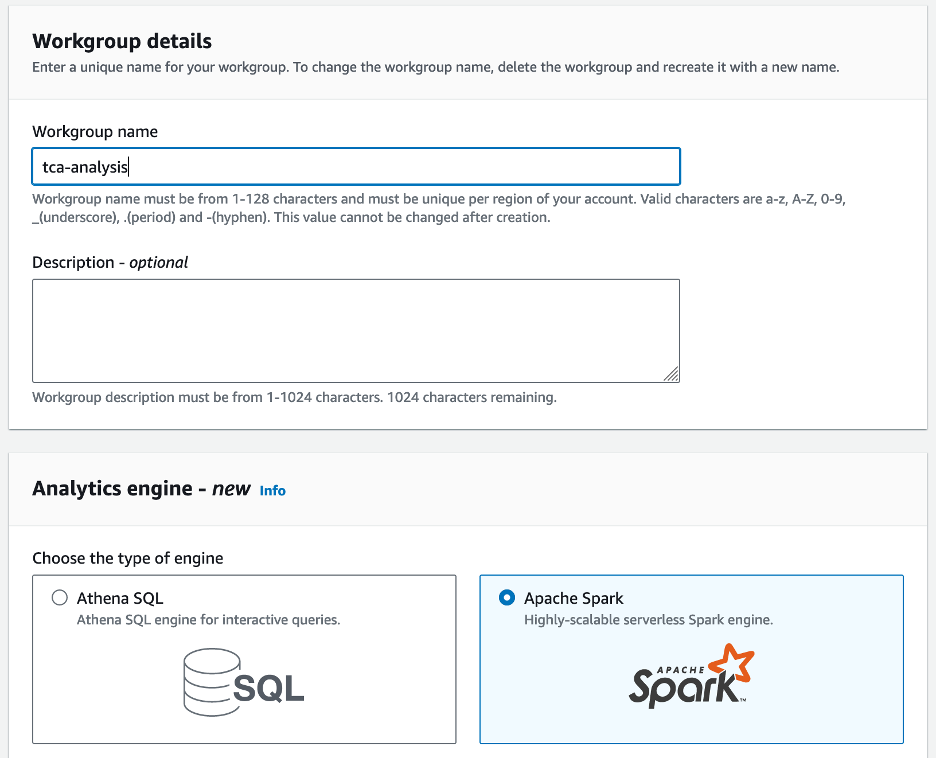
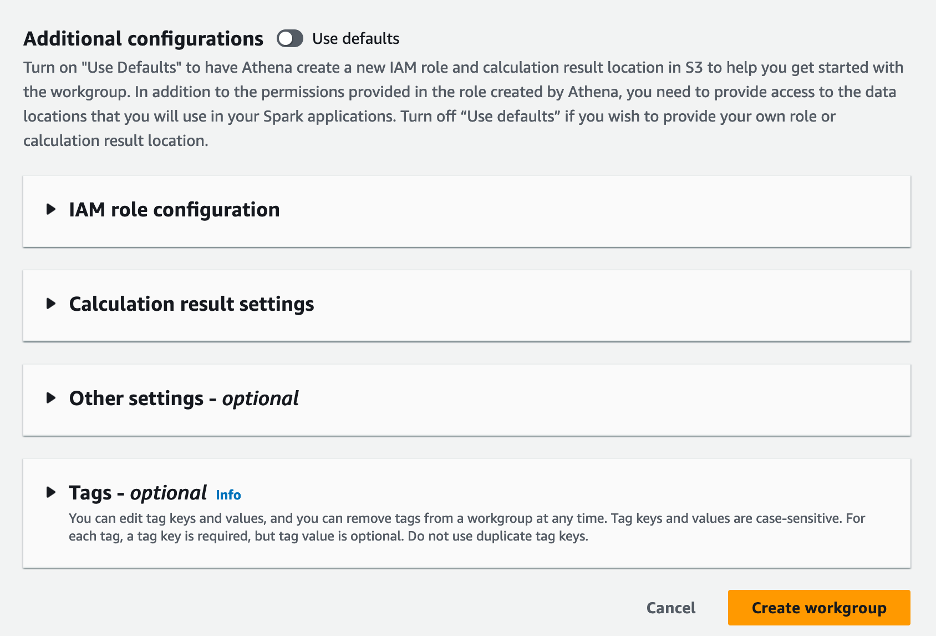
- içinde Ek yapılandırmalar bölümünden seçim yapabilirsiniz Varsayılanları kullan veya özel bir şey sağlayın AWS Kimlik ve Erişim Yönetimi Hesaplama sonuçları için (IAM) rolü ve Amazon S3 konumu.
- Klinik Çalışma grubu oluştur.
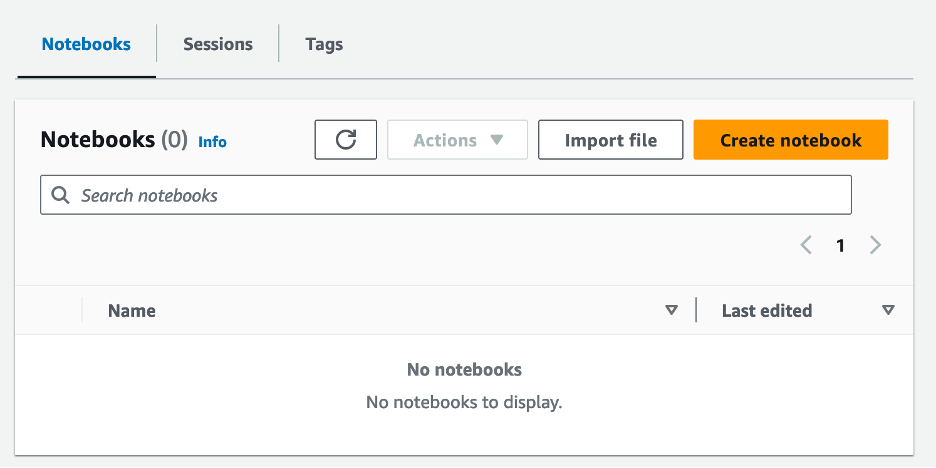
- Çalışma grubunu oluşturduktan sonra şuraya gidin: Defterler sekme ve seçim Defter oluştur.
- Not defteriniz için bir ad girin; örneğin
tca-analysis-with-tick-history. - Klinik oluşturmak Not defterinizi oluşturmak için.
Dizüstü bilgisayarınızı başlatın
Zaten bir Spark çalışma grubu oluşturduysanız Not defteri düzenleyicisini başlat altında BAŞLAYIN.
![]()
Not defteriniz oluşturulduktan sonra etkileşimli not defteri düzenleyicisine yönlendirileceksiniz.
![]()
Artık aşağıdaki kodu not defterimize ekleyip çalıştırabiliriz.
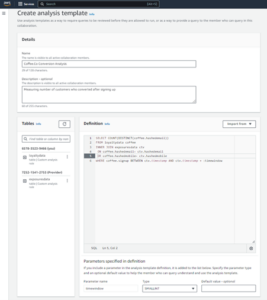
Bir analiz oluşturun
Bir analiz oluşturmak için aşağıdaki adımları tamamlayın:
- Ortak kitaplıkları içe aktarın:
- BBO, NBBO ve işlemler için veri çerçevelerimizi oluşturun:
- Artık işlem maliyeti analizi için kullanılacak bir işlemi tanımlayabiliriz:
Aşağıdaki çıktıyı alıyoruz:
Ticari ürün (tp), ticari fiyat (tpr) ve ticaret süresi (tt) için öne çıkan ticari bilgileri ileriye dönük olarak kullanırız.
- Burada analizimiz için bir dizi yardımcı fonksiyon oluşturuyoruz
- Aşağıdaki fonksiyonda işlem öncesi ve sonrası tüm kotasyonları içeren veri setini oluşturuyoruz. Athena Spark, veri kümemizi işlemek için kaç DPU'nun başlatılacağını otomatik olarak belirler.
- Şimdi seçtiğimiz ticaretteki bilgilerle TCA analiz fonksiyonunu çağıralım:
Analiz sonuçlarını görselleştirin
Şimdi görselleştirmemiz için kullandığımız veri çerçevelerini oluşturalım. Her veri çerçevesi, her veri beslemesi (BBO, NBBO) için beş zaman aralığından biri için alıntılar içerir:
Aşağıdaki bölümlerde farklı görselleştirmeler oluşturmak için örnek kod sağlıyoruz.
Ticaretten önce QS ve NBBO'yu planlayın
İşlem öncesinde kote edilen spreadi ve NBBO'yu çizmek için aşağıdaki kodu kullanın:
![]()
Her pazar için QS grafiğini ve işlemden sonra NBBO'yu çizin
Her bir piyasa ve NBBO için kote edilen spreadi işlemin hemen ardından çizmek için aşağıdaki kodu kullanın:
![]()
BBO için her zaman aralığı ve her pazar için QS grafiğini çizin
BBO için her zaman aralığı ve her pazar için teklif edilen spreadi çizmek üzere aşağıdaki kodu kullanın:
![]()
BBO için her zaman aralığı ve pazar için ES grafiği
BBO için her zaman aralığı ve pazar için etkili yayılmayı çizmek üzere aşağıdaki kodu kullanın:
BBO için her zaman aralığı ve pazar için EQF grafiğini çizin
BBO için her zaman aralığı ve pazar için etkin/kotalı spreadi çizmek için aşağıdaki kodu kullanın:
Athena Spark hesaplama performansı
Bir kod bloğunu çalıştırdığınızda Athena Spark, hesaplamayı tamamlamak için kaç DPU'ya ihtiyaç duyulduğunu otomatik olarak belirler. Son kod bloğunda dediğimiz yer tca_analysis işlevinde aslında Spark'a verileri işlemesi talimatını veriyoruz ve ardından ortaya çıkan Spark veri çerçevelerini Pandas veri çerçevelerine dönüştürüyoruz. Bu, analizin en yoğun işlem kısmını oluşturur ve Athena Spark bu bloğu çalıştırdığında ilerleme çubuğunu, geçen süreyi ve o anda kaç DPU'nun veri işlediğini gösterir. Örneğin aşağıdaki hesaplamada Athena Spark 18 DPU kullanıyor.
![]()
Athena Spark dizüstü bilgisayarınızı yapılandırdığınızda kullanabileceği maksimum DPU sayısını ayarlama seçeneğiniz vardır. Varsayılan değer 20 DPU'dur ancak Athena Spark'ın analizimizi yürütmek için nasıl otomatik olarak ölçeklendiğini göstermek için bu hesaplamayı 10, 20 ve 40 DPU ile test ettik. Athena Spark'ın doğrusal olarak ölçeklendiğini, dizüstü bilgisayar maksimum 15 DPU ile yapılandırıldığında 21 dakika 10 saniye, dizüstü bilgisayar 8 DPU ile yapılandırıldığında 23 dakika 20 saniye ve dizüstü bilgisayar maksimum 4 DPU ile yapılandırıldığında 44 dakika 40 saniye sürdüğünü gözlemledik. XNUMX DPU ile yapılandırılmıştır. Athena Spark, DPU kullanımına dayalı olarak saniye başına ayrıntı düzeyinde ücret aldığından, bu hesaplamaların maliyeti benzerdir ancak daha yüksek bir maksimum DPU değeri ayarlarsanız Athena Spark, analiz sonucunu çok daha hızlı döndürebilir. Athena Spark fiyatlandırması hakkında daha fazla bilgi için lütfen tıklayın okuyun.
Sonuç
Bu yazıda, Athena Spark'ı kullanarak işlem maliyeti analitiğini gerçekleştirmek için LSEG'nin Tick History-PCAP'ındaki yüksek kaliteli OPRA verilerini nasıl kullanabileceğinizi gösterdik. OPRA verilerinin zamanında kullanılabilirliği, AWS Data Exchange for Amazon S3'ün erişilebilirlik yenilikleriyle tamamlandığında, kritik ticaret kararları için eyleme dönüştürülebilir öngörüler oluşturmak isteyen firmaların analiz süresini stratejik olarak azaltır. OPRA her gün yaklaşık 7 TB normalleştirilmiş Parquet verisi üretiyor ve OPRA verilerine dayalı analizler sağlayacak altyapıyı yönetmek zorlu bir iş.
Athena'nın Tick History – OPRA verileri için PCAP için büyük ölçekli veri işlemeyi yönetmedeki ölçeklenebilirliği, onu AWS'de hızlı ve ölçeklenebilir analiz çözümleri arayan kuruluşlar için cazip bir seçim haline getiriyor. Bu gönderi, AWS ekosistemi ile Tick History-PCAP verileri arasındaki kusursuz etkileşimi ve finansal kurumların, kritik ticaret ve yatırım stratejileri için veriye dayalı karar almayı desteklemek amacıyla bu sinerjiden nasıl yararlanabileceğini gösteriyor.
Yazarlar Hakkında
![]() Pramod Nayak LSEG'de Düşük Gecikme Grubunun Ürün Yönetimi Direktörüdür. Pramod'un finansal teknoloji endüstrisinde yazılım geliştirme, analitik ve veri yönetimine odaklanan 10 yılı aşkın deneyimi vardır. Pramod eski bir yazılım mühendisidir ve piyasa verileri ve niceliksel ticaret konusunda tutkuludur.
Pramod Nayak LSEG'de Düşük Gecikme Grubunun Ürün Yönetimi Direktörüdür. Pramod'un finansal teknoloji endüstrisinde yazılım geliştirme, analitik ve veri yönetimine odaklanan 10 yılı aşkın deneyimi vardır. Pramod eski bir yazılım mühendisidir ve piyasa verileri ve niceliksel ticaret konusunda tutkuludur.
![]() LakshmiKanth Mannem LSEG'in Düşük Gecikme Grubunda Ürün Yöneticisidir. Düşük gecikmeli piyasa veri endüstrisi için veri ve platform ürünlerine odaklanmaktadır. LakshmiKanth, müşterilerin pazar verisi ihtiyaçları için en uygun çözümleri oluşturmalarına yardımcı oluyor.
LakshmiKanth Mannem LSEG'in Düşük Gecikme Grubunda Ürün Yöneticisidir. Düşük gecikmeli piyasa veri endüstrisi için veri ve platform ürünlerine odaklanmaktadır. LakshmiKanth, müşterilerin pazar verisi ihtiyaçları için en uygun çözümleri oluşturmalarına yardımcı oluyor.
![]() Vivek Aggarwal LSEG'in Düşük Gecikme Grubunda Kıdemli Veri Mühendisidir. Vivek, yakalanan piyasa veri akışlarının ve referans veri akışlarının işlenmesi ve sunulması için veri hatları geliştirmek ve sürdürmek üzerinde çalışıyor.
Vivek Aggarwal LSEG'in Düşük Gecikme Grubunda Kıdemli Veri Mühendisidir. Vivek, yakalanan piyasa veri akışlarının ve referans veri akışlarının işlenmesi ve sunulması için veri hatları geliştirmek ve sürdürmek üzerinde çalışıyor.
![]() Alket Memuşaj AWS'de Finansal Hizmetler Piyasası Geliştirme ekibinde Baş Mimardır. Alket, en zorlu sermaye piyasası iş yüklerini bile AWS Cloud'a dağıtmak için iş ortakları ve müşterilerle birlikte çalışan teknik stratejiden sorumludur.
Alket Memuşaj AWS'de Finansal Hizmetler Piyasası Geliştirme ekibinde Baş Mimardır. Alket, en zorlu sermaye piyasası iş yüklerini bile AWS Cloud'a dağıtmak için iş ortakları ve müşterilerle birlikte çalışan teknik stratejiden sorumludur.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :vardır
- :dır-dir
- :olumsuzluk
- :Neresi
- $UP
- 1
- 10
- 100
- 12
- %15
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- Hakkımızda
- erişim
- erişilen
- ulaşabilme
- ulaşılabilir
- karşısında
- aktif
- etkinlik
- gerçek
- aslında
- eklemek
- Ayrıca
- adresleme
- avantaj
- Sonra
- karşı
- Aggarwal
- Amaçları
- Türkiye
- Izin
- zaten
- Amazon
- Amazon Atina
- Amazon Web Servisleri
- an
- analizleri
- analiz
- Analitik
- analytics
- çözümlemek
- analiz
- ve
- herhangi
- Apache
- Apache Spark
- API'ler
- Uygulama
- uygulamaları
- Tamam
- yaklaşım
- yaklaşık olarak
- arbitraj
- tahkim
- ARE
- etrafında
- AS
- sormak
- belirlemek
- ilişkili
- At
- öznitelikleri
- yetki
- otomatik olarak
- Otomasyon
- kullanılabilirliği
- mevcut
- AWS
- yedek
- bar
- merkezli
- BE
- Çünkü
- önce
- kriterler
- İYİ
- arasında
- teklif
- Milyar
- Engellemek
- broker
- inşa etmek
- fakat
- by
- hesaplamak
- hesaplanmış
- hesaplama
- çağrı
- CAN
- Kapasite
- Başkent
- Sermaye piyasaları
- ele geçirmek
- Yakalanan
- Yakalama
- katalog
- Merkezleri
- zor
- kanallar
- özelliği
- yükler
- seçim
- Klinik
- istemciler
- bulut
- kod
- Toplama
- ortak
- zorlayıcı
- tamamlamak
- Tamamlandı
- bileşenler
- kapsamlı
- aşağıdakileri içerir:
- Davranış
- yapılandırılmış
- yapılandırarak
- konsolos
- birleştirerek
- içeren
- sözleşmeleri
- katkıda bulunmak
- dönüştürmek
- KURUMSAL
- Ücret
- maliyetler
- birlikte yazılmış
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- oluşturma
- kritik
- çok önemli
- Şu anda
- görenek
- Müşteriler
- Dash
- veri
- veri merkezleri
- veri mühendisi
- Veri değişimi
- veri yönetimi
- veri işleme
- veri saklama
- veri-güdümlü
- veri kümeleri
- gün
- Karar verme
- kararlar
- Varsayılan
- tanımlamak
- teslim
- talep
- talepleri
- göstermek
- gösterdi
- dağıtmak
- ayrıntılar
- belirleyen
- gelişen
- gelişme
- Geliştirme Takımı
- fark
- farklı
- direkt olarak
- yönetmen
- dağıtıldı
- dağıtım
- çeşitli
- çift
- sürücü
- dinamik
- dinamik
- dinamik
- her
- kolaylaştırmak
- kullanım kolaylığı
- ekosistem
- editör
- Etkili
- etki
- uygun
- ortadan
- istihdam
- kullanılarak
- etkinleştirmek
- sağlar
- kapsayan
- çabaları
- Motor
- mühendis
- Motorlar
- artış
- olmasını sağlar
- Keşfet
- tırmanan
- Eter (ETH)
- değerlendirmek
- değerlendirme
- Hatta
- Etkinlikler
- Her
- örnek
- takas
- Değişimleri
- infaz
- deneyim
- keşfetmek
- ekspres
- uzanır
- Daha hızlı
- Featuring
- Şubat
- Incir
- dosyalar
- doldurmak
- filtre
- mali
- Finansal Kurumlar
- finansal hizmetler
- finansal teknoloji
- firmalar
- Ad
- ilk kez
- beş
- Esneklik
- odaklanır
- odaklanma
- takip etme
- İçin
- biçim
- Eski
- ileri
- dört
- ÇERÇEVE
- itibaren
- işlev
- fonksiyonlar
- daha fazla
- boşluklar
- üretir
- almak
- verilmiş
- Küresel
- küresel market
- Go
- gidiş
- gps
- grup
- kullanma
- Var
- sahip olan
- he
- kafa boşluğu
- yardımcı olur
- Yüksek kaliteli
- daha yüksek
- en yüksek
- Vurgulanan
- tarihsel
- tarih
- konut
- Ne kadar
- Nasıl Yapılır
- http
- HTTPS
- IAM
- belirlemek
- Kimlik
- if
- Acil
- hemen
- darbe
- ithalat
- in
- Dahil olmak üzere
- artmış
- sanayi
- bilgi
- Altyapı
- yenilikler
- anlayışlar
- kurumları
- integral
- entegre
- bütünleşme
- etkileşim
- interaktif
- içine
- karmaşık
- yatırım
- içerir
- IT
- jpg
- sadece
- büyük
- büyük ölçekli
- Soyad
- Gecikme
- başlatmak
- az
- kütüphaneler
- çizgi
- Likidite
- yer
- mantık
- bakıyor
- Düşük
- en düşük
- sürdürmek
- büyük
- YAPAR
- Yapımı
- yönetmek
- yönetim
- müdür
- Yöneticileri
- yönetme
- tavır
- çok
- pazar
- Piyasa verileri
- pazar etkisi
- Pazar araştırması
- Piyasa oynaklığı
- Pazar yapımı
- Piyasalar
- masif
- Mastering
- maksimum
- Mayıs..
- ölçmek
- mesaj
- mesajları
- titiz
- titizlikle
- Metrikleri
- milyon
- azaltmak
- dakika
- izleme
- Daha
- Dahası
- çoğu
- çok
- çoklu
- isim
- Tabiat
- Gezin
- gerek
- ihtiyaçlar
- Hayır
- defter
- dizüstü bilgisayarlar
- numara
- sayısız
- dizi
- gözlenen
- of
- teklif
- Teklifler
- on
- ONE
- optimum
- optimize
- optimize
- seçenek
- Opsiyonlar
- or
- organizasyonlar
- bizim
- dışarı
- çıktı
- tekrar
- tüm
- kendi
- pandalar
- Bölüm
- ortaklar
- tutkulu
- desen
- zirve
- başına
- yapmak
- performans
- asıl
- platform
- Platon
- Plato Veri Zekası
- PlatoVeri
- çalış
- Lütfen
- arsa
- portföy
- portföy yöneticileri
- yerleştirilmiş
- Çivi
- Post-ticaret
- potansiyel
- Hassas
- Hazırlamak
- hazırlanması
- fiyat
- fiyatlandırma
- birincil
- Anapara
- süreç
- Süreçler
- işleme
- İşlemci
- PLATFORM
- ürün Yönetimi
- ürün müdürü
- Ürünler
- Ilerleme
- sağlamak
- sağlama
- yayınlanan
- Python
- Q3
- nicel
- miktar
- sorgu
- tırnak işareti
- oran
- oranlar
- Okumak
- gerçek
- gerçek zaman
- Tavsiye edilen
- kayıtlar
- Kırmızı
- azaltmak
- azaltır
- referans
- refinitiv
- Raporlama
- Raporlar
- Depo
- gereklilik
- gerektirir
- araştırma
- yanıt
- sorumlu
- sonuç
- Ortaya çıkan
- Sonuçlar
- dönüş
- riskler
- Rol
- koşmak
- ishal
- satış
- ölçeklenebilirlik
- ölçeklenebilir
- terazi
- ölçekleme
- sorunsuz
- sorunsuz
- İkinci
- saniye
- Bölüm
- bölümler
- Senetler
- güvenlik
- arayan
- seçmek
- seçilmiş
- kıdemli
- ayrı
- vermektedir
- Hizmetler
- set
- ayar
- şov
- Gösteriler
- önemli ölçüde
- benzer
- Basit
- basitleştirilmiş
- tek
- kayma
- Yazılım
- yazılım geliştirme
- Yazılım Mühendisi
- Çözümler
- sofistike
- gerginlik
- Kıvılcım
- özel
- yayılma
- Spreadler
- standları
- Basamaklar
- hafızası
- mağaza
- Stratejik olarak
- stratejileri
- Stratejileri
- akıntı yolları
- Ders çalışma
- sonraki
- böyle
- SWIFT
- sembol
- sinerji
- Bizi daha iyi tanımak için
- alma
- takım
- Teknik
- teknikleri
- Teknoloji
- test edilmiş
- göre
- o
- The
- Bilgi
- ve bazı Asya
- Onları
- sonra
- Bunlar
- Re-Tweet
- İçinden
- kene
- zaman
- vakitli
- zaman damgası
- Başlık
- için
- Toplam
- tp
- TPR
- Ticaret
- Tüccarlar
- esnaf
- Trading
- Ticaret Stratejileri
- ticaret stratejisi
- işlem
- işlem maliyetleri
- dönüşüm
- geçiş
- Ultra
- altında
- uğrar
- yükseltmek
- us
- kullanım
- kullanım
- Kullanılmış
- kullanım
- kullanma
- Kullanılması
- değer
- çeşitli
- görüntüleme
- görselleştirmek
- Uçuculuk
- hacim
- hacimleri
- oldu
- we
- ağ
- web hizmetleri
- ne zaman
- hangi
- geniş ölçüde
- irade
- ile
- içinde
- olmadan
- Çalışma grubu
- çalışma
- çalışır
- Dünya çapında
- endişe
- X
- yıl
- sen
- zefirnet