Giriş
birleşmesi yapay zeka (AI) ve sanat, yaratıcı dijital sanatta, özellikle yayılma modelleri aracılığıyla yeni yollar ortaya çıkarıyor. Bu modeller, geleneksel sinir ağlarından farklı bir yaklaşım sunarak yaratıcı yapay zeka sanat neslinde öne çıkıyor. Bu makale sizi difüzyon modellerinin derinliklerine doğru keşfedici bir yolculuğa çıkarıyor ve bu modellerin görsel olarak büyüleyici ve yaratıcı açıdan zengin sanat eserleri yaratmadaki benzersiz mekanizmalarını açıklıyor. Yayılma modellerinin nüanslarını anlayın ve gelişmiş yapay zeka teknolojileri merceğinden sanatsal ifadenin yeniden tanımlanmasındaki rollerine ilişkin fikir edinin.

Öğrenme hedefleri
- Yapay zekadaki yayılma modellerinin temel kavramlarını anlayın.
- Sanat üretiminde yayılma modelleri ile geleneksel sinir ağları arasındaki farkı keşfedin.
- Yayılma modellerini kullanarak sanat yaratma sürecini analiz edin.
- Yapay zekanın dijital sanattaki yaratıcı ve estetik etkilerini değerlendirin.
- Yapay zeka tarafından oluşturulan sanat eserlerinde etik hususları tartışın.
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Difüzyon Modellerini Anlamak

Difüzyon modelleri, Üretken Rekabet Ağları (GAN'lar) gibi geleneksel tekniklerden farklı, benzersiz bir görüntü oluşturma yöntemi sunarak üretken yapay zekada devrim yaratıyor. Rastgele gürültüyle başlayan bu modeller, bir sanatçının bir tabloya ince ayar yapmasına benzer şekilde onu aşamalı olarak iyileştirir ve sonuçta karmaşık ve tutarlı görüntüler elde edilir.
Bu artan iyileştirme süreci, difüzyonun yöntemsel doğasını yansıtır. Burada her yineleme, gürültüyü ustalıkla değiştirerek nihai sanatsal vizyona yaklaştırıyor. Çıktı yalnızca rastlantısallığın bir ürünü değil, ilerlemesi ve bitişi bakımından farklı, gelişmiş bir sanat eseridir.
Difüzyon modellerinin kodlanması, sinir ağlarının ve TensorFlow veya PyTorch gibi makine öğrenimi çerçevelerinin derinlemesine anlaşılmasını gerektirir. Ortaya çıkan kod karmaşıktır ve yapay zeka tarafından oluşturulan sanatta gözlemlenen incelikli etkileri elde etmek için geniş veri kümeleri üzerinde kapsamlı eğitim gerektirir.
Sanatta Kararlı Difüzyonun Uygulanması
Kararlı yayılma modelleri gibi yapay zeka sanat oluşturucularının ortaya çıkışı, TensorFlow veya PyTorch gibi platformlarda karmaşık kodlama gerektirir. Bu modeller, tıpkı bir ön taslağı canlı bir başyapıta dönüştüren bir sanatçı gibi, rastgeleliği yöntemli bir şekilde yapıya dönüştürme yetenekleriyle öne çıkıyor.
Kararlı yayılma modelleri, GAN'ların rekabetçi dinamik özelliğinden kaçınarak, rastgele görüntülerden düzenli görüntüler oluşturarak yapay zeka sanat ortamını yeniden şekillendirir. Kavramsal ipuçlarını görsel sanata dönüştürmede başarılı oluyorlar ve yapay zeka yetenekleri ile insan yaratıcılığı arasında sinerjik bir dans geliştiriyorlar. PyTorch'u kullanarak, bu modellerin kaosu nasıl yinelemeli olarak netliğe dönüştürdüğünü, sanatçının yeni ortaya çıkan bir fikirden gösterişli bir yaratıma doğru yolculuğunu yansıttığını gözlemliyoruz.
Yapay Zeka Tarafından Üretilen Sanatla Denemeler Yapmak
Bu gösteri, yapay zeka tarafından üretilen sanatın büyüleyici dünyasını, evrişimli bir sinir ağı kullanılarak inceliyor. DönüşümDiffüzyonModeli. Bu model, çizimleri, tabloları, heykelleri ve gravürleri kapsayan çeşitli sanat görselleri üzerine eğitilmiştir. bu Kaggle veri kümesi. Amacımız, modelin bu sanat eserlerinin karmaşık estetiğini yakalama ve yeniden üretme yeteneğini keşfetmektir.
Model Mimarisi ve Eğitimi
Mimari tasarım
ConvDiffusionModel, özünde, sanat üretiminin taleplerine göre tasarlanmış gelişmiş bir kodlayıcı-kod çözücü mimarisine sahip bir sinir mühendisliği harikasıdır. Modelin yapısı, özellikle sanat üretimi için geliştirilmiş, geliştirilmiş kodlayıcı-kod çözücü mekanizmalarını entegre eden karmaşık bir sinir ağıdır. Model, sanatsal sezgiyi taklit eden ek kıvrımlı katmanlar ve atlama bağlantılarıyla, kompozisyon ve stile dair ustaca bir anlayışla sanatı parçalara ayırıp yeniden bir araya getirebilir.
- Encoder: Kodlayıcı, her giriş görüntüsünün en küçük ayrıntılarını inceleyen modelin analitik gözüdür. Görüntüler kodlayıcının evrişimli katmanlarından geçerken, aşamalı olarak gizli bir alana sıkıştırılır; bu, orijinal sanat eserinin kompakt, kodlanmış bir temsilidir. Kodlayıcımız yalnızca girdi görüntülerini incelemekle kalmıyor, artık bunu artırılmış bir algı derinliği, ek katmanlar ve toplu normalleştirme teknikleri sayesinde yapıyor. Bu genişletilmiş inceleme, bir sanatçının bir konu hakkındaki derin düşüncelerini yansıtarak, gizli alanda daha zengin, yoğunlaştırılmış bir temsile olanak tanır.
- dekoder: Buna karşılık kod çözücü, modelin yaratıcı eli olarak hizmet eder; kodlayıcıdan soyut çizimleri alır ve onlara hayat verir. Tam bir görüntü ortaya çıkana kadar sanat eserini gizli alandan, katman katman, ayrıntı ayrıntı yeniden yapılandırır. Kod çözücümüz atlama bağlantılarından yararlanır ve resmi daha yüksek hassasiyetle yeniden oluşturabilir. Girdinin soyutlanmış özünü yeniden gözden geçirir ve onu giderek süsleyerek kaynak malzemeye daha sadık bir sunum elde eder. Geliştirilmiş katmanlar, son görüntünün, girdinin sanatını yansıtan canlı, karmaşık bir parça olmasını sağlamak için uyum içinde çalışır.
Eğitim süreci
ConvDiffusionModel'in eğitimi, 150 dönemi kapsayan sanatsal bir manzara boyunca yapılan bir yolculuktur. Her dönem, tüm veri kümesi boyunca tam bir geçişi temsil eder; model, anlayışını iyileştirmeye ve oluşturulan görüntülerin aslına uygunluğunu iyileştirmeye çalışır.
- Hibrit Kayıp Fonksiyonu: Eğitimin merkezinde ortalama hata karesi (MSE) kayıp fonksiyonu yatmaktadır. Bu işlev, orijinal şaheser ile modelin yeniden yaratımı arasındaki farkı ölçerek en aza indirilecek net bir ölçüm sağlar. Ortalama karesel hata (MSE) metriğini tamamlayan, önceden eğitilmiş bir VGG ağından türetilen bir algısal kayıp bileşenini tanıtacağız. Bu ikili kayıp stratejisi, modeli orijinallerin sanatsal bütünlüğünü onurlandırırken, ayrıntılarının teknik olarak çoğaltılmasını mükemmelleştirmeye teşvik ediyor.
- Optimize Edici: Bir zamanlayıcı tarafından dinamik olarak ayarlanan öğrenme oranıyla Adam optimizer, modelin öğrenmesini artan bir bilgelikle yönlendirir. Bu uyarlanabilir yaklaşım, modelin sanatı kopyalamayı ve yenilemeyi öğrenmedeki ilerlemesinin hem istikrarlı hem de sağlam olmasını sağlar.
- Yineleme ve İyileştirme: Eğitim yinelemeleri, sanatsal özün korunması ile teknik kopyanın sürdürülmesi arasında bir danstır. Her döngüde model, sadakat ve yaratıcılığın sentezine daha da yaklaşıyor.
- İlerlemenin Görselleştirilmesi: Modelin ilerlemesini görselleştirmek için eğitim sırasında görüntüler düzenli aralıklarla kaydedilir.. Bu anlık görüntüler, modelin öğrenme eğrisine bir pencere açarak, üretilen sanatın nasıl geliştiğini, her çağda daha net, daha ayrıntılı ve sanatsal açıdan daha tutarlı hale geldiğini gösteriyor.



Yukarıdakiler aşağıdaki kod parçasıyla gösterilmiştir:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')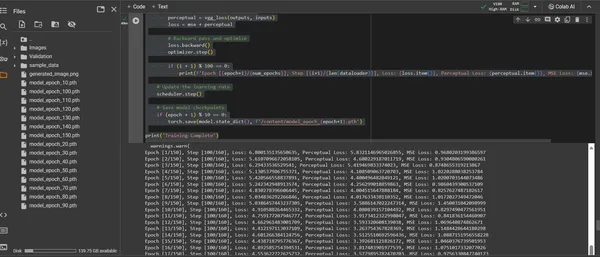
Oluşturulan Resmin Görselleştirilmesi
Yapay Zeka ile Üretilen Sanatı Ortaya Çıkarmak
ConvDiffusionModel'in artık tamamen eğitilmesiyle odak noktası soyuttan somuta, potansiyelden yapay zeka tarafından hazırlanmış sanatın gerçekleştirilmesine doğru kayıyor. Sonraki kod parçacığı, modelin öğrenilmiş sanatsal yeteneklerini hayata geçirerek girdi verilerini dijital bir ifade tuvaline dönüştürüyor.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()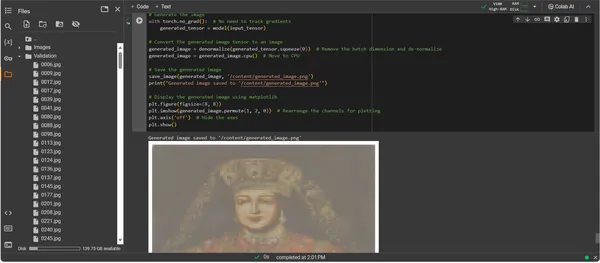

Sanat Eseri Oluşturma Kodunun Çözüm Yolu
- Diriliş Modeli: Sanat eseri oluşturmanın ilk adımı, eğitimli ConvDiffusionModel'imizi yeniden canlandırmaktır. Modelin öğrenilen ağırlıkları yüklenir ve değerlendirme moduna getirilir, böylece parametreleri daha fazla değiştirilmeden oluşturma aşaması hazırlanır.
- Görüntü Dönüşümü: Eğitim rejimiyle tutarlılığı sağlamak için giriş görüntüleri aynı dönüşüm dizisiyle işlenir. Bu, modelin giriş boyutlarına uyacak şekilde yeniden boyutlandırmayı, PyTorch uyumluluğu için tensör dönüştürmeyi ve eğitim verilerinin istatistiksel profiline dayalı normalleştirmeyi içerir.
- Denormalizasyon Yardımcı Programı: Özel bir işlev, tensörü orijinal görüntünün renk aralığına göre yeniden ölçeklendirerek ön işleme efektlerini tersine çevirir. Bu adım, oluşturulan çıktının görsel olarak doğru bir temsile dönüştürülmesi için gereklidir.
- Giriş Hazırlama: Bir görüntü yüklenir ve yukarıda belirtilen dönüşümlere tabi tutulur. Bu görüntünün, yapay zekanın ilham alacağı ilham perisi görevi gördüğünü belirtmek çok önemlidir; sessiz fısıltı, modelin sentetik hayal gücünü ateşler.
- Sanat Eseri Sentezi: Model, ileri doğru yayılmanın hassas bir dansıyla girdi tensörünü yorumlayarak katmanlarının yeni bir sanatsal vizyon üretmek için işbirliği yapmasına olanak tanır. Artık eğitim değil uygulama alanında olduğumuz için bu işlemi gradyanları izlemeden gerçekleştirin.
- Görüntü Dönüşümü: Modelin artık dijital olarak doğmuş sanat eserlerini barındıran tensör çıktısı normallikten arındırılarak modelin yaratımını gözlerimizin takdir edebileceği tanıdık renk ve ışık alanına geri dönüştürüyor.
- Sanat Eserinin Vahiy: Dönüştürülen tensör dijital bir tuval üzerine yerleştirilerek kayıtlı bir görüntü dosyası elde edilir. Bu dosya, yapay zekanın yaratıcı ruhuna açılan bir pencere, ona hayat veren dinamik sürecin statik bir yankısıdır.
- Sanat Eseri Alma: Komut dosyası, oluşturulan görüntünün belirlenmiş bir yola kaydedilmesi ve tamamlandığının duyurulması ile sona erer. Öğrenilmiş sanatsal ilkelerin ve ortaya çıkan yaratıcılığın bir sentezi olan kaydedilen görüntü, sergilenmeye ve üzerinde düşünülmeye hazırdır.
Çıktıyı Analiz Etme
ConvDiffusionModel'in çıktısı, tarihi sanata açık bir gönderme yapan bir figür sunuyor. Ayrıntılı kıyafetlerle giydirilen yapay zekayla oluşturulan görüntü, klasik portrelerin ihtişamını yine de farklı, modern bir dokunuşla yansıtıyor. Deneğin kıyafeti, modelin öğrenilmiş kalıplarını yeni bir yorumla harmanlayarak doku bakımından zengindir. Hassas yüz özellikleri ve hafif ışık ve gölge etkileşimi, yapay zekanın geleneksel sanat tekniklerine ilişkin incelikli anlayışını sergiliyor. Bu sanat eseri, modelin gelişmiş eğitiminin bir kanıtıdır ve gelişmiş makine öğrenimi prizması aracılığıyla tarihsel sanatın zarif bir sentezini yansıtır. Özünde, günümüzün algoritmalarıyla hazırlanmış, geçmişe dijital bir saygı duruşudur.
Zorluklar ve Etik Hususlar
Sanat üretimi için yayılma modellerini uygulamak, dikkate almanız gereken çeşitli zorlukları ve etik hususları beraberinde getirir:
- Veri Kaynağı: Eğitim veri kümeleri sorumlu bir şekilde düzenlenmelidir. Yayılım modellerini eğitmek için kullanılan verilerin, uygun yetkilendirme olmadan telif hakkıyla korunan veya korunan çalışmalar içermediğinin doğrulanması çok önemlidir.
- Önyargı ve Temsil: Yapay zeka modelleri, eğitim verilerindeki önyargıları sürdürebilir. Yapay zeka tarafından üretilen sanatta stereotiplerin güçlendirilmesini önlemek için çeşitli ve kapsayıcı veri kümelerinin sağlanması önemlidir.
- Çıkış Üzerinden Kontrol: Yayılma modelleri çok çeşitli çıktılar üretebildiğinden, uygunsuz veya rahatsız edici içeriğin oluşturulmasını engelleyecek sınırlar koymak gereklidir.
- Yasal çerçeve: Yapay zekanın yaratıcı süreçteki nüanslarını ele alacak sağlam bir yasal çerçevenin bulunmaması bir zorluk teşkil ediyor. Mevzuatın ilgili tüm tarafların haklarını koruyacak şekilde gelişmesi gerekiyor.
Sonuç
Yapay zeka ve sanatta yayılma modellerinin yükselişi, hesaplama hassasiyetini estetik keşifle birleştiren dönüştürücü bir döneme işaret ediyor. Sanat dünyasındaki yolculukları önemli inovasyon potansiyelini vurguluyor ancak karmaşıklıkları da beraberinde getiriyor. Özgünlük, etki, etik yaratım ve mevcut çalışmalara saygıyı dengelemek sanatsal sürecin ayrılmaz bir parçasıdır.
Önemli Noktalar
- Yayılma modelleri, sanat yaratımındaki dönüştürücü değişimin ön saflarında yer alıyor. Sanatsal ifadenin tuvalini geleneksel sınırların ötesine genişleten yeni dijital araçlar sunuyorlar.
- Yapay zeka ile geliştirilmiş sanatta, eğitim verilerinin etik olarak toplanmasına öncelik vermek ve yaratıcıların fikri mülkiyetine saygı duymak, dijital sanatta bütünlüğü korumak açısından zorunludur.
- Sanatsal vizyon ile teknolojik yeniliğin yakınsaması, sanatçılar ve yapay zeka geliştiricileri arasında simbiyotik bir ilişkinin kapılarını açıyor. Çığır açan sanata yol açabilecek işbirlikçi bir ortamı teşvik edin.
- Yapay zeka tarafından üretilen sanatın geniş bir perspektif yelpazesini temsil etmesini sağlamak hayati önem taşıyor. Farklı kültürlerin ve bakış açılarının zenginliğini yansıtan çeşitli verileri bir araya getirerek kapsayıcılığı teşvik edin.
- Yapay zekanın yarattığı sanata yönelik artan ilgi, sağlam yasal çerçevelerin oluşturulmasını gerektiriyor. Bu çerçeveler telif hakkı konularını netleştirmeli, katkıları tanımalı ve yapay zeka tarafından üretilen sanat eserlerinin ticari kullanımını yönetmelidir.
Bu sanatsal evrimin şafağı, yaratıcı potansiyelle dolu ancak dikkatli bir koruyuculuk gerektiren bir yol sunuyor. Sorumlu ve kültürel açıdan hassas uygulamaların rehberliğinde, yapay zeka ile sanatın kaynaşmasının geliştiği bir ortam yaratmak bizim görevimizdir.
Sıkça Sorulan Sorular
C. Difüzyon modelleri, rastgele bir gürültü modeliyle başlayıp onu yavaş yavaş tutarlı bir resme dönüştürerek görüntüler oluşturan üretken makine öğrenimi algoritmalarıdır. Bu süreç, bir sanatçının boş bir tuvalle başlayıp yavaş yavaş ayrıntı katmanları eklemesine benzer.
A. GAN'lar, yayılma modelleri, çıktıyı değerlendirmek için ayrı bir ağ gerektirmez. Tekrar tekrar gürültü ekleyip çıkararak çalışırlar ve genellikle daha ayrıntılı ve incelikli görüntüler elde edilir.
C. Evet, yayılma modelleri, bir görüntü veri kümesinden öğrenerek orijinal sanat eserleri oluşturabilir. Ancak özgünlük, eğitim verilerinin çeşitliliğinden ve kapsamından etkilenir. Bu modelleri eğitmek için mevcut sanat eserlerini kullanmanın etiği konusunda devam eden bir tartışma var.
A. Etik kaygılar, yapay zeka tarafından oluşturulan sanat eserlerinin telif hakkı ihlallerinden kaçınmayı kapsar. İnsan sanatçıların özgünlüğüne saygı duymak, önyargının sürekliliğini önlemek ve yapay zekanın yaratıcı sürecinde şeffaflığı sağlamak.
C. Yapay zeka tarafından üretilen sanatın geleceği, sanatçılar ve yaratıcılar için yeni araçlar sunan yayılma modelleriyle umut verici görünüyor. Teknoloji ilerledikçe daha sofistike ve karmaşık sanat eserleri görmeyi bekleyebiliriz. Ancak yaratıcı topluluğun etik hususları dikkate alması ve net yönergeler ve en iyi uygulamalar doğrultusunda çalışması gerekir.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :dır-dir
- :olumsuzluk
- :Neresi
- 001
- 1
- 10
- 100
- 11
- 12
- İNDİRİM
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- kabiliyet
- Hakkımızda
- yukarıdaki
- ÖZET
- doğru
- Başarmak
- elde
- Adem
- adaptif
- ekleme
- Ek
- adres
- Düzeltilmiş
- ileri
- gelişmeler
- Advent
- düşmanca
- AI
- yapay zeka
- benzeyen
- algoritmalar
- Türkiye
- Izin
- veriyor
- an
- Analitik
- analytics
- Analitik Vidhya
- ve
- Duyurusu
- Uygulama
- takdir etmek
- yaklaşım
- mimari
- ARE
- Sanat
- göre
- sanatçı
- artistik
- sanatsal olarak
- yetenek
- Sanatçılar
- sanat eseri
- Sanat Eserleri
- AS
- At
- augmented
- yetki
- mevcut
- caddeler
- önlemek
- kaçınma
- EKSENLER
- Arka
- Kötü
- dengeleme
- merkezli
- BE
- olma
- faydaları
- İYİ
- en iyi uygulamalar
- arasında
- Ötesinde
- önyargı
- önyargıları
- boş
- karıştırma
- blogathon
- doğmuş
- her ikisi de
- sınırları
- nefes alma
- dolup taşan
- Getiriyor
- geniş
- getirdi
- filizlenen
- fakat
- by
- hesaplamak
- denilen
- CAN
- tuval
- yetenekleri
- kabiliyet
- ele geçirmek
- meydan okuma
- zorluklar
- kanallar
- Kaos
- karakteristik
- Kontrol
- denetleme
- kelepçe
- berraklık
- sınıf
- açık
- Daha net
- yakın
- kod
- kodlama
- tutarlı
- işbirliği yapmak
- işbirlikçi
- renk
- geliyor
- ticari
- topluluk
- kompakt
- uygunluk
- rekabet
- tamamlamak
- tamamlama
- karmaşık
- karmaşıklıklar
- bileşen
- kompozisyon
- bilişimsel
- hesaplamak
- kavramlar
- kavramsal
- Endişeler
- konser
- varır
- Bağlantılar
- Düşünmek
- hususlar
- içermek
- içerik
- kontrast
- katkıları
- geleneksel
- Yakınsama
- Dönüştürme
- dönüştürme
- evrişimli sinir ağı
- telif hakkı
- telif hakkı ihlali
- çekirdek
- yozlaşmış
- işlemci
- hazırlanmış
- yaratmak
- Oluşturma
- oluşturma
- Yaratıcı
- Yaratıcı
- yaratıcılık
- yaratıcıları
- çok önemli
- doruğa
- Yetiştirmek
- kültürel
- küratörlüğünü
- eğri
- görenek
- devir
- dans
- veri
- veri kümeleri
- tartışma
- derin
- tanımlarken
- talepleri
- gösterdi
- derinlik
- Derinlikleri
- Türetilmiş
- belirlenen
- ayrıntı
- detaylı
- ayrıntılar
- geliştiriciler
- cihaz
- farklılık
- fark
- farklı
- Yayılma
- dijital
- dijital Sanat
- dijital
- Boyut
- boyutlar
- takdir
- ekran
- sergileyen
- farklı
- ayrım
- çeşitli
- Çeşitlilik
- do
- yok
- kapılar
- çekmek
- Çizimler
- sırasında
- dinamik
- dinamik
- dinamik
- e
- her
- kaçırmak
- yankıları
- etkileri
- ayrıntılı
- başka
- ortaya
- kodlanmış
- kapsamak
- kapsayan
- Mühendislik
- gelişmiş
- sağlamak
- olmasını sağlar
- sağlanması
- Tüm
- çevre
- çağ
- devirler
- çağ
- hata
- öz
- gerekli
- kuruluş
- Eter (ETH)
- törel
- etik
- değerlendirme
- Her
- evrim
- gelişmek
- gelişti
- geliştikçe
- inceleme
- Excel
- Dışında
- mevcut
- Genişletmek
- geniş
- beklemek
- keşif
- keşfetmek
- ifade
- genişletilmiş
- kapsamlı, geniş
- göz
- Gözler
- yüz
- sadık
- yanlış
- tanıdık
- büyüleyici
- Özellikler
- Featuring
- vefa
- şekil
- fileto
- dosyalar
- son
- bitiş
- Ad
- odak
- takip etme
- İçin
- Forefront
- ileri
- Beslemek
- teşvik
- iskelet
- çerçeveler
- itibaren
- tamamen
- işlev
- fonksiyonel
- temel
- daha fazla
- füzyon
- gelecek
- Kazanç
- Gans
- toplama
- verdi
- oluşturmak
- oluşturulan
- üreten
- nesil
- üretken
- üretici ters ağlar
- üretken yapay zeka
- jeneratörler
- Vermek
- gol
- GPU
- gradyanları
- kademeli olarak
- ihtişam
- kavramak
- büyük
- çığır açan
- güdümlü
- kuralları yenileyerek
- Rehberler
- el
- Koşum
- Network XNUMX'in Kalbi
- okuyun
- gizlemek
- özeti
- tarihsel
- tutma
- saygı
- onur
- Ne kadar
- Ancak
- HTTPS
- insan
- i
- Fikir
- if
- tutuşturur
- görüntü
- görüntüleri
- hayal gücü
- zorunlu
- uygulanması
- etkileri
- ithalat
- önemli
- iyileştirmek
- in
- içerir
- dahil
- Kapsayıcılık
- birleştirmek
- artmış
- artımlı
- görevdeki
- etkilemek
- etkilenmiş
- ihlal
- marifet
- yenilik yapmak
- Yenilikçilik
- giriş
- girişler
- kavrama
- integral
- Bütünleştirme
- bütünlük
- entellektüel
- fikri mülkiyet
- faiz
- yorumlama
- içine
- karmaşık
- tanıtmak
- sezgi
- ilgili
- sorunlar
- IT
- tekrarlama
- yineleme
- ONUN
- seyahat
- jpg
- yargıç
- Eksiklik
- manzara
- tabaka
- katmanları
- öğrendim
- öğrenme
- Yasal Şartlar
- Yasal çerçeve
- Mevzuat
- Lens
- yalan
- hayat
- ışık
- sevmek
- yükleme
- GÖRÜNÜYOR
- kayıp
- kayıp
- makine
- makine öğrenme
- korumak
- mucize
- başyapıt
- Maç
- malzeme
- matplotlib
- ortalama
- mekanizma
- mekanizmaları
- medya
- sadece
- birleştirme
- yöntem
- sistemli
- metrik
- azaltmak
- dakika
- yansıtma
- ML
- ML algoritmaları
- Moda
- model
- modelleri
- Modern
- modül
- Daha
- hareket
- çok
- MUSE
- şart
- isimleri
- oluşmaya başlayan
- Tabiat
- Gezin
- gerekli
- ihtiyaçlar
- ağ
- ağlar
- sinirsel
- Sinir mühendisliği
- sinir ağı
- nöral ağlar
- yeni
- Gürültü
- notlar
- roman
- şimdi
- gölgeleme
- gözlemek
- gözlenen
- of
- kapalı
- saldırgan
- teklif
- teklif
- Teklifler
- sık sık
- on
- devam
- bir tek
- açılır
- optimize
- or
- orijinal
- özgünlük
- Orijinalleri
- OS
- Diğer
- bizim
- dışarı
- çıktı
- çıkışlar
- tekrar
- Sahip olunan
- boyama
- resimler
- parametre
- parametreler
- Bölüm
- partiler
- geçmek
- geçmiş
- yol
- model
- desen
- algı
- mükemmelleştirmek
- yapmak
- perspektifler
- resim
- parça
- parçalar
- Platformlar
- Platon
- Plato Veri Zekası
- PlatoVeri
- portreler
- potansiyel
- uygulamalar
- Hassas
- ön
- mevcut
- hediyeler
- korunması
- önlemek
- önlenmesi
- ilkeler
- baskı
- önceliklendirme
- süreç
- işlenmiş
- üreten
- PLATFORM
- Profil
- derin
- Ilerleme
- ilerleme
- aşamalı olarak
- umut verici
- teşvik
- istemleri
- yayılma
- uygun
- özellik
- korumak
- korumalı
- kaynak
- sağlama
- yayınlanan
- takip
- pytorch
- nicelleştirir
- rasgele
- rasgelelik
- menzil
- oran
- hazır
- alan
- tanımak
- Yeniden Tanımlanması
- arıtmak
- rafine
- yansıtan
- yansıtır
- rejim
- düzenli
- ilişki
- kaldırma
- render
- kopya
- temsil
- temsil
- üreme
- gerektirir
- gerektirir
- benzeyen
- yeniden şekillendirmek
- saygı
- ilişkin
- sorumlu
- sorumlu
- Ortaya çıkan
- dönüş
- vahiy
- canlandırmak
- devrim yapmak
- RGB
- Zengin
- haklar
- Yükselmek
- gürbüz
- Rol
- aynı
- kaydedilmiş
- tasarruf
- sahne
- Bilim
- kapsam
- senaryo
- görmek
- SELF
- hassas
- ayrı
- Dizi
- vermektedir
- set
- ayar
- kurulum
- birkaç
- gölge
- şekillendirme
- çalışma
- Vardiyalar
- meli
- vitrin
- vitrine
- gösterilen
- önemli
- beri
- Yavaş yavaş
- pasajı
- So
- sofistike
- ruh
- Kaynak
- kaynaklı
- uzay
- gerginlik
- özellikle
- Spektrum
- Kare
- kararlı
- Aşama
- durmak
- XNUMX dakika içinde!
- istatistiksel
- istikrarlı
- adım
- Stratejileri
- çabası
- yapı
- Çarpıcı
- stil
- konu
- sonraki
- böyle
- Simbiyont
- sinerjistik
- sentez
- sentetik
- ısmarlama
- alır
- alma
- Hedef
- Teknik
- teknikleri
- teknolojik
- Teknolojileri
- Teknoloji
- tensorflow
- vasiyetname
- o
- The
- Gelecek
- Kaynak
- ve bazı Asya
- Onları
- Orada.
- Bunlar
- onlar
- Re-Tweet
- gelişir
- İçinden
- Böylece
- için
- araçlar
- meşale
- Torchvizyon
- dokunma
- karşı
- Takip
- geleneksel
- Tren
- eğitilmiş
- Eğitim
- Dönüştürmek
- Dönüşüm
- dönüşümler
- dönüştürücü
- transforme
- dönüşüm
- dönüşümler
- Şeffaflık
- gerçek
- denemek
- anlamak
- anlayış
- benzersiz
- kadar
- Tanıttı
- güncellenmesi
- üzerine
- us
- kullanım
- Kullanılmış
- kullanma
- yarar
- geçerli
- doğrulama
- üzerinden
- görüntüleme
- bakış açıları
- vizyonumuz
- görsel
- Görsel sanat
- görüntüleme
- görselleştirmek
- görsel
- hayati
- oldu
- we
- webp
- Ne
- Nedir
- hangi
- süre
- Fısıltı
- DSÖ
- geniş
- Geniş ürün yelpazesi
- irade
- pencere
- ile
- içinde
- olmadan
- İş
- çalışır
- Dünya
- X
- Evet
- henüz
- sen
- zefirnet
- sıfır