By เดวิด เวนท์ และ เกรกอรี คิมบอลล์
การประมวลผลข้อมูลสตริงอย่างมีประสิทธิภาพถือเป็นสิ่งสำคัญสำหรับแอปพลิเคชันด้านวิทยาศาสตร์ข้อมูลจำนวนมาก เพื่อดึงข้อมูลอันมีค่าจากข้อมูลสตริง RAPIDS libcudf มอบเครื่องมืออันทรงพลังสำหรับการเร่งการแปลงข้อมูลสตริง libcudf เป็นไลบรารี C++ GPU DataFrame ที่ใช้สำหรับการโหลด การรวม การรวม และการกรองข้อมูล
ในสาขาวิทยาศาสตร์ข้อมูล ข้อมูลสตริงแสดงถึงคำพูด ข้อความ ลำดับทางพันธุกรรม การบันทึก และข้อมูลประเภทอื่นๆ อีกมากมาย เมื่อทำงานกับข้อมูลสตริงสำหรับแมชชีนเลิร์นนิงและวิศวกรรมฟีเจอร์ ข้อมูลจะต้องได้รับการทำให้เป็นมาตรฐานและแปลงบ่อยครั้งก่อนจึงจะสามารถนำไปใช้กับกรณีการใช้งานเฉพาะได้ libcudf มีทั้ง API สำหรับวัตถุประสงค์ทั่วไปและยูทิลิตีฝั่งอุปกรณ์เพื่อให้สามารถดำเนินการสตริงแบบกำหนดเองได้หลากหลาย
โพสต์นี้สาธิตวิธีการแปลงคอลัมน์สตริงอย่างเชี่ยวชาญด้วย API วัตถุประสงค์ทั่วไปของ libcudf คุณจะได้รับความรู้ใหม่เกี่ยวกับวิธีการปลดล็อกประสิทธิภาพสูงสุดโดยใช้เคอร์เนลที่กำหนดเองและยูทิลิตี้ฝั่งอุปกรณ์ libcudf โพสต์นี้ยังแนะนำคุณผ่านตัวอย่างวิธีจัดการหน่วยความจำ GPU ได้ดีที่สุด และสร้างคอลัมน์ libcudf อย่างมีประสิทธิภาพเพื่อเร่งการแปลงสตริงของคุณ
libcudf เก็บข้อมูลสตริงในหน่วยความจำอุปกรณ์โดยใช้ รูปแบบลูกศรซึ่งแสดงถึงคอลัมน์สตริงเป็นคอลัมน์ลูกสองคอลัมน์: chars and offsets (รูปที่ 1)
พื้นที่ chars คอลัมน์เก็บข้อมูลสตริงเป็นไบต์อักขระที่เข้ารหัส UTF-8 ซึ่งจัดเก็บต่อเนื่องกันในหน่วยความจำ
พื้นที่ offsets คอลัมน์ประกอบด้วยลำดับจำนวนเต็มที่เพิ่มขึ้นซึ่งเป็นตำแหน่งไบต์ที่ระบุจุดเริ่มต้นของแต่ละสตริงภายในอาร์เรย์ข้อมูลตัวอักษร องค์ประกอบออฟเซ็ตสุดท้ายคือจำนวนไบต์ทั้งหมดในคอลัมน์ตัวอักษร นี่หมายถึงขนาดของแต่ละสตริงที่แถว i ถูกกำหนดให้เป็น (offsets[i+1]-offsets[i]).
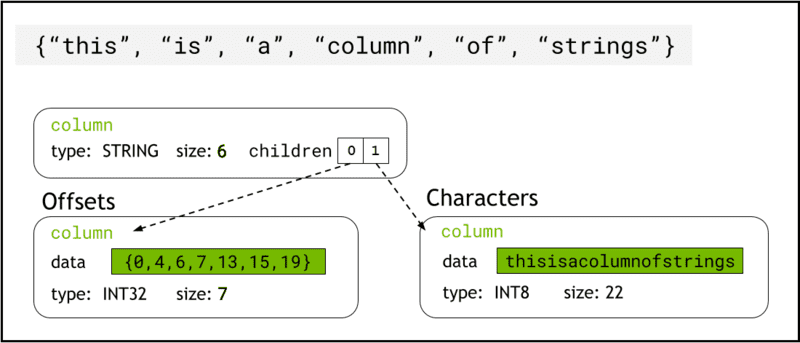 รูปที่ 1 แผนผังแสดงว่ารูปแบบลูกศรแสดงถึงคอลัมน์สตริงอย่างไร
รูปที่ 1 แผนผังแสดงว่ารูปแบบลูกศรแสดงถึงคอลัมน์สตริงอย่างไร chars และ offsets คอลัมน์ย่อย
ในการแสดงตัวอย่างการแปลงสตริง ให้พิจารณาฟังก์ชันที่รับคอลัมน์สตริงอินพุตสองคอลัมน์ และสร้างคอลัมน์สตริงเอาต์พุตที่แก้ไขใหม่หนึ่งคอลัมน์
ข้อมูลที่ป้อนมีรูปแบบดังต่อไปนี้: คอลัมน์ "ชื่อ" ที่มีชื่อและนามสกุลคั่นด้วยช่องว่างและคอลัมน์ "การมองเห็น" ที่มีสถานะเป็น "สาธารณะ" หรือ "ส่วนตัว"
เราเสนอฟังก์ชัน "redact" ที่ทำงานบนข้อมูลอินพุตเพื่อสร้างข้อมูลเอาต์พุตที่ประกอบด้วยอักษรตัวแรกของนามสกุล ตามด้วยช่องว่างและชื่อเต็ม อย่างไรก็ตาม หากคอลัมน์การมองเห็นที่สอดคล้องกันเป็น "ส่วนตัว" สตริงเอาต์พุตควรถูกแก้ไขใหม่ทั้งหมดเป็น "X X"
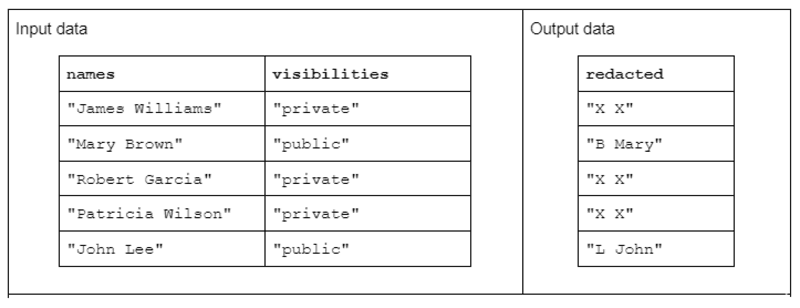 ตารางที่ 1. ตัวอย่างของการแปลงสตริง "ปกปิด" ที่ได้รับชื่อและคอลัมน์สตริงการมองเห็นเป็นอินพุตและข้อมูลที่ถูกทำซ้ำบางส่วนหรือทั้งหมดเป็นเอาต์พุต
ตารางที่ 1. ตัวอย่างของการแปลงสตริง "ปกปิด" ที่ได้รับชื่อและคอลัมน์สตริงการมองเห็นเป็นอินพุตและข้อมูลที่ถูกทำซ้ำบางส่วนหรือทั้งหมดเป็นเอาต์พุต
ขั้นแรก การแปลงสตริงสามารถทำได้สำเร็จโดยใช้ API สตริง libcudf. API สำหรับวัตถุประสงค์ทั่วไปเป็นจุดเริ่มต้นที่ดีเยี่ยมและเป็นพื้นฐานที่ดีสำหรับการเปรียบเทียบประสิทธิภาพ
ฟังก์ชัน API ทำงานบนคอลัมน์สตริงทั้งหมด โดยเรียกใช้เคอร์เนลอย่างน้อยหนึ่งรายการต่อฟังก์ชัน และกำหนดหนึ่งเธรดต่อสตริง แต่ละเธรดจะจัดการข้อมูลแถวเดียวขนานกันทั่วทั้ง GPU และส่งออกแถวเดียวโดยเป็นส่วนหนึ่งของคอลัมน์เอาต์พุตใหม่
หากต้องการดำเนินการฟังก์ชันตัวอย่างให้สมบูรณ์โดยใช้ API วัตถุประสงค์ทั่วไป ให้ทำตามขั้นตอนเหล่านี้:
- แปลงคอลัมน์สตริง "การมองเห็น" ให้เป็นคอลัมน์บูลีนโดยใช้
contains - สร้างคอลัมน์สตริงใหม่จากคอลัมน์ชื่อโดยการคัดลอก "XX" เมื่อใดก็ตามที่รายการแถวที่เกี่ยวข้องในคอลัมน์บูลีนเป็น "false"
- แยกคอลัมน์ "ปกปิด" ออกเป็นคอลัมน์ชื่อและนามสกุล
- แบ่งอักขระตัวแรกของนามสกุลเป็นชื่อย่อของนามสกุล
- สร้างคอลัมน์เอาต์พุตโดยการต่อคอลัมน์ชื่อย่อสุดท้ายและคอลัมน์ชื่อด้วยตัวคั่นช่องว่าง (” “)
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
วิธีการนี้ใช้เวลาประมาณ 3.5 มิลลิวินาทีบน A6000 ที่มีข้อมูล 600 แถว ตัวอย่างนี้ใช้ contains, copy_if_else, split, slice_strings และ concatenate เพื่อทำการแปลงสตริงแบบกำหนดเองให้สำเร็จ การวิเคราะห์โปรไฟล์ด้วย ระบบการมองเห็น แสดงให้เห็นว่า split ฟังก์ชั่นใช้เวลานานที่สุด ตามด้วย slice_strings และ concatenate.
รูปที่ 2 แสดงข้อมูลโปรไฟล์จาก Nsight Systems ของตัวอย่างการแก้ไข ซึ่งแสดงการประมวลผลสตริงจากต้นทางถึงปลายทางที่สูงถึง ~600 ล้านองค์ประกอบต่อวินาที ขอบเขตต่างๆ จะสอดคล้องกับช่วง NVTX ที่เกี่ยวข้องกับแต่ละฟังก์ชัน ช่วงสีฟ้าอ่อนสอดคล้องกับช่วงเวลาที่เคอร์เนล CUDA ทำงาน
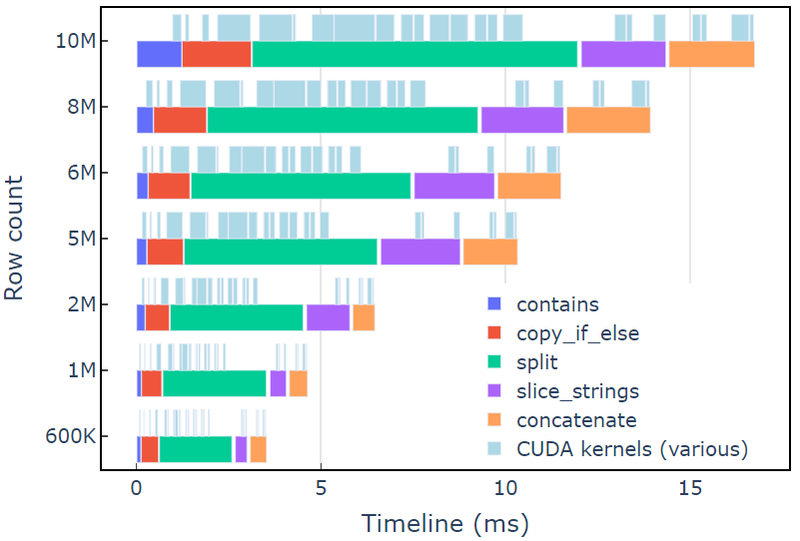 รูปที่ 2 ข้อมูลโปรไฟล์จาก Nsight Systems ของตัวอย่างการแก้ไข
รูปที่ 2 ข้อมูลโปรไฟล์จาก Nsight Systems ของตัวอย่างการแก้ไข
API สตริง libcudf เป็นชุดเครื่องมือที่รวดเร็วและมีประสิทธิภาพสำหรับการแปลงสตริง แต่บางครั้งฟังก์ชันที่มีความสำคัญต่อประสิทธิภาพจำเป็นต้องทำงานเร็วยิ่งขึ้นอีก แหล่งที่มาสำคัญของการทำงานเพิ่มเติมใน API สตริง libcudf คือการสร้างคอลัมน์สตริงใหม่อย่างน้อยหนึ่งคอลัมน์ในหน่วยความจำอุปกรณ์ส่วนกลางสำหรับการเรียก API แต่ละครั้ง ซึ่งเปิดโอกาสให้รวมการเรียก API หลายรายการเข้ากับเคอร์เนลแบบกำหนดเอง
ข้อจำกัดด้านประสิทธิภาพในการเรียก kernel malloc
ขั้นแรก เราจะสร้างเคอร์เนลแบบกำหนดเองเพื่อใช้การแปลงตัวอย่างการแก้ไข เมื่อออกแบบเคอร์เนลนี้ เราต้องจำไว้ว่าคอลัมน์สตริง libcudf นั้นไม่เปลี่ยนรูป
ไม่สามารถเปลี่ยนคอลัมน์สตริงในตำแหน่งได้เนื่องจากไบต์ของอักขระจะถูกเก็บไว้ติดกัน และการเปลี่ยนแปลงความยาวของสตริงจะทำให้ข้อมูลออฟเซ็ตไม่ถูกต้อง ดังนั้น redact_kernel เคอร์เนลแบบกำหนดเองจะสร้างคอลัมน์สตริงใหม่โดยใช้แฟกทอรีคอลัมน์ libcudf เพื่อสร้างทั้งสองคอลัมน์ offsets และ chars คอลัมน์ย่อย
ในแนวทางแรกนี้ สตริงเอาต์พุตสำหรับแต่ละแถวจะถูกสร้างขึ้น หน่วยความจำอุปกรณ์แบบไดนามิก ใช้การเรียก malloc ภายในเคอร์เนล เอาต์พุตเคอร์เนลแบบกำหนดเองคือเวกเตอร์ของตัวชี้อุปกรณ์ไปยังเอาต์พุตแต่ละแถว และเวกเตอร์นี้ทำหน้าที่เป็นอินพุตไปยังแฟกทอรีคอลัมน์สตริง
เคอร์เนลที่กำหนดเองยอมรับไฟล์ cudf::column_device_view เพื่อเข้าถึงข้อมูลคอลัมน์สตริงและใช้ element วิธีการคืนก cudf::string_view แสดงถึงข้อมูลสตริงที่ดัชนีแถวที่ระบุ เอาต์พุตเคอร์เนลเป็นเวกเตอร์ประเภท cudf::string_view ที่เก็บพอยน์เตอร์ไปยังหน่วยความจำอุปกรณ์ที่มีสตริงเอาต์พุตและขนาดของสตริงนั้นมีหน่วยเป็นไบต์
พื้นที่ cudf::string_view คลาสคล้ายกับคลาส std::string_view แต่ถูกนำมาใช้โดยเฉพาะสำหรับ libcudf และล้อมข้อมูลอักขระที่มีความยาวคงที่ในหน่วยความจำอุปกรณ์ที่เข้ารหัสเป็น UTF-8 มีคุณสมบัติหลายอย่างเหมือนกัน (find และ substr ฟังก์ชั่น เป็นต้น) และข้อจำกัด (ไม่มีจุดสิ้นสุดที่เป็นโมฆะ) เป็น std คู่กัน ก cudf::string_view แสดงถึงลำดับอักขระที่เก็บไว้ในหน่วยความจำอุปกรณ์ ดังนั้นเราจึงสามารถใช้มันที่นี่เพื่อบันทึกหน่วยความจำ malloc สำหรับเวกเตอร์เอาท์พุต
เคอร์เนล Malloc
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
นี่อาจดูเหมือนเป็นแนวทางที่สมเหตุสมผล จนกว่าจะมีการวัดประสิทธิภาพของเคอร์เนล วิธีการนี้ใช้เวลาประมาณ 108 มิลลิวินาทีบน A6000 ที่มีข้อมูล 600 แถว ซึ่งช้ากว่าโซลูชันที่ให้ไว้ข้างต้นมากกว่า 30 เท่าโดยใช้ API สตริง libcudf
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
คอขวดหลักคือ malloc/free เรียกภายในเมล็ดทั้งสองที่นี่ ต้องใช้หน่วยความจำอุปกรณ์ไดนามิก CUDA malloc/free การเรียกเคอร์เนลให้ซิงโครไนซ์ ทำให้การประมวลผลแบบขนานเสื่อมลงเป็นการดำเนินการตามลำดับ
การจัดสรรหน่วยความจำในการทำงานล่วงหน้าเพื่อขจัดปัญหาคอขวด
กำจัด malloc/free คอขวดโดยการเปลี่ยน malloc/free เรียกใช้เคอร์เนลด้วยหน่วยความจำการทำงานที่จัดสรรไว้ล่วงหน้าก่อนเปิดตัวเคอร์เนล
สำหรับตัวอย่างการแก้ไข ขนาดเอาต์พุตของแต่ละสตริงในตัวอย่างนี้ไม่ควรใหญ่กว่าสตริงอินพุต เนื่องจากตรรกะจะลบเฉพาะอักขระเท่านั้น ดังนั้นบัฟเฟอร์หน่วยความจำของอุปกรณ์ตัวเดียวจึงสามารถใช้กับขนาดเดียวกับบัฟเฟอร์อินพุตได้ ใช้อินพุตออฟเซ็ตเพื่อค้นหาตำแหน่งแต่ละแถว
การเข้าถึงออฟเซ็ตของคอลัมน์สตริงเกี่ยวข้องกับการล้อม cudf::column_view กับ cudf::strings_column_view และเรียกมันว่า offsets_begin วิธี. ขนาดของ chars คอลัมน์ลูกยังสามารถเข้าถึงได้โดยใช้ chars_size วิธี. แล้วก rmm::device_uvector ได้รับการจัดสรรล่วงหน้าก่อนที่จะเรียกเคอร์เนลเพื่อจัดเก็บข้อมูลเอาต์พุตอักขระ
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);เคอร์เนลที่จัดสรรไว้ล่วงหน้า
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
เคอร์เนลส่งออกเวกเตอร์ของ cudf::string_view วัตถุที่ถูกส่งผ่านไปยัง cudf::make_strings_column ฟังก์ชั่นโรงงาน พารามิเตอร์ตัวที่สองของฟังก์ชันนี้ใช้สำหรับระบุรายการว่างในคอลัมน์เอาต์พุต ตัวอย่างในโพสต์นี้ไม่มีรายการว่าง ดังนั้นตัวยึดตำแหน่ง nullptr cudf::string_view{nullptr,0} ถูกนำมาใช้.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
วิธีการนี้ใช้เวลาประมาณ 1.1 มิลลิวินาทีบน A6000 ที่มีข้อมูล 600 แถว ดังนั้นจึงเร็วกว่าค่าพื้นฐานมากกว่า 2 เท่า รายละเอียดโดยประมาณแสดงไว้ด้านล่าง:
redact_kernel 66us make_strings_column 400us
ใช้เวลาที่เหลืออยู่ใน cudaMalloc, cudaFree, cudaMemcpy, ซึ่งเป็นเรื่องปกติของค่าใช้จ่ายในการจัดการอินสแตนซ์ชั่วคราวของ rmm::device_uvector. วิธีการนี้จะทำงานได้ดีหากสตริงเอาต์พุตทั้งหมดรับประกันว่าจะมีขนาดเท่ากันหรือเล็กกว่าสตริงอินพุต
โดยรวมแล้ว การเปลี่ยนไปใช้การจัดสรรหน่วยความจำการทำงานจำนวนมากด้วย RAPIDS RMM ถือเป็นการปรับปรุงที่สำคัญและเป็นโซลูชันที่ดีสำหรับฟังก์ชันสตริงแบบกำหนดเอง
การเพิ่มประสิทธิภาพการสร้างคอลัมน์เพื่อเวลาในการคำนวณที่เร็วขึ้น
มีวิธีปรับปรุงสิ่งนี้ให้ดียิ่งขึ้นไปอีกหรือไม่? คอขวดอยู่ในขณะนี้ cudf::make_strings_column ฟังก์ชั่นโรงงานซึ่งสร้างส่วนประกอบคอลัมน์สองสาย offsets และ charsจากเวกเตอร์ของ cudf::string_view วัตถุ
ใน libcudf ฟังก์ชั่นโรงงานจำนวนมากจะรวมไว้สำหรับการสร้างคอลัมน์สตริง ฟังก์ชั่นโรงงานที่ใช้ในตัวอย่างก่อนหน้านี้ใช้เวลา cudf::device_span of cudf::string_view วัตถุแล้วสร้างคอลัมน์โดยดำเนินการ gather บนข้อมูลอักขระพื้นฐานเพื่อสร้างคอลัมน์ออฟเซ็ตและคอลัมน์ย่อยอักขระ ก rmm::device_uvector จะถูกแปลงเป็น a โดยอัตโนมัติ cudf::device_span โดยไม่ต้องคัดลอกข้อมูลใดๆ
อย่างไรก็ตาม หากเวกเตอร์ของอักขระและเวกเตอร์ของออฟเซ็ตถูกสร้างขึ้นโดยตรง ก็สามารถใช้ฟังก์ชันโรงงานอื่นได้ ซึ่งเพียงแค่สร้างคอลัมน์สตริงโดยไม่ต้องรวบรวมเพื่อคัดลอกข้อมูล
พื้นที่ sizes_kernel ส่งผ่านข้อมูลอินพุตครั้งแรกเพื่อคำนวณขนาดเอาต์พุตที่แน่นอนของแต่ละแถวเอาต์พุต:
เคอร์เนลที่ปรับให้เหมาะสม: ตอนที่ 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
ขนาดเอาต์พุตจะถูกแปลงเป็นออฟเซ็ตโดยดำเนินการแบบแทนที่ exclusive_scan. โปรดทราบว่าไฟล์ offsets เวกเตอร์ถูกสร้างขึ้นด้วย names.size()+1 องค์ประกอบ รายการสุดท้ายจะเป็นจำนวนไบต์ทั้งหมด (ทุกขนาดรวมกัน) ในขณะที่รายการแรกจะเป็น 0 ทั้งสองรายการได้รับการจัดการโดย exclusive_scan เรียก. ขนาดของ chars คอลัมน์ถูกดึงมาจากรายการสุดท้ายของ offsets คอลัมน์เพื่อสร้างเวกเตอร์ตัวอักษร
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
พื้นที่ redact_kernel ตรรกะยังคงเหมือนเดิมยกเว้นว่ายอมรับเอาต์พุต d_offsets vector เพื่อแก้ไขตำแหน่งเอาต์พุตของแต่ละแถว:
เคอร์เนลที่ปรับให้เหมาะสม: ตอนที่ 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
ขนาดของเอาท์พุท d_chars คอลัมน์ถูกดึงมาจากรายการสุดท้ายของ d_offsets คอลัมน์เพื่อจัดสรรเวกเตอร์ตัวอักษร เคอร์เนลเปิดตัวพร้อมกับเวกเตอร์ออฟเซ็ตที่คำนวณไว้ล่วงหน้า และส่งกลับเวกเตอร์อักขระที่มีประชากร ในที่สุด โรงงานคอลัมน์สตริง libcudf จะสร้างคอลัมน์สตริงเอาต์พุต
cudf::make_strings_column ฟังก์ชันโรงงานสร้างคอลัมน์สตริงโดยไม่ต้องทำสำเนาข้อมูล ที่ offsets ข้อมูลและ chars ข้อมูลอยู่ในรูปแบบที่ถูกต้องและคาดหวังไว้แล้ว และโรงงานแห่งนี้ก็เพียงแค่ย้ายข้อมูลจากเวกเตอร์แต่ละตัวและสร้างโครงสร้างคอลัมน์รอบๆ เวกเตอร์ เมื่อเสร็จแล้ว. rmm::device_uvectors for
offsets และ chars ว่างเปล่า ข้อมูลถูกย้ายไปยังคอลัมน์เอาต์พุตแล้ว
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
วิธีการนี้ใช้เวลาประมาณ 300 us (0.3 ms) บน A6000 ที่มีข้อมูล 600 แถว และปรับปรุงจากแนวทางก่อนหน้ามากกว่า 2 เท่า คุณอาจสังเกตเห็นว่า sizes_kernel และ redact_kernel ใช้ตรรกะเดียวกันมาก: หนึ่งครั้งเพื่อวัดขนาดของเอาต์พุต และอีกครั้งเพื่อเติมเอาต์พุต
จากมุมมองของคุณภาพของโค้ด จะเป็นประโยชน์ในการปรับโครงสร้างการเปลี่ยนแปลงเป็นฟังก์ชันอุปกรณ์ที่เรียกโดยทั้งขนาดและแก้ไขเคอร์เนล จากมุมมองของประสิทธิภาพ คุณอาจแปลกใจที่เห็นต้นทุนการคำนวณของการเปลี่ยนแปลงที่จ่ายเป็นสองเท่า
ประโยชน์สำหรับการจัดการหน่วยความจำและการสร้างคอลัมน์ที่มีประสิทธิภาพมากขึ้นมักจะเกินดุลต้นทุนการคำนวณในการดำเนินการแปลงสองครั้ง
ตารางที่ 2 แสดงเวลาในการคำนวณ จำนวนเคอร์เนล และไบต์ที่ประมวลผลสำหรับโซลูชันทั้งสี่ที่กล่าวถึงในโพสต์นี้ “การเปิดตัวเคอร์เนลทั้งหมด” แสดงถึงจำนวนเคอร์เนลทั้งหมดที่เปิดตัว รวมถึงเคอร์เนลประมวลผลและตัวช่วยเหลือ “จำนวนไบต์ทั้งหมดที่ประมวลผล” คือปริมาณการประมวลผลการอ่านและเขียน DRAM สะสม และ “จำนวนไบต์ขั้นต่ำที่ประมวลผล” คือค่าเฉลี่ย 37.9 ไบต์ต่อแถวสำหรับอินพุตและเอาต์พุตทดสอบของเรา กรณี “แบนด์วิดท์หน่วยความจำจำกัด” ในอุดมคติจะใช้แบนด์วิดท์ 768 GB/s ซึ่งเป็นทรูพุตสูงสุดตามทฤษฎีของ A6000
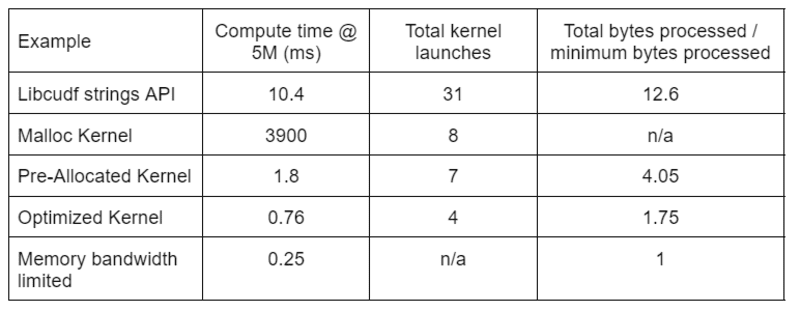 ตารางที่ 2. เวลาในการคำนวณ จำนวนเคอร์เนล และไบต์ที่ประมวลผลสำหรับโซลูชันทั้งสี่ที่กล่าวถึงในโพสต์นี้
ตารางที่ 2. เวลาในการคำนวณ จำนวนเคอร์เนล และไบต์ที่ประมวลผลสำหรับโซลูชันทั้งสี่ที่กล่าวถึงในโพสต์นี้
“เคอร์เนลที่ปรับให้เหมาะสม” ให้ปริมาณงานสูงสุดเนื่องจากจำนวนเคอร์เนลที่ลดลงและจำนวนไบต์ทั้งหมดที่ประมวลผลน้อยลง ด้วยเคอร์เนลแบบกำหนดเองที่มีประสิทธิภาพ จำนวนเคอร์เนลทั้งหมดที่เปิดตัวลดลงจาก 31 เหลือ 4 และจำนวนไบต์ทั้งหมดที่ประมวลผลจาก 12.6x เป็น 1.75x ของอินพุตบวกขนาดเอาต์พุต
ด้วยเหตุนี้ เคอร์เนลแบบกำหนดเองจึงได้รับปริมาณงานสูงกว่า API สตริงวัตถุประสงค์ทั่วไปถึง 10 เท่าสำหรับการแก้ไขการแปลง
ทรัพยากรหน่วยความจำพูลใน ตัวจัดการหน่วยความจำ RAPIDS (RMM) เป็นอีกหนึ่งเครื่องมือที่คุณสามารถใช้เพื่อเพิ่มประสิทธิภาพได้ ตัวอย่างข้างต้นใช้ “ทรัพยากรหน่วยความจำ CUDA” เริ่มต้นสำหรับการจัดสรรและเพิ่มหน่วยความจำอุปกรณ์ส่วนกลาง อย่างไรก็ตาม เวลาที่จำเป็นในการจัดสรรหน่วยความจำในการทำงานจะเพิ่มเวลาแฝงที่สำคัญระหว่างขั้นตอนต่างๆ ของการแปลงสตริง “ทรัพยากรหน่วยความจำพูล” ใน RMM ช่วยลดเวลาแฝงด้วยการจัดสรรหน่วยความจำขนาดใหญ่ไว้ด้านหน้า และกำหนดการจัดสรรย่อยตามความจำเป็นในระหว่างการประมวลผล
ด้วยทรัพยากรหน่วยความจำ CUDA “เคอร์เนลที่ปรับให้เหมาะสม” จะแสดงการเร่งความเร็ว 10x-15x ที่เริ่มลดลงที่จำนวนแถวที่สูงขึ้นเนื่องจากขนาดการจัดสรรที่เพิ่มขึ้น (รูปที่ 3) การใช้ทรัพยากรหน่วยความจำพูลช่วยลดผลกระทบนี้และรักษาการเร่งความเร็ว 15x-25x เหนือแนวทาง API สตริง libcudf
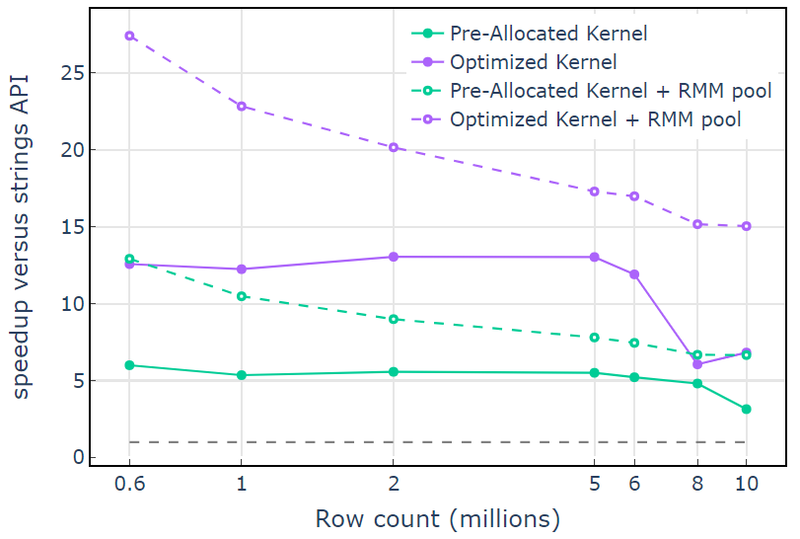 รูปที่ 3 การเร่งความเร็วจากเคอร์เนลแบบกำหนดเอง “เคอร์เนลที่จัดสรรไว้ล่วงหน้า” และ “เคอร์เนลที่ปรับให้เหมาะสม” ด้วยทรัพยากรหน่วยความจำ CUDA เริ่มต้น (โซลิด) และทรัพยากรหน่วยความจำพูล (เส้นประ) เทียบกับ API สตริง libcudf โดยใช้ทรัพยากรหน่วยความจำ CUDA เริ่มต้น
รูปที่ 3 การเร่งความเร็วจากเคอร์เนลแบบกำหนดเอง “เคอร์เนลที่จัดสรรไว้ล่วงหน้า” และ “เคอร์เนลที่ปรับให้เหมาะสม” ด้วยทรัพยากรหน่วยความจำ CUDA เริ่มต้น (โซลิด) และทรัพยากรหน่วยความจำพูล (เส้นประ) เทียบกับ API สตริง libcudf โดยใช้ทรัพยากรหน่วยความจำ CUDA เริ่มต้น
ด้วยทรัพยากรหน่วยความจำพูล จะมีการสาธิตปริมาณงานหน่วยความจำจากต้นทางถึงปลายทางที่เข้าใกล้ขีดจำกัดทางทฤษฎีสำหรับอัลกอริธึมแบบสองรอบ “เคอร์เนลที่ปรับให้เหมาะสม” มีปริมาณงานถึง 320-340 GB/s วัดโดยใช้ขนาดของอินพุตบวกกับขนาดของเอาต์พุตและเวลาในการประมวลผล (รูปที่ 4)
วิธีแรกแบบสองรอบจะวัดขนาดขององค์ประกอบเอาต์พุต จัดสรรหน่วยความจำ จากนั้นตั้งค่าหน่วยความจำด้วยเอาต์พุต ด้วยอัลกอริธึมการประมวลผลแบบสองรอบ การใช้งานใน "เคอร์เนลที่ปรับให้เหมาะสม" จะดำเนินการใกล้กับขีดจำกัดแบนด์วิดท์หน่วยความจำ “ปริมาณการประมวลผลหน่วยความจำตั้งแต่ต้นทางถึงปลายทาง” หมายถึงอินพุตบวกขนาดเอาต์พุตในหน่วย GB หารด้วยเวลาในการประมวลผล *แบนด์วิธหน่วยความจำ RTX A6000 (768 GB/s)
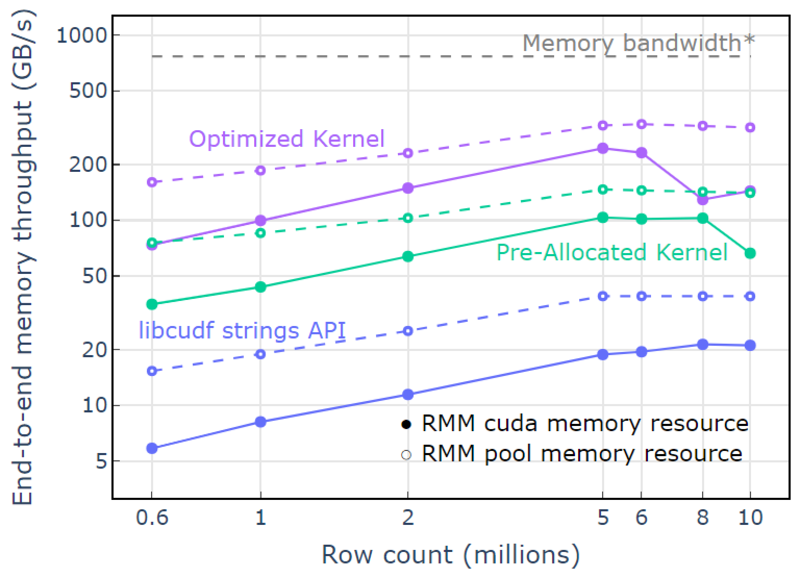 รูปที่ 4 ปริมาณงานหน่วยความจำสำหรับ "Optimized Kernel" "Pre-Allocated Kernel" และ "libcudf strings API" เป็นฟังก์ชันของการนับแถวอินพุต/เอาต์พุต
รูปที่ 4 ปริมาณงานหน่วยความจำสำหรับ "Optimized Kernel" "Pre-Allocated Kernel" และ "libcudf strings API" เป็นฟังก์ชันของการนับแถวอินพุต/เอาต์พุต
โพสต์นี้สาธิตสองวิธีในการเขียนการแปลงข้อมูลสตริงที่มีประสิทธิภาพใน libcudf API วัตถุประสงค์ทั่วไปของ libcudf นั้นรวดเร็วและตรงไปตรงมาสำหรับนักพัฒนา และให้ประสิทธิภาพที่ดี libcudf ยังมียูทิลิตี้ฝั่งอุปกรณ์ที่ออกแบบมาเพื่อใช้กับเคอร์เนลแบบกำหนดเอง ในตัวอย่างนี้จะปลดล็อคประสิทธิภาพที่เร็วขึ้น >10 เท่า
ใช้ความรู้ของคุณ
หากต้องการเริ่มต้นใช้งาน RAPIDS cuDF โปรดไปที่ รวดเร็ว/cudf ที่เก็บ GitHub หากคุณยังไม่ได้ลองใช้ cuDF และ libcudf สำหรับปริมาณงานการประมวลผลสตริง เราขอแนะนำให้คุณทดสอบรีลีสล่าสุด คอนเทนเนอร์เทียบท่า มีไว้เพื่อการเปิดตัวเช่นเดียวกับงานสร้างทุกคืน แพ็คเกจคอนดา นอกจากนี้ยังมีให้เพื่อให้การทดสอบและการปรับใช้ง่ายขึ้น หากคุณใช้ cuDF อยู่แล้ว เราขอแนะนำให้คุณเรียกใช้ตัวอย่างการแปลงสตริงใหม่โดยไปที่ Rapidsai/cudf/tree/HEAD/cpp/examples/strings บน GitHub
เดวิด เวนท์ เป็นวิศวกรซอฟต์แวร์ระบบอาวุโสที่ NVIDIA พัฒนาโค้ด C++/CUDA สำหรับ RAPIDS David สำเร็จการศึกษาระดับปริญญาโทสาขาวิศวกรรมไฟฟ้าจากมหาวิทยาลัย Johns Hopkins
เกรกอรี คิมบอลล์ เป็นผู้จัดการฝ่ายวิศวกรรมซอฟต์แวร์ที่ NVIDIA ซึ่งทำงานในทีม RAPIDS Gregory เป็นผู้นำการพัฒนาสำหรับ libcudf ซึ่งเป็นไลบรารี CUDA/C++ สำหรับการประมวลผลข้อมูลแบบเรียงเป็นแนวที่ขับเคลื่อน RAPIDS cuDF Gregory สำเร็จการศึกษาระดับปริญญาเอกสาขาฟิสิกส์ประยุกต์จากสถาบันเทคโนโลยีแคลิฟอร์เนีย
Original. โพสต์ใหม่โดยได้รับอนุญาต
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- เกี่ยวกับเรา
- ข้างบน
- เร่ง
- ยอมรับ
- เข้า
- Accessed
- คล่องแคล่ว
- ข้าม
- ที่เพิ่ม
- เพิ่ม
- ขั้นตอนวิธี
- ทั้งหมด
- จัดสรร
- การจัดสรร
- แล้ว
- จำนวน
- การวิเคราะห์
- และ
- อื่น
- อาปาเช่
- API
- APIs
- การใช้งาน
- ประยุกต์
- เข้าใกล้
- วิธีการ
- ใกล้เข้ามา
- รอบ
- แถว
- ที่เกี่ยวข้อง
- รถยนต์
- อัตโนมัติ
- ใช้ได้
- เฉลี่ย
- แบนด์วิดธ์
- baseline
- เพราะ
- ก่อน
- กำลัง
- ด้านล่าง
- เป็นประโยชน์
- ประโยชน์ที่ได้รับ
- ที่ดีที่สุด
- ระหว่าง
- สีน้ำเงิน
- รายละเอียด
- กันชน
- สร้าง
- การก่อสร้าง
- สร้าง
- สร้าง
- C + +
- แคลิฟอร์เนีย
- โทรศัพท์
- ที่เรียกว่า
- โทร
- โทร
- ไม่ได้
- กรณี
- กรณี
- การก่อให้เกิด
- การเปลี่ยนแปลง
- ตัวอักษร
- อักขระ
- เด็ก
- ชั้น
- ปิดหน้านี้
- รหัส
- คอลัมน์
- คอลัมน์
- รวมกัน
- เปรียบเทียบ
- สมบูรณ์
- เสร็จ
- ส่วนประกอบ
- การคำนวณ
- คำนวณ
- พิจารณา
- ประกอบด้วย
- สร้าง
- มี
- แปลง
- แปลง
- การทำสำเนา
- ตรงกัน
- ราคา
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- การสร้าง
- ประเพณี
- ข้อมูล
- การประมวลผล
- วิทยาศาสตร์ข้อมูล
- เดวิด
- ค่าเริ่มต้น
- องศา
- มอบ
- แสดงให้เห็นถึง
- การใช้งาน
- ได้รับการออกแบบ
- การออกแบบ
- นักพัฒนา
- ที่กำลังพัฒนา
- พัฒนาการ
- เครื่อง
- ต่าง
- โดยตรง
- กล่าวถึง
- แบ่งออก
- นักเทียบท่า
- หล่น
- ในระหว่าง
- พลวัต
- แต่ละ
- ง่ายดาย
- ผล
- ที่มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- วิศวกรรมไฟฟ้า
- องค์ประกอบ
- กำจัด
- ทำให้สามารถ
- ส่งเสริม
- จบสิ้น
- วิศวกร
- ชั้นเยี่ยม
- ทั้งหมด
- การเข้า
- อีเธอร์ (ETH)
- แม้
- ทุกอย่าง
- ตัวอย่าง
- ตัวอย่าง
- ยอดเยี่ยม
- ยกเว้น
- การปฏิบัติ
- ที่คาดหวัง
- ภายนอก
- พิเศษ
- สารสกัด
- โรงงาน
- FAST
- เร็วขึ้น
- ลักษณะ
- คุณสมบัติ
- รูป
- กรอง
- สุดท้าย
- ในที่สุด
- ชื่อจริง
- การแก้ไข
- ปฏิบัติตาม
- ตาม
- ดังต่อไปนี้
- ฟอร์ม
- รูป
- ฟรี
- มัก
- ราคาเริ่มต้นที่
- ด้านหน้า
- อย่างเต็มที่
- ฟังก์ชัน
- ฟังก์ชั่น
- ต่อไป
- ได้รับ
- General
- สร้าง
- ได้รับ
- GitHub
- กำหนด
- เหตุการณ์ที่
- ดี
- GPU
- รับประกัน
- จัดการ
- มี
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- สูงกว่า
- ที่สูงที่สุด
- ถือ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- HTTPS
- ในอุดมคติ
- ระบุ
- ไม่เปลี่ยนรูป
- การดำเนินการ
- การดำเนินงาน
- การดำเนินการ
- ปรับปรุง
- การปรับปรุง
- ช่วยเพิ่ม
- in
- รวม
- รวมทั้ง
- เพิ่ม
- ที่เพิ่มขึ้น
- ดัชนี
- เป็นรายบุคคล
- ข้อมูล
- แรกเริ่ม
- อินพุต
- สถาบัน
- ภายใน
- IT
- ตัวเอง
- Johns Hopkins
- มหาวิทยาลัย Johns Hopkins
- การร่วม
- KD นักเก็ต
- เก็บ
- คีย์
- ความรู้
- ฉลาก
- ใหญ่
- ที่มีขนาดใหญ่
- ชื่อสกุล
- ความแอบแฝง
- ล่าสุด
- รุ่นล่าสุด
- เปิดตัว
- การเปิดตัว
- การเปิดตัว
- นำไปสู่
- การเรียนรู้
- ความยาว
- ห้องสมุด
- เบา
- LIMIT
- ข้อ จำกัด
- โหลด
- ที่ตั้ง
- เครื่อง
- เรียนรู้เครื่อง
- หลัก
- รักษา
- ทำ
- ทำให้
- การทำ
- จัดการ
- การจัดการ
- ผู้จัดการ
- การจัดการ
- หลาย
- เจ้านาย
- Mastering
- การจับคู่
- วิธี
- วัด
- มาตรการ
- หน่วยความจำ
- วิธี
- อาจ
- ล้าน
- ใจ
- ข้อมูลเพิ่มเติม
- มีประสิทธิภาพมากขึ้น
- ย้าย
- MS
- หลาย
- ชื่อ
- ชื่อ
- จำเป็นต้อง
- จำเป็น
- ใหม่
- จำนวน
- Nvidia
- วัตถุ
- ชดเชย
- ONE
- การเปิด
- ทำงาน
- ดำเนินการ
- การดำเนินการ
- โอกาส
- อื่นๆ
- ต้องจ่าย
- Parallel
- พารามิเตอร์
- ส่วนหนึ่ง
- ผ่าน
- จุดสูงสุด
- การปฏิบัติ
- ที่มีประสิทธิภาพ
- ดำเนินการ
- งวด
- การอนุญาต
- มุมมอง
- ฟิสิกส์
- สถานที่
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- บวก
- จุด
- สระ
- ประชากร
- ตำแหน่ง
- ตำแหน่ง
- โพสต์
- ที่มีประสิทธิภาพ
- อำนาจ
- ก่อน
- การประมวลผล
- ก่อ
- โปรไฟล์
- เสนอ
- ให้
- ให้
- สาธารณะ
- วัตถุประสงค์
- คุณภาพ
- พิสัย
- ต้นน้ำ
- อ่าน
- เหมาะสม
- ที่ได้รับ
- ระเบียน
- ลดลง
- ลด
- ปรับปรุงโครงสร้าง
- สะท้อนให้เห็นถึง
- ภูมิภาค
- ปล่อย
- สัมพันธ์
- ที่เหลืออยู่
- เป็นตัวแทนของ
- แสดงให้เห็นถึง
- ทรัพยากร
- ผล
- กลับ
- รับคืน
- แถว
- วิ่ง
- วิ่ง
- เดียวกัน
- วิทยาศาสตร์
- ที่สอง
- ระดับอาวุโส
- ลำดับ
- ให้บริการอาหาร
- ชุดอุปกรณ์
- Share
- น่า
- แสดง
- แสดงให้เห็นว่า
- สำคัญ
- คล้ายคลึงกัน
- ง่ายดาย
- ตั้งแต่
- เดียว
- ขนาด
- ขนาด
- มีขนาดเล็กกว่า
- So
- ซอฟต์แวร์
- วิศวกรซอฟต์แวร์
- วิศวกรรมซอฟต์แวร์
- ของแข็ง
- ทางออก
- โซลูชัน
- แหล่ง
- ช่องว่าง
- โดยเฉพาะ
- เฉพาะ
- ที่ระบุไว้
- การพูด
- ความเร็ว
- การใช้จ่าย
- แยก
- เริ่มต้น
- ข้อความที่เริ่ม
- ที่เริ่มต้น
- Status
- ขั้นตอน
- ยังคง
- จัดเก็บ
- เก็บไว้
- ร้านค้า
- ซื่อตรง
- กระแส
- โครงสร้าง
- ประหลาดใจ
- ระบบ
- ใช้เวลา
- ทีม
- เทคโนโลยี
- ชั่วคราว
- ทดสอบ
- การทดสอบ
- พื้นที่
- ของพวกเขา
- ตามทฤษฎี
- ดังนั้น
- ตลอด
- ปริมาณงาน
- เวลา
- ไปยัง
- ร่วมกัน
- เครื่องมือ
- เครื่องมือ
- เครื่องมือ
- รวม
- แปลง
- การแปลง
- การแปลง
- เปลี่ยน
- การเปลี่ยนแปลง
- tv
- ชนิด
- ตามแบบฉบับ
- พื้นฐาน
- มหาวิทยาลัย
- ปลดล็อก
- ปลดล็อค
- us
- ใช้
- ยูทิลิตี้
- มีคุณค่า
- ข้อมูลที่มีค่า
- กับ
- ความชัดเจน
- มองเห็นได้
- จำเป็น
- ที่
- ในขณะที่
- กว้าง
- ช่วงกว้าง
- จะ
- ภายใน
- ไม่มี
- งาน
- การทำงาน
- โรงงาน
- จะ
- เขียน
- การเขียน
- X
- ของคุณ
- ลมทะเล










