OpenAI กระซิบ เป็นโมเดลการรู้จำเสียงพูดอัตโนมัติขั้นสูง (ASR) พร้อมใบอนุญาต MIT เทคโนโลยี ASR ค้นหาประโยชน์ในบริการถอดเสียง ระบบสั่งงานด้วยเสียง และเพิ่มประสิทธิภาพการเข้าถึงสำหรับบุคคลที่มีความบกพร่องทางการได้ยิน โมเดลที่ล้ำสมัยนี้ได้รับการฝึกอบรมเกี่ยวกับชุดข้อมูลขนาดใหญ่และหลากหลายซึ่งประกอบด้วยข้อมูลหลายภาษาและมัลติทาสก์ที่รวบรวมจากเว็บ ความแม่นยำและความสามารถในการปรับตัวสูงทำให้เป็นทรัพย์สินที่มีค่าสำหรับงานที่เกี่ยวข้องกับเสียงที่หลากหลาย
ในภูมิทัศน์ที่เปลี่ยนแปลงตลอดเวลาของแมชชีนเลิร์นนิงและปัญญาประดิษฐ์ อเมซอน SageMaker ให้ระบบนิเวศที่ครอบคลุม SageMaker ช่วยให้นักวิทยาศาสตร์ข้อมูล นักพัฒนา และองค์กรต่างๆ พัฒนา ฝึกอบรม ปรับใช้ และจัดการโมเดลการเรียนรู้ของเครื่องในวงกว้าง ด้วยเครื่องมือและความสามารถที่หลากหลาย ทำให้เวิร์กโฟลว์แมชชีนเลิร์นนิงทั้งหมดง่ายขึ้น ตั้งแต่การประมวลผลข้อมูลล่วงหน้าและการพัฒนาโมเดล ไปจนถึงการปรับใช้งานและการตรวจสอบที่ง่ายดาย อินเทอร์เฟซที่ใช้งานง่ายของ SageMaker ทำให้ SageMaker เป็นแพลตฟอร์มสำคัญในการปลดล็อกศักยภาพของ AI อย่างเต็มรูปแบบ โดยกำหนดให้เป็นโซลูชันที่เปลี่ยนแปลงเกมในขอบเขตของปัญญาประดิษฐ์
ในโพสต์นี้ เราจะเริ่มต้นการสำรวจความสามารถของ SageMaker โดยเน้นที่การโฮสต์โมเดล Whisper โดยเฉพาะ เราจะเจาะลึกลงไปในสองวิธีในการทำเช่นนี้: วิธีแรกใช้โมเดล Whisper PyTorch และอีกวิธีหนึ่งโดยใช้การใช้ Hugging Face ของโมเดล Whisper นอกจากนี้ เราจะดำเนินการตรวจสอบตัวเลือกการอนุมานของ SageMaker ในเชิงลึก โดยเปรียบเทียบกับพารามิเตอร์ต่างๆ เช่น ความเร็ว ต้นทุน ขนาดเพย์โหลด และความสามารถในการปรับขนาด การวิเคราะห์นี้ช่วยให้ผู้ใช้มีข้อมูลในการตัดสินใจเมื่อรวมโมเดล Whisper เข้ากับกรณีการใช้งานและระบบเฉพาะของตน
ภาพรวมโซลูชัน
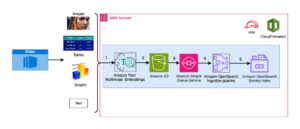
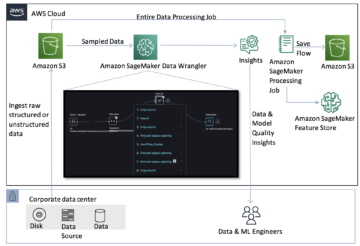
แผนภาพต่อไปนี้แสดงส่วนประกอบหลักของโซลูชันนี้
- ในการโฮสต์โมเดลบน Amazon SageMaker ขั้นตอนแรกคือการบันทึกอาร์ติแฟกต์ของโมเดล สิ่งประดิษฐ์เหล่านี้อ้างถึงองค์ประกอบสำคัญของโมเดลการเรียนรู้ของเครื่องที่จำเป็นสำหรับแอปพลิเคชันต่างๆ รวมถึงการปรับใช้และการฝึกอบรมใหม่ ซึ่งอาจรวมถึงพารามิเตอร์โมเดล ไฟล์การกำหนดค่า ส่วนประกอบก่อนการประมวลผล ตลอดจนข้อมูลเมตา เช่น รายละเอียดเวอร์ชัน ผู้เขียน และหมายเหตุใดๆ ที่เกี่ยวข้องกับประสิทธิภาพ สิ่งสำคัญที่ควรทราบคือโมเดล Whisper สำหรับการใช้งาน PyTorch และ Hugging Face ประกอบด้วยอาร์ติแฟกต์ของโมเดลที่แตกต่างกัน
- ต่อไป เราจะสร้างสคริปต์การอนุมานแบบกำหนดเอง ภายในสคริปต์เหล่านี้ เรากำหนดวิธีการโหลดโมเดลและระบุกระบวนการอนุมาน นี่คือจุดที่เราสามารถรวมพารามิเตอร์ที่กำหนดเองได้ตามต้องการ นอกจากนี้ คุณยังสามารถแสดงรายการแพ็คเกจ Python ที่จำเป็นใน
requirements.txtไฟล์. ในระหว่างการปรับใช้โมเดล แพ็คเกจ Python เหล่านี้จะถูกติดตั้งโดยอัตโนมัติในขั้นตอนการเริ่มต้น - จากนั้นเราเลือกคอนเทนเนอร์การเรียนรู้เชิงลึก (DLC) ของ PyTorch หรือ Hugging Face ที่จัดเตรียมและดูแลโดย AWS. คอนเทนเนอร์เหล่านี้เป็นอิมเมจ Docker ที่สร้างไว้ล่วงหน้าพร้อมเฟรมเวิร์กการเรียนรู้เชิงลึกและแพ็คเกจ Python ที่จำเป็นอื่นๆ สำหรับข้อมูลเพิ่มเติม คุณสามารถตรวจสอบได้ ลิงค์.
- ด้วยอาร์ติแฟกต์ของโมเดล สคริปต์การอนุมานแบบกำหนดเอง และ DLC ที่เลือก เราจะสร้างโมเดล Amazon SageMaker สำหรับ PyTorch และ Hugging Face ตามลำดับ
- สุดท้ายนี้ คุณสามารถปรับใช้โมเดลบน SageMaker และใช้กับตัวเลือกต่อไปนี้: ตำแหน่งข้อมูลการอนุมานแบบเรียลไทม์ งานการแปลงเป็นชุด และตำแหน่งข้อมูลการอนุมานแบบอะซิงโครนัส เราจะเจาะลึกตัวเลือกเหล่านี้โดยละเอียดเพิ่มเติมในโพสต์นี้
ตัวอย่างสมุดบันทึกและโค้ดสำหรับโซลูชันนี้มีอยู่ในสิ่งนี้ พื้นที่เก็บข้อมูล GitHub.
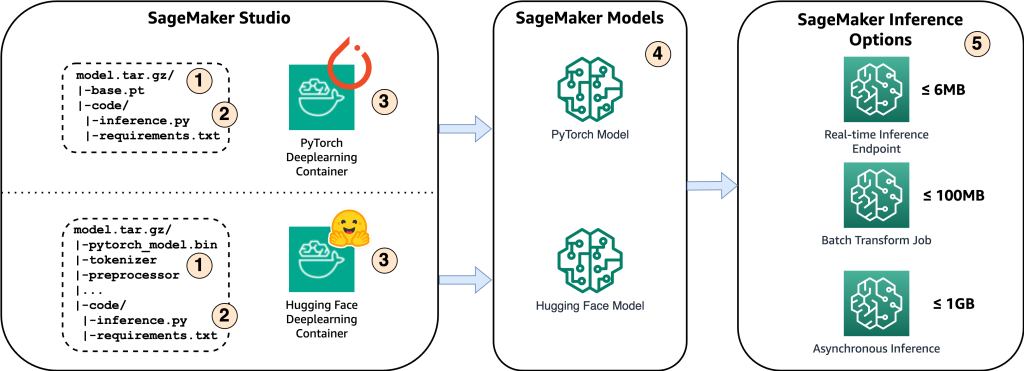
รูปที่ 1 ภาพรวมของส่วนประกอบโซลูชันหลัก
คำแนะนำแบบ
การโฮสต์โมเดล Whisper บน Amazon SageMaker
ในส่วนนี้ เราจะอธิบายขั้นตอนในการโฮสต์โมเดล Whisper บน Amazon SageMaker โดยใช้ PyTorch และ Hugging Face Frameworks ตามลำดับ หากต้องการทดลองใช้โซลูชันนี้ คุณต้องมีบัญชี AWS และเข้าถึงบริการ Amazon SageMaker
กรอบงาน PyTorch
- บันทึกสิ่งประดิษฐ์ของโมเดล
ตัวเลือกแรกในการโฮสต์โมเดลคือการใช้ แพ็คเกจ Python อย่างเป็นทางการของ Whisperซึ่งสามารถติดตั้งได้โดยใช้ pip install openai-whisper. แพ็คเกจนี้มีโมเดล PyTorch เมื่อบันทึกสิ่งประดิษฐ์ของโมเดลในพื้นที่เก็บข้อมูลในตัวเครื่อง ขั้นตอนแรกคือการบันทึกพารามิเตอร์ที่เรียนรู้ได้ของโมเดล เช่น น้ำหนักและอคติของโมเดลแต่ละเลเยอร์ในโครงข่ายประสาทเทียม เป็นไฟล์ 'pt' คุณสามารถเลือกขนาดโมเดลที่แตกต่างกันได้ รวมถึง 'เล็ก' 'ฐาน' 'เล็ก' 'กลาง' และ 'ใหญ่' ขนาดแบบจำลองที่ใหญ่กว่าให้ประสิทธิภาพที่มีความแม่นยำสูงกว่า แต่ต้องแลกมาด้วยค่าเวลาแฝงในการอนุมานที่นานขึ้น นอกจากนี้ คุณต้องบันทึกพจนานุกรมสถานะของโมเดลและพจนานุกรมมิติซึ่งประกอบด้วยพจนานุกรม Python ที่แมปแต่ละเลเยอร์หรือพารามิเตอร์ของโมเดล PyTorch กับพารามิเตอร์ที่เรียนรู้ได้ที่เกี่ยวข้อง พร้อมด้วยข้อมูลเมตาอื่นๆ และการกำหนดค่าแบบกำหนดเอง โค้ดด้านล่างแสดงวิธีการบันทึกสิ่งประดิษฐ์ Whisper PyTorch
- เลือกเนื้อหาดาวน์โหลด
ขั้นตอนต่อไปคือการเลือก DLC ที่สร้างไว้ล่วงหน้าจากสิ่งนี้ ลิงค์. โปรดใช้ความระมัดระวังเมื่อเลือกรูปภาพที่ถูกต้องโดยคำนึงถึงการตั้งค่าต่อไปนี้: เฟรมเวิร์ก (PyTorch), เวอร์ชันเฟรมเวิร์ก, งาน (การอนุมาน), เวอร์ชัน Python และฮาร์ดแวร์ (เช่น GPU) ขอแนะนำให้ใช้เวอร์ชันล่าสุดสำหรับเฟรมเวิร์กและ Python ทุกครั้งที่เป็นไปได้ เนื่องจากส่งผลให้มีประสิทธิภาพดีขึ้น และแก้ไขปัญหาและจุดบกพร่องที่ทราบจากรุ่นก่อนหน้า
- สร้างโมเดล Amazon SageMaker
ต่อไปเราใช้ SageMaker Python SDK เพื่อสร้างโมเดล PyTorch สิ่งสำคัญคือต้องจำไว้ว่าต้องเพิ่มตัวแปรสภาพแวดล้อมเมื่อสร้างโมเดล PyTorch ตามค่าเริ่มต้น TorchServe สามารถประมวลผลขนาดไฟล์ได้สูงสุด 6MB เท่านั้น โดยไม่คำนึงถึงประเภทการอนุมานที่ใช้
ตารางต่อไปนี้แสดงการตั้งค่าสำหรับ PyTorch เวอร์ชันต่างๆ:
| กรอบ | ตัวแปรสภาพแวดล้อม |
| PyTorch 1.8 (อิงจาก TorchServe) | 'TS_MAX_REQUEST_SIZE': '100000000'' TS_MAX_RESPONSE_SIZE': '100000000'' TS_DEFAULT_RESPONSE_TIMEOUT': '1000' |
| PyTorch 1.4 (อิงตาม MMS) | 'MMS_MAX_REQUEST_SIZE': '1000000000'' MMS_MAX_RESPONSE_SIZE': '1000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- กำหนดวิธีการโหลดโมเดลใน inference.py
ในธรรมเนียม inference.py อันดับแรกเราจะตรวจสอบความพร้อมใช้งานของ GPU ที่รองรับ CUDA หาก GPU ดังกล่าวพร้อมใช้งาน เราจะกำหนด 'cuda' อุปกรณ์ไปยัง DEVICE ตัวแปร; มิฉะนั้นเราจะมอบหมายให้ 'cpu' อุปกรณ์. ขั้นตอนนี้ช่วยให้แน่ใจว่าโมเดลถูกวางบนฮาร์ดแวร์ที่มีอยู่เพื่อการคำนวณที่มีประสิทธิภาพ เราโหลดโมเดล PyTorch โดยใช้แพ็คเกจ Whisper Python
กรอบหน้ากอด
- บันทึกสิ่งประดิษฐ์ของโมเดล
ตัวเลือกที่สองคือการใช้ เสียงกระซิบของใบหน้ากอด การดำเนินการ สามารถโหลดโมเดลได้โดยใช้ AutoModelForSpeechSeq2Seq คลาสหม้อแปลงไฟฟ้า พารามิเตอร์ที่เรียนรู้ได้จะถูกบันทึกไว้ในไฟล์ไบนารี (bin) โดยใช้ save_pretrained วิธี. โทเค็นไนเซอร์และพรีโปรเซสเซอร์ยังต้องได้รับการบันทึกแยกต่างหากเพื่อให้แน่ใจว่าโมเดล Hugging Face ทำงานได้อย่างถูกต้อง หรือคุณสามารถปรับใช้โมเดลบน Amazon SageMaker ได้โดยตรงจาก Hugging Face Hub โดยการตั้งค่าตัวแปรสภาพแวดล้อมสองตัว: HF_MODEL_ID และ HF_TASK. สำหรับข้อมูลเพิ่มเติม โปรดดูที่นี้ เวปไซด์.
- เลือกเนื้อหาดาวน์โหลด
เช่นเดียวกับเฟรมเวิร์ก PyTorch คุณสามารถเลือก Hugging Face DLC ที่สร้างไว้ล่วงหน้าได้จากอันเดียวกัน ลิงค์. ตรวจสอบให้แน่ใจว่าได้เลือก DLC ที่รองรับหม้อแปลง Hugging Face รุ่นล่าสุดและมีการรองรับ GPU
- สร้างโมเดล Amazon SageMaker
ในทำนองเดียวกันเราใช้ SageMaker Python SDK เพื่อสร้างโมเดล Hugging Face โมเดล Hugging Face Whisper มีข้อจำกัดเริ่มต้นซึ่งสามารถประมวลผลส่วนเสียงได้สูงสุด 30 วินาทีเท่านั้น เพื่อแก้ไขข้อจำกัดนี้ คุณสามารถรวม chunk_length_s พารามิเตอร์ในตัวแปรสภาพแวดล้อมเมื่อสร้างโมเดล Hugging Face และส่งพารามิเตอร์นี้ไปยังสคริปต์การอนุมานที่กำหนดเองในภายหลังเมื่อโหลดโมเดล สุดท้าย ตั้งค่าตัวแปรสภาพแวดล้อมเพื่อเพิ่มขนาดเพย์โหลดและการหมดเวลาตอบสนองสำหรับคอนเทนเนอร์ Hugging Face
| กรอบ | ตัวแปรสภาพแวดล้อม |
|
คอนเทนเนอร์การอนุมาน HuggingFace (ขึ้นอยู่กับ MMS) |
'MMS_MAX_REQUEST_SIZE': '2000000000'' MMS_MAX_RESPONSE_SIZE': '2000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- กำหนดวิธีการโหลดโมเดลใน inference.py
เมื่อสร้างสคริปต์การอนุมานแบบกำหนดเองสำหรับโมเดล Hugging Face เราจะใช้ไปป์ไลน์เพื่อให้เราส่งต่อได้ chunk_length_s เป็นพารามิเตอร์ พารามิเตอร์นี้ทำให้โมเดลสามารถประมวลผลไฟล์เสียงขนาดยาวในระหว่างการอนุมานได้อย่างมีประสิทธิภาพ
สำรวจตัวเลือกการอนุมานต่างๆ บน Amazon SageMaker
ขั้นตอนในการเลือกตัวเลือกการอนุมานจะเหมือนกันสำหรับทั้งรุ่น PyTorch และ Hugging Face ดังนั้น เราจะไม่แยกความแตกต่างระหว่างรุ่นเหล่านี้ด้านล่าง อย่างไรก็ตาม เป็นที่น่าสังเกตว่าในขณะที่เขียนโพสต์นี้ การอนุมานแบบไร้เซิร์ฟเวอร์ ตัวเลือกจาก SageMaker ไม่รองรับ GPU และด้วยเหตุนี้ เราจึงไม่รวมตัวเลือกนี้สำหรับกรณีการใช้งานนี้
เราสามารถนำโมเดลไปใช้เป็นจุดสิ้นสุดแบบเรียลไทม์ โดยให้การตอบสนองในหน่วยมิลลิวินาที อย่างไรก็ตาม โปรดทราบว่าตัวเลือกนี้จำกัดเฉพาะการประมวลผลอินพุตที่มีขนาดต่ำกว่า 6 MB เรากำหนดซีเรียลไลเซอร์ให้เป็นซีเรียลไลเซอร์เสียง ซึ่งมีหน้าที่ในการแปลงข้อมูลอินพุตให้อยู่ในรูปแบบที่เหมาะสมสำหรับโมเดลที่ใช้งาน เราใช้อินสแตนซ์ GPU สำหรับการอนุมาน ช่วยให้สามารถประมวลผลไฟล์เสียงได้เร็วขึ้น อินพุตการอนุมานเป็นไฟล์เสียงที่มาจากที่เก็บในเครื่อง
ตัวเลือกการอนุมานที่สองคืองานการแปลงเป็นชุด ซึ่งสามารถประมวลผลเพย์โหลดอินพุตสูงสุด 100 MB อย่างไรก็ตาม วิธีนี้อาจใช้เวลาสักครู่ แต่ละอินสแตนซ์สามารถจัดการคำขอแบบแบตช์ได้ครั้งละหนึ่งคำขอเท่านั้น และการเริ่มต้นและการปิดอินสแตนซ์ยังต้องใช้เวลาสักครู่ด้วย ผลลัพธ์การอนุมานจะถูกบันทึกไว้ใน Amazon Simple Storage Service (Amazon S3) ที่เก็บข้อมูลเมื่องานการแปลงแบบแบตช์เสร็จสิ้น
เมื่อกำหนดค่าหม้อแปลงแบบแบตช์ ต้องแน่ใจว่าได้รวมไว้ด้วย max_payload = 100 เพื่อรองรับน้ำหนักบรรทุกที่มากขึ้นได้อย่างมีประสิทธิภาพ อินพุตการอนุมานควรเป็นเส้นทาง Amazon S3 ไปยังไฟล์เสียงหรือโฟลเดอร์ Amazon S3 Bucket ที่มีรายการไฟล์เสียง โดยแต่ละไฟล์มีขนาดเล็กกว่า 100 MB
Batch Transform จะแบ่งพาร์ติชันอ็อบเจ็กต์ Amazon S3 ในอินพุตด้วยคีย์ และแมปอ็อบเจ็กต์ Amazon S3 กับอินสแตนซ์ ตัวอย่างเช่น เมื่อคุณมีไฟล์เสียงหลายไฟล์ อินสแตนซ์หนึ่งอาจประมวลผล input1.wav และอีกอินสแตนซ์หนึ่งอาจประมวลผลไฟล์ชื่อ input2.wav เพื่อเพิ่มความสามารถในการปรับขนาด Batch Transform ช่วยให้คุณสามารถกำหนดค่าได้ max_concurrent_transforms เพื่อเพิ่มจำนวนคำขอ HTTP ที่ทำกับคอนเทนเนอร์หม้อแปลงแต่ละตัว อย่างไรก็ตาม สิ่งสำคัญคือต้องทราบว่ามูลค่าของ (max_concurrent_transforms* max_payload) ต้องไม่เกิน 100 MB
สุดท้ายนี้ Amazon SageMaker Asynchronous Inference เหมาะอย่างยิ่งสำหรับการประมวลผลคำขอหลายรายการพร้อมกัน โดยให้เวลาแฝงปานกลางและรองรับเพย์โหลดอินพุตสูงสุด 1 GB ตัวเลือกนี้มอบความสามารถในการปรับขนาดที่ยอดเยี่ยม ช่วยให้สามารถกำหนดค่ากลุ่มการปรับขนาดอัตโนมัติสำหรับปลายทางได้ เมื่อคำขอเพิ่มขึ้นอย่างรวดเร็ว ระบบจะขยายขนาดโดยอัตโนมัติเพื่อรองรับการรับส่งข้อมูล และเมื่อคำขอทั้งหมดได้รับการประมวลผล จุดสิ้นสุดจะลดขนาดลงเหลือ 0 เพื่อประหยัดค่าใช้จ่าย
เมื่อใช้การอนุมานแบบอะซิงโครนัส ผลลัพธ์จะถูกบันทึกลงในบัคเก็ต Amazon S3 โดยอัตโนมัติ ใน AsyncInferenceConfigคุณสามารถกำหนดค่าการแจ้งเตือนว่าดำเนินการสำเร็จหรือล้มเหลวได้ เส้นทางอินพุตชี้ไปยังตำแหน่ง Amazon S3 ของไฟล์เสียง สำหรับรายละเอียดเพิ่มเติม โปรดดูที่โค้ดบน GitHub.
ตัวเลือก: ตามที่กล่าวไว้ก่อนหน้านี้ เรามีตัวเลือกในการกำหนดค่ากลุ่มการปรับขนาดอัตโนมัติสำหรับจุดสิ้นสุดการอนุมานแบบอะซิงโครนัส ซึ่งช่วยให้สามารถจัดการกับคำขอการอนุมานที่เพิ่มขึ้นอย่างฉับพลัน มีตัวอย่างรหัสระบุไว้ในนี้ พื้นที่เก็บข้อมูล GitHub. ในแผนภาพต่อไปนี้ คุณสามารถสังเกตแผนภูมิเส้นที่แสดงเมตริกสองตัวได้ อเมซอน คลาวด์วอตช์: ApproximateBacklogSize และ ApproximateBacklogSizePerInstance. ในขั้นต้น เมื่อมีการเรียกใช้คำขอ 1000 รายการ จะมีเพียงอินสแตนซ์เดียวเท่านั้นที่พร้อมจะจัดการการอนุมานได้ เป็นเวลาสามนาที ขนาด Backlog เกินสามอย่างต่อเนื่อง (โปรดทราบว่าตัวเลขเหล่านี้สามารถกำหนดค่าได้) และกลุ่มการปรับขนาดอัตโนมัติตอบสนองด้วยการหมุนอินสแตนซ์เพิ่มเติมเพื่อล้าง Backlog ได้อย่างมีประสิทธิภาพ ส่งผลให้การลดลงอย่างมีนัยสำคัญ ApproximateBacklogSizePerInstanceช่วยให้สามารถประมวลผลคำขอที่ค้างอยู่ได้เร็วกว่าในช่วงเริ่มต้นมาก

รูปที่ 2 แผนภูมิเส้นที่แสดงการเปลี่ยนแปลงชั่วคราวในตัววัด Amazon CloudWatch
การวิเคราะห์เปรียบเทียบสำหรับตัวเลือกการอนุมาน
การเปรียบเทียบตัวเลือกการอนุมานต่างๆ จะขึ้นอยู่กับกรณีการใช้งานการประมวลผลเสียงทั่วไป การอนุมานแบบเรียลไทม์ให้ความเร็วในการอนุมานที่เร็วที่สุด แต่จำกัดขนาดเพย์โหลดไว้ที่ 6 MB การอนุมานประเภทนี้เหมาะสำหรับระบบคำสั่งเสียง ซึ่งผู้ใช้ควบคุมหรือโต้ตอบกับอุปกรณ์หรือซอฟต์แวร์โดยใช้คำสั่งเสียงหรือคำสั่งเสียง โดยทั่วไปคำสั่งเสียงจะมีขนาดเล็ก และเวลาแฝงในการอนุมานต่ำเป็นสิ่งสำคัญเพื่อให้แน่ใจว่าคำสั่งที่ถอดเสียงสามารถกระตุ้นการดำเนินการตามมาได้ทันที การแปลงเป็นชุดเหมาะอย่างยิ่งสำหรับงานออฟไลน์ตามกำหนดเวลา เมื่อไฟล์เสียงแต่ละไฟล์มีขนาดไม่เกิน 100 MB และไม่มีข้อกำหนดเฉพาะสำหรับเวลาตอบสนองการอนุมานที่รวดเร็ว การอนุมานแบบอะซิงโครนัสอนุญาตให้อัปโหลดได้สูงสุด 1 GB และมีเวลาแฝงในการอนุมานปานกลาง ประเภทการอนุมานนี้เหมาะอย่างยิ่งสำหรับการถอดเสียงภาพยนตร์ ละครโทรทัศน์ และการประชุมที่บันทึกไว้ซึ่งจำเป็นต้องประมวลผลไฟล์เสียงขนาดใหญ่
ตัวเลือกการอนุมานแบบเรียลไทม์และแบบอะซิงโครนัสมีความสามารถในการปรับขนาดอัตโนมัติ ช่วยให้อินสแตนซ์ตำแหน่งข้อมูลเพิ่มหรือลดขนาดโดยอัตโนมัติตามปริมาณคำขอ ในกรณีที่ไม่มีคำขอ การปรับขนาดอัตโนมัติจะลบอินสแตนซ์ที่ไม่จำเป็นออก ซึ่งช่วยให้คุณหลีกเลี่ยงค่าใช้จ่ายที่เกี่ยวข้องกับอินสแตนซ์ที่จัดเตรียมไว้ซึ่งไม่ได้ใช้งานอยู่ อย่างไรก็ตาม สำหรับการอนุมานแบบเรียลไทม์ จะต้องคงอินสแตนซ์ถาวรไว้อย่างน้อยหนึ่งอินสแตนซ์ ซึ่งอาจนำไปสู่ต้นทุนที่สูงขึ้นหากตำแหน่งข้อมูลทำงานอย่างต่อเนื่อง ในทางตรงกันข้าม การอนุมานแบบอะซิงโครนัสทำให้ปริมาณอินสแตนซ์ลดลงเหลือ 0 เมื่อไม่ได้ใช้งาน เมื่อกำหนดค่างานการแปลงเป็นชุด คุณสามารถใช้หลายอินสแตนซ์เพื่อประมวลผลงานและปรับ max_concurrent_transforms เพื่อให้อินสแตนซ์เดียวจัดการคำขอหลายรายการได้ ดังนั้น ตัวเลือกการอนุมานทั้งสามตัวเลือกจึงมีความสามารถในการขยายขนาดที่ดีเยี่ยม
การทำความสะอาด
เมื่อคุณใช้โซลูชันเสร็จแล้ว อย่าลืมลบตำแหน่งข้อมูล SageMaker ออกเพื่อป้องกันค่าใช้จ่ายเพิ่มเติม คุณสามารถใช้โค้ดที่ให้มาเพื่อลบจุดสิ้นสุดการอนุมานแบบเรียลไทม์และแบบอะซิงโครนัสตามลำดับ
สรุป
ในโพสต์นี้ เราได้แสดงให้คุณเห็นว่าการนำโมเดลการเรียนรู้ของเครื่องจักรไปใช้ในการประมวลผลเสียงมีความสำคัญมากขึ้นในอุตสาหกรรมต่างๆ อย่างไร จากตัวอย่างโมเดล Whisper เราได้สาธิตวิธีโฮสต์โมเดล ASR แบบโอเพ่นซอร์สบน Amazon SageMaker โดยใช้วิธี PyTorch หรือ Hugging Face การสำรวจครอบคลุมตัวเลือกการอนุมานต่างๆ บน Amazon SageMaker ซึ่งนำเสนอข้อมูลเชิงลึกในการจัดการข้อมูลเสียงอย่างมีประสิทธิภาพ คาดการณ์ และจัดการต้นทุนอย่างมีประสิทธิภาพ โพสต์นี้มีจุดมุ่งหมายเพื่อให้ความรู้สำหรับนักวิจัย นักพัฒนา และนักวิทยาศาสตร์ข้อมูลที่สนใจใช้ประโยชน์จากโมเดล Whisper สำหรับงานที่เกี่ยวข้องกับเสียง และการตัดสินใจโดยใช้ข้อมูลรอบด้านเกี่ยวกับกลยุทธ์การอนุมาน
สำหรับข้อมูลโดยละเอียดเพิ่มเติมเกี่ยวกับการปรับใช้โมเดลบน SageMaker โปรดดูที่นี้ คู่มือนักพัฒนา. นอกจากนี้ ยังปรับใช้โมเดล Whisper ได้โดยใช้ SageMaker JumpStart สำหรับรายละเอียดเพิ่มเติม กรุณาตรวจสอบที่ โมเดล Whisper สำหรับการรู้จำเสียงอัตโนมัติพร้อมใช้งานแล้วใน Amazon SageMaker JumpStart เสา
อย่าลังเลที่จะตรวจสอบสมุดบันทึกและโค้ดสำหรับโปรเจ็กต์นี้ GitHub และแบ่งปันความคิดเห็นของคุณกับเรา
เกี่ยวกับผู้เขียน
 หยิงโหว, PhDเป็นสถาปนิกต้นแบบการเรียนรู้ของเครื่องที่ AWS ความสนใจหลักของเธอ ได้แก่ Deep Learning โดยมุ่งเน้นไปที่ GenAI, Computer Vision, NLP และการทำนายข้อมูลอนุกรมเวลา ในเวลาว่าง เธอเพลิดเพลินกับการใช้ช่วงเวลาดีๆ กับครอบครัว ดื่มด่ำไปกับนิยาย และเดินป่าในอุทยานแห่งชาติของสหราชอาณาจักร
หยิงโหว, PhDเป็นสถาปนิกต้นแบบการเรียนรู้ของเครื่องที่ AWS ความสนใจหลักของเธอ ได้แก่ Deep Learning โดยมุ่งเน้นไปที่ GenAI, Computer Vision, NLP และการทำนายข้อมูลอนุกรมเวลา ในเวลาว่าง เธอเพลิดเพลินกับการใช้ช่วงเวลาดีๆ กับครอบครัว ดื่มด่ำไปกับนิยาย และเดินป่าในอุทยานแห่งชาติของสหราชอาณาจักร
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- เร่ง
- เข้า
- การเข้าถึง
- ลงชื่อเข้าใช้
- ความถูกต้อง
- ข้าม
- การปฏิบัติ
- อย่างกระตือรือร้น
- เพิ่ม
- เพิ่มเติม
- นอกจากนี้
- ที่อยู่
- ปรับ
- สูง
- AI
- จุดมุ่งหมาย
- ทั้งหมด
- การอนุญาต
- ช่วยให้
- ตาม
- ด้วย
- อเมซอน
- อเมซอน SageMaker
- Amazon Web Services
- an
- การวิเคราะห์
- และ
- อื่น
- ใด
- การใช้งาน
- วิธีการ
- เป็น
- พื้นที่
- แถว
- เทียม
- ปัญญาประดิษฐ์
- AS
- สินทรัพย์
- ผู้ช่วย
- ที่เกี่ยวข้อง
- At
- เสียง
- การประพันธ์
- อัตโนมัติ
- อัตโนมัติ
- ความพร้อมใช้งาน
- ใช้ได้
- หลีกเลี่ยง
- AWS
- ฐาน
- ตาม
- BE
- กลายเป็น
- ด้านล่าง
- ดีกว่า
- ระหว่าง
- อคติ
- BIN
- ทั้งสอง
- เป็นโรคจิต
- แต่
- by
- CAN
- ความสามารถในการ
- สามารถ
- ระมัดระวัง
- กรณี
- การเปลี่ยนแปลง
- แผนภูมิ
- ตรวจสอบ
- Choose
- เลือก
- ชั้น
- ชัดเจน
- รหัส
- อย่างไร
- ความเห็น
- ร่วมกัน
- เปรียบเทียบ
- เปรียบเทียบ
- เสร็จ
- เสร็จสิ้น
- ส่วนประกอบ
- ครอบคลุม
- การคำนวณ
- คอมพิวเตอร์
- วิสัยทัศน์คอมพิวเตอร์
- ความประพฤติ
- การประชุม
- องค์ประกอบ
- การกำหนดค่า
- การกำหนดค่า
- พิจารณา
- เสมอต้นเสมอปลาย
- บรรจุ
- ภาชนะ
- ภาชนะบรรจุ
- อย่างต่อเนื่อง
- ตรงกันข้าม
- ควบคุม
- การแปลง
- แก้ไข
- ตรงกัน
- ราคา
- ค่าใช้จ่าย
- ได้
- ซีพียู
- สร้าง
- การสร้าง
- สำคัญมาก
- ประเพณี
- ข้อมูล
- การตัดสินใจ
- ลดลง
- ลึก
- การเรียนรู้ลึก ๆ
- ค่าเริ่มต้น
- กำหนด
- แสดงให้เห็นถึง
- ปรับใช้
- นำไปใช้
- ปรับใช้
- การใช้งาน
- รายละเอียด
- รายละเอียด
- รายละเอียด
- พัฒนา
- นักพัฒนา
- พัฒนาการ
- เครื่อง
- อุปกรณ์
- ต่าง
- แยก
- Dimension
- โดยตรง
- แสดง
- การดำน้ำ
- หลาย
- นักเทียบท่า
- ไม่
- การทำ
- ลง
- ในระหว่าง
- e
- แต่ละ
- ก่อน
- ระบบนิเวศ
- มีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- ง่ายดาย
- ทั้ง
- อื่น
- เริ่มดำเนินการ
- ให้อำนาจ
- ทำให้สามารถ
- ช่วยให้
- การเปิดใช้งาน
- ห้อมล้อม
- ปลายทาง
- ปลายทาง
- เสริม
- การเสริมสร้าง
- ทำให้มั่นใจ
- เพื่อให้แน่ใจ
- ทั้งหมด
- สิ่งแวดล้อม
- จำเป็น
- การสร้าง
- อีเธอร์ (ETH)
- การตรวจสอบ
- ตัวอย่าง
- เกินกว่า
- เกินกว่าที่กำหนด
- ยอดเยี่ยม
- การทดลอง
- อธิบาย
- การสำรวจ
- สำรวจ
- ใบหน้า
- ล้มเหลว
- เท็จ
- ครอบครัว
- FAST
- เร็วขึ้น
- ที่เร็วที่สุด
- สองสาม
- เนื้อไม่มีมัน
- ไฟล์
- พบ
- ชื่อจริง
- โฟกัส
- โดยมุ่งเน้น
- ดังต่อไปนี้
- สำหรับ
- รูป
- กรอบ
- กรอบ
- ฟรี
- ราคาเริ่มต้นที่
- เต็ม
- GPU
- GPUs
- ยิ่งใหญ่
- บัญชีกลุ่ม
- จัดการ
- การจัดการ
- ฮาร์ดแวร์
- มี
- การได้ยิน
- การช่วยเหลือ
- เธอ
- จุดสูง
- สูงกว่า
- การธุดงค์
- เจ้าภาพ
- โฮสติ้ง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- อย่างไรก็ตาม
- HTML
- ที่ http
- HTTPS
- Hub
- กอดใบหน้า
- i
- ในอุดมคติ
- if
- แสดง
- ภาพ
- ภาพ
- การดำเนินงาน
- การใช้งาน
- นำเข้า
- สำคัญ
- in
- ลึกซึ้ง
- ประกอบด้วย
- รวมถึง
- รวมทั้ง
- รวมเข้าด้วยกัน
- เพิ่ม
- ขึ้น
- เป็นรายบุคคล
- บุคคล
- อุตสาหกรรม
- ข้อมูล
- แจ้ง
- แรกเริ่ม
- ในขั้นต้น
- การเริ่มต้น
- อินพุต
- ปัจจัยการผลิต
- ข้อมูลเชิงลึก
- ติดตั้ง
- ตัวอย่าง
- อินสแตนซ์
- คำแนะนำการใช้
- การบูรณาการ
- Intelligence
- โต้ตอบ
- อยากเรียนรู้
- สนใจ
- อินเตอร์เฟซ
- เข้าไป
- ปัญหา
- IT
- ITS
- การสัมภาษณ์
- งาน
- jpg
- คีย์
- ความรู้
- ที่รู้จักกัน
- ภูมิประเทศ
- ที่มีขนาดใหญ่
- ในที่สุด
- ความแอบแฝง
- ต่อมา
- ล่าสุด
- ชั้น
- นำ
- การเรียนรู้
- น้อยที่สุด
- การใช้ประโยชน์
- License
- การ จำกัด
- ถูก จำกัด
- Line
- รายการ
- โหลด
- โหลด
- ในประเทศ
- ที่ตั้ง
- นาน
- อีกต่อไป
- ต่ำ
- เครื่อง
- เรียนรู้เครื่อง
- ทำ
- หลัก
- ทำ
- ทำให้
- การทำ
- จัดการ
- การจัดการ
- แผนที่
- อาจ..
- กล่าวถึง
- เมตาดาต้า
- วิธี
- วิธีการ
- ตัวชี้วัด
- อาจ
- มิลลิวินาที
- นาที
- เอ็มไอที
- ML
- แบบ
- โมเดล
- ปานกลาง
- Moments
- การตรวจสอบ
- ข้อมูลเพิ่มเติม
- Movies
- มาก
- หลาย
- ต้อง
- ที่มีชื่อ
- แห่งชาติ
- อุทยานแห่งชาติ
- จำเป็น
- จำเป็นต้อง
- จำเป็น
- เครือข่าย
- ประสาท
- เครือข่ายประสาท
- ถัดไป
- NLP
- ไม่
- หมายเหตุ
- สมุดบันทึก
- หมายเหตุ / รายละเอียดเพิ่มเติม
- การประกาศ
- การแจ้งเตือน
- สังเกต
- ตอนนี้
- จำนวน
- ตัวเลข
- วัตถุ
- วัตถุ
- สังเกต
- of
- เสนอ
- การเสนอ
- เสนอ
- เป็นทางการ
- ออฟไลน์
- on
- ครั้งเดียว
- ONE
- เพียง
- โอเพนซอร์ส
- ดำเนินการ
- ตัวเลือกเสริม (Option)
- Options
- or
- ใบสั่ง
- องค์กร
- OS
- อื่นๆ
- มิฉะนั้น
- ออก
- ภาพรวม
- แพ็คเกจ
- แพคเกจ
- พารามิเตอร์
- พารามิเตอร์
- สวนสาธารณะ
- ส่ง
- เส้นทาง
- ดำเนินการ
- การปฏิบัติ
- ระยะ
- ท่อ
- เป็นจุดสำคัญ
- วางไว้
- เวที
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- กรุณา
- จุด
- เป็นไปได้
- โพสต์
- ที่มีศักยภาพ
- คำทำนาย
- การคาดการณ์
- ป้องกัน
- ก่อน
- ประถม
- กระบวนการ
- การประมวลผล
- การประมวลผล
- หน่วยประมวลผล
- โครงการ
- อย่างถูกต้อง
- การสร้างต้นแบบ
- ให้
- ให้
- ให้
- การให้
- หลาม
- ไฟฉาย
- คุณภาพ
- พิสัย
- เรียลไทม์
- ดินแดน
- การรับรู้
- แนะนำ
- บันทึก
- ลดลง
- อ้างอิง
- ไม่คำนึงถึง
- ที่เกี่ยวข้อง
- สัมพันธ์
- จำ
- เอาออก
- ลบ
- กรุ
- ขอ
- การร้องขอ
- ต้องการ
- จำเป็นต้องใช้
- ความต้องการ
- นักวิจัย
- ตามลำดับ
- คำตอบ
- การตอบสนอง
- รับผิดชอบ
- ผล
- ส่งผลให้
- ผลสอบ
- เก็บไว้
- การอบรมขึ้นใหม่
- กลับ
- sagemaker
- เดียวกัน
- ลด
- ที่บันทึกไว้
- ประหยัด
- scalability
- ขนาด
- ตาชั่ง
- ที่กำหนดไว้
- นักวิทยาศาสตร์
- ต้นฉบับ
- สคริปต์
- ที่สอง
- วินาที
- Section
- กลุ่ม
- เลือก
- เลือก
- การเลือก
- ชุด
- บริการ
- บริการ
- ชุด
- การตั้งค่า
- การตั้งค่า
- Share
- เธอ
- น่า
- แสดงให้เห็นว่า
- แสดงให้เห็นว่า
- การปิด
- สำคัญ
- ง่าย
- ช่วยลดความยุ่งยาก
- ขนาด
- ขนาด
- เล็ก
- มีขนาดเล็กกว่า
- So
- ซอฟต์แวร์
- ทางออก
- โดยเฉพาะ
- เฉพาะ
- ที่ระบุไว้
- การพูด
- การรู้จำเสียง
- ความเร็ว
- การใช้จ่าย
- พูด
- เริ่มต้น
- สถานะ
- รัฐของศิลปะ
- ขั้นตอน
- ขั้นตอน
- การเก็บรักษา
- กลยุทธ์
- ภายหลัง
- ที่ประสบความสำเร็จ
- อย่างเช่น
- ฉับพลัน
- เหมาะสม
- สนับสนุน
- ที่สนับสนุน
- รองรับ
- แน่ใจ
- พรั่ง
- ระบบ
- ตาราง
- เอา
- การ
- งาน
- งาน
- เทคโนโลยี
- กว่า
- ที่
- พื้นที่
- สหราชอาณาจักร
- ของพวกเขา
- พวกเขา
- แล้วก็
- ที่นั่น
- ดังนั้น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- สาม
- เวลา
- อนุกรมเวลา
- ครั้ง
- ไปยัง
- เครื่องมือ
- ไฟฉาย
- การจราจร
- รถไฟ
- ผ่านการฝึกอบรม
- แปลง
- หม้อแปลงไฟฟ้า
- หม้อแปลง
- เรียก
- ทริกเกอร์
- tv
- ทีวีซีรีส์
- สอง
- ชนิด
- เป็นปกติ
- Uk
- ภายใต้
- ปลดล็อค
- เมื่อ
- us
- ใช้
- มือสอง
- ที่ใช้งานง่าย
- ผู้ใช้
- การใช้
- ประโยชน์
- นำไปใช้
- การใช้ประโยชน์
- มีคุณค่า
- ความคุ้มค่า
- ตัวแปร
- ต่างๆ
- กว้างใหญ่
- รุ่น
- วิสัยทัศน์
- เสียงพูด
- คำสั่งเสียง
- ปริมาณ
- รอ
- ต้องการ
- คือ
- we
- เว็บ
- บริการเว็บ
- ดี
- คือ
- เมื่อ
- เมื่อไรก็ตาม
- ที่
- กระซิบ
- กว้าง
- ช่วงกว้าง
- กับ
- ภายใน
- เวิร์กโฟลว์
- โรงงาน
- คุ้มค่า
- การเขียน
- เธอ
- ของคุณ
- ลมทะเล