โปรเจ็กต์แมชชีนเลิร์นนิงประสบความสำเร็จในการใช้งานบ่อยเพียงใด ไม่ค่อยเพียงพอ มี มากมาย of อุตสาหกรรม การวิจัย การแสดง โปรเจ็กต์ ML มักล้มเหลวในการให้ผลตอบแทน แต่มีเพียงไม่กี่คนที่มีค่าที่ประเมินอัตราส่วนของความล้มเหลวต่อความสำเร็จจากมุมมองของนักวิทยาศาสตร์ข้อมูล ซึ่งเป็นผู้ที่พัฒนาแบบจำลองเดียวกับที่โปรเจ็กต์เหล่านี้ตั้งใจจะปรับใช้
ติดตาม การสำรวจนักวิทยาศาสตร์ข้อมูล ที่ผมแสดงกับ KDnuggets เมื่อปีที่แล้ว การสำรวจวิทยาศาสตร์ข้อมูลชั้นนำของอุตสาหกรรมในปีนี้ ดำเนินการโดยที่ปรึกษา ML Rexer Analytics ตอบคำถามนี้ ส่วนหนึ่งเป็นเพราะ Karl Rexer ผู้ก่อตั้งและประธานบริษัท อนุญาตให้คุณมีส่วนร่วมอย่างแท้จริง โดยผลักดันให้เกิดการรวมคำถามเกี่ยวกับความสำเร็จในการปรับใช้ (ส่วนหนึ่งของงานของฉันในช่วงตำแหน่งศาสตราจารย์ด้านการวิเคราะห์หนึ่งปีที่ฉันดำรงตำแหน่ง ที่รังสี UVA Darden)
ข่าวไม่ค่อยดีนัก นักวิทยาศาสตร์ข้อมูลเพียง 22% เท่านั้นที่กล่าวว่าความคิดริเริ่ม "ปฏิวัติ" ซึ่งเป็นแบบจำลองที่พัฒนาขึ้นเพื่อรองรับกระบวนการหรือความสามารถใหม่ - มักจะนำไปใช้งาน 43% กล่าวว่า 80% ขึ้นไปล้มเหลวในการปรับใช้
ข้าม ทั้งหมด ประเภทของโปรเจ็กต์ ML รวมถึงโมเดลที่รีเฟรชสำหรับการปรับใช้ที่มีอยู่ มีเพียง 32% เท่านั้นที่บอกว่าโมเดลของพวกเขามักจะปรับใช้
ต่อไปนี้เป็นผลลัพธ์โดยละเอียดของส่วนนั้นของการสำรวจ ตามที่ Rexer Analytics นำเสนอ โดยแจกแจงอัตราการปรับใช้ในโครงการริเริ่ม ML สามประเภท:
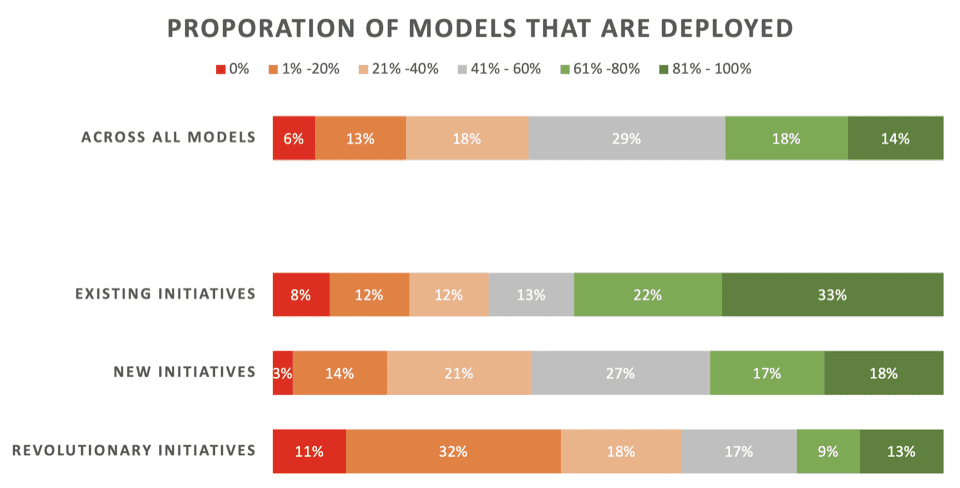
คีย์:
- โครงการริเริ่มที่มีอยู่: โมเดลที่พัฒนาขึ้นเพื่ออัปเดต/รีเฟรชโมเดลที่มีอยู่ซึ่งปรับใช้สำเร็จแล้ว
- ความคิดริเริ่มใหม่: โมเดลที่พัฒนาขึ้นเพื่อปรับปรุงกระบวนการที่มีอยู่ซึ่งยังไม่มีโมเดลใดถูกนำไปใช้งานอยู่แล้ว
- ความคิดริเริ่มในการปฏิวัติ: แบบจำลองที่พัฒนาขึ้นเพื่อรองรับกระบวนการหรือความสามารถใหม่
ในมุมมองของฉัน การต่อสู้เพื่อปรับใช้นี้เกิดจากปัจจัยหลักสองประการ ได้แก่ การวางแผนเฉพาะถิ่นภายใต้การวางแผน และผู้มีส่วนได้ส่วนเสียทางธุรกิจขาดการมองเห็นที่เป็นรูปธรรม ผู้เชี่ยวชาญด้านข้อมูลและผู้นำทางธุรกิจจำนวนมากไม่ทราบว่าการดำเนินการตามเจตนาของ ML ต้องมีการวางแผนอย่างละเอียดและดำเนินการอย่างจริงจังตั้งแต่เริ่มโครงการ ML ทุกรายการ
อันที่จริง ฉันได้เขียนหนังสือเล่มใหม่เกี่ยวกับเรื่องนั้น: คู่มือ AI: การเรียนรู้ศิลปะที่หายากของการปรับใช้การเรียนรู้ของเครื่อง. ในหนังสือเล่มนี้ ฉันแนะนำแนวทางปฏิบัติหกขั้นตอนที่มุ่งเน้นการปรับใช้สำหรับการนำโปรเจ็กต์แมชชีนเลิร์นนิงตั้งแต่แนวคิดไปจนถึงการปรับใช้งานที่ฉันเรียกว่า บิซเอ็มแอล (สั่งจองปกแข็งหรือ e-book ล่วงหน้าและ รับสำเนาหนังสือเสียงเวอร์ชันขั้นสูงฟรี ทันที)
ผู้มีส่วนได้ส่วนเสียหลักของโครงการ ML ซึ่งเป็นบุคคลที่รับผิดชอบด้านประสิทธิภาพในการดำเนินงานที่มุ่งเป้าไปที่การปรับปรุง เช่น ผู้จัดการสายงานธุรกิจ ต้องการความชัดเจนว่า ML จะปรับปรุงการดำเนินงานของพวกเขาอย่างไร และคาดว่าจะส่งมอบมูลค่าเท่าใดจากการปรับปรุง พวกเขาต้องการสิ่งนี้เพื่อให้ไฟเขียวแก่การปรับใช้แบบจำลองในท้ายที่สุด รวมถึงชั่งน้ำหนักการดำเนินการของโครงการตลอดขั้นตอนก่อนการปรับใช้ก่อนหน้านั้น
แต่ประสิทธิภาพของ ML มักไม่ได้วัดกัน! เมื่อแบบสำรวจ Rexer ถามว่า “บริษัท/องค์กรของคุณวัดประสิทธิภาพของโครงการวิเคราะห์บ่อยแค่ไหน” นักวิทยาศาสตร์ข้อมูลเพียง 48% เท่านั้นที่กล่าวว่า "เสมอ" หรือ "เกือบตลอดเวลา" มันค่อนข้างดุร้าย มันควรจะมากกว่า 99% หรือ 100%
และเมื่อมีการวัดประสิทธิภาพ ก็เป็นตัวชี้วัดทางเทคนิคที่เป็นความลับและส่วนใหญ่ไม่เกี่ยวข้องกับผู้มีส่วนได้ส่วนเสียทางธุรกิจ นักวิทยาศาสตร์ด้านข้อมูลรู้ดีกว่า แต่โดยทั่วไปแล้วจะไม่ปฏิบัติตาม ส่วนหนึ่งเนื่องจากโดยทั่วไปแล้วเครื่องมือ ML จะให้บริการเฉพาะตัวชี้วัดทางเทคนิคเท่านั้น จากการสำรวจ นักวิทยาศาสตร์ข้อมูลจัดอันดับ KPI ของธุรกิจ เช่น ROI และรายได้เป็นเมตริกที่สำคัญที่สุด แต่กลับแสดงรายการเมตริกทางเทคนิค เช่น การเพิ่มและ AUC เป็นเมตริกที่ใช้วัดบ่อยที่สุด
ตัวชี้วัดประสิทธิภาพทางเทคนิคนั้น “โดยพื้นฐานแล้วไร้ประโยชน์และถูกตัดขาดจากผู้มีส่วนได้ส่วนเสียทางธุรกิจ” ตามที่ระบุไว้ ทบทวนวิทยาศาสตร์ข้อมูลของฮาร์วาร์ด. นี่คือเหตุผล: พวกเขาบอกคุณเท่านั้น ญาติ ประสิทธิภาพของแบบจำลอง เช่น การเปรียบเทียบกับการคาดเดาหรือข้อมูลพื้นฐานอื่นๆ ตัวชี้วัดทางธุรกิจบอกคุณว่า แน่นอน มูลค่าทางธุรกิจที่โมเดลคาดว่าจะส่งมอบ หรือเมื่อประเมินหลังจากการปรับใช้ โมเดลดังกล่าวได้พิสูจน์แล้วว่าสามารถส่งมอบได้ ตัววัดดังกล่าวจำเป็นสำหรับโปรเจ็กต์ ML ที่เน้นการปรับใช้
นอกเหนือจากการเข้าถึงตัวชี้วัดทางธุรกิจแล้ว ผู้มีส่วนได้ส่วนเสียทางธุรกิจยังต้องเพิ่มขึ้นอีกด้วย เมื่อแบบสำรวจ Rexer ถามว่า “โดยทั่วไปแล้วผู้จัดการและผู้มีอำนาจตัดสินใจในองค์กรของคุณที่ต้องอนุมัติการปรับใช้แบบจำลองมีความรู้เพียงพอที่จะทำการตัดสินใจในลักษณะที่มีข้อมูลครบถ้วนหรือไม่” มีเพียง 49% ของผู้ตอบแบบสอบถามตอบว่า "เกือบตลอดเวลา" หรือ "เสมอ"
นี่คือสิ่งที่ฉันเชื่อว่ากำลังเกิดขึ้น “ลูกค้า” ของนักวิทยาศาสตร์ข้อมูล ซึ่งเป็นผู้มีส่วนได้ส่วนเสียทางธุรกิจ มักจะรู้สึกไม่สบายใจเมื่อต้องอนุมัติการใช้งาน เพราะมันหมายถึงการเปลี่ยนแปลงการดำเนินงานที่สำคัญกับ bread and Butter ของบริษัท ซึ่งเป็นกระบวนการขนาดใหญ่ที่สุด พวกเขาไม่มีกรอบบริบท ตัวอย่างเช่น พวกเขาสงสัยว่า "ฉันจะเข้าใจได้อย่างไรว่าโมเดลนี้ซึ่งทำงานได้สมบูรณ์แบบและขี้อายจากลูกบอลคริสตัลจะช่วยได้จริงขนาดไหน" โครงการจึงล้มตาย จากนั้น การใส่ "ข้อมูลเชิงลึกที่ได้รับ" เชิงบวกอย่างสร้างสรรค์จะช่วยกวาดความล้มเหลวไว้ใต้พรมอย่างเรียบร้อย การโฆษณาชวนเชื่อของ AI ยังคงไม่บุบสลาย แม้ว่ามูลค่าที่เป็นไปได้และวัตถุประสงค์ของโครงการจะสูญหายไป
ในหัวข้อนี้ – การเพิ่มผู้มีส่วนได้ส่วนเสีย – ฉันจะเสียบหนังสือเล่มใหม่ของฉัน คู่มือการเล่น AIอีกครั้งหนึ่ง แม้จะครอบคลุมแนวทางปฏิบัติของ bizML แล้ว หนังสือเล่มนี้ยังยกระดับทักษะของนักธุรกิจโดยมอบความรู้พื้นฐานกึ่งเทคนิคที่สำคัญแต่เป็นมิตร ซึ่งผู้มีส่วนได้ส่วนเสียทุกคนจำเป็นต้องมีเพื่อเป็นผู้นำหรือมีส่วนร่วมในโครงการการเรียนรู้ของเครื่องตั้งแต่ต้นจนจบ สิ่งนี้ทำให้ผู้เชี่ยวชาญด้านธุรกิจและข้อมูลอยู่ในหน้าเดียวกันเพื่อให้สามารถทำงานร่วมกันอย่างลึกซึ้งและร่วมกันจัดตั้งได้อย่างแม่นยำ แมชชีนเลิร์นนิงใช้อะไรในการทำนาย คาดการณ์ได้ดีแค่ไหน และคาดการณ์อย่างไรเพื่อปรับปรุงการดำเนินงาน. ข้อมูลสำคัญเหล่านี้สร้างหรือทำลายความคิดริเริ่มแต่ละข้อ การทำให้ถูกต้องจะปูทางไปสู่การใช้งานที่ขับเคลื่อนด้วยคุณค่าของแมชชีนเลิร์นนิง
พูดได้อย่างปลอดภัยว่าสถานการณ์ภายนอกนั้นยากลำบาก โดยเฉพาะอย่างยิ่งสำหรับโครงการริเริ่ม ML ใหม่ๆ ที่เพิ่งลองใช้ครั้งแรก ในขณะที่พลังที่แท้จริงของ AI สูญเสียความสามารถในการชดเชยอย่างต่อเนื่อง
มูลค่าที่รับรู้น้อยกว่าที่สัญญาไว้ จะมีแรงกดดันมากขึ้นเรื่อยๆ ในการพิสูจน์มูลค่าการดำเนินงานของ ML? ดังนั้นผมขอบอกว่า ก้าวไปข้างหน้าซะตอนนี้ เริ่มปลูกฝังวัฒนธรรมที่มีประสิทธิภาพมากขึ้นในการทำงานร่วมกันข้ามองค์กรและความเป็นผู้นำโครงการที่มุ่งเน้นการปรับใช้!
หากต้องการทราบผลลัพธ์โดยละเอียดเพิ่มเติมจาก แบบสำรวจวิทยาศาสตร์ข้อมูล Rexer Analytics ปี 2023คลิก โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม. นี่คือการสำรวจที่ใหญ่ที่สุดของผู้เชี่ยวชาญด้านวิทยาศาสตร์ข้อมูลและการวิเคราะห์ในอุตสาหกรรม ประกอบด้วยคำถามแบบเลือกตอบและปลายเปิดประมาณ 35 ข้อ ซึ่งครอบคลุมมากกว่าอัตราความสำเร็จในการปรับใช้เท่านั้น – เจ็ดประเด็นทั่วไปของวิทยาศาสตร์และการปฏิบัติในการทำเหมืองข้อมูล: (1) ภาคสนามและเป้าหมาย (2) อัลกอริทึม (3) โมเดล ( 4) เครื่องมือ (ชุดซอฟต์แวร์ที่ใช้) (5) เทคโนโลยี (6) ความท้าทาย และ (7) อนาคต ดำเนินการเป็นบริการ (ไม่มีการสนับสนุนจากองค์กร) ให้กับชุมชนวิทยาศาสตร์ข้อมูล และโดยปกติจะประกาศผลที่ การประชุมสัปดาห์การเรียนรู้ของเครื่อง และแบ่งปันผ่านรายงานสรุปที่มีให้อย่างเสรี
บทความนี้เป็นผลจากผลงานของผู้เขียนในขณะที่เขาดำรงตำแหน่งหนึ่งปีในตำแหน่งศาสตราจารย์ Bodily Bicentennial สาขา Analytics ที่ UVA Darden School of Business ซึ่งท้ายที่สุดก็ปิดท้ายด้วยการตีพิมพ์ของ คู่มือ AI: การเรียนรู้ศิลปะที่หายากของการปรับใช้การเรียนรู้ของเครื่อง (ข้อเสนอหนังสือเสียงฟรี).
เอริค ซีเกลPh.D. เป็นที่ปรึกษาชั้นนำและอดีตศาสตราจารย์มหาวิทยาลัยโคลัมเบียที่ทำให้การเรียนรู้ของเครื่องเป็นที่เข้าใจและน่าดึงดูด เขาเป็นผู้ก่อตั้ง โลกแห่งการวิเคราะห์เชิงทำนาย และ โลกการเรียนรู้ลึก ชุดการประชุมซึ่งให้บริการผู้เข้าร่วมมากกว่า 17,000 คนตั้งแต่ปี 2009 ผู้สอนหลักสูตรที่ได้รับการยกย่อง ความเป็นผู้นำและการปฏิบัติของแมชชีนเลิร์นนิง – การเรียนรู้แบบครบวงจรซึ่งเป็นวิทยากรชื่อดังที่ได้รับมอบหมายให้ คำปราศรัยสำคัญกว่า 100 รายการและบรรณาธิการบริหารของ ไทม์แมชชีนเลิร์นนิง. เขาประพันธ์หนังสือขายดี การวิเคราะห์เชิงทำนาย: พลังในการทำนายว่าใครจะคลิก ซื้อ โกหก หรือตายซึ่งใช้ในหลักสูตรของมหาวิทยาลัยมากกว่า 35 แห่ง และเขาได้รับรางวัลการสอนเมื่อครั้งเป็นอาจารย์ที่มหาวิทยาลัยโคลัมเบียซึ่งเขาร้องเพลง เพลงการศึกษา ให้กับนักเรียนของเขา เอริคยังตีพิมพ์ ความเห็นเกี่ยวกับการวิเคราะห์และความยุติธรรมทางสังคม. ติดตามเขาได้ที่ @ทำนายวิเคราะห์.
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/survey-machine-learning-projects-still-routinely-fail-to-deploy?utm_source=rss&utm_medium=rss&utm_campaign=survey-machine-learning-projects-still-routinely-fail-to-deploy
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 000
- 1
- 17
- 35%
- 7
- a
- ความสามารถ
- เกี่ยวกับเรา
- เข้า
- ที่ได้รับรางวัล
- ตาม
- ข้าม
- จริง
- จ่าหน้า
- สูง
- หลังจาก
- อุกอาจ
- ก่อน
- AI
- อัลกอริทึม
- ทั้งหมด
- อนุญาตให้
- แล้ว
- ด้วย
- เสมอ
- am
- an
- วิเคราะห์
- การวิเคราะห์
- และ
- ประกาศ
- อื่น
- อนุมัติ
- ประมาณ
- Arcane
- เป็น
- พื้นที่
- ศิลปะ
- บทความ
- AS
- At
- ผู้เข้าร่วมประชุม
- au
- ประพันธ์
- ใช้ได้
- ได้รับรางวัล
- ไป
- พื้นหลัง
- baseline
- BE
- เพราะ
- รับ
- ก่อน
- เชื่อ
- ขายดีที่สุด
- ดีกว่า
- หนังสือ
- ขนมปัง
- ทำลาย
- หมดสภาพ
- ธุรกิจ
- ผู้นำทางธุรกิจ
- แต่
- ซื้อ
- by
- โทรศัพท์
- ที่เรียกว่า
- CAN
- ความสามารถ
- น่ารัก
- ความท้าทาย
- เปลี่ยนแปลง
- รับผิดชอบ
- ทางเลือก
- คลิก
- ไคลเอนต์
- ผู้สมัครที่ไม่รู้จัก
- ร่วมมือ
- การทำงานร่วมกัน
- โคลัมเบีย
- COM
- อย่างไร
- มา
- อย่างธรรมดา
- ชุมชน
- บริษัท
- บริษัท
- ความคิด
- คอนกรีต
- ดำเนินการ
- การประชุม
- ประกอบ
- การให้คำปรึกษา
- ผู้ให้คำปรึกษา
- ตามบริบท
- เรื่อย
- การบริจาค
- ไทม์ไลน์การ
- หลักสูตร
- หลักสูตร
- หน้าปก
- ครอบคลุม
- อย่างสร้างสรรค์
- cs
- วัฒนธรรม
- ข้อมูล
- การทำเหมืองข้อมูล
- วิทยาศาสตร์ข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- ผู้มีอำนาจตัดสินใจ
- การตัดสินใจ
- ลึก
- ส่งมอบ
- การส่งมอบ
- ปรับใช้
- นำไปใช้
- การใช้งาน
- การใช้งาน
- รายละเอียด
- รายละเอียด
- พัฒนา
- พัฒนา
- ตัดการเชื่อมต่อ
- do
- ทำ
- สวม
- Dont
- ปริมาณ
- ลง
- การขับขี่
- ในระหว่าง
- แต่ละ
- บรรณาธิการ
- มีประสิทธิภาพ
- ประสิทธิผล
- ทำให้สามารถ
- ปลาย
- จบสิ้น
- เฉพาะถิ่น
- เสริม
- พอ
- เอริค
- โดยเฉพาะอย่างยิ่ง
- จำเป็น
- Essentials
- การสร้าง
- อีเธอร์ (ETH)
- การประเมินการ
- แม้
- ทุกๆ
- ตัวอย่าง
- การปฏิบัติ
- ผู้บริหารงาน
- ที่มีอยู่
- ที่คาดหวัง
- ความจริง
- ปัจจัย
- ล้มเหลว
- ความล้มเหลว
- ไกล
- ฟุต
- สองสาม
- สนาม
- ปฏิบัติตาม
- สำหรับ
- บังคับ
- อดีต
- ผู้สร้าง
- กรอบ
- ฟรี
- อิสระ
- เป็นมิตร
- ราคาเริ่มต้นที่
- อนาคต
- ที่ได้รับ
- General
- โดยทั่วไป
- ได้รับ
- ได้รับ
- เป้าหมาย
- ยิ่งใหญ่
- สิ่งที่เกิดขึ้น
- มี
- he
- จัดขึ้น
- ช่วย
- พระองค์
- ของเขา
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- HTML
- ที่ http
- HTTPS
- hype
- i
- ไอบีเอ็ม
- สำคัญ
- ปรับปรุง
- การปรับปรุง
- in
- การเริ่ม
- รวมทั้ง
- รวม
- อุตสาหกรรม
- ชั้นนำของอุตสาหกรรม
- Initiative
- ความคิดริเริ่ม
- ข้อมูลเชิงลึก
- ตั้งใจว่า
- เข้าไป
- แนะนำ
- ISN
- IT
- ITS
- เพียงแค่
- แค่หนึ่ง
- คาร์ล
- KD นักเก็ต
- คีย์
- ประเด็นสำคัญ
- ชนิด
- ทราบ
- ความรู้
- ขาดแคลน
- ใหญ่ที่สุด
- ชื่อสกุล
- ปีที่แล้ว
- นำ
- ผู้นำ
- ความเป็นผู้นำ
- ชั้นนำ
- การเรียนรู้
- โกหก
- กดไลก์
- รายการ
- ll
- สูญเสีย
- สูญหาย
- เครื่อง
- เรียนรู้เครื่อง
- หลัก
- ทำ
- ทำให้
- การทำ
- ผู้จัดการ
- ผู้จัดการ
- ลักษณะ
- หลาย
- Mastering
- หมายความ
- หมายความว่า
- วัด
- วัด
- ตัวชี้วัด
- การทำเหมืองแร่
- เอ็มไอที
- ML
- แบบ
- โมเดล
- ข้อมูลเพิ่มเติม
- มากที่สุด
- ส่วนใหญ่
- มาก
- หลาย
- ต้อง
- my
- จำเป็นต้อง
- ความต้องการ
- ใหม่
- ข่าว
- ไม่
- ตอนนี้
- of
- มักจะ
- on
- ONE
- คน
- เพียง
- การดำเนินงาน
- การดำเนินการ
- or
- ใบสั่ง
- organizacja
- ออก
- แพคเกจ
- หน้า
- ส่วนหนึ่ง
- มีส่วนร่วม
- ปู
- รูปแบบไฟล์ PDF
- ความสมบูรณ์
- การปฏิบัติ
- ดำเนินการ
- คน
- มุมมอง
- การวางแผน
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- ปลั๊ก
- ยอดนิยม
- ตำแหน่ง
- บวก
- ที่มีศักยภาพ
- อำนาจ
- การปฏิบัติ
- สั่งซื้อล่วงหน้า
- ล้ำค่า
- อย่างแม่นยำ
- คาดการณ์
- การคาดการณ์
- คาดการณ์
- นำเสนอ
- ประธาน
- ความดัน
- สวย
- กระบวนการ
- กระบวนการ
- ผลิตภัณฑ์
- มืออาชีพ
- ศาสตราจารย์
- โครงการ
- โครงการ
- สัญญา
- พิสูจน์
- ที่พิสูจน์แล้ว
- สิ่งพิมพ์
- เผยแพร่
- วัตถุประสงค์
- ทำให้
- วาง
- คำถาม
- คำถาม
- ทางลาด
- กระโจน
- อันดับ
- หายาก
- ราคา
- อัตราส่วน
- มาถึง
- ตระหนัก
- รับรู้
- ซากศพ
- รายงาน
- ผู้ตอบแบบสอบถาม
- ผลสอบ
- รับคืน
- รายได้
- การปฏิวัติ
- ขวา
- เต็มไปด้วยหิน
- ผลตอบแทนการลงทุน
- จำเจ
- วิ่ง
- s
- ปลอดภัย
- กล่าวว่า
- เดียวกัน
- กล่าว
- ขนาด
- โรงเรียน
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- นักวิทยาศาสตร์
- ชุด
- ให้บริการ
- ให้บริการ
- ให้บริการอาหาร
- บริการ
- เจ็ด
- ที่ใช้ร่วมกัน
- สำคัญ
- ตั้งแต่
- So
- สังคม
- ซอฟต์แวร์
- บาง
- ลำโพง
- สปิน
- การประกัน
- ขั้นตอน
- ผู้ถือเงินเดิมพัน
- ผู้มีส่วนได้เสีย
- เริ่มต้น
- ลำต้น
- ยังคง
- การต่อสู้
- นักเรียน
- ความสำเร็จ
- ที่ประสบความสำเร็จ
- ประสบความสำเร็จ
- อย่างเช่น
- สรุป
- การสำรวจ
- กวาด
- T
- เป้าหมาย
- การเรียนการสอน
- วิชาการ
- เทคโนโลยี
- บอก
- เงื่อนไขการใช้บริการ
- กว่า
- ที่
- พื้นที่
- ของพวกเขา
- พวกเขา
- แล้วก็
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- สาม
- ตลอด
- ดังนั้น
- เวลา
- ไปยัง
- เครื่องมือ
- หัวข้อ
- อย่างแท้จริง
- สอง
- ในที่สุด
- ภายใต้
- เข้าใจ
- เข้าใจได้
- มหาวิทยาลัย
- มหาวิทยาลัย
- เมื่อ
- มือสอง
- นำ
- มักจะ
- ความคุ้มค่า
- Ve
- มาก
- ผ่านทาง
- รายละเอียด
- ความชัดเจน
- จำเป็น
- คือ
- ทาง..
- สัปดาห์
- ชั่งน้ำหนัก
- ดี
- อะไร
- เมื่อ
- ที่
- ในขณะที่
- WHO
- ทำไม
- ป่า
- จะ
- กับ
- ไม่มี
- วอน
- แปลกใจ
- งาน
- จะ
- เขียน
- ปี
- ยัง
- เธอ
- ของคุณ
- ลมทะเล








