นี่เป็นโพสต์รับเชิญที่เขียนโดย Taylor Names, Staff Machine Learning Engineer, Dev Gupta, Machine Learning Manager และ Argie Angeleas ผู้จัดการผลิตภัณฑ์อาวุโสของ Ibotta Ibotta เป็นบริษัทเทคโนโลยีของอเมริกาที่อนุญาตให้ผู้ใช้แอปเดสก์ท็อปและมือถือได้รับเงินคืนในร้านค้า แอพมือถือ และการซื้อออนไลน์ด้วยการส่งใบเสร็จรับเงิน บัญชีความภักดีของผู้ค้าปลีกที่เชื่อมโยง การชำระเงิน และการตรวจสอบการซื้อ
Ibotta มุ่งมั่นที่จะแนะนำโปรโมชั่นส่วนบุคคลเพื่อรักษาและดึงดูดผู้ใช้ให้ดีขึ้น อย่างไรก็ตาม โปรโมชั่นและความชอบของผู้ใช้มีการพัฒนาอย่างต่อเนื่อง สภาพแวดล้อมที่เปลี่ยนแปลงตลอดเวลาที่มีผู้ใช้ใหม่จำนวนมากและการส่งเสริมการขายใหม่เป็นปัญหาทั่วไปในการเริ่มระบบเย็น—ไม่มีการโต้ตอบของผู้ใช้ในอดีตและการส่งเสริมการขายที่เพียงพอต่อการอนุมานใดๆ Reinforcement Learning (RL) เป็นพื้นที่ของการเรียนรู้ของเครื่อง (ML) ที่เกี่ยวข้องกับวิธีที่เจ้าหน้าที่อัจฉริยะควรดำเนินการในสภาพแวดล้อมเพื่อเพิ่มแนวคิดของรางวัลสะสมสูงสุด RL มุ่งเน้นไปที่การค้นหาสมดุลระหว่างการสำรวจดินแดนที่ไม่คุ้นเคยและการใช้ประโยชน์จากความรู้ในปัจจุบัน Multi-armed bandit (MAB) เป็นปัญหาการเรียนรู้การเสริมแรงแบบคลาสสิกที่แสดงให้เห็นถึงการแลกเปลี่ยนการสำรวจ/การแสวงหาผลประโยชน์: การเพิ่มผลตอบแทนสูงสุดในระยะสั้น (การเอารัดเอาเปรียบ) ในขณะที่เสียสละรางวัลระยะสั้นสำหรับความรู้ที่สามารถเพิ่มผลตอบแทนในระยะยาว (การสำรวจ) ). อัลกอริทึม MAB จะสำรวจและใช้ประโยชน์จากคำแนะนำที่เหมาะสมที่สุดสำหรับผู้ใช้
Ibotta ร่วมมือกับ ห้องปฏิบัติการโซลูชันแมชชีนเลิร์นนิงของ Amazon เพื่อใช้อัลกอริทึม MAB เพื่อเพิ่มการมีส่วนร่วมของผู้ใช้เมื่อข้อมูลผู้ใช้และโปรโมชันมีไดนามิกสูง
เราเลือกอัลกอริทึม MAB เชิงบริบท เนื่องจากมีประสิทธิภาพในกรณีการใช้งานต่อไปนี้:
- ให้คำแนะนำส่วนบุคคลตามสภาพของผู้ใช้ (บริบท)
- การรับมือกับปัญหา Cold Start เช่น โบนัสใหม่และลูกค้าใหม่
- รองรับคำแนะนำที่ความชอบของผู้ใช้เปลี่ยนไปตามกาลเวลา
ข้อมูล
เพื่อเพิ่มการแลกโบนัส Ibotta ปรารถนาที่จะส่งโบนัสส่วนบุคคลให้กับลูกค้า โบนัสคือสิ่งจูงใจเงินสดที่หาเองได้ของ Ibotta ซึ่งทำหน้าที่เป็นตัวดำเนินการของแบบจำลองโจรหลายอาวุธตามบริบท
โมเดลโจรใช้คุณสมบัติสองชุด:
- คุณสมบัติการกระทำ – สิ่งเหล่านี้อธิบายการกระทำเช่นประเภทโบนัสและจำนวนเฉลี่ยของโบนัส
- คุณลักษณะของลูกค้า – สิ่งเหล่านี้อธิบายการตั้งค่าและการโต้ตอบในอดีตของลูกค้า เช่น การแลกรับ การคลิก และการดูของสัปดาห์ที่ผ่านมา
คุณลักษณะตามบริบทมาจากการเดินทางของลูกค้าในอดีต ซึ่งมีตัววัดกิจกรรม 26 รายการต่อสัปดาห์ที่สร้างขึ้นจากการโต้ตอบของผู้ใช้กับแอป Ibotta
โจรหลายอาวุธตามบริบท
โจรคือกรอบงานสำหรับการตัดสินใจตามลำดับ โดยที่ผู้มีอำนาจตัดสินใจจะเลือกการกระทำตามลำดับ โดยอาจอิงตามข้อมูลบริบทในปัจจุบัน และสังเกตสัญญาณรางวัล
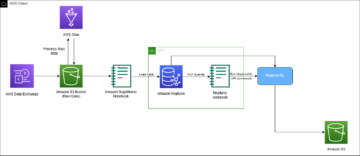
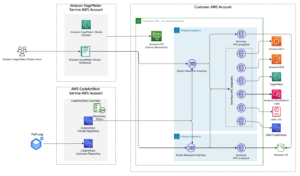
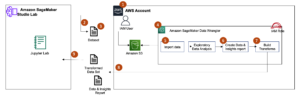
เราตั้งค่าเวิร์กโฟลว์ของโจรติดอาวุธตามบริบทใน อเมซอน SageMaker ใช้ built-in คำสาบาน Wabbit (VW) คอนเทนเนอร์. SageMaker ช่วยนักวิทยาศาสตร์ด้านข้อมูลและนักพัฒนาในการจัดเตรียม สร้าง ฝึกอบรม และปรับใช้โมเดล ML คุณภาพสูงได้อย่างรวดเร็วโดยรวบรวมชุดความสามารถที่หลากหลายซึ่งสร้างขึ้นเพื่อวัตถุประสงค์เฉพาะสำหรับ ML มาไว้ด้วยกัน การฝึกโมเดลและการทดสอบอิงจากการทดลองออฟไลน์ โจรเรียนรู้การตั้งค่าของผู้ใช้ตามความคิดเห็นจากการโต้ตอบที่ผ่านมามากกว่าสภาพแวดล้อมสด อัลกอริธึมสามารถเปลี่ยนเป็นโหมดการผลิตได้ โดยที่ SageMaker ยังคงเป็นโครงสร้างพื้นฐานที่รองรับ
ในการใช้กลยุทธ์การสำรวจ/การแสวงหาผลประโยชน์ เราได้สร้างระบบการฝึกอบรมและการปรับใช้แบบวนซ้ำซึ่งดำเนินการดังต่อไปนี้:
- แนะนำการดำเนินการโดยใช้รูปแบบการโจรกรรมตามบริบทตามบริบทของผู้ใช้
- จับข้อเสนอแนะโดยนัยเมื่อเวลาผ่านไป
- ฝึกฝนโมเดลอย่างต่อเนื่องด้วยข้อมูลการโต้ตอบที่เพิ่มขึ้น
เวิร์กโฟลว์ของแอปพลิเคชันไคลเอนต์มีดังนี้:
- แอปพลิเคชันไคลเอนต์เลือกบริบท ซึ่งถูกส่งไปยังปลายทาง SageMaker เพื่อเรียกการดำเนินการ
- ตำแหน่งข้อมูล SageMaker ส่งคืนการดำเนินการ ความน่าจะเป็นในการแลกโบนัสที่เกี่ยวข้อง และ
event_id. - เนื่องจากตัวจำลองนี้สร้างขึ้นโดยใช้ปฏิสัมพันธ์ทางประวัติศาสตร์ โมเดลจึงรู้คลาสที่แท้จริงสำหรับบริบทนั้น หากตัวแทนเลือกการดำเนินการที่มีการแลกรางวัล รางวัลคือ 1 มิฉะนั้น ตัวแทนจะได้รับรางวัลเป็น 0
กรณีที่มีข้อมูลย้อนหลังและอยู่ในรูปแบบ <state, action, action probability, reward>, Ibotta สามารถ warm start โมเดลสดโดยการเรียนรู้นโยบายออฟไลน์ มิฉะนั้น Ibotta สามารถเริ่มต้นนโยบายแบบสุ่มสำหรับวันที่ 1 และเริ่มเรียนรู้นโยบายเกี่ยวกับโจรจากที่นั่น
ต่อไปนี้เป็นข้อมูลโค้ดสำหรับฝึกโมเดล:
ประสิทธิภาพของโมเดล
เราสุ่มแบ่งการโต้ตอบที่แลกเป็นข้อมูลการฝึกอบรม (การโต้ตอบ 10,000 ครั้ง) และข้อมูลการประเมิน (5,300 การโต้ตอบการระงับ)
เมตริกการประเมินคือรางวัลเฉลี่ย โดยที่ 1 ระบุว่ามีการแลกใช้การดำเนินการที่แนะนำ และ 0 ระบุว่ายังไม่ได้แลกใช้การดำเนินการที่แนะนำ
เราสามารถกำหนดผลตอบแทนเฉลี่ยได้ดังนี้:
รางวัลเฉลี่ย (อัตราการแลก) = (# การกระทำที่แนะนำพร้อมการแลกรางวัล)/(ทั้งหมด # การกระทำที่แนะนำ)
ตารางต่อไปนี้แสดงผลรางวัลเฉลี่ย:
| รางวัลเฉลี่ย | เครื่องแบบสุ่มคำแนะนำ | คำแนะนำตามบริบทของ MAB |
| รถไฟ | 11.44% | 56.44% |
| ทดสอบ | 10.69% | 59.09% |
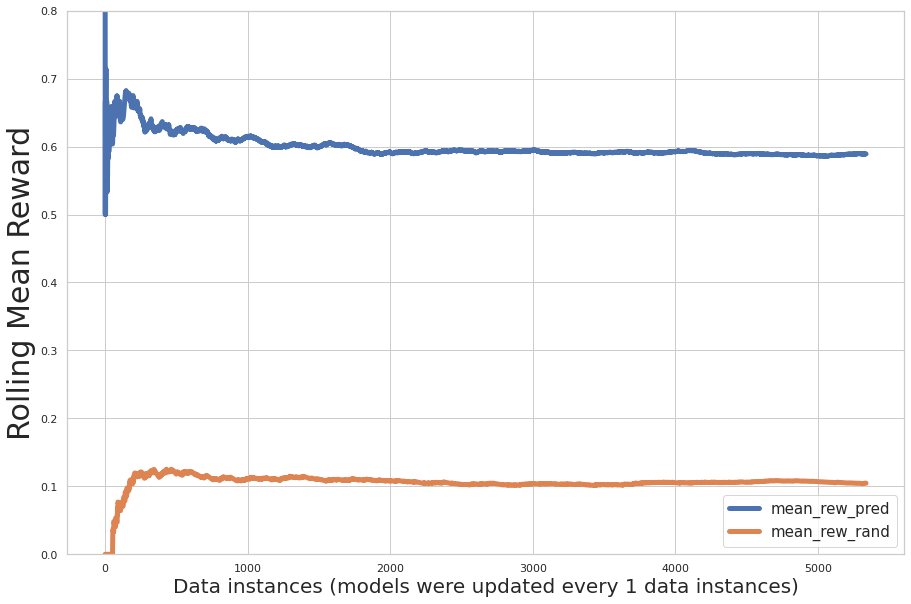
รูปต่อไปนี้แสดงการประเมินประสิทธิภาพที่เพิ่มขึ้นระหว่างการฝึก โดยที่แกน x คือจำนวนระเบียนที่เรียนรู้โดยแบบจำลอง และแกน y คือรางวัลเฉลี่ยส่วนเพิ่ม เส้นสีน้ำเงินหมายถึงกลุ่มโจรติดอาวุธ เส้นสีส้มแสดงถึงคำแนะนำแบบสุ่ม

กราฟแสดงให้เห็นว่าค่าเฉลี่ยของรางวัลที่คาดการณ์ไว้จะเพิ่มขึ้นจากการทำซ้ำ และรางวัลจากการดำเนินการที่คาดการณ์นั้นมีค่ามากกว่าการกำหนดแบบสุ่มของการกระทำอย่างมีนัยสำคัญ
เราสามารถใช้แบบจำลองที่ได้รับการฝึกมาก่อนหน้านี้เป็นการอุ่นเครื่องและฝึกแบบจำลองซ้ำแบบกลุ่มด้วยข้อมูลใหม่ ในกรณีนี้ ประสิทธิภาพของแบบจำลองได้หลอมรวมผ่านการฝึกเบื้องต้นแล้ว ไม่พบการปรับปรุงประสิทธิภาพเพิ่มเติมที่มีนัยสำคัญในการฝึกซ้ำแบบกลุ่มใหม่ ดังแสดงในรูปต่อไปนี้
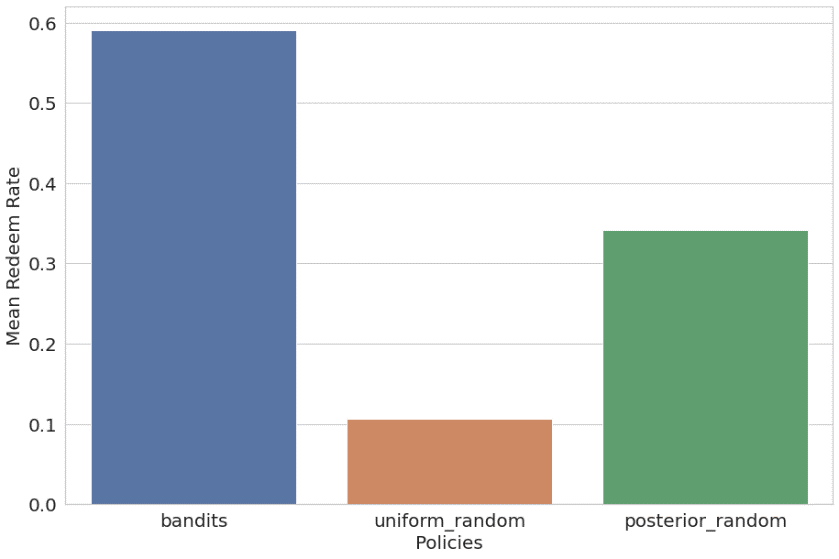
นอกจากนี้เรายังเปรียบเทียบนโยบายการสุ่มตามบริบทกับนโยบายการสุ่มแบบสม่ำเสมอและการสุ่มแบบหลัง ผลลัพธ์ถูกแสดงรายการและวางแผนดังนี้:
- โจร – รางวัลเฉลี่ย 59.09% (การฝึกอบรม 56.44%)
- ชุดสุ่ม – รางวัลเฉลี่ย 10.69% (การฝึกอบรม 11.44%)
- สุ่มความน่าจะเป็นหลัง – รางวัลเฉลี่ย 34.21% (การฝึกอบรม 34.82%)
อัลกอริธึมแบบโจรหลายอาวุธตามบริบทมีประสิทธิภาพเหนือกว่านโยบายอีกสองข้ออย่างมีนัยสำคัญ
สรุป
Amazon ML Solutions Lab ร่วมมือกับ Ibotta เพื่อพัฒนาโซลูชันคำแนะนำการเรียนรู้การเสริมแรงแบบแบนด์ตามบริบทโดยใช้คอนเทนเนอร์ SageMaker RL
โซลูชันนี้แสดงให้เห็นการเพิ่มอัตราการแลกใช้ที่เพิ่มขึ้นอย่างต่อเนื่องตามคำแนะนำแบบสุ่ม (เพิ่มขึ้นห้าเท่า) และ RL ที่ไม่มีบริบท (เพิ่มขึ้นสองเท่า) ตามการทดสอบออฟไลน์ ด้วยโซลูชันนี้ Ibotta สามารถสร้างเครื่องมือแนะนำที่เน้นผู้ใช้เป็นศูนย์กลางแบบไดนามิกเพื่อเพิ่มประสิทธิภาพการมีส่วนร่วมของลูกค้า เมื่อเทียบกับคำแนะนำแบบสุ่ม โซลูชันนี้ปรับปรุงความถูกต้องของคำแนะนำ (รางวัลเฉลี่ย) จาก 11% เป็น 59% ตามการทดสอบออฟไลน์ Ibotta วางแผนที่จะรวมโซลูชันนี้เข้ากับกรณีการใช้งานส่วนบุคคลมากขึ้น
"Amazon ML Solutions Lab ทำงานอย่างใกล้ชิดกับทีม Machine Learning ของ Ibotta เพื่อสร้างเครื่องมือแนะนำโบนัสแบบไดนามิกเพื่อเพิ่มการแลกรางวัลและเพิ่มประสิทธิภาพการมีส่วนร่วมของลูกค้า เราได้สร้างเครื่องมือแนะนำที่ใช้ประโยชน์จากการเรียนรู้แบบเสริมกำลังที่เรียนรู้และปรับให้เข้ากับสถานะของลูกค้าที่เปลี่ยนแปลงตลอดเวลา และเริ่มโบนัสใหม่โดยอัตโนมัติ ภายใน 2 เดือน นักวิทยาศาสตร์ของ ML Solutions Lab ได้พัฒนาโซลูชันการเรียนรู้การเสริมกำลังด้วยโจรหลายอาวุธตามบริบทโดยใช้คอนเทนเนอร์ SageMaker RL โซลูชัน RL ตามบริบทแสดงอัตราการแลกรับที่เพิ่มขึ้นอย่างต่อเนื่อง โดยได้รับอัตราการแลกโบนัสเพิ่มขึ้นห้าเท่าเมื่อเทียบกับคำแนะนำแบบสุ่ม และเพิ่มขึ้นสองเท่าสำหรับโซลูชัน RL ที่ไม่มีบริบท ความถูกต้องของคำแนะนำเพิ่มขึ้นจาก 11% โดยใช้คำแนะนำแบบสุ่มเป็น 59% โดยใช้โซลูชัน ML Solutions Lab ด้วยประสิทธิภาพและความยืดหยุ่นของโซลูชันนี้ เราวางแผนที่จะรวมโซลูชันนี้เข้ากับกรณีการใช้งานส่วนบุคคลของ Ibotta เพิ่มเติมเพื่อสานต่อภารกิจของเราในการทำให้ทุกการซื้อมีรางวัลสำหรับผู้ใช้ของเรา"
– Heather Shannon รองประธานอาวุโสฝ่ายวิศวกรรมและข้อมูลของ Ibotta
เกี่ยวกับผู้เขียน
 ชื่อเทย์เลอร์ เป็นวิศวกรแมชชีนเลิร์นนิงของเจ้าหน้าที่ที่ Ibotta โดยมุ่งเน้นที่การปรับเนื้อหาให้เป็นส่วนตัวและการคาดการณ์ความต้องการแบบเรียลไทม์ ก่อนร่วมงานกับ Ibotta เทย์เลอร์เป็นผู้นำทีมแมชชีนเลิร์นนิงในด้าน IoT และพื้นที่พลังงานสะอาด
ชื่อเทย์เลอร์ เป็นวิศวกรแมชชีนเลิร์นนิงของเจ้าหน้าที่ที่ Ibotta โดยมุ่งเน้นที่การปรับเนื้อหาให้เป็นส่วนตัวและการคาดการณ์ความต้องการแบบเรียลไทม์ ก่อนร่วมงานกับ Ibotta เทย์เลอร์เป็นผู้นำทีมแมชชีนเลิร์นนิงในด้าน IoT และพื้นที่พลังงานสะอาด
 เดฟ คุปตะ เป็นผู้จัดการฝ่ายวิศวกรรมที่ Ibotta Inc ซึ่งเขาเป็นผู้นำทีมแมชชีนเลิร์นนิง ทีมงาน ML ที่ Ibotta ได้รับมอบหมายให้จัดหาซอฟต์แวร์ ML คุณภาพสูง เช่น ผู้แนะนำ นักพยากรณ์ และเครื่องมือ ML ภายใน ก่อนร่วมงานกับ Ibotta Dev เคยทำงานที่ Predikto Inc ซึ่งเป็นบริษัทสตาร์ทอัพด้านแมชชีนเลิร์นนิงและ The Home Depot เขาจบการศึกษาจากมหาวิทยาลัยฟลอริดา
เดฟ คุปตะ เป็นผู้จัดการฝ่ายวิศวกรรมที่ Ibotta Inc ซึ่งเขาเป็นผู้นำทีมแมชชีนเลิร์นนิง ทีมงาน ML ที่ Ibotta ได้รับมอบหมายให้จัดหาซอฟต์แวร์ ML คุณภาพสูง เช่น ผู้แนะนำ นักพยากรณ์ และเครื่องมือ ML ภายใน ก่อนร่วมงานกับ Ibotta Dev เคยทำงานที่ Predikto Inc ซึ่งเป็นบริษัทสตาร์ทอัพด้านแมชชีนเลิร์นนิงและ The Home Depot เขาจบการศึกษาจากมหาวิทยาลัยฟลอริดา
 อาร์กี้ แองเจลีส เป็นผู้จัดการผลิตภัณฑ์อาวุโสที่ Ibotta ซึ่งเขาเป็นผู้นำทีมการเรียนรู้ของเครื่องและส่วนขยายเบราว์เซอร์ ก่อนร่วมงานกับ Ibotta Argie ทำงานเป็นผู้อำนวยการฝ่ายผลิตภัณฑ์ของ iReportsource Argie สำเร็จการศึกษาระดับปริญญาเอกด้านวิทยาการคอมพิวเตอร์และวิศวกรรมศาสตร์จาก Wright State University
อาร์กี้ แองเจลีส เป็นผู้จัดการผลิตภัณฑ์อาวุโสที่ Ibotta ซึ่งเขาเป็นผู้นำทีมการเรียนรู้ของเครื่องและส่วนขยายเบราว์เซอร์ ก่อนร่วมงานกับ Ibotta Argie ทำงานเป็นผู้อำนวยการฝ่ายผลิตภัณฑ์ของ iReportsource Argie สำเร็จการศึกษาระดับปริญญาเอกด้านวิทยาการคอมพิวเตอร์และวิศวกรรมศาสตร์จาก Wright State University
 ฝางวัง เป็นนักวิทยาศาสตร์วิจัยอาวุโสที่ ห้องปฏิบัติการโซลูชันแมชชีนเลิร์นนิงของ Amazonซึ่งเธอเป็นผู้นำกลุ่มธุรกิจค้าปลีก โดยทำงานร่วมกับลูกค้า AWS ในอุตสาหกรรมต่างๆ เพื่อแก้ปัญหา ML ของพวกเขา ก่อนร่วมงานกับ AWS Fang เคยทำงานเป็น Sr. Director of Data Science ที่ Anthem ซึ่งเป็นผู้นำด้านแพลตฟอร์ม AI ในการประมวลผลการเคลมทางการแพทย์ เธอสำเร็จการศึกษาระดับปริญญาโทด้านสถิติจากมหาวิทยาลัยชิคาโก
ฝางวัง เป็นนักวิทยาศาสตร์วิจัยอาวุโสที่ ห้องปฏิบัติการโซลูชันแมชชีนเลิร์นนิงของ Amazonซึ่งเธอเป็นผู้นำกลุ่มธุรกิจค้าปลีก โดยทำงานร่วมกับลูกค้า AWS ในอุตสาหกรรมต่างๆ เพื่อแก้ปัญหา ML ของพวกเขา ก่อนร่วมงานกับ AWS Fang เคยทำงานเป็น Sr. Director of Data Science ที่ Anthem ซึ่งเป็นผู้นำด้านแพลตฟอร์ม AI ในการประมวลผลการเคลมทางการแพทย์ เธอสำเร็จการศึกษาระดับปริญญาโทด้านสถิติจากมหาวิทยาลัยชิคาโก
 ซินเฉิน เป็นผู้จัดการอาวุโสที่ ห้องปฏิบัติการโซลูชันแมชชีนเลิร์นนิงของ Amazonซึ่งเขาเป็นผู้นำในภาคกลางของสหรัฐฯ ภูมิภาคจีนแผ่นดินใหญ่ ลาตัม และแนวดิ่งด้านยานยนต์ เขาช่วยลูกค้า AWS ในอุตสาหกรรมต่างๆ ในการระบุและสร้างโซลูชันการเรียนรู้ของเครื่องเพื่อจัดการกับโอกาสการเรียนรู้ของเครื่องที่ให้ผลตอบแทนจากการลงทุนสูงสุดขององค์กร Xin สำเร็จการศึกษาระดับปริญญาเอกด้านวิทยาการคอมพิวเตอร์และวิศวกรรมศาสตร์จากมหาวิทยาลัยนอเทรอดาม
ซินเฉิน เป็นผู้จัดการอาวุโสที่ ห้องปฏิบัติการโซลูชันแมชชีนเลิร์นนิงของ Amazonซึ่งเขาเป็นผู้นำในภาคกลางของสหรัฐฯ ภูมิภาคจีนแผ่นดินใหญ่ ลาตัม และแนวดิ่งด้านยานยนต์ เขาช่วยลูกค้า AWS ในอุตสาหกรรมต่างๆ ในการระบุและสร้างโซลูชันการเรียนรู้ของเครื่องเพื่อจัดการกับโอกาสการเรียนรู้ของเครื่องที่ให้ผลตอบแทนจากการลงทุนสูงสุดขององค์กร Xin สำเร็จการศึกษาระดับปริญญาเอกด้านวิทยาการคอมพิวเตอร์และวิศวกรรมศาสตร์จากมหาวิทยาลัยนอเทรอดาม
 ราช บิสวาส เป็นนักวิทยาศาสตร์ข้อมูลที่cient ห้องปฏิบัติการโซลูชันแมชชีนเลิร์นนิงของ Amazon. เขาช่วยลูกค้า AWS พัฒนาโซลูชันที่ขับเคลื่อนด้วย ML ในอุตสาหกรรมที่หลากหลายสำหรับความท้าทายทางธุรกิจที่เร่งด่วนที่สุดของพวกเขา ก่อนร่วมงานกับ AWS เขาเป็นนักศึกษาระดับบัณฑิตศึกษาที่ Columbia University ใน Data Science
ราช บิสวาส เป็นนักวิทยาศาสตร์ข้อมูลที่cient ห้องปฏิบัติการโซลูชันแมชชีนเลิร์นนิงของ Amazon. เขาช่วยลูกค้า AWS พัฒนาโซลูชันที่ขับเคลื่อนด้วย ML ในอุตสาหกรรมที่หลากหลายสำหรับความท้าทายทางธุรกิจที่เร่งด่วนที่สุดของพวกเขา ก่อนร่วมงานกับ AWS เขาเป็นนักศึกษาระดับบัณฑิตศึกษาที่ Columbia University ใน Data Science
 ซิงหัวเหลียง เป็นนักวิทยาศาสตร์ประยุกต์ที่ ห้องปฏิบัติการโซลูชันแมชชีนเลิร์นนิงของ Amazonซึ่งเขาทำงานร่วมกับลูกค้าในอุตสาหกรรมต่างๆ รวมถึงการผลิตและยานยนต์ และช่วยให้พวกเขาเร่งความเร็วการนำ AI และระบบคลาวด์ไปใช้ Xinghua สำเร็จการศึกษาระดับปริญญาเอกด้านวิศวกรรมจากมหาวิทยาลัย Carnegie Mellon
ซิงหัวเหลียง เป็นนักวิทยาศาสตร์ประยุกต์ที่ ห้องปฏิบัติการโซลูชันแมชชีนเลิร์นนิงของ Amazonซึ่งเขาทำงานร่วมกับลูกค้าในอุตสาหกรรมต่างๆ รวมถึงการผลิตและยานยนต์ และช่วยให้พวกเขาเร่งความเร็วการนำ AI และระบบคลาวด์ไปใช้ Xinghua สำเร็จการศึกษาระดับปริญญาเอกด้านวิศวกรรมจากมหาวิทยาลัย Carnegie Mellon
 ยี่หลิว เป็นนักวิทยาศาสตร์ประยุกต์กับฝ่ายบริการลูกค้าของ Amazon เธอหลงใหลในการใช้พลังของ ML/AI เพื่อเพิ่มประสิทธิภาพประสบการณ์ผู้ใช้สำหรับลูกค้า Amazon และช่วยลูกค้า AWS สร้างโซลูชันระบบคลาวด์ที่ปรับขนาดได้ งานด้านวิทยาศาสตร์ของเธอใน Amazon ครอบคลุมถึงการมีส่วนร่วมของสมาชิก ระบบแนะนำออนไลน์ และการระบุข้อบกพร่องและการแก้ไขประสบการณ์ของลูกค้า ยีสนุกกับการเดินทางและสำรวจธรรมชาติกับสุนัขของเธอนอกงาน
ยี่หลิว เป็นนักวิทยาศาสตร์ประยุกต์กับฝ่ายบริการลูกค้าของ Amazon เธอหลงใหลในการใช้พลังของ ML/AI เพื่อเพิ่มประสิทธิภาพประสบการณ์ผู้ใช้สำหรับลูกค้า Amazon และช่วยลูกค้า AWS สร้างโซลูชันระบบคลาวด์ที่ปรับขนาดได้ งานด้านวิทยาศาสตร์ของเธอใน Amazon ครอบคลุมถึงการมีส่วนร่วมของสมาชิก ระบบแนะนำออนไลน์ และการระบุข้อบกพร่องและการแก้ไขประสบการณ์ของลูกค้า ยีสนุกกับการเดินทางและสำรวจธรรมชาติกับสุนัขของเธอนอกงาน
- "
- &
- 000
- 10
- 100
- 11
- 7
- 9
- เกี่ยวกับเรา
- เร่งความเร็ว
- ตาม
- ข้าม
- การกระทำ
- การปฏิบัติ
- อยากทำกิจกรรม
- เพิ่มเติม
- ที่อยู่
- การนำมาใช้
- ตัวแทน
- AI
- ขั้นตอนวิธี
- อัลกอริทึม
- แล้ว
- อเมซอน
- อเมริกัน
- จำนวน
- app
- การใช้งาน
- ปพลิเคชัน
- AREA
- ยานยนต์
- ใช้ได้
- เฉลี่ย
- AWS
- โบนัส
- เบราว์เซอร์
- สร้าง
- built-in
- ธุรกิจ
- ความสามารถในการ
- Carnegie Mellon
- กรณี
- เงินสด
- ความท้าทาย
- เปลี่ยนแปลง
- ชิคาโก
- สาธารณรัฐประชาชนจีน
- คลาสสิก
- เมฆ
- รหัส
- บริษัท
- เมื่อเทียบกับ
- วิทยาการคอมพิวเตอร์
- ภาชนะ
- เนื้อหา
- ปัจจุบัน
- ประสบการณ์ของลูกค้า
- บริการลูกค้า
- ลูกค้า
- ข้อมูล
- วิทยาศาสตร์ข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- วัน
- ผู้มีอำนาจตัดสินใจ
- ความต้องการ
- แสดงให้เห็นถึง
- ปรับใช้
- การใช้งาน
- dev
- พัฒนา
- พัฒนา
- นักพัฒนา
- ต่าง
- ผู้อำนวยการ
- การกระจาย
- พลวัต
- มีประสิทธิภาพ
- ปลายทาง
- พลังงาน
- มีส่วนร่วม
- เครื่องยนต์
- วิศวกร
- ชั้นเยี่ยม
- สิ่งแวดล้อม
- สร้าง
- การพัฒนา
- ประสบการณ์
- การสำรวจ
- คุณสมบัติ
- ข้อเสนอแนะ
- รูป
- ความยืดหยุ่น
- ฟลอริด้า
- มุ่งเน้นไปที่
- ดังต่อไปนี้
- รูป
- กรอบ
- ต่อไป
- สำเร็จการศึกษา
- แขก
- โพสต์ของผู้เข้าพัก
- ความสูง
- ช่วย
- จะช่วยให้
- อย่างสูง
- ทางประวัติศาสตร์
- หน้าแรก
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- HTTPS
- ประจำตัว
- แยกแยะ
- การดำเนินการ
- รวมทั้ง
- เพิ่ม
- อุตสาหกรรม
- อุตสาหกรรม
- ข้อมูล
- โครงสร้างพื้นฐาน
- รวบรวม
- ฉลาด
- ปฏิสัมพันธ์
- IOT
- ความรู้
- ห้องปฏิบัติการ
- ชั้นนำ
- นำไปสู่
- เรียนรู้
- ได้เรียนรู้
- การเรียนรู้
- นำ
- การใช้ประโยชน์
- Line
- จดทะเบียน
- นาน
- ความจงรักภักดี
- เครื่อง
- เรียนรู้เครื่อง
- การทำ
- ผู้จัดการ
- การผลิต
- ปริญญาโท
- ทางการแพทย์
- ตัวชี้วัด
- ภารกิจ
- ML
- โทรศัพท์มือถือ
- app มือถือ
- แบบ
- โมเดล
- เดือน
- ข้อมูลเพิ่มเติม
- มากที่สุด
- ชื่อ
- ธรรมชาติ
- ความคิด
- จำนวน
- ออนไลน์
- การสั่งซื้อออนไลน์
- โอกาส
- ใบสั่ง
- อื่นๆ
- มิฉะนั้น
- การชำระเงิน
- การปฏิบัติ
- ส่วนบุคคล
- เวที
- นโยบาย
- นโยบาย
- อำนาจ
- ประธาน
- ปัญหา
- ปัญหาที่เกิดขึ้น
- ผลิตภัณฑ์
- การผลิต
- โปรโมชั่น
- การให้
- ซื้อ
- การซื้อสินค้า
- อย่างรวดเร็ว
- ราคา
- เรียลไทม์
- แนะนำ
- บันทึก
- การวิจัย
- ผลสอบ
- ค้าปลีก
- ร้านค้าปลีก
- รับคืน
- รางวัล
- ที่ปรับขนาดได้
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- นักวิทยาศาสตร์
- เลือก
- บริการ
- ชุด
- สำคัญ
- ซอฟต์แวร์
- ทางออก
- โซลูชัน
- แก้
- ช่องว่าง
- แยก
- เริ่มต้น
- เริ่มต้น
- การเริ่มต้น
- สถานะ
- สถิติ
- กลยุทธ์
- นักเรียน
- ที่สนับสนุน
- รองรับ
- สวิตซ์
- ระบบ
- ทีม
- เทคโนโลยี
- ทดสอบ
- การทดสอบ
- ตลอด
- ร่วมกัน
- เครื่องมือ
- การฝึกอบรม
- รถไฟ
- มหาวิทยาลัย
- us
- ใช้
- ผู้ใช้
- ต่างๆ
- การตรวจสอบ
- Vice President
- รายสัปดาห์
- ภายใน
- งาน
- ทำงาน
- การทำงาน
- โรงงาน