นี่คือแขกโพสต์โดย AK Roy จาก Qualcomm AI
Amazon Elastic Compute Cloud (อเมซอน EC2) อินสแตนซ์ DL2q ซึ่งขับเคลื่อนโดยตัวเร่งความเร็วมาตรฐาน Qualcomm AI 100 สามารถใช้เพื่อปรับใช้ปริมาณงานการเรียนรู้เชิงลึก (DL) ในระบบคลาวด์ได้อย่างคุ้มต้นทุน นอกจากนี้ยังสามารถใช้เพื่อพัฒนาและตรวจสอบประสิทธิภาพและความแม่นยำของปริมาณงาน DL ที่จะปรับใช้บนอุปกรณ์ Qualcomm อินสแตนซ์ DL2q เป็นอินสแตนซ์แรกที่นำเทคโนโลยีปัญญาประดิษฐ์ (AI) ของ Qualcomm มาสู่ระบบคลาวด์
ด้วยตัวเร่งความเร็วมาตรฐาน Qualcomm AI 100 Standard แปดตัวและหน่วยความจำตัวเร่งทั้งหมด 128 GiB ลูกค้ายังสามารถใช้อินสแตนซ์ DL2q เพื่อรันแอปพลิเคชัน AI เจนเนอเรชั่นยอดนิยม เช่น การสร้างเนื้อหา การสรุปข้อความ และผู้ช่วยเสมือน รวมถึงแอปพลิเคชัน AI แบบคลาสสิกสำหรับการประมวลผลภาษาธรรมชาติ และการมองเห็นของคอมพิวเตอร์ นอกจากนี้ ตัวเร่งความเร็ว Qualcomm AI 100 ยังมีเทคโนโลยี AI แบบเดียวกับที่ใช้ในสมาร์ทโฟน การขับขี่อัตโนมัติ คอมพิวเตอร์ส่วนบุคคล และชุดหูฟังความเป็นจริงเสริม ดังนั้นอินสแตนซ์ DL2q จึงสามารถใช้เพื่อพัฒนาและตรวจสอบปริมาณงาน AI เหล่านี้ก่อนปรับใช้ได้
ไฮไลท์อินสแตนซ์ DL2q ใหม่
อินสแตนซ์ DL2q แต่ละตัวประกอบด้วยตัวเร่งความเร็ว Qualcomm Cloud AI100 แปดตัว โดยมีประสิทธิภาพรวมมากกว่า 2.8 PetaOps ของประสิทธิภาพการอนุมาน Int8 และ 1.4 PetaFlops ของประสิทธิภาพการอนุมาน FP16 อินสแตนซ์นี้มีคอร์ AI รวม 112 คอร์ ความจุหน่วยความจำเร่งความเร็ว 128 GB และแบนด์วิดท์หน่วยความจำ 1.1 TB ต่อวินาที
อินสแตนซ์ DL2q แต่ละตัวมี vCPU 96 ตัว ความจุหน่วยความจำระบบ 768 GB และรองรับแบนด์วิธเครือข่าย 100 Gbps รวมถึง ร้านค้า Amazon Elastic Block (Amazon EBS) พื้นที่เก็บข้อมูล 19 Gbps
| ชื่ออินสแตนซ์ | vCPU | ตัวเร่งความเร็ว Cloud AI100 | หน่วยความจำคันเร่ง | หน่วยความจำคันเร่ง BW (รวม) | หน่วยความจำอินสแตนซ์ | เครือข่ายอินสแตนซ์ | แบนด์วิธพื้นที่จัดเก็บข้อมูล (Amazon EBS) |
| DL2q.24xใหญ่ | 96 | 8 | 128 GB | 1.088 TB / s | 768 GB | 100 Gbps | 19 Gbps |
นวัตกรรมตัวเร่ง Qualcomm Cloud AI100
ระบบบนชิป (SoC) ตัวเร่ง Cloud AI100 เป็นสถาปัตยกรรมแบบมัลติคอร์ที่สร้างขึ้นตามวัตถุประสงค์และปรับขนาดได้ โดยรองรับกรณีการใช้งานการเรียนรู้เชิงลึกที่หลากหลายตั้งแต่ศูนย์ข้อมูลไปจนถึง Edge SoC ใช้แกนประมวลผลแบบสเกลาร์ เวกเตอร์ และเทนเซอร์ พร้อมด้วยความจุ SRAM on-die ชั้นนำของอุตสาหกรรมที่ 126 MB แกนประมวลผลเชื่อมต่อกันด้วยเครือข่ายบนชิป (NoC) ที่มีแบนด์วิดท์สูง เวลาแฝงต่ำ
เครื่องเร่งความเร็ว AI100 รองรับรุ่นและกรณีการใช้งานที่หลากหลายและครอบคลุม ตารางด้านล่างเน้นช่วงของการรองรับรุ่น
| หมวดโมเดล | จำนวนของรูปแบบ | ตัวอย่าง |
| เอ็นแอลพี | 157 | BERT, BART, FasterTransformer, T5, รหัส Z MOE |
| เจเนอเรชั่นเอไอ – NLP | 40 | LLaMA, CodeGen, GPT, OPT, BLOOM, Jais, ส่องสว่าง, StarCoder, XGen |
| AI เจนเนอเรชั่น – รูปภาพ | 3 | การแพร่กระจายที่เสถียร v1.5 และ v2.1, OpenAI CLIP |
| CV – การจำแนกภาพ | 45 | ViT, ResNet, ResNext, MobileNet, EfficientNet |
| CV – การตรวจจับวัตถุ | 23 | YOLO v2, v3, v4, v5 และ v7, SSD-ResNet, RetinaNet |
| CV – อื่นๆ | 15 | LPRNet, ความละเอียดพิเศษ/SRGAN, ByteTrack |
| เครือข่ายยานยนต์* | 53 | การรับรู้และการตรวจจับ LIDAR คนเดินเท้า เลน และสัญญาณไฟจราจร |
| รวม | > 300 †< | †< |
* เครือข่ายยานยนต์ส่วนใหญ่เป็นเครือข่ายคอมโพสิตที่ประกอบด้วยการรวมเครือข่ายแต่ละเครือข่ายเข้าด้วยกัน
SRAM ออนดายขนาดใหญ่บนตัวเร่งความเร็ว DL2q ช่วยให้สามารถนำเทคนิคประสิทธิภาพขั้นสูงไปใช้ได้อย่างมีประสิทธิภาพ เช่น ความแม่นยำระดับไมโครเอ็กซ์โพเนนต์ MX6 สำหรับการจัดเก็บน้ำหนัก และความแม่นยำระดับไมโครเอ็กซ์โปเนนต์ MX9 สำหรับการสื่อสารระหว่างตัวเร่งถึงตัวเร่งความเร็ว เทคโนโลยีไมโครเอ็กซ์โพเนนต์ได้รับการอธิบายไว้ในประกาศอุตสาหกรรม Open Compute Project (OCP) ต่อไปนี้: AMD, Arm, Intel, Meta, Microsoft, NVIDIA และ Qualcomm สร้างมาตรฐานรูปแบบข้อมูลความแม่นยำแคบแห่งอนาคตสำหรับ AI » Open Compute Project.
ผู้ใช้อินสแตนซ์สามารถใช้กลยุทธ์ต่อไปนี้เพื่อเพิ่มประสิทธิภาพต่อต้นทุนให้สูงสุด:
- จัดเก็บน้ำหนักโดยใช้ความแม่นยำไมโครเอ็กซ์โพเนนต์ MX6 ในหน่วยความจำ DDR บนคันเร่ง การใช้ความแม่นยำ MX6 ช่วยเพิ่มการใช้ความจุหน่วยความจำที่มีอยู่และแบนด์วิดท์หน่วยความจำให้สูงสุดเพื่อมอบปริมาณงานและเวลาแฝงที่ดีที่สุดในระดับเดียวกัน
- ประมวลผลใน FP16 เพื่อมอบความแม่นยำกรณีการใช้งานที่จำเป็น ขณะใช้ SRAM บนชิปที่เหนือกว่าและ TOP สำรองบนการ์ด เพื่อใช้เคอร์เนล MX6 ที่มีความหน่วงต่ำประสิทธิภาพสูง
- ใช้กลยุทธ์การจัดชุดที่ได้รับการปรับปรุงและขนาดชุดงานที่สูงขึ้นโดยใช้ SRAM บนชิปขนาดใหญ่ที่มีอยู่เพื่อเพิ่มการใช้ตุ้มน้ำหนักซ้ำให้เกิดประโยชน์สูงสุด ขณะเดียวกันก็รักษาการเปิดใช้งานบนชิปไว้ให้มากที่สุดเท่าที่จะเป็นไปได้
DL2q AI Stack และ toolchain
อินสแตนซ์ DL2q มาพร้อมกับ Qualcomm AI Stack ที่มอบประสบการณ์นักพัฒนาที่สอดคล้องกันใน Qualcomm AI ในระบบคลาวด์และผลิตภัณฑ์ Qualcomm อื่นๆ เทคโนโลยี AI สแต็กและฐานของ Qualcomm AI แบบเดียวกันนั้นทำงานบนอินสแตนซ์ DL2q และอุปกรณ์ Qualcomm Edge ช่วยให้ลูกค้าได้รับประสบการณ์นักพัฒนาที่สอดคล้องกัน ด้วย API แบบรวมทั่วทั้งระบบคลาวด์ ยานยนต์ คอมพิวเตอร์ส่วนบุคคล Extended Reality และสภาพแวดล้อมการพัฒนาสมาร์ทโฟน
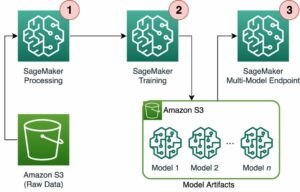
ห่วงโซ่เครื่องมือช่วยให้ผู้ใช้อินสแตนซ์สามารถเริ่มต้นใช้งานโมเดลที่ผ่านการฝึกอบรมก่อนหน้านี้ได้อย่างรวดเร็ว คอมไพล์และเพิ่มประสิทธิภาพโมเดลสำหรับความสามารถของอินสแตนซ์ และต่อมาปรับใช้โมเดลที่คอมไพล์แล้วสำหรับกรณีการใช้งานการอนุมานการผลิตในสามขั้นตอนดังแสดงในรูปต่อไปนี้

หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการปรับแต่งประสิทธิภาพของโมเดล โปรดดูที่ พารามิเตอร์ประสิทธิภาพหลักของ Cloud AI 100 เอกสาร
เริ่มต้นใช้งานอินสแตนซ์ DL2q
ในตัวอย่างนี้ คุณคอมไพล์และปรับใช้โปรแกรมที่ได้รับการฝึกอบรมล่วงหน้า รุ่น BERT ราคาเริ่มต้นที่ กอดหน้า บนอินสแตนซ์ EC2 DL2q โดยใช้ DL2q AMI ที่สร้างไว้ล่วงหน้าที่พร้อมใช้งานในสี่ขั้นตอน
คุณสามารถใช้อย่างใดอย่างหนึ่งที่สร้างไว้ล่วงหน้า ควอลคอมม์ ดลามี บนอินสแตนซ์หรือเริ่มต้นด้วย Amazon Linux2 AMI และสร้าง DL2q AMI ของคุณเองด้วย Cloud AI 100 Platform และ Apps SDK ที่มีอยู่ในนี้ บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) ถัง: s3://ec2-linux-qualcomm-ai100-sdks/latest/.
ขั้นตอนที่ตามมาใช้ DL2q AMI ที่สร้างไว้ล่วงหน้า ฐาน Qualcomm AL2 DLAMI.
ใช้ SSH เพื่อเข้าถึงอินสแตนซ์ DL2q ของคุณด้วย Qualcomm Base AL2 DLAMI AMI และทำตามขั้นตอนที่ 1 ถึง 4
ขั้นตอนที่ 1 ตั้งค่าสภาพแวดล้อมและติดตั้งแพ็คเกจที่จำเป็น
- ติดตั้ง Python 3.8
- ตั้งค่าสภาพแวดล้อมเสมือน Python 3.8
- เปิดใช้งานสภาพแวดล้อมเสมือน Python 3.8
- ติดตั้งแพ็คเกจที่จำเป็น ดังแสดงในไฟล์ เอกสารข้อกำหนด.txt สามารถดูได้ที่ไซต์ Github สาธารณะของ Qualcomm
- นำเข้าไลบรารีที่จำเป็น
ขั้นตอนที่ 2 นำเข้าโมเดล
- นำเข้าและโทเค็นโมเดล
- กำหนดอินพุตตัวอย่างและแยกไฟล์
inputIdsและattentionMask. - แปลงโมเดลเป็น ONNX ซึ่งสามารถส่งผ่านไปยังคอมไพเลอร์ได้
- คุณจะรันโมเดลด้วยความแม่นยำ FP16 ดังนั้น คุณต้องตรวจสอบว่าโมเดลมีค่าคงที่ใดๆ ที่เกินช่วง FP16 หรือไม่ ส่งต่อโมเดลไปที่
fix_onnx_fp16ฟังก์ชั่นเพื่อสร้างไฟล์ ONNX ใหม่พร้อมการแก้ไขที่จำเป็น
ขั้นตอนที่ 3 รวบรวมโมเดล
พื้นที่ qaic-exec เครื่องมือคอมไพเลอร์อินเตอร์เฟสบรรทัดคำสั่ง (CLI) ใช้ในการคอมไพล์โมเดล อินพุตของคอมไพลเลอร์นี้คือไฟล์ ONNX ที่สร้างขึ้นในขั้นตอนที่ 2 คอมไพเลอร์สร้างไฟล์ไบนารี (เรียกว่า คิวพีซีสำหรับ คอนเทนเนอร์โปรแกรม Qualcomm) ในเส้นทางที่กำหนดโดย -aic-binary-dir ข้อโต้แย้ง.
ในคำสั่งคอมไพล์ด้านล่าง คุณใช้คอร์ประมวลผล AI สี่คอร์และขนาดแบทช์หนึ่งคอร์ในการคอมไพล์โมเดล
QPC ถูกสร้างขึ้นใน bert-base-cased/generatedModels/bert-base-cased_fix_outofrange_fp16_qpc โฟลเดอร์
ขั้นตอนที่ 4 รันโมเดล
ตั้งค่าเซสชันเพื่อเรียกใช้การอนุมานบนตัวเร่งความเร็ว Cloud AI100 Qualcomm ในอินสแตนซ์ DL2q
ไลบรารี Qualcomm qaic Python คือชุดของ API ที่ให้การสนับสนุนสำหรับการรันการอนุมานบน Cloud AI100 accelerator
- ใช้การเรียก Session API เพื่อสร้างอินสแตนซ์ของเซสชัน การเรียก Session API เป็นจุดเริ่มต้นในการใช้ไลบรารี qaic Python
- ปรับโครงสร้างข้อมูลจากบัฟเฟอร์เอาต์พุตด้วย
output_shapeและoutput_type. - ถอดรหัสผลลัพธ์ที่ผลิต
ต่อไปนี้เป็นผลลัพธ์ของประโยคอินพุต “The dog [MASK] on the mat”
แค่นั้นแหละ. เพียงไม่กี่ขั้นตอน คุณก็คอมไพล์และรันโมเดล PyTorch บนอินสแตนซ์ Amazon EC2 DL2q ได้ หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการเริ่มใช้งานและการคอมไพล์โมเดลบนอินสแตนซ์ DL2q โปรดดูที่ เอกสารการสอนการใช้งาน Cloud AI100
หากต้องการเรียนรู้เพิ่มเติมว่าสถาปัตยกรรมโมเดล DL ใดที่เหมาะกับอินสแตนซ์ AWS DL2q และเมทริกซ์การรองรับโมเดลปัจจุบัน โปรดดูที่ เอกสารประกอบของ Qualcomm Cloud AI100.
ใช้ได้ในขณะนี้
คุณสามารถเปิดใช้อินสแตนซ์ DL2q ได้แล้ววันนี้ในภูมิภาค AWS ของสหรัฐอเมริกาฝั่งตะวันตก (ออริกอน) และยุโรป (แฟรงก์เฟิร์ต) ตามความต้องการ, ที่สงวนไว้และ อินสแตนซ์ของสปอตหรือเป็นส่วนหนึ่งของ แผนการออม. ตามปกติสำหรับ Amazon EC2 คุณจะจ่ายเฉพาะส่วนที่คุณใช้เท่านั้น สำหรับข้อมูลเพิ่มเติม โปรดดู ราคา Amazon EC2.
สามารถปรับใช้อินสแตนซ์ DL2q ได้ AWS Deep Learning AMI (DLAMI)และอิมเมจคอนเทนเนอร์พร้อมใช้งานผ่านบริการที่มีการจัดการ เช่น อเมซอน SageMaker, บริการ Amazon Elastic Kubernetes (Amazon EKS), บริการ Amazon Elastic Container (Amazon ECS)และ AWS ParallelCluster.
หากต้องการเรียนรู้เพิ่มเติมโปรดไปที่ อินสแตนซ์ Amazon EC2 DL2q เพจ และส่งข้อเสนอแนะมาที่ AWS re:Post สำหรับ EC2 หรือผ่านผู้ติดต่อ AWS Support ปกติของคุณ
เกี่ยวกับผู้แต่ง
 เอเค รอย เป็นผู้อำนวยการฝ่ายการจัดการผลิตภัณฑ์ที่ Qualcomm สำหรับผลิตภัณฑ์และโซลูชัน Cloud และ Datacenter AI เขามีประสบการณ์มากกว่า 20 ปีในด้านกลยุทธ์และการพัฒนาผลิตภัณฑ์ โดยปัจจุบันมุ่งเน้นไปที่ประสิทธิภาพและประสิทธิภาพที่ดีที่สุดในระดับเดียวกัน/$ โซลูชัน end-to-end สำหรับการอนุมาน AI ในระบบคลาวด์ สำหรับกรณีการใช้งานที่หลากหลาย รวมถึง GenAI, LLM, Auto และ Hybrid AI
เอเค รอย เป็นผู้อำนวยการฝ่ายการจัดการผลิตภัณฑ์ที่ Qualcomm สำหรับผลิตภัณฑ์และโซลูชัน Cloud และ Datacenter AI เขามีประสบการณ์มากกว่า 20 ปีในด้านกลยุทธ์และการพัฒนาผลิตภัณฑ์ โดยปัจจุบันมุ่งเน้นไปที่ประสิทธิภาพและประสิทธิภาพที่ดีที่สุดในระดับเดียวกัน/$ โซลูชัน end-to-end สำหรับการอนุมาน AI ในระบบคลาวด์ สำหรับกรณีการใช้งานที่หลากหลาย รวมถึง GenAI, LLM, Auto และ Hybrid AI
 เจียนหยิง หลาง เป็น Principal Solutions Architect ที่ AWS Worldwide Specialist Organisation (WWSO) เธอมีประสบการณ์การทำงานมากกว่า 15 ปีในด้าน HPC และ AI ที่ AWS เธอมุ่งเน้นไปที่การช่วยเหลือลูกค้าปรับใช้ เพิ่มประสิทธิภาพ และปรับขนาดปริมาณงาน AI/ML บนอินสแตนซ์การประมวลผลแบบเร่งความเร็ว เธอมีความหลงใหลในการผสานเทคนิคในด้าน HPC และ AI Jianying สำเร็จการศึกษาระดับปริญญาเอกสาขาฟิสิกส์คอมพิวเตอร์จากมหาวิทยาลัยโคโลราโดที่โบลเดอร์
เจียนหยิง หลาง เป็น Principal Solutions Architect ที่ AWS Worldwide Specialist Organisation (WWSO) เธอมีประสบการณ์การทำงานมากกว่า 15 ปีในด้าน HPC และ AI ที่ AWS เธอมุ่งเน้นไปที่การช่วยเหลือลูกค้าปรับใช้ เพิ่มประสิทธิภาพ และปรับขนาดปริมาณงาน AI/ML บนอินสแตนซ์การประมวลผลแบบเร่งความเร็ว เธอมีความหลงใหลในการผสานเทคนิคในด้าน HPC และ AI Jianying สำเร็จการศึกษาระดับปริญญาเอกสาขาฟิสิกส์คอมพิวเตอร์จากมหาวิทยาลัยโคโลราโดที่โบลเดอร์
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/amazon-ec2-dl2q-instance-for-cost-efficient-high-performance-ai-inference-is-now-generally-available/
- :มี
- :เป็น
- $ ขึ้น
- 1
- วัณโรค 1
- 10
- 100
- 11
- 12
- 13
- 15%
- 17
- 19
- 20
- 22
- 23
- 46
- 7
- 75
- 8
- 84
- a
- เกี่ยวกับเรา
- ข้างบน
- เร่ง
- คันเร่ง
- เร่ง
- เข้า
- มาพร้อมกับ
- ความถูกต้อง
- ข้าม
- การเปิดใช้งาน
- นอกจากนี้
- สูง
- สรุป
- AI
- AI / ML
- ทั้งหมด
- ด้วย
- อเมซอน
- Amazon EC2
- Amazon Web Services
- an
- และ
- การประกาศ
- ใด
- API
- APIs
- การใช้งาน
- ปพลิเคชัน
- สถาปัตยกรรม
- เป็น
- อาร์กิวเมนต์
- ARM
- เทียม
- AS
- ผู้ช่วย
- At
- รถยนต์
- ยานยนต์
- อิสระ
- ใช้ได้
- AWS
- แกน
- แบนด์วิดธ์
- ฐาน
- เครื่องผสม
- BE
- ก่อน
- ด้านล่าง
- เกิน
- BIN
- ปิดกั้น
- บานสะพรั่ง
- นำมาซึ่ง
- กว้าง
- กันชน
- สร้าง
- by
- โทรศัพท์
- ที่เรียกว่า
- CAN
- ความสามารถในการ
- ความจุ
- บัตร
- กรณี
- ตรวจสอบ
- คลาสสิก
- เมฆ
- โคโลราโด
- การรวมกัน
- การสื่อสาร
- รวบรวม
- ครอบคลุม
- การคำนวณ
- คำนวณ
- คอมพิวเตอร์
- วิสัยทัศน์คอมพิวเตอร์
- คอมพิวเตอร์
- การคำนวณ
- คงเส้นคงวา
- ประกอบด้วย
- รายชื่อผู้ติดต่อ
- ภาชนะ
- มี
- เนื้อหา
- สร้าง
- ปัจจุบัน
- ลูกค้า
- ข้อมูล
- ศูนย์ข้อมูล
- ลึก
- การเรียนรู้ลึก ๆ
- กำหนด
- องศา
- ส่งมอบ
- มอบ
- ปรับใช้
- นำไปใช้
- การใช้งาน
- อธิบาย
- พัฒนา
- ผู้พัฒนา
- พัฒนาการ
- เครื่อง
- อุปกรณ์
- การจัดจำหน่าย
- ผู้อำนวยการ
- เอกสาร
- สุนัข
- การขับขี่
- พลวัต
- EBS
- ขอบ
- ที่มีประสิทธิภาพ
- ทั้ง
- พนักงาน
- ช่วยให้
- จบสิ้น
- การเข้า
- สิ่งแวดล้อม
- สภาพแวดล้อม
- อีเธอร์ (ETH)
- ยุโรป
- ตัวอย่าง
- ประสบการณ์
- ขยายความเป็นจริง
- สารสกัด
- เท็จ
- ลักษณะ
- ข้อเสนอแนะ
- สองสาม
- สนาม
- สาขา
- รูป
- เนื้อไม่มีมัน
- ชื่อจริง
- พอดี
- แก้ไข
- โฟกัส
- มุ่งเน้นไปที่
- ปฏิบัติตาม
- ดังต่อไปนี้
- สำหรับ
- พบ
- สี่
- แฟรงค์เฟิร์ต
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- การผสม
- โดยทั่วไป
- สร้าง
- สร้าง
- รุ่น
- กำเนิด
- กำเนิด AI
- GitHub
- กำหนด
- ดี
- แขก
- โพสต์ของผู้เข้าพัก
- he
- ชุดหูฟัง
- การช่วยเหลือ
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- ประสิทธิภาพสูง
- สูงกว่า
- ไฮไลท์
- ถือ
- HPC
- HTML
- HTTPS
- เป็นลูกผสม
- i
- IDX
- if
- ภาพ
- ภาพ
- การดำเนินการ
- การดำเนินงาน
- นำเข้า
- in
- รวมทั้ง
- รวม
- เป็นรายบุคคล
- อุตสาหกรรม
- ชั้นนำของอุตสาหกรรม
- ข้อมูล
- อินพุต
- ติดตั้ง
- ตัวอย่าง
- อินสแตนซ์
- อินเทล
- ฉลาด
- เชื่อมต่อถึงกัน
- อินเตอร์เฟซ
- IT
- jpg
- เพียงแค่
- คีย์
- Kubernetes
- เลน
- ภาษา
- ใหญ่
- ความแอบแฝง
- เปิดตัว
- เรียนรู้
- การเรียนรู้
- ห้องสมุด
- ห้องสมุด
- LIDAR
- เบา
- Line
- โหลด
- การจัดการ
- การจัดการ
- หน้ากาก
- มดลูก
- แม็กซ์
- เพิ่ม
- เพิ่ม
- สูงสุด
- หน่วยความจำ
- ตาข่าย
- Meta
- ไมโครซอฟท์
- นาที
- แบบ
- โมเดล
- การแก้ไข
- ข้อมูลเพิ่มเติม
- มากที่สุด
- ชื่อ
- โดยธรรมชาติ
- ภาษาธรรมชาติ
- ประมวลผลภาษาธรรมชาติ
- จำเป็น
- จำเป็นต้อง
- เครือข่าย
- เครือข่าย
- เครือข่าย
- ใหม่
- รุ่นต่อไป
- ตอนนี้
- มึน
- Nvidia
- วัตถุ
- of
- on
- ออนบอร์ด
- การดูแลพนักงานใหม่
- ONE
- เพียง
- เปิด
- OpenAI
- เพิ่มประสิทธิภาพ
- การปรับให้เหมาะสม
- or
- ออริกอน
- organizacja
- OS
- อื่นๆ
- ออก
- เอาท์พุต
- เอาท์พุท
- เกิน
- ของตนเอง
- แพคเกจ
- หน้า
- ส่วนหนึ่ง
- ส่ง
- ผ่าน
- หลงใหล
- เส้นทาง
- ชำระ
- ต่อ
- การปฏิบัติ
- ส่วนบุคคล
- คอมพิวเตอร์ส่วนบุคคล
- phd
- ฟิสิกส์
- เวที
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- จุด
- ยอดนิยม
- เป็นไปได้
- โพสต์
- ขับเคลื่อน
- ความแม่นยำ
- ก่อนหน้านี้
- หลัก
- การประมวลผล
- ผลิต
- ผลิต
- ผลิตภัณฑ์
- การจัดการผลิตภัณฑ์
- การผลิต
- ผลิตภัณฑ์
- โครงการ
- โครงการ
- ให้
- การให้
- สาธารณะ
- หลาม
- ไฟฉาย
- วอลคอมม์
- อย่างรวดเร็ว
- พิสัย
- RE
- การอ่าน
- ความจริง
- ภูมิภาค
- จำเป็นต้องใช้
- ความต้องการ
- การรักษา
- กลับ
- นำมาใช้ใหม่
- รอย
- วิ่ง
- วิ่ง
- ทำงาน
- เดียวกัน
- ลด
- ประหยัด
- ที่ปรับขนาดได้
- ขนาด
- SDK
- ที่สอง
- เห็น
- ส่ง
- ประโยค
- ลำดับ
- บริการ
- บริการ
- เซสชั่น
- ชุด
- เธอ
- แสดง
- ง่าย
- ลดความซับซ้อน
- เว็บไซต์
- ขนาด
- มาร์ทโฟน
- มาร์ทโฟน
- So
- โซลูชัน
- ความตึงเครียด
- ผู้เชี่ยวชาญ
- กอง
- มาตรฐาน
- เริ่มต้น
- ข้อความที่เริ่ม
- ขั้นตอน
- ขั้นตอน
- การเก็บรักษา
- จัดเก็บ
- กลยุทธ์
- ต่อจากนั้น
- อย่างเช่น
- เหนือกว่า
- สนับสนุน
- ที่สนับสนุน
- รองรับ
- ระบบ
- ตาราง
- เทคนิค
- เทคโนโลยี
- ข้อความ
- ที่
- พื้นที่
- ของพวกเขา
- แล้วก็
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- สาม
- ตลอด
- ปริมาณงาน
- ผ่าน
- ไปยัง
- ในวันนี้
- โทเค็น
- เครื่องมือ
- ท็อปส์ซู
- ไฟฉาย
- รวม
- การจราจร
- ผ่านการฝึกอบรม
- หม้อแปลง
- จริง
- เกี่ยวกับการสอน
- ปึกแผ่น
- มหาวิทยาลัย
- us
- ใช้
- ใช้กรณี
- กรณีใช้งาน
- มือสอง
- ผู้ใช้งาน
- การใช้
- ตามปกติ
- v1
- VAL
- ตรวจสอบความถูกต้อง
- ความคุ้มค่า
- เสมือน
- วิสัยทัศน์
- เยี่ยมชมร้านค้า
- we
- เว็บ
- บริการเว็บ
- ดี
- ตะวันตก
- อะไร
- ที่
- ในขณะที่
- กว้าง
- ช่วงกว้าง
- จะ
- กับ
- คำ
- การทำงาน
- ทั่วโลก
- ปี
- เธอ
- ของคุณ
- ลมทะเล