องค์กรต่างๆ ในทุกอุตสาหกรรมมีข้อกำหนดในการประมวลผลข้อมูลที่ซับซ้อนสำหรับกรณีการใช้งานเชิงวิเคราะห์ในระบบการวิเคราะห์ต่างๆ เช่น ทะเลสาบข้อมูลบน AWS, คลังข้อมูล (อเมซอน Redshift), ค้นหา (บริการ Amazon OpenSearch), NoSQL (อเมซอน ไดนาโมดีบี) การเรียนรู้ของเครื่อง (อเมซอน SageMaker), และอื่น ๆ. ผู้เชี่ยวชาญด้านการวิเคราะห์ได้รับมอบหมายให้ได้รับคุณค่าจากข้อมูลที่จัดเก็บในระบบแบบกระจายเหล่านี้เพื่อสร้างประสบการณ์ที่ดียิ่งขึ้น ปลอดภัย และคุ้มค่าแก่ลูกค้า ตัวอย่างเช่น บริษัทสื่อดิจิทัลพยายามรวมและประมวลผลชุดข้อมูลในฐานข้อมูลภายในและภายนอกเพื่อสร้างมุมมองที่เป็นหนึ่งเดียวของโปรไฟล์ลูกค้า กระตุ้นแนวคิดสำหรับคุณลักษณะที่เป็นนวัตกรรมใหม่ และเพิ่มการมีส่วนร่วมของแพลตฟอร์ม
ในสถานการณ์เหล่านี้ ลูกค้าที่กำลังมองหาข้อเสนอการผสานรวมข้อมูลแบบไร้เซิร์ฟเวอร์ AWS กาว เป็นองค์ประกอบหลักในการประมวลผลและจัดทำรายการข้อมูล AWS Glue ผสานรวมกับบริการของ AWS และผลิตภัณฑ์ของคู่ค้าได้เป็นอย่างดี และมีตัวเลือกในการแยก แปลง และโหลด (ETL) แบบโค้ดน้อย/ไม่ใช้โค้ด เพื่อเปิดใช้งานการวิเคราะห์ การเรียนรู้ของเครื่อง (ML) หรือเวิร์กโฟลว์การพัฒนาแอปพลิเคชัน งาน AWS Glue ETL อาจเป็นองค์ประกอบหนึ่งในไปป์ไลน์ที่ซับซ้อนกว่า การจัดการการเรียกใช้และการจัดการการขึ้นต่อกันระหว่างส่วนประกอบเหล่านี้เป็นความสามารถหลักในกลยุทธ์ข้อมูล เวิร์กโฟลว์ที่มีการจัดการของ Amazon สำหรับ Apache Airflow (Amazon MWAA) จัดการไปป์ไลน์ข้อมูลโดยใช้เทคโนโลยีแบบกระจาย รวมถึงทรัพยากรในองค์กร บริการของ AWS และส่วนประกอบของบุคคลที่สาม
ในโพสต์นี้ เราจะแสดงวิธีลดความซับซ้อนในการตรวจสอบงาน AWS Glue ที่จัดการโดย Airflow โดยใช้คุณสมบัติล่าสุดของ Amazon MWAA
ภาพรวมของโซลูชัน
โพสต์นี้กล่าวถึงสิ่งต่อไปนี้:
- วิธีอัปเกรดสภาพแวดล้อม Amazon MWAA เป็นเวอร์ชัน 2.4.3
- วิธีประสานงาน AWS Glue จาก Airflow กราฟ Acyclic กำกับ (แดก).
- การปรับปรุงความสามารถในการสังเกตของแพ็คเกจผู้ให้บริการ Airflow Amazon ใน Amazon MWAA ตอนนี้คุณสามารถรวมบันทึกการรันของงาน AWS Glue บนคอนโซล Airflow เพื่อลดความซับซ้อนในการแก้ปัญหาไปป์ไลน์ข้อมูล คอนโซล Amazon MWAA กลายเป็นข้อมูลอ้างอิงเดียวในการตรวจสอบและวิเคราะห์การเรียกใช้งาน AWS Glue ก่อนหน้านี้ ทีมสนับสนุนจำเป็นต้องเข้าถึง คอนโซลการจัดการ AWS และทำตามขั้นตอนด้วยตนเองสำหรับการเปิดเผยนี้ คุณลักษณะนี้พร้อมใช้งานตามค่าเริ่มต้นจาก Amazon MWAA เวอร์ชัน 2.4.3
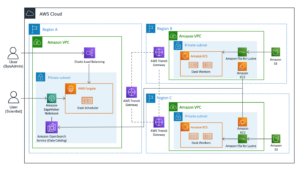
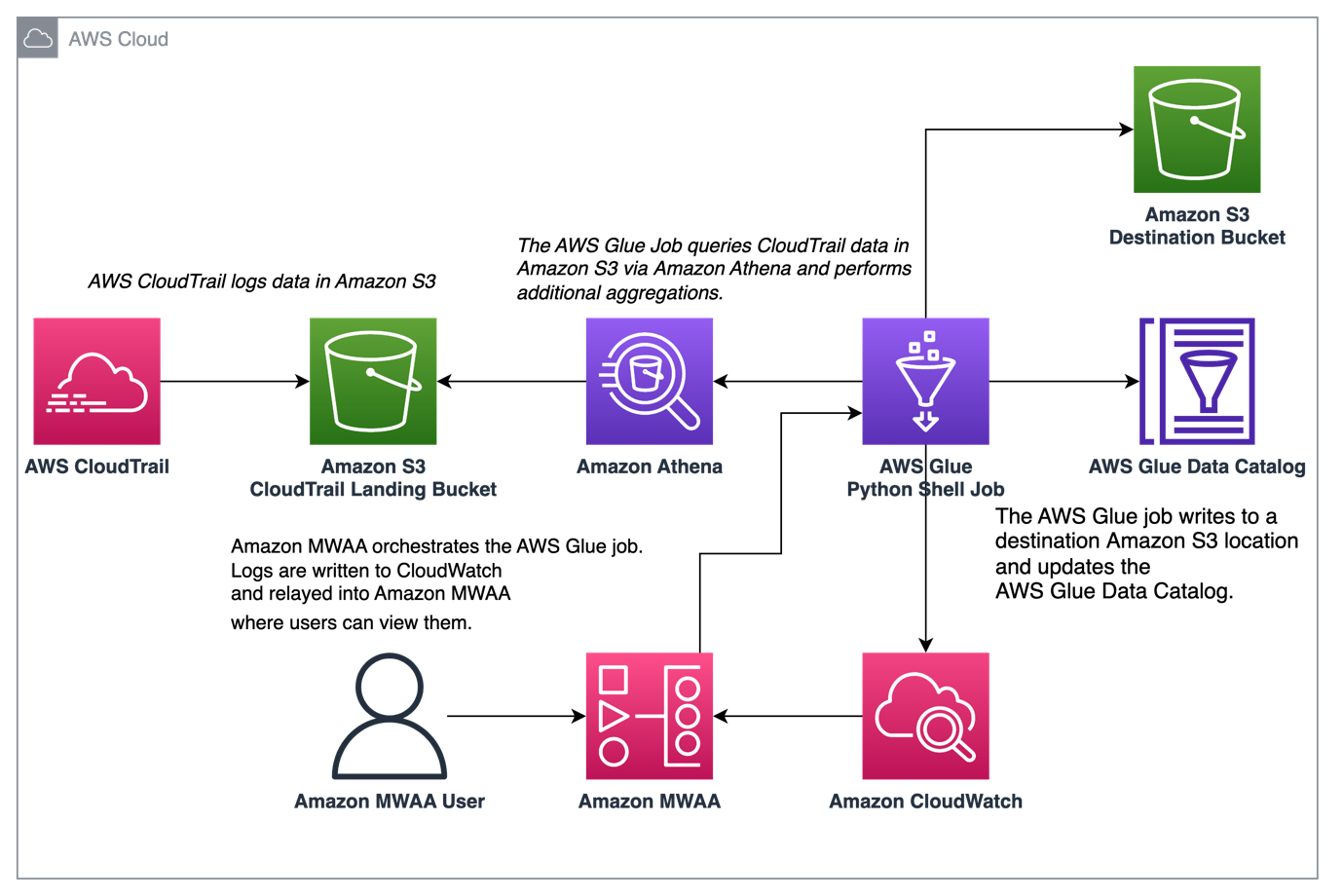
ไดอะแกรมต่อไปนี้แสดงสถาปัตยกรรมโซลูชันของเรา
เบื้องต้น
คุณต้องมีข้อกำหนดเบื้องต้นต่อไปนี้:
ตั้งค่าสภาพแวดล้อม Amazon MWAA
สำหรับคำแนะนำในการสร้างสภาพแวดล้อมของคุณ โปรดดูที่ สร้างสภาพแวดล้อม Amazon MWAA. สำหรับผู้ใช้ปัจจุบัน เราขอแนะนำให้อัปเกรดเป็นเวอร์ชัน 2.4.3 เพื่อใช้ประโยชน์จากการปรับปรุงความสามารถในการสังเกตที่มีในโพสต์นี้
ขั้นตอนในการอัปเกรด Amazon MWAA เป็นเวอร์ชัน 2.4.3 จะแตกต่างกันไปขึ้นอยู่กับว่าเวอร์ชันปัจจุบันคือ 1.10.12 หรือ 2.2.2 เราพูดถึงตัวเลือกทั้งสองในโพสต์นี้
ข้อกำหนดเบื้องต้นสำหรับการตั้งค่าสภาพแวดล้อม Amazon MWAA
คุณต้องปฏิบัติตามข้อกำหนดเบื้องต้นต่อไปนี้:
อัปเกรดจากเวอร์ชัน 1.10.12 เป็น 2.4.3
หากคุณใช้เวอร์ชัน Amazon MWAA 1.10.12, เอ่ยถึง การย้ายข้อมูลไปยังสภาพแวดล้อม Amazon MWAA ใหม่ เพื่ออัปเกรดเป็น 2.4.3
อัปเกรดจากเวอร์ชัน 2.0.2 หรือ 2.2.2 เป็น 2.4.3
หากคุณใช้สภาพแวดล้อม Amazon MWAA เวอร์ชัน 2.2.2 หรือต่ำกว่า ให้ทำตามขั้นตอนต่อไปนี้:
- สร้าง requirement.txt สำหรับการอ้างอิงที่กำหนดเอง ด้วยเวอร์ชันเฉพาะที่จำเป็นสำหรับ DAG ของคุณ
- อัปโหลดไฟล์ไปยัง Amazon S3 ในตำแหน่งที่เหมาะสมซึ่งสภาพแวดล้อมของ Amazon MWAA ชี้ไปที่ requirement.txt สำหรับการติดตั้งการขึ้นต่อกัน
- ทำตามขั้นตอนใน การย้ายข้อมูลไปยังสภาพแวดล้อม Amazon MWAA ใหม่ แล้วเลือกเวอร์ชั่น 2.4.3
อัปเดต DAG ของคุณ
ลูกค้าที่อัปเกรดจากสภาพแวดล้อม Amazon MWAA รุ่นเก่าอาจต้องอัปเดต DAG ที่มีอยู่ ใน Airflow เวอร์ชัน 2.4.3 สภาพแวดล้อม Airflow จะใช้แพ็คเกจผู้ให้บริการ Amazon เวอร์ชัน 6.0.0 ตามค่าเริ่มต้น แพ็คเกจนี้อาจรวมถึงการเปลี่ยนแปลงที่อาจเกิดขึ้นได้ เช่น การเปลี่ยนชื่อผู้ให้บริการ ตัวอย่างเช่น, AWSGlueJobOperator เลิกใช้แล้วและแทนที่ด้วย ผู้ปฏิบัติงานกาว. เพื่อรักษาความเข้ากันได้ ให้อัปเดต Airflow DAG ของคุณโดยแทนที่ตัวดำเนินการที่เลิกใช้แล้วหรือไม่รองรับจากเวอร์ชันก่อนหน้าด้วยตัวดำเนินการใหม่ ทำตามขั้นตอนต่อไปนี้:
- นำทางไปยัง ผู้ดำเนินการ Amazon AWS.
- เลือกเวอร์ชันที่เหมาะสมที่ติดตั้งในอินสแตนซ์ Amazon MWAA ของคุณ (6.0.0 โดยค่าเริ่มต้น) เพื่อค้นหารายการตัวดำเนินการ Airflow ที่รองรับ
- ทำการเปลี่ยนแปลงที่จำเป็นในโค้ด DAG ที่มีอยู่ และอัปโหลดไฟล์ที่แก้ไขไปยังตำแหน่ง DAG ใน Amazon S3
จัดการงาน AWS Glue จาก Airflow
ส่วนนี้ครอบคลุมรายละเอียดของการจัดการงาน AWS Glue ภายใน Airflow DAG Airflow ช่วยให้การพัฒนาไปป์ไลน์ข้อมูลง่ายขึ้นด้วยการพึ่งพาระหว่างระบบที่แตกต่างกัน เช่น กระบวนการในองค์กร การพึ่งพาภายนอก บริการ AWS อื่นๆ และอื่นๆ
ควบคุมการรวมบันทึก CloudTrail ด้วย AWS Glue และ Amazon MWAA
ในตัวอย่างนี้ เราจะพิจารณากรณีการใช้งานของการใช้ Amazon MWAA เพื่อจัดการงาน AWS Glue Python Shell ที่คงตัววัดแบบรวมตามบันทึกของ CloudTrail
CloudTrail ช่วยให้มองเห็นการเรียก AWS API ที่กำลังดำเนินการในบัญชี AWS ของคุณ กรณีการใช้งานทั่วไปที่มีข้อมูลนี้คือการรวบรวมเมตริกการใช้งานของตัวการที่ดำเนินการกับทรัพยากรของบัญชีของคุณสำหรับการตรวจสอบและความต้องการด้านกฎระเบียบ
เนื่องจากเหตุการณ์ CloudTrail ถูกบันทึก จึงจัดส่งเป็นไฟล์ JSON ใน Amazon S3 ซึ่งไม่เหมาะสำหรับการค้นหาเชิงวิเคราะห์ เราต้องการรวมข้อมูลนี้และคงไว้เป็นไฟล์ Parquet เพื่อให้การสืบค้นมีประสิทธิภาพสูงสุด ในขั้นตอนเริ่มต้น เราสามารถใช้ Athena เพื่อทำการสืบค้นข้อมูลเบื้องต้นก่อนที่จะทำการรวมเพิ่มเติมในงาน AWS Glue ของเรา สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการสร้างตาราง AWS Glue Data Catalog โปรดดูที่ การสร้างตารางสำหรับบันทึก CloudTrail ใน Athena โดยใช้การฉายภาพพาร์ติชัน ข้อมูล. หลังจากที่เราได้สำรวจข้อมูลผ่าน Athena และตัดสินใจว่าเราต้องการเก็บเมตริกใดไว้ในตารางรวม เราก็สามารถสร้างงาน AWS Glue ได้
สร้างตาราง CloudTrail ใน Athena
ขั้นแรก เราต้องสร้างตารางใน Data Catalog ของเราที่อนุญาตให้สืบค้นข้อมูล CloudTrail ผ่าน Athena แบบสอบถามตัวอย่างต่อไปนี้สร้างตารางที่มีสองพาร์ติชันในภูมิภาคและวันที่ (เรียกว่า snapshot_date) อย่าลืมแทนที่ตัวยึดตำแหน่งสำหรับบัคเก็ต CloudTrail, ID บัญชี AWS และชื่อตาราง CloudTrail:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')เรียกใช้การสืบค้นก่อนหน้าบนคอนโซล Athena และจดบันทึกชื่อตารางและฐานข้อมูล AWS Glue Data Catalog ที่ถูกสร้างขึ้น เราใช้ค่าเหล่านี้ในภายหลังในรหัส Airflow DAG
ตัวอย่างโค้ดงาน AWS Glue
รหัสต่อไปนี้เป็นตัวอย่าง งาน AWS Glue Python Shell ที่ทำสิ่งต่อไปนี้:
- รับข้อโต้แย้ง (ซึ่งเราส่งผ่านจาก Amazon MWAA DAG ของเรา) ในการประมวลผลข้อมูลของวันใด
- ใช้ไฟล์ AWS SDK สำหรับแพนด้า เพื่อเรียกใช้การสืบค้น Athena เพื่อทำการกรองเริ่มต้นของข้อมูล CloudTrail JSON ภายนอก AWS Glue
- ใช้ Pandas เพื่อทำการรวมอย่างง่ายกับข้อมูลที่กรอง
- ส่งออกข้อมูลรวมไปยัง AWS Glue Data Catalog ในตาราง
- ใช้การบันทึกระหว่างการประมวลผล ซึ่งจะมองเห็นได้ใน Amazon MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
ต่อไปนี้เป็นข้อได้เปรียบที่สำคัญบางประการในงาน AWS Glue นี้:
- เราใช้การสืบค้น Athena เพื่อให้แน่ใจว่าการกรองเบื้องต้นเสร็จสิ้นนอกงาน AWS Glue ของเรา ด้วยเหตุนี้ งาน Python Shell ที่มีการประมวลผลน้อยที่สุดจึงยังคงเพียงพอสำหรับการรวมชุดข้อมูล CloudTrail ขนาดใหญ่
- เรารับประกันว่า ตัวเลือกชุดไลบรารีการวิเคราะห์ เปิดอยู่เมื่อสร้างงาน AWS Glue เพื่อใช้ไลบรารี AWS SDK for Pandas
สร้างงาน AWS Glue
ทำตามขั้นตอนต่อไปนี้เพื่อสร้างงาน AWS Glue ของคุณ:
- คัดลอกสคริปต์ในส่วนก่อนหน้าและบันทึกลงในไฟล์ในเครื่อง สำหรับโพสต์นี้ ไฟล์ชื่อ
script.py. - บนคอนโซล AWS Glue ให้เลือก งาน ETL ในบานหน้าต่างนำทาง
- สร้างงานใหม่และเลือก โปรแกรมแก้ไขสคริปต์ Python Shell.
- เลือก อัปโหลดและแก้ไขสคริปต์ที่มีอยู่ และอัปโหลดไฟล์ที่คุณบันทึกไว้ในเครื่อง
- Choose สร้างบัญชีตัวแทน.

- เกี่ยวกับ รายละเอียดงาน แท็บ ป้อนชื่อสำหรับงาน AWS Glue ของคุณ
- สำหรับ บทบาท IAMเลือกบทบาทที่มีอยู่หรือสร้างบทบาทใหม่ที่มีสิทธิ์ที่จำเป็นสำหรับ Amazon S3, AWS Glue และ Athena บทบาทจำเป็นต้องค้นหาตาราง CloudTrail ที่คุณสร้างไว้ก่อนหน้านี้และเขียนไปยังตำแหน่งเอาต์พุต
คุณสามารถใช้รหัสนโยบายตัวอย่างต่อไปนี้ แทนที่ตัวยึดตำแหน่งด้วยบัคเก็ตบันทึก CloudTrail, ชื่อตารางเอาต์พุต, ฐานข้อมูล AWS Glue เอาต์พุต, บัคเก็ต S3 เอาต์พุต, ชื่อตาราง CloudTrail, ฐานข้อมูล AWS Glue ที่มีตาราง CloudTrail และ ID บัญชี AWS ของคุณ
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
สำหรับ เวอร์ชัน Pythonเลือก งูหลาม 3.9.
- เลือก โหลดไลบรารีการวิเคราะห์ทั่วไป.
- สำหรับ หน่วยประมวลผลข้อมูลเลือก 1 ปส.
- ปล่อยให้ตัวเลือกอื่นๆ เป็นค่าเริ่มต้นหรือปรับตามต้องการ

- Choose ลด เพื่อบันทึกการกำหนดค่างานของคุณ
กำหนดค่า Amazon MWAA DAG เพื่อจัดการงาน AWS Glue
โค้ดต่อไปนี้มีไว้สำหรับ DAG ที่สามารถจัดการงาน AWS Glue ที่เราสร้างขึ้น เราใช้ประโยชน์จากคุณสมบัติหลักต่อไปนี้ใน DAG นี้:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
เพิ่มความสามารถในการสังเกตของงาน AWS Glue ใน Amazon MWAA
งาน AWS Glue เขียนบันทึกไปที่ อเมซอน คลาวด์วอตช์. ด้วยการปรับปรุงความสามารถในการสังเกตล่าสุดของแพ็คเกจผู้ให้บริการ Amazon ของ Airflow บันทึกเหล่านี้รวมเข้ากับบันทึกงาน Airflow แล้ว การรวมเข้าด้วยกันนี้ช่วยให้ผู้ใช้ Airflow มองเห็นตั้งแต่ต้นทางถึงปลายทางได้โดยตรงใน Airflow UI ทำให้ไม่ต้องค้นหาใน CloudWatch หรือ AWS Glue Console
หากต้องการใช้คุณลักษณะนี้ ตรวจสอบให้แน่ใจว่าบทบาท IAM ที่แนบกับสภาพแวดล้อม Amazon MWAA มีสิทธิ์ต่อไปนี้ในการดึงและเขียนบันทึกที่จำเป็น:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}ถ้า verbose=true บันทึกการรันงาน AWS Glue จะแสดงในบันทึกงาน Airflow ค่าดีฟอลต์เป็นเท็จ สำหรับข้อมูลเพิ่มเติม โปรดดูที่ พารามิเตอร์.
เมื่อเปิดใช้งาน DAG จะอ่านจากสตรีมบันทึก CloudWatch ของงาน AWS Glue และส่งต่อไปยังบันทึกขั้นตอนงาน AWS Glue ของ Airflow DAG ข้อมูลนี้ให้ข้อมูลเชิงลึกโดยละเอียดเกี่ยวกับการรันงาน AWS Glue ตามเวลาจริงผ่านบันทึก DAG โปรดทราบว่างาน AWS Glue สร้างเอาต์พุตและกลุ่มบันทึก CloudWatch ข้อผิดพลาดตาม STDOUT และ STDERR ของงานตามลำดับ บันทึกทั้งหมดในกลุ่มบันทึกผลลัพธ์และบันทึกข้อยกเว้นหรือข้อผิดพลาดจากกลุ่มบันทึกข้อผิดพลาดจะถูกส่งต่อไปยัง Amazon MWAA
ขณะนี้ผู้ดูแลระบบ AWS สามารถจำกัดการเข้าถึงของทีมสนับสนุนได้เฉพาะ Airflow ทำให้ Amazon MWAA เป็นกระจกบานเดียวในการจัดการงานและการจัดการความสมบูรณ์ของงาน ก่อนหน้านี้ ผู้ใช้จำเป็นต้องตรวจสอบสถานะการรันงาน AWS Glue ในขั้นตอน Airflow DAG และเรียกข้อมูลตัวระบุการรันงาน จากนั้น พวกเขาจำเป็นต้องเข้าถึง AWS Glue Console เพื่อค้นหาประวัติการเรียกใช้งาน ค้นหางานที่สนใจโดยใช้ตัวระบุ และสุดท้ายไปที่บันทึก CloudWatch ของงานเพื่อแก้ไขปัญหา
สร้าง DAG
หากต้องการสร้าง DAG ให้ทำตามขั้นตอนต่อไปนี้:
- บันทึกโค้ด DAG ก่อนหน้าลงในไฟล์ .py ในเครื่อง โดยแทนที่ตัวยึดตำแหน่งที่ระบุ
ควรทราบค่าสำหรับ ID บัญชี AWS, ชื่องาน AWS Glue, ฐานข้อมูล AWS Glue ที่มีตาราง CloudTrail และชื่อตาราง CloudTrail อยู่แล้ว คุณสามารถปรับเอาต์พุต S3 Bucket, เอาต์พุตฐานข้อมูล AWS Glue และชื่อตารางเอาต์พุตได้ตามต้องการ แต่ตรวจสอบให้แน่ใจว่าบทบาท IAM ของงาน AWS Glue ที่คุณใช้ก่อนหน้านี้ได้รับการกำหนดค่าตามนั้น
- บนคอนโซล Amazon MWAA ให้ไปที่สภาพแวดล้อมของคุณเพื่อดูว่าโค้ด DAG ถูกเก็บไว้ที่ใด
โฟลเดอร์ DAGs คือส่วนนำหน้าภายในบัคเก็ต S3 ที่ควรวางไฟล์ DAG ของคุณ
- อัปโหลดไฟล์ที่แก้ไขของคุณที่นั่น

- เปิดคอนโซล Amazon MWAA เพื่อยืนยันว่า DAG ปรากฏในตาราง

เรียกใช้ DAG
ในการรัน DAG ให้ทำตามขั้นตอนต่อไปนี้:
- เลือกจากตัวเลือกต่อไปนี้:
- ทริกเกอร์DAG – ทำให้ข้อมูลของเมื่อวานถูกใช้เป็นข้อมูลในการประมวลผล
- ทริกเกอร์ DAG พร้อมการกำหนดค่า – ด้วยตัวเลือกนี้ คุณสามารถส่งผ่านวันที่อื่นได้ ซึ่งเป็นไปได้ว่าจะมีการทดแทน ซึ่งดึงข้อมูลมาโดยใช้
dag_run.confในโค้ด DAG แล้วส่งผ่านไปยังงาน AWS Glue เป็นพารามิเตอร์

ภาพหน้าจอต่อไปนี้แสดงตัวเลือกการกำหนดค่าเพิ่มเติม หากคุณเลือก ทริกเกอร์ DAG พร้อมการกำหนดค่า.

- ตรวจสอบ DAG ขณะที่มันทำงาน
- เมื่อ DAG เสร็จสมบูรณ์ ให้เปิดรายละเอียดการวิ่ง
ในบานหน้าต่างด้านขวา คุณสามารถดูบันทึก หรือเลือก รายละเอียดอินสแตนซ์ของงาน เพื่อดูแบบเต็ม

- ดูบันทึกเอาต์พุตงาน AWS Glue ใน Amazon MWAA โดยไม่ต้องใช้คอนโซล AWS Glue ด้วย
GlueJobOperatorธงอย่างละเอียด

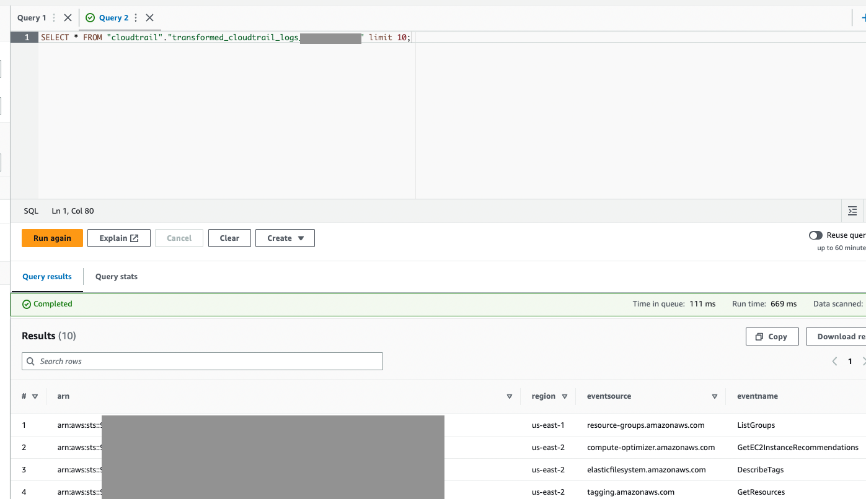
งาน AWS Glue จะเขียนผลลัพธ์ไปยังตารางผลลัพธ์ที่คุณระบุ
- สอบถามตารางนี้ผ่าน Athena เพื่อยืนยันว่าสำเร็จ
สรุป
ตอนนี้ Amazon MWAA เป็นที่เดียวในการติดตามสถานะงาน AWS Glue และช่วยให้คุณใช้คอนโซล Airflow เป็นกระจกบานเดียวสำหรับการประสานงานและการจัดการสถานภาพ ในโพสต์นี้ เราแนะนำขั้นตอนต่างๆ เพื่อจัดการงาน AWS Glue ผ่าน Airflow โดยใช้ GlueJobOperator. ด้วยการปรับปรุงความสามารถในการสังเกตใหม่ คุณสามารถแก้ไขปัญหางาน AWS Glue ได้อย่างราบรื่นในประสบการณ์ที่เป็นหนึ่งเดียว นอกจากนี้ เรายังสาธิตวิธีอัปเกรดสภาพแวดล้อม Amazon MWAA ของคุณเป็นเวอร์ชันที่เข้ากันได้ อัปเดตการอ้างอิง และเปลี่ยนนโยบายบทบาท IAM ให้สอดคล้องกัน
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับขั้นตอนการแก้ไขปัญหาทั่วไป โปรดดูที่ การแก้ไขปัญหา: การสร้างและอัปเดตสภาพแวดล้อม Amazon MWAA. สำหรับรายละเอียดเชิงลึกของการย้ายไปยังสภาพแวดล้อม Amazon MWAA โปรดดูที่ อัปเกรดจาก 1.10 เป็น 2. หากต้องการเรียนรู้เกี่ยวกับการเปลี่ยนแปลงรหัสโอเพ่นซอร์สเพื่อเพิ่มความสามารถในการสังเกตงาน AWS Glue ในแพ็คเกจผู้ให้บริการ Airflow Amazon โปรดดูที่ บันทึกการส่งต่อจากงาน AWS Glue.
สุดท้ายนี้ เราขอแนะนำให้ไปที่ บล็อก AWS Big Data สำหรับเนื้อหาอื่นๆ เกี่ยวกับการวิเคราะห์ ML และการกำกับดูแลข้อมูลบน AWS
เกี่ยวกับผู้เขียน
 รัชบาห์ โลกานด์ เป็นวิศวกรข้อมูลและ ML ที่มี AWS Professional Services Analytics Practice เขาช่วยให้ลูกค้าใช้บิ๊กดาต้า แมชชีนเลิร์นนิง และโซลูชันการวิเคราะห์ นอกเวลางาน เขาชอบใช้เวลากับครอบครัว อ่านหนังสือ วิ่ง และตีกอล์ฟ
รัชบาห์ โลกานด์ เป็นวิศวกรข้อมูลและ ML ที่มี AWS Professional Services Analytics Practice เขาช่วยให้ลูกค้าใช้บิ๊กดาต้า แมชชีนเลิร์นนิง และโซลูชันการวิเคราะห์ นอกเวลางาน เขาชอบใช้เวลากับครอบครัว อ่านหนังสือ วิ่ง และตีกอล์ฟ
 ไรอัน โกเมส เป็นวิศวกรข้อมูลและ ML ที่มี AWS Professional Services Analytics Practice เขามีความกระตือรือร้นในการช่วยให้ลูกค้าได้รับผลลัพธ์ที่ดีขึ้นผ่านโซลูชันการวิเคราะห์และการเรียนรู้ของเครื่องในระบบคลาวด์ นอกเวลางาน เขาชอบออกกำลังกาย ทำอาหาร และใช้เวลาคุณภาพกับเพื่อนและครอบครัว
ไรอัน โกเมส เป็นวิศวกรข้อมูลและ ML ที่มี AWS Professional Services Analytics Practice เขามีความกระตือรือร้นในการช่วยให้ลูกค้าได้รับผลลัพธ์ที่ดีขึ้นผ่านโซลูชันการวิเคราะห์และการเรียนรู้ของเครื่องในระบบคลาวด์ นอกเวลางาน เขาชอบออกกำลังกาย ทำอาหาร และใช้เวลาคุณภาพกับเพื่อนและครอบครัว
 วิศวคุปตะ เป็นสถาปนิกข้อมูลอาวุโสที่มี AWS Professional Services Analytics Practice เขาช่วยให้ลูกค้าใช้ข้อมูลขนาดใหญ่และโซลูชันการวิเคราะห์ นอกเวลางาน เขาชอบใช้เวลากับครอบครัว ท่องเที่ยว และลองอาหารใหม่ๆ
วิศวคุปตะ เป็นสถาปนิกข้อมูลอาวุโสที่มี AWS Professional Services Analytics Practice เขาช่วยให้ลูกค้าใช้ข้อมูลขนาดใหญ่และโซลูชันการวิเคราะห์ นอกเวลางาน เขาชอบใช้เวลากับครอบครัว ท่องเที่ยว และลองอาหารใหม่ๆ
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตไอสตรีม. ข้อมูลอัจฉริยะ Web3 ขยายความรู้ เข้าถึงได้ที่นี่.
- การสร้างอนาคตโดย Adryenn Ashley เข้าถึงได้ที่นี่.
- ซื้อและขายหุ้นในบริษัท PRE-IPO ด้วย PREIPO® เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 1
- 10
- 100
- 12
- 8
- a
- เกี่ยวกับเรา
- เข้า
- ตาม
- ลงชื่อเข้าใช้
- บรรลุ
- ข้าม
- การกระทำ
- วัฏจักร
- เพิ่มเติม
- ความได้เปรียบ
- ข้อได้เปรียบ
- หลังจาก
- การรวมตัว
- ทั้งหมด
- อนุญาต
- ช่วยให้
- แล้ว
- ด้วย
- อเมซอน
- Amazon Web Services
- an
- วิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- และ
- ใด
- อาปาเช่
- API
- การใช้งาน
- การพัฒนาโปรแกรมประยุกต์
- เหมาะสม
- สถาปัตยกรรม
- เป็น
- อาร์กิวเมนต์
- ข้อโต้แย้ง
- AS
- At
- แอตทริบิวต์
- การตรวจสอบบัญชี
- ใช้ได้
- AWS
- AWS กาว
- บริการระดับมืออาชีพของ AWS
- ตาม
- BE
- จะกลายเป็น
- รับ
- ก่อน
- กำลัง
- ดีกว่า
- ระหว่าง
- ใหญ่
- ข้อมูลขนาดใหญ่
- ทั้งสอง
- หมดสภาพ
- สร้าง
- แต่
- by
- ที่เรียกว่า
- โทร
- CAN
- กรณี
- กรณี
- แค็ตตาล็อก
- สาเหตุที่
- เปลี่ยนแปลง
- การเปลี่ยนแปลง
- ตรวจสอบ
- Choose
- เมฆ
- รหัส
- COM
- รวมกัน
- ความเห็น
- ร่วมกัน
- บริษัท
- ความเข้ากันได้
- เข้ากันได้
- สมบูรณ์
- ซับซ้อน
- ส่วนประกอบ
- ส่วนประกอบ
- คำนวณ
- องค์ประกอบ
- ยืนยัน
- ปลอบใจ
- รวบรวม
- การรวบรวม
- การปรุงอาหาร
- แกน
- ครอบคลุม
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- การสร้าง
- ปัจจุบัน
- ประเพณี
- ลูกค้า
- ลูกค้า
- DAG
- ข้อมูล
- การรวมข้อมูล
- การประมวลผล
- กลยุทธ์ข้อมูล
- คลังข้อมูล
- ฐานข้อมูล
- ฐานข้อมูล
- ชุดข้อมูล
- วันที่
- วันที่
- วันเวลา
- วัน
- ตัดสินใจ
- ค่าเริ่มต้น
- ส่ง
- แสดงให้เห็นถึง
- ทั้งนี้ขึ้นอยู่กับ
- เลิก
- รายละเอียด
- รายละเอียด
- พัฒนาการ
- แตกต่าง
- ต่าง
- ดิจิตอล
- สื่อดิจิทัล
- โดยตรง
- สนทนา
- กระจาย
- ระบบกระจาย
- do
- ทำ
- การทำ
- ทำ
- ในระหว่าง
- e
- ก่อน
- eases
- ผล
- การกำจัด
- อื่น
- ทำให้สามารถ
- เปิดการใช้งาน
- ช่วยให้
- จบสิ้น
- มีส่วนร่วม
- วิศวกร
- ปรับปรุง
- ทำให้มั่นใจ
- เข้าสู่
- สิ่งแวดล้อม
- ความผิดพลาด
- อีเธอร์ (ETH)
- เหตุการณ์
- ตัวอย่าง
- ยกเว้น
- ข้อยกเว้น
- มีอยู่
- ที่มีอยู่
- ที่มีอยู่
- ประสบการณ์
- ประสบการณ์
- สำรวจ
- การแสดงออก
- ภายนอก
- สารสกัด
- ล้มเหลว
- เท็จ
- ครอบครัว
- ลักษณะ
- ที่โดดเด่น
- คุณสมบัติ
- เนื้อไม่มีมัน
- ไฟล์
- กรอง
- ในที่สุด
- หา
- ออกกำลังกาย
- ดังต่อไปนี้
- อาหาร
- สำหรับ
- รูป
- เพื่อน
- ราคาเริ่มต้นที่
- เต็ม
- รวบรวม
- สร้าง
- กระจก
- Go
- กอล์ฟ
- การกำกับดูแล
- บัญชีกลุ่ม
- Hadoop
- มี
- he
- สุขภาพ
- การช่วยเหลือ
- จะช่วยให้
- ประวัติ
- รัง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- ที่ http
- HTTPS
- AMI
- ID
- ในอุดมคติ
- ความคิด
- ระบุ
- if
- แสดงให้เห็นถึง
- การดำเนินการ
- นำเข้า
- in
- ลึกซึ้ง
- ประกอบด้วย
- รวมทั้ง
- เพิ่ม
- เพิ่มขึ้น
- แสดงว่า
- อุตสาหกรรม
- ข้อมูล
- ข้อมูล
- แรกเริ่ม
- นวัตกรรม
- ข้อมูลเชิงลึก
- การติดตั้ง
- ตัวอย่าง
- คำแนะนำการใช้
- แบบบูรณาการ
- บูรณาการ
- อยากเรียนรู้
- ภายใน
- เข้าไป
- IT
- การสัมภาษณ์
- งาน
- jpg
- JSON
- คีย์
- ที่รู้จักกัน
- ใหญ่
- ต่อมา
- ล่าสุด
- เรียนรู้
- การเรียนรู้
- ห้องสมุด
- LIMIT
- รายการ
- โหลด
- ในประเทศ
- ในท้องถิ่น
- ที่ตั้ง
- เข้าสู่ระบบ
- เข้า
- การเข้าสู่ระบบ
- ที่ต้องการหา
- เครื่อง
- เรียนรู้เครื่อง
- ทำ
- เก็บรักษา
- ทำ
- การทำ
- การจัดการ
- การจัดการ
- การจัดการ
- คู่มือ
- วัสดุ
- อาจ..
- ภาพบรรยากาศ
- พบ
- ข่าวสาร
- ตัวชี้วัด
- การโยกย้าย
- ต่ำสุด
- ML
- การแก้ไข
- โมดูล
- การตรวจสอบ
- การตรวจสอบ
- ข้อมูลเพิ่มเติม
- ต้อง
- ชื่อ
- ชื่อ
- นำทาง
- การเดินเรือ
- จำเป็น
- จำเป็นต้อง
- จำเป็น
- ความต้องการ
- ใหม่
- ไม่มีอะไร
- ตอนนี้
- of
- การเสนอ
- on
- ONE
- คน
- เพียง
- เปิด
- โอเพนซอร์ส
- รหัสโอเพนซอร์ซ
- ผู้ประกอบการ
- ผู้ประกอบการ
- ดีที่สุด
- ตัวเลือกเสริม (Option)
- Options
- or
- บงการ
- ประสาน
- อื่นๆ
- ของเรา
- ผลลัพธ์
- เอาท์พุต
- ด้านนอก
- แพ็คเกจ
- หมีแพนด้า
- บานหน้าต่าง
- พารามิเตอร์
- หุ้นส่วน
- ส่ง
- ผ่าน
- หลงใหล
- การปฏิบัติ
- สิทธิ์
- ยังคงมีอยู่
- ท่อ
- สถานที่
- เวที
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- จุด
- นโยบาย
- โพสต์
- ที่อาจเกิดขึ้น
- การปฏิบัติ
- ข้อกำหนดเบื้องต้น
- ก่อน
- ก่อนหน้านี้
- กระบวนการ
- กระบวนการ
- การประมวลผล
- ผลิตภัณฑ์
- มืออาชีพ
- มืออาชีพ
- ดูรายละเอียด
- เงื้อม
- ผู้จัดหา
- ผู้ให้บริการ
- ให้
- หลาม
- คุณภาพ
- คำสั่ง
- ยก
- พิสัย
- อ่าน
- การอ่าน
- จริง
- เรียลไทม์
- เมื่อเร็ว ๆ นี้
- แนะนำ
- ภูมิภาค
- หน่วยงานกำกับดูแล
- ถ่ายทอด
- แทนที่
- แทนที่
- จำเป็นต้องใช้
- ความต้องการ
- ทรัพยากร
- แหล่งข้อมูล
- ตามลำดับ
- คำตอบ
- ผลสอบ
- รักษา
- ขวา
- บทบาท
- แถว
- วิ่ง
- วิ่ง
- s
- ลด
- สถานการณ์
- SDK
- ได้อย่างลงตัว
- ค้นหา
- Section
- ปลอดภัย
- เห็น
- แสวงหา
- ระดับอาวุโส
- serverless
- บริการ
- การตั้งค่า
- การติดตั้ง
- เปลือก
- น่า
- โชว์
- แสดงให้เห็นว่า
- ง่าย
- ลดความซับซ้อน
- ตั้งแต่
- เดียว
- ภาพย่อ
- ทางออก
- โซลูชัน
- บาง
- โดยเฉพาะ
- ที่ระบุไว้
- การใช้จ่าย
- คำแถลง
- Status
- ขั้นตอน
- ขั้นตอน
- ยังคง
- การเก็บรักษา
- เก็บไว้
- กลยุทธ์
- กระแส
- เชือก
- ที่ประสบความสำเร็จ
- อย่างเช่น
- เพียงพอ
- สนับสนุน
- ที่สนับสนุน
- ระบบ
- ตาราง
- เอา
- การ
- งาน
- ทีม
- เทคโนโลยี
- เทมเพลต
- ขอบคุณ
- ที่
- พื้นที่
- ของพวกเขา
- พวกเขา
- แล้วก็
- ที่นั่น
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- ของบุคคลที่สาม
- นี้
- ตลอด
- เวลา
- ไปยัง
- ลู่
- แปลง
- การเดินทาง
- จริง
- ลอง
- อังคาร
- หัน
- สอง
- ชนิด
- ui
- ปึกแผ่น
- หน่วย
- บันทึก
- การปรับปรุง
- การปรับปรุง
- อัพเกรด
- อัพเกรด
- อัปโหลด
- การใช้
- ใช้
- ใช้กรณี
- มือสอง
- ผู้ใช้
- การใช้
- ความคุ้มค่า
- ความคุ้มค่า
- รุ่น
- ผ่านทาง
- รายละเอียด
- ยอดวิว
- ความชัดเจน
- มองเห็นได้
- เดิน
- ต้องการ
- คือ
- we
- เว็บ
- บริการเว็บ
- ดี
- อะไร
- เมื่อ
- ว่า
- ที่
- WHO
- จะ
- กับ
- ภายใน
- ไม่มี
- งาน
- ขั้นตอนการทำงาน
- จะ
- เขียน
- เขียน
- เธอ
- ของคุณ
- ลมทะเล