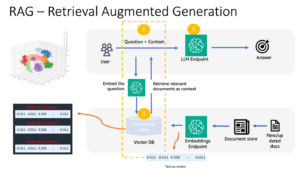
ป่าชายเลนเป็นส่วนนำเข้าของระบบนิเวศที่ดี และกิจกรรมของมนุษย์เป็นหนึ่งในสาเหตุหลักที่ทำให้ป่าเหล่านี้ค่อยๆ หายไปจากแนวชายฝั่งทั่วโลก การใช้แบบจำลองแมชชีนเลิร์นนิง (ML) เพื่อระบุพื้นที่ป่าชายเลนจากภาพถ่ายดาวเทียมช่วยให้นักวิจัยสามารถตรวจสอบขนาดของป่าได้อย่างมีประสิทธิภาพเมื่อเวลาผ่านไป ใน 1 หมายเลข ของชุดนี้ เราแสดงวิธีการรวบรวมข้อมูลดาวเทียมในแบบอัตโนมัติและวิเคราะห์ใน สตูดิโอ Amazon SageMaker ด้วยการแสดงภาพแบบโต้ตอบ ในโพสต์นี้เราจะแสดงวิธีการใช้งาน ระบบนำร่องอัตโนมัติของ Amazon SageMaker เพื่อทำให้กระบวนการสร้างตัวแยกประเภทป่าชายเลนเป็นไปโดยอัตโนมัติ
ฝึกโมเดลด้วย Autopilot
Autopilot ให้วิธีที่สมดุลในการสร้างหลายรุ่นและเลือกรุ่นที่ดีที่สุด ขณะสร้างการผสมผสานเทคนิคการประมวลผลข้อมูลล่วงหน้าและโมเดล ML ที่หลากหลายโดยใช้ความพยายามเพียงเล็กน้อย Autopilot ให้การควบคุมขั้นตอนส่วนประกอบเหล่านี้อย่างสมบูรณ์แก่นักวิทยาศาสตร์ข้อมูล หากต้องการ
คุณสามารถใช้ Autopilot ได้โดยใช้หนึ่งใน AWS SDK (รายละเอียดอยู่ใน คู่มืออ้างอิง API สำหรับ Autopilot) หรือผ่าน Studio เราใช้ Autopilot ในโซลูชัน Studio โดยทำตามขั้นตอนที่อธิบายไว้ในส่วนนี้:
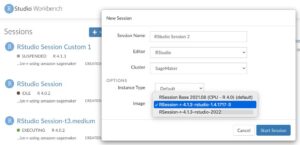
- ในหน้า Studio Launcher ให้เลือกเครื่องหมายบวกสำหรับ การทดลอง Autopilot ใหม่.

- สำหรับ เชื่อมต่อข้อมูลของคุณให้เลือก ค้นหาถัง S3และป้อนชื่อบัคเก็ตที่คุณเก็บชุดข้อมูลการฝึกอบรมและทดสอบไว้
- สำหรับ ชื่อไฟล์ชุดข้อมูล, ป้อนชื่อไฟล์ข้อมูลการฝึกที่คุณสร้างใน เตรียมข้อมูลการอบรม ส่วนเข้า 1 หมายเลข.
- สำหรับ ตำแหน่งข้อมูลเอาต์พุต (บัคเก็ต S3)ป้อนชื่อที่เก็บข้อมูลเดียวกันกับที่คุณใช้ในขั้นตอนที่ 2
- สำหรับ ชื่อไดเร็กทอรีชุดข้อมูลให้ป้อนชื่อโฟลเดอร์ใต้ที่เก็บข้อมูลที่คุณต้องการให้ Autopilot จัดเก็บสิ่งประดิษฐ์
- สำหรับ อินพุต S3 ของคุณเป็นไฟล์รายการหรือไม่เลือก Off.
- สำหรับ เป้าเลือก ฉลาก.
- สำหรับ ปรับใช้อัตโนมัติเลือก Off.
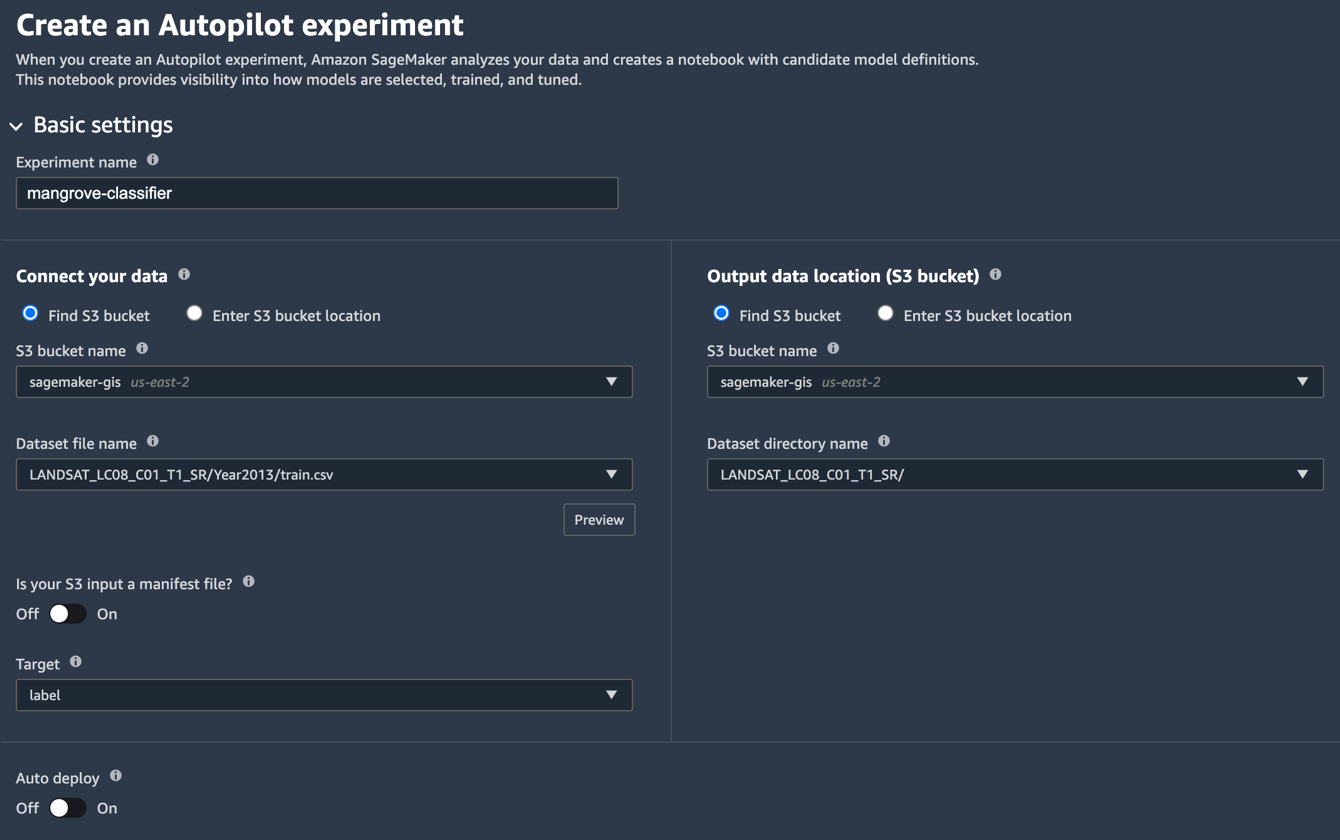
- ภายใต้ ตั้งค่าขั้นสูงสำหรับ ประเภทปัญหาการเรียนรู้ของเครื่องเลือก การจำแนกไบนารี.
- สำหรับ ตัวชี้วัดวัตถุประสงค์เลือก AUC.
- สำหรับ เลือกวิธีเรียกใช้การทดสอบของคุณเลือก ไม่ เรียกใช้โครงการนำร่องเพื่อสร้างสมุดบันทึกที่มีคำจำกัดความของผู้สมัคร.
- Choose สร้างการทดสอบ.

สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการสร้างการทดสอบ โปรดดูที่ สร้างการทดลอง Amazon SageMaker Autopilot. อาจใช้เวลาประมาณ 15 นาทีในการรันขั้นตอนนี้ - เมื่อเสร็จแล้วให้เลือก เปิดสมุดบันทึกการสร้างผู้สมัครซึ่งเปิดสมุดบันทึกใหม่ในโหมดอ่านอย่างเดียว

- Choose นำเข้าโน๊ตบุ๊ค เพื่อให้สมุดบันทึกสามารถแก้ไขได้

- สำหรับรูปภาพ เลือก ข้อมูลวิทยาศาสตร์.
- สำหรับ เมล็ดเลือก งูหลาม 3.
- Choose เลือก.
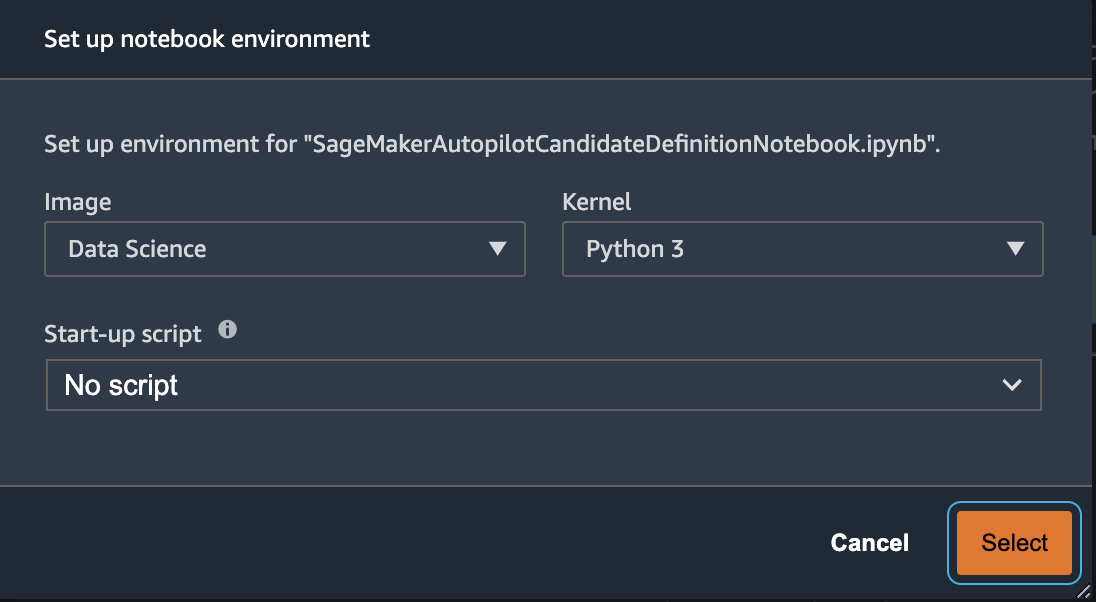
สมุดบันทึกที่สร้างขึ้นโดยอัตโนมัตินี้มีคำอธิบายโดยละเอียดและให้การควบคุมที่สมบูรณ์สำหรับงานสร้างแบบจำลองจริงที่จะปฏิบัติตาม เวอร์ชันที่กำหนดเองของ สมุดบันทึกซึ่งตัวจำแนกประเภทได้รับการฝึกอบรมโดยใช้คลื่นความถี่ Landsat จากปี 2013 มีอยู่ในที่เก็บรหัสภายใต้ notebooks/mangrove-2013.ipynb.
กรอบงานการสร้างแบบจำลองประกอบด้วยสองส่วน: การแปลงคุณลักษณะซึ่งเป็นส่วนหนึ่งของขั้นตอนการประมวลผลข้อมูล และการปรับให้เหมาะสมของพารามิเตอร์ไฮเปอร์พารามิเตอร์ (HPO) ซึ่งเป็นส่วนหนึ่งของขั้นตอนการเลือกแบบจำลอง สิ่งประดิษฐ์ที่จำเป็นสำหรับงานเหล่านี้ทั้งหมดถูกสร้างขึ้นระหว่างการทดลอง Autopilot และบันทึกไว้ใน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (อเมซอน เอส3). เซลล์โน้ตบุ๊กเครื่องแรกดาวน์โหลดสิ่งประดิษฐ์เหล่านั้นจาก Amazon S3 ลงในเครื่อง อเมซอน SageMaker ระบบไฟล์สำหรับการตรวจสอบและการแก้ไขที่จำเป็น มีสองโฟลเดอร์: generated_module และ sagemaker_automlที่ซึ่งโมดูลและสคริปต์ Python ทั้งหมดที่จำเป็นต่อการเรียกใช้โน้ตบุ๊กจะถูกจัดเก็บไว้ ขั้นตอนการแปลงคุณลักษณะต่างๆ เช่น การใส่แทน การปรับสเกล และ PCA จะถูกบันทึกเป็น generated_modules/candidate_data_processors/dpp*.py.
Autopilot สร้างโมเดลที่แตกต่างกันสามแบบตามอัลกอริทึม XGBoost, ผู้เรียนเชิงเส้นตรง และอัลกอริธึม Perceptron หลายชั้น (MLP) ไปป์ไลน์ผู้สมัครประกอบด้วยหนึ่งในตัวเลือกการแปลงคุณลักษณะที่เรียกว่า data_transformerและอัลกอริทึม ไปป์ไลน์คือพจนานุกรม Python และสามารถกำหนดได้ดังนี้:
ในตัวอย่างนี้ ไปป์ไลน์แปลงข้อมูลการฝึกตามสคริปต์ใน generated_modules/candidate_data_processors/dpp5.py และสร้างโมเดล XGBoost นี่คือที่ที่ Autopilot ให้การควบคุมอย่างสมบูรณ์แก่นักวิทยาศาสตร์ข้อมูล ซึ่งสามารถเลือกการแปลงคุณลักษณะที่สร้างขึ้นโดยอัตโนมัติและขั้นตอนการเลือกแบบจำลอง หรือสร้างชุดค่าผสมของตนเอง
คุณสามารถเพิ่มไปป์ไลน์ไปยังพูลเพื่อให้ Autopilot ทำการทดสอบได้ดังนี้:
นี่เป็นขั้นตอนสำคัญที่คุณสามารถเลือกเก็บเฉพาะชุดย่อยของผู้สมัครที่แนะนำโดย Autopilot ตามความเชี่ยวชาญในหัวข้อนั้นๆ เพื่อลดรันไทม์ทั้งหมด ในตอนนี้ ให้เก็บคำแนะนำ Autopilot ไว้ทั้งหมด ซึ่งคุณสามารถระบุได้ดังนี้:
| ชื่อผู้สมัคร | ขั้นตอนวิธี | คุณสมบัติ Transformer |
| dpp0-xgboost | xgboost | dpp0.py |
| dpp1-xgboost | xgboost | dpp1.py |
| dpp2-linear-ผู้เรียน | ผู้เรียนเชิงเส้น | dpp2.py |
| dpp3-xgboost | xgboost | dpp3.py |
| dpp4-xgboost | xgboost | dpp4.py |
| dpp5-xgboost | xgboost | dpp5.py |
| dpp6-มล | MLP | dpp6.py |
การทดสอบ Autopilot ฉบับสมบูรณ์นั้นทำในสองส่วน ก่อนอื่น คุณต้องรันงานการแปลงข้อมูล:
ขั้นตอนนี้ควรเสร็จสิ้นภายใน 30 นาทีสำหรับผู้สมัครทั้งหมด หากคุณไม่ได้ทำการแก้ไขเพิ่มเติมใน dpp*.py ไฟล์
ขั้นตอนต่อไปคือการสร้างชุดโมเดลที่ดีที่สุดโดยการปรับไฮเปอร์พารามิเตอร์สำหรับอัลกอริธึมที่เกี่ยวข้อง พารามิเตอร์ไฮเปอร์มักจะแบ่งออกเป็นสองส่วน: แบบคงที่และแบบปรับได้ พารามิเตอร์ไฮเปอร์พารามิเตอร์แบบคงที่ยังคงไม่เปลี่ยนแปลงตลอดการทดสอบสำหรับตัวเลือกทั้งหมดที่ใช้อัลกอริทึมเดียวกัน ไฮเปอร์พารามิเตอร์เหล่านี้ถูกส่งไปยังการทดลองเป็นพจนานุกรม หากคุณเลือกเลือกโมเดล XGBoost ที่ดีที่สุดโดยเพิ่ม AUC ให้สูงสุดจากแผนการตรวจสอบข้ามห้าเท่าสามรอบ พจนานุกรมจะมีลักษณะดังนี้:
สำหรับไฮเปอร์พารามิเตอร์ที่ปรับได้ คุณต้องส่งพจนานุกรมอื่นที่มีช่วงและประเภทการปรับขนาด:
มีไฮเปอร์พารามิเตอร์ครบชุดใน mangrove-2013.ipynb สมุดบันทึก.
ในการสร้างการทดสอบที่สามารถทดสอบผู้สมัครทั้งเจ็ดพร้อมกันได้ ให้สร้างเครื่องรับ HPO แบบหลายอัลกอริทึม:
ตัวชี้วัดวัตถุประสงค์ถูกกำหนดอย่างอิสระสำหรับแต่ละอัลกอริทึม:
การลองใช้ค่าไฮเปอร์พารามิเตอร์ที่เป็นไปได้ทั้งหมดสำหรับการทดลองทั้งหมดนั้นเป็นการสิ้นเปลือง คุณสามารถใช้กลยุทธ์ Bayesian เพื่อสร้างเครื่องรับ HPO:
ในการตั้งค่าเริ่มต้น Autopilot จะเลือกงาน 250 งานในเครื่องรับสัญญาณเพื่อเลือกรุ่นที่ดีที่สุด สำหรับกรณีการใช้งานนี้ก็เพียงพอแล้วที่จะตั้งค่า max_jobs=50 เพื่อประหยัดเวลาและทรัพยากร โดยไม่มีการลงโทษที่สำคัญในแง่ของการเลือกชุดไฮเปอร์พารามิเตอร์ที่ดีที่สุด สุดท้าย ส่งงาน HPO ดังนี้:
กระบวนการนี้ใช้เวลาประมาณ 80 นาทีบนอินสแตนซ์ ml.m5.4xlarge คุณสามารถติดตามความคืบหน้าบนคอนโซล SageMaker ได้โดยเลือก งานปรับแต่งไฮเปอร์พารามิเตอร์ ภายใต้ การฝึกอบรม ในบานหน้าต่างนำทาง

คุณสามารถเห็นภาพข้อมูลที่เป็นประโยชน์มากมาย รวมถึงประสิทธิภาพของผู้สมัครแต่ละคน โดยเลือกชื่อของงานที่อยู่ระหว่างดำเนินการ

สุดท้าย เปรียบเทียบประสิทธิภาพของแบบจำลองของผู้สมัครที่ดีที่สุดดังนี้
| ผู้สมัคร | AUC | run_time (วินาที) |
| dpp6-มล | 0.96008 | 2711.0 |
| dpp4-xgboost | 0.95236 | 385.0 |
| dpp3-xgboost | 0.95095 | 202.0 |
| dpp4-xgboost | 0.95069 | 458.0 |
| dpp3-xgboost | 0.95015 | 361.0 |
โมเดลที่มีประสิทธิภาพสูงสุดตาม MLP ในขณะที่ดีกว่ารุ่น XGBoost เล็กน้อยที่มีขั้นตอนการประมวลผลข้อมูลให้เลือกมากมาย แต่ก็ใช้เวลาในการฝึกนานกว่ามาก คุณสามารถดูรายละเอียดที่สำคัญเกี่ยวกับการฝึกโมเดล MLP ซึ่งรวมถึงการใช้ไฮเปอร์พารามิเตอร์ร่วมกันดังนี้:
| การฝึกอบรมชื่องาน | mangrove-2-notebook–211021-2016-012-500271c8 |
| การฝึกอบรมสถานะงาน | เสร็จ |
| สุดท้ายObjectiveValue | 0.96008 |
| การฝึกอบรมStartTime | 2021-10-21 20:22:55+00:00 |
| การฝึกอบรมEndTime | 2021-10-21 21:08:06+00:00 |
| การฝึกอบรมElapsedTimeSeconds | 2711 |
| การฝึกอบรมJobDefinitionName | dpp6-มล |
| dropout_prob | 0.415778 |
| การฝัง_ขนาด_ปัจจัย | 0.849226 |
| ชั้น | 256 |
| อัตราการเรียนรู้ | 0.00013862 |
| mini_batch_size | 317 |
| เครือข่าย_ประเภท | ฟีดไปข้างหน้า |
| น้ำหนัก_สลาย | 1.29323st-12 |
สร้างไปป์ไลน์การอนุมาน
ในการสร้างการอนุมานข้อมูลใหม่ คุณต้องสร้างไปป์ไลน์การอนุมานบน SageMaker เพื่อโฮสต์โมเดลที่ดีที่สุดที่สามารถเรียกได้ในภายหลังเพื่อสร้างการอนุมาน โมเดลไปป์ไลน์ SageMaker ต้องใช้คอนเทนเนอร์สามตัวเป็นส่วนประกอบ: การแปลงข้อมูล อัลกอริธึม และการแปลงฉลากผกผัน (หากจำเป็นต้องจับคู่การคาดการณ์เชิงตัวเลขกับป้ายกำกับที่ไม่ใช่ตัวเลข) เพื่อความกระชับ จะแสดงเพียงส่วนหนึ่งของรหัสที่จำเป็นในตัวอย่างต่อไปนี้ รหัสที่สมบูรณ์มีอยู่ใน mangrove-2013.ipynb สมุดบันทึก:
หลังจากสร้างคอนเทนเนอร์แบบจำลองแล้ว คุณสามารถสร้างและปรับใช้ไปป์ไลน์ได้ดังนี้:
การปรับใช้ปลายทางจะใช้เวลาประมาณ 10 นาทีจึงจะเสร็จสมบูรณ์
รับการอนุมานชุดข้อมูลทดสอบโดยใช้จุดปลาย
หลังจากปรับใช้จุดปลายแล้ว คุณสามารถเรียกใช้ด้วยเพย์โหลดของฟีเจอร์ B1–B7 เพื่อจำแนกแต่ละพิกเซลในภาพเป็นป่าชายเลน (1) หรืออื่นๆ (0):
รายละเอียดที่สมบูรณ์เกี่ยวกับการประมวลผลภายหลังการทำนายแบบจำลองสำหรับการประเมินและการวางแผนมีอยู่ใน notebooks/model_performance.ipynb.
รับการอนุมานในชุดข้อมูลทดสอบโดยใช้การแปลงแบบแบตช์
ตอนนี้คุณได้สร้างแบบจำลองที่มีประสิทธิภาพดีที่สุดด้วย Autopilot แล้ว เราก็สามารถใช้แบบจำลองนี้ในการอนุมานได้ ในการอนุมานชุดข้อมูลขนาดใหญ่ การใช้การแปลงแบบแบตช์จะมีประสิทธิภาพมากกว่า มาสร้างการคาดคะเนบนชุดข้อมูลทั้งหมด (การฝึกอบรมและการทดสอบ) และผนวกผลลัพธ์เข้ากับคุณสมบัติ เพื่อให้เราสามารถทำการวิเคราะห์เพิ่มเติม เช่น ตรวจสอบการคาดการณ์เทียบกับข้อมูลจริง และการกระจายของคุณสมบัติระหว่างคลาสที่คาดการณ์ไว้
ขั้นแรก เราสร้างไฟล์รายการใน Amazon S3 ที่ชี้ไปยังตำแหน่งของการฝึกอบรมและทดสอบข้อมูลจากขั้นตอนการประมวลผลข้อมูลก่อนหน้านี้:
ตอนนี้ เราสามารถสร้างงานการแปลงแบบแบตช์ได้ เนื่องจากอินพุทเทรนและชุดข้อมูลทดสอบของเรามี label เป็นคอลัมน์สุดท้าย เราต้องวางมันระหว่างการอนุมาน ในการทำเช่นนั้นเราผ่าน InputFilter ใน DataProcessing การโต้แย้ง. รหัส "$[:-2]" ระบุว่าจะดรอปคอลัมน์สุดท้าย ผลลัพธ์ที่คาดการณ์ไว้จะถูกรวมเข้ากับข้อมูลต้นฉบับสำหรับการวิเคราะห์เพิ่มเติม
ในโค้ดต่อไปนี้ เราสร้างอาร์กิวเมนต์สำหรับงานการแปลงแบตช์แล้วส่งต่อไปยัง create_transform_job ฟังก์ชั่น:
คุณสามารถตรวจสอบสถานะของงานได้บนคอนโซล SageMaker
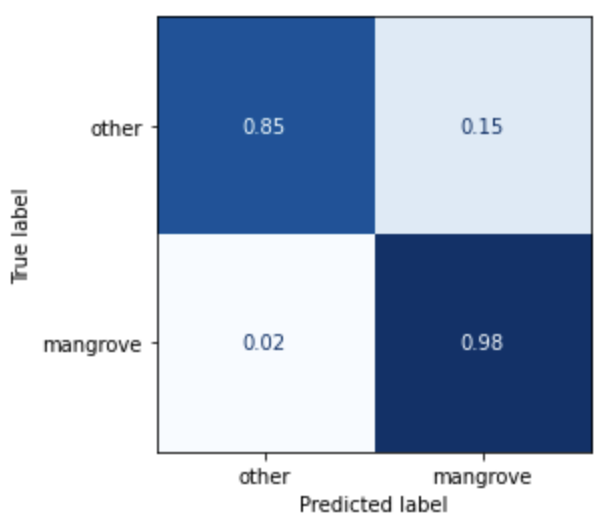
เห็นภาพประสิทธิภาพของแบบจำลอง
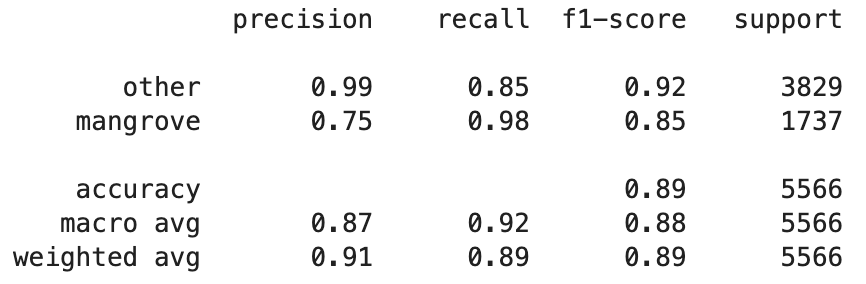
ตอนนี้คุณสามารถเห็นภาพประสิทธิภาพของแบบจำลองที่ดีที่สุดในชุดข้อมูลการทดสอบ ซึ่งประกอบด้วยภูมิภาคต่างๆ จากอินเดีย เมียนมาร์ คิวบา และเวียดนาม เป็นเมทริกซ์ความสับสน โมเดลนี้มีค่าการเรียกคืนสูงสำหรับพิกเซลที่เป็นตัวแทนของป่าชายเลน แต่มีความแม่นยำประมาณ 75% เท่านั้น ความแม่นยำของพิกเซลที่ไม่ใช่ป่าชายเลนหรือพิกเซลอื่นๆ อยู่ที่ 99% โดยมีการเรียกคืน 85% คุณสามารถปรับการตัดความน่าจะเป็นของการคาดคะเนแบบจำลองเพื่อปรับค่าที่เกี่ยวข้องโดยขึ้นอยู่กับกรณีการใช้งานเฉพาะ
เป็นที่น่าสังเกตว่าผลลัพธ์ที่ได้คือการปรับปรุงที่สำคัญกว่าโมเดล smileCart ในตัว
เห็นภาพการทำนายแบบจำลอง
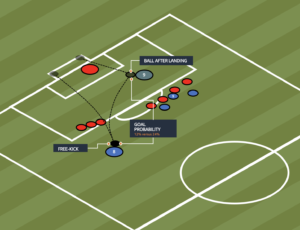
สุดท้าย การสังเกตประสิทธิภาพของแบบจำลองในพื้นที่เฉพาะบนแผนที่จะเป็นประโยชน์ ในภาพต่อไปนี้ พื้นที่ป่าชายเลนในชายแดนอินเดีย-บังกลาเทศเป็นสีแดง จุดที่สุ่มตัวอย่างจากแพตช์ภาพ Landsat ที่เป็นของชุดข้อมูลทดสอบจะถูกซ้อนทับบนภูมิภาค โดยที่แต่ละจุดเป็นพิกเซลที่ตัวแบบกำหนดไว้เพื่อเป็นตัวแทนของป่าชายเลน จุดสีน้ำเงินจัดประเภทอย่างถูกต้องตามแบบจำลอง ในขณะที่จุดสีดำแสดงถึงข้อผิดพลาดของแบบจำลอง
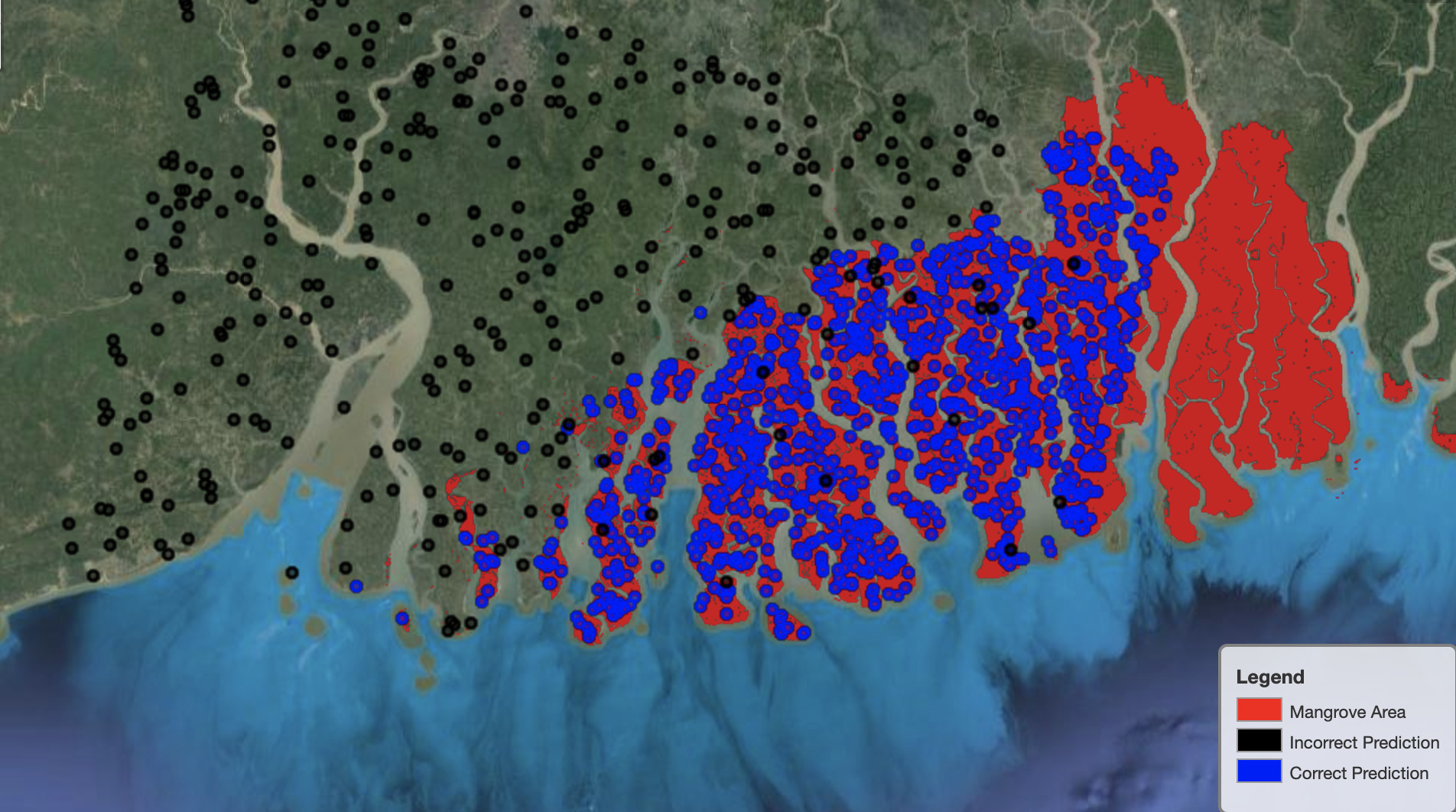
รูปภาพต่อไปนี้แสดงเฉพาะจุดที่แบบจำลองคาดการณ์ว่าจะไม่เป็นตัวแทนของป่าชายเลน โดยใช้โทนสีเดียวกับตัวอย่างก่อนหน้านี้ โครงร่างสีเทาเป็นส่วนหนึ่งของแพทช์ Landsat ที่ไม่มีป่าชายเลน ดังที่เห็นได้ชัดจากภาพ นางแบบไม่ได้ทำผิดพลาดในการจำแนกจุดบนน้ำ แต่ต้องเผชิญกับความท้าทายเมื่อแยกแยะพิกเซลที่เป็นตัวแทนของป่าชายเลนจากส่วนที่เป็นตัวแทนของใบไม้ปกติ

ภาพต่อไปนี้แสดงการแสดงแบบจำลองพื้นที่ป่าชายเลนเมียนมาร์
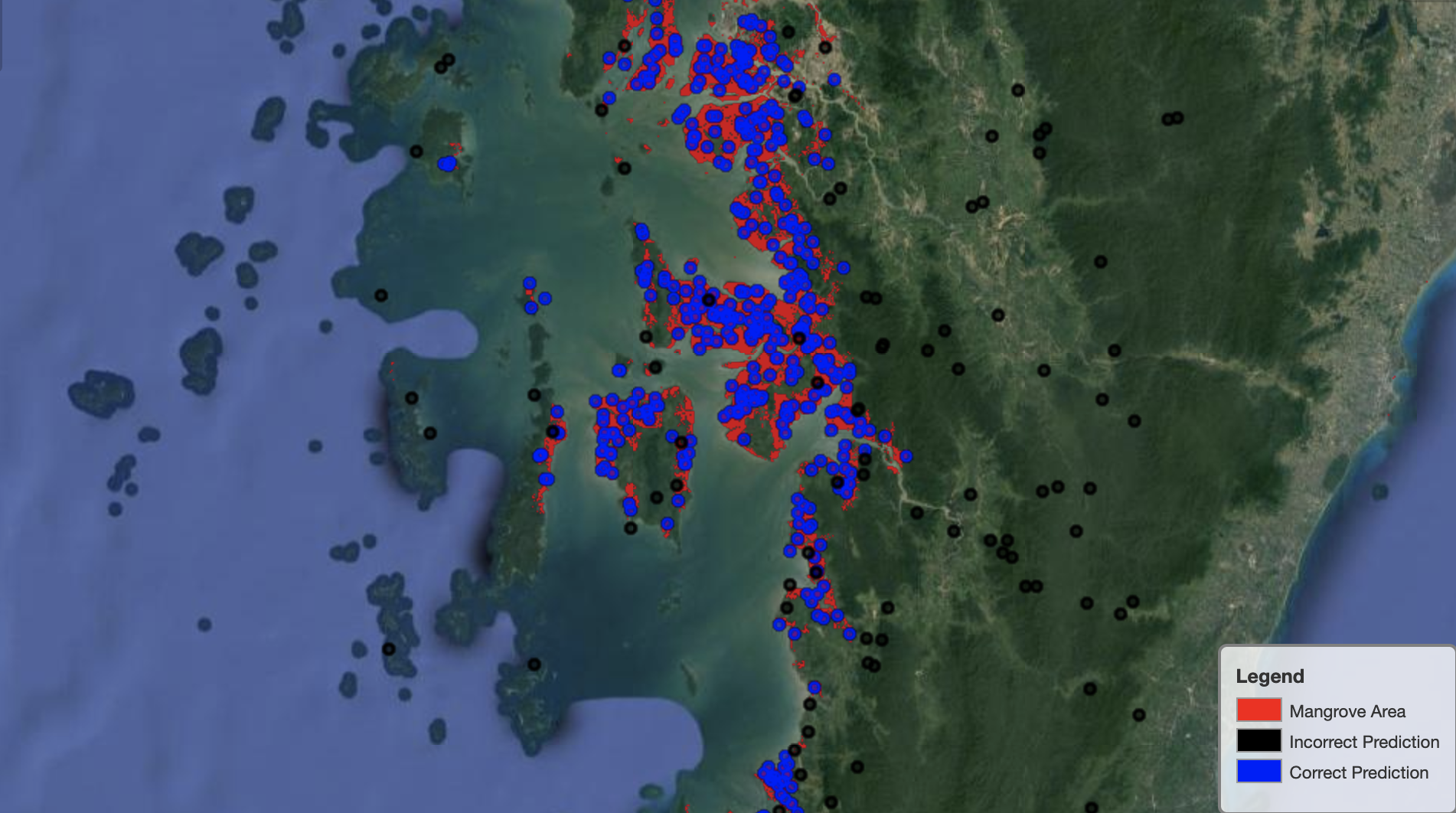
ในภาพต่อไปนี้ ตัวแบบสามารถระบุพิกเซลของป่าชายเลนได้ดีกว่า

ทำความสะอาด
จุดสิ้นสุดการอนุมานของ SageMaker ยังคงมีค่าใช้จ่ายหากยังทำงานอยู่ ลบปลายทางดังต่อไปนี้เมื่อคุณทำเสร็จแล้ว:
สรุป
บทความชุดนี้เป็นกรอบการทำงานแบบ end-to-end สำหรับนักวิทยาศาสตร์ข้อมูลในการแก้ปัญหา GIS 1 หมายเลข แสดงให้เห็นกระบวนการ ETL และวิธีที่สะดวกในการโต้ตอบกับข้อมูลด้วยสายตา ส่วนที่ 2 แสดงวิธีใช้ Autopilot เพื่อสร้างตัวแยกประเภทป่าชายเลนแบบกำหนดเองโดยอัตโนมัติ
คุณสามารถใช้เฟรมเวิร์กนี้เพื่อสำรวจชุดข้อมูลดาวเทียมใหม่ที่มีกลุ่มแบนด์ที่สมบูรณ์ยิ่งขึ้นซึ่งมีประโยชน์สำหรับการจำแนกประเภทป่าชายเลนและสำรวจวิศวกรรมคุณลักษณะโดยผสมผสานความรู้โดเมน
เกี่ยวกับผู้เขียน
 อังเดร อิวาโนวิช เป็นนักศึกษาปริญญาโทสาขาวิทยาการคอมพิวเตอร์ที่มหาวิทยาลัยโตรอนโต และเพิ่งสำเร็จการศึกษาจากหลักสูตรวิศวกรรมศาสตร์ที่มหาวิทยาลัยโตรอนโต สาขาวิชา Machine Intelligence กับผู้เยาว์ด้านวิทยาการหุ่นยนต์/เมคคาทรอนิกส์ เขาสนใจคอมพิวเตอร์วิทัศน์ การเรียนรู้เชิงลึก และวิทยาการหุ่นยนต์ เขาทำงานที่นำเสนอในโพสต์นี้ระหว่างการฝึกงานภาคฤดูร้อนที่ Amazon
อังเดร อิวาโนวิช เป็นนักศึกษาปริญญาโทสาขาวิทยาการคอมพิวเตอร์ที่มหาวิทยาลัยโตรอนโต และเพิ่งสำเร็จการศึกษาจากหลักสูตรวิศวกรรมศาสตร์ที่มหาวิทยาลัยโตรอนโต สาขาวิชา Machine Intelligence กับผู้เยาว์ด้านวิทยาการหุ่นยนต์/เมคคาทรอนิกส์ เขาสนใจคอมพิวเตอร์วิทัศน์ การเรียนรู้เชิงลึก และวิทยาการหุ่นยนต์ เขาทำงานที่นำเสนอในโพสต์นี้ระหว่างการฝึกงานภาคฤดูร้อนที่ Amazon
 เดวิด ดอง เป็นนักวิทยาศาสตร์ข้อมูลที่ Amazon Web Services
เดวิด ดอง เป็นนักวิทยาศาสตร์ข้อมูลที่ Amazon Web Services
 อัครโยติ มิสเราะห์ เป็นนักวิทยาศาสตร์ข้อมูลที่ Amazon LastMile Transportation เขาหลงใหลในการใช้เทคนิค Computer Vision เพื่อแก้ปัญหาที่ช่วยโลก เขาชอบทำงานกับองค์กรไม่แสวงหาผลกำไรและเป็นสมาชิกผู้ก่อตั้งของ ekipi.org.
อัครโยติ มิสเราะห์ เป็นนักวิทยาศาสตร์ข้อมูลที่ Amazon LastMile Transportation เขาหลงใหลในการใช้เทคนิค Computer Vision เพื่อแก้ปัญหาที่ช่วยโลก เขาชอบทำงานกับองค์กรไม่แสวงหาผลกำไรและเป็นสมาชิกผู้ก่อตั้งของ ekipi.org.
- คอยน์สมาร์ท การแลกเปลี่ยน Bitcoin และ Crypto ที่ดีที่สุดในยุโรป
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าฟรี
- คริปโตฮอว์ก เรดาร์ Altcoin ทดลองฟรี.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/part-2-identify-mangrove-forests-using-satellite-image-features-using-amazon-sagemaker-studio-and-amazon-sagemaker- นักบินอัตโนมัติ/
- "
- 10
- 100
- a
- เกี่ยวกับเรา
- ตาม
- กิจกรรม
- ขั้นตอนวิธี
- อัลกอริทึม
- ทั้งหมด
- อเมซอน
- Amazon Web Services
- ในหมู่
- การวิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- อื่น
- การประยุกต์ใช้
- AREA
- ข้อโต้แย้ง
- รอบ
- โดยอัตโนมัติ
- อัตโนมัติ
- อัตโนมัติ
- ใช้ได้
- AWS
- เพราะ
- ที่ดีที่สุด
- Black
- ร่างกาย
- ชายแดน
- สร้าง
- การก่อสร้าง
- สร้าง
- built-in
- ผู้สมัคร
- ผู้สมัคร
- กรณี
- ท้าทาย
- ทางเลือก
- Choose
- ชั้นเรียน
- การจัดหมวดหมู่
- จัด
- รหัส
- คอลัมน์
- การผสมผสาน
- รวม
- สมบูรณ์
- ส่วนประกอบ
- ส่วนประกอบ
- คอมพิวเตอร์
- วิทยาการคอมพิวเตอร์
- ความสับสน
- ปลอบใจ
- ภาชนะบรรจุ
- อย่างต่อเนื่อง
- ควบคุม
- สะดวกสบาย
- สร้าง
- ที่สร้างขึ้น
- สร้าง
- การสร้าง
- คิวบา
- ประเพณี
- ข้อมูล
- การประมวลผล
- นักวิทยาศาสตร์ข้อมูล
- ลึก
- ทั้งนี้ขึ้นอยู่กับ
- ปรับใช้
- นำไปใช้
- การใช้งาน
- รายละเอียด
- รายละเอียด
- DID
- ต่าง
- แสดง
- การกระจาย
- ไม่
- โดเมน
- ดาวน์โหลด
- หล่น
- ในระหว่าง
- แต่ละ
- โลก
- ระบบนิเวศ
- มีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- ความพยายาม
- จบสิ้น
- ปลายทาง
- ชั้นเยี่ยม
- เข้าสู่
- การประเมินผล
- ตัวอย่าง
- การทดลอง
- ความชำนาญ
- สำรวจ
- ใบหน้า
- แฟชั่น
- ลักษณะ
- คุณสมบัติ
- ในที่สุด
- ชื่อจริง
- ปฏิบัติตาม
- ดังต่อไปนี้
- ดังต่อไปนี้
- คำวินิจฉัย
- กรอบ
- ราคาเริ่มต้นที่
- เต็ม
- ฟังก์ชัน
- ต่อไป
- สร้าง
- สร้าง
- รุ่น
- สำเร็จการศึกษา
- สีเทา
- ให้คำแนะนำ
- ความสูง
- จะช่วยให้
- จุดสูง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTTPS
- เป็นมนุษย์
- แยกแยะ
- ระบุ
- ภาพ
- สำคัญ
- การปรับปรุง
- ประกอบด้วย
- รวมทั้ง
- อิสระ
- อินเดีย
- ข้อมูล
- อินพุต
- ตัวอย่าง
- Intelligence
- การโต้ตอบ
- สนใจ
- IT
- การสัมภาษณ์
- งาน
- เข้าร่วม
- เก็บ
- ความรู้
- ที่รู้จักกัน
- ฉลาก
- ป้ายกำกับ
- ใหญ่
- การเรียนรู้
- Line
- รายการ
- ในประเทศ
- ที่ตั้ง
- วันหยุด
- เครื่อง
- เรียนรู้เครื่อง
- สำคัญ
- ทำ
- แผนที่
- ปริญญาโท
- มดลูก
- เรื่อง
- สมาชิก
- ตัวชี้วัด
- ความผิดพลาด
- ML
- แบบ
- โมเดล
- การตรวจสอบ
- ข้อมูลเพิ่มเติม
- หลาย
- พม่า
- การเดินเรือ
- จำเป็น
- ถัดไป
- ไม่แสวงหาผลกำไร
- สมุดบันทึก
- เปิด
- การเพิ่มประสิทธิภาพ
- Options
- องค์กร
- อื่นๆ
- ของตนเอง
- ส่วนหนึ่ง
- ในสิ่งที่สนใจ
- หลงใหล
- ปะ
- การปฏิบัติ
- การแสดง
- ที่มีประสิทธิภาพ
- นักบิน
- จุด
- จุด
- สระ
- เป็นไปได้
- โพสต์
- การคาดการณ์
- ก่อน
- ปัญหา
- ปัญหาที่เกิดขึ้น
- กระบวนการ
- การประมวลผล
- โครงการ
- ให้
- ให้
- เหตุผล
- เมื่อเร็ว ๆ นี้
- ลด
- ภูมิภาค
- ปกติ
- ยังคง
- กรุ
- แสดง
- เป็นตัวแทนของ
- ขอ
- จำเป็นต้องใช้
- ต้อง
- นักวิจัย
- แหล่งข้อมูล
- ผลสอบ
- หุ่นยนต์
- บทบาท
- รอบ
- วิ่ง
- วิ่ง
- เดียวกัน
- ดาวเทียม
- ลด
- ปรับ
- โครงการ
- วิทยาศาสตร์
- นักวิทยาศาสตร์
- นักวิทยาศาสตร์
- การเลือก
- ชุด
- บริการ
- ชุด
- การตั้งค่า
- หลาย
- Share
- โชว์
- แสดง
- ลงชื่อ
- สำคัญ
- ง่าย
- ขนาด
- So
- ของแข็ง
- ทางออก
- แก้
- โดยเฉพาะ
- ยืน
- Status
- การเก็บรักษา
- จัดเก็บ
- กลยุทธ์
- นักเรียน
- สตูดิโอ
- หรือ
- ฤดูร้อน
- ระบบ
- งาน
- เทคนิค
- เงื่อนไขการใช้บริการ
- ทดสอบ
- พื้นที่
- ที่มา
- โลก
- สาม
- ตลอด
- ตลอด
- เวลา
- ด้านบน
- ชั้น 5
- โตรอน
- การฝึกอบรม
- แปลง
- การแปลง
- การแปลง
- การขนส่ง
- ภายใต้
- มหาวิทยาลัย
- ใช้
- มักจะ
- การตรวจสอบ
- ความคุ้มค่า
- ต่างๆ
- รุ่น
- วิสัยทัศน์
- การสร้างภาพ
- น้ำดื่ม
- เว็บ
- บริการเว็บ
- ในขณะที่
- WHO
- ไม่มี
- งาน
- โลก
- คุ้มค่า
- X
- ของคุณ