รูปภาพโดยบรรณาธิการ
ประเด็นที่สำคัญ
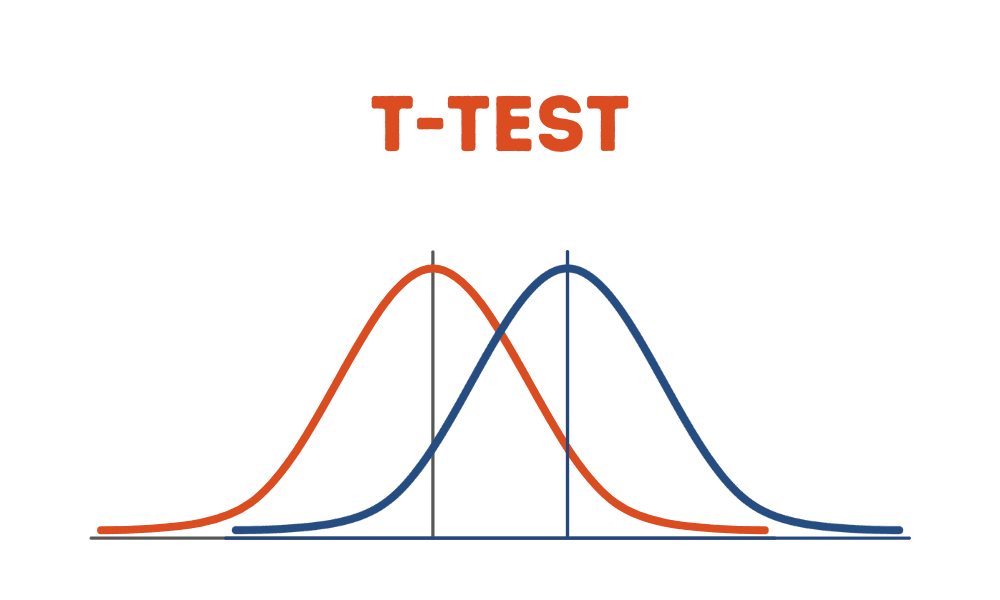
- t-test เป็นการทดสอบทางสถิติที่สามารถใช้เพื่อระบุว่ามีความแตกต่างอย่างมีนัยสำคัญระหว่างค่าเฉลี่ยของตัวอย่างข้อมูลสองตัวอย่างที่เป็นอิสระต่อกันหรือไม่
- เราแสดงให้เห็นว่าสามารถใช้การทดสอบ t โดยใช้ชุดข้อมูล iris และไลบรารี Scipy ของ Python ได้อย่างไร
t-test เป็นการทดสอบทางสถิติที่สามารถใช้เพื่อระบุว่ามีความแตกต่างอย่างมีนัยสำคัญระหว่างค่าเฉลี่ยของตัวอย่างข้อมูลสองตัวอย่างที่เป็นอิสระต่อกันหรือไม่ ในบทช่วยสอนนี้ เราแสดงตัวอย่างการทดสอบ t เวอร์ชันพื้นฐานที่สุด ซึ่งเราจะถือว่าตัวอย่างทั้งสองมีความแปรปรวนเท่ากัน การทดสอบ t เวอร์ชันขั้นสูงอื่นๆ ได้แก่ การทดสอบ t ของ Welch ซึ่งเป็นการดัดแปลงการทดสอบ t และมีความน่าเชื่อถือมากกว่าเมื่อตัวอย่างทั้งสองมีความแปรปรวนไม่เท่ากันและอาจมีขนาดตัวอย่างไม่เท่ากัน
สถิติ t หรือค่า t คำนวณดังนี้:
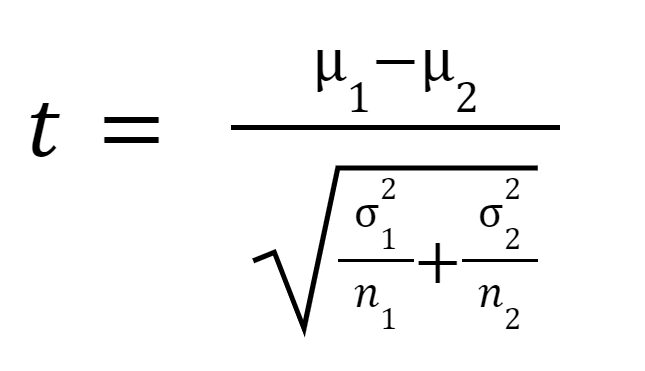
ที่ไหน
เป็นค่าเฉลี่ยของกลุ่มตัวอย่าง 1
เป็นค่าเฉลี่ยของกลุ่มตัวอย่าง 2
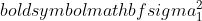 คือความแปรปรวนของกลุ่มตัวอย่างที่ 1
คือความแปรปรวนของกลุ่มตัวอย่างที่ 1 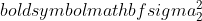 คือความแปรปรวนของกลุ่มตัวอย่างที่ 2
คือความแปรปรวนของกลุ่มตัวอย่างที่ 2 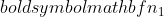 คือขนาดตัวอย่างของตัวอย่างที่ 1 และ
คือขนาดตัวอย่างของตัวอย่างที่ 1 และ 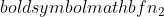 คือขนาดตัวอย่างของกลุ่มตัวอย่างที่ 2
คือขนาดตัวอย่างของกลุ่มตัวอย่างที่ 2
เพื่อแสดงการใช้ t-test เราจะแสดงตัวอย่างง่ายๆ โดยใช้ชุดข้อมูลม่านตา สมมติว่าเราสังเกตตัวอย่างสองตัวอย่างอิสระ เช่น ความยาวของกลีบเลี้ยงดอกไม้ และเรากำลังพิจารณาว่าทั้งสองตัวอย่างมาจากประชากรเดียวกัน (เช่น ดอกไม้ชนิดเดียวกันหรือสองชนิดที่มีลักษณะกลีบเลี้ยงคล้ายกัน) หรือสองกลุ่มประชากรที่แตกต่างกัน
การทดสอบค่า t หาปริมาณความแตกต่างระหว่างค่าเฉลี่ยเลขคณิตของสองตัวอย่าง ค่า p ระบุปริมาณความน่าจะเป็นที่จะได้ผลลัพธ์ที่สังเกตได้ โดยถือว่าสมมติฐานว่าง (ตัวอย่างถูกดึงมาจากประชากรที่มีค่าเฉลี่ยประชากรเดียวกัน) เป็นจริง ค่า p ที่มากกว่าเกณฑ์ที่เลือก (เช่น 5% หรือ 0.05) บ่งชี้ว่าการสังเกตของเราไม่น่าจะเกิดขึ้นโดยบังเอิญ ดังนั้นเราจึงยอมรับสมมติฐานว่างของค่าเฉลี่ยประชากรที่เท่ากัน ถ้าค่า p น้อยกว่าเกณฑ์ของเรา เราก็มีหลักฐานต่อต้านสมมติฐานว่างของค่าเฉลี่ยประชากรที่เท่ากัน
อินพุตทดสอบ T
อินพุตหรือพารามิเตอร์ที่จำเป็นสำหรับการทดสอบค่า t คือ:
- สองอาร์เรย์ a และ b มีข้อมูลสำหรับตัวอย่างที่ 1 และตัวอย่างที่ 2
T-Test ผลลัพธ์
t-test ส่งคืนค่าต่อไปนี้:
- สถิติ t ที่คำนวณได้
- p-value
นำเข้าไลบรารีที่จำเป็น
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
โหลดชุดข้อมูล Iris
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
คำนวณค่าเฉลี่ยของตัวอย่างและความแปรปรวนของตัวอย่าง
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
ใช้ t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
เอาท์พุต
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
เอาท์พุต
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
เอาท์พุต
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)ข้อสังเกต
เราสังเกตว่าการใช้ "จริง" หรือ "เท็จ" สำหรับพารามิเตอร์ "เท่ากับ-var" จะไม่เปลี่ยนผลการทดสอบ t-test มากนัก นอกจากนี้ เรายังสังเกตว่าการเปลี่ยนลำดับของอาร์เรย์ตัวอย่าง a_1 และ b_1 ให้ค่า t-test เป็นลบ แต่ไม่ได้เปลี่ยนขนาดของค่า t-test ตามที่คาดไว้ เนื่องจากค่า p ที่คำนวณได้นั้นมากกว่าค่าเกณฑ์ที่ 0.05 เราจึงสามารถปฏิเสธสมมติฐานว่างที่ว่าความแตกต่างระหว่างค่าเฉลี่ยของตัวอย่างที่ 1 และตัวอย่างที่ 2 นั้นมีนัยสำคัญ นี่แสดงให้เห็นว่าความยาวของกลีบเลี้ยงสำหรับตัวอย่างที่ 1 และตัวอย่างที่ 2 ดึงมาจากข้อมูลประชากรเดียวกัน
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
คำนวณค่าเฉลี่ยของตัวอย่างและความแปรปรวนของตัวอย่าง
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
ใช้ t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
เอาท์พุต
stats.ttest_ind(a_1, b_1, equal_var = False)ข้อสังเกต
เราสังเกตว่าการใช้ตัวอย่างที่มีขนาดไม่เท่ากันจะไม่เปลี่ยนค่าสถิติ t และค่า p อย่างมีนัยสำคัญ
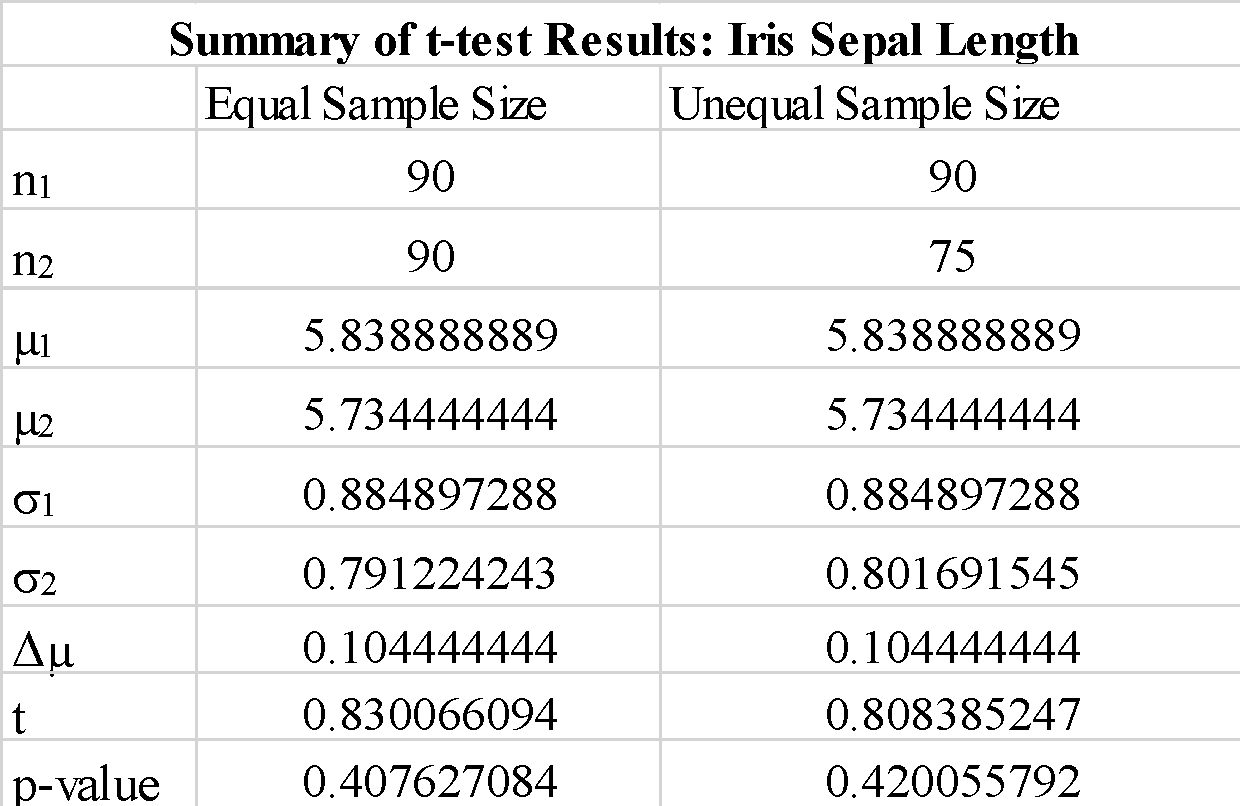
โดยสรุป เราได้แสดงให้เห็นว่าการทดสอบ t อย่างง่ายสามารถนำไปใช้โดยใช้ไลบรารี scipy ใน python ได้อย่างไร
เบนจามิน โอ ทาโย เป็นนักฟิสิกส์ นักการศึกษาด้านวิทยาศาสตร์ข้อมูล และนักเขียน ตลอดจนเจ้าของ DataScienceHub ก่อนหน้านี้ Benjamin กำลังสอนวิศวกรรมและฟิสิกส์ที่ U. of Central Oklahoma, Grand Canyon U. และ Pittsburgh State U.
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- ยอมรับ
- สูง
- กับ
- และ
- ประยุกต์
- ขั้นพื้นฐาน
- เบนจามิน
- ระหว่าง
- คำนวณ
- ส่วนกลาง
- โอกาส
- เปลี่ยนแปลง
- ลักษณะ
- เลือก
- พิจารณา
- ได้
- ข้อมูล
- วิทยาศาสตร์ข้อมูล
- ชุดข้อมูล
- กำหนด
- ความแตกต่าง
- ต่าง
- วาด
- ชั้นเยี่ยม
- หลักฐาน
- ตัวอย่าง
- ที่คาดหวัง
- ดอกไม้
- ดังต่อไปนี้
- ดังต่อไปนี้
- ราคาเริ่มต้นที่
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- HTTPS
- การดำเนินการ
- นำเข้า
- in
- ประกอบด้วย
- อิสระ
- บ่งชี้ว่า
- KD นักเก็ต
- ที่มีขนาดใหญ่
- ห้องสมุด
- matplotlib
- วิธี
- ข้อมูลเพิ่มเติม
- มากที่สุด
- จำเป็น
- เชิงลบ
- มึน
- สังเกต
- การได้รับ
- ที่เกิดขึ้น
- โอกลาโฮมา
- ใบสั่ง
- อื่นๆ
- เจ้าของ
- พารามิเตอร์
- พารามิเตอร์
- ที่มีประสิทธิภาพ
- ฟิสิกส์
- พิตส์เบิร์ก
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- ประชากร
- ประชากร
- ก่อนหน้านี้
- ความน่าจะเป็น
- หลาม
- น่าเชื่อถือ
- ผลสอบ
- รับคืน
- เดียวกัน
- วิทยาศาสตร์
- โชว์
- แสดง
- แสดงให้เห็นว่า
- สำคัญ
- อย่างมีความหมาย
- คล้ายคลึงกัน
- ง่าย
- ตั้งแต่
- ขนาด
- ขนาด
- มีขนาดเล็กกว่า
- So
- สถานะ
- ทางสถิติ
- สถิติ
- สรุป
- การเรียนการสอน
- ทดสอบ
- พื้นที่
- ดังนั้น
- ธรณีประตู
- ไปยัง
- จริง
- เกี่ยวกับการสอน
- ใช้
- ความคุ้มค่า
- รุ่น
- ว่า
- ที่
- จะ
- นักเขียน
- อัตราผลตอบแทน
- ลมทะเล