ในการโพสต์ ขอแนะนำเครื่องมือ AWS ProServe Hadoop Migration Delivery Kit TCOเราได้แนะนำเครื่องมือ AWS ProServe Hadoop Migration Delivery Kit (HMDK) TCO และประโยชน์ของการย้ายปริมาณงาน Hadoop ในองค์กรไปยัง อเมซอน EMR. ในโพสต์นี้ เราจะลงลึกในเครื่องมือ อธิบายทุกขั้นตอนตั้งแต่การส่งผ่านข้อมูลบันทึก การแปลง การแสดงภาพ และการออกแบบสถาปัตยกรรม ไปจนถึงการคำนวณ TCO
ภาพรวมโซลูชัน
เรามาเยี่ยมชมคุณสมบัติหลักของเครื่องมือ HMDK TCO กันโดยสังเขป เครื่องมือนี้มีตัวรวบรวมบันทึก YARN เพื่อเชื่อมต่อ Hadoop Resource Manager เพื่อรวบรวมบันทึก YARN ตัววิเคราะห์ปริมาณงาน Hadoop ที่ใช้ Python ซึ่งเรียกว่าตัววิเคราะห์บันทึก YARN จะกลั่นกรองแอปพลิเคชัน Hadoop อเมซอน QuickSight แดชบอร์ดแสดงผลจากตัววิเคราะห์ ผลลัพธ์เดียวกันนี้ยังเร่งการออกแบบอินสแตนซ์ EMR ในอนาคตอีกด้วย นอกจากนี้ เครื่องคำนวณ TCO ยังสร้างการประมาณ TCO ของคลัสเตอร์ EMR ที่ปรับให้เหมาะสมเพื่ออำนวยความสะดวกในการย้ายข้อมูล
ทีนี้มาดูว่าเครื่องมือนี้ทำงานอย่างไร ไดอะแกรมต่อไปนี้แสดงเวิร์กโฟลว์แบบ end-to-end

ในหัวข้อถัดไป เราจะอธิบายห้าขั้นตอนหลักของเครื่องมือ:
- รวบรวมบันทึกประวัติงานของ YARN
- แปลงบันทึกประวัติงานจาก JSON เป็น CSV
- วิเคราะห์บันทึกประวัติงาน
- ออกแบบคลัสเตอร์ EMR สำหรับการโยกย้าย
- คำนวณ TCO
เบื้องต้น
ก่อนเริ่มต้น ตรวจสอบให้แน่ใจว่าได้ทำข้อกำหนดเบื้องต้นต่อไปนี้ให้ครบถ้วน:
- โคลน ที่เก็บ hadoop-migration-assessment-tco.
- ติดตั้ง Python 3 บนเครื่องของคุณ
- มีบัญชี AWS ที่ได้รับอนุญาต AWS แลมบ์ดา, QuickSight (รุ่นสำหรับองค์กร) และ การก่อตัวของ AWS Cloud.
รวบรวมบันทึกประวัติงานของ YARN
ก่อนอื่น คุณเรียกใช้ a ตัวรวบรวมบันทึก YARN, start-collector.sh บนเครื่องโลคัลของคุณ ขั้นตอนนี้รวบรวมบันทึก Hadoop YARN และวางบันทึกในเครื่องของคุณ สคริปต์เชื่อมต่อเครื่องโลคัลของคุณกับโหนดหลัก Hadoop และสื่อสารกับ Resource Manager จากนั้นจะดึงข้อมูลประวัติงาน (บันทึก YARN จากตัวจัดการแอปพลิเคชัน) โดยการเรียก API แอปพลิเคชัน YARN ResourceManager
ก่อนเรียกใช้ตัวรวบรวมบันทึก YARN คุณต้องกำหนดค่าและสร้างการเชื่อมต่อ (HTTP: 8088 หรือ HTTPS: 8090 แนะนำให้ใช้อย่างหลัง) เพื่อตรวจสอบการเข้าถึงของ YARN ResourceManager และเปิดใช้งาน YARN Timeline Server (รองรับ Timeline Server v1 หรือใหม่กว่า ). คุณอาจต้องกำหนดช่วงเวลาการรวบรวมบันทึกของ YARN และนโยบายการเก็บรักษา เพื่อให้แน่ใจว่าคุณรวบรวมบันทึก YARN ติดต่อกัน คุณสามารถใช้งาน cron เพื่อกำหนดเวลาตัวรวบรวมบันทึกในช่วงเวลาที่เหมาะสม ตัวอย่างเช่น สำหรับคลัสเตอร์ Hadoop ที่มีแอปพลิเคชันรายวัน 2,000 รายการ และการตั้งค่า Yarn.resourcemanager.max-completed-applications เป็น 1,000 ในทางทฤษฎี คุณต้องเรียกใช้ตัวรวบรวมบันทึกอย่างน้อยสองครั้งเพื่อรับบันทึก YARN ทั้งหมด นอกจากนี้ เราขอแนะนำให้รวบรวมบันทึก YARN อย่างน้อย 7 วันสำหรับการวิเคราะห์ปริมาณงานแบบองค์รวม
สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับวิธีกำหนดค่าและกำหนดเวลาตัวรวบรวมบันทึก โปรดดูที่ เส้นด้ายบันทึกการเก็บ GitHub repo.
แปลงบันทึกประวัติงาน YARN จาก JSON เป็น CSV
หลังจากได้รับบันทึก YARN แล้ว ให้เรียกใช้ตัวจัดระเบียบบันทึก YARN ซึ่งก็คือ yarn-log-organizer.py ซึ่งเป็นโปรแกรมแยกวิเคราะห์เพื่อแปลงบันทึกตาม JSON เป็นไฟล์ CSV ไฟล์ CSV เอาต์พุตเหล่านี้เป็นอินพุตสำหรับตัววิเคราะห์บันทึก YARN โปรแกรมแยกวิเคราะห์ยังมีความสามารถอื่นๆ รวมถึงการเรียงลำดับเหตุการณ์ตามเวลา การลบการอุทิศ และการรวมบันทึกหลายรายการ
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับวิธีใช้ตัวจัดระเบียบบันทึก YARN โปรดดูที่ เส้นด้ายล็อกออแกไนเซอร์ GitHub repo.
วิเคราะห์บันทึกประวัติงานของ YARN
ต่อไป ให้คุณเปิดใช้ตัววิเคราะห์บันทึก YARN เพื่อวิเคราะห์บันทึก YARN ในรูปแบบ CSV
ด้วย QuickSight คุณสามารถแสดงภาพข้อมูลบันทึกของ YARN และดำเนินการวิเคราะห์กับชุดข้อมูลที่สร้างโดยเทมเพลตแดชบอร์ดที่สร้างไว้ล่วงหน้าและวิดเจ็ต วิดเจ็ตจะสร้างแดชบอร์ด QuickSight โดยอัตโนมัติในบัญชี AWS เป้าหมาย ซึ่งกำหนดค่าในเทมเพลต CloudFormation
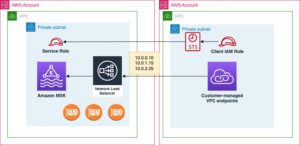
ไดอะแกรมต่อไปนี้แสดงสถาปัตยกรรม HMDK TCO

เครื่องมือวิเคราะห์บันทึก YARN มีฟังก์ชันหลักสี่ฟังก์ชัน:
- อัปโหลดบันทึกประวัติงาน YARN ที่แปลงแล้วในรูปแบบ CSV (ตัวอย่างเช่น
cluster_yarn_logs_*.csv) มัน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) ที่ฝากข้อมูล ไฟล์ CSV เหล่านี้เป็นเอาต์พุตจากตัวจัดระเบียบบันทึก YARN - สร้างไฟล์ Manifest JSON (เช่น
yarn-log-manifest.json) สำหรับ QuickSight และอัปโหลดไปยังบัคเก็ต S3: - ปรับใช้แดชบอร์ด QuickSight โดยใช้เทมเพลต CloudFormation ซึ่งอยู่ในรูปแบบ YAML หลังจากปรับใช้ ให้เลือกไอคอนรีเฟรชจนกว่าคุณจะเห็นสถานะของสแต็กเป็น
CREATE_COMPLETE. ขั้นตอนนี้สร้างชุดข้อมูลบนแดชบอร์ด QuickSight ในบัญชีเป้าหมาย AWS ของคุณ
- บนแดชบอร์ด QuickSight คุณสามารถค้นหาข้อมูลเชิงลึกของปริมาณงาน Hadoop ที่วิเคราะห์ได้จากแผนภูมิต่างๆ ข้อมูลเชิงลึกเหล่านี้ช่วยให้คุณออกแบบอินสแตนซ์ EMR ในอนาคตสำหรับการเร่งความเร็วการย้ายข้อมูล ดังที่แสดงไว้ในขั้นตอนถัดไป

ออกแบบคลัสเตอร์ EMR สำหรับการโยกย้าย
ผลลัพธ์ของตัววิเคราะห์บันทึก YARN ช่วยให้คุณเข้าใจปริมาณงาน Hadoop จริงในระบบที่มีอยู่ ขั้นตอนนี้ช่วยเร่งการออกแบบอินสแตนซ์ EMR ในอนาคตสำหรับการโยกย้ายโดยใช้ เทมเพลต Excel. เทมเพลตประกอบด้วยรายการตรวจสอบสำหรับการวิเคราะห์ภาระงานและการวางแผนกำลังการผลิต:
- แอปพลิเคชันที่ทำงานบนคลัสเตอร์ถูกใช้งานอย่างเหมาะสมกับความจุปัจจุบันหรือไม่
- คลัสเตอร์อยู่ภายใต้การโหลด ณ เวลาใดเวลาหนึ่งหรือไม่? ถ้าเป็นเช่นนั้น เวลาคือเมื่อไร?
- แอปพลิเคชันและเอ็นจิ้นประเภทใด (เช่น MR, TEZ หรือ Spark) ที่กำลังทำงานบนคลัสเตอร์ และแต่ละประเภทมีการใช้ทรัพยากรเท่าใด
- รอบการทำงานของงานที่แตกต่างกัน (เรียลไทม์ ชุดงาน เฉพาะกิจ) ทำงานในคลัสเตอร์เดียวหรือไม่
- มีงานใดบ้างที่ทำงานเป็นแบทช์ปกติ และถ้ามี ช่วงเวลาเหล่านี้คืออะไร (เช่น ทุก 10 นาที 1 ชั่วโมง 1 วัน) คุณมีงานที่ใช้ทรัพยากรจำนวนมากในช่วงเวลาที่ยาวนานหรือไม่?
- มีงานใดที่ต้องการการปรับปรุงประสิทธิภาพหรือไม่?
- มีองค์กรหรือบุคคลใดที่ผูกขาดคลัสเตอร์หรือไม่
- มีงานการพัฒนาและการดำเนินงานผสมกันในคลัสเตอร์เดียวหรือไม่
หลังจากทำรายการตรวจสอบเสร็จแล้ว คุณจะเข้าใจวิธีการออกแบบสถาปัตยกรรมในอนาคตได้ดีขึ้น เพื่อเพิ่มประสิทธิภาพต้นทุนของคลัสเตอร์ EMR ตารางต่อไปนี้ให้แนวทางทั่วไปในการเลือกประเภทคลัสเตอร์ EMR ที่เหมาะสมและ อเมซอน อีลาสติก คอมพิวท์ คลาวด์ (อเมซอน EC2) ครอบครัว

หากต้องการเลือกประเภทคลัสเตอร์และตระกูลอินสแตนซ์ที่เหมาะสม คุณต้องทำการวิเคราะห์หลายรอบกับบันทึก YARN ตามเกณฑ์ต่างๆ มาดูเมตริกสำคัญๆ กันบ้าง
ปฏิบัติการ
คุณสามารถค้นหารูปแบบปริมาณงานตามจำนวนแอปพลิเคชัน Hadoop ที่ทำงานในช่วงเวลาหนึ่งๆ ตัวอย่างเช่น แผนภูมิรายวันหรือรายชั่วโมง “จำนวนบันทึกตามเวลาเริ่มต้น” ให้ข้อมูลเชิงลึกต่อไปนี้:
- ในแผนภูมิอนุกรมเวลารายวัน คุณจะเปรียบเทียบจำนวนแอปพลิเคชันที่ทำงานระหว่างวันที่ทำงานและวันหยุด และระหว่างวันตามปฏิทิน หากตัวเลขใกล้เคียงกัน แสดงว่าการใช้งานประจำวันของคลัสเตอร์นั้นเทียบได้ ในทางกลับกัน หากค่าเบี่ยงเบนมีมาก สัดส่วนของงานเฉพาะกิจก็มีความสำคัญ คุณยังสามารถค้นหางานรายสัปดาห์หรือรายเดือนที่เป็นไปได้ในวันใดวันหนึ่ง ในสถานการณ์นี้ คุณสามารถดูวันที่ต้องการในหนึ่งสัปดาห์หรือหนึ่งเดือนที่มีภาระงานสูงได้อย่างง่ายดาย
- ในแผนภูมิอนุกรมเวลารายชั่วโมง คุณจะเข้าใจมากขึ้นว่าแอปพลิเคชันทำงานอย่างไรในหน้าต่างรายชั่วโมง คุณสามารถหาชั่วโมงเร่งด่วนและนอกเวลาเร่งด่วนได้ในหนึ่งวัน
ผู้ใช้
บันทึก YARN มี ID ผู้ใช้ของแต่ละแอปพลิเคชัน ข้อมูลนี้ช่วยให้คุณเข้าใจว่าใครส่งใบสมัครเข้าคิว ตามสถิติของการรันแอปพลิเคชันแต่ละรายการและแบบรวมต่อคิวและต่อผู้ใช้ คุณสามารถกำหนดการกระจายภาระงานที่มีอยู่ตามผู้ใช้ โดยปกติแล้ว ผู้ใช้ในทีมเดียวกันจะมีคิวร่วมกัน บางครั้งหลายทีมมีคิวร่วมกัน เมื่อออกแบบคิวสำหรับผู้ใช้ ตอนนี้คุณมีข้อมูลเชิงลึกเพื่อช่วยคุณออกแบบและกระจายปริมาณงานของแอปพลิเคชันที่มีความสมดุลระหว่างคิวต่างๆ มากกว่าที่เคยเป็นมา
ประเภทการสมัคร
คุณสามารถแบ่งกลุ่มปริมาณงานตามประเภทแอปพลิเคชันต่างๆ (เช่น Hive, Spark, Presto หรือ HBase) และรันเอ็นจิ้น (เช่น MR, Spark หรือ Tez) สำหรับเวิร์กโหลดที่มีการประมวลผลสูง เช่น งาน MapReduce หรือ Hive-on-MR ให้ใช้อินสแตนซ์ที่ปรับให้เหมาะกับ CPU สำหรับปริมาณงานที่ใช้หน่วยความจำมาก เช่น งาน Hive-on-TEZ, Presto และ Spark ให้ใช้อินสแตนซ์ที่ปรับหน่วยความจำให้เหมาะสม
เวลาที่ผ่านไป
คุณสามารถจัดหมวดหมู่แอปพลิเคชันตามรันไทม์ เทมเพลต CloudFormation ที่ฝังไว้จะสร้างฟิลด์ elapsedGroup ในแดชบอร์ด QuickSight โดยอัตโนมัติ ซึ่งเปิดใช้งานฟีเจอร์หลักเพื่อให้คุณสังเกตงานที่ใช้เวลานานในหนึ่งในสี่แผนภูมิบนแดชบอร์ด QuickSight ดังนั้น คุณจึงสามารถออกแบบสถาปัตยกรรมในอนาคตที่เหมาะกับงานขนาดใหญ่เหล่านี้ได้
แดชบอร์ด QuickSight ที่สอดคล้องกันประกอบด้วยสี่แผนภูมิ คุณสามารถเจาะลึกแต่ละแผนภูมิซึ่งเชื่อมโยงกับกลุ่มเดียว
| บัญชีกลุ่ม จำนวน |
รันไทม์/เวลาที่ผ่านไปของงาน |
| 1 | น้อยกว่า 10 นาที |
| 2 | ระหว่าง 10 นาที ถึง 30 นาที |
| 3 | ระหว่าง 30 นาทีถึง 1 ชั่วโมง |
| 4 | มากกว่า 1 ชม |
ในแผนภูมิของกลุ่ม 4 คุณสามารถจดจ่อกับการพิจารณางานขนาดใหญ่ตามเมตริกต่างๆ รวมถึงผู้ใช้ คิว ประเภทแอปพลิเคชัน ไทม์ไลน์ การใช้ทรัพยากร และอื่นๆ จากการพิจารณานี้ คุณอาจมีคิวเฉพาะบนคลัสเตอร์หรือคลัสเตอร์ EMR เฉพาะสำหรับงานขนาดใหญ่ ในระหว่างนี้ คุณสามารถส่งงานขนาดเล็กไปยังคิวที่ใช้ร่วมกันได้
แหล่งข้อมูล
ตามรูปแบบการใช้ทรัพยากร (CPU หน่วยความจำ) คุณเลือกขนาดและตระกูลของอินสแตนซ์ EC2 ที่เหมาะสมเพื่อประสิทธิภาพและความคุ้มค่า สำหรับแอปพลิเคชันที่ใช้การประมวลผลสูง เราขอแนะนำอินสแตนซ์ของตระกูลที่ปรับให้เหมาะกับ CPU สำหรับแอปพลิเคชันที่ใช้หน่วยความจำมาก แนะนำให้ใช้ตระกูลอินสแตนซ์ที่ปรับหน่วยความจำให้เหมาะสม
นอกจากนี้ ขึ้นอยู่กับลักษณะของปริมาณงานของแอปพลิเคชันและการใช้ทรัพยากรในช่วงเวลาหนึ่ง คุณสามารถเลือกคลัสเตอร์ EMR แบบถาวรหรือชั่วคราว Amazon EMR บน EKS,หรือ Amazon EMR ไร้เซิร์ฟเวอร์.
หลังจากวิเคราะห์บันทึก YARN ตามเมตริกต่างๆ แล้ว คุณก็พร้อมที่จะออกแบบสถาปัตยกรรม EMR ในอนาคต ตารางต่อไปนี้แสดงตัวอย่างคลัสเตอร์ EMR ที่เสนอ สามารถดูรายละเอียดเพิ่มเติมได้ใน GitHub Repo เครื่องคิดเลข tco ที่ปรับให้เหมาะสม.

คำนวณ TCO
สุดท้าย ในเครื่องของคุณ ให้เรียกใช้ tco-input-generator.py เพื่อรวมบันทึกประวัติงาน YARN เป็นรายชั่วโมงก่อนที่จะใช้เทมเพลต Excel เพื่อคำนวณ TCO ที่ปรับให้เหมาะสม ขั้นตอนนี้มีความสำคัญเนื่องจากผลลัพธ์จะจำลองปริมาณงาน Hadoop ในอินสแตนซ์ EMR ในอนาคต
ข้อกำหนดเบื้องต้นของการจำลอง TCO คือการเรียกใช้ tco-input-generator.pyซึ่งสร้างบันทึกรวมรายชั่วโมง ต่อไป ให้คุณเปิดไฟล์เทมเพลต Excel เพื่อเปิดใช้งานมาโครและป้อนอินพุตของคุณในเซลล์สีเขียวเพื่อคำนวณ TCO เกี่ยวกับข้อมูลอินพุต คุณป้อนขนาดข้อมูลจริงโดยไม่ต้องจำลองแบบ และข้อกำหนดฮาร์ดแวร์ (vCore, mem) ของโหนดหลักและโหนดข้อมูล Hadoop คุณต้องเลือกและอัปโหลดบันทึกรวมรายชั่วโมงที่สร้างขึ้นก่อนหน้านี้ หลังจากที่คุณตั้งค่าตัวแปรจำลอง TCO เช่น ภูมิภาค, ประเภท EC2, ความพร้อมใช้งานสูงของ Amazon EMR, เอฟเฟกต์เครื่องยนต์, ส่วนลด Amazon EC2 และ Amazon EBS (EDP), ส่วนลดปริมาณ Amazon S3, อัตราสกุลเงินท้องถิ่น และอัตราส่วนราคา EMR EC2 งาน/คอร์ และราคาต่อชั่วโมง ตัวจำลอง TCO จะคำนวณต้นทุนที่เหมาะสมของอินสแตนซ์ EMR ในอนาคตบน Amazon EC2 โดยอัตโนมัติ ภาพหน้าจอต่อไปนี้แสดงตัวอย่างผลลัพธ์ของ HMDK TCO

สำหรับข้อมูลเพิ่มเติมและคำแนะนำในการคำนวณ HMDK TCO โปรดดูที่ GitHub Repo เครื่องคิดเลข tco ที่ปรับให้เหมาะสม.
ทำความสะอาด
หลังจากที่คุณทำตามขั้นตอนทั้งหมดและเสร็จสิ้นการทดสอบแล้ว ให้ทำตามขั้นตอนต่อไปนี้เพื่อลบทรัพยากรเพื่อหลีกเลี่ยงค่าใช้จ่ายที่เกิดขึ้น:
- บนคอนโซล AWS CloudFormation เลือกสแต็กที่คุณสร้างขึ้น
- Choose ลบ.
- Choose ลบ stack.
- รีเฟรชหน้าจนกว่าคุณจะเห็นสถานะ
DELETE_COMPLETE. - บนคอนโซล Amazon S3 ให้ลบบัคเก็ต S3 ที่คุณสร้างขึ้น
สรุป
เครื่องมือ AWS ProServe HMDK TCO ช่วยลดความพยายามในการวางแผนการย้ายข้อมูลได้อย่างมาก ซึ่งเป็นงานที่ใช้เวลานานและท้าทายในการประเมินปริมาณงาน Hadoop ของคุณ ด้วยเครื่องมือ HMDK TCO การประเมินมักใช้เวลา 2–3 สัปดาห์ คุณยังสามารถกำหนด TCO ที่คำนวณได้ของสถาปัตยกรรม EMR ในอนาคต ด้วยเครื่องมือ HMDK TCO คุณจะสามารถเข้าใจปริมาณงานและรูปแบบการใช้ทรัพยากรของคุณได้อย่างรวดเร็ว ด้วยข้อมูลเชิงลึกที่สร้างโดยเครื่องมือ คุณพร้อมที่จะออกแบบสถาปัตยกรรม EMR ในอนาคตที่เหมาะสมที่สุด ในหลายกรณีการใช้งาน TCO 1 ปีของสถาปัตยกรรมการปรับโครงสร้างให้เหมาะสมช่วยประหยัดต้นทุนได้อย่างมาก (ลดลง 64–80%) ในการประมวลผลและการจัดเก็บ เมื่อเทียบกับการย้าย Hadoop แบบยกและเปลี่ยน
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการเร่งความเร็วการย้าย Hadoop ของคุณไปยัง Amazon EMR และเครื่องมือ CTO ของ HMDK โปรดดูที่ ชุดการส่งมอบ Hadoop Migration คลังเก็บ TCO GitHubหรือติดต่อมาที่ AWS-HMDK@amazon.com.
เกี่ยวกับผู้แต่ง
 ปาร์คซองยอล เป็นผู้จัดการฝ่ายปฏิบัติอาวุโสที่ AWS ProServe เขาช่วยลูกค้าสร้างนวัตกรรมทางธุรกิจด้วยบริการ AWS Analytics, IoT และ AI/ML เขามีความเชี่ยวชาญด้านบริการบิ๊กดาต้าและเทคโนโลยี และมีความสนใจในการสร้างผลลัพธ์ทางธุรกิจของลูกค้าร่วมกัน
ปาร์คซองยอล เป็นผู้จัดการฝ่ายปฏิบัติอาวุโสที่ AWS ProServe เขาช่วยลูกค้าสร้างนวัตกรรมทางธุรกิจด้วยบริการ AWS Analytics, IoT และ AI/ML เขามีความเชี่ยวชาญด้านบริการบิ๊กดาต้าและเทคโนโลยี และมีความสนใจในการสร้างผลลัพธ์ทางธุรกิจของลูกค้าร่วมกัน
 จีซอง คิม เป็นสถาปนิกข้อมูลอาวุโสที่ AWS ProServe เขาทำงานร่วมกับลูกค้าระดับองค์กรเป็นหลักเพื่อช่วยในการย้ายและปรับปรุง Data Lake ให้ทันสมัย และให้คำแนะนำและความช่วยเหลือด้านเทคนิคเกี่ยวกับโครงการ Big Data เช่น Hadoop, Spark, คลังข้อมูล, การประมวลผลข้อมูลแบบเรียลไทม์ และการเรียนรู้ของเครื่องขนาดใหญ่ เขายังเข้าใจวิธีการใช้เทคโนโลยีเพื่อแก้ปัญหาข้อมูลขนาดใหญ่และสร้างสถาปัตยกรรมข้อมูลที่ออกแบบมาอย่างดี
จีซอง คิม เป็นสถาปนิกข้อมูลอาวุโสที่ AWS ProServe เขาทำงานร่วมกับลูกค้าระดับองค์กรเป็นหลักเพื่อช่วยในการย้ายและปรับปรุง Data Lake ให้ทันสมัย และให้คำแนะนำและความช่วยเหลือด้านเทคนิคเกี่ยวกับโครงการ Big Data เช่น Hadoop, Spark, คลังข้อมูล, การประมวลผลข้อมูลแบบเรียลไทม์ และการเรียนรู้ของเครื่องขนาดใหญ่ เขายังเข้าใจวิธีการใช้เทคโนโลยีเพื่อแก้ปัญหาข้อมูลขนาดใหญ่และสร้างสถาปัตยกรรมข้อมูลที่ออกแบบมาอย่างดี
 จอร์จ Zhao เป็นสถาปนิกข้อมูลอาวุโสที่ AWS ProServe เขาเป็นผู้นำด้านการวิเคราะห์ที่มีประสบการณ์ซึ่งทำงานร่วมกับลูกค้า AWS เพื่อนำเสนอโซลูชันข้อมูลที่ทันสมัย เขายังเป็นผู้เชี่ยวชาญด้านโดเมน ProServe Amazon EMR ที่ช่วยให้ที่ปรึกษาของ ProServe เกี่ยวกับแนวทางปฏิบัติที่ดีที่สุดและชุดการจัดส่งสำหรับการย้ายข้อมูล Hadoop ไปยัง Amazon EMR ความสนใจของเขาคือ Data Lake และการส่งมอบสถาปัตยกรรมข้อมูลสมัยใหม่บนคลาวด์
จอร์จ Zhao เป็นสถาปนิกข้อมูลอาวุโสที่ AWS ProServe เขาเป็นผู้นำด้านการวิเคราะห์ที่มีประสบการณ์ซึ่งทำงานร่วมกับลูกค้า AWS เพื่อนำเสนอโซลูชันข้อมูลที่ทันสมัย เขายังเป็นผู้เชี่ยวชาญด้านโดเมน ProServe Amazon EMR ที่ช่วยให้ที่ปรึกษาของ ProServe เกี่ยวกับแนวทางปฏิบัติที่ดีที่สุดและชุดการจัดส่งสำหรับการย้ายข้อมูล Hadoop ไปยัง Amazon EMR ความสนใจของเขาคือ Data Lake และการส่งมอบสถาปัตยกรรมข้อมูลสมัยใหม่บนคลาวด์
 คาเลน จาง เป็นหัวหน้าฝ่ายเทคโนโลยีส่วนงานระดับโลกของข้อมูลคู่ค้าและการวิเคราะห์ที่ AWS ในฐานะที่ปรึกษาด้านข้อมูลและการวิเคราะห์ที่เชื่อถือได้ เธอได้ดูแลจัดการความคิดริเริ่มเชิงกลยุทธ์สำหรับการแปลงข้อมูล นำข้อมูลและการวิเคราะห์เวิร์กโหลดการโยกย้ายและโปรแกรมการปรับปรุงให้ทันสมัย และเร่งรัดเส้นทางการโยกย้ายลูกค้ากับพันธมิตรตามขนาด เธอเชี่ยวชาญด้านระบบกระจาย การจัดการข้อมูลองค์กร การวิเคราะห์ขั้นสูง และการริเริ่มเชิงกลยุทธ์ขนาดใหญ่
คาเลน จาง เป็นหัวหน้าฝ่ายเทคโนโลยีส่วนงานระดับโลกของข้อมูลคู่ค้าและการวิเคราะห์ที่ AWS ในฐานะที่ปรึกษาด้านข้อมูลและการวิเคราะห์ที่เชื่อถือได้ เธอได้ดูแลจัดการความคิดริเริ่มเชิงกลยุทธ์สำหรับการแปลงข้อมูล นำข้อมูลและการวิเคราะห์เวิร์กโหลดการโยกย้ายและโปรแกรมการปรับปรุงให้ทันสมัย และเร่งรัดเส้นทางการโยกย้ายลูกค้ากับพันธมิตรตามขนาด เธอเชี่ยวชาญด้านระบบกระจาย การจัดการข้อมูลองค์กร การวิเคราะห์ขั้นสูง และการริเริ่มเชิงกลยุทธ์ขนาดใหญ่
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/deep-dive-into-the-aws-proserve-hadoop-migration-delivery-kit-tco-tool/
- 000
- 1
- 10
- 100
- 7
- a
- สามารถ
- เกี่ยวกับเรา
- เร่งความเร็ว
- เร่ง
- เร่ง
- เร่ง
- การเร่งความเร็ว
- การเข้าถึง
- ลงชื่อเข้าใช้
- ข้าม
- Ad
- นอกจากนี้
- เพิ่มเติม
- ข้อมูลเพิ่มเติม
- นอกจากนี้
- สูง
- กุนซือ
- หลังจาก
- กับ
- AI / ML
- ทั้งหมด
- อเมซอน
- Amazon EC2
- อเมซอน EMR
- ในหมู่
- การวิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- วิเคราะห์
- และ
- API
- การใช้งาน
- การใช้งาน
- ใช้
- อย่างเหมาะสม
- สถาปัตยกรรม
- AREA
- การประเมินผล
- ความช่วยเหลือ
- ที่เกี่ยวข้อง
- อัตโนมัติ
- ความพร้อมใช้งาน
- AWS
- การก่อตัวของ AWS Cloud
- ตาม
- รากฐาน
- เพราะ
- กำลัง
- ประโยชน์ที่ได้รับ
- ที่ดีที่สุด
- ปฏิบัติที่ดีที่สุด
- ดีกว่า
- ระหว่าง
- ใหญ่
- ข้อมูลขนาดใหญ่
- สั้น
- สร้าง
- การก่อสร้าง
- ธุรกิจ
- คำนวณ
- คำนวณ
- คำนวณ
- การคํานวณ
- ปฏิทิน
- ที่เรียกว่า
- โทร
- ความสามารถในการ
- ความจุ
- กรณี
- เซลล์
- บาง
- ท้าทาย
- แผนภูมิ
- ชาร์ต
- Choose
- เลือก
- เมฆ
- Cluster
- รวบรวม
- การเก็บรวบรวม
- ชุด
- สะสม
- เก็บรวบรวม
- COM
- เทียบเคียง
- เปรียบเทียบ
- เมื่อเทียบกับ
- สมบูรณ์
- คำนวณ
- จดจ่อ
- สมาธิ
- ความประพฤติ
- การดำเนิน
- เชื่อมต่อ
- การเชื่อมต่อ
- เชื่อมต่อ
- ติดต่อกัน
- การพิจารณา
- ปลอบใจ
- ที่ปรึกษา
- การบริโภค
- มี
- ตรงกัน
- ราคา
- ประหยัดค่าใช้จ่าย
- ค่าใช้จ่าย
- ซีพียู
- ที่สร้างขึ้น
- สร้าง
- เกณฑ์
- สำคัญมาก
- CTO
- curated
- เงินตรา
- ปัจจุบัน
- ลูกค้า
- ลูกค้า
- รอบ
- ประจำวัน
- หน้าปัด
- ข้อมูล
- ดาต้าเลค
- การจัดการข้อมูล
- การประมวลผล
- ชุดข้อมูล
- วัน
- วัน
- ทุ่มเท
- ลึก
- ดำน้ำลึก
- ส่งมอบ
- การจัดส่ง
- แสดงให้เห็นถึง
- ปรับใช้
- ออกแบบ
- การออกแบบ
- รายละเอียด
- กำหนด
- พัฒนาการ
- การเบี่ยงเบน
- ต่าง
- ส่วนลด
- กระจาย
- กระจาย
- ระบบกระจาย
- การกระจาย
- โดเมน
- ลง
- ในระหว่าง
- แต่ละ
- อย่างง่ายดาย
- EBS
- ฉบับ
- ผล
- ประสิทธิผล
- ความพยายาม
- ที่ฝัง
- ทำให้สามารถ
- เปิดการใช้งาน
- ช่วยให้
- จบสิ้น
- เครื่องยนต์
- เครื่องยนต์
- ทำให้มั่นใจ
- เข้าสู่
- Enterprise
- ลูกค้าองค์กร
- พร้อม
- สร้าง
- อีเธอร์ (ETH)
- เหตุการณ์
- ทุกๆ
- ตัวอย่าง
- ตัวอย่าง
- Excel
- ที่มีอยู่
- มีประสบการณ์
- อำนวยความสะดวก
- ครอบครัว
- ครอบครัว
- ลักษณะ
- คุณสมบัติ
- สนาม
- รูป
- เนื้อไม่มีมัน
- ไฟล์
- หา
- เสร็จสิ้น
- ดังต่อไปนี้
- รูป
- ราคาเริ่มต้นที่
- ฟังก์ชันการทำงาน
- ต่อไป
- อนาคต
- General
- สร้าง
- สร้าง
- ได้รับ
- ได้รับ
- GitHub
- เหตุการณ์ที่
- สีเขียว
- บัญชีกลุ่ม
- แนวทาง
- Hadoop
- ฮาร์ดแวร์
- ช่วย
- จะช่วยให้
- จุดสูง
- ประวัติ
- รัง
- วันหยุด
- แบบองค์รวม
- ชั่วโมง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- HTML
- HTTPS
- ICON
- การปรับปรุง
- in
- ประกอบด้วย
- รวมทั้ง
- เป็นรายบุคคล
- บุคคล
- ข้อมูล
- ความคิดริเริ่ม
- เราสร้างสรรค์สิ่งใหม่ ๆ
- อินพุต
- ข้อมูลเชิงลึก
- ตัวอย่าง
- คำแนะนำการใช้
- อยากเรียนรู้
- ผลประโยชน์
- แนะนำ
- IOT
- IT
- การสัมภาษณ์
- งาน
- เส้นทางท่องเที่ยว
- JSON
- คีย์
- ชุด
- ทะเลสาบ
- ใหญ่
- ขนาดใหญ่
- เปิดตัว
- นำ
- ผู้นำ
- เรียนรู้
- การเรียนรู้
- นำ
- นำข้อมูล
- รายการ
- โหลด
- ในประเทศ
- นาน
- เวลานาน
- ดู
- Lot
- เครื่อง
- เรียนรู้เครื่อง
- แมโคร
- หลัก
- ทำ
- การจัดการ
- ผู้จัดการ
- ผู้จัดการ
- หลาย
- วิธี
- ในขณะเดียวกัน
- หน่วยความจำ
- การผสม
- ตัวชี้วัด
- การโยกย้าย
- นาที
- ผสม
- ทันสมัย
- สร้างสรรค์สิ่งใหม่ ๆ
- เดือน
- รายเดือน
- ข้อมูลเพิ่มเติม
- หลาย
- ธรรมชาติ
- จำเป็นต้อง
- ถัดไป
- ปม
- โหนด
- จำนวน
- ตัวเลข
- สังเกต
- การได้รับ
- ONE
- เปิด
- การดำเนินงาน
- การดำเนินการ
- ดีที่สุด
- การปรับให้เหมาะสม
- การเพิ่มประสิทธิภาพ
- สูงสุด
- องค์กร
- อื่นๆ
- ในสิ่งที่สนใจ
- หุ้นส่วน
- พาร์ทเนอร์
- รูปแบบ
- จุดสูงสุด
- ดำเนินการ
- การปฏิบัติ
- ระยะเวลา
- การอนุญาต
- สถานที่
- การวางแผน
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- นโยบาย
- เป็นไปได้
- โพสต์
- การปฏิบัติ
- การปฏิบัติ
- ข้อกำหนดเบื้องต้น
- ก่อนหน้านี้
- การตั้งราคา
- ประถม
- ก่อน
- ปัญหาที่เกิดขึ้น
- การประมวลผล
- โปรแกรม
- โครงการ
- เหมาะสม
- เสนอ
- ให้
- ให้
- หลาม
- อย่างรวดเร็ว
- คะแนน
- อัตราส่วน
- มาถึง
- พร้อม
- เรียลไทม์
- ข้อมูลตามเวลาจริง
- แนะนำ
- แนะนำ
- บันทึก
- ลด
- เกี่ยวกับ
- ภูมิภาค
- ปกติ
- ลบ
- การทำซ้ำ
- ทรัพยากร
- แหล่งข้อมูล
- ผลสอบ
- ความจำ
- รอบ
- วิ่ง
- วิ่ง
- เดียวกัน
- เงินออม
- ขนาด
- กำหนด
- ภาพหน้าจอ
- ส่วน
- ส่วน
- ระดับอาวุโส
- ชุด
- บริการ
- ชุด
- การตั้งค่า
- หลาย
- ที่ใช้ร่วมกัน
- โชว์
- แสดง
- สำคัญ
- อย่างมีความหมาย
- คล้ายคลึงกัน
- ง่าย
- จำลอง
- จำลอง
- สถานการณ์
- ขนาด
- เล็ก
- So
- โซลูชัน
- แก้
- บาง
- จุดประกาย
- ผู้เชี่ยวชาญ
- ความเชี่ยวชาญ
- พิเศษ
- โดยเฉพาะ
- ข้อกำหนด
- กอง
- ข้อความที่เริ่ม
- สถิติ
- Status
- ขั้นตอน
- ขั้นตอน
- การเก็บรักษา
- ยุทธศาสตร์
- ส่ง
- อย่างเช่น
- ที่สนับสนุน
- ระบบ
- ระบบ
- ตาราง
- ปรับปรุง
- ใช้เวลา
- เป้า
- งาน
- ทีม
- ทีม
- เทคโนโลยี
- วิชาการ
- เทคโนโลยี
- เทมเพลต
- แม่แบบ
- การทดสอบ
- พื้นที่
- ก้าวสู่อนาคต
- ของพวกเขา
- ดังนั้น
- ตลอด
- เวลา
- อนุกรมเวลา
- ต้องใช้เวลามาก
- ไทม์ไลน์
- ไปยัง
- ร่วมกัน
- เครื่องมือ
- แปลง
- การแปลง
- เปลี่ยน
- จริง
- ที่เชื่อถือ
- ชนิด
- ภายใต้
- เข้าใจ
- ความเข้าใจ
- เข้าใจ
- การใช้
- ใช้
- ผู้ใช้งาน
- ผู้ใช้
- มักจะ
- ต่างๆ
- ตรวจสอบ
- การสร้างภาพ
- ปริมาณ
- ที่เดิน
- การจัดเก็บสินค้า
- สัปดาห์
- รายสัปดาห์
- สัปดาห์ที่ผ่านมา
- อะไร
- ความหมายของ
- ที่
- WHO
- หน้าต่าง
- ไม่มี
- เวิร์กโฟลว์
- การทำงาน
- โรงงาน
- มันแกว
- ของคุณ
- ลมทะเล