บทนำ
ในภูมิทัศน์ที่พัฒนาอย่างรวดเร็วของ generative AI บทบาทสำคัญของฐานข้อมูลเวกเตอร์มีความชัดเจนมากขึ้น บทความนี้จะเจาะลึกถึงการทำงานร่วมกันแบบไดนามิกระหว่างฐานข้อมูลเวกเตอร์และโซลูชัน AI เชิงสร้างสรรค์ โดยสำรวจว่ารากฐานทางเทคโนโลยีเหล่านี้กำลังกำหนดอนาคตของความคิดสร้างสรรค์ด้านปัญญาประดิษฐ์อย่างไร เข้าร่วมกับเราในการเดินทางผ่านความซับซ้อนของพันธมิตรอันทรงพลังนี้ ปลดล็อกข้อมูลเชิงลึกเกี่ยวกับผลกระทบด้านการเปลี่ยนแปลงที่ฐานข้อมูลเวกเตอร์นำมาสู่แถวหน้าของโซลูชัน AI เชิงนวัตกรรม
วัตถุประสงค์การเรียนรู้
บทความนี้ช่วยให้คุณเข้าใจแง่มุมต่างๆ ของฐานข้อมูลเวกเตอร์ด้านล่าง
- ความสำคัญของฐานข้อมูลเวกเตอร์และส่วนประกอบที่สำคัญ
- การศึกษารายละเอียดของการเปรียบเทียบฐานข้อมูลเวกเตอร์กับฐานข้อมูลแบบดั้งเดิม
- การสำรวจการฝังเวกเตอร์จากมุมมองของแอปพลิเคชัน
- การสร้างฐานข้อมูลเวกเตอร์โดยใช้ Pincone
- การใช้งานฐานข้อมูล Pinecone Vector โดยใช้โมเดล langchain LLM
บทความนี้เผยแพร่โดยเป็นส่วนหนึ่งของไฟล์ Blogathon วิทยาศาสตร์ข้อมูล
สารบัญ
ฐานข้อมูลเวกเตอร์คืออะไร?
ฐานข้อมูลเวกเตอร์เป็นรูปแบบหนึ่งของการรวบรวมข้อมูลที่จัดเก็บไว้ในอวกาศ อย่างไรก็ตาม ที่นี่ มันถูกจัดเก็บไว้ในการแทนค่าทางคณิตศาสตร์ เนื่องจากรูปแบบที่จัดเก็บไว้ในฐานข้อมูลช่วยให้โมเดล AI แบบเปิดสามารถจดจำอินพุตได้ง่ายขึ้น และอนุญาตให้แอปพลิเคชัน AI แบบเปิดของเราใช้การค้นหาทางปัญญา คำแนะนำ และการสร้างข้อความสำหรับกรณีการใช้งานต่างๆ ใน อุตสาหกรรมที่มีการเปลี่ยนแปลงทางดิจิทัล การจัดเก็บและการเรียกค้นข้อมูลเรียกว่า "การฝังเวกเตอร์" หรือ "การฝัง" นอกจากนี้ ยังแสดงในรูปแบบอาเรย์ตัวเลขอีกด้วย การค้นหาง่ายกว่าฐานข้อมูลแบบเดิมที่ใช้สำหรับเปอร์สเปคทีฟ AI ที่มีความสามารถในการจัดทำดัชนีจำนวนมาก
ลักษณะของฐานข้อมูลเวกเตอร์
- โดยใช้ประโยชน์จากพลังของการฝังเวกเตอร์เหล่านี้ ซึ่งนำไปสู่การจัดทำดัชนีและการค้นหาในชุดข้อมูลขนาดใหญ่
- บีบอัดข้อมูลได้ทุกรูปแบบ (รูปภาพ ข้อความ หรือข้อมูล)
- เนื่องจากปรับเทคนิคการฝังและคุณลักษณะที่มีการจัดทำดัชนีสูง จึงสามารถนำเสนอโซลูชั่นที่สมบูรณ์สำหรับการจัดการข้อมูลและอินพุตสำหรับปัญหาที่กำหนด
- ฐานข้อมูลเวกเตอร์จัดระเบียบข้อมูลผ่านเวกเตอร์มิติสูงที่มีหลายร้อยมิติ เราสามารถกำหนดค่าได้อย่างรวดเร็ว
- แต่ละมิติสอดคล้องกับคุณลักษณะหรือคุณสมบัติเฉพาะของออบเจ็กต์ข้อมูลที่แสดง
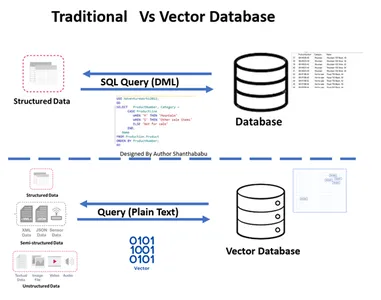
แบบดั้งเดิมกับ ฐานข้อมูลเวกเตอร์
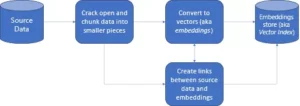
- รูปภาพแสดงเวิร์กโฟลว์ระดับสูงของฐานข้อมูลแบบดั้งเดิมและเวกเตอร์
- การโต้ตอบฐานข้อมูลอย่างเป็นทางการเกิดขึ้นผ่าน SQL คำสั่งและข้อมูลที่เก็บในรูปแบบแถวฐานและตาราง
- ในฐานข้อมูล Vector การโต้ตอบเกิดขึ้นผ่านข้อความธรรมดา (เช่น ภาษาอังกฤษ) และข้อมูลที่จัดเก็บไว้ในการแทนค่าทางคณิตศาสตร์
ความคล้ายคลึงกันของฐานข้อมูลแบบดั้งเดิมและเวกเตอร์
เราต้องพิจารณาว่าฐานข้อมูล Vector แตกต่างจากฐานข้อมูลแบบเดิมอย่างไร มาพูดคุยกันที่นี่ ข้อแตกต่างสั้นๆ ประการหนึ่งที่ฉันสามารถให้ได้ก็คือในฐานข้อมูลทั่วไป ข้อมูลจะถูกจัดเก็บอย่างแม่นยำตามสภาพที่เป็นอยู่ เราสามารถเพิ่มตรรกะทางธุรกิจเพื่อปรับแต่งข้อมูลและผสานหรือแยกข้อมูลตามความต้องการหรือความต้องการทางธุรกิจ อย่างไรก็ตาม ฐานข้อมูลเวกเตอร์มีการเปลี่ยนแปลงครั้งใหญ่ และข้อมูลกลายเป็นการแสดงเวกเตอร์ที่ซับซ้อน
นี่คือแผนที่สำหรับความเข้าใจและมุมมองที่ชัดเจนของคุณ ฐานข้อมูลเชิงสัมพันธ์ เทียบกับฐานข้อมูลเวกเตอร์ รูปภาพด้านล่างนี้อธิบายได้ในตัวสำหรับการทำความเข้าใจฐานข้อมูลเวกเตอร์ด้วยฐานข้อมูลแบบดั้งเดิม กล่าวโดยสรุป เราสามารถดำเนินการแทรกและลบลงในฐานข้อมูลเวกเตอร์ ไม่ใช่อัปเดตคำสั่ง
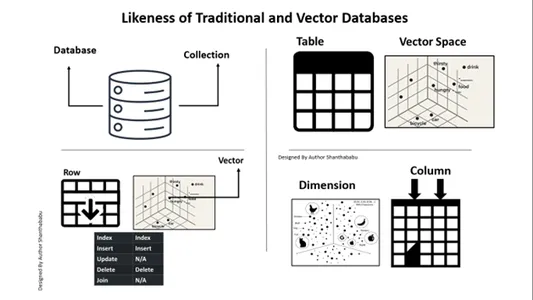
การเปรียบเทียบอย่างง่ายเพื่อทำความเข้าใจฐานข้อมูลเวกเตอร์
ข้อมูลจะถูกจัดเรียงตามพื้นที่โดยอัตโนมัติตามความคล้ายคลึงกันของเนื้อหาในข้อมูลที่จัดเก็บ ดังนั้น ลองพิจารณาร้านค้าแผนกสำหรับการเปรียบเทียบฐานข้อมูลเวกเตอร์ สินค้าทั้งหมดจะถูกจัดวางบนชั้นวางโดยคำนึงถึงลักษณะ วัตถุประสงค์ การผลิต การใช้งาน และฐานปริมาณ ในพฤติกรรมที่คล้ายคลึงกันข้อมูลก็คือ
จัดเรียงโดยอัตโนมัติในฐานข้อมูลเวกเตอร์โดยการเรียงลำดับที่คล้ายกัน แม้ว่าประเภทจะไม่ถูกกำหนดไว้อย่างดีในขณะที่จัดเก็บหรือเข้าถึงข้อมูล
ฐานข้อมูลเวกเตอร์ช่วยให้เห็นรายละเอียดและขนาดที่ชัดเจนของความคล้ายคลึงกัน ดังนั้นลูกค้าจึงค้นหาผลิตภัณฑ์ ผู้ผลิต และปริมาณที่ต้องการ และเก็บสินค้าไว้ในรถเข็น ฐานข้อมูลเวกเตอร์จัดเก็บข้อมูลทั้งหมดไว้ในโครงสร้างการจัดเก็บข้อมูลที่สมบูรณ์แบบ ที่นี่ วิศวกร Machine Learning และ AI ไม่จำเป็นต้องติดป้ายกำกับหรือแท็กเนื้อหาที่จัดเก็บด้วยตนเอง
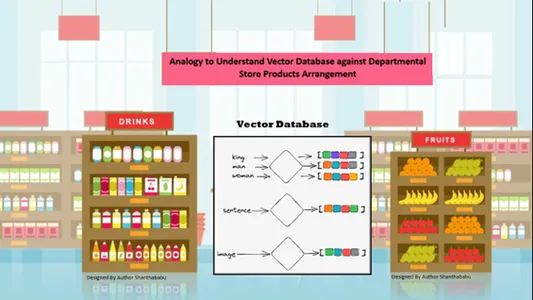
ทฤษฎีสำคัญเบื้องหลังฐานข้อมูลเวกเตอร์
- การฝังเวกเตอร์และขอบเขตของมัน
- ข้อกำหนดในการจัดทำดัชนี
- ทำความเข้าใจกับการค้นหาความหมายและความคล้ายคลึง
การฝังเวกเตอร์และขอบเขต
การฝังเวกเตอร์คือการแสดงเวกเตอร์ในแง่ของค่าตัวเลข ในรูปแบบที่บีบอัด การฝังจะจับคุณสมบัติและการเชื่อมโยงโดยธรรมชาติของข้อมูลต้นฉบับ ทำให้กลายเป็นส่วนสำคัญในกรณีการใช้งานปัญญาประดิษฐ์และการเรียนรู้ของเครื่อง การออกแบบการฝังเพื่อเข้ารหัสข้อมูลที่เกี่ยวข้องกับข้อมูลต้นฉบับลงในพื้นที่มิติที่ต่ำกว่า ช่วยให้มั่นใจได้ถึงความเร็วในการดึงข้อมูลสูง ประสิทธิภาพในการคำนวณ และการจัดเก็บข้อมูลที่มีประสิทธิภาพ
การจับสาระสำคัญของข้อมูลในลักษณะที่มีโครงสร้างเหมือนกันมากขึ้นคือกระบวนการของการฝังเวกเตอร์ โดยสร้าง 'โมเดลการฝัง' ในท้ายที่สุด โมเดลเหล่านี้จะพิจารณาออบเจ็กต์ข้อมูลทั้งหมด แยกรูปแบบและความสัมพันธ์ที่มีความหมายภายในแหล่งข้อมูล และแปลงให้เป็นการฝังเวกเตอร์ . ต่อจากนั้น อัลกอริธึมจะใช้ประโยชน์จากการฝังเวกเตอร์เหล่านี้เพื่อดำเนินงานต่างๆ โมเดลการฝังที่ได้รับการพัฒนาอย่างสูงจำนวนมาก ซึ่งมีจำหน่ายทางออนไลน์ทั้งแบบฟรีหรือแบบจ่ายเงินตามการใช้งาน ช่วยให้การฝังเวกเตอร์ประสบความสำเร็จ
ขอบเขตของการฝังเวกเตอร์จากมุมมองของแอปพลิเคชัน
การฝังเหล่านี้มีขนาดเล็ก มีข้อมูลที่ซับซ้อน สืบทอดความสัมพันธ์ระหว่างข้อมูลที่จัดเก็บไว้ในฐานข้อมูลเวกเตอร์ ช่วยให้สามารถวิเคราะห์การประมวลผลข้อมูลที่มีประสิทธิภาพเพื่ออำนวยความสะดวกในการทำความเข้าใจและการตัดสินใจ และสร้างผลิตภัณฑ์ข้อมูลที่เป็นนวัตกรรมใหม่ๆ แบบไดนามิกทั่วทั้งองค์กร
เทคนิคการฝังเวกเตอร์ถือเป็นสิ่งสำคัญในการเชื่อมต่อช่องว่างระหว่างข้อมูลที่อ่านได้กับอัลกอริธึมที่ซับซ้อน เนื่องจากประเภทข้อมูลเป็นเวกเตอร์ตัวเลข เราจึงสามารถปลดล็อกศักยภาพสำหรับแอปพลิเคชัน Generative AI ที่หลากหลายพร้อมกับโมเดล Open AI ที่มีจำหน่าย
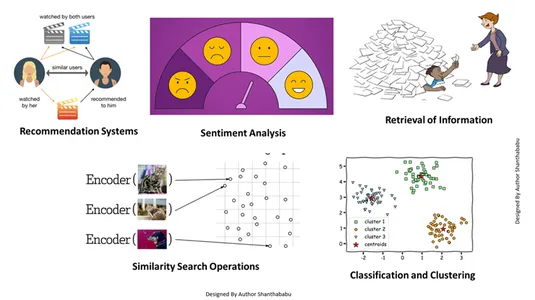
งานหลายงานพร้อมการฝังเวกเตอร์
การฝังเวกเตอร์นี้ช่วยให้เราทำงานหลายอย่างได้:
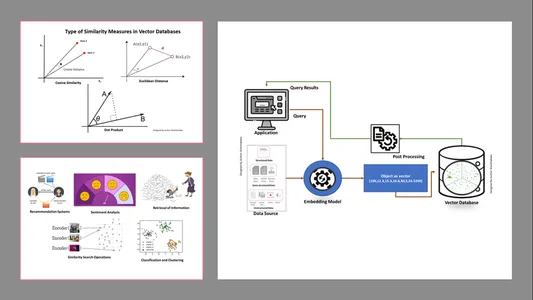
- การสืบค้นข้อมูล: ด้วยความช่วยเหลือของเทคนิคอันทรงพลังเหล่านี้ เราสามารถสร้างเครื่องมือค้นหาที่ทรงอิทธิพลซึ่งสามารถช่วยให้เราค้นหาคำตอบตามคำค้นหาของผู้ใช้จากไฟล์ เอกสาร หรือสื่อที่เก็บไว้
- การดำเนินการค้นหาความคล้ายคลึงกัน: นี่เป็นการจัดระเบียบและจัดทำดัชนีอย่างดี มันช่วยให้เราค้นหาความคล้ายคลึงกันระหว่างเหตุการณ์ต่างๆ ในข้อมูลเวกเตอร์
- การจำแนกประเภทและการจัดกลุ่ม: การใช้เทคนิคการฝังเหล่านี้ทำให้เราสามารถใช้โมเดลเหล่านี้เพื่อฝึกอัลกอริธึมแมชชีนเลิร์นนิงที่เกี่ยวข้องและจัดกลุ่มและจำแนกประเภทได้
- ระบบคำแนะนำ: เนื่องจากเทคนิคการฝังได้รับการจัดระเบียบอย่างเหมาะสม จึงนำไปสู่ระบบการแนะนำที่เกี่ยวข้องกับผลิตภัณฑ์ สื่อ และบทความอย่างแม่นยำตามข้อมูลในอดีต
- การวิเคราะห์ความรู้สึก: โมเดลการฝังนี้ช่วยให้เราจัดหมวดหมู่และรับโซลูชันทางความรู้สึกได้
ข้อกำหนดในการจัดทำดัชนี
ดังที่เราทราบ ดัชนีจะปรับปรุงข้อมูลการค้นหาจากตารางในฐานข้อมูลแบบดั้งเดิม ซึ่งคล้ายกับฐานข้อมูลเวกเตอร์ และจัดเตรียมคุณลักษณะการจัดทำดัชนี
ฐานข้อมูลเวกเตอร์จัดให้มี "ดัชนีแบบเรียบ" ซึ่งเป็นการแสดงโดยตรงของการฝังเวกเตอร์ ความสามารถในการค้นหามีความครอบคลุม และไม่ได้ใช้คลัสเตอร์ที่ได้รับการฝึกอบรมล่วงหน้า โดยจะดำเนินการค้นหาเวกเตอร์กับแต่ละเวกเตอร์ที่ฝังอยู่ และระยะทาง K จะถูกคำนวณสำหรับแต่ละคู่
- เนื่องจากความง่ายของดัชนีนี้ จึงจำเป็นต้องมีการคำนวณขั้นต่ำเพื่อสร้างดัชนีใหม่
- อันที่จริงดัชนีแบบแบนสามารถจัดการกับการสืบค้นได้อย่างมีประสิทธิภาพและให้เวลาในการเรียกค้นที่รวดเร็ว
ทำความเข้าใจกับการค้นหาความหมายและความคล้ายคลึง
เราทำการค้นหาที่แตกต่างกันสองครั้งในฐานข้อมูลเวกเตอร์: การค้นหาความหมายและความคล้ายคลึงกัน
- ค้นหาความหมาย: ในขณะที่ค้นหาข้อมูล แทนที่จะค้นหาด้วยคำสำคัญ คุณสามารถค้นหาข้อมูลเหล่านั้นได้โดยอาศัยวิธีการสนทนาที่มีความหมาย วิศวกรรมพร้อมท์มีบทบาทสำคัญในการส่งผ่านข้อมูลเข้าไปยังระบบ การค้นหานี้ช่วยให้การค้นหาและผลลัพธ์คุณภาพสูงขึ้นอย่างไม่ต้องสงสัย ซึ่งสามารถป้อนให้กับแอปพลิเคชันเชิงนวัตกรรม, SEO, การสร้างข้อความ และการสรุป
- ค้นหาความคล้ายคลึงกัน: ในการวิเคราะห์ข้อมูลเสมอ การค้นหาความคล้ายคลึงกันช่วยให้ได้ชุดข้อมูลที่ไม่มีโครงสร้างและได้รับมอบที่ดีกว่ามาก เกี่ยวกับฐานข้อมูลเวกเตอร์ เราต้องตรวจสอบความใกล้ชิดของเวกเตอร์สองตัวและลักษณะที่พวกมันคล้ายกัน: ตาราง ข้อความ เอกสาร รูปภาพ คำ และไฟล์เสียง ในกระบวนการทำความเข้าใจ ความคล้ายคลึงกันระหว่างเวกเตอร์จะถูกเปิดเผยว่าเป็นความคล้ายคลึงกันระหว่างวัตถุข้อมูลในชุดข้อมูลที่กำหนด แบบฝึกหัดนี้ช่วยให้เราเข้าใจปฏิสัมพันธ์ ระบุรูปแบบ ดึงข้อมูลเชิงลึก และตัดสินใจจากมุมมองของแอปพลิเคชัน การค้นหาความหมายและความคล้ายคลึงจะช่วยเราสร้างแอปพลิเคชันด้านล่างเพื่อประโยชน์ของอุตสาหกรรม
- การสืบค้นข้อมูล: เมื่อใช้ Open AI และฐานข้อมูล Vector เราจะสร้างเครื่องมือค้นหาสำหรับการดึงข้อมูลโดยใช้คำค้นหาของผู้ใช้ทางธุรกิจหรือผู้ใช้ปลายทางและเอกสารที่จัดทำดัชนีภายในฐานข้อมูลเวกเตอร์
- การจำแนกประเภทและการจัดกลุ่ม:การจัดประเภทหรือการจัดกลุ่มจุดข้อมูลหรือกลุ่มวัตถุที่คล้ายกันเกี่ยวข้องกับการกำหนดให้กับหลายหมวดหมู่ตามลักษณะที่ใช้ร่วมกัน
- การตรวจจับความผิดปกติ: การค้นพบความผิดปกติจากรูปแบบปกติโดยการวัดความคล้ายคลึงกันของจุดข้อมูลและการตรวจจับความผิดปกติ
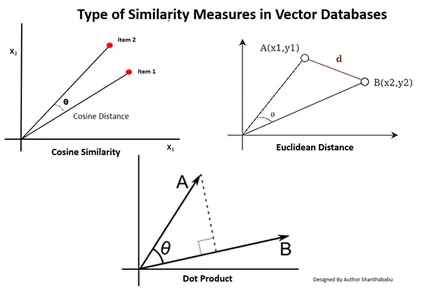
ประเภทของการวัดความคล้ายคลึงกันในฐานข้อมูลเวกเตอร์
วิธีการวัดขึ้นอยู่กับลักษณะของข้อมูลและการใช้งานเฉพาะ โดยทั่วไป จะมีการใช้สามวิธีในการวัดความคล้ายคลึงและความคุ้นเคยกับการเรียนรู้ของเครื่อง
ระยะทางแบบยุคลิด
พูดง่ายๆ ก็คือ ระยะห่างระหว่างเวกเตอร์สองตัวคือระยะห่างเป็นเส้นตรงระหว่างจุดเวกเตอร์สองตัวที่ใช้วัดค่าเซนต์
ดอทโปรดักส์
สิ่งนี้ช่วยให้เราเข้าใจการจัดตำแหน่งระหว่างเวกเตอร์สองตัว โดยระบุว่าเวกเตอร์สองตัวชี้ไปในทิศทางเดียวกัน ทิศทางตรงกันข้าม หรือตั้งฉากกัน
ความคล้ายคลึงของโคไซน์
ประเมินความคล้ายคลึงกันของเวกเตอร์สองตัวโดยใช้มุมระหว่างเวกเตอร์ดังแสดงในรูป ในกรณีนี้ ค่าและขนาดของเวกเตอร์ไม่มีนัยสำคัญและไม่ส่งผลกระทบต่อผลลัพธ์ พิจารณาเฉพาะมุมเท่านั้นในการคำนวณ
ฐานข้อมูลแบบดั้งเดิม ค้นหาคำสั่ง SQL ที่ตรงกันทุกประการและดึงข้อมูลในรูปแบบตาราง ในเวลาเดียวกัน เราจัดการกับฐานข้อมูลเวกเตอร์ที่ค้นหาเวกเตอร์ที่คล้ายกันมากที่สุดกับอินพุตคิวรีในภาษาอังกฤษธรรมดาโดยใช้เทคนิค Prompt Engineering ฐานข้อมูลใช้อัลกอริธึมการค้นหาใกล้เคียงที่ใกล้ที่สุด (ANN) เพื่อค้นหาข้อมูลที่คล้ายคลึงกัน ให้ผลลัพธ์ที่แม่นยำพอสมควรเสมอโดยมีประสิทธิภาพ ความแม่นยำ และเวลาตอบสนองสูง
กลไกการทำงาน
- ขั้นแรกฐานข้อมูลเวกเตอร์จะแปลงข้อมูลเป็นเวกเตอร์ที่ฝังไว้ เก็บไว้ในฐานข้อมูลเวกเตอร์ และสร้างดัชนีเพื่อการค้นหาที่รวดเร็วยิ่งขึ้น
- การสืบค้นจากแอปพลิเคชันจะโต้ตอบกับเวกเตอร์ที่ฝัง ค้นหาเพื่อนบ้านที่ใกล้ที่สุดหรือข้อมูลที่คล้ายกันในฐานข้อมูลเวกเตอร์โดยใช้ดัชนี และดึงผลลัพธ์ที่ส่งไปยังแอปพลิเคชัน
- ตามความต้องการทางธุรกิจ ข้อมูลที่ดึงมาจะได้รับการปรับแต่ง จัดรูปแบบ และแสดงต่อฝั่งผู้ใช้ปลายทาง หรือฟีดข้อความค้นหาหรือการดำเนินการ
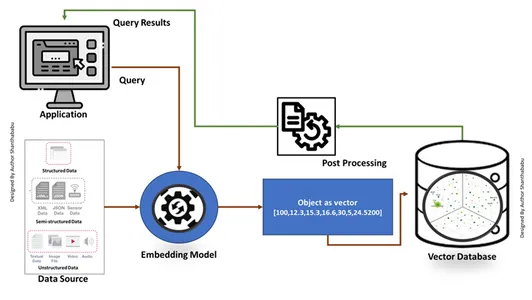
การสร้างฐานข้อมูลเวกเตอร์
มาเชื่อมต่อกับ Pinecone กันเถอะ
คุณสามารถเชื่อมต่อกับ Pinecone โดยใช้ Google, GitHub หรือ Microsoft ID
สร้างข้อมูลเข้าสู่ระบบผู้ใช้ใหม่สำหรับการใช้งานของคุณ
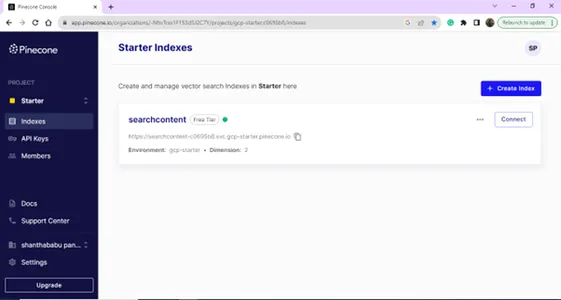
หลังจากเข้าสู่ระบบสำเร็จ คุณจะเข้าสู่หน้าดัชนี คุณสามารถสร้างดัชนีสำหรับวัตถุประสงค์ฐานข้อมูลเวกเตอร์ของคุณได้ คลิกที่ปุ่มสร้างดัชนี
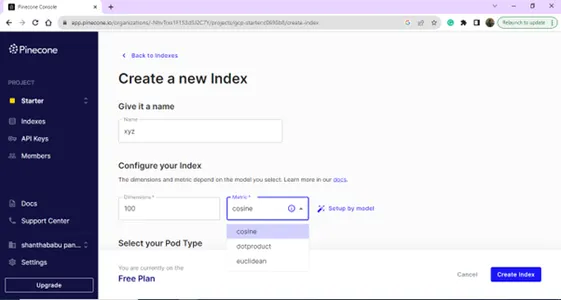
สร้างดัชนีใหม่ของคุณโดยระบุชื่อและขนาด
หน้ารายการดัชนี
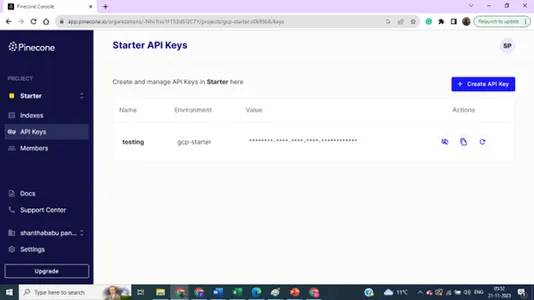
รายละเอียดดัชนี – ชื่อ ภูมิภาค และสภาพแวดล้อม – เราต้องการรายละเอียดทั้งหมดนี้เพื่อเชื่อมต่อฐานข้อมูลเวกเตอร์ของเราจากโค้ดการสร้างโมเดล
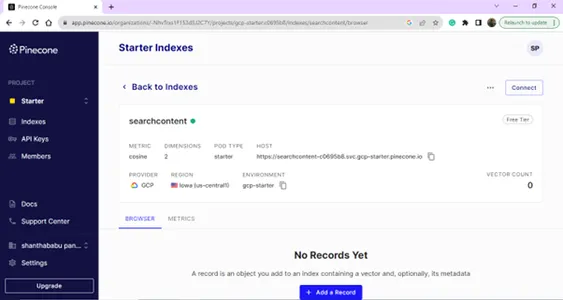
รายละเอียดการตั้งค่าโครงการ
คุณสามารถอัปเกรดการตั้งค่าของคุณสำหรับดัชนีและคีย์หลายรายการเพื่อวัตถุประสงค์ของโปรเจ็กต์
จนถึงตอนนี้ เราได้พูดคุยถึงการสร้างดัชนีฐานข้อมูลเวกเตอร์และการตั้งค่าใน Pinecone แล้ว
การใช้งานฐานข้อมูลเวกเตอร์โดยใช้ Python
มาเขียนโค้ดกันตอนนี้เลย
การนำเข้าไลบรารี
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAIจัดเตรียมคีย์ API สำหรับฐานข้อมูล OpenAI และ Vector
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)การริเริ่ม LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)การเริ่มต้นไพน์โคน
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" กำลังโหลดไฟล์ .csv เพื่อสร้างฐานข้อมูลเวกเตอร์
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()แบ่งข้อความออกเป็น Chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)ค้นหาข้อความใน text_chunk
text_chunksเอาท์พุต
[Document(page_content='name: 100% Brannmfr: Nntype: Cnแคลอรี่: 70nprotein: 4nfat: 1nsodium: 130nfiber: 10ncarbo: 5nsugars: 6npotass: 280nvitamins: 25nshelf: 3nweight: 1ncups: 0.33nrating: 68.402973nre คำชมเชย: Kids', ข้อมูลเมตา={ 'แหล่งที่มา': 'รำ 100%', 'แถว': 0}), , …..
การฝังอาคาร
embeddings = OpenAIEmbeddings()สร้างอินสแตนซ์ Pinecone สำหรับฐานข้อมูลเวกเตอร์จาก 'data'
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")สร้างรีทรีฟเวอร์สำหรับการสืบค้นฐานข้อมูลเวกเตอร์
retriever = vectordb.as_retriever(score_threshold = 0.7)การดึงข้อมูลจากฐานข้อมูลเวกเตอร์
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsการใช้ Prompt และดึงข้อมูล
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
ลองสืบค้นข้อมูลกัน
chain('Can you please provide cereal recommendation for Kids?')เอาท์พุตจากการสืบค้น
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]สรุป
หวังว่าคุณจะเข้าใจวิธีการทำงานของฐานข้อมูลเวกเตอร์ ส่วนประกอบ สถาปัตยกรรม และคุณลักษณะของฐานข้อมูลเวกเตอร์ในโซลูชัน Generative AI ทำความเข้าใจว่าฐานข้อมูลเวกเตอร์แตกต่างจากฐานข้อมูลแบบดั้งเดิมอย่างไร และเปรียบเทียบกับองค์ประกอบฐานข้อมูลทั่วไปได้อย่างไร แท้จริงแล้ว การเปรียบเทียบช่วยให้คุณเข้าใจฐานข้อมูลเวกเตอร์ได้ดีขึ้น ฐานข้อมูลเวกเตอร์ของ Pinecone และขั้นตอนการจัดทำดัชนีจะช่วยคุณสร้างฐานข้อมูลเวกเตอร์และนำคีย์สำหรับการติดตั้งโค้ดต่อไปนี้
ประเด็นที่สำคัญ
- สามารถบีบอัดข้อมูลที่มีโครงสร้าง ไม่มีโครงสร้าง และกึ่งโครงสร้างได้
- ปรับเทคนิคการฝังและคุณลักษณะที่มีการจัดทำดัชนีสูง
- การโต้ตอบเกิดขึ้นผ่านข้อความธรรมดาโดยใช้ข้อความแจ้ง (เช่น ภาษาอังกฤษ) และข้อมูลที่เก็บอยู่ในการแทนค่าทางคณิตศาสตร์
- ความคล้ายคลึงกันจะปรับเทียบในฐานข้อมูลเวกเตอร์ผ่าน – ระยะทางแบบยุคลิด ความคล้ายคลึงกันของโคไซน์ และดอทโปรดัค
คำถามที่พบบ่อย
A. ฐานข้อมูลเวกเตอร์จัดเก็บชุดข้อมูลในอวกาศ มันเก็บข้อมูลไว้ในรูปแบบทางคณิตศาสตร์ เนื่องจากรูปแบบที่จัดเก็บไว้ในฐานข้อมูลช่วยให้โมเดล AI แบบเปิดสามารถจดจำอินพุตก่อนหน้าได้ง่ายขึ้น และช่วยให้แอปพลิเคชัน AI แบบเปิดของเราใช้การค้นหาแบบองค์ความรู้ คำแนะนำ และการสร้างข้อความที่แม่นยำสำหรับกรณีการใช้งานต่างๆ ในอุตสาหกรรมที่เปลี่ยนแปลงทางดิจิทัล
A. คุณลักษณะบางประการได้แก่: 1. ใช้ประโยชน์จากพลังของการฝังเวกเตอร์เหล่านี้ ซึ่งนำไปสู่การจัดทำดัชนีและการค้นหาในชุดข้อมูลขนาดใหญ่ 2. สามารถบีบอัดข้อมูลที่มีโครงสร้าง ไม่มีโครงสร้าง และกึ่งโครงสร้างได้ 3. ฐานข้อมูลเวกเตอร์จัดระเบียบข้อมูลผ่านเวกเตอร์มิติสูงที่มีหลายร้อยมิติ
ก. ฐานข้อมูล ==> คอลเลกชัน
ตาราง==> สเปซเวกเตอร์
แถว==>ซีกเตอร์
คอลัมน์==>มิติ
การแทรกและการลบสามารถทำได้ในฐานข้อมูล Vector เช่นเดียวกับในฐานข้อมูลแบบดั้งเดิม
การอัปเดตและเข้าร่วมไม่อยู่ในขอบเขต
– การดึงข้อมูลเพื่อการรวบรวมข้อมูลจำนวนมากอย่างรวดเร็ว
– การดำเนินการค้นหาความหมายและความคล้ายคลึงจากเอกสารขนาดใหญ่
– การจำแนกประเภทและการประยุกต์ใช้การจัดกลุ่ม
– ระบบการวิเคราะห์ข้อเสนอแนะและความรู้สึก
A5: ด้านล่างนี้คือสามวิธีในการวัดความคล้ายคลึงกัน:
– ระยะทางแบบยุคลิด
– ความคล้ายคลึงกันของโคไซน์
– ดอทโปรดัคท์
สื่อที่แสดงในบทความนี้ไม่ได้เป็นของ Analytics Vidhya และถูกใช้ตามดุลยพินิจของผู้เขียน
ที่เกี่ยวข้อง
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- :มี
- :เป็น
- :ไม่
- $ ขึ้น
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- สามารถ
- เกี่ยวกับเรา
- การเข้าถึง
- ความถูกต้อง
- ถูกต้อง
- แม่นยำ
- ข้าม
- ปรับ
- เพิ่ม
- มีผลต่อ
- AI
- โมเดล AI
- ขั้นตอนวิธี
- อัลกอริทึม
- การวางแนว
- ทั้งหมด
- พันธมิตร
- อนุญาต
- ช่วยให้
- ตาม
- เสมอ
- ในหมู่
- an
- การวิเคราะห์
- การวิเคราะห์
- การวิเคราะห์ วิทยา
- และ
- คำตอบ
- ใด
- API
- เห็นได้ชัด
- การใช้งาน
- เฉพาะแอปพลิเคชัน
- การใช้งาน
- ประมาณ
- สถาปัตยกรรม
- เป็น
- จัด
- แถว
- บทความ
- บทความ
- เทียม
- ปัญญาประดิษฐ์
- ปัญญาประดิษฐ์และการเรียนรู้ด้วยเครื่อง
- AS
- ด้าน
- ประเมิน
- สมาคม
- At
- เสียง
- อัตโนมัติ
- ใช้ได้
- ตาม
- BE
- กลายเป็น
- จะกลายเป็น
- พฤติกรรม
- หลัง
- กำลัง
- ด้านล่าง
- ประโยชน์ที่ได้รับ
- ดีกว่า
- ระหว่าง
- บล็อกกาธอน
- นำมาซึ่ง
- สร้าง
- การก่อสร้าง
- ธุรกิจ
- ปุ่ม
- by
- คำนวณ
- การคำนวณ
- ที่เรียกว่า
- CAN
- ความสามารถในการ
- ความสามารถ
- จับ
- กรณี
- กรณี
- หมวดหมู่
- โซ่
- ห่วงโซ่
- ลักษณะ
- ความชัดเจน
- การจัดหมวดหมู่
- แยกประเภท
- คลิก
- การจัดกลุ่ม
- รหัส
- การเข้ารหัส
- ความรู้ความเข้าใจ
- ชุด
- อย่างธรรมดา
- กะทัดรัด
- เปรียบเทียบ
- การเปรียบเทียบ
- สมบูรณ์
- ซับซ้อน
- ส่วนประกอบ
- ครอบคลุม
- การคำนวณ
- การคำนวณ
- เชื่อมต่อ
- การเชื่อมต่อ
- พิจารณา
- ถือว่า
- บรรจุ
- เนื้อหา
- สิ่งแวดล้อม
- ตามธรรมเนียม
- การสนทนา
- แปลง
- สอดคล้อง
- ได้
- สร้าง
- การสร้าง
- ความคิดสร้างสรรค์
- ลูกค้า
- ข้อมูล
- การวิเคราะห์ข้อมูล
- จุดข้อมูล
- การประมวลผล
- ฐานข้อมูล
- ฐานข้อมูล
- ชุดข้อมูล
- จัดการ
- การตัดสินใจ
- การตัดสินใจ
- ความต้องการ
- ได้มา
- การออกแบบ
- ที่ต้องการ
- รายละเอียด
- การตรวจพบ
- พัฒนา
- แตกต่าง
- ความแตกต่าง
- ต่าง
- ดิจิทัล
- Dimension
- มิติ
- โดยตรง
- ทิศทาง
- คำสั่ง
- การค้นพบ
- ดุลพินิจ
- สนทนา
- กล่าวถึง
- แสดง
- ระยะทาง
- do
- เอกสาร
- ทำ
- สวม
- DOT
- พลวัต
- แบบไดนามิก
- e
- แต่ละ
- ความสะดวก
- ง่ายดาย
- มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- ทั้ง
- องค์ประกอบ
- การฝัง
- ทำให้สามารถ
- ปลาย
- ชั้นเยี่ยม
- วิศวกร
- เครื่องยนต์
- ภาษาอังกฤษ
- เพื่อให้แน่ใจ
- สิ่งแวดล้อม
- แก่นแท้
- จำเป็น
- อีเธอร์ (ETH)
- แม้
- การพัฒนา
- ดำเนินการ
- การออกกำลังกาย
- สำรวจ
- สารสกัด
- อำนวยความสะดวก
- ความคุ้นเคย
- ไกล
- ลักษณะ
- คุณสมบัติ
- เฟด
- รูป
- เนื้อไม่มีมัน
- ไฟล์
- หา
- ชื่อจริง
- แบน
- ดังต่อไปนี้
- สำหรับ
- แถวหน้า
- ฟอร์ม
- รูป
- ฟรี
- ราคาเริ่มต้นที่
- อนาคต
- ช่องว่าง
- สร้าง
- รุ่น
- กำเนิด
- กำเนิด AI
- ชนิด
- GitHub
- ให้
- กำหนด
- บัญชีกลุ่ม
- กลุ่ม
- จัดการ
- เกิดขึ้น
- มี
- ช่วย
- จะช่วยให้
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- จุดสูง
- ระดับสูง
- อย่างสูง
- ทางประวัติศาสตร์
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- อย่างไรก็ตาม
- HTTPS
- ใหญ่
- ร้อย
- i
- ID
- แยกแยะ
- if
- ภาพ
- ส่งผลกระทบ
- การดำเนินงาน
- นำเข้า
- ปรับปรุง
- in
- ขึ้น
- ดัชนี
- การจัดทำดัชนี
- ดัชนี
- การแสดง
- ดัชนี
- อุตสาหกรรม
- อุตสาหกรรม
- มีอิทธิพล
- ข้อมูล
- โดยธรรมชาติ
- นวัตกรรม
- อินพุต
- ปัจจัยการผลิต
- แทรก
- ภายใน
- ข้อมูลเชิงลึก
- ตัวอย่าง
- แทน
- Intelligence
- โต้ตอบ
- ปฏิสัมพันธ์
- ปฏิสัมพันธ์
- เข้าไป
- ความซับซ้อน
- ที่เกี่ยวข้องกับการ
- IT
- ITS
- งาน
- ร่วม
- เข้าร่วมกับเรา
- การเดินทาง
- เพียงแค่
- คีย์
- กุญแจ
- คำหลัก
- เด็ก
- ทราบ
- ฉลาก
- ที่ดิน
- ภูมิประเทศ
- ใหญ่
- ชั้นนำ
- นำไปสู่
- การเรียนรู้
- เลฟเวอเรจ
- ยกระดับ
- กดไลก์
- รายการ
- loader
- ตรรกะ
- เข้าสู่ระบบ
- เครื่อง
- เรียนรู้เครื่อง
- สำคัญ
- ทำ
- ทำให้
- การทำ
- การจัดการ
- ลักษณะ
- ด้วยมือ
- ผู้ผลิต
- แผนที่
- มาก
- ที่ตรงกัน
- คณิตศาสตร์
- มีความหมาย
- วัด
- มาตรการ
- การวัด
- กลไก
- ภาพบรรยากาศ
- ผสาน
- ระเบียบวิธี
- วิธีการ
- ไมโครซอฟท์
- ต่ำสุด
- แบบ
- โมเดล
- ข้อมูลเพิ่มเติม
- ยิ่งไปกว่านั้น
- มากที่สุด
- มาก
- หลาย
- ต้อง
- ชื่อ
- ธรรมชาติ
- จำเป็นต้อง
- ใหม่
- ตอนนี้
- มากมาย
- วัตถุ
- วัตถุ
- of
- เสนอ
- on
- ONE
- คน
- ออนไลน์
- เพียง
- เปิด
- OpenAI
- การดำเนินการ
- ตรงข้าม
- or
- องค์กร
- Organized
- จัดงาน
- เป็นต้นฉบับ
- OS
- อื่นๆ
- ของเรา
- เป็นเจ้าของ
- หน้า
- คู่
- ส่วนหนึ่ง
- ผ่าน
- ที่ผ่านไป
- รูปแบบ
- สมบูรณ์
- ดำเนินการ
- การปฏิบัติ
- ดำเนินการ
- ดำเนินการ
- มุมมอง
- มุมมอง
- ภาพ
- เป็นจุดสำคัญ
- ที่ราบ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- กรุณา
- จุด
- จุด
- เป็นไปได้
- ที่มีศักยภาพ
- อำนาจ
- ที่มีประสิทธิภาพ
- ประยุกต์
- การใช้งานจริง
- จำเป็นต้อง
- อย่างแม่นยำ
- การตั้งค่า
- ก่อน
- ปัญหา
- กระบวนการ
- ผลิตภัณฑ์
- ผลิตภัณฑ์
- โครงการ
- โดดเด่น
- แจ้ง
- อย่างถูกต้อง
- คุณสมบัติ
- คุณสมบัติ
- ให้
- การให้
- บทบัญญัติ
- การตีพิมพ์
- พัฟฟ์
- วัตถุประสงค์
- วัตถุประสงค์
- ปริมาณ
- คำสั่ง
- คำถาม
- รวดเร็ว
- ได้เร็วขึ้น
- อย่างรวดเร็ว
- อย่างรวดเร็ว
- แนะนำ
- แนะนำ
- เกี่ยวกับ
- ภูมิภาค
- ความสัมพันธ์
- ความสัมพันธ์
- ตรงประเด็น
- การแสดง
- เป็นตัวแทนของ
- แสดงให้เห็นถึง
- จำเป็นต้องใช้
- ความต้องการ
- คำตอบ
- การตอบสนอง
- ผล
- ผลสอบ
- เปิดเผย
- บทบาท
- แถว
- s
- เดียวกัน
- วิทยาศาสตร์
- ขอบเขต
- ค้นหา
- เครื่องมือค้นหา
- ค้นหา
- ค้นหา
- ความรู้สึก
- SEO
- การตั้งค่า
- รูปร่าง
- การสร้าง
- ที่ใช้ร่วมกัน
- หิ้ง
- สั้น
- แสดง
- แสดงให้เห็นว่า
- ด้าน
- คล้ายคลึงกัน
- ความคล้ายคลึงกัน
- ง่าย
- ตั้งแต่
- เดียว
- ขนาด
- So
- ทางออก
- โซลูชัน
- บาง
- แหล่ง
- ช่องว่าง
- โดยเฉพาะ
- ความเร็ว
- แยก
- การทำให้เป็นจุด
- SQL
- สถานะ
- คำแถลง
- งบ
- ขั้นตอน
- ยังคง
- การเก็บรักษา
- จัดเก็บ
- เก็บไว้
- ร้านค้า
- โครงสร้าง
- โครงสร้าง
- ศึกษา
- ต่อจากนั้น
- ที่ประสบความสำเร็จ
- ทำงานร่วมกัน
- ระบบ
- ระบบ
- T
- ตาราง
- TAG
- งาน
- เทคนิค
- เทคโนโลยี
- เงื่อนไขการใช้บริการ
- ข้อความ
- การสร้างข้อความ
- กว่า
- ที่
- พื้นที่
- ก้าวสู่อนาคต
- ของพวกเขา
- พวกเขา
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- สาม
- ตลอด
- เวลา
- ครั้ง
- ไปยัง
- แบบดั้งเดิม
- รถไฟ
- แปลง
- การแปลง
- กระแส
- เปลี่ยน
- ลอง
- สอง
- ชนิด
- ในที่สุด
- เข้าใจ
- ความเข้าใจ
- ไม่ต้องสงสัย
- ปลดล็อก
- ปลดล็อค
- บันทึก
- อัพเกรด
- us
- การใช้
- ใช้
- มือสอง
- ผู้ใช้งาน
- ใช้
- การใช้
- ตามปกติ
- ความคุ้มค่า
- ความหลากหลาย
- ต่างๆ
- มาก
- จำเป็น
- vs
- คือ
- we
- webp
- กำหนดไว้อย่างดี
- คือ
- อะไร
- ความหมายของ
- ว่า
- ที่
- ในขณะที่
- จะ
- กับ
- ภายใน
- คำ
- งาน
- การทำงาน
- จะ
- เธอ
- ของคุณ
- ลมทะเล