ภาพโดยผู้เขียน
การดำน้ำลึกเข้าไปในโลกแห่งวิทยาศาสตร์ข้อมูลและการเรียนรู้ของเครื่อง หนึ่งในทักษะพื้นฐานที่คุณจะพบคือศิลปะของการอ่านข้อมูล หากคุณมีประสบการณ์มาบ้างแล้ว คุณอาจคุ้นเคยกับ JSON (JavaScript Object Notation) ซึ่งเป็นรูปแบบยอดนิยมสำหรับจัดเก็บและแลกเปลี่ยนข้อมูล
ลองนึกถึงวิธีที่ฐานข้อมูล NoSQL เช่น MongoDB ชอบจัดเก็บข้อมูลใน JSON หรือวิธีที่ REST API มักจะตอบสนองในรูปแบบเดียวกัน
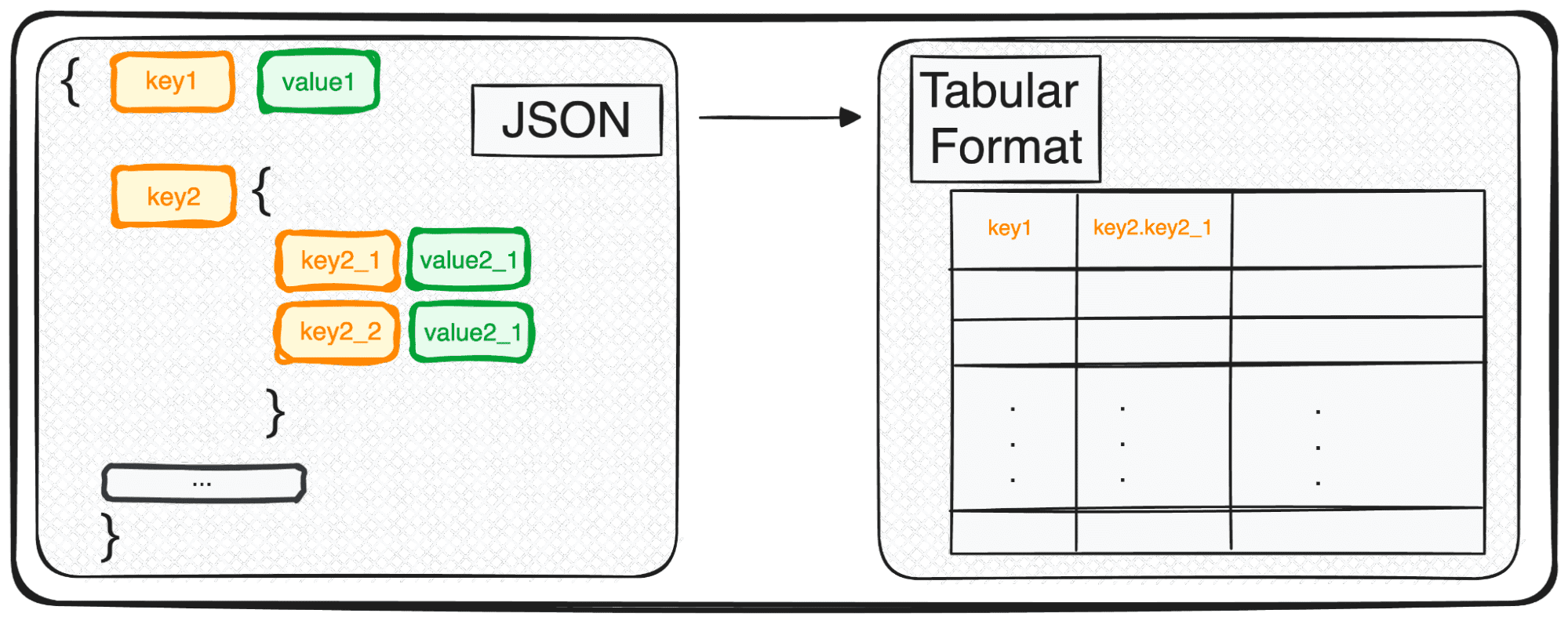
อย่างไรก็ตาม JSON แม้จะสมบูรณ์แบบสำหรับการจัดเก็บและการแลกเปลี่ยน แต่ก็ยังไม่พร้อมสำหรับการวิเคราะห์เชิงลึกในรูปแบบดิบ นี่คือจุดที่เราแปลงให้เป็นสิ่งที่เป็นมิตรกับการวิเคราะห์มากขึ้น นั่นคือรูปแบบตาราง
ดังนั้นไม่ว่าคุณจะจัดการกับออบเจ็กต์ JSON เดียวหรืออาร์เรย์ที่สวยงาม ในแง่ของ Python คุณจะต้องจัดการ dict หรือรายการ dicts เป็นหลัก
มาสำรวจด้วยกันว่าการเปลี่ยนแปลงนี้เกิดขึ้นได้อย่างไร ทำให้ข้อมูลของเราสุกงอมสำหรับการวิเคราะห์ ????
วันนี้ผมจะอธิบายคำสั่งมหัศจรรย์ที่ช่วยให้เราสามารถแยกวิเคราะห์ JSON เป็นรูปแบบตารางได้อย่างง่ายดายภายในไม่กี่วินาที
และมันคือ… pd.json_normalize()
มาดูกันว่ามันทำงานอย่างไรกับ JSON ประเภทต่างๆ
JSON ประเภทแรกที่เราสามารถใช้ได้คือ JSON ระดับเดียวที่มีคีย์และค่าไม่กี่คีย์ เรากำหนด JSON แบบง่ายตัวแรกของเราดังนี้:
รหัสโดยผู้เขียน
เรามาจำลองความจำเป็นในการทำงานกับ JSON เหล่านี้กันดีกว่า เราทุกคนรู้ดีว่าไม่มีอะไรให้ทำมากนักในรูปแบบ JSON เราจำเป็นต้องแปลง JSON เหล่านี้ให้เป็นรูปแบบที่สามารถอ่านและแก้ไขได้... ซึ่งหมายถึง Pandas DataFrames!
1.1 การจัดการกับโครงสร้าง JSON อย่างง่าย
อันดับแรก เราต้องนำเข้าไลบรารีของ pandas จากนั้นจึงใช้คำสั่ง pd.json_normalize() ได้ดังนี้:
import pandas as pd
pd.json_normalize(json_string)
เมื่อใช้คำสั่งนี้กับ JSON ด้วยระเบียนเดียว เราจะได้ตารางพื้นฐานที่สุด อย่างไรก็ตาม เมื่อข้อมูลของเราซับซ้อนขึ้นเล็กน้อยและแสดงรายการ JSON เรายังคงสามารถใช้คำสั่งเดียวกันได้โดยไม่มีความยุ่งยากเพิ่มเติม และผลลัพธ์จะสอดคล้องกับตารางที่มีหลายบันทึก

ภาพโดยผู้เขียน
ง่าย…ใช่มั้ย?
คำถามทั่วไปถัดไปคือจะเกิดอะไรขึ้นเมื่อค่าบางค่าหายไป
1.2 การจัดการกับค่าว่าง
ลองนึกภาพค่าบางค่าไม่ได้รับการแจ้ง เช่น บันทึกรายได้ของ David หายไป เมื่อแปลง JSON ของเราให้เป็น dataframe แพนด้าธรรมดา ค่าที่เกี่ยวข้องจะปรากฏเป็น NaN
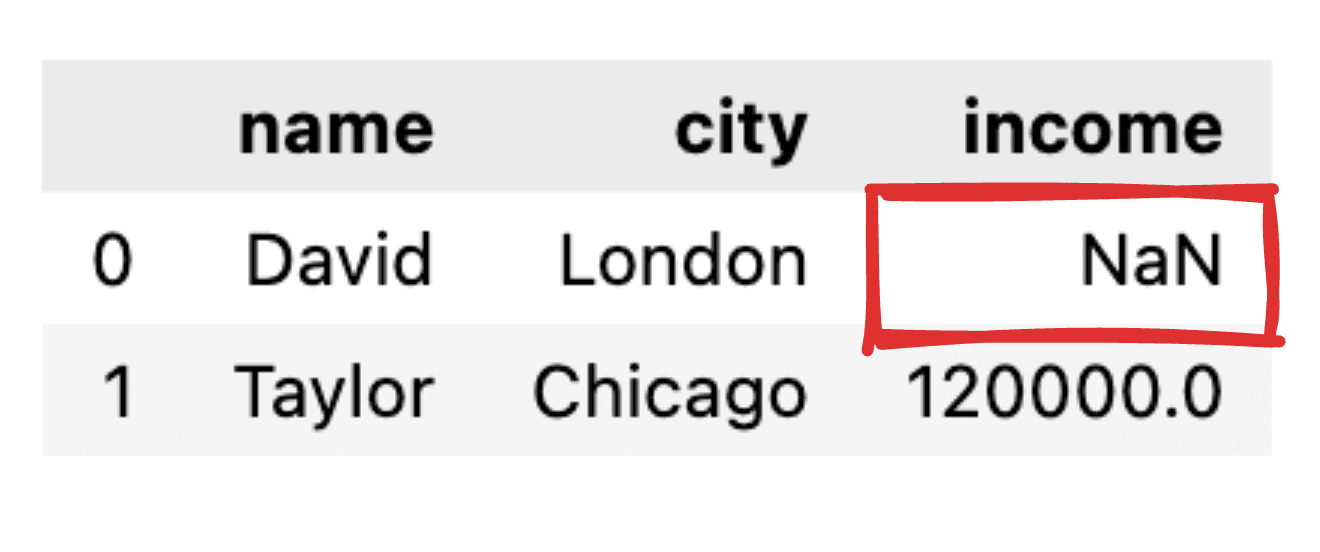
ภาพโดยผู้เขียน
แล้วถ้าฉันอยากได้แค่บางสาขาล่ะ?
1.3 เลือกเฉพาะคอลัมน์ที่สนใจ
ในกรณีที่เราเพียงต้องการแปลงบางฟิลด์เฉพาะให้เป็น DataFrame แพนด้าแบบตาราง คำสั่ง json_normalize() จะไม่อนุญาตให้เราเลือกฟิลด์ที่จะแปลง
ดังนั้น ควรดำเนินการประมวลผลล่วงหน้าเล็กน้อยของ JSON โดยที่เรากรองเฉพาะคอลัมน์ที่สนใจเหล่านั้น
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
มาดูโครงสร้าง JSON ขั้นสูงกัน
เมื่อต้องจัดการกับ JSON หลายระดับ เราพบว่าตัวเองมี JSON ที่ซ้อนกันภายในระดับที่ต่างกัน ขั้นตอนจะเหมือนเดิม แต่ในกรณีนี้ เราสามารถเลือกได้ว่าต้องการแปลงกี่ระดับก็ได้ ตามค่าเริ่มต้น คำสั่งจะขยายทุกระดับและสร้างคอลัมน์ใหม่ที่มีชื่อที่ต่อกันของระดับที่ซ้อนกันทั้งหมด
ดังนั้นหากเราทำให้ JSON ต่อไปนี้เป็นมาตรฐาน
รหัสโดยผู้เขียน
เราจะได้ตารางต่อไปนี้ซึ่งมี 3 คอลัมน์ภายใต้ทักษะภาคสนาม:
- ทักษะหลาม
- ทักษะ.SQL
- ทักษะ.GCP
และ 4 คอลัมน์ใต้บทบาทภาคสนาม
- บทบาทผู้จัดการโครงการ
- บทบาทวิศวกรข้อมูล
- บทบาทนักวิทยาศาสตร์ข้อมูล
- นักวิเคราะห์ Role.data

ภาพโดยผู้เขียน
อย่างไรก็ตาม ลองจินตนาการว่าเราเพียงต้องการเปลี่ยนแปลงระดับบนสุดของเรา เราสามารถทำได้โดยการกำหนดพารามิเตอร์ max_level เป็น 0 โดยเฉพาะ (max_level ที่เราต้องการขยาย)
pd.json_normalize(mutliple_level_json_list, max_level = 0)
ค่าที่รอดำเนินการจะถูกรักษาไว้ภายใน JSON ภายใน DataFrame แพนด้าของเรา
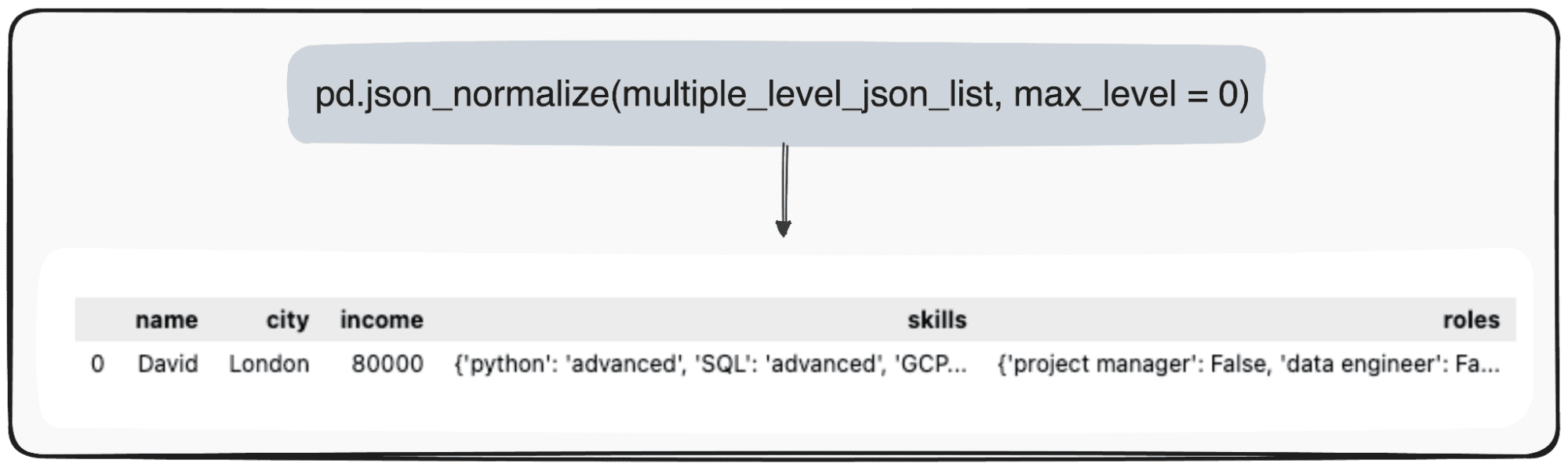
ภาพโดยผู้เขียน
กรณีสุดท้ายที่เราพบคือการมีรายการที่ซ้อนกันภายในเขตข้อมูล JSON ดังนั้นเราจึงกำหนด JSON ของเราที่จะใช้ก่อน
รหัสโดยผู้เขียน
เราสามารถจัดการข้อมูลนี้ได้อย่างมีประสิทธิภาพโดยใช้ Pandas ใน Python ฟังก์ชัน pd.json_normalize() มีประโยชน์อย่างยิ่งในบริบทนี้ โดยสามารถแบ่งข้อมูล JSON รวมถึงรายการที่ซ้อนกัน ให้อยู่ในรูปแบบที่มีโครงสร้างที่เหมาะสมสำหรับการวิเคราะห์ เมื่อนำฟังก์ชันนี้ไปใช้กับข้อมูล JSON ของเรา จะสร้างตารางมาตรฐานที่รวมรายการที่ซ้อนกันไว้เป็นส่วนหนึ่งของช่อง
นอกจากนี้ Pandas ยังมีความสามารถในการปรับแต่งกระบวนการนี้เพิ่มเติมอีกด้วย ด้วยการใช้พารามิเตอร์ record_path ใน pd.json_normalize() เราจึงสามารถกำหนดให้ฟังก์ชันเพื่อทำให้รายการที่ซ้อนกันเป็นมาตรฐานโดยเฉพาะ
การดำเนินการนี้ส่งผลให้มีตารางเฉพาะสำหรับเนื้อหาของรายการเท่านั้น ตามค่าเริ่มต้น กระบวนการนี้จะแสดงเฉพาะองค์ประกอบภายในรายการเท่านั้น อย่างไรก็ตาม เพื่อเพิ่มคุณค่าให้กับตารางนี้ด้วยบริบทเพิ่มเติม เช่น การเก็บรักษา ID ที่เกี่ยวข้องสำหรับแต่ละเรกคอร์ด เราสามารถใช้พารามิเตอร์เมตาได้

ภาพโดยผู้เขียน
โดยสรุป การแปลงข้อมูล JSON เป็นไฟล์ CSV โดยใช้ไลบรารี Pandas ของ Python นั้นง่ายและมีประสิทธิภาพ
JSON ยังคงเป็นรูปแบบที่ใช้กันทั่วไปในพื้นที่จัดเก็บและการแลกเปลี่ยนข้อมูลสมัยใหม่ โดยเฉพาะในฐานข้อมูล NoSQL และ REST API อย่างไรก็ตาม ทำให้เกิดความท้าทายในการวิเคราะห์ที่สำคัญเมื่อต้องรับมือกับข้อมูลในรูปแบบดิบ
บทบาทสำคัญของ pd.json_normalize() ของ Pandas กลายเป็นวิธีที่ดีเยี่ยมในการจัดการรูปแบบดังกล่าวและแปลงข้อมูลของเราให้เป็น DataFrame ของ pandas
ฉันหวังว่าคู่มือนี้จะเป็นประโยชน์ และครั้งต่อไปที่คุณกำลังจัดการกับ JSON คุณสามารถทำได้อย่างมีประสิทธิผลมากขึ้น
คุณสามารถตรวจสอบ Jupyter Notebook ที่เกี่ยวข้องได้ใน ติดตาม repo GitHub
โจเซป เฟอร์เรอร์ เป็นวิศวกรวิเคราะห์จากบาร์เซโลนา เขาสำเร็จการศึกษาด้านวิศวกรรมฟิสิกส์และกำลังทำงานในสาขาวิทยาศาสตร์ข้อมูลที่ประยุกต์ใช้กับการเคลื่อนที่ของมนุษย์ เขาเป็นผู้สร้างเนื้อหานอกเวลาที่มุ่งเน้นด้านวิทยาศาสตร์ข้อมูลและเทคโนโลยี สามารถติดต่อเขาได้ที่ LinkedIn, Twitter or กลาง.
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :เป็น
- :ไม่
- :ที่ไหน
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- เกี่ยวกับเรา
- การกระทำ
- เพิ่มเติม
- สูง
- ทั้งหมด
- อนุญาต
- ช่วยให้
- แล้ว
- เสมอ
- an
- การวิเคราะห์
- นักวิเคราะห์
- วิเคราะห์
- การวิเคราะห์
- และ
- ใด
- APIs
- ปรากฏ
- ประยุกต์
- การประยุกต์ใช้
- เป็น
- แถว
- ศิลปะ
- AS
- ที่เกี่ยวข้อง
- บาร์เซโลนา
- ขั้นพื้นฐาน
- BE
- ก่อน
- บิต
- ทั้งสอง
- แต่
- by
- CAN
- ความสามารถ
- กรณี
- ความท้าทาย
- ตรวจสอบ
- Choose
- เมือง
- คอลัมน์
- ร่วมกัน
- ซับซ้อน
- ภาวะแทรกซ้อน
- ติดต่อเรา
- เนื้อหา
- เนื้อหา
- สิ่งแวดล้อม
- แปลง
- การแปลง
- ตรงกัน
- ตรงกัน
- ผู้สร้าง
- ขณะนี้
- ข้อมูล
- นักวิเคราะห์ข้อมูล
- วิศวกรข้อมูล
- วิทยาศาสตร์ข้อมูล
- นักวิทยาศาสตร์ข้อมูล
- การจัดเก็บข้อมูล
- ฐานข้อมูล
- เดวิด
- การซื้อขาย
- ทุ่มเท
- ค่าเริ่มต้น
- กำหนด
- การกำหนด
- น่ารื่นรมย์
- Dict
- ต่าง
- โดยตรง
- do
- ทำ
- แต่ละ
- อย่างง่ายดาย
- ง่าย
- มีประสิทธิภาพ
- มีประสิทธิภาพ
- องค์ประกอบ
- โผล่ออกมา
- พบ
- วิศวกร
- ชั้นเยี่ยม
- ประเทือง
- เป็นหลัก
- ตลาดแลกเปลี่ยน
- การแลกเปลี่ยน
- โดยเฉพาะ
- แสดง
- ประสบการณ์
- อธิบาย
- สำรวจ
- คุ้นเคย
- สองสาม
- สนาม
- สาขา
- ไฟล์
- กรอง
- หา
- ชื่อจริง
- มุ่งเน้น
- ดังต่อไปนี้
- ดังต่อไปนี้
- สำหรับ
- ฟอร์ม
- รูป
- เป็นมิตร
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- พื้นฐาน
- ต่อไป
- GCP
- สร้าง
- ได้รับ
- GitHub
- Go
- ยิ่งใหญ่
- ให้คำแนะนำ
- จัดการ
- การจัดการ
- ที่เกิดขึ้น
- มี
- มี
- he
- พระองค์
- ความหวัง
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- อย่างไรก็ตาม
- HTTPS
- เป็นมนุษย์
- i
- ฉันเป็น
- ID
- if
- ภาพ
- นำเข้า
- สำคัญ
- in
- ลึกซึ้ง
- ประกอบด้วย
- รวมทั้ง
- เงินได้
- รวม
- แจ้ง
- ตัวอย่าง
- อยากเรียนรู้
- เข้าไป
- ISN
- IT
- ITS
- JavaScript
- JSON
- โน้ตบุ๊ค Jupyter
- เพียงแค่
- KD นักเก็ต
- คีย์
- กุญแจ
- ทราบ
- ชื่อสกุล
- การเรียนรู้
- ชั้น
- ระดับ
- ห้องสมุด
- กดไลก์
- รายการ
- น้อย
- ll
- ความรัก
- เครื่อง
- เรียนรู้เครื่อง
- มายากล
- การบำรุงรักษา
- การทำ
- จัดการ
- ผู้จัดการ
- หลาย
- วิธี
- Meta
- หายไป
- การเคลื่อนย้าย
- ทันสมัย
- MongoDB
- ข้อมูลเพิ่มเติม
- มากที่สุด
- ย้าย
- มาก
- หลาย
- ชื่อ
- โดยธรรมชาติ
- จำเป็นต้อง
- ที่ซ้อนกัน
- ใหม่
- ถัดไป
- ไม่
- ยวด
- สมุดบันทึก
- วัตถุ
- ได้รับ
- of
- เสนอ
- มักจะ
- on
- ONE
- เพียง
- or
- ของเรา
- ตัวเรา
- เอาท์พุต
- หมีแพนด้า
- พารามิเตอร์
- ส่วนหนึ่ง
- โดยเฉพาะ
- คาราคาซัง
- สมบูรณ์
- ดำเนินการ
- ฟิสิกส์
- เป็นจุดสำคัญ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- ยอดนิยม
- นำเสนอ
- อาจ
- ขั้นตอนการ
- กระบวนการ
- ผลิต
- โครงการ
- หลาม
- คำถาม
- ทีเดียว
- ดิบ
- RE
- การอ่าน
- พร้อม
- ระเบียน
- บันทึก
- ปรับแต่ง
- ตอบสนอง
- REST
- ผลสอบ
- การรักษา
- ขวา
- บทบาท
- s
- เดียวกัน
- วิทยาศาสตร์
- วิทยาศาสตร์และเทคโนโลยี
- นักวิทยาศาสตร์
- วินาที
- เห็น
- การเลือก
- น่า
- ง่าย
- แกล้งทำ
- เดียว
- ทักษะ
- เล็ก
- So
- บาง
- บางสิ่งบางอย่าง
- โดยเฉพาะ
- เฉพาะ
- SQL
- ยังคง
- การเก็บรักษา
- จัดเก็บ
- โครงสร้าง
- โครงสร้าง
- อย่างเช่น
- เหมาะสม
- สรุป
- T
- ตาราง
- เทคโนโลยี
- เงื่อนไขการใช้บริการ
- ที่
- พื้นที่
- โลก
- ของพวกเขา
- พวกเขา
- แล้วก็
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- นี้
- เหล่านั้น
- เวลา
- ไปยัง
- ร่วมกัน
- ด้านบน
- แปลง
- การแปลง
- การเปลี่ยนแปลง
- ชนิด
- ชนิด
- ภายใต้
- us
- ใช้
- มีประโยชน์
- การใช้
- การใช้ประโยชน์
- ความคุ้มค่า
- ความคุ้มค่า
- ต้องการ
- คือ
- ทาง..
- we
- อะไร
- เมื่อ
- ว่า
- ที่
- ในขณะที่
- จะ
- กับ
- ภายใน
- งาน
- การทำงาน
- โรงงาน
- โลก
- จะ
- เธอ
- ลมทะเล