โพสต์นี้เขียนร่วมกับ Pramod Nayak, LakshmiKanth Mannem และ Vivek Aggarwal จาก Low Latency Group ของ LSEG
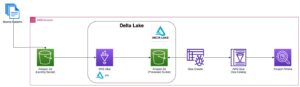
การวิเคราะห์ต้นทุนธุรกรรม (TCA) ใช้กันอย่างแพร่หลายโดยเทรดเดอร์ ผู้จัดการพอร์ตโฟลิโอ และโบรกเกอร์สำหรับการวิเคราะห์ก่อนการซื้อขายและหลังการซื้อขาย และช่วยให้พวกเขาวัดและเพิ่มประสิทธิภาพต้นทุนการทำธุรกรรมและประสิทธิผลของกลยุทธ์การซื้อขายของพวกเขา ในโพสต์นี้ เราจะวิเคราะห์ตัวเลือก bid-ask สเปรดจาก ประวัติเห็บ LSEG – PCAP ชุดข้อมูลที่ใช้ Amazon Athena สำหรับ Apache Spark. เราแสดงวิธีการเข้าถึงข้อมูล กำหนดฟังก์ชันแบบกำหนดเองเพื่อใช้กับข้อมูล สืบค้นและกรองชุดข้อมูล และแสดงภาพผลลัพธ์ของการวิเคราะห์ ทั้งหมดนี้โดยไม่ต้องกังวลกับการตั้งค่าโครงสร้างพื้นฐานหรือกำหนดค่า Spark แม้แต่ชุดข้อมูลขนาดใหญ่ก็ตาม
พื้นหลัง
Options Price Reporting Authority (OPRA) ทำหน้าที่เป็นผู้ประมวลผลข้อมูลหลักทรัพย์ที่สำคัญ รวบรวม รวบรวม และเผยแพร่รายงานการขายล่าสุด ราคา และข้อมูลที่เกี่ยวข้องสำหรับ US Options ด้วยการแลกเปลี่ยนออปชั่นของสหรัฐฯ 18 แห่งและสัญญาที่เข้าเกณฑ์มากกว่า 1.5 ล้านสัญญา OPRA มีบทบาทสำคัญในการให้ข้อมูลตลาดที่ครอบคลุม
ในวันที่ 5 กุมภาพันธ์ 2024 บริษัท Securities Industry Automation Corporation (SIAC) ได้รับการตั้งค่าให้อัปเกรดฟีด OPRA จาก 48 ช่องเป็น 96 ช่องมัลติคาสต์ การปรับปรุงนี้มีจุดมุ่งหมายเพื่อเพิ่มประสิทธิภาพการกระจายสัญลักษณ์และการใช้กำลังการผลิตเพื่อตอบสนองต่อกิจกรรมการซื้อขายที่เพิ่มขึ้นและความผันผวนในตลาดออปชั่นของสหรัฐฯ SIAC แนะนำให้บริษัทต่างๆ เตรียมความพร้อมสำหรับอัตราข้อมูลสูงสุดที่ 37.3 GBits ต่อวินาที
แม้ว่าการอัปเกรดจะไม่เปลี่ยนแปลงปริมาณรวมของข้อมูลที่เผยแพร่ในทันที แต่ก็ทำให้ OPRA สามารถเผยแพร่ข้อมูลในอัตราที่เร็วขึ้นอย่างมาก การเปลี่ยนแปลงนี้มีความสำคัญอย่างยิ่งต่อการตอบสนองความต้องการของตลาดออปชั่นแบบไดนามิก
OPRA โดดเด่นในฐานะฟีดที่มีปริมาณมากที่สุดรายการหนึ่ง โดยมียอดข้อความสูงสุด 150.4 พันล้านข้อความในวันเดียวในไตรมาสที่ 3 ปี 2023 และความต้องการความจุที่เหลือที่ 400 พันล้านข้อความภายในวันเดียว การบันทึกทุกข้อความเป็นสิ่งสำคัญสำหรับการวิเคราะห์ต้นทุนธุรกรรม การตรวจสอบสภาพคล่องของตลาด การประเมินกลยุทธ์การซื้อขาย และการวิจัยตลาด
เกี่ยวกับข้อมูล
ประวัติเห็บ LSEG – PCAP เป็นพื้นที่เก็บข้อมูลบนคลาวด์ที่มีขนาดเกิน 30 PB ซึ่งเป็นที่เก็บข้อมูลตลาดระดับโลกคุณภาพสูงเป็นพิเศษ ข้อมูลนี้จะถูกบันทึกอย่างพิถีพิถันโดยตรงภายในศูนย์ข้อมูลการแลกเปลี่ยน โดยใช้กระบวนการบันทึกข้อมูลซ้ำซ้อนซึ่งมีการวางตำแหน่งเชิงกลยุทธ์ในศูนย์ข้อมูลแลกเปลี่ยนหลักและสำรองที่สำคัญทั่วโลก เทคโนโลยีการจับภาพของ LSEG ช่วยให้มั่นใจในการเก็บข้อมูลโดยไม่สูญเสียข้อมูล และใช้แหล่งเวลา GPS เพื่อความแม่นยำในการประทับเวลาระดับนาโนวินาที นอกจากนี้ ยังมีการใช้เทคนิคการเก็งกำไรข้อมูลที่ซับซ้อนเพื่อเติมเต็มช่องว่างของข้อมูลอย่างราบรื่น ภายหลังการจับภาพ ข้อมูลจะผ่านการประมวลผลและการอนุญาโตตุลาการอย่างพิถีพิถัน จากนั้นจึงทำให้เป็นมาตรฐานในรูปแบบไม้ปาร์เก้โดยใช้ Ultra Direct แบบเรียลไทม์ของ LSEG (RTUD) ตัวจัดการฟีด
กระบวนการทำให้เป็นมาตรฐานซึ่งเป็นส่วนสำคัญในการเตรียมข้อมูลสำหรับการวิเคราะห์ จะสร้างไฟล์ Parquet ที่ถูกบีบอัดได้มากถึง 6 TB ต่อวัน ข้อมูลจำนวนมหาศาลเป็นผลมาจากลักษณะที่ครอบคลุมของ OPRA ซึ่งครอบคลุมการแลกเปลี่ยนหลายครั้ง และมีสัญญาออปชั่นมากมายที่มีลักษณะเฉพาะที่หลากหลาย ความผันผวนของตลาดที่เพิ่มขึ้นและกิจกรรมการสร้างตลาดในการแลกเปลี่ยนออปชันยังส่งผลต่อปริมาณข้อมูลที่เผยแพร่บน OPRA อีกด้วย
คุณลักษณะของ Tick History – PCAP ช่วยให้บริษัทสามารถทำการวิเคราะห์ต่างๆ ได้ รวมถึงสิ่งต่อไปนี้:
- การวิเคราะห์ก่อนการซื้อขาย – ประเมินผลกระทบทางการค้าที่อาจเกิดขึ้นและสำรวจกลยุทธ์การดำเนินการที่แตกต่างกันตามข้อมูลในอดีต
- การประเมินหลังการซื้อขาย – วัดต้นทุนการดำเนินการตามจริงเทียบกับเกณฑ์มาตรฐานเพื่อประเมินประสิทธิภาพของกลยุทธ์การดำเนินการ
- ปลดข้อจำกัด การปฏิบัติ – ปรับแต่งกลยุทธ์การดำเนินการตามรูปแบบตลาดในอดีตเพื่อลดผลกระทบของตลาดและลดต้นทุนการซื้อขายโดยรวม
- การบริหารความเสี่ยง – ระบุรูปแบบการเลื่อนไหล ระบุค่าผิดปกติ และจัดการความเสี่ยงที่เกี่ยวข้องกับกิจกรรมการซื้อขายในเชิงรุก
- การระบุแหล่งที่มาของประสิทธิภาพ – แยกผลกระทบของการตัดสินใจซื้อขายออกจากการตัดสินใจลงทุนเมื่อวิเคราะห์ประสิทธิภาพของพอร์ตโฟลิโอ
ชุดข้อมูล LSEG Tick History – PCAP มีอยู่ใน การแลกเปลี่ยนข้อมูล AWS และสามารถเข้าถึงได้ที่ AWS Marketplace. ด้วย AWS Data Exchange สำหรับ Amazon S3คุณสามารถเข้าถึงข้อมูล PCAP ได้โดยตรงจาก LSEG บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) ช่วยลดความจำเป็นสำหรับบริษัทต่างๆ ในการจัดเก็บสำเนาข้อมูลของตนเอง แนวทางนี้เพิ่มความคล่องตัวในการจัดการข้อมูลและการจัดเก็บข้อมูล ช่วยให้ลูกค้าเข้าถึง PCAP คุณภาพสูงหรือข้อมูลมาตรฐานได้ทันทีโดยใช้งานง่าย บูรณาการ และ ประหยัดพื้นที่จัดเก็บข้อมูลได้อย่างมาก.
เอเธน่าสำหรับ Apache Spark
สำหรับความพยายามในการวิเคราะห์ เอเธน่าสำหรับ Apache Spark มอบประสบการณ์โน้ตบุ๊กที่เรียบง่ายซึ่งสามารถเข้าถึงได้ผ่านคอนโซล Athena หรือ Athena API ซึ่งช่วยให้คุณสร้างแอปพลิเคชัน Apache Spark แบบโต้ตอบได้ ด้วยรันไทม์ Spark ที่ปรับให้เหมาะสม Athena จะช่วยวิเคราะห์ข้อมูลระดับเพตะไบต์โดยการปรับขนาดจำนวนเอ็นจิ้น Spark ที่น้อยกว่าหนึ่งวินาทีแบบไดนามิก ยิ่งไปกว่านั้น ไลบรารี Python ทั่วไป เช่น pandas และ NumPy ได้รับการผสานรวมอย่างลงตัว ซึ่งช่วยให้สามารถสร้างตรรกะแอปพลิเคชันที่ซับซ้อนได้ ความยืดหยุ่นขยายไปถึงการนำเข้าไลบรารีแบบกำหนดเองเพื่อใช้ในโน้ตบุ๊ก Athena สำหรับ Spark รองรับรูปแบบข้อมูลเปิดส่วนใหญ่ และผสานรวมเข้ากับรูปแบบได้อย่างราบรื่น AWS กาว แคตตาล็อกข้อมูล
ชุด
สำหรับการวิเคราะห์นี้ เราใช้ชุดข้อมูล LSEG Tick History – PCAP OPRA ตั้งแต่วันที่ 17 พฤษภาคม 2023 ชุดข้อมูลนี้ประกอบด้วยส่วนประกอบต่อไปนี้:
- ราคาเสนอซื้อและข้อเสนอที่ดีที่สุด (BBO) – รายงานราคาเสนอสูงสุดและคำขอต่ำสุดเพื่อความปลอดภัยในการแลกเปลี่ยนที่กำหนด
- การเสนอราคาและข้อเสนอที่ดีที่สุดระดับชาติ (NBBO) – รายงานราคาเสนอสูงสุดและคำขอต่ำสุดเพื่อความปลอดภัยในการแลกเปลี่ยนทั้งหมด
- การซื้อขาย – บันทึกการซื้อขายที่เสร็จสมบูรณ์ในการแลกเปลี่ยนทั้งหมด
ชุดข้อมูลเกี่ยวข้องกับปริมาณข้อมูลต่อไปนี้:
- การซื้อขาย – 160 MB กระจายอยู่ในไฟล์ Parquet ที่ถูกบีบอัดประมาณ 60 ไฟล์
- บีบีโอ – 2.4 TB กระจายอยู่ในไฟล์ Parquet ที่ถูกบีบอัดประมาณ 300 ไฟล์
- สพท – 2.8 TB กระจายอยู่ในไฟล์ Parquet ที่ถูกบีบอัดประมาณ 200 ไฟล์
ภาพรวมการวิเคราะห์
การวิเคราะห์ข้อมูลประวัติ OPRA Tick สำหรับการวิเคราะห์ต้นทุนธุรกรรม (TCA) เกี่ยวข้องกับการพิจารณาราคาตลาดและการซื้อขายตามเหตุการณ์การค้าที่เฉพาะเจาะจงอย่างละเอียด เราใช้ตัวชี้วัดต่อไปนี้เป็นส่วนหนึ่งของการศึกษานี้:
- สเปรดที่เสนอราคา (QS) – คำนวณเป็นความแตกต่างระหว่าง BBO Ask และ BBO Bid
- สเปรดที่มีประสิทธิภาพ (ES) – คำนวณเป็นส่วนต่างระหว่างราคาซื้อขายกับจุดกึ่งกลางของ BBO (BBO bid + (BBO Ask – BBO bid)/2)
- สเปรดที่มีประสิทธิภาพ/เสนอราคา (EQF) – คิดตาม (ES/QS) * 100
เราคำนวณสเปรดเหล่านี้ก่อนการซื้อขายและเพิ่มเติมที่สี่ช่วงเวลาหลังการซื้อขาย (หลังจาก 1 วินาที 10 วินาที และ 60 วินาทีหลังการซื้อขาย)
กำหนดค่า Athena สำหรับ Apache Spark
หากต้องการกำหนดค่า Athena สำหรับ Apache Spark ให้ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล Athena ใต้ สมัครที่นี่ให้เลือก วิเคราะห์ข้อมูลของคุณโดยใช้ PySpark และ Spark SQL.
- หากนี่เป็นครั้งแรกที่คุณใช้ Athena Spark ให้เลือก สร้างเวิร์กกรุ๊ป.

- สำหรับ ชื่อเวิร์กกรุ๊ปธ กรอกชื่อคณะทำงาน เช่น
tca-analysis. - ตัว Vortex Indicator ได้ถูกนำเสนอลงในนิตยสาร เครื่องมือวิเคราะห์ เลือก Apache Spark.
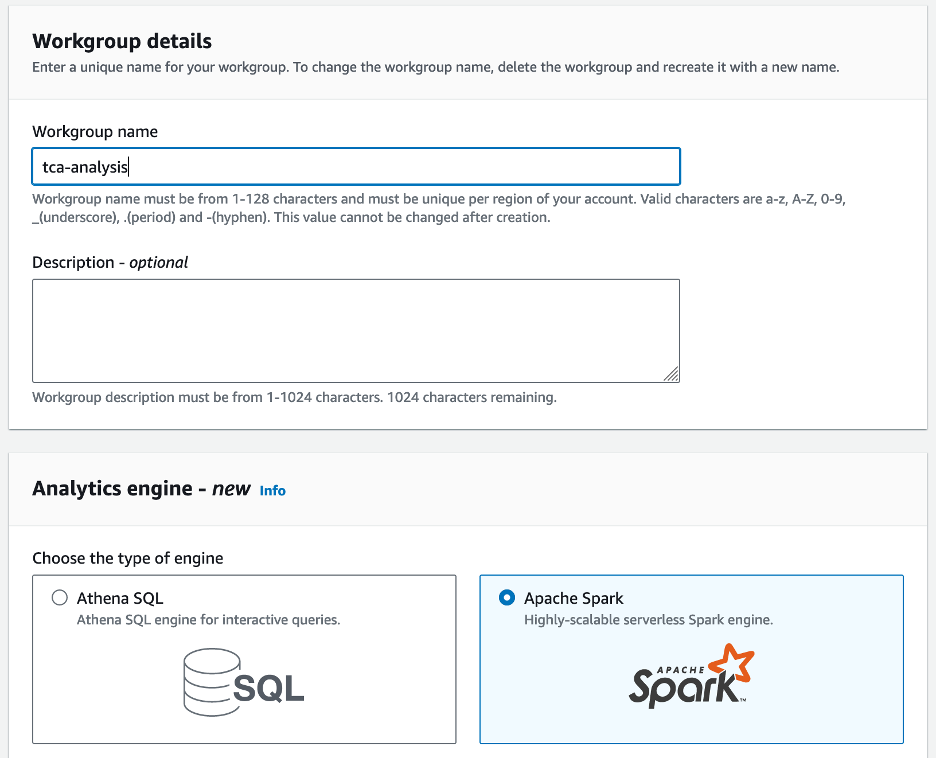
- ตัว Vortex Indicator ได้ถูกนำเสนอลงในนิตยสาร การกำหนดค่าเพิ่มเติม ส่วนคุณสามารถเลือกได้ ใช้ค่าเริ่มต้น หรือให้กำหนดเอง AWS Identity และการจัดการการเข้าถึง บทบาท (IAM) และตำแหน่ง Amazon S3 สำหรับผลการคำนวณ
- Choose สร้างเวิร์กกรุ๊ป.
- หลังจากที่คุณสร้างเวิร์กกรุ๊ปแล้ว ให้ไปที่ โน๊ตบุ๊ค และเลือก สร้างสมุดบันทึก.
- ป้อนชื่อสมุดบันทึกของคุณ เช่น
tca-analysis-with-tick-history. - Choose สร้างบัญชีตัวแทน เพื่อสร้างสมุดบันทึกของคุณ
เปิดสมุดบันทึกของคุณ
หากคุณได้สร้างกลุ่มงาน Spark แล้ว ให้เลือก เปิดตัวแก้ไขสมุดบันทึก ภายใต้ สมัครที่นี่.
![]()
หลังจากที่สมุดบันทึกของคุณถูกสร้างขึ้น คุณจะถูกนำไปยังตัวแก้ไขสมุดบันทึกแบบโต้ตอบ
![]()
ตอนนี้เราสามารถเพิ่มและรันโค้ดต่อไปนี้ลงในสมุดบันทึกของเราได้
สร้างบทวิเคราะห์
ทำตามขั้นตอนต่อไปนี้เพื่อสร้างการวิเคราะห์:
- นำเข้าไลบรารีทั่วไป:
- สร้างกรอบข้อมูลของเราสำหรับ BBO, NBBO และการซื้อขาย:
- ตอนนี้เราสามารถระบุการค้าเพื่อใช้สำหรับการวิเคราะห์ต้นทุนธุรกรรมได้:
เราได้รับผลลัพธ์ต่อไปนี้:
เราใช้ข้อมูลการค้าที่เน้นไว้สำหรับผลิตภัณฑ์การค้า (tp) ราคาซื้อขาย (tpr) และเวลาซื้อขาย (tt)
- ที่นี่เราสร้างฟังก์ชันตัวช่วยจำนวนหนึ่งสำหรับการวิเคราะห์ของเรา
- ในฟังก์ชันต่อไปนี้ เราสร้างชุดข้อมูลที่มีราคาทั้งหมดก่อนและหลังการซื้อขาย Athena Spark จะกำหนดจำนวน DPU ที่จะเรียกใช้เพื่อประมวลผลชุดข้อมูลของเราโดยอัตโนมัติ
- ตอนนี้เรามาเรียกใช้ฟังก์ชันการวิเคราะห์ TCA พร้อมข้อมูลจากการซื้อขายที่เราเลือก:
เห็นภาพผลการวิเคราะห์
ตอนนี้เรามาสร้างกรอบข้อมูลที่เราใช้สำหรับการแสดงภาพของเรากันดีกว่า แต่ละเฟรมข้อมูลมีเครื่องหมายคำพูดสำหรับหนึ่งในห้าช่วงเวลาสำหรับฟีดข้อมูลแต่ละรายการ (BBO, NBBO):
ในส่วนต่อไปนี้ เราจะให้โค้ดตัวอย่างเพื่อสร้างการแสดงภาพที่แตกต่างกัน
พล็อต QS และ NBBO ก่อนการซื้อขาย
ใช้โค้ดต่อไปนี้เพื่อพล็อตสเปรดที่เสนอราคาและ NBBO ก่อนการซื้อขาย:
![]()
วางแผน QS สำหรับแต่ละตลาดและ NBBO หลังการซื้อขาย
ใช้โค้ดต่อไปนี้เพื่อพล็อตค่าสเปรดที่เสนอสำหรับแต่ละตลาดและ NBBO ทันทีหลังการซื้อขาย:
![]()
พล็อต QS สำหรับแต่ละช่วงเวลาและแต่ละตลาดสำหรับ BBO
ใช้โค้ดต่อไปนี้เพื่อพล็อตสเปรดที่เสนอราคาสำหรับแต่ละช่วงเวลาและแต่ละตลาดสำหรับ BBO:
![]()
พล็อต ES สำหรับแต่ละช่วงเวลาและตลาดสำหรับ BBO
ใช้โค้ดต่อไปนี้เพื่อพล็อตค่าสเปรดที่มีประสิทธิภาพสำหรับแต่ละช่วงเวลาและตลาดสำหรับ BBO:
พล็อต EQF สำหรับแต่ละช่วงเวลาและตลาดสำหรับ BBO
ใช้โค้ดต่อไปนี้เพื่อพล็อตสเปรดที่มีประสิทธิผล/เสนอราคาสำหรับแต่ละช่วงเวลาและตลาดสำหรับ BBO:
ประสิทธิภาพการคำนวณ Athena Spark
เมื่อคุณเรียกใช้บล็อกโค้ด Athena Spark จะกำหนดจำนวน DPU ที่ต้องใช้โดยอัตโนมัติในการคำนวณให้เสร็จสิ้น ในบล็อกโค้ดสุดท้ายที่เราเรียกว่า tca_analysis เรากำลังสั่งให้ Spark ประมวลผลข้อมูล จากนั้นเราจะแปลงดาต้าเฟรม Spark ที่ได้ให้เป็นดาต้าเฟรมของ Pandas นี่ถือเป็นส่วนการประมวลผลที่เข้มข้นที่สุดของการวิเคราะห์ และเมื่อ Athena Spark รันบล็อกนี้ ก็จะแสดงแถบความคืบหน้า เวลาที่ผ่านไป และจำนวน DPU ที่กำลังประมวลผลข้อมูลในปัจจุบัน ตัวอย่างเช่น ในการคำนวณต่อไปนี้ Athena Spark ใช้ 18 DPU
![]()
เมื่อคุณกำหนดค่าโน้ตบุ๊ก Athena Spark คุณจะมีตัวเลือกในการตั้งค่าจำนวน DPU สูงสุดที่โน้ตบุ๊กสามารถใช้ได้ ค่าเริ่มต้นคือ 20 DPU แต่เราทดสอบการคำนวณนี้ด้วย 10, 20 และ 40 DPU เพื่อแสดงให้เห็นว่า Athena Spark ปรับขนาดโดยอัตโนมัติเพื่อดำเนินการวิเคราะห์ของเราอย่างไร เราสังเกตว่า Athena Spark ปรับขนาดเป็นเส้นตรง โดยใช้เวลา 15 นาที 21 วินาทีเมื่อโน้ตบุ๊กได้รับการกำหนดค่าด้วย DPU สูงสุด 10 DPU, 8 นาทีและ 23 วินาทีเมื่อโน้ตบุ๊กได้รับการกำหนดค่าด้วย 20 DPU และ 4 นาที 44 วินาทีเมื่อโน้ตบุ๊กถูกกำหนดค่า กำหนดค่าด้วย 40 DPU เนื่องจาก Athena Spark เรียกเก็บเงินตามการใช้งาน DPU ที่รายละเอียดต่อวินาที ค่าใช้จ่ายในการคำนวณเหล่านี้จึงใกล้เคียงกัน แต่หากคุณตั้งค่า DPU สูงสุดที่สูงกว่า Athena Spark ก็สามารถส่งกลับผลลัพธ์ของการวิเคราะห์ได้เร็วกว่ามาก สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับราคา Athena Spark กรุณาคลิก โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม.
สรุป
ในโพสต์นี้ เราได้สาธิตวิธีที่คุณสามารถใช้ข้อมูล OPRA ความเที่ยงตรงสูงจาก Tick History-PCAP ของ LSEG เพื่อทำการวิเคราะห์ต้นทุนธุรกรรมโดยใช้ Athena Spark ความพร้อมใช้งานของข้อมูล OPRA ในเวลาที่เหมาะสม เสริมด้วยนวัตกรรมการเข้าถึงของ AWS Data Exchange สำหรับ Amazon S3 ช่วยลดเวลาในการวิเคราะห์เชิงกลยุทธ์สำหรับบริษัทที่ต้องการสร้างข้อมูลเชิงลึกที่นำไปปฏิบัติได้สำหรับการตัดสินใจซื้อขายที่สำคัญ OPRA สร้างข้อมูล Parquet ที่ทำให้เป็นมาตรฐานประมาณ 7 TB ในแต่ละวัน และการจัดการโครงสร้างพื้นฐานเพื่อให้การวิเคราะห์ตามข้อมูล OPRA ถือเป็นเรื่องท้าทาย
ความสามารถในการปรับขนาดของ Athena ในการจัดการการประมวลผลข้อมูลขนาดใหญ่สำหรับ Tick History – PCAP สำหรับข้อมูล OPRA ทำให้เป็นตัวเลือกที่น่าสนใจสำหรับองค์กรที่กำลังมองหาโซลูชันการวิเคราะห์ที่รวดเร็วและปรับขนาดได้ใน AWS โพสต์นี้แสดงปฏิสัมพันธ์ที่ราบรื่นระหว่างระบบนิเวศ AWS และข้อมูล Tick History-PCAP และวิธีที่สถาบันการเงินสามารถใช้ประโยชน์จากการทำงานร่วมกันนี้เพื่อขับเคลื่อนการตัดสินใจที่ขับเคลื่อนด้วยข้อมูลสำหรับกลยุทธ์การซื้อขายและการลงทุนที่สำคัญ
เกี่ยวกับผู้เขียน
![]() ปราโมทย์ นายัค เป็นผู้อำนวยการฝ่ายการจัดการผลิตภัณฑ์ของกลุ่ม Low Latency ที่ LSEG ปราโมดมีประสบการณ์มากกว่า 10 ปีในอุตสาหกรรมเทคโนโลยีทางการเงิน โดยมุ่งเน้นที่การพัฒนาซอฟต์แวร์ การวิเคราะห์ และการจัดการข้อมูล Pramod เป็นอดีตวิศวกรซอฟต์แวร์และหลงใหลเกี่ยวกับข้อมูลตลาดและการซื้อขายเชิงปริมาณ
ปราโมทย์ นายัค เป็นผู้อำนวยการฝ่ายการจัดการผลิตภัณฑ์ของกลุ่ม Low Latency ที่ LSEG ปราโมดมีประสบการณ์มากกว่า 10 ปีในอุตสาหกรรมเทคโนโลยีทางการเงิน โดยมุ่งเน้นที่การพัฒนาซอฟต์แวร์ การวิเคราะห์ และการจัดการข้อมูล Pramod เป็นอดีตวิศวกรซอฟต์แวร์และหลงใหลเกี่ยวกับข้อมูลตลาดและการซื้อขายเชิงปริมาณ
![]() ลักษมีคานธ์ มันเนม เป็นผู้จัดการผลิตภัณฑ์ในกลุ่ม Low Latency Group ของ LSEG เขามุ่งเน้นไปที่ผลิตภัณฑ์ข้อมูลและแพลตฟอร์มสำหรับอุตสาหกรรมข้อมูลตลาดที่มีความหน่วงต่ำ LakshmiKanth ช่วยให้ลูกค้าสร้างโซลูชันที่เหมาะสมที่สุดสำหรับความต้องการข้อมูลตลาดของตน
ลักษมีคานธ์ มันเนม เป็นผู้จัดการผลิตภัณฑ์ในกลุ่ม Low Latency Group ของ LSEG เขามุ่งเน้นไปที่ผลิตภัณฑ์ข้อมูลและแพลตฟอร์มสำหรับอุตสาหกรรมข้อมูลตลาดที่มีความหน่วงต่ำ LakshmiKanth ช่วยให้ลูกค้าสร้างโซลูชันที่เหมาะสมที่สุดสำหรับความต้องการข้อมูลตลาดของตน
![]() วิเวก อัคการ์วาล เป็นวิศวกรข้อมูลอาวุโสในกลุ่ม Low Latency Group ของ LSEG วิเวกทำงานเกี่ยวกับการพัฒนาและบำรุงรักษาท่อข้อมูลสำหรับการประมวลผลและการส่งมอบฟีดข้อมูลตลาดที่บันทึกไว้และฟีดข้อมูลอ้างอิง
วิเวก อัคการ์วาล เป็นวิศวกรข้อมูลอาวุโสในกลุ่ม Low Latency Group ของ LSEG วิเวกทำงานเกี่ยวกับการพัฒนาและบำรุงรักษาท่อข้อมูลสำหรับการประมวลผลและการส่งมอบฟีดข้อมูลตลาดที่บันทึกไว้และฟีดข้อมูลอ้างอิง
![]() อัลเก็ต เมมูชาจ เป็นสถาปนิกหลักในทีมพัฒนาตลาดบริการทางการเงินที่ AWS Alket รับผิดชอบด้านกลยุทธ์ทางเทคนิค โดยทำงานร่วมกับคู่ค้าและลูกค้าเพื่อปรับใช้แม้แต่ปริมาณงานตลาดทุนที่มีความต้องการมากที่สุดกับ AWS Cloud
อัลเก็ต เมมูชาจ เป็นสถาปนิกหลักในทีมพัฒนาตลาดบริการทางการเงินที่ AWS Alket รับผิดชอบด้านกลยุทธ์ทางเทคนิค โดยทำงานร่วมกับคู่ค้าและลูกค้าเพื่อปรับใช้แม้แต่ปริมาณงานตลาดทุนที่มีความต้องการมากที่สุดกับ AWS Cloud
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 1
- 10
- 100
- 12
- ลด 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- เกี่ยวกับเรา
- เข้า
- Accessed
- การเข้าถึง
- สามารถเข้าถึงได้
- ข้าม
- คล่องแคล่ว
- อยากทำกิจกรรม
- ที่เกิดขึ้นจริง
- จริง
- เพิ่ม
- นอกจากนี้
- ที่อยู่
- ความได้เปรียบ
- หลังจาก
- กับ
- Aggarwal
- จุดมุ่งหมาย
- ทั้งหมด
- การอนุญาต
- แล้ว
- อเมซอน
- อเมซอน อาเธน่า
- Amazon Web Services
- an
- วิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- วิเคราะห์
- และ
- ใด
- อาปาเช่
- Apache Spark
- APIs
- การใช้งาน
- การใช้งาน
- ใช้
- เข้าใกล้
- ประมาณ
- อนุญาโตตุลาการ
- อนุญาโตตุลาการ
- เป็น
- รอบ
- AS
- ถาม
- ประเมินผล
- ที่เกี่ยวข้อง
- At
- แอตทริบิวต์
- ผู้มีอำนาจ
- อัตโนมัติ
- อัตโนมัติ
- ความพร้อมใช้งาน
- ใช้ได้
- AWS
- สำรอง
- บาร์
- ตาม
- BE
- เพราะ
- ก่อน
- มาตรฐาน
- ที่ดีที่สุด
- ระหว่าง
- สั่ง
- พันล้าน
- ปิดกั้น
- โบรกเกอร์
- สร้าง
- แต่
- by
- คำนวณ
- คำนวณ
- การคำนวณ
- โทรศัพท์
- CAN
- ความจุ
- เมืองหลวง
- ตลาดทุน
- จับ
- ถูกจับกุม
- จับ
- แค็ตตาล็อก
- ศูนย์
- ท้าทาย
- ช่อง
- ลักษณะ
- โหลด
- ทางเลือก
- Choose
- ลูกค้า
- เมฆ
- รหัส
- การเก็บรวบรวม
- ร่วมกัน
- จับใจ
- สมบูรณ์
- เสร็จ
- ส่วนประกอบ
- ครอบคลุม
- ประกอบด้วย
- ความประพฤติ
- การกำหนดค่า
- การกำหนดค่า
- ปลอบใจ
- รวม
- มี
- สัญญา
- สนับสนุน
- แปลง
- บริษัท
- ราคา
- ค่าใช้จ่าย
- เขียนร่วม
- สร้าง
- ที่สร้างขึ้น
- การสร้าง
- วิกฤติ
- สำคัญมาก
- ขณะนี้
- ประเพณี
- ลูกค้า
- แดช หรือ Dash
- ข้อมูล
- ศูนย์ข้อมูล
- วิศวกรข้อมูล
- การแลกเปลี่ยนข้อมูล
- การจัดการข้อมูล
- การประมวลผล
- การจัดเก็บข้อมูล
- ที่ขับเคลื่อนด้วยข้อมูล
- ชุดข้อมูล
- วัน
- การตัดสินใจ
- การตัดสินใจ
- ค่าเริ่มต้น
- กำหนด
- การจัดส่ง
- เรียกร้อง
- ความต้องการ
- สาธิต
- แสดงให้เห็นถึง
- ปรับใช้
- รายละเอียด
- แน่นอน
- ที่กำลังพัฒนา
- พัฒนาการ
- ทีมพัฒนา
- ความแตกต่าง
- ต่าง
- โดยตรง
- ผู้อำนวยการ
- กระจาย
- การกระจาย
- หลาย
- สอง
- ขับรถ
- พลวัต
- แบบไดนามิก
- พลศาสตร์
- แต่ละ
- ความสะดวก
- สะดวกในการใช้
- ระบบนิเวศ
- บรรณาธิการ
- มีประสิทธิภาพ
- ประสิทธิผล
- เหมาะสม
- การกำจัด
- การจ้างงาน
- จ้าง
- ทำให้สามารถ
- ช่วยให้
- ห้อมล้อม
- ความพยายาม
- เครื่องยนต์
- วิศวกร
- เครื่องยนต์
- หัตถการด้านการเสริมความงาม
- เพื่อให้แน่ใจ
- เข้าสู่
- ทวีความรุนแรง
- อีเธอร์ (ETH)
- ประเมินค่า
- การประเมินผล
- แม้
- เหตุการณ์
- ทุกๆ
- ตัวอย่าง
- ตลาดแลกเปลี่ยน
- แลกเปลี่ยน
- การปฏิบัติ
- ประสบการณ์
- สำรวจ
- ด่วน
- ขยาย
- เร็วขึ้น
- ที่มีคุณสมบัติ
- กุมภาพันธ์
- มะเดื่อ
- ไฟล์
- ใส่
- กรอง
- ทางการเงิน
- สถาบันการเงิน
- บริการทางการเงิน
- เทคโนโลยีทางการเงิน
- บริษัท
- ชื่อจริง
- ครั้งแรก
- ห้า
- ความยืดหยุ่น
- มุ่งเน้นไปที่
- โดยมุ่งเน้น
- ดังต่อไปนี้
- สำหรับ
- รูป
- อดีต
- ข้างหน้า
- สี่
- FRAME
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- ฟังก์ชั่น
- ต่อไป
- ช่องว่าง
- สร้าง
- ได้รับ
- กำหนด
- เหตุการณ์ที่
- ตลาดโลก
- Go
- ไป
- จีพีเอส
- บัญชีกลุ่ม
- การจัดการ
- มี
- มี
- he
- เฮดรูม
- จะช่วยให้
- ที่มีคุณภาพสูง
- สูงกว่า
- ที่สูงที่สุด
- ไฮไลต์
- ทางประวัติศาสตร์
- ประวัติ
- การเคหะ
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- ทำอย่างไร
- ที่ http
- HTTPS
- AMI
- แยกแยะ
- เอกลักษณ์
- if
- ทันที
- ทันที
- ส่งผลกระทบ
- นำเข้า
- in
- รวมทั้ง
- เพิ่มขึ้น
- อุตสาหกรรม
- ข้อมูล
- โครงสร้างพื้นฐาน
- นวัตกรรม
- ข้อมูลเชิงลึก
- สถาบัน
- สำคัญ
- แบบบูรณาการ
- บูรณาการ
- ปฏิสัมพันธ์
- การโต้ตอบ
- เข้าไป
- ซับซ้อน
- การลงทุน
- ที่เกี่ยวข้องกับการ
- IT
- jpg
- เพียงแค่
- ใหญ่
- ขนาดใหญ่
- ชื่อสกุล
- ความแอบแฝง
- เปิดตัว
- น้อยลง
- ห้องสมุด
- Line
- สภาพคล่อง
- ที่ตั้ง
- ตรรกะ
- ที่ต้องการหา
- ต่ำ
- ต่ำที่สุด
- การบำรุงรักษา
- สำคัญ
- ทำให้
- การทำ
- จัดการ
- การจัดการ
- ผู้จัดการ
- ผู้จัดการ
- การจัดการ
- ลักษณะ
- หลาย
- ตลาด
- ข้อมูลการตลาด
- ผลกระทบต่อตลาด
- การวิจัยทางการตลาด
- ความผันผวนของตลาด
- การทำตลาด
- ตลาด
- มาก
- Mastering
- สูงสุด
- อาจ..
- วัด
- ข่าวสาร
- ข้อความ
- พิถีพิถัน
- อย่างพิถีพิถัน
- ตัวชี้วัด
- ล้าน
- ลด
- นาที
- การตรวจสอบ
- ข้อมูลเพิ่มเติม
- ยิ่งไปกว่านั้น
- มากที่สุด
- มาก
- หลาย
- ชื่อ
- ธรรมชาติ
- นำทาง
- จำเป็นต้อง
- ความต้องการ
- ไม่มี
- สมุดบันทึก
- โน๊ตบุ๊ค
- จำนวน
- มากมาย
- มึน
- ตั้งข้อสังเกต
- of
- เสนอ
- เสนอ
- on
- ONE
- ดีที่สุด
- เพิ่มประสิทธิภาพ
- การปรับให้เหมาะสม
- ตัวเลือกเสริม (Option)
- Options
- or
- องค์กร
- ของเรา
- ออก
- เอาท์พุต
- เกิน
- ทั้งหมด
- ของตนเอง
- หมีแพนด้า
- ส่วนหนึ่ง
- พาร์ทเนอร์
- หลงใหล
- รูปแบบ
- จุดสูงสุด
- ต่อ
- ดำเนินการ
- การปฏิบัติ
- เป็นจุดสำคัญ
- เวที
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- กรุณา
- พล็อต
- ผลงาน
- ผู้จัดการพอร์ต
- ตำแหน่ง
- โพสต์
- หลังการค้า
- ที่มีศักยภาพ
- ความแม่นยำ
- เตรียมการ
- การเตรียมความพร้อม
- ราคา
- การตั้งราคา
- ประถม
- หลัก
- กระบวนการ
- กระบวนการ
- การประมวลผล
- หน่วยประมวลผล
- ผลิตภัณฑ์
- การจัดการผลิตภัณฑ์
- ผู้จัดการผลิตภัณฑ์
- ผลิตภัณฑ์
- ความคืบหน้า
- ให้
- การให้
- การตีพิมพ์
- หลาม
- Q3
- เชิงปริมาณ
- ปริมาณ
- การสอบถาม
- คำพูด
- คะแนน
- ราคา
- อ่าน
- จริง
- เรียลไทม์
- แนะนำ
- บันทึก
- สีแดง
- ลด
- ลด
- การอ้างอิง
- รีฟินิทีฟ
- การรายงาน
- รายงาน
- กรุ
- ความต้องการ
- ต้อง
- การวิจัย
- คำตอบ
- รับผิดชอบ
- ผล
- ส่งผลให้
- ผลสอบ
- กลับ
- ความเสี่ยง
- บทบาท
- วิ่ง
- ทำงาน
- การขาย
- scalability
- ที่ปรับขนาดได้
- ตาชั่ง
- ปรับ
- ไร้รอยต่อ
- ได้อย่างลงตัว
- ที่สอง
- วินาที
- Section
- ส่วน
- หลักทรัพย์
- ความปลอดภัย
- ที่กำลังมองหา
- เลือก
- เลือก
- ระดับอาวุโส
- แยก
- ให้บริการอาหาร
- บริการ
- ชุด
- การตั้งค่า
- โชว์
- แสดงให้เห็นว่า
- อย่างมีความหมาย
- คล้ายคลึงกัน
- ง่าย
- ที่เรียบง่าย
- เดียว
- ลื่นไถล
- ซอฟต์แวร์
- การพัฒนาซอฟต์แวร์
- วิศวกรซอฟต์แวร์
- โซลูชัน
- ซับซ้อน
- ความตึงเครียด
- จุดประกาย
- โดยเฉพาะ
- กระจาย
- สเปรด
- ยืน
- ขั้นตอน
- การเก็บรักษา
- จัดเก็บ
- กลยุทธ์
- กลยุทธ์
- กลยุทธ์
- ช่วยเพิ่มความคล่องตัว
- ศึกษา
- ภายหลัง
- อย่างเช่น
- SWIFT
- เครื่องหมาย
- ทำงานร่วมกัน
- เอา
- การ
- ทีม
- วิชาการ
- เทคนิค
- เทคโนโลยี
- การทดสอบ
- กว่า
- ที่
- พื้นที่
- ข้อมูล
- ของพวกเขา
- พวกเขา
- แล้วก็
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- นี้
- ตลอด
- เห็บ
- เวลา
- ทันเวลา
- การประทับเวลา
- ชื่อหนังสือ
- ไปยัง
- รวม
- tp
- TPR
- การค้า
- ผู้ประกอบการค้า
- ธุรกิจการค้า
- เทรด
- กลยุทธ์การซื้อขาย
- กลยุทธ์การซื้อขาย
- การทำธุกรรม
- ต้นทุนการทำธุรกรรม
- การเปลี่ยนแปลง
- การเปลี่ยนแปลง
- รุนแรง
- ภายใต้
- ผ่านการ
- อัพเกรด
- us
- การใช้
- ใช้
- มือสอง
- ใช้
- การใช้
- การใช้ประโยชน์
- ความคุ้มค่า
- ต่างๆ
- การสร้างภาพ
- เห็นภาพ
- การระเหย
- ปริมาณ
- ไดรฟ์
- คือ
- we
- เว็บ
- บริการเว็บ
- เมื่อ
- ที่
- อย่างกว้างขวาง
- จะ
- กับ
- ภายใน
- ไม่มี
- กลุ่มงาน
- การทำงาน
- โรงงาน
- ทั่วโลก
- กังวล
- X
- ปี
- เธอ
- ของคุณ
- ลมทะเล