บทความด้านเทคนิคชื่อ “โซลูชันการอนุมาน LLM ที่มีประสิทธิภาพบน Intel GPU” ได้รับการเผยแพร่โดยนักวิจัยจาก Intel Corporation
นามธรรม:
“โมเดลภาษาขนาดใหญ่ที่ใช้หม้อแปลงไฟฟ้า (LLM) มีการใช้กันอย่างแพร่หลายในหลายสาขา และประสิทธิภาพของการอนุมาน LLM กลายเป็นประเด็นร้อนในการใช้งานจริง อย่างไรก็ตาม LLM มักจะได้รับการออกแบบอย่างซับซ้อนในโครงสร้างแบบจำลองที่มีการดำเนินการจำนวนมาก และทำการอนุมานในโหมดถอยหลังอัตโนมัติ ทำให้เป็นงานที่ท้าทายในการออกแบบระบบที่มีประสิทธิภาพสูง
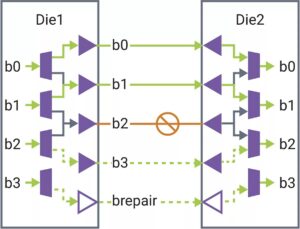
ในบทความนี้ เราขอเสนอโซลูชันการอนุมาน LLM ที่มีประสิทธิภาพพร้อมเวลาแฝงต่ำและปริมาณงานสูง ประการแรก เราทำให้เลเยอร์ตัวถอดรหัส LLM ง่ายขึ้นโดยการหลอมรวมการเคลื่อนย้ายข้อมูลและการดำเนินการตามองค์ประกอบเพื่อลดความถี่ในการเข้าถึงหน่วยความจำและลดเวลาแฝงของระบบ นอกจากนี้เรายังเสนอนโยบายแคช KV ส่วนเพื่อเก็บคีย์/ค่าของคำขอและโทเค็นการตอบกลับไว้ในหน่วยความจำกายภาพแยกต่างหากเพื่อการจัดการหน่วยความจำอุปกรณ์ที่มีประสิทธิภาพ ช่วยขยายขนาดแบตช์รันไทม์และปรับปรุงปริมาณงานของระบบ เคอร์เนล Scaled-Dot-Product-Attention แบบกำหนดเองได้รับการออกแบบเพื่อให้ตรงกับนโยบายการผสมของเราโดยอิงตามโซลูชันแคชเซกเมนต์ KV เราใช้โซลูชันการอนุมาน LLM บน Intel GPU และเผยแพร่ต่อสาธารณะ เมื่อเปรียบเทียบกับการใช้งาน HuggingFace มาตรฐาน โซลูชันที่นำเสนอมีความหน่วงของโทเค็นลดลงสูงสุด 7 เท่า และทรูพุตสูงกว่า 27 เท่าสำหรับ LLM ยอดนิยมบางตัวบน Intel GPU”
หา เอกสารทางเทคนิคที่นี่ จัดพิมพ์ธันวาคม 2023 (พิมพ์ล่วงหน้า)
อู๋, ฮุย, ยี่ก้าน, เฟิงหยวน, จิงหม่า, เว่ยจู้, หยูเทาซู, หงจู้, ยู่หัวจู้, เซียวลี่หลิว และจิงฮุยกู่ “โซลูชันการอนุมาน LLM ที่มีประสิทธิภาพบน Intel GPU” arXiv พิมพ์ล่วงหน้า arXiv:2401.05391 (2023)
การอ่านที่เกี่ยวข้อง
การอนุมาน LLM บน CPU (Intel)
บทความด้านเทคนิคชื่อ “การอนุมาน LLM ที่มีประสิทธิภาพบน CPU” ได้รับการตีพิมพ์โดยนักวิจัยที่ Intel
AI แข่งกันจนสุดขอบ
การอนุมานและการฝึกอบรมบางอย่างถูกผลักดันไปยังอุปกรณ์ขนาดเล็ก เนื่องจาก AI แพร่กระจายไปยังแอปพลิเคชันใหม่ๆ
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://semiengineering.com/llm-inference-on-gpus-intel/
- :เป็น
- $ ขึ้น
- 2023
- a
- เข้า
- ประสบความสำเร็จ
- AI
- ด้วย
- an
- และ
- การใช้งาน
- เป็น
- AS
- At
- ตาม
- จะกลายเป็น
- รับ
- กำลัง
- by
- แคช
- ท้าทาย
- เมื่อเทียบกับ
- บริษัท
- การปรับแต่ง
- ข้อมูล
- ธันวาคม
- ออกแบบ
- ได้รับการออกแบบ
- เครื่อง
- อุปกรณ์
- มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- ขยาย
- สาขา
- สำหรับ
- เวลา
- หลอมรวม
- การผสม
- GPU
- GPUs
- มี
- การช่วยเหลือ
- โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม
- จุดสูง
- สูงกว่า
- ฮ่องกง
- ร้อน
- อย่างไรก็ตาม
- HTTPS
- กอดใบหน้า
- การดำเนินการ
- การดำเนินงาน
- ปรับปรุง
- in
- อินเทล
- IT
- jpg
- เก็บ
- ภาษา
- ใหญ่
- ความแอบแฝง
- ชั้น
- llm
- ต่ำ
- ลด
- การทำ
- การจัดการ
- หลาย
- มาก
- การจับคู่
- หน่วยความจำ
- โหมด
- แบบ
- โมเดล
- การเคลื่อนไหว
- ใหม่
- of
- on
- เปิด
- การดำเนินการ
- ของเรา
- กระดาษ
- ดำเนินการ
- กายภาพ
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- นโยบาย
- ยอดนิยม
- เสนอ
- เสนอ
- สาธารณชน
- ประกาศ
- การตีพิมพ์
- ผลักดัน
- เผ่าพันธุ์
- จริง
- ลด
- ขอ
- นักวิจัย
- คำตอบ
- ส่วน
- แยก
- ลดความซับซ้อน
- ขนาด
- มีขนาดเล็กกว่า
- ทางออก
- บาง
- สเปรด
- มาตรฐาน
- โครงสร้าง
- ระบบ
- งาน
- วิชาการ
- พื้นที่
- นี้
- ปริมาณงาน
- หัวข้อ
- ไปยัง
- โทเค็น
- ราชสกุล
- หัวข้อ
- การฝึกอบรม
- มือสอง
- มักจะ
- คือ
- we
- อย่างกว้างขวาง
- กับ
- หยวน
- ลมทะเล