บทนำ
ลองนึกภาพการยืนอยู่ในห้องสมุดที่มีแสงสลัวๆ พยายามดิ้นรนเพื่อถอดรหัสเอกสารที่ซับซ้อนในขณะที่ต้องจัดการกับข้อความอื่นๆ อีกหลายสิบข้อความ นี่คือโลกของ Transformers ก่อนที่รายงาน "Attention is All You Need" จะเปิดเผยจุดเด่นที่ปฏิวัติวงการ นั่นก็คือ กลไกความสนใจ.
สารบัญ
ข้อจำกัดของ RNN
โมเดลลำดับแบบดั้งเดิมเช่น Recurrent Neural Networks (RNN), ประมวลผลภาษาทีละคำ นำไปสู่ข้อจำกัดหลายประการ:
- การพึ่งพาระยะสั้น: RNN พยายามทำความเข้าใจความเชื่อมโยงระหว่างคำที่อยู่ห่างไกล โดยมักตีความความหมายของประโยค เช่น “ชายผู้เยี่ยมชมสวนสัตว์เมื่อวานนี้” ผิด โดยที่ประธานและคำกริยาอยู่ห่างไกลกัน
- ความเท่าเทียมที่จำกัด: การประมวลผลข้อมูลตามลำดับนั้นช้าโดยธรรมชาติ ทำให้การฝึกอบรมและการใช้ทรัพยากรการคำนวณมีประสิทธิภาพลดลง โดยเฉพาะอย่างยิ่งสำหรับลำดับที่ยาว
- มุ่งเน้นไปที่บริบทท้องถิ่น: RNN พิจารณาเพื่อนบ้านใกล้เคียงเป็นหลัก ซึ่งอาจพลาดข้อมูลสำคัญจากส่วนอื่นๆ ของประโยค
ข้อจำกัดเหล่านี้ขัดขวางความสามารถของ Transformers ในการทำงานที่ซับซ้อน เช่น การแปลด้วยเครื่องและการทำความเข้าใจภาษาธรรมชาติ แล้วมา กลไกความสนใจซึ่งเป็นสปอตไลท์ปฏิวัติที่ส่องสว่างการเชื่อมโยงที่ซ่อนอยู่ระหว่างคำ เปลี่ยนความเข้าใจของเราในการประมวลผลภาษา แต่ความสนใจได้แก้ไขอะไรกันแน่ และมันเปลี่ยนเกมของ Transformers อย่างไร?
เรามามุ่งเน้นไปที่สามประเด็นสำคัญ:
การพึ่งพาระยะไกล
- ปัญหา: นางแบบดั้งเดิมมักจะสะดุดกับประโยคเช่น “ผู้หญิงที่อาศัยอยู่บนเนินเขาเห็นดาวตกเมื่อคืนนี้” พวกเขาพยายามดิ้นรนเพื่อเชื่อมโยง “ผู้หญิง” และ “ดาวตก” เนื่องจากระยะห่างระหว่างกัน ทำให้เกิดการตีความที่ผิด
- กลไกความสนใจ: ลองนึกภาพนางแบบที่ส่องแสงเจิดจ้าไปทั่วประโยค เชื่อมต่อ "ผู้หญิง" กับ "ดาวตก" โดยตรง และทำความเข้าใจประโยคโดยรวม ความสามารถในการบันทึกความสัมพันธ์โดยไม่คำนึงถึงระยะทางถือเป็นสิ่งสำคัญสำหรับงานต่างๆ เช่น การแปลด้วยเครื่องและการสรุป
ยังอ่าน: ภาพรวมของหน่วยความจำระยะสั้นระยะยาว (LSTM)
พลังการประมวลผลแบบขนาน
- ปัญหา: โมเดลแบบดั้งเดิมจะประมวลผลข้อมูลตามลำดับ เช่น การอ่านหนังสือทีละหน้า การดำเนินการนี้ช้าและไม่มีประสิทธิภาพ โดยเฉพาะข้อความยาวๆ
- กลไกความสนใจ: ลองนึกภาพสปอตไลท์หลายดวงสแกนห้องสมุดพร้อมกัน และวิเคราะห์ส่วนต่างๆ ของข้อความพร้อมกัน สิ่งนี้จะช่วยเร่งความเร็วการทำงานของโมเดลได้อย่างมาก ทำให้สามารถจัดการข้อมูลจำนวนมหาศาลได้อย่างมีประสิทธิภาพ พลังการประมวลผลแบบขนานนี้จำเป็นสำหรับการฝึกโมเดลที่ซับซ้อนและการคาดการณ์แบบเรียลไทม์
การรับรู้บริบททั่วโลก
- ปัญหา: โมเดลแบบดั้งเดิมมักเน้นไปที่คำแต่ละคำ โดยไม่มีบริบทที่กว้างขึ้นของประโยค สิ่งนี้นำไปสู่ความเข้าใจผิดในกรณีต่างๆ เช่น การเสียดสีหรือความหมายซ้ำซ้อน
- กลไกความสนใจ: ลองนึกภาพสปอตไลต์ที่กวาดไปทั่วห้องสมุด หยิบหนังสือทุกเล่มเข้ามาและทำความเข้าใจว่าหนังสือแต่ละเล่มเกี่ยวข้องกันอย่างไร การรับรู้บริบททั่วโลกนี้ทำให้โมเดลสามารถพิจารณาข้อความทั้งหมดเมื่อตีความแต่ละคำ นำไปสู่ความเข้าใจที่สมบูรณ์ยิ่งขึ้นและเหมาะสมยิ่งขึ้น
แยกแยะคำ Polysemous
- ปัญหา: คำเช่น "ธนาคาร" หรือ "แอปเปิ้ล" อาจเป็นคำนาม กริยา หรือแม้แต่บริษัท ทำให้เกิดความกำกวมที่โมเดลดั้งเดิมพยายามแก้ไข
- กลไกความสนใจ: ลองจินตนาการถึงแบบจำลองที่ส่องสปอตไลท์ไปที่คำว่า "ธนาคาร" ที่เกิดขึ้นทั้งหมดในประโยค จากนั้นวิเคราะห์บริบทและความสัมพันธ์โดยรอบด้วยคำอื่นๆ เมื่อพิจารณาโครงสร้างไวยากรณ์ คำนามใกล้เคียง และแม้แต่ประโยคที่ผ่านมา กลไกความสนใจก็สามารถอนุมานความหมายที่ตั้งใจไว้ได้ ความสามารถในการแยกแยะคำที่มีหลายคำนี้มีความสำคัญอย่างยิ่งสำหรับงานต่างๆ เช่น การแปลด้วยคอมพิวเตอร์ การสรุปข้อความ และระบบบทสนทนา
สี่แง่มุมเหล่านี้ ได้แก่ การพึ่งพาระยะไกล พลังการประมวลผลแบบขนาน การรับรู้บริบททั่วโลก และการแก้ความคลุมเครือ แสดงให้เห็นถึงพลังการเปลี่ยนแปลงของกลไกความสนใจ พวกเขาได้ขับเคลื่อน Transformers ไปสู่แถวหน้าของการประมวลผลภาษาธรรมชาติ ช่วยให้พวกเขาสามารถรับมือกับงานที่ซับซ้อนได้อย่างแม่นยำและมีประสิทธิภาพ
เนื่องจาก NLP และ LLM โดยเฉพาะมีการพัฒนาอย่างต่อเนื่อง กลไกความสนใจจะมีบทบาทสำคัญยิ่งขึ้นอย่างไม่ต้องสงสัย เป็นสะพานเชื่อมระหว่างลำดับคำเชิงเส้นและพรมอันอุดมสมบูรณ์ของภาษามนุษย์ และท้ายที่สุดคือกุญแจสำคัญในการปลดล็อกศักยภาพที่แท้จริงของสิ่งมหัศจรรย์ทางภาษาเหล่านี้ บทความนี้จะเจาะลึกกลไกความสนใจประเภทต่างๆ และฟังก์ชันการทำงาน
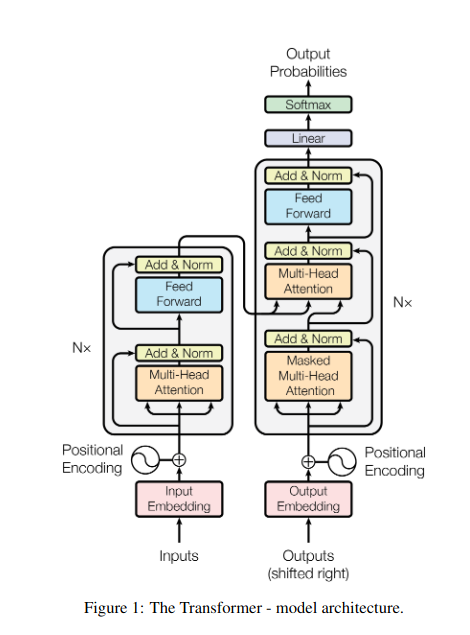
1. การเอาใจใส่ตนเอง: ดาวนำทางของทรานส์ฟอร์มเมอร์
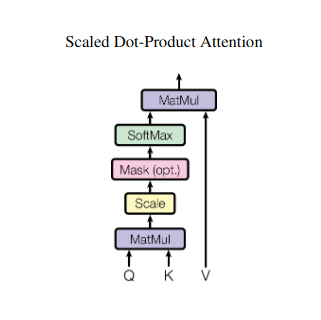
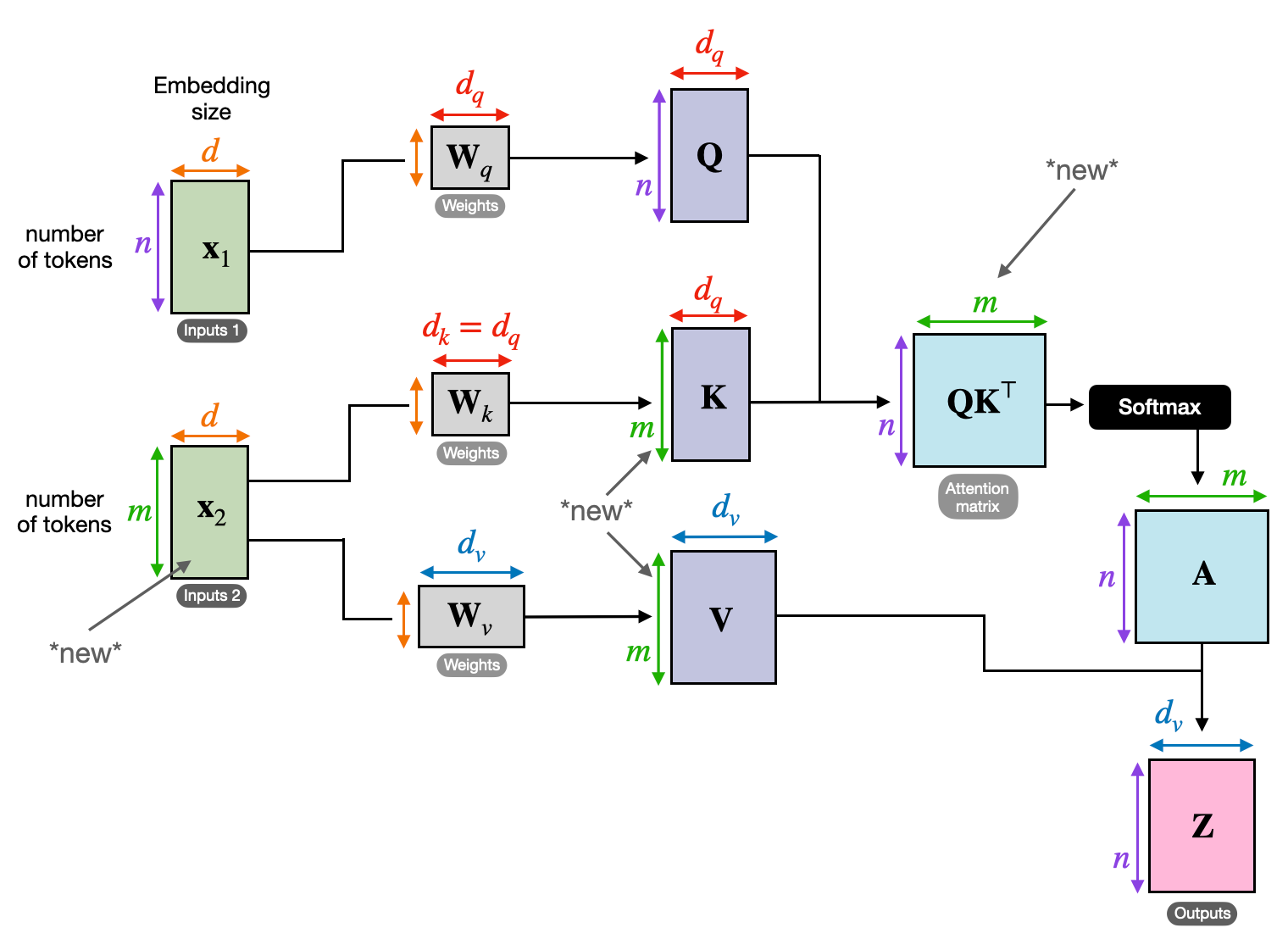
ลองนึกภาพการเล่นหนังสือหลายๆ เล่มและจำเป็นต้องอ้างอิงข้อความเฉพาะในแต่ละตอนขณะเขียนบทสรุป การเอาใจใส่ตนเองหรือความสนใจแบบ Dot-Product แบบปรับขนาดทำหน้าที่เหมือนผู้ช่วยอัจฉริยะ ช่วยให้โมเดลทำแบบเดียวกันกับข้อมูลตามลำดับ เช่น ประโยคหรืออนุกรมเวลา ช่วยให้แต่ละองค์ประกอบในลำดับเข้าร่วมกับองค์ประกอบอื่นๆ ทั้งหมด จับการพึ่งพาระยะยาวและความสัมพันธ์ที่ซับซ้อนได้อย่างมีประสิทธิภาพ
ต่อไปนี้คือภาพรวมทางเทคนิคหลักโดยละเอียด:
การแสดงเวกเตอร์
แต่ละองค์ประกอบ (คำ จุดข้อมูล) จะถูกแปลงเป็นเวกเตอร์มิติสูง โดยเข้ารหัสเนื้อหาข้อมูล สเปซเวกเตอร์นี้ทำหน้าที่เป็นรากฐานสำหรับการโต้ตอบระหว่างองค์ประกอบต่างๆ
การแปลงร่างของคิวเควี
มีการกำหนดเมทริกซ์หลักสามรายการ:
- แบบสอบถาม (ถาม): แสดงถึง “คำถาม” ที่แต่ละองค์ประกอบตั้งคำถามถึงองค์ประกอบอื่นๆ Q รวบรวมความต้องการข้อมูลขององค์ประกอบปัจจุบันและแนะนำการค้นหาข้อมูลที่เกี่ยวข้องภายในลำดับ
- คีย์ (K): เก็บ "กุญแจ" ไว้ที่ข้อมูลของแต่ละองค์ประกอบ K เข้ารหัสสาระสำคัญของเนื้อหาแต่ละองค์ประกอบ ทำให้องค์ประกอบอื่นๆ สามารถระบุความเกี่ยวข้องที่อาจเกิดขึ้นได้ตามความต้องการของตนเอง
- ค่า (V): เก็บเนื้อหาจริงที่แต่ละองค์ประกอบต้องการแชร์ V มีข้อมูลโดยละเอียดที่องค์ประกอบอื่นๆ สามารถเข้าถึงและใช้ประโยชน์ได้ตามคะแนนความสนใจของพวกเขา
การคำนวณคะแนนความสนใจ
ความเข้ากันได้ระหว่างคู่องค์ประกอบแต่ละคู่จะวัดผ่านดอทโปรดัคระหว่างเวกเตอร์ Q และ K ตามลำดับ คะแนนที่สูงกว่าบ่งชี้ถึงความเกี่ยวข้องที่เป็นไปได้มากขึ้นระหว่างองค์ประกอบต่างๆ
น้ำหนักความสนใจที่ปรับขนาด
เพื่อให้มั่นใจถึงความสำคัญสัมพัทธ์ คะแนนความเข้ากันได้เหล่านี้จะถูกทำให้เป็นมาตรฐานโดยใช้ฟังก์ชัน softmax ซึ่งส่งผลให้มีน้ำหนักความสนใจตั้งแต่ 0 ถึง 1 ซึ่งแสดงถึงความสำคัญแบบถ่วงน้ำหนักของแต่ละองค์ประกอบสำหรับบริบทขององค์ประกอบปัจจุบัน
การรวมบริบทแบบถ่วงน้ำหนัก
น้ำหนักความสนใจจะถูกนำไปใช้กับเมทริกซ์ V โดยเน้นข้อมูลที่สำคัญจากแต่ละองค์ประกอบตามความเกี่ยวข้องกับองค์ประกอบปัจจุบัน ผลรวมถ่วงน้ำหนักนี้สร้างการนำเสนอตามบริบทสำหรับองค์ประกอบปัจจุบัน โดยผสมผสานข้อมูลเชิงลึกที่รวบรวมจากองค์ประกอบอื่นๆ ทั้งหมดในลำดับ
การแสดงองค์ประกอบที่ได้รับการปรับปรุง
ด้วยการนำเสนอที่สมบูรณ์ยิ่งขึ้น องค์ประกอบจึงมีความเข้าใจเนื้อหาของตัวเองอย่างลึกซึ้งยิ่งขึ้น รวมถึงความสัมพันธ์กับองค์ประกอบอื่นๆ ในลำดับด้วย การแสดงที่ได้รับการเปลี่ยนแปลงนี้เป็นพื้นฐานสำหรับการประมวลผลภายในโมเดลในภายหลัง
กระบวนการหลายขั้นตอนนี้ช่วยให้สามารถใส่ใจตนเองเพื่อ:
- บันทึกการพึ่งพาระยะยาว: ความสัมพันธ์ระหว่างองค์ประกอบที่อยู่ห่างไกลจะปรากฏชัดเจน แม้ว่าจะแยกจากกันด้วยองค์ประกอบที่แทรกแซงหลายรายการก็ตาม
- จำลองการโต้ตอบที่ซับซ้อน: การพึ่งพาและความสัมพันธ์ที่ละเอียดอ่อนภายในลำดับจะถูกเปิดเผย นำไปสู่ความเข้าใจที่สมบูรณ์ยิ่งขึ้นเกี่ยวกับโครงสร้างข้อมูลและไดนามิก
- ปรับบริบทแต่ละองค์ประกอบ: แบบจำลองวิเคราะห์แต่ละองค์ประกอบโดยไม่แยกจากกัน แต่อยู่ภายในกรอบลำดับที่กว้างขึ้น นำไปสู่การทำนายหรือการนำเสนอที่แม่นยำและเหมาะสมยิ่งขึ้น
การใส่ใจในตนเองได้ปฏิวัติวิธีที่โมเดลประมวลผลข้อมูลตามลำดับ ปลดล็อกความเป็นไปได้ใหม่ๆ ในสาขาต่างๆ เช่น การแปลด้วยคอมพิวเตอร์ การสร้างภาษาธรรมชาติ การพยากรณ์อนุกรมเวลา และอื่นๆ ความสามารถในการเปิดเผยความสัมพันธ์ที่ซ่อนอยู่ภายในลำดับนั้นเป็นเครื่องมือที่ทรงพลังสำหรับการเปิดเผยข้อมูลเชิงลึกและบรรลุประสิทธิภาพที่เหนือกว่าในงานที่หลากหลาย
2. ความสนใจแบบหลายหัว: มองผ่านเลนส์ที่แตกต่างกัน
การเอาใจใส่ตนเองให้มุมมองแบบองค์รวม แต่บางครั้งการมุ่งเน้นไปที่ลักษณะเฉพาะของข้อมูลก็เป็นสิ่งสำคัญ นั่นคือที่มาของความสนใจจากหลายหัว ลองนึกภาพการมีผู้ช่วยหลายคน โดยแต่ละคนมีเลนส์ที่แตกต่างกัน:
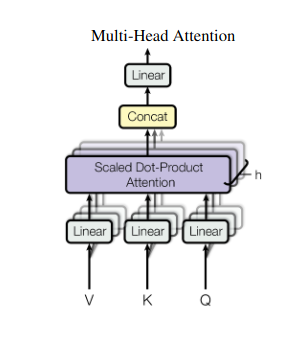
- “หัว” หลายอัน ถูกสร้างขึ้น โดยแต่ละรายการจะเข้าร่วมกับลำดับอินพุตผ่านเมทริกซ์ Q, K และ V ของตัวเอง
- หัวหน้าแต่ละคนเรียนรู้ที่จะมุ่งเน้นไปที่แง่มุมต่างๆ ของข้อมูล เช่น การขึ้นต่อกันในระยะยาว ความสัมพันธ์ทางวากยสัมพันธ์ หรือการโต้ตอบของคำในท้องถิ่น
- จากนั้นเอาต์พุตจากแต่ละหัวจะถูกต่อเข้าด้วยกันและฉายภาพเป็นการนำเสนอขั้นสุดท้าย โดยจับลักษณะหลายแง่มุมของอินพุต
ซึ่งช่วยให้โมเดลสามารถพิจารณามุมมองต่างๆ ได้พร้อมๆ กัน นำไปสู่ความเข้าใจข้อมูลที่สมบูรณ์และเหมาะสมยิ่งขึ้น
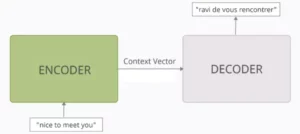
3. ความสนใจข้าม: การสร้างสะพานเชื่อมระหว่างลำดับ
ความสามารถในการเข้าใจความเชื่อมโยงระหว่างข้อมูลส่วนต่างๆ ถือเป็นสิ่งสำคัญสำหรับงาน NLP หลายอย่าง ลองนึกภาพการเขียนบทวิจารณ์หนังสือ คุณจะไม่เพียงแค่สรุปข้อความทีละคำ แต่ดึงข้อมูลเชิงลึกและความเชื่อมโยงระหว่างบทต่างๆ แทน เข้า ความสนใจข้ามซึ่งเป็นกลไกที่ทรงพลังที่สร้างสะพานเชื่อมระหว่างลำดับ เสริมศักยภาพให้กับโมเดลในการใช้ประโยชน์จากข้อมูลจากสองแหล่งที่แตกต่างกัน
- ในสถาปัตยกรรมตัวเข้ารหัส-ตัวถอดรหัส เช่น Transformers encoder ประมวลผลลำดับอินพุต (หนังสือ) และสร้างการแสดงที่ซ่อนอยู่
- พื้นที่ ถอดรหัส ใช้ความสนใจแบบข้ามเพื่อเข้าร่วมการแสดงที่ซ่อนอยู่ของตัวเข้ารหัสในแต่ละขั้นตอนในขณะที่สร้างลำดับเอาต์พุต (การตรวจสอบ)
- เมทริกซ์ Q ของตัวถอดรหัสโต้ตอบกับเมทริกซ์ K และ V ของตัวเข้ารหัส ทำให้สามารถมุ่งเน้นไปที่ส่วนที่เกี่ยวข้องของหนังสือในขณะที่เขียนแต่ละประโยคของการทบทวน
กลไกนี้มีคุณค่าอย่างยิ่งสำหรับงานต่างๆ เช่น การแปลด้วยคอมพิวเตอร์ การสรุป และการตอบคำถาม ซึ่งการทำความเข้าใจความสัมพันธ์ระหว่างลำดับอินพุตและเอาต์พุตเป็นสิ่งสำคัญ
4. ความสนใจเชิงสาเหตุ: รักษากระแสของเวลา
ลองจินตนาการถึงการคาดเดาคำถัดไปในประโยคโดยไม่ต้องมองไปข้างหน้า กลไกความสนใจแบบดั้งเดิมต้องต่อสู้กับงานที่จำเป็นต้องรักษาลำดับข้อมูลชั่วคราว เช่น การสร้างข้อความและการพยากรณ์อนุกรมเวลา พวกเขาพร้อมจะ "มองไปข้างหน้า" ตามลำดับ ซึ่งนำไปสู่การคาดเดาที่ไม่ถูกต้อง การเอาใจใส่เชิงสาเหตุจะแก้ไขข้อจำกัดนี้โดยทำให้แน่ใจว่าการคาดการณ์จะขึ้นอยู่กับข้อมูลที่ประมวลผลก่อนหน้านี้เท่านั้น
นี่คือวิธีการทำงาน
- กลไกการปิดบัง: มีการใช้มาสก์เฉพาะกับน้ำหนักความสนใจ ซึ่งจะบล็อกการเข้าถึงองค์ประกอบในอนาคตในลำดับของโมเดลได้อย่างมีประสิทธิภาพ ตัวอย่างเช่น เมื่อทำนายคำที่สองใน "ผู้หญิงที่..." แบบจำลองจะพิจารณาเฉพาะ "นั้น" เท่านั้น ไม่ใช่ "ใคร" หรือคำที่ตามมา
- การประมวลผลอัตโนมัติแบบถดถอย: ข้อมูลไหลเป็นเส้นตรง โดยการแสดงแต่ละองค์ประกอบสร้างขึ้นจากองค์ประกอบที่ปรากฏก่อนหน้าเท่านั้น แบบจำลองจะประมวลผลตามลำดับคำต่อคำ สร้างการคาดการณ์ตามบริบทที่สร้างขึ้นจนถึงจุดนั้น
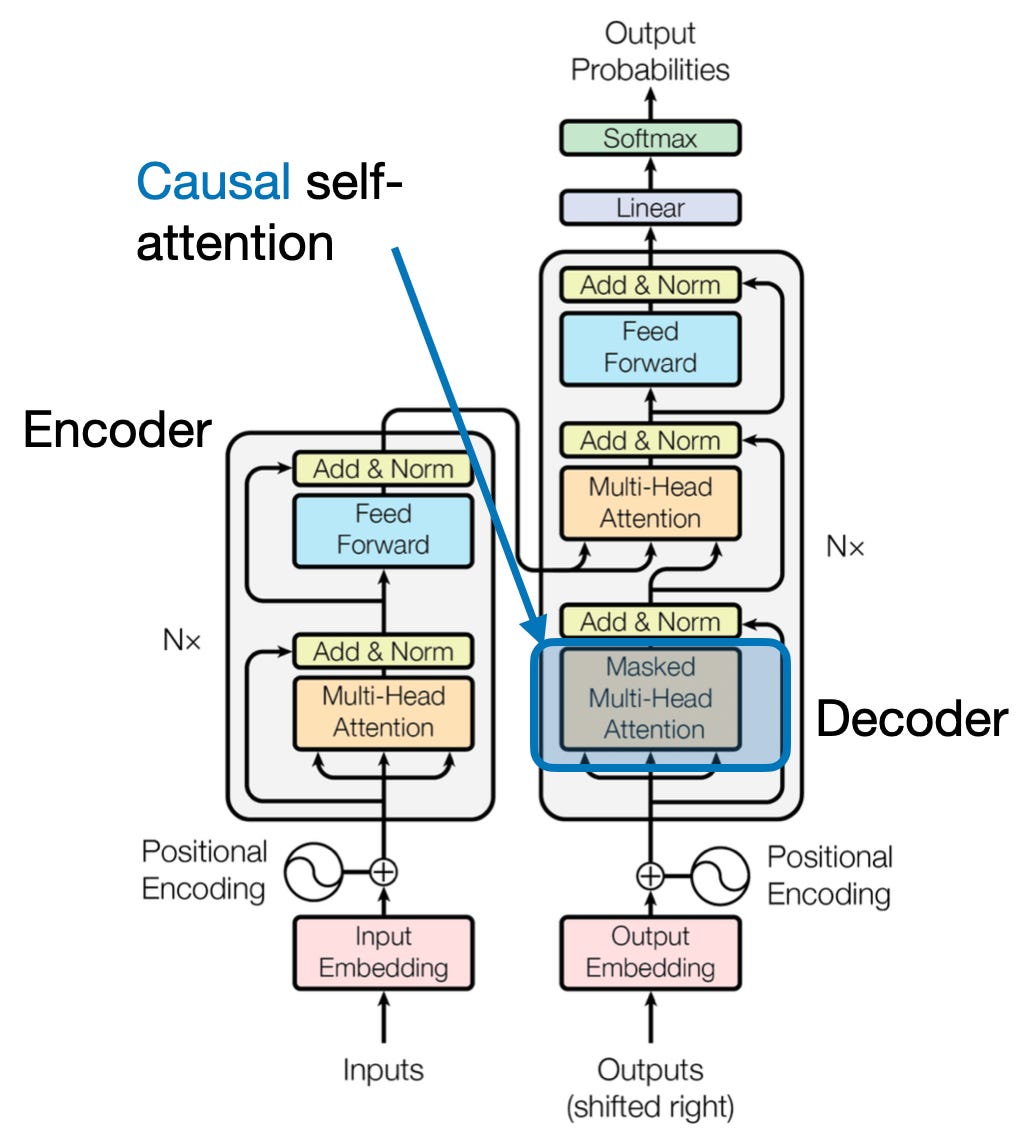
การเอาใจใส่เชิงสาเหตุเป็นสิ่งสำคัญสำหรับงานต่างๆ เช่น การสร้างข้อความและการพยากรณ์อนุกรมเวลา ซึ่งการรักษาลำดับเวลาของข้อมูลเป็นสิ่งสำคัญสำหรับการคาดการณ์ที่แม่นยำ
5. ความสนใจจากทั่วโลกและระดับท้องถิ่น: การสร้างสมดุล
กลไกความสนใจต้องเผชิญกับข้อเสียเปรียบที่สำคัญ: การจับภาพการพึ่งพาระยะยาวเทียบกับการรักษาการคำนวณที่มีประสิทธิภาพ สิ่งนี้แสดงให้เห็นในสองแนวทางหลัก: ความสนใจทั่วโลก และ ความสนใจในท้องถิ่น. ลองนึกภาพการอ่านหนังสือทั้งเล่มเทียบกับการมุ่งเน้นไปที่บทใดบทหนึ่งโดยเฉพาะ ความสนใจจากทั่วโลกจะประมวลผลลำดับทั้งหมดพร้อมกัน ในขณะที่ความสนใจในท้องถิ่นจะเน้นไปที่หน้าต่างที่เล็กกว่า:
- ความสนใจจากทั่วโลก จับการขึ้นต่อกันในระยะยาวและบริบทโดยรวม แต่อาจมีราคาแพงในการคำนวณสำหรับลำดับที่ยาว
- ความสนใจในท้องถิ่น มีประสิทธิภาพมากกว่าแต่อาจพลาดความสัมพันธ์อันห่างไกล
ทางเลือกระหว่างความสนใจในระดับโลกและระดับท้องถิ่นขึ้นอยู่กับปัจจัยหลายประการ:
- ข้อกำหนดของงาน: งานต่างๆ เช่น การแปลด้วยเครื่องจำเป็นต้องจับความสัมพันธ์ที่ห่างไกล โดยให้ความสำคัญกับความสนใจจากทั่วโลก ในขณะที่การวิเคราะห์ความรู้สึกอาจสนับสนุนการมุ่งเน้นที่ความสนใจในท้องถิ่น
- ความยาวลำดับ: ลำดับที่ยาวขึ้นทำให้ความสนใจทั่วโลกมีราคาแพงในการคำนวณ โดยจำเป็นต้องใช้วิธีท้องถิ่นหรือแบบผสม
- ความจุของรุ่น: ข้อจำกัดด้านทรัพยากรอาจจำเป็นต้องให้ความสนใจในท้องถิ่น แม้สำหรับงานที่ต้องใช้บริบททั่วโลกก็ตาม
เพื่อให้เกิดความสมดุลที่เหมาะสม โมเดลต่างๆ สามารถใช้:
- การสลับแบบไดนามิก: ใช้ความสนใจทั่วโลกสำหรับองค์ประกอบหลัก และใช้ความสนใจในท้องถิ่นสำหรับผู้อื่น ปรับเปลี่ยนตามความสำคัญและระยะทาง
- แนวทางไฮบริด: รวมกลไกทั้งสองไว้ในชั้นเดียวกันโดยใช้ประโยชน์จากจุดแข็งตามลำดับ
ยังอ่าน: การวิเคราะห์ประเภทของโครงข่ายประสาทเทียมในการเรียนรู้เชิงลึก
สรุป
ท้ายที่สุดแล้ว แนวทางในอุดมคตินั้นขึ้นอยู่กับความสนใจระหว่างความสนใจในระดับโลกและระดับท้องถิ่น การทำความเข้าใจข้อดีข้อเสียเหล่านี้และการนำกลยุทธ์ที่เหมาะสมมาใช้ช่วยให้แบบจำลองสามารถใช้ประโยชน์จากข้อมูลที่เกี่ยวข้องในระดับต่างๆ ได้อย่างมีประสิทธิภาพ นำไปสู่ความเข้าใจลำดับที่สมบูรณ์ยิ่งขึ้นและแม่นยำยิ่งขึ้น
อ้างอิง
- ราชกา, เอส. (2023) “การทำความเข้าใจและการเข้ารหัสความสนใจในตนเอง ความสนใจแบบหลายหัว ความสนใจแบบข้าม และความสนใจเชิงสาเหตุใน LLM”
- วาสวานี เอ. และคณะ (2017) “ความสนใจคือสิ่งที่คุณต้องการ”
- แรดฟอร์ด เอ. และคณะ (2019) “โมเดลภาษาคือผู้เรียนที่ทำงานหลายอย่างพร้อมกันโดยไม่ได้รับการดูแล”
ที่เกี่ยวข้อง
ฉันเป็นคนรักข้อมูลและชอบที่จะแยกและทำความเข้าใจรูปแบบที่ซ่อนอยู่ในข้อมูล ฉันต้องการเรียนรู้และเติบโตในสาขา Machine Learning และ Data Science
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- :มี
- :เป็น
- :ไม่
- :ที่ไหน
- $ ขึ้น
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- ความสามารถ
- เข้า
- ความถูกต้อง
- ถูกต้อง
- บรรลุ
- การบรรลุ
- ข้าม
- การกระทำ
- ที่เกิดขึ้นจริง
- ที่อยู่
- การนำ
- ก่อน
- AL
- ทั้งหมด
- การอนุญาต
- ช่วยให้
- am
- ความคลุมเครือ
- จำนวน
- an
- การวิเคราะห์
- การวิเคราะห์
- วิเคราะห์
- และ
- ตอบ
- นอกเหนือ
- เห็นได้ชัด
- ประยุกต์
- เข้าใกล้
- วิธีการ
- เป็น
- พื้นที่
- บทความ
- AS
- ด้าน
- ผู้ช่วย
- ผู้ช่วย
- At
- ที่คาดหวัง
- เข้าร่วม
- ความสนใจ
- ความตระหนัก
- ยอดคงเหลือ
- ตาม
- รากฐาน
- BE
- คาน
- กลายเป็น
- ก่อน
- ระหว่าง
- เกิน
- การปิดกั้น
- หนังสือ
- ร้านหนังสือเกาหลี
- ทั้งสอง
- สะพาน
- สะพาน
- สดใส
- ที่กว้างขึ้น
- นำ
- การก่อสร้าง
- สร้าง
- สร้าง
- แต่
- by
- มา
- CAN
- จับ
- จับ
- จับ
- กรณี
- เปลี่ยนแปลง
- บท
- บท
- ทางเลือก
- ใกล้ชิด
- การเข้ารหัส
- รวมกัน
- มา
- บริษัท
- ความเข้ากันได้
- ซับซ้อน
- การคำนวณ
- การคำนวณ
- เชื่อมต่อ
- การเชื่อมต่อ
- การเชื่อมต่อ
- พิจารณา
- พิจารณา
- ข้อ จำกัด
- มี
- เนื้อหา
- สิ่งแวดล้อม
- ต่อ
- แกน
- ความสัมพันธ์
- ที่สร้างขึ้น
- สร้าง
- การสร้าง
- วิกฤติ
- สำคัญมาก
- ปัจจุบัน
- ข้อมูล
- วิทยาศาสตร์ข้อมูล
- แปลรหัส
- ลึก
- ลึก
- กำหนด
- เดลฟ์
- ขึ้นอยู่กับ
- การพึ่งพาอาศัยกัน
- การอ้างอิง
- การอยู่ที่
- ขึ้นอยู่กับ
- รายละเอียด
- บทสนทนา
- DID
- ต่าง
- โดยตรง
- ระยะทาง
- ไกล
- แตกต่าง
- หลาย
- do
- เอกสาร
- DOT
- สอง
- หลายสิบ
- เป็นคุ้งเป็นแคว
- วาด
- สอง
- พลศาสตร์
- E&T
- แต่ละ
- มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- ที่มีประสิทธิภาพ
- อย่างมีประสิทธิภาพ
- ธาตุ
- องค์ประกอบ
- เพิ่มขีดความสามารถ
- ช่วยให้
- การเปิดใช้งาน
- การเข้ารหัส
- อุดม
- ทำให้มั่นใจ
- การสร้างความมั่นใจ
- เข้าสู่
- ทั้งหมด
- ทั้งหมด
- พร้อม
- โดยเฉพาะอย่างยิ่ง
- แก่นแท้
- จำเป็น
- เป็นหลัก
- ที่จัดตั้งขึ้น
- แม้
- ทุกๆ
- คาย
- เผง
- แพง
- เอาเปรียบ
- สารสกัด
- ใบหน้า
- ปัจจัย
- ไกล
- โปรดปราน
- สนาม
- สาขา
- สุดท้าย
- ไหล
- กระแส
- โฟกัส
- มุ่งเน้น
- มุ่งเน้นไปที่
- โดยมุ่งเน้น
- สำหรับ
- แถวหน้า
- รูปแบบ
- รากฐาน
- สี่
- กรอบ
- ราคาเริ่มต้นที่
- ฟังก์ชัน
- ฟังก์ชันการทำงาน
- อนาคต
- เกม
- สร้าง
- การสร้าง
- รุ่น
- เหตุการณ์ที่
- บริบททั่วโลก
- เข้าใจ
- ขึ้น
- คู่มือ
- ที่แนะนำ
- จัดการ
- มี
- มี
- หัว
- การช่วยเหลือ
- ซ่อนเร้น
- จุดสูง
- สูงกว่า
- ไฮไลต์
- ถือ
- แบบองค์รวม
- สรุป ความน่าเชื่อถือของ Olymp Trade?
- HTTPS
- เป็นมนุษย์
- เป็นลูกผสม
- i
- ในอุดมคติ
- แยกแยะ
- if
- ภาพ
- ทันที
- ความสำคัญ
- สำคัญ
- in
- ไม่เที่ยง
- ผสมผสาน
- แสดง
- เป็นรายบุคคล
- ไม่มีประสิทธิภาพ
- ข้อมูล
- อย่างโดยเนื้อแท้
- อินพุต
- ข้อมูลเชิงลึก
- ตัวอย่าง
- ฉลาด
- ตั้งใจว่า
- ปฏิสัมพันธ์
- ปฏิสัมพันธ์
- เชิงโต้ตอบ
- ที่แทรกแซง
- เข้าไป
- ล้ำค่า
- ความเหงา
- IT
- ITS
- jpg
- เพียงแค่
- คีย์
- พื้นที่สำคัญ
- ภาษา
- ชื่อสกุล
- ชั้น
- ชั้นนำ
- เรียนรู้
- เรียนรู้และเติบโต
- ผู้เรียน
- การเรียนรู้
- นำ
- เลนส์
- เลนส์
- เลฟเวอเรจ
- การใช้ประโยชน์
- ห้องสมุด
- ตั้งอยู่
- เบา
- กดไลก์
- การ จำกัด
- ข้อ จำกัด
- ในประเทศ
- นาน
- อีกต่อไป
- ดู
- ความรัก
- เครื่อง
- เรียนรู้เครื่อง
- การแปลด้วยเครื่อง
- การบำรุงรักษา
- ทำ
- การทำ
- มนุษย์
- หลาย
- หน้ากาก
- มดลูก
- ความกว้างสูงสุด
- ความหมาย
- ความหมาย
- วัด
- กลไก
- กลไก
- หน่วยความจำ
- อาจ
- พลาด
- หายไป
- แบบ
- โมเดล
- ข้อมูลเพิ่มเติม
- มีประสิทธิภาพมากขึ้น
- หลายแง่มุม
- หลาย
- โดยธรรมชาติ
- ภาษาธรรมชาติ
- การสร้างภาษาธรรมชาติ
- ประมวลผลภาษาธรรมชาติ
- การเข้าใจภาษาธรรมชาติ
- ธรรมชาติ
- จำเป็นต้อง
- ต้อง
- ความต้องการ
- เพื่อนบ้าน
- เครือข่าย
- ประสาท
- เครือข่ายประสาทเทียม
- ใหม่
- ถัดไป
- คืน
- NLP
- คำนาม
- ตอนนี้
- เหมาะสมยิ่ง
- of
- มักจะ
- on
- ครั้งเดียว
- เพียง
- ดีที่สุด
- or
- ใบสั่ง
- อื่นๆ
- ผลิตภัณฑ์อื่นๆ
- ของเรา
- ออก
- เอาท์พุต
- เอาท์พุท
- ทั้งหมด
- ภาพรวม
- ของตนเอง
- หน้า
- คู่
- กระดาษ
- Parallel
- ส่วน
- ทางเดิน
- อดีต
- รูปแบบ
- ดำเนินการ
- การปฏิบัติ
- มุมมอง
- ชิ้น
- เพลโต
- เพลโตดาต้าอินเทลลิเจนซ์
- เพลโตดาต้า
- เล่น
- จุด
- โพสท่า
- ครอบครอง
- ความเป็นไปได้
- มีพลัง
- ที่มีศักยภาพ
- ที่อาจเกิดขึ้น
- อำนาจ
- ที่มีประสิทธิภาพ
- ทำนาย
- การคาดการณ์
- การรักษา
- การป้องกัน
- ก่อนหน้านี้
- ส่วนใหญ่
- ประถม
- กระบวนการ
- การประมวลผล
- กระบวนการ
- การประมวลผล
- กำลังประมวลผล
- ผลิตภัณฑ์
- ที่คาดการณ์
- ขับเคลื่อน
- ให้
- คำถาม
- พิสัย
- ตั้งแต่
- ค่อนข้าง
- อ่าน
- อย่างง่ายดาย
- การอ่าน
- เรียลไทม์
- การอ้างอิง
- ไม่คำนึงถึง
- ความสัมพันธ์
- ญาติ
- ความสัมพันธ์กัน
- ตรงประเด็น
- โดดเด่น
- การแสดง
- เป็นตัวแทนของ
- แสดงให้เห็นถึง
- ต้องการ
- แก้ไข
- ทรัพยากร
- แหล่งข้อมูล
- ว่า
- ผลสอบ
- ทบทวน
- การปฏิวัติ
- ปฏิวัติ
- รวย
- บทบาท
- s
- เดียวกัน
- การเสียดสี
- เห็น
- ตาชั่ง
- การสแกน
- วิทยาศาสตร์
- คะแนน
- คะแนน
- ค้นหา
- ที่สอง
- เห็น
- ประโยค
- ความรู้สึก
- ลำดับ
- ชุด
- ให้บริการอาหาร
- หลาย
- Share
- ส่องแสง
- การยิง
- สั้น
- แสดง
- พร้อมกัน
- ช้า
- มีขนาดเล็กกว่า
- เพียงผู้เดียว
- แก้
- บางครั้ง
- แหล่งที่มา
- ช่องว่าง
- โดยเฉพาะ
- เฉพาะ
- สเปกตรัม
- ความเร็ว
- ไฟฉายสว่างจ้า
- ยืน
- ดาว
- ขั้นตอน
- ร้านค้า
- กลยุทธ์
- จุดแข็ง
- แข็งแกร่ง
- โครงสร้าง
- การต่อสู้
- การดิ้นรน
- หรือ
- ภายหลัง
- อย่างเช่น
- เหมาะสม
- รวม
- สรุป
- สรุป
- เหนือกว่า
- ที่ล้อมรอบ
- ระบบ
- ต่อสู้
- การ
- พรม
- งาน
- วิชาการ
- ระยะ
- ข้อความ
- การสร้างข้อความ
- ที่
- พื้นที่
- โลก
- ของพวกเขา
- พวกเขา
- แล้วก็
- ล้อยางขัดเหล่านี้ติดตั้งบนแกน XNUMX (มม.) ผลิตภัณฑ์นี้ถูกผลิตในหลายรูปทรง และหลากหลายเบอร์ความแน่นหนาของปริมาณอนุภาคขัดของมัน จะทำให้ท่านได้รับประสิทธิภาพสูงในการขัดและการใช้งานที่ยาวนาน
- พวกเขา
- นี้
- สาม
- ตลอด
- เวลา
- อนุกรมเวลา
- ไปยัง
- เครื่องมือ
- แบบดั้งเดิม
- การฝึกอบรม
- กระแส
- เปลี่ยน
- หม้อแปลงไฟฟ้า
- หม้อแปลง
- การเปลี่ยนแปลง
- การแปลภาษา
- จริง
- สอง
- ชนิด
- ในที่สุด
- เข้าใจ
- ความเข้าใจ
- ไม่ต้องสงสัย
- ปลดล็อค
- เปิดเผย
- เปิดตัว
- ใช้
- ใช้
- การใช้
- ต่างๆ
- กว้างใหญ่
- กับ
- รายละเอียด
- เข้าเยี่ยมชม
- จำเป็น
- vs
- ต้องการ
- ต้องการ
- คือ
- ดี
- อะไร
- เมื่อ
- ในขณะที่
- WHO
- ทั้งหมด
- กว้าง
- ช่วงกว้าง
- จะ
- หน้าต่าง
- กับ
- ภายใน
- ไม่มี
- หญิง
- คำ
- คำ
- งาน
- โลก
- การเขียน
- เมื่อวาน
- เธอ
- ลมทะเล
- สวนสัตว์