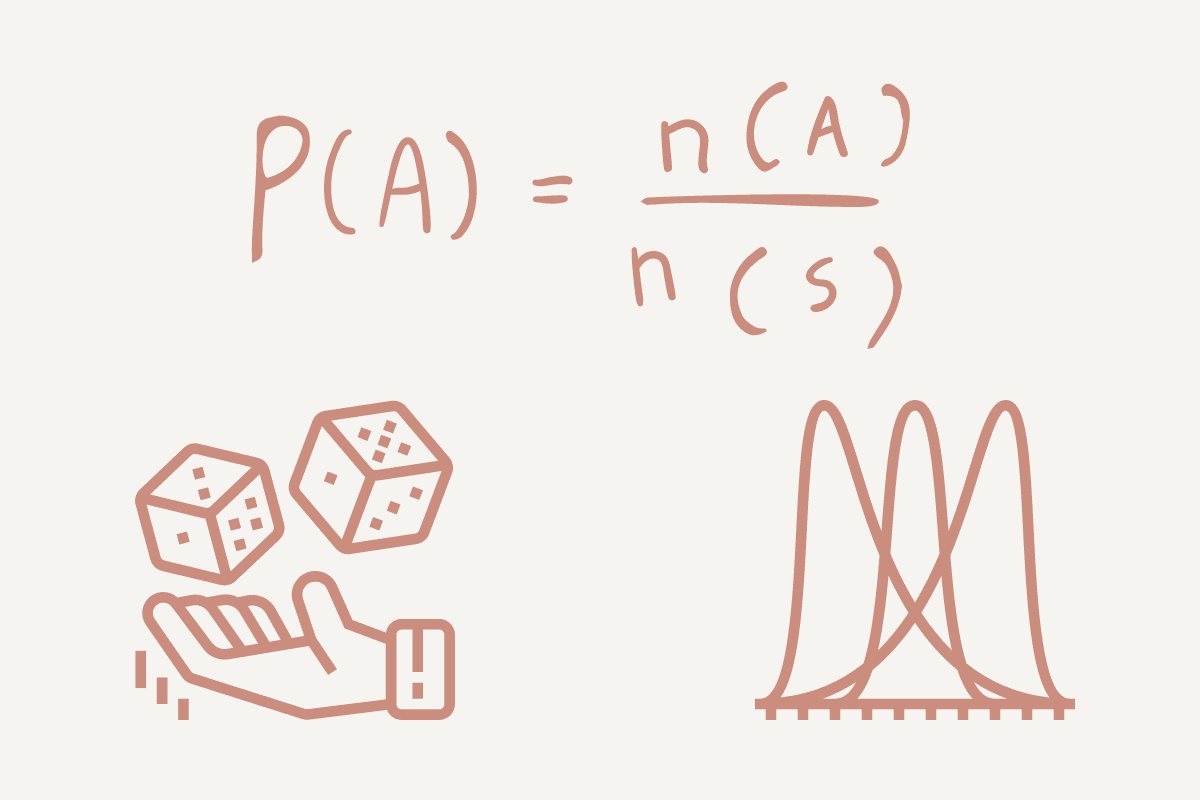
Bild av författare
Som dataforskare vill du veta exaktheten i dina resultat för att säkerställa giltigheten. Arbetsflödet för datavetenskap är ett planerat projekt, med kontrollerade förhållanden. Så att du kan bedöma varje steg och hur det lånade ut din produktion.
Sannolikhet är måttet på sannolikheten för att en händelse/något ska hända. Det är ett viktigt inslag i prediktiv analys som låter dig utforska beräkningsmatematiken bakom ditt resultat.
Med ett enkelt exempel, låt oss titta på att kasta ett mynt: antingen huvuden (H) eller svansar (T). Din sannolikhet kommer att vara antalet sätt som en händelse kan inträffa dividerat med det totala antalet möjliga utfall.
- Om vi vill hitta sannolikheten för huvuden skulle det vara 1 (Huvud) / 2 (Huvud och svans) = 0.5.
- Om vi vill hitta sannolikheten för svansar skulle det vara 1 (svansar) / 2 (huvuden och svansar) = 0.5.
Men vi vill inte blanda ihop sannolikhet och sannolikhet – det finns en skillnad. Sannolikhet är måttet på att en specifik händelse eller utfall inträffar. Sannolikhet tillämpas när du vill öka chanserna att en specifik händelse eller utfall inträffar.
För att bryta ner det – sannolikhet handlar om möjliga resultat, medan sannolikhet handlar om hypoteser.
En annan term att känna till är ''ömsesidigt uteslutande evenemang''. Detta är händelser som inte inträffar samtidigt. Du kan till exempel inte gå åt höger och vänster samtidigt. Eller om vi slår ett mynt, kan vi antingen få huvuden eller svansar, inte båda.
Typer av sannolikhet
- Teoretisk sannolikhet: detta fokuserar på hur sannolikt en händelse är att inträffa och är baserat på grunden för resonemang. Med hjälp av teori är utfallet det förväntade värdet. Med exemplet med huvud och svans är den teoretiska sannolikheten för att landa på huvuden 0.5 eller 50 %.
- Experimentell sannolikhet: detta fokuserar på hur ofta en händelse inträffar under experimentets varaktighet. Om vi använder exemplet med huvud och svansar – om vi skulle kasta ett mynt 10 gånger och det landade på huvuden 6 gånger, skulle den experimentella sannolikheten för att myntet landar på huvuden vara 6/10 eller 60 %.
Villkorlig sannolikhet är möjligheten att en händelse/utfall inträffar baserat på en befintlig händelse/utfall. Till exempel, om du arbetar för ett försäkringsbolag, kanske du vill ta reda på sannolikheten för att en person ska kunna betala för sin försäkring baserat på villkoret att de har tagit ett huslån.
Villkorlig sannolikhet hjälper dataforskare att producera mer exakta modeller och utdata genom att använda andra variabler i datamängden.
En sannolikhetsfördelning är en statistisk funktion som hjälper till att beskriva möjliga värden och sannolikheter för en slumpvariabel inom ett givet intervall. Området kommer att ha möjliga minimi- och maximivärden, och var de plottas på en distributionsgraf beror på statistiska tester.
Beroende på vilken typ av data som används i projektet kan du ta reda på vilken typ av distribution du använder. Jag kommer att dela upp dem i två kategorier: diskret distribution och kontinuerlig distribution.
Diskret distribution
Diskret distribution är när data bara kan anta vissa värden eller har ett begränsat antal utfall. Om du till exempel skulle kasta en tärning är dina begränsade värden 1, 2, 3, 4, 5 och 6.
Det finns olika typer av diskret distribution. Till exempel:
- Diskret enhetlig fördelning är när alla utfall är lika sannolika. Om vi använder exemplet med att slå en sexsidig tärning, är det lika stor sannolikhet att den kan landa på 1, 2, 3, 4, 5 eller 6 – ⅙. Problemet med diskret enhetlig fördelning är dock att den inte ger oss relevant information som dataforskare kan använda och tillämpa.
- Bernoulli Distribution är en annan typ av diskret fördelning, där experimentet bara har två möjliga utfall, antingen ja eller nej, 1 eller 2, sant eller falskt. Detta kan användas när man slår ett mynt, det är antingen huvud eller svans. När vi använder Bernoulli-fördelningen har vi sannolikheten för ett av utfallen (p) och vi kan dra av den från den totala sannolikheten (1), representerad som (1-p).
- Binomial distribution är en sekvens av Bernoulli-händelser och är den diskreta sannolikhetsfördelningen som bara kan ge två möjliga resultat i ett experiment, antingen framgång eller misslyckande. När du vänder ett mynt kommer sannolikheten att vända ett mynt alltid vara 1.5 eller ½ i varje experiment som utförs.
- Poisson-distribution är fördelningen av hur många gånger en händelse sannolikt inträffar under en viss period eller avstånd. Istället för att fokusera på en händelse som inträffar, fokuserar den på frekvensen av en händelse som inträffar i ett specifikt intervall. Till exempel, om 12 bilar kör på en viss väg klockan 11 varje dag, kan vi använda Poisson-fördelningen för att räkna ut hur många bilar som kör på den vägen klockan 11 på en månad.
Kontinuerlig distribution
Till skillnad från diskreta distributioner som har ändliga utfall, har kontinuerliga distributioner kontinuerliga utfall. Dessa fördelningar visas vanligtvis som en kurva eller en linje på en graf eftersom data är kontinuerliga.
- Normal distribution är en som du kanske har hört talas om eftersom den är den mest använda. Det är en symmetrisk fördelning av värdena runt medelvärdet, utan skevhet. Datan följer en klockform när den plottas, där mittintervallet är medelvärdet. Till exempel följer egenskaper som höjd och IQ-poäng en normalfördelning.
- T-distribution är en typ av kontinuerlig fördelning som används när populationens standardavvikelse (σ) är okänd och urvalsstorleken är liten (n<30). Den följer samma form som en normalfördelning, klockkurvan. Om vi till exempel tittar på hur många chokladkakor som såldes på en dag, skulle vi använda normalfördelningen. Men om vi vill titta på hur många som såldes under en specifik timme kommer vi att använda t-distribution.
- Exponentiell fördelning är en typ av kontinuerlig sannolikhetsfördelning som fokuserar på hur lång tid det tar innan en händelse inträffar. Vi kanske till exempel vill titta på jordbävningar och kan använda exponentiell distribution. Mängden tid, från denna punkt tills en jordbävning inträffar. Exponentialfördelningen plottas som en krökt linje och representerar sannolikheterna exponentiellt.
Från ovanstående kan du se hur datavetare kan använda sannolikhet för att förstå mer om data och svara på frågor. Det är mycket användbart för datavetare att känna till och förstå chanserna att en händelse inträffar och kan vara mycket effektiv i beslutsprocessen.
Du kommer ständigt att arbeta med data och du behöver lära dig mer om det innan du utför någon form av analys. Att titta på datadistributionen kan ge dig mycket information och kan använda denna för att justera din uppgift, process och modell för att tillgodose datadistributionen.
Detta minskar din tid på att förstå data, ger ett mer effektivt arbetsflöde och ger mer exakta utdata.
Många av begreppen datavetenskap är baserade på sannolikhetsgrunderna.
Nisha Arya är datavetare och frilansande teknisk skribent. Hon är särskilt intresserad av att ge Data Science karriärråd eller handledning och teoribaserad kunskap kring Data Science. Hon vill också utforska de olika sätten artificiell intelligens är/kan gynna människans livslängd. En angelägen lärande, som vill bredda sina tekniska kunskaper och skrivförmåga, samtidigt som hon hjälper andra att vägleda.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.kdnuggets.com/2023/02/importance-probability-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-importance-of-probability-in-data-science
- 1
- 10
- 11
- a
- Able
- Om Oss
- om det
- ovan
- noggrannhet
- exakt
- rådgivning
- Alla
- tillåta
- alltid
- mängd
- analys
- och
- Annan
- svara
- visas
- tillämpas
- Ansök
- runt
- konstgjord
- artificiell intelligens
- barer
- baserat
- innan
- bakom
- Där vi får lov att vara utan att konstant prestera,
- klocka
- fördel
- Ha sönder
- bredda
- kan inte
- Karriär
- bilar
- kategorier
- vissa
- chanser
- egenskaper
- Chocolate
- Coin
- företag
- Begreppen
- tillstånd
- villkor
- förväxlas
- ständigt
- kontinuerlig
- Kontinuum
- kontrolleras
- kurva
- datum
- datavetenskap
- datavetare
- dag
- Beslutsfattande
- beskriva
- avvikelse
- den
- Skillnaden
- olika
- avstånd
- fördelning
- Distributioner
- dividerat
- inte
- ner
- under
- varje
- jordskalv
- Effektiv
- antingen
- säkerställa
- lika
- händelse
- händelser
- Varje
- varje dag
- exempel
- Exklusiv
- befintliga
- förväntat
- experimentera
- utforska
- exponentiell
- exponentiellt
- Misslyckande
- Figur
- hitta
- fokuserar
- fokusering
- följer
- följer
- formen
- fundament
- frilans
- Frekvens
- ofta
- från
- fungera
- Fundamentals
- skaffa sig
- Ge
- ges
- Go
- diagram
- styra
- Happening
- huvud
- huvuden
- hört
- höjd
- hjälpa
- hjälper
- Huset
- Hur ser din drömresa ut
- Men
- HTTPS
- humant
- vikt
- med Esport
- in
- Öka
- informationen
- försäkring
- Intelligens
- intresserad
- IT
- KDnuggets
- Angelägen
- Vet
- kunskap
- land
- landning
- LÄRA SIG
- elev
- livet
- sannolikt
- Begränsad
- linje
- lån
- livslängd
- se
- du letar
- Lot
- många
- matte
- maximal
- mäta
- Mitten
- minsta
- modell
- modeller
- Månad
- mer
- mest
- Behöver
- normala
- antal
- ONE
- Övriga
- Övrigt
- Resultat
- särskilt
- särskilt
- Betala
- utför
- perioden
- personen
- planeras
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- befolkning
- Möjligheten
- möjlig
- Prediktiv analys
- Sannolikheten
- Problem
- process
- producera
- projektet
- ge
- ger
- tillhandahålla
- frågor
- slumpmässig
- område
- minskar
- relevanta
- representerade
- representerar
- Resultat
- väg
- Rulla
- Rullande
- Samma
- Vetenskap
- Forskare
- vetenskapsmän
- söker
- Sekvens
- Forma
- Enkelt
- Storlek
- skev
- färdigheter
- Small
- säljs
- specifik
- specificerade
- spent
- Etapp
- standard
- Starta
- statistisk
- framgång
- sådana
- Ta
- uppgift
- tech
- Teknisk
- tester
- Smakämnen
- teoretiska
- tid
- gånger
- till
- kasta
- Totalt
- mot
- sann
- självstudiekurser
- typer
- typiskt
- förstå
- förståelse
- us
- användning
- värde
- Värden
- sätt
- Vad
- som
- Medan
- kommer
- önskemål
- inom
- arbetsflöde
- arbetssätt
- skulle
- författare
- skrivning
- Din
- zephyrnet