OpenAI Whisper är en avancerad automatisk taligenkänning (ASR) modell med en MIT-licens. ASR-tekniken är användbar i transkriptionstjänster, röstassistenter och förbättrad tillgänglighet för personer med hörselnedsättning. Denna toppmoderna modell är tränad på ett stort och mångsidigt dataset av flerspråkig och multitask övervakad data som samlats in från webben. Dess höga noggrannhet och anpassningsförmåga gör den till en värdefull tillgång för ett brett utbud av röstrelaterade uppgifter.
I det ständigt föränderliga landskapet av maskininlärning och artificiell intelligens, Amazon SageMaker ger ett heltäckande ekosystem. SageMaker ger datavetare, utvecklare och organisationer möjlighet att utveckla, träna, distribuera och hantera maskininlärningsmodeller i stor skala. Den erbjuder ett brett utbud av verktyg och funktioner och förenklar hela arbetsflödet för maskininlärning, från förbearbetning av data och modellutveckling till enkel implementering och övervakning. SageMakers användarvänliga gränssnitt gör det till en central plattform för att låsa upp den fulla potentialen hos AI och etablera den som en spelförändrande lösning inom artificiell intelligens.
I det här inlägget ger vi oss ut på en utforskning av SageMakers möjligheter, speciellt med fokus på att vara värd för Whisper-modeller. Vi kommer att dyka djupt in i två metoder för att göra detta: en använder Whisper PyTorch-modellen och den andra använder Hugging Face-implementeringen av Whisper-modellen. Dessutom kommer vi att genomföra en djupgående undersökning av SageMakers slutledningsalternativ och jämföra dem över parametrar som hastighet, kostnad, nyttolaststorlek och skalbarhet. Denna analys ger användare möjlighet att fatta välgrundade beslut när de integrerar Whisper-modeller i deras specifika användningsfall och system.
Lösningsöversikt
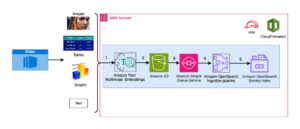
Följande diagram visar huvudkomponenterna i denna lösning.
- För att vara värd för modellen på Amazon SageMaker är det första steget att spara modellartefakterna. Dessa artefakter hänvisar till de väsentliga komponenterna i en maskininlärningsmodell som behövs för olika applikationer, inklusive distribution och omskolning. De kan inkludera modellparametrar, konfigurationsfiler, förbearbetningskomponenter, såväl som metadata, såsom versionsdetaljer, författarskap och eventuella anteckningar relaterade till dess prestanda. Det är viktigt att notera att Whisper-modeller för PyTorch och Hugging Face-implementeringar består av olika modellartefakter.
- Därefter skapar vi anpassade slutledningsskript. Inom dessa skript definierar vi hur modellen ska laddas och specificerar slutledningsprocessen. Det är också här vi kan införliva anpassade parametrar efter behov. Dessutom kan du lista de nödvändiga Python-paketen i en
requirements.txtfil. Under modellens distribution installeras dessa Python-paket automatiskt i initialiseringsfasen. - Sedan väljer vi antingen PyTorch eller Hugging Face djupinlärningsbehållare (DLC) som tillhandahålls och underhålls av AWS. Dessa behållare är förbyggda Docker-bilder med ramverk för djupinlärning och andra nödvändiga Python-paket. För mer information kan du kolla detta länk.
- Med modellartefakter, anpassade slutledningsskript och utvalda DLC:er skapar vi Amazon SageMaker-modeller för PyTorch respektive Hugging Face.
- Slutligen kan modellerna distribueras på SageMaker och användas med följande alternativ: slutpunkter i realtid, batchtransformeringsjobb och asynkrona slutpunkter. Vi kommer att dyka in i dessa alternativ mer i detalj senare i det här inlägget.
Exempelanteckningsboken och koden för den här lösningen är tillgängliga på detta GitHub repository.
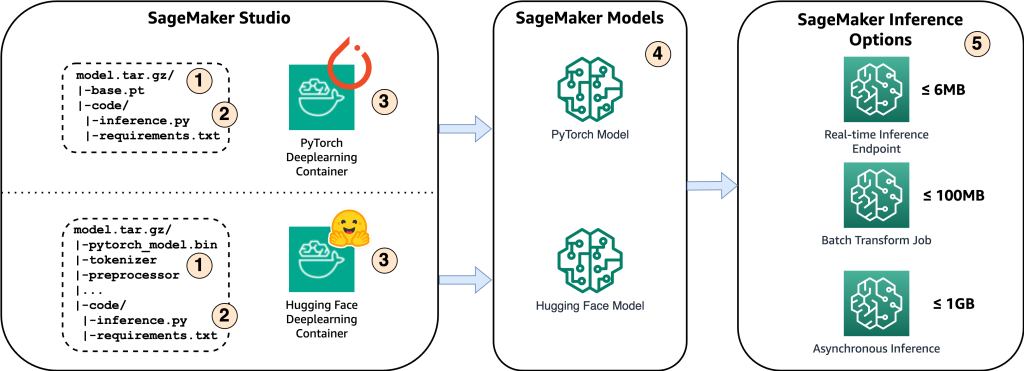
Figur 1. Översikt över viktiga lösningskomponenter
genomgång
Värd för Whisper Model på Amazon SageMaker
I det här avsnittet kommer vi att förklara stegen för att vara värd för Whisper-modellen på Amazon SageMaker, med PyTorch respektive Hugging Face Frameworks. För att experimentera med den här lösningen behöver du ett AWS-konto och tillgång till Amazon SageMaker-tjänsten.
PyTorch ramverk
- Spara modellartefakter
Det första alternativet att vara värd för modellen är att använda Whisper officiella Python-paket, som kan installeras med hjälp av pip install openai-whisper. Detta paket tillhandahåller en PyTorch-modell. När du sparar modellartefakter i det lokala arkivet är det första steget att spara modellens inlärbara parametrar, såsom modellvikter och fördomar för varje lager i det neurala nätverket, som en "pt"-fil. Du kan välja mellan olika modellstorlekar, inklusive 'liten', 'bas', 'liten', 'medium' och 'stor'. Större modellstorlekar ger högre noggrannhet, men kommer till priset av längre slutledningsfördröjning. Dessutom måste du spara modelltillståndsordboken och dimensionslexikon, som innehåller en Python-ordbok som mappar varje lager eller parameter i PyTorch-modellen till dess motsvarande inlärbara parametrar, tillsammans med andra metadata och anpassade konfigurationer. Koden nedan visar hur man sparar Whisper PyTorch-artefakterna.
- Välj DLC
Nästa steg är att välja den förbyggda DLC från denna länk. Var försiktig när du väljer rätt bild genom att överväga följande inställningar: ramverk (PyTorch), ramverksversion, uppgift (inferens), Python-version och hårdvara (d.v.s. GPU). Det rekommenderas att använda de senaste versionerna för ramverket och Python när det är möjligt, eftersom detta resulterar i bättre prestanda och åtgärdar kända problem och buggar från tidigare utgåvor.
- Skapa Amazon SageMaker-modeller
Därefter använder vi SageMaker Python SDK för att skapa PyTorch-modeller. Det är viktigt att komma ihåg att lägga till miljövariabler när du skapar en PyTorch-modell. Som standard kan TorchServe endast bearbeta filstorlekar upp till 6 MB, oavsett vilken slutledningstyp som används.
Följande tabell visar inställningarna för olika PyTorch-versioner:
| Ramverk | Miljövariabler |
| PyTorch 1.8 (baserat på TorchServe) | 'TS_MAX_REQUEST_SIZE': '100000000'' TS_MAX_RESPONSE_SIZE': '100000000'' TS_DEFAULT_RESPONSE_TIMEOUT': '1000' |
| PyTorch 1.4 (baserat på MMS) | 'MMS_MAX_REQUEST_SIZE': '1000000000'' MMS_MAX_RESPONSE_SIZE': '1000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definiera modellladdningsmetoden i inference.py
I seden inference.py skript, kontrollerar vi först om det finns en CUDA-kapabel GPU. Om en sådan GPU är tillgänglig, tilldelar vi 'cuda' enhet till DEVICE variabel; annars tilldelar vi 'cpu' enhet. Detta steg säkerställer att modellen placeras på tillgänglig hårdvara för effektiv beräkning. Vi laddar PyTorch-modellen med Whisper Python-paketet.
Kramande ansiktsram
- Spara modellartefakter
Det andra alternativet är att använda Hugging Face's Whisper genomförande. Modellen kan laddas med hjälp av AutoModelForSpeechSeq2Seq transformatorklass. De lärbara parametrarna sparas i en binär (bin) fil med hjälp av save_pretrained metod. Tokenizern och förprocessorn måste också sparas separat för att säkerställa att Hugging Face-modellen fungerar korrekt. Alternativt kan du distribuera en modell på Amazon SageMaker direkt från Hugging Face Hub genom att ställa in två miljövariabler: HF_MODEL_ID och HF_TASK. För mer information, se denna webbsida.
- Välj DLC
I likhet med PyTorch-ramverket kan du välja en förbyggd Hugging Face DLC från densamma länk. Se till att välja en DLC som stöder de senaste Hugging Face-transformatorerna och inkluderar GPU-stöd.
- Skapa Amazon SageMaker-modeller
På samma sätt använder vi SageMaker Python SDK att skapa Hugging Face-modeller. Hugging Face Whisper-modellen har en standardbegränsning där den bara kan bearbeta ljudsegment i upp till 30 sekunder. För att åtgärda denna begränsning kan du inkludera chunk_length_s parameter i miljövariabeln när du skapar Hugging Face-modellen, och senare skicka denna parameter till det anpassade slutledningsskriptet när modellen laddas. Slutligen, ställ in miljövariablerna för att öka nyttolaststorleken och svarstidsgränsen för Hugging Face-behållaren.
| Ramverk | Miljövariabler |
|
HuggingFace Inference Container (baserat på MMS) |
'MMS_MAX_REQUEST_SIZE': '2000000000'' MMS_MAX_RESPONSE_SIZE': '2000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definiera modellladdningsmetoden i inference.py
När vi skapar anpassade slutledningsskript för Hugging Face-modellen använder vi en pipeline som gör att vi kan passera chunk_length_s som en parameter. Denna parameter gör det möjligt för modellen att effektivt bearbeta långa ljudfiler under slutledning.
Utforska olika slutledningsalternativ på Amazon SageMaker
Stegen för att välja slutledningsalternativ är desamma för både PyTorch och Hugging Face-modeller, så vi kommer inte att skilja mellan dem nedan. Det är dock värt att notera att när detta inlägg skrivs, serverlös slutledning alternativet från SageMaker stöder inte GPU:er, och som ett resultat utesluter vi det här alternativet för detta användningsfall.
Vi kan distribuera modellen som en slutpunkt i realtid och ge svar på millisekunder. Det är dock viktigt att notera att det här alternativet är begränsat till att bearbeta indata under 6 MB. Vi definierar serializern som en audio serializer, som ansvarar för att konvertera indata till ett lämpligt format för den utplacerade modellen. Vi använder en GPU-instans för slutledning, vilket möjliggör accelererad bearbetning av ljudfiler. Slutledningsingången är en ljudfil som kommer från det lokala förvaret.
Det andra slutledningsalternativet är batchtransformeringsjobbet, som kan bearbeta indatanyttolaster upp till 100 MB. Den här metoden kan dock ta några minuters latens. Varje instans kan endast hantera en batchbegäran åt gången, och initieringen och avstängningen av instansen kräver också några minuter. Slutledningsresultaten sparas i en Amazon Simple Storage Service (Amazon S3) hink efter slutförandet av batchtransformeringsjobbet.
När du konfigurerar batchtransformatorn, se till att inkludera max_payload = 100 att hantera större nyttolaster effektivt. Slutledningsingången bör vara Amazon S3-sökvägen till en ljudfil eller en Amazon S3 Bucket-mapp som innehåller en lista med ljudfiler, var och en med en storlek som är mindre än 100 MB.
Batch Transform partitionerar Amazon S3-objekten i inmatningen med nyckel och mappar Amazon S3-objekt till instanser. Till exempel, när du har flera ljudfiler kan en instans bearbeta input1.wav och en annan instans kan bearbeta filen som heter input2.wav för att förbättra skalbarheten. Batch Transform låter dig konfigurera max_concurrent_transforms för att öka antalet HTTP-förfrågningar som görs till varje enskild transformatorbehållare. Det är dock viktigt att notera att värdet av (max_concurrent_transforms* max_payload) får inte överstiga 100 MB.
Slutligen är Amazon SageMaker Asynchronous Inference idealisk för att bearbeta flera förfrågningar samtidigt, och erbjuder måttlig latens och stöder indatanyttolaster på upp till 1 GB. Detta alternativ ger utmärkt skalbarhet, vilket möjliggör konfigurationen av en autoskalningsgrupp för slutpunkten. När en ökning av förfrågningar inträffar skalas den automatiskt upp för att hantera trafiken, och när alla förfrågningar har behandlats skalas slutpunkten ner till 0 för att spara kostnader.
Med hjälp av asynkron slutledning sparas resultaten automatiskt i en Amazon S3-hink. I den AsyncInferenceConfig, kan du konfigurera aviseringar för framgångsrika eller misslyckade slutföranden. Inmatningssökvägen pekar på en Amazon S3-plats för ljudfilen. För ytterligare information, se koden på GitHub.
Frivillig: Som nämnts tidigare har vi möjlighet att konfigurera en autoskalningsgrupp för den asynkrona slutpunkten, vilket gör att den kan hantera en plötslig ökning av inferensförfrågningar. Ett kodexempel finns i detta GitHub repository. I följande diagram kan du observera ett linjediagram som visar två mätvärden från amazoncloudwatch: ApproximateBacklogSize och ApproximateBacklogSizePerInstance. Från början, när 1000 förfrågningar triggades, var endast en instans tillgänglig för att hantera slutsatsen. Under tre minuter översteg eftersläpningen konsekvent tre (observera att dessa siffror kan konfigureras), och den automatiska skalningsgruppen svarade genom att snurra upp ytterligare instanser för att effektivt rensa bort eftersläpningen. Detta resulterade i en betydande minskning av ApproximateBacklogSizePerInstance, vilket gör att förfrågningar om eftersläpning kan behandlas mycket snabbare än under den inledande fasen.

Figur 2. Linjediagram som illustrerar de tidsmässiga förändringarna i Amazon CloudWatch-mått
Jämförande analys för slutledningsalternativen
Jämförelserna för olika slutledningsalternativ baseras på vanliga fall för ljudbehandling. Realtidsinferens ger den snabbaste slutledningshastigheten men begränsar nyttolaststorleken till 6 MB. Denna slutledningstyp är lämplig för ljudkommandosystem, där användare styr eller interagerar med enheter eller programvara med hjälp av röstkommandon eller talade instruktioner. Röstkommandon är vanligtvis små i storlek, och låg slutledningsfördröjning är avgörande för att säkerställa att transkriberade kommandon snabbt kan utlösa efterföljande åtgärder. Batch Transform är idealiskt för schemalagda offlineuppgifter, när varje ljudfils storlek är under 100 MB och det inte finns några specifika krav på snabba slutledningssvarstider. Asynkron slutledning tillåter uppladdningar på upp till 1 GB och erbjuder måttlig slutledningsfördröjning. Denna inferenstyp är väl lämpad för att transkribera filmer, TV-serier och inspelade konferenser där större ljudfiler behöver bearbetas.
Både realtids- och asynkrona slutledningsalternativ ger autoskalningsmöjligheter, vilket gör att ändpunktsinstanserna automatiskt kan skala upp eller ner baserat på volymen av förfrågningar. I fall utan förfrågningar tar autoskalning bort onödiga instanser, vilket hjälper dig att undvika kostnader förknippade med provisionerade instanser som inte används aktivt. För realtidsinferens måste dock minst en beständig instans behållas, vilket kan leda till högre kostnader om slutpunkten fungerar kontinuerligt. Däremot tillåter asynkron inferens att instansvolymen reduceras till 0 när den inte används. När du konfigurerar ett batchtransformeringsjobb är det möjligt att använda flera instanser för att bearbeta jobbet och justera max_concurrent_transforms så att en instans kan hantera flera förfrågningar. Därför erbjuder alla tre slutledningsalternativen stor skalbarhet.
Städar upp
När du har slutfört användningen av lösningen, se till att ta bort SageMaker-ändpunkterna för att förhindra extra kostnader. Du kan använda den medföljande koden för att radera realtids- respektive asynkrona slutpunkter.
Slutsats
I det här inlägget visade vi dig hur implementering av maskininlärningsmodeller för ljudbehandling har blivit allt viktigare i olika branscher. Med Whisper-modellen som ett exempel, visade vi hur man är värd för ASR-modeller med öppen källkod på Amazon SageMaker med PyTorch eller Hugging Face-metoder. Utforskningen omfattade olika slutledningsalternativ på Amazon SageMaker, som erbjuder insikter i att effektivt hantera ljuddata, göra förutsägelser och hantera kostnader effektivt. Det här inlägget syftar till att ge kunskap för forskare, utvecklare och datavetare som är intresserade av att utnyttja Whisper-modellen för ljudrelaterade uppgifter och fatta välgrundade beslut om slutledningsstrategier.
För mer detaljerad information om hur du distribuerar modeller på SageMaker, se detta Utvecklarguide. Dessutom kan Whisper-modellen distribueras med SageMaker JumpStart. För ytterligare information, vänligen kontrollera Whisper-modeller för automatisk taligenkänning är nu tillgängliga i Amazon SageMaker JumpStart posta.
Kolla gärna in anteckningsboken och koden för detta projekt på GitHub och dela din kommentar med oss.
Om författaren
 Ying Hou, PhD, är Machine Learning Prototyping Architect på AWS. Hennes primära intresseområden omfattar Deep Learning, med fokus på GenAI, Computer Vision, NLP och förutsägelse av tidsseriedata. På fritiden njuter hon av att tillbringa kvalitetsstunder med sin familj, fördjupa sig i romaner och vandra i Storbritanniens nationalparker.
Ying Hou, PhD, är Machine Learning Prototyping Architect på AWS. Hennes primära intresseområden omfattar Deep Learning, med fokus på GenAI, Computer Vision, NLP och förutsägelse av tidsseriedata. På fritiden njuter hon av att tillbringa kvalitetsstunder med sin familj, fördjupa sig i romaner och vandra i Storbritanniens nationalparker.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- : har
- :är
- :inte
- :var
- $UPP
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- accelererad
- tillgång
- tillgänglighet
- Konto
- noggrannhet
- tvärs
- åtgärder
- aktivt
- lägga till
- Annat
- Dessutom
- adress
- justera
- avancerat
- AI
- Syftet
- Alla
- tillåta
- tillåter
- längs
- också
- amason
- Amazon SageMaker
- Amazon Web Services
- an
- analys
- och
- Annan
- vilken som helst
- tillämpningar
- tillvägagångssätt
- ÄR
- områden
- array
- konstgjord
- artificiell intelligens
- AS
- tillgång
- assistenter
- associerad
- At
- audio
- Författarskap
- Automat
- automatiskt
- tillgänglighet
- tillgänglig
- undvika
- AWS
- bas
- baserat
- BE
- blir
- nedan
- Bättre
- mellan
- förspänner
- SOPTUNNA
- båda
- fel
- men
- by
- KAN
- kapacitet
- kapabel
- noggrann
- fall
- Förändringar
- Diagram
- ta
- Välja
- välja
- klass
- klar
- koda
- komma
- kommentar
- Gemensam
- jämförande
- jämförelser
- Avslutade
- fullbordan
- komponenter
- omfattande
- beräkning
- dator
- Datorsyn
- Genomför
- konferenser
- konfiguration
- konfigurerad
- konfigurering
- med tanke på
- konsekvent
- innehålla
- Behållare
- Behållare
- kontinuerligt
- Däremot
- kontroll
- omvandling
- korrekt
- Motsvarande
- Pris
- Kostar
- kunde
- CPU
- skapa
- Skapa
- avgörande
- beställnings
- datum
- beslut
- minskning
- djup
- djupt lärande
- Standard
- definiera
- demonstreras
- distribuera
- utplacerade
- utplacera
- utplacering
- detalj
- detaljerad
- detaljer
- utveckla
- utvecklare
- Utveckling
- anordning
- enheter
- olika
- skilja
- Dimensionera
- direkt
- visning
- Dyk
- flera
- Hamnarbetare
- inte
- gör
- ner
- under
- e
- varje
- Tidigare
- ekosystemet
- effektivt
- effektiv
- effektivt
- enkel
- antingen
- annars
- gå ombord
- bemyndigar
- möjliggöra
- möjliggör
- möjliggör
- omfatta
- Slutpunkt
- endpoints
- förbättra
- förbättra
- säkerställa
- säkerställer
- Hela
- Miljö
- väsentlig
- upprättandet
- Eter (ETH)
- undersökning
- exempel
- överstiga
- överskrids
- utmärkt
- experimentera
- Förklara
- utforskning
- Utforska
- Ansikte
- Misslyckades
- falsk
- familj
- SNABB
- snabbare
- snabbast
- få
- Fil
- Filer
- fynd
- Förnamn
- Fokus
- fokusering
- efter
- För
- format
- Ramverk
- ramar
- Fri
- från
- full
- GPU
- GPUs
- stor
- Grupp
- hantera
- Arbetsmiljö
- hårdvara
- Har
- hörsel
- hjälpa
- här
- Hög
- högre
- vandring
- värd
- värd
- Hur ser din drömresa ut
- How To
- Men
- html
- http
- HTTPS
- Nav
- Kramar ansikte
- i
- idealisk
- if
- som illustrerar
- bild
- bilder
- genomförande
- implementeringar
- importera
- med Esport
- in
- djupgående
- innefattar
- innefattar
- Inklusive
- införliva
- Öka
- alltmer
- individuellt
- individer
- industrier
- informationen
- informeras
- inledande
- initialt
- initiering
- ingång
- ingångar
- insikter
- installera
- exempel
- instanser
- instruktioner
- Integrera
- Intelligens
- interagera
- intresse
- intresserad
- Gränssnitt
- in
- problem
- IT
- DESS
- Jobb
- Lediga jobb
- jpg
- Nyckel
- kunskap
- känd
- liggande
- större
- slutligen
- Latens
- senare
- senaste
- lager
- leda
- inlärning
- t minst
- hävstångs
- Licens
- begränsning
- Begränsad
- linje
- Lista
- läsa in
- läser in
- lokal
- läge
- Lång
- längre
- Låg
- Maskinen
- maskininlärning
- gjord
- Huvudsida
- göra
- GÖR
- Framställning
- hantera
- hantera
- kartor
- Maj..
- nämnts
- metadata
- metod
- metoder
- Metrics
- kanske
- millisekunder
- minuter
- MIT
- ML
- modell
- modeller
- måttlig
- Ögonblick
- övervakning
- mer
- Filmer
- mycket
- multipel
- måste
- Som heter
- nationell
- National Parker
- nödvändigt för
- Behöver
- behövs
- nät
- neural
- neurala nätverk
- Nästa
- nlp
- Nej
- Notera
- anteckningsbok
- Anmärkningar
- anmälan
- anmälningar
- notera
- nu
- antal
- nummer
- objektet
- objekt
- observera
- of
- erbjudanden
- erbjuda
- Erbjudanden
- tjänsteman
- offline
- on
- gång
- ONE
- endast
- öppen källkod
- fungerar
- Alternativet
- Tillbehör
- or
- beställa
- organisationer
- OS
- Övriga
- annat
- ut
- Översikt
- paket
- paket
- parameter
- parametrar
- parker
- passera
- bana
- utföra
- prestanda
- fas
- rörledning
- svängbara
- placeras
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- snälla du
- poäng
- möjlig
- Inlägg
- potentiell
- förutsägelse
- Förutsägelser
- förhindra
- föregående
- primär
- process
- bearbetade
- bearbetning
- Processorn
- projektet
- ordentligt
- prototyping
- ge
- förutsatt
- ger
- tillhandahålla
- Python
- pytorch
- kvalitet
- område
- realtid
- rike
- erkännande
- rekommenderas
- registreras
- Minskad
- hänvisa
- Oavsett
- relaterad
- meddelanden
- ihåg
- ta bort
- avlägsnar
- Repository
- begära
- förfrågningar
- kräver
- Obligatorisk
- krav
- forskare
- respektive
- respons
- svar
- ansvarig
- resultera
- resulte
- Resultat
- behöll
- omskolning
- avkastning
- sagemaker
- Samma
- Save
- sparade
- sparande
- skalbarhet
- Skala
- skalor
- planerad
- vetenskapsmän
- skript
- skript
- Andra
- sekunder
- §
- segment
- välj
- vald
- väljer
- Serier
- service
- Tjänster
- in
- inställning
- inställningar
- Dela
- hon
- skall
- visade
- Visar
- avstängning
- signifikant
- Enkelt
- förenklar
- Storlek
- storlekar
- Small
- mindre
- So
- Mjukvara
- lösning
- specifik
- specifikt
- specificerade
- tal
- Taligenkänning
- fart
- Spendera
- talat
- starta
- Ange
- state-of-the-art
- Steg
- Steg
- förvaring
- strategier
- senare
- framgångsrik
- sådana
- plötslig
- lämplig
- stödja
- Stödjande
- Stöder
- säker
- uppstår
- System
- bord
- Ta
- tar
- uppgift
- uppgifter
- Teknologi
- än
- den där
- Smakämnen
- Storbritannien
- deras
- Dem
- sedan
- Där.
- därför
- Dessa
- de
- detta
- tre
- tid
- Tidsföljder
- gånger
- till
- verktyg
- brännaren
- trafik
- Tåg
- tränad
- Förvandla
- transformator
- transformatorer
- utlösa
- triggas
- tv
- TV-serier
- två
- Typ
- typiskt
- Uk
- under
- upplåsning
- på
- us
- användning
- Begagnade
- användarvänligt
- användare
- med hjälp av
- verktyg
- utnyttja
- Använda
- Värdefulla
- värde
- variabel
- olika
- Omfattande
- version
- syn
- Röst
- röstkommandon
- volym
- vänta
- vill
- var
- we
- webb
- webbservice
- VÄL
- były
- när
- närhelst
- som
- Viska
- bred
- Brett utbud
- med
- inom
- arbetsflöde
- fungerar
- värt
- skrivning
- dig
- Din
- zephyrnet