Bild av redaktör
Key Takeaways
- t-testet är ett statistiskt test som kan användas för att avgöra om det finns en signifikant skillnad mellan medelvärdet av två oberoende urval av data.
- Vi illustrerar hur ett t-test kan tillämpas med hjälp av irisdatasetet och Pythons Scipy-bibliotek.
t-testet är ett statistiskt test som kan användas för att avgöra om det finns en signifikant skillnad mellan medelvärdet av två oberoende urval av data. I den här handledningen illustrerar vi den mest grundläggande versionen av t-testet, för vilket vi kommer att anta att de två proverna har lika varianser. Andra avancerade versioner av t-testet inkluderar Welchs t-test, som är en anpassning av t-testet, och är mer tillförlitligt när de två stickproven har olika varianser och möjligen olika urvalsstorlekar.
t-statistiken eller t-värdet beräknas enligt följande:
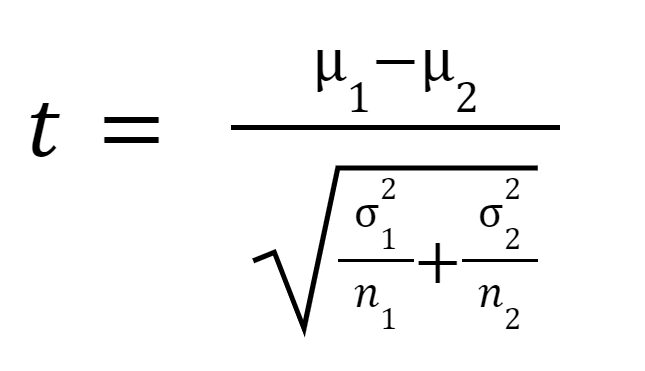
var
är medelvärdet av prov 1,
är medelvärdet av prov 2,
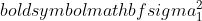 är variansen för prov 1,
är variansen för prov 1, 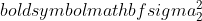 är variansen för prov 2,
är variansen för prov 2, 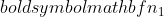 är urvalsstorleken för prov 1, och
är urvalsstorleken för prov 1, och 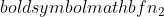 är provstorleken för prov 2.
är provstorleken för prov 2.
För att illustrera användningen av t-testet kommer vi att visa ett enkelt exempel med hjälp av irisdataset. Anta att vi observerar två oberoende prover, t.ex. blombladsbladslängder, och vi överväger om de två proverna togs från samma population (t.ex. samma art av blommor eller två arter med liknande foderbladsegenskaper) eller två olika populationer.
t-testet kvantifierar skillnaden mellan de aritmetiska medelvärdena för de två proverna. P-värdet kvantifierar sannolikheten för att erhålla de observerade resultaten, förutsatt att nollhypotesen (att stickproven är dragna från populationer med samma populationsmedelvärde) är sann. Ett p-värde som är större än ett valt tröskelvärde (t.ex. 5 % eller 0.05) indikerar att vår observation inte är så osannolik att ha skett av en slump. Därför accepterar vi nollhypotesen om lika befolkningsmedel. Om p-värdet är mindre än vårt tröskelvärde, så har vi bevis mot nollhypotesen om lika populationsmedelvärden.
T-testingång
Ingångarna eller parametrarna som krävs för att utföra ett t-test är:
- Två arrayer a och b som innehåller data för prov 1 och prov 2
T-testutgångar
t-testet returnerar följande:
- Den beräknade t-statistiken
- P-värdet
Importera nödvändiga bibliotek
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Ladda Iris Dataset
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
Beräkna urvalets medelvärde och urvalsvarianser
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Genomför t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
Produktion
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
Produktion
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
Produktion
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)Observationer
Vi observerar att användningen av "true" eller "false" för parametern "equal-var" inte förändrar t-testresultaten så mycket. Vi observerar också att utbyte av ordningen på sampelmatriserna a_1 och b_1 ger ett negativt t-testvärde, men ändrar inte storleken på t-testvärdet, som förväntat. Eftersom det beräknade p-värdet är mycket större än tröskelvärdet på 0.05, kan vi förkasta nollhypotesen att skillnaden mellan medelvärdet för prov 1 och prov 2 är signifikant. Detta visar att foderbladslängderna för prov 1 och prov 2 drogs från samma populationsdata.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
Beräkna urvalets medelvärde och urvalsvarianser
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Genomför t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
Produktion
stats.ttest_ind(a_1, b_1, equal_var = False)Observationer
Vi observerar att användning av prover med olika storlek inte förändrar t-statistiken och p-värdet signifikant.
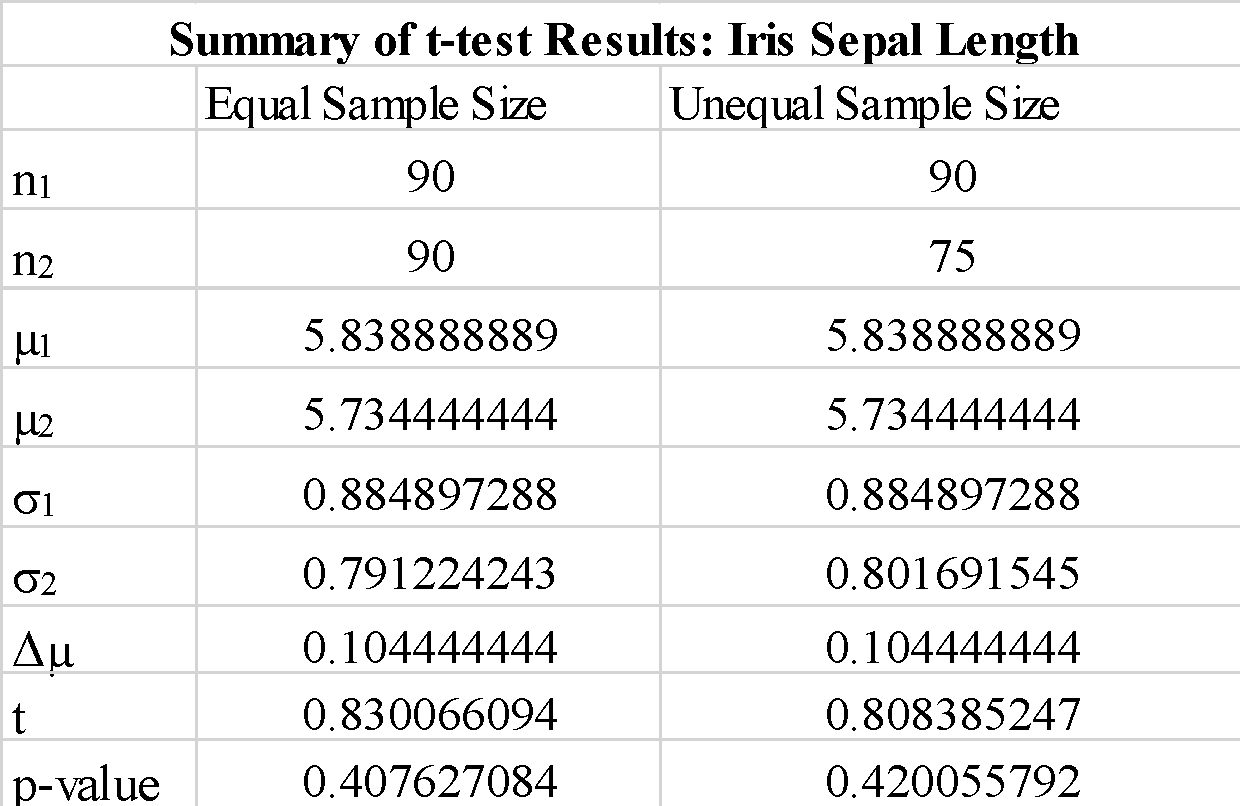
Sammanfattningsvis har vi visat hur ett enkelt t-test kan implementeras med hjälp av scipy-biblioteket i python.
Benjamin O. Tayo är fysiker, utbildare i datavetenskap och författare, samt ägare till DataScienceHub. Tidigare har Benjamin undervisat i teknik och fysik vid U. of Central Oklahoma, Grand Canyon U. och Pittsburgh State U.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- Acceptera
- avancerat
- mot
- och
- tillämpas
- grundläggande
- Benjamin
- mellan
- beräknat
- centrala
- chans
- byta
- egenskaper
- valda
- med tanke på
- kunde
- datum
- datavetenskap
- datauppsättningar
- Bestämma
- Skillnaden
- olika
- dras
- Teknik
- bevis
- exempel
- förväntat
- blomma
- efter
- följer
- från
- Hur ser din drömresa ut
- HTTPS
- genomföras
- importera
- in
- innefattar
- oberoende
- pekar på
- KDnuggets
- större
- Bibliotek
- matplotlib
- betyder
- mer
- mest
- nödvändigt för
- negativ
- numpy
- observera
- erhållande
- inträffade
- Oklahoma
- beställa
- Övriga
- ägaren
- parameter
- parametrar
- utför
- Fysik
- pittsburgh
- plato
- Platon Data Intelligence
- PlatonData
- befolkning
- populationer
- tidigare
- Sannolikheten
- Python
- pålitlig
- Resultat
- återgår
- Samma
- Vetenskap
- show
- visas
- Visar
- signifikant
- signifikant
- liknande
- Enkelt
- eftersom
- Storlek
- storlekar
- mindre
- So
- Ange
- statistisk
- statistik
- SAMMANFATTNING
- Undervisning
- testa
- Smakämnen
- därför
- tröskelvärde
- till
- sann
- handledning
- användning
- värde
- version
- om
- som
- kommer
- författare
- utbyten
- zephyrnet





