Hur ofta når maskininlärningsprojekt framgångsrik implementering? Inte tillräckligt ofta. Det finns gott of industrin forskning visar att ML-projekt vanligtvis misslyckas med att ge avkastning, men värdefulla få har mätt förhållandet mellan misslyckande och framgång ur dataforskarnas perspektiv – de personer som utvecklar just de modeller som dessa projekt är avsedda att distribuera.
Följa upp en dataforskareundersökning som jag dirigerade med KDnuggets förra året, årets branschledande Data Science Survey drivs av ML-konsultföretaget Rexer Analytics tog upp frågan – delvis för att Karl Rexer, företagets grundare och VD, lät er verkligen delta, vilket ledde till att frågor om implementeringsframgång inkluderades (en del av mitt arbete under en ettårig analysprofessur som jag hade vid UVA Darden).
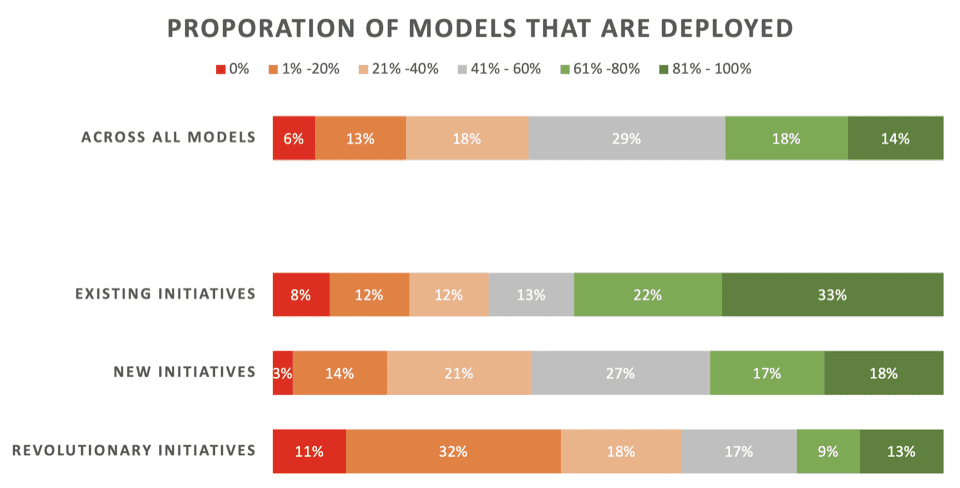
Nyheten är inte bra. Endast 22 % av dataforskarna säger att deras "revolutionära" initiativ – modeller utvecklade för att möjliggöra en ny process eller kapacitet – vanligtvis implementeras. 43 % säger att 80 % eller fler misslyckas med att distribuera.
Tvärs över alla typer av ML-projekt – inklusive uppfriskande modeller för befintliga implementeringar – säger bara 32 % att deras modeller vanligtvis distribueras.
Här är de detaljerade resultaten av den delen av undersökningen, som presenteras av Rexer Analytics, som bryter ned distributionshastigheter över tre typer av ML-initiativ:
Nyckel:
- Befintliga initiativ: Modeller utvecklade för att uppdatera/uppdatera en befintlig modell som redan har implementerats framgångsrikt
- Nya initiativ: Modeller utvecklade för att förbättra en befintlig process för vilken ingen modell redan var utplacerad
- Revolutionära initiativ: Modeller utvecklade för att möjliggöra en ny process eller förmåga
Enligt min åsikt härrör denna kamp för att implementera två huvudsakliga bidragande faktorer: endemisk underplanering och affärsintressenter som saknar konkret synlighet. Många dataproffs och företagsledare har inte insett att ML:s avsedda operationalisering måste planeras i detalj och fullföljas aggressivt från starten av varje ML-projekt.
Jag har faktiskt skrivit en ny bok om just det: The AI Playbook: Mastering the Rare Art of Machine Learning Deployment. I den här boken introducerar jag en implementeringsfokuserad sexstegspraxis för att inleda maskininlärningsprojekt från idé till implementering som jag kallar bizML (förbeställ inbunden eller e-boken och få en gratis avancerad kopia av ljudboksversionen direkt).
Ett ML-projekts nyckelintressenter – den person som är ansvarig för den operativa effektiviteten som är inriktad på förbättring, till exempel en linjechef – behöver insyn i exakt hur ML kommer att förbättra sin verksamhet och hur mycket värde förbättringen förväntas ge. De behöver detta för att i slutändan grönt ljus för en modells utplacering samt för att, innan dess, väga in projektets genomförande under förinstallationsstadierna.
Men ML:s prestation mäts ofta inte! När Rexer-undersökningen frågade: "Hur ofta mäter ditt företag/organisation resultatet av analytiska projekt?" bara 48 % av dataforskarna sa "alltid" eller "för det mesta." Det är ganska vilt. Det borde vara mer som 99% eller 100%.
Och när prestanda mäts är det i termer av tekniska mått som är svårbegripliga och mestadels irrelevanta för affärsintressenter. Dataforskare vet bättre, men håller sig i allmänhet inte – delvis eftersom ML-verktyg i allmänhet bara tjänar tekniska mätvärden. Enligt undersökningen rankar dataforskare affärs-KPI:er som ROI och intäkter som de viktigaste måtten, men de listar tekniska mätvärden som lyft och AUC som de som oftast mäts.
Tekniska prestandamått är "i grunden värdelösa för och bortkopplade från affärsintressenter", enligt Harvard Data Science Review. Här är anledningen: De berättar bara för dig relativ prestanda för en modell, till exempel hur den kan jämföras med gissning eller en annan baslinje. Affärsstatistik säger dig absolut affärsvärde modellen förväntas leverera – eller, vid utvärdering efter implementering, att den har visat sig leverera. Sådana mätvärden är avgörande för implementeringsfokuserade ML-projekt.
Utöver tillgång till affärsmått behöver affärsintressenter också öka. När Rexer-undersökningen frågade: "Är de chefer och beslutsfattare i din organisation som måste godkänna modellimplementering i allmänhet tillräckligt kunniga för att fatta sådana beslut på ett välinformerat sätt?" endast 49 % av de tillfrågade svarade "För det mesta" eller "Alltid."
Här är vad jag tror händer. Dataforskarens "klient", affärsintressenten, får ofta kalla fötter när det kommer till att godkänna driftsättning, eftersom det skulle innebära en betydande operativ förändring av företagets bröd och smör, dess processer i största skala. De har inte den kontextuella ramen. Till exempel undrar de: "Hur ska jag förstå hur mycket den här modellen, som presterar långt borta från perfektion av kristallkulor, faktiskt kommer att hjälpa?" Därmed dör projektet. Att sedan kreativt sätta någon form av positiv snurr på "insikterna" tjänar till att prydligt sopa misslyckandet under mattan. AI-hypen förblir intakt även när det potentiella värdet, syftet med projektet, går förlorat.
Om det här ämnet – att öka intressenterna – ska jag koppla in min nya bok, AI Playbook, bara en gång till. Samtidigt som boken täcker bizML-praxis, utvecklar boken också affärspersonal genom att leverera en viktig men ändå vänlig dos av semi-teknisk bakgrundskunskap som alla intressenter behöver för att leda eller delta i maskininlärningsprojekt, från början till slut. Detta sätter affärs- och dataproffs på samma sida så att de kan samarbeta djupt och gemensamt etablera exakt vilken maskininlärning krävs för att förutsäga, hur väl den förutsäger och hur dess förutsägelser agerar för att förbättra verksamheten. Dessa väsentligheter skapar eller bryter varje initiativ – att få dem rätt banar väg för maskininlärnings värdedrivna implementering.
Det är säkert att säga att det är stenigt där ute, särskilt för nya, första försöks ML-initiativ. Eftersom själva kraften i AI-hypen förlorar sin förmåga att ständigt kompensera för
mindre realiserat värde än utlovat, kommer det att bli mer och mer press för att bevisa ML:s operativa värde.? Så jag säger, gå ur det här nu – börja skapa en mer effektiv kultur av samarbete över företag och implementeringsorienterat projektledarskap!
För mer detaljerade resultat från 2023 Rexer Analytics Data Science Survey, Klicka här.. Detta är den största undersökningen av datavetenskaps- och analytiker inom branschen. Den består av cirka 35 flervalsfrågor och öppna frågor som täcker mycket mer än bara framgångsfrekvenser för implementering – sju allmänna områden inom datautvinningsvetenskap och praktik: (1) Fält och mål, (2) Algoritmer, (3) Modeller, ( 4) Verktyg (använda mjukvarupaket), (5) Teknik, (6) Utmaningar och (7) Framtid. Det utförs som en tjänst (utan företagssponsring) till datavetenskapsgemenskapen, och resultaten tillkännages vanligtvis kl. konferensen Machine Learning Week och delas via fritt tillgängliga sammanfattande rapporter.
Den här artikeln är en produkt av författarens arbete medan han hade en ettårig position som kroppslig Bicentennial Professor i Analytics vid UVA Darden School of Business, vilket slutligen kulminerade med publiceringen av The AI Playbook: Mastering the Rare Art of Machine Learning Deployment (gratis ljudbokserbjudande).
Eric Siegel, Ph.D., är en ledande konsult och före detta professor vid Columbia University som gör maskininlärning begriplig och fängslande. Han är grundaren av Predictive Analytics World och Deep Learning World konferensserier, som har tjänat mer än 17,000 2009 deltagare sedan XNUMX, instruktören för den hyllade kursen Machine Learning Ledarskap och praktik – End-to-end behärskning, en populär talare som har fått i uppdrag för 100+ keynote-adresser, och verkställande redaktör för Maskininlärningstiderna. Han skrev bästsäljaren Prediktiv analys: Kraften att förutsäga vem som kommer att klicka, köpa, ljuga eller dö, som har använts i kurser vid mer än 35 universitet, och han vann undervisningspriser när han var professor vid Columbia University, där han sjöng pedagogiska sånger till sina elever. Eric publicerar också analyser och social rättvisa. Följ honom kl @predikanalytisk.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/survey-machine-learning-projects-still-routinely-fail-to-deploy?utm_source=rss&utm_medium=rss&utm_campaign=survey-machine-learning-projects-still-routinely-fail-to-deploy
- : har
- :är
- :inte
- :var
- $UPP
- 000
- 1
- 17
- 35%
- 7
- a
- förmåga
- Om Oss
- tillgång
- uppmärksammad
- Enligt
- tvärs
- faktiskt
- adresserad
- avancerat
- Efter
- aggressivt
- framåt
- AI
- algoritmer
- Alla
- tillåts
- redan
- också
- alltid
- am
- an
- Analytisk
- analytics
- och
- meddelade
- Annan
- godkänna
- cirka
- Arcane
- ÄR
- områden
- Konst
- Artikeln
- AS
- At
- deltagare
- ingen
- författat
- tillgänglig
- Utmärkelser
- bort
- bakgrund
- Baslinje
- BE
- därför att
- varit
- innan
- tro
- bästsäljare
- Bättre
- boken
- Bröd
- Ha sönder
- Breaking
- företag
- Företagsledare
- men
- Köp
- by
- Ring
- kallas
- KAN
- kapacitet
- fängslande
- utmaningar
- byta
- laddning
- val
- klick
- klient
- förkylning
- samarbeta
- samverkan
- Columbia
- COM
- komma
- kommer
- vanligen
- samfundet
- företag
- Företagets
- befruktning
- betong
- genomfördes
- Konferens
- består
- konsult
- konsult
- kontextuella
- kontinuerligt
- Bidragande
- Företag
- Naturligtvis
- kurser
- täcka
- beläggning
- Kreativt
- cs
- kultur
- datum
- data mining
- datavetenskap
- datavetare
- beslutsfattare
- beslut
- djupt
- leverera
- leverera
- distribuera
- utplacerade
- utplacering
- distributioner
- detalj
- detaljerad
- utveckla
- utvecklade
- bortkopplad
- do
- gör
- donation
- inte
- dos
- ner
- drivande
- under
- varje
- redaktör
- Effektiv
- effektivitet
- möjliggöra
- änden
- början till slut
- endemisk
- förbättra
- tillräckligt
- eric
- speciellt
- väsentlig
- Essentials
- upprättandet
- Eter (ETH)
- utvärdering
- Även
- Varje
- exempel
- utförande
- verkställande
- befintliga
- förväntat
- Faktum
- faktorer
- MISSLYCKAS
- Misslyckande
- långt
- fot
- få
- fält
- följer
- För
- kraft
- Tidigare
- grundare
- Ramverk
- Fri
- fritt
- vänliga
- från
- framtida
- vunnits
- Allmänt
- allmänhet
- skaffa sig
- få
- Mål
- stor
- Happening
- Har
- he
- Held
- hjälpa
- honom
- hans
- Hur ser din drömresa ut
- html
- http
- HTTPS
- Hype
- i
- IBM
- med Esport
- förbättra
- förbättring
- in
- början
- Inklusive
- integration
- industrin
- branschledande
- Initiativ
- initiativ
- insikter
- avsedd
- in
- införa
- isn
- IT
- DESS
- bara
- bara en
- karl
- KDnuggets
- Nyckel
- Keynote
- Snäll
- Vet
- kunskap
- saknas
- största
- Efternamn
- Förra året
- leda
- ledare
- Ledarskap
- ledande
- inlärning
- lie
- tycka om
- Lista
- ll
- förlorar
- förlorat
- Maskinen
- maskininlärning
- Huvudsida
- göra
- GÖR
- Framställning
- chef
- chefer
- sätt
- många
- Mastering
- betyda
- menas
- mäta
- mätt
- Metrics
- Gruvdrift
- MIT
- ML
- modell
- modeller
- mer
- mest
- för det mesta
- mycket
- multipel
- måste
- my
- Behöver
- behov
- Nya
- nyheter
- Nej
- nu
- of
- Ofta
- on
- ONE
- ettor
- endast
- operativa
- Verksamhet
- or
- beställa
- organisation
- ut
- paket
- sida
- del
- delta
- vrak
- perfektion
- prestanda
- utför
- personen
- perspektiv
- planeras
- plato
- Platon Data Intelligence
- PlatonData
- kontakt
- Populära
- placera
- positiv
- potentiell
- kraft
- praktiken
- pre-order
- Dyrbar
- exakt
- förutse
- Förutsägelser
- Förutspår
- presenteras
- VD
- tryck
- pretty
- process
- processer
- Produkt
- yrkesmän/kvinnor
- Professor
- projektet
- projekt
- utlovade
- Bevisa
- beprövade
- Offentliggörande
- publicerar
- Syftet
- Puts
- sätta
- fråga
- frågor
- Ramp
- rampning
- rangordna
- SÄLLSYNT
- rates
- ratio
- nå
- insåg
- känner igen
- resterna
- Rapport
- svarande
- Resultat
- återgår
- intäkter
- revolutionerande
- höger
- stenig
- ROI
- rutinmässigt
- Körning
- s
- säker
- Nämnda
- Samma
- säga
- Skala
- Skola
- Vetenskap
- Forskare
- vetenskapsmän
- Serier
- tjänar
- eras
- serverar
- service
- sju
- delas
- signifikant
- eftersom
- So
- Social hållbarhet
- Mjukvara
- några
- Högtalare
- Snurra
- sponsorskap
- stadier
- intressenter
- intressenter
- starta
- stjälkar
- Fortfarande
- Kamp
- Studenter
- framgång
- framgångsrik
- Framgångsrikt
- sådana
- SAMMANFATTNING
- Undersökning
- Sweep
- T
- riktade
- Undervisning
- Teknisk
- Teknologi
- tala
- villkor
- än
- den där
- Smakämnen
- deras
- Dem
- sedan
- Där.
- Dessa
- de
- detta
- tre
- hela
- Således
- tid
- till
- verktyg
- ämne
- verkligen
- två
- Ytterst
- under
- förstå
- förståeligt
- Universitet
- universitet
- på
- Begagnade
- inledande
- vanligen
- värde
- Ve
- mycket
- via
- utsikt
- synlighet
- avgörande
- var
- Sätt..
- vecka
- väga
- VÄL
- Vad
- när
- som
- medan
- VEM
- varför
- Vild
- kommer
- med
- utan
- Vann
- undrar
- Arbete
- skulle
- skriven
- år
- ännu
- dig
- Din
- zephyrnet