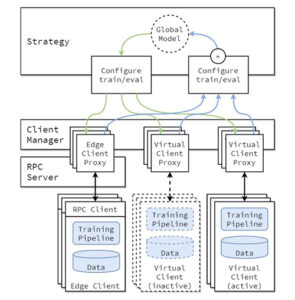
I första delen i den här tredelade serien presenterade vi en lösning som visar hur du kan automatisera upptäckt av dokumentmanipulering och bedrägerier i stor skala med hjälp av AWS AI och maskininlärningstjänster (ML) för ett användningsfall för hypoteksgarantier.
I det här inlägget presenterar vi ett tillvägagångssätt för att utveckla en djupinlärningsbaserad datorseendemodell för att upptäcka och lyfta fram förfalskade bilder i hypoteksgarantier. Vi ger vägledning om att bygga, träna och distribuera nätverk för djupinlärning Amazon SageMaker.
I del 3 visar vi hur man implementerar lösningen på Amazon bedrägeri detektor.
Lösningsöversikt
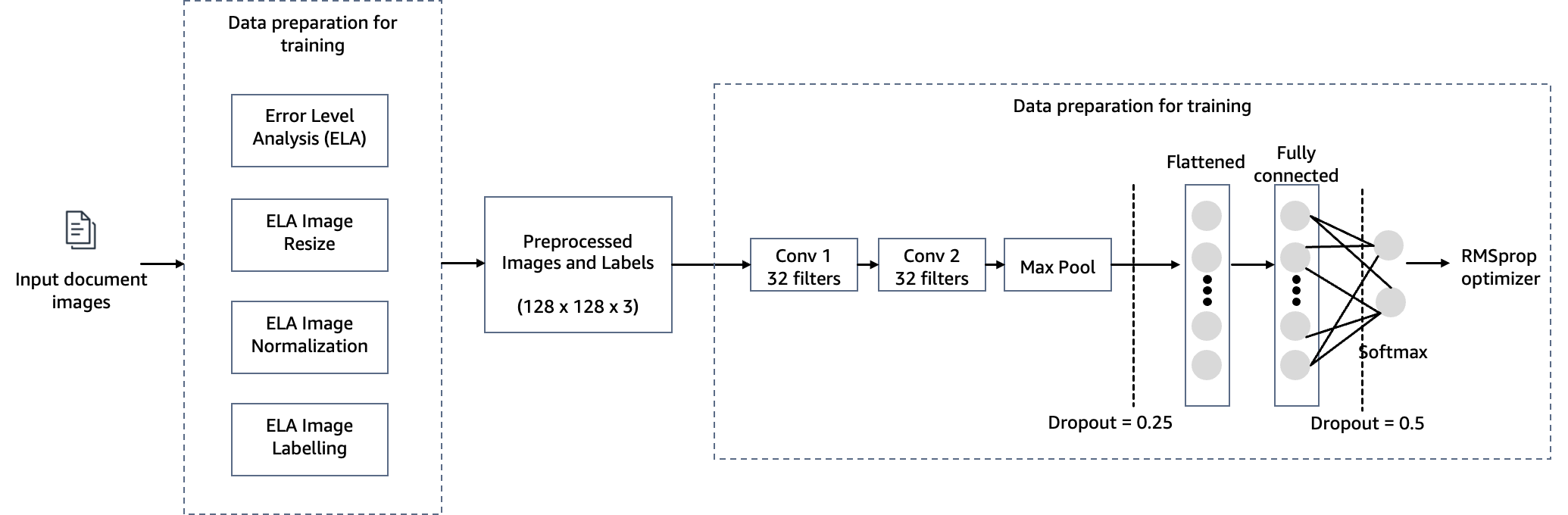
För att möta målet att upptäcka dokumentmanipulering vid hypoteksgarantier använder vi en datorseendemodell som finns på SageMaker för vår lösning för upptäckt av bildförfalskning. Denna modell tar emot en testbild som indata och genererar en sannolikhetsförutsägelse av förfalskning som dess utdata. Nätverksarkitekturen är den som visas i följande diagram.
Bildförfalskning involverar huvudsakligen fyra tekniker: skarvning, kopiering-flyttning, borttagning och förbättring. Beroende på förfalskningens egenskaper kan olika ledtrådar användas som grund för upptäckt och lokalisering. Dessa ledtrådar inkluderar JPEG-komprimeringsartefakter, kantinkonsekvenser, brusmönster, färgkonsistens, visuell likhet, EXIF-konsistens och kameramodell.
Med tanke på det expansiva området för upptäckt av bildförfalskning använder vi algoritmen Error Level Analysis (ELA) som en illustrativ metod för att upptäcka förfalskningar. Vi valde ELA-tekniken för det här inlägget av följande skäl:
- Det går snabbare att implementera och kan lätt fånga manipulering av bilder.
- Det fungerar genom att analysera komprimeringsnivåerna för olika delar av en bild. Detta gör att den kan upptäcka inkonsekvenser som kan tyda på manipulering – till exempel om ett område kopierades och klistrades in från en annan bild som hade sparats på en annan komprimeringsnivå.
- Det är bra på att upptäcka mer subtila eller sömlösa manipulationer som kan vara svåra att upptäcka med blotta ögat. Även små förändringar i en bild kan introducera detekterbara komprimeringsavvikelser.
- Det är inte beroende av att ha den ursprungliga omodifierade bilden för jämförelse. ELA kan identifiera manipuleringstecken endast i den ifrågasatta bilden själv. Andra tekniker kräver ofta det omodifierade originalet att jämföra med.
- Det är en lättviktsteknik som bara bygger på att analysera kompressionsartefakter i digital bilddata. Det beror inte på specialiserad hårdvara eller kriminalteknisk expertis. Detta gör ELA tillgängligt som ett förstapassanalysverktyg.
- Den utgående ELA-bilden kan tydligt markera skillnader i komprimeringsnivåer, vilket gör manipulerade områden synliga. Detta gör att även en icke-expert kan känna igen tecken på möjlig manipulation.
- Det fungerar på många bildtyper (som JPEG, PNG och GIF) och kräver att bara bilden själv analyseras. Andra kriminaltekniska tekniker kan vara mer begränsade vad gäller format eller originalbildskrav.
Men i verkliga scenarier där du kan ha en kombination av indatadokument (JPEG, PNG, GIF, TIFF, PDF), rekommenderar vi att du använder ELA i kombination med olika andra metoder, som t.ex. upptäcka inkonsekvenser i kanter, brusmönster, färglikformighet, EXIF-datakonsistens, identifiering av kameramodelloch enhetlig typsnitt. Vi strävar efter att uppdatera koden för det här inlägget med ytterligare förfalskningsdetekteringstekniker.
ELA:s underliggande utgångspunkt förutsätter att ingångsbilderna är i JPEG-format, känt för sin förlustbringande komprimering. Ändå kan metoden fortfarande vara effektiv även om de ingående bilderna ursprungligen var i ett förlustfritt format (som PNG, GIF eller BMP) och senare konverterades till JPEG under manipuleringsprocessen. När ELA tillämpas på ursprungliga förlustfria format indikerar det vanligtvis konsekvent bildkvalitet utan försämring, vilket gör det svårt att lokalisera ändrade områden. I JPEG-bilder är den förväntade normen att hela bilden ska uppvisa liknande komprimeringsnivåer. Men om ett visst avsnitt i bilden visar en markant annorlunda felnivå, tyder det ofta på att en digital ändring har gjorts.
ELA belyser skillnader i JPEG-komprimeringshastigheten. Regioner med enhetlig färg kommer sannolikt att ha ett lägre ELA-resultat (till exempel en mörkare färg jämfört med kanter med hög kontrast). De saker att leta efter för att identifiera manipulering eller modifiering inkluderar följande:
- Liknande kanter bör ha liknande ljusstyrka i ELA-resultatet. Alla kanter med hög kontrast ska se likadana ut, och alla kanter med låg kontrast ska se likadana ut. Med ett originalfoto bör kanter med låg kontrast vara nästan lika ljusa som kanter med hög kontrast.
- Liknande texturer bör ha liknande färg under ELA. Områden med fler ytdetaljer, som en närbild av en basketboll, kommer sannolikt att ha ett högre ELA-resultat än en slät yta.
- Oavsett ytans faktiska färg bör alla plana ytor ha ungefär samma färg enligt ELA.
JPEG-bilder använder ett komprimeringssystem med förlust. Varje omkodning (resave) av bilden ger mer kvalitetsförlust till bilden. Närmare bestämt arbetar JPEG-algoritmen på ett rutnät på 8×8 pixlar. Varje 8×8 kvadrat komprimeras oberoende av varandra. Om bilden är helt omodifierad bör alla 8×8 rutor ha liknande felpotentialer. Om bilden är oförändrad och sparad på nytt, bör varje ruta försämras med ungefär samma hastighet.
ELA sparar bilden med en angiven JPEG-kvalitetsnivå. Denna återlagring introducerar ett känt antal fel över hela bilden. Den återsparade bilden jämförs sedan med originalbilden. Om en bild modifieras bör varje 8×8 kvadrat som berördes av modifieringen ha en högre felpotential än resten av bilden.
Resultaten från ELA är direkt beroende av bildkvaliteten. Du kanske vill veta om något har lagts till, men om bilden kopieras flera gånger, kan ELA endast tillåta att återlagringar upptäcks. Försök att hitta den bästa kvalitetsversionen av bilden.
Med träning och övning kan ELA också lära sig att identifiera bildskalning, kvalitet, beskärning och återspara transformationer. Till exempel, om en icke-JPEG-bild innehåller synliga rutnätslinjer (1 pixel breda i 8×8 rutor), betyder det att bilden började som en JPEG och konverterades till icke-JPEG-format (som PNG). Om vissa områden av bilden saknar rutnätslinjer eller om rutnätslinjerna förskjuts, anger det en skarvning eller en ritad del i icke-JPEG-bilden.
I följande avsnitt visar vi stegen för att konfigurera, träna och distribuera datorseendemodellen.
Förutsättningar
För att följa det här inlägget, fyll i följande förutsättningar:
- Ha ett AWS-konto.
- Montera myggnät för luckor Amazon SageMaker Studio. Du kan snabbt initiera SageMaker Studio med standardförinställningar, vilket underlättar en snabb start. För mer information, se Amazon SageMaker förenklar Amazon SageMaker Studio-installationen för enskilda användare.
- Öppna SageMaker Studio och starta en systemterminal.
- Kör följande kommando i terminalen:
git clone https://github.com/aws-samples/document-tampering-detection.git - Den totala kostnaden för att köra SageMaker Studio för en användare och konfigurationerna av notebookmiljön är $7.314 USD per timme.
Ställ in modellträningsanteckningsboken
Utför följande steg för att ställa in din tränings-anteckningsbok:
- Öppna
tampering_detection_training.ipynbfil från katalogen för dokumentmanipulering-detektion. - Ställ in notebookmiljön med bilden TensorFlow 2.6 Python 3.8 CPU eller GPU Optimized.
Du kan stöta på problem med otillräcklig tillgänglighet eller nå kvotgränsen för GPU-instanser i ditt AWS-konto när du väljer GPU-optimerade instanser. För att öka kvoten, besök konsolen Service Quotas och höj servicegränsen för den specifika instanstypen du behöver. Du kan också använda en CPU-optimerad notebook-miljö i sådana fall. - För Kärnaväljer Python3.
- För Instans typväljer ml.m5d.24xlarge eller någon annan stor instans.
Vi valde en större instanstyp för att minska träningstiden för modellen. Med en ml.m5d.24xlarge notebookmiljö är kostnaden per timme 7.258 USD per timme.
Kör träningsanteckningsboken
Kör varje cell i anteckningsboken tampering_detection_training.ipynb i ordning. Vi diskuterar några celler mer i detalj i följande avsnitt.
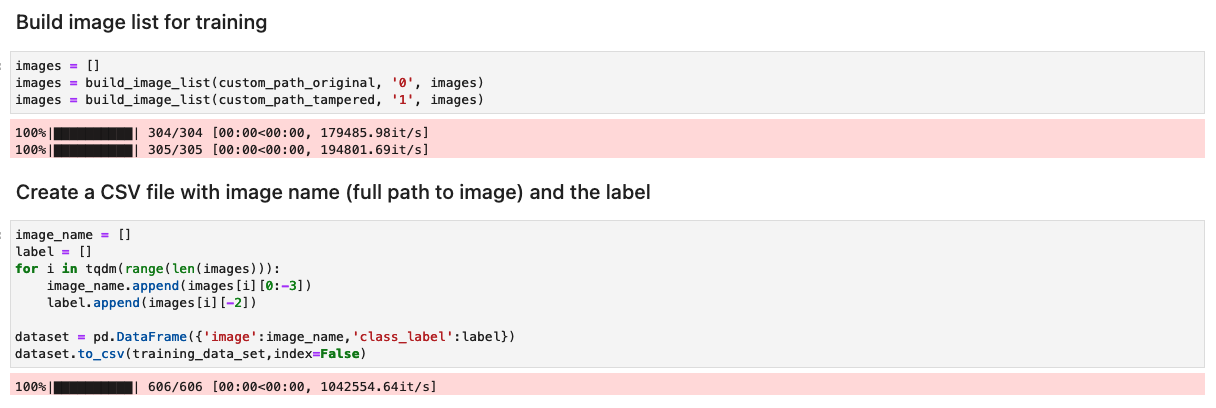
Förbered datasetet med en lista över originalbilder och manipulerade bilder
Innan du kör följande cell i anteckningsboken, förbered en datauppsättning av originaldokument och manipulerade dokument baserat på dina specifika affärskrav. För det här inlägget använder vi en exempeluppsättning av manipulerade lönekort och kontoutdrag. Datauppsättningen är tillgänglig i bildkatalogen för GitHub repository.

Anteckningsboken läser de ursprungliga och manipulerade bilderna från images/training katalog.
Datauppsättningen för träning skapas med en CSV-fil med två kolumner: sökvägen till bildfilen och etiketten för bilden (0 för originalbild och 1 för manipulerad bild).
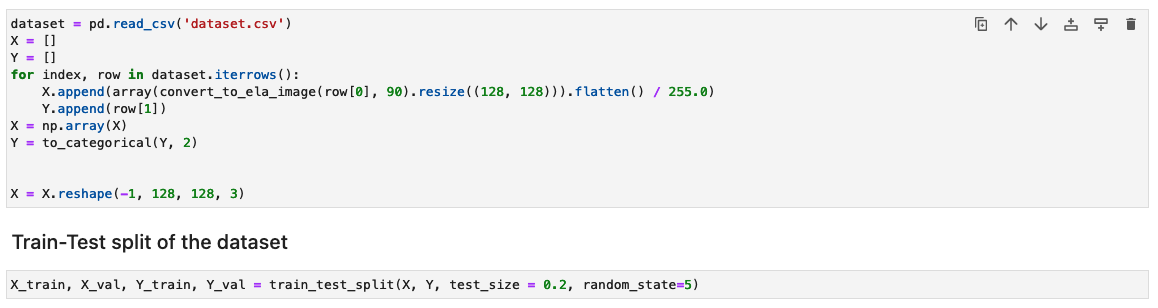
Bearbeta datasetet genom att generera ELA-resultaten för varje träningsbild
I det här steget genererar vi ELA-resultatet (med 90 % kvalitet) av den ingående träningsbilden. Funktionen convert_to_ela_image tar två parametrar: sökväg, som är sökvägen till en bildfil, och kvalitet, som representerar kvalitetsparametern för JPEG-komprimering. Funktionen utför följande steg:
- Konvertera bilden till RGB-format och spara om bilden som en JPEG-fil med angiven kvalitet under namnet tempresaved.jpg.
- Beräkna skillnaden mellan originalbilden och den återsparade JPEG-bilden (ELA) för att bestämma den maximala skillnaden i pixelvärden mellan originalbilden och återlagda bilder.
- Beräkna en skalfaktor baserat på den maximala skillnaden för att justera ljusstyrkan på ELA-bilden.
- Förbättra ljusstyrkan i ELA-bilden med den beräknade skalfaktorn.
- Ändra storlek på ELA-resultatet till 128x128x3, där 3 representerar antalet kanaler för att minska ingångsstorleken för träning.
- Returnera ELA-bilden.
I bildformat med förluster som JPEG leder den initiala lagringsprocessen till avsevärd färgförlust. Men när bilden läses in och sedan kodas om i samma förlustformat blir det i allmänhet mindre färgförsämring. ELA-resultaten betonar de bildområden som är mest mottagliga för färgförsämring vid återlagring. Generellt förekommer förändringar framträdande i regioner som uppvisar högre potential för nedbrytning jämfört med resten av bilden.
Därefter bearbetas bilderna till en NumPy-array för träning. Vi delar sedan upp indatauppsättningen slumpmässigt i tränings- och test- eller valideringsdata (80/20). Du kan ignorera alla varningar när du kör dessa celler.
Beroende på datauppsättningens storlek kan det ta tid att köra dessa celler. Det kan ta 5–10 minuter för provdatauppsättningen som vi tillhandahållit i det här arkivet.
Konfigurera CNN-modellen
I det här steget konstruerar vi en minimal version av VGG-nätverket med små faltningsfilter. VGG-16 består av 13 faltningslager och tre helt sammankopplade lager. Följande skärmdump illustrerar arkitekturen för vår modell för Convolutional Neural Network (CNN).
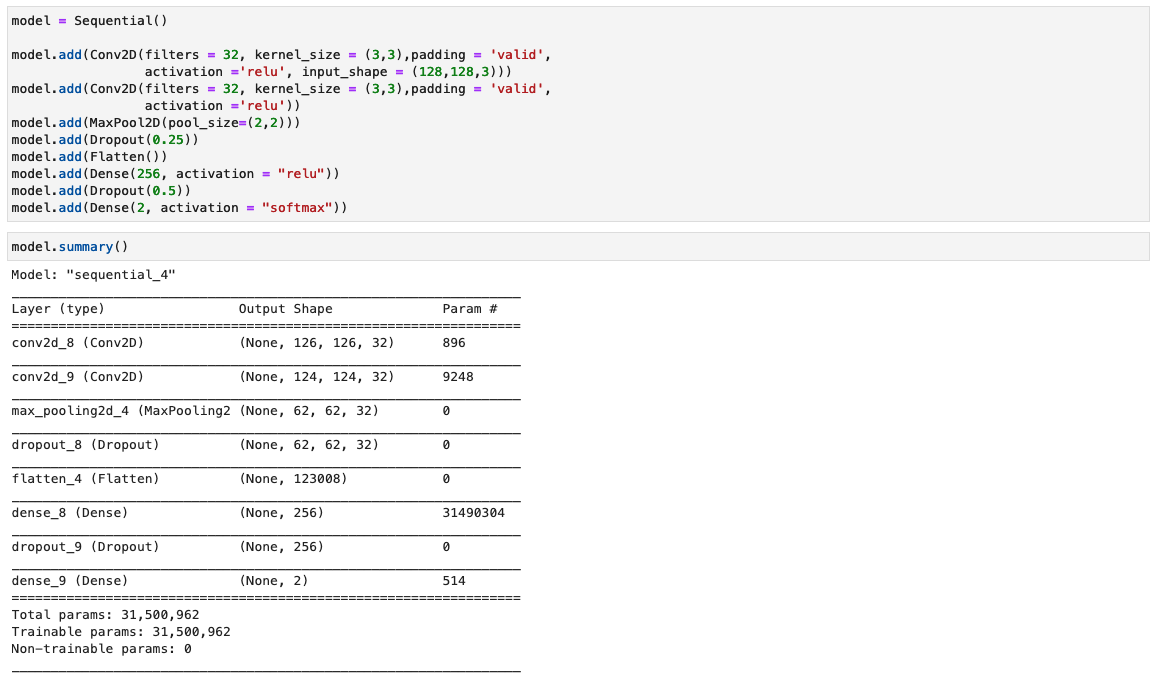
Observera följande konfigurationer:
- Ingång – Modellen tar in en bildinmatningsstorlek på 128x128x3.
- Konventionella lager – De falsade lagren använder ett minimalt receptivt fält (3×3), den minsta möjliga storleken som fortfarande fångar upp/ner och vänster/höger. Detta följs av en korrigerad linjär enhet (ReLU) aktiveringsfunktion som minskar träningstiden. Detta är en linjär funktion som kommer att mata ut ingången om den är positiv; annars är utgången noll. Faltningssteg är fixerat som standard (1 pixel) för att behålla den rumsliga upplösningen efter faltning (steg är antalet pixelskiftningar över inmatningsmatrisen).
- Helt sammankopplade lager – Nätverket har två helt anslutna lager. Det första täta lagret använder ReLU-aktivering och det andra använder softmax för att klassificera bilden som original eller manipulerad.
Du kan ignorera alla varningar när du kör dessa celler.
Spara modellartefakterna
Spara den tränade modellen med ett unikt filnamn – till exempel baserat på aktuellt datum och tid – i en katalog med namnet modell.

Modellen sparas i Keras-format med tillägget .keras. Vi sparar också modellartefakterna som en katalog med namnet 1 som innehåller serialiserade signaturer och tillståndet som behövs för att köra dem, inklusive variabla värden och vokabulärer för att distribuera till en SageMaker-runtime (som vi diskuterar senare i det här inlägget).
Mät modellens prestanda
Följande förlustkurva visar progressionen av modellens förlust över träningsepoker (iterationer).
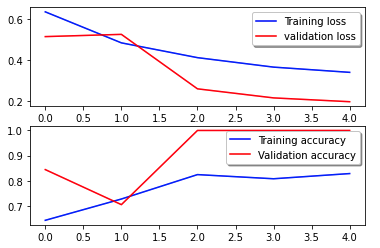
Förlustfunktionen mäter hur väl modellens förutsägelser matchar de faktiska målen. Lägre värden indikerar bättre anpassning mellan förutsägelser och sanna värden. Minskande förlust under epoker betyder att modellen förbättras. Noggrannhetskurvan illustrerar modellens noggrannhet över träningsepoker. Noggrannhet är förhållandet mellan korrekta förutsägelser och det totala antalet förutsägelser. Högre noggrannhet indikerar en bättre presterande modell. Vanligtvis ökar noggrannheten under träning när modellen lär sig mönster och förbättrar sin prediktionsförmåga. Dessa hjälper dig att avgöra om modellen är överanpassad (presterar bra på träningsdata men dåligt på osynliga data) eller underpassar (inte lär sig tillräckligt av träningsdata).
Följande förvirringsmatris representerar visuellt hur väl modellen exakt skiljer mellan den positiva (smidda bilden, representerad som värde 1) och negativ (omanipulerad bild, representerad som värde 0) klasserna.
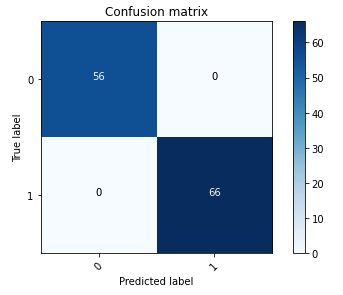
Efter modellutbildningen innebär vårt nästa steg att implementera datorseendemodellen som ett API. Detta API kommer att integreras i affärsapplikationer som en komponent i försäkringsarbetsflödet. För att uppnå detta använder vi Amazon SageMaker Inference, en helt hanterad tjänst. Den här tjänsten integreras sömlöst med MLOps-verktyg, vilket möjliggör skalbar modelldistribution, kostnadseffektiv slutledning, förbättrad modellhantering i produktionen och minskad operationell komplexitet. I det här inlägget distribuerar vi modellen som en slutpunkt i realtid. Det är dock viktigt att notera att, beroende på arbetsflödet för dina affärsapplikationer, kan modellimplementeringen också skräddarsys som batchbearbetning, asynkron hantering eller genom en serverlös implementeringsarkitektur.
Konfigurera anteckningsboken för modelldistribution
Slutför följande steg för att konfigurera din modelldistributionsanteckningsbok:
- Öppna
tampering_detection_model_deploy.ipynbfil från katalogen för dokumentmanipulering-detektion. - Ställ in den bärbara datorns miljö med bilden Data Science 3.0.
- För Kärnaväljer Python3.
- För Instans typväljer ml.t3.medium.
Med en ml.t3.medium notebook-miljö är kostnaden per timme $0.056 USD.
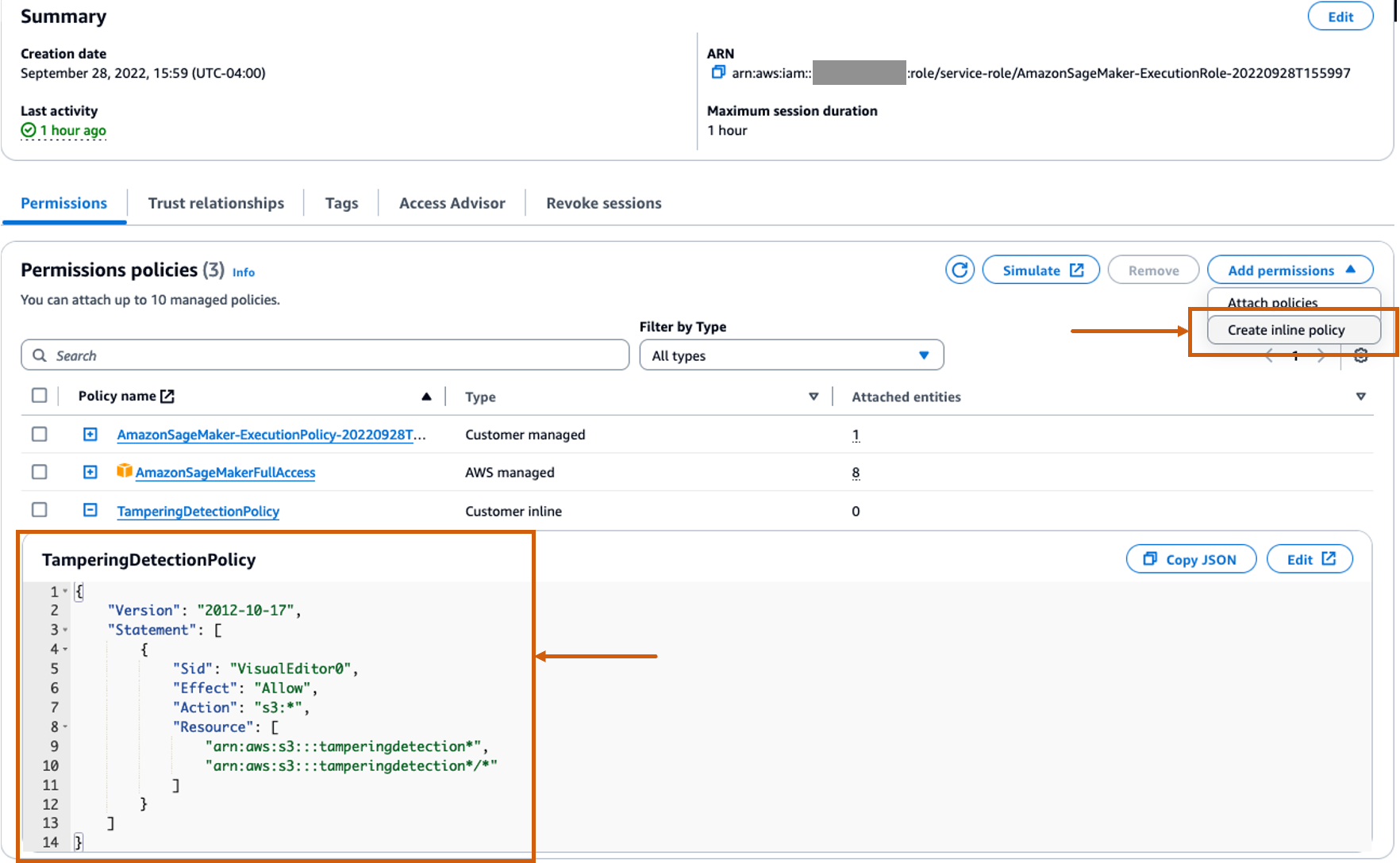
Skapa en anpassad inline-policy för SageMaker-rollen för att tillåta alla Amazon S3-åtgärder
Smakämnen AWS identitets- och åtkomsthantering (IAM) roll för SageMaker kommer att vara i formatet AmazonSageMaker- ExecutionRole-<random numbers>. Se till att du använder rätt roll. Rollnamnet finns under användarinformationen i SageMakers domänkonfigurationer.

Uppdatera IAM-rollen så att den inkluderar en inline-policy som tillåter alla Amazon enkel lagringstjänst (Amazon S3) åtgärder. Detta kommer att krävas för att automatisera skapandet och raderingen av S3-hinkar som lagrar modellartefakterna. Du kan begränsa åtkomsten till specifika S3-hinkar. Observera att vi använde ett jokertecken för S3-segmentets namn i IAM-policyn (tamperingdetection*).
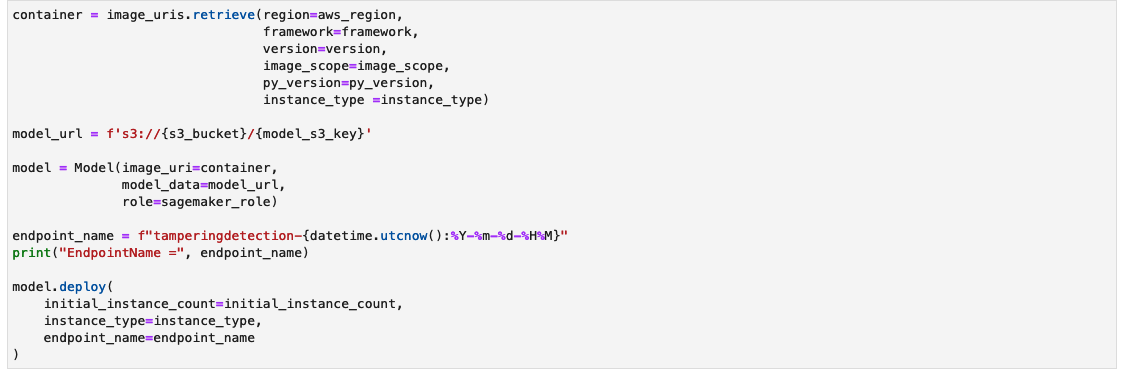
Kör anteckningsboken för distribution
Kör varje cell i anteckningsboken tampering_detection_model_deploy.ipynb i ordning. Vi diskuterar några celler mer i detalj i följande avsnitt.
Skapa en S3-hink
Kör cellen för att skapa en S3-hink. Hinken kommer att få ett namn tamperingdetection<current date time> och i samma AWS-region som din SageMaker Studio-miljö.

Skapa modellartefaktarkivet och ladda upp till Amazon S3
Skapa en tar.gz-fil från modellartefakterna. Vi har sparat modellartefakterna som en katalog med namnet 1, som innehåller serialiserade signaturer och det tillstånd som behövs för att köra dem, inklusive variabla värden och vokabulärer för att distribuera till SageMaker runtime. Du kan också inkludera en anpassad slutledningsfil som heter inference.py i kodmappen i modellartefakten. Den anpassade slutledningen kan användas för förbearbetning och efterbearbetning av inmatningsbilden.
![]()
Skapa en SageMaker slutpunkt slutpunkt
Cellen för att skapa en SageMaker slutpunkt slutpunkt kan ta några minuter att slutföra.
Testa slutpunktens slutpunkt
Funktionen check_image förbehandlar en bild som en ELA-bild, skickar den till en SageMaker-slutpunkt för slutledning, hämtar och bearbetar modellens förutsägelser och skriver ut resultaten. Modellen tar en NumPy-array av ingångsbilden som en ELA-bild för att ge förutsägelser. Förutsägelserna matas ut som 0, som representerar en omanipulerad bild, och 1, som representerar en förfalskad bild.

Låt oss åberopa modellen med en omanipulerad bild av en betalningsstub och kontrollera resultatet.

Modellen matar ut klassificeringen som 0, vilket representerar en omanipulerad bild.
Låt oss nu åberopa modellen med en manipulerad bild av en betalstub och kontrollera resultatet.

Modellen matar ut klassificeringen som 1, vilket representerar en förfalskad bild.
Begränsningar
Även om ELA är ett utmärkt verktyg för att upptäcka ändringar, finns det ett antal begränsningar, till exempel följande:
- En enda pixeländring eller mindre färgjustering kanske inte genererar en märkbar förändring i ELA eftersom JPEG fungerar på ett rutnät.
- ELA identifierar bara vilka regioner som har olika komprimeringsnivåer. Om en bild av lägre kvalitet skarvas till en bild med högre kvalitet, kan bilden med lägre kvalitet visas som ett mörkare område.
- Skala, färga om eller lägga till brus i en bild kommer att modifiera hela bilden, vilket skapar en högre felnivåpotential.
- Om en bild sparas om flera gånger kan den vara helt på en lägsta felnivå, där fler återsparningar inte ändrar bilden. I det här fallet kommer ELA:n att returnera en svart bild och inga ändringar kan identifieras med denna algoritm.
- Med Photoshop kan den enkla handlingen att spara bilden automatiskt skärpa texturer och kanter, vilket skapar en högre felnivåpotential. Denna artefakt identifierar inte avsiktlig modifiering; den identifierar att en Adobe-produkt har använts. Tekniskt sett visas ELA som en ändring eftersom Adobe automatiskt utförde en ändring, men ändringen var inte nödvändigtvis avsiktlig av användaren.
Vi rekommenderar att du använder ELA tillsammans med andra tekniker som tidigare diskuterats i bloggen för att upptäcka ett större antal fall av bildmanipulation. ELA kan också fungera som ett oberoende verktyg för att visuellt undersöka bildskillnader, särskilt när träning av en CNN-baserad modell blir utmanande.
Städa upp
För att ta bort resurserna du skapade som en del av den här lösningen, utför följande steg:
- Kör anteckningsbokens celler under Städa sektion. Detta tar bort följande:
- SageMaker slutpunkt slutpunkt – Slutpunktens namn kommer att vara
tamperingdetection-<datetime>. - Föremål i S3-skopan och själva S3-skopan – Hinkens namn kommer att vara
tamperingdetection<datetime>.
- SageMaker slutpunkt slutpunkt – Slutpunktens namn kommer att vara
- stänga SageMaker Studios anteckningsbokresurser.
Slutsats
I det här inlägget presenterade vi en helhetslösning för att upptäcka dokumentmanipulering och bedrägeri med hjälp av djupinlärning och SageMaker. Vi använde ELA för att förbehandla bilder och identifiera avvikelser i komprimeringsnivåer som kan indikera manipulation. Sedan tränade vi en CNN-modell på denna bearbetade datauppsättning för att klassificera bilder som original eller manipulerade.
Modellen kan uppnå stark prestanda, med en noggrannhet på över 95 % med en datauppsättning (smidd och original) som passar dina affärsbehov. Detta indikerar att det på ett tillförlitligt sätt kan upptäcka förfalskade dokument som lönebesked och kontoutdrag. Den tränade modellen distribueras till en SageMaker-slutpunkt för att möjliggöra slutledning med låg latens i skala. Genom att integrera denna lösning i arbetsflöden för bolån kan institutioner automatiskt flagga misstänkta dokument för ytterligare bedrägeriutredning.
Även om det är kraftfullt, har ELA vissa begränsningar när det gäller att identifiera vissa typer av mer subtil manipulation. Som nästa steg kan modellen förbättras genom att införliva ytterligare kriminaltekniska tekniker i träning och använda större, mer varierande datamängder. Sammantaget visar den här lösningen hur du kan använda djupinlärning och AWS-tjänster för att bygga effektfulla lösningar som ökar effektiviteten, minskar risker och förhindrar bedrägerier.
I del 3 visar vi hur man implementerar lösningen på Amazon Fraud Detector.
Om författarna
 Anup Ravindranath är en Senior Solutions Architect på Amazon Web Services (AWS) baserad i Toronto, Kanada och arbetar med Financial Services-organisationer. Han hjälper kunder att förändra sina verksamheter och förnya sig i molnet.
Anup Ravindranath är en Senior Solutions Architect på Amazon Web Services (AWS) baserad i Toronto, Kanada och arbetar med Financial Services-organisationer. Han hjälper kunder att förändra sina verksamheter och förnya sig i molnet.
 Vinnie Saini är Senior Solutions Architect på Amazon Web Services (AWS) baserad i Toronto, Kanada. Hon har hjälpt Financial Services-kunder att förvandla sig till molnet, med AI- och ML-drivna lösningar som ligger på starka grundpelare för Architectural Excellence.
Vinnie Saini är Senior Solutions Architect på Amazon Web Services (AWS) baserad i Toronto, Kanada. Hon har hjälpt Financial Services-kunder att förvandla sig till molnet, med AI- och ML-drivna lösningar som ligger på starka grundpelare för Architectural Excellence.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/train-and-host-a-computer-vision-model-for-tampering-detection-on-amazon-sagemaker-part-2/
- : har
- :är
- :inte
- :var
- $UPP
- 056
- 1
- 100
- 13
- 195
- 258
- 408
- 75
- 8
- 95%
- a
- förmåga
- Om oss
- tillgång
- tillgänglig
- Konto
- noggrannhet
- exakt
- Uppnå
- tvärs
- Agera
- åtgärder
- aktivering
- faktiska
- lagt till
- tillsats
- Annat
- Lägger
- justera
- Justering
- Adobe
- Efter
- mot
- AI
- Syftet
- algoritm
- uppriktning
- Alla
- tillåter
- tillåter
- nästan
- längs
- vid sidan av
- också
- förändrad
- amason
- Amazon bedrägeri detektor
- Amazon SageMaker
- Amazon SageMaker Studio
- Amazon Web Services
- Amazon Web Services (AWS)
- mängd
- an
- analys
- analysera
- analys
- och
- Annan
- vilken som helst
- api
- visas
- visas
- tillämpningar
- tillämpas
- tillvägagångssätt
- cirka
- arkitektoniska
- arkitektur
- arkiv
- ÄR
- OMRÅDE
- områden
- array
- AS
- antar
- At
- automatisera
- automatiskt
- tillgänglighet
- tillgänglig
- AWS
- Bank
- baserat
- Basketboll
- BE
- därför att
- blir
- varit
- BÄST
- Bättre
- mellan
- Svart
- Blogg
- lyft
- Bright
- SLUTRESULTAT
- Byggnad
- företag
- Business Applications
- företag
- men
- by
- beräknat
- kallas
- rum
- KAN
- Kanada
- fångar
- Vid
- fall
- brottning
- cellen
- Celler
- vissa
- utmanande
- byta
- Förändringar
- kanaler
- egenskaper
- ta
- Välja
- klasser
- klassificering
- klassificera
- klart
- cloud
- CNN
- koda
- färg
- Kolonner
- kombination
- jämföra
- jämfört
- jämförelse
- fullborda
- fullständigt
- Komplexiteten
- komponent
- dator
- Datorsyn
- konfigurering
- förvirring
- förening
- anslutna
- betydande
- konsekvent
- består
- Konsol
- konstruera
- innehåller
- konvertera
- konverterad
- convolutional neuralt nätverk
- korrekt
- Pris
- kunde
- CPU
- skapa
- skapas
- Skapa
- skapande
- Aktuella
- kurva
- beställnings
- Kunder
- mörkare
- datum
- datavetenskap
- datauppsättningar
- Datum
- minskande
- djup
- djupt lärande
- Standard
- demonstrera
- demonstrerar
- betecknar
- tät
- bero
- beroende
- beroende
- distribuera
- utplacerade
- utplacera
- utplacering
- detalj
- detaljer
- upptäcka
- Detektering
- Bestämma
- utveckla
- Diagrammet
- Skillnaden
- skillnader
- olika
- digital
- direkt
- diskutera
- diskuteras
- displayer
- åtskillnad
- flera
- do
- dokumentera
- dokument
- inte
- domän
- dras
- driven
- under
- varje
- lätt
- kant
- Effektiv
- effektivitet
- betona
- utnyttjande
- möjliggöra
- möjliggör
- början till slut
- Slutpunkt
- förbättrad
- förbättring
- tillräckligt
- Hela
- helt
- Miljö
- epoker
- fel
- fel
- speciellt
- Eter (ETH)
- Även
- Varje
- Granskning
- exempel
- Excellence
- utmärkt
- uppvisar
- uppvisar
- expansiv
- förväntat
- expertis
- förlängning
- ögat
- underlättande
- faktor
- få
- fält
- Fil
- filter
- finansiella
- finansiella tjänster
- hitta
- Förnamn
- fixerad
- platta
- följer
- följt
- efter
- För
- Forensic
- kriminalteknik
- smidda
- format
- hittade
- fundament
- foundational
- fyra
- bedrägeri
- från
- fullständigt
- fungera
- ytterligare
- allmänhet
- generera
- genererar
- generera
- gif
- gå
- god
- GPU
- större
- Rutnät
- vägleda
- hade
- Arbetsmiljö
- Hård
- hårdvara
- Har
- har
- he
- hjälpa
- hjälpa
- hjälper
- högre
- Markera
- höjdpunkter
- Träffa
- värd
- värd
- timme
- Hur ser din drömresa ut
- How To
- Men
- html
- http
- HTTPS
- IAM
- identifierade
- identifierar
- identifiera
- identifiera
- Identitet
- IEEE
- if
- ignorera
- illustrerar
- bild
- bilder
- effektfull
- genomföra
- med Esport
- förbättrar
- förbättra
- in
- innefattar
- Inklusive
- inkonsekvenser
- införlivande
- Öka
- Ökar
- oberoende
- oberoende av
- indikerar
- pekar på
- individuellt
- informationen
- inledande
- initiera
- förnya
- ingång
- exempel
- instanser
- institutioner
- integrerade
- integrerar
- Integrera
- Avsiktlig
- in
- införa
- Introducerar
- Undersökningen
- innebär
- fråga
- IT
- iterationer
- DESS
- sig
- jpg
- Ha kvar
- Keras
- Vet
- känd
- etikett
- Brist
- Large
- större
- senare
- lansera
- lager
- skikt
- Leads
- LÄRA SIG
- inlärning
- mindre
- Nivå
- nivåer
- lättvikt
- tycka om
- sannolikhet
- sannolikt
- BEGRÄNSA
- begränsningar
- linjär
- rader
- Lista
- Lokalisering
- se
- förlust
- lägre
- Maskinen
- maskininlärning
- gjord
- huvudsakligen
- göra
- GÖR
- Framställning
- förvaltade
- ledning
- Manipulation
- många
- Match
- Matris
- maximal
- Maj..
- betyder
- åtgärder
- Medium
- Möt
- metod
- metoder
- minimum
- minsta
- mindre
- minuter
- ML
- MLOps
- modell
- modifieringar
- modifierad
- modifiera
- mer
- Inteckning
- mest
- multipel
- namn
- Som heter
- nödvändigtvis
- Behöver
- behövs
- negativ
- nät
- nätverk
- neural
- neurala nätverk
- Icke desto mindre
- Nästa
- Nej
- Brus
- Notera
- anteckningsbok
- antal
- numpy
- mål
- Uppenbara
- of
- Ofta
- on
- ONE
- endast
- fungerar
- operativa
- optimerad
- or
- beställa
- organisationer
- ursprungliga
- ursprungligen
- Övriga
- annat
- vår
- utfall
- produktion
- utgångar
- över
- övergripande
- parameter
- parametrar
- del
- särskilt
- reservdelar till din klassiker
- bana
- mönster
- för
- prestanda
- utfört
- utför
- utför
- bild
- photoshop
- Bild
- pelare
- pixel
- plato
- Platon Data Intelligence
- PlatonData
- komplott
- policy
- del
- positiv
- möjlig
- Inlägg
- potentiell
- potentialer
- den mäktigaste
- praktiken
- förutsägelse
- Förutsägelser
- prediktiva
- Förbered
- förutsättningar
- presentera
- presenteras
- bevarad
- förhindra
- tidigare
- utskrifter
- process
- bearbetade
- processer
- bearbetning
- Produkt
- Produktion
- progression
- ge
- förutsatt
- Python
- kvalitet
- Tillfrågad
- snabbare
- slumpmässig
- område
- snabb
- Betygsätta
- ratio
- verkliga världen
- realtid
- rike
- skäl
- erhåller
- känner igen
- rekommenderar
- likriktad
- minska
- Minskad
- minskar
- hänvisa
- region
- regioner
- återupptagande
- förlita
- avlägsnande
- ta bort
- rendering
- Repository
- representerade
- representerar
- representerar
- kräver
- Obligatorisk
- Krav
- Kräver
- Upplösning
- Resurser
- REST
- begränsad
- resultera
- Resultat
- avkastning
- RGB
- Risk
- Roll
- Körning
- rinnande
- sagemaker
- SageMaker Inference
- Samma
- Exempeldatauppsättning
- Save
- sparade
- sparande
- skalbar
- Skala
- skalning
- scenarier
- Vetenskap
- sömlös
- sömlöst
- Andra
- §
- sektioner
- vald
- väljer
- sänder
- senior
- Serier
- tjänar
- Server
- service
- Tjänster
- in
- inställning
- hon
- skifta
- Skift
- skall
- Visar
- signaturer
- betyder
- Tecken
- liknande
- Enkelt
- förenklar
- enda
- Storlek
- Small
- släta
- lösning
- Lösningar
- några
- något
- rumsliga
- specialiserad
- specifik
- specifikt
- specificerade
- delas
- Spot
- kvadrat
- kvadrater
- igång
- Ange
- uttalanden
- Steg
- Steg
- Fortfarande
- förvaring
- lagra
- steg
- stark
- studio
- Senare
- sådana
- Föreslår
- säker
- yta
- apt
- misstänksam
- snabbt
- system
- skräddarsydd
- Ta
- tar
- mål
- tekniskt
- Tekniken
- tekniker
- tensorflow
- terminal
- testa
- Testning
- än
- den där
- Smakämnen
- Staten
- deras
- Dem
- sedan
- Där.
- Dessa
- saker
- detta
- tre
- Genom
- tid
- gånger
- till
- verktyg
- verktyg
- toronto
- Totalt
- rörd
- Tåg
- tränad
- Utbildning
- Förvandla
- transformationer
- sann
- prova
- två
- Typ
- typer
- typiskt
- under
- underliggande
- writing
- unika
- enhet
- Uppdatering
- på
- USD
- användning
- användningsfall
- Begagnade
- Användare
- användningar
- med hjälp av
- godkännande
- värde
- Värden
- variabel
- olika
- version
- synlig
- syn
- Besök
- visuell
- visuellt
- vill
- var
- we
- webb
- webbservice
- VÄL
- były
- Vad
- när
- som
- bred
- kommer
- med
- inom
- utan
- arbetsflöde
- arbetsflöden
- arbetssätt
- fungerar
- dig
- Din
- zephyrnet
- noll-