Med lanseringen av den neurala sökfunktionen för Amazon OpenSearch Service i OpenSearch 2.9 är det nu enkelt att integrera med AI/ML-modeller för att driva semantisk sökning och andra användningsfall. OpenSearch Service har stött både lexikal och vektorsökning sedan introduktionen av sin k-närmaste granne (k-NN) funktion 2020; Men att konfigurera semantisk sökning krävde att man byggde ett ramverk för att integrera maskininlärningsmodeller (ML) för att inta och söka. Den neurala sökfunktionen underlättar text-till-vektor-transformation under intag och sökning. När du använder en neural fråga under sökning, översätts frågan till en vektorinbäddning och k-NN används för att returnera de närmaste vektorinbäddningarna från korpusen.
För att använda neural sökning måste du ställa in en ML-modell. Vi rekommenderar att du konfigurerar AI/ML-anslutningar till AWS AI- och ML-tjänster (som t.ex Amazon SageMaker or Amazonas berggrund) eller tredjepartsalternativ. Från och med version 2.9 på OpenSearch Service, integreras AI/ML-anslutningar med neural sökning för att förenkla och operationalisera översättningen av din datakorpus och frågor till vektorinbäddningar, och därigenom ta bort mycket av komplexiteten med vektorhydrering och sökning.
I det här inlägget visar vi hur man konfigurerar AI/ML-anslutningar till externa modeller via OpenSearch Service-konsolen.
Lösningsöversikt
Specifikt leder det här inlägget dig genom att ansluta till en modell i SageMaker. Sedan guidar vi dig genom att använda kopplingen för att konfigurera semantisk sökning på OpenSearch Service som ett exempel på ett användningsfall som stöds genom anslutning till en ML-modell. Amazon Bedrock och SageMaker-integrationer stöds för närvarande på OpenSearch Service-konsolens UI, och listan över UI-stödda första- och tredjepartsintegrationer kommer att fortsätta att växa.
För alla modeller som inte stöds via användargränssnittet kan du istället ställa in dem med de tillgängliga API:erna och ML ritningar. För mer information, se Introduktion till OpenSearch-modeller. Du kan hitta ritningar för varje kontakt i ML Commons GitHub-förråd.
Förutsättningar
Innan du ansluter modellen via OpenSearch Service-konsolen, skapa en OpenSearch Service-domän. Karta en AWS identitets- och åtkomsthantering (IAM) roll vid namnet LambdaInvokeOpenSearchMLCommonsRole som backend-rollen på ml_full_access roll med hjälp av säkerhetsplugin på OpenSearch Dashboards, som visas i följande video. OpenSearch Service-integreringsarbetsflödet är förifyllt för att använda LambdaInvokeOpenSearchMLCommonsRole IAM-roll som standard för att skapa kopplingen mellan OpenSearch Service-domänen och modellen som distribueras på SageMaker. Om du använder en anpassad IAM-roll på OpenSearch Service-konsolintegreringarna, se till att den anpassade rollen är mappad som backend-rollen med ml_full_access behörigheter innan mallen distribueras.
Distribuera modellen med AWS CloudFormation
Följande video visar stegen för att använda OpenSearch Service-konsolen för att distribuera en modell inom några minuter på Amazon SageMaker och generera modell-ID via AI-anslutningarna. Det första steget är att välja integrationer i navigeringsrutan på OpenSearch Service AWS-konsolen, som leder till en lista över tillgängliga integrationer. Integrationen ställs in via ett användargränssnitt, som kommer att uppmana dig att ange nödvändiga ingångar.
För att ställa in integrationen behöver du bara tillhandahålla domänändpunkten för OpenSearch Service och ange ett modellnamn för att unikt identifiera modellanslutningen. Som standard använder mallen Hugging Face-satstransformatormodellen, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
När du väljer Skapa stack, dirigeras du till AWS molnformation trösta. CloudFormation-mallen distribuerar arkitekturen som beskrivs i följande diagram.

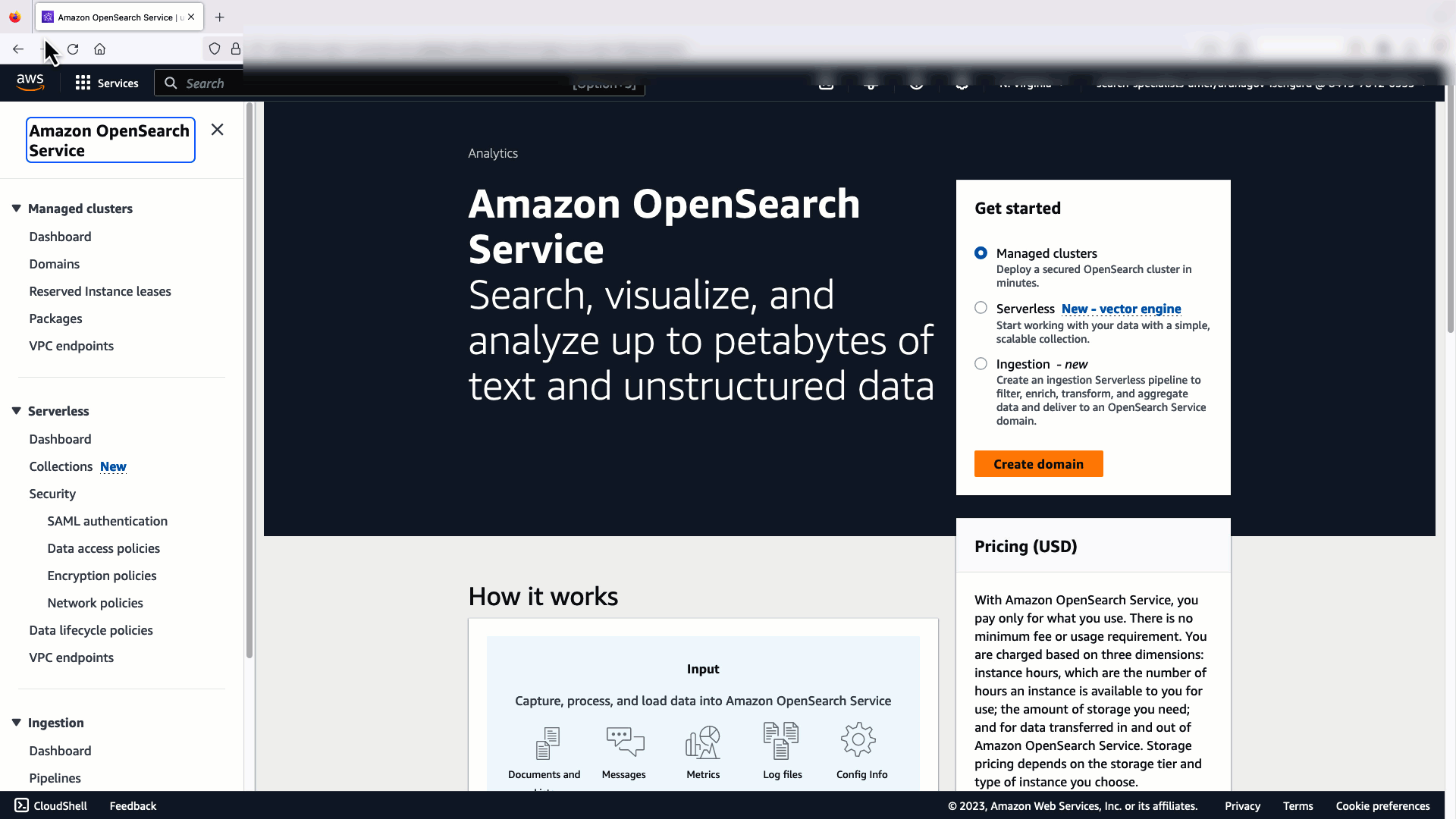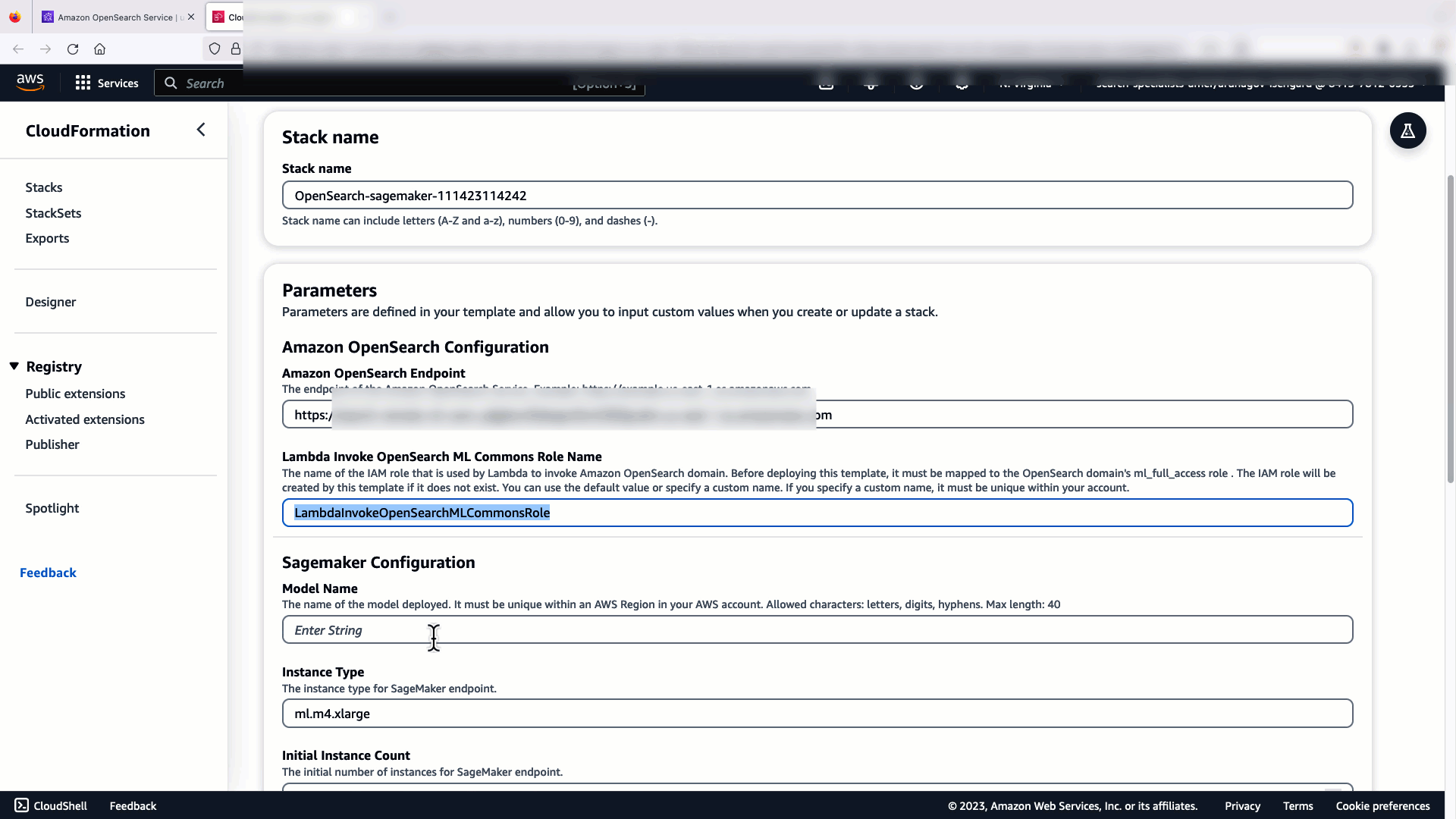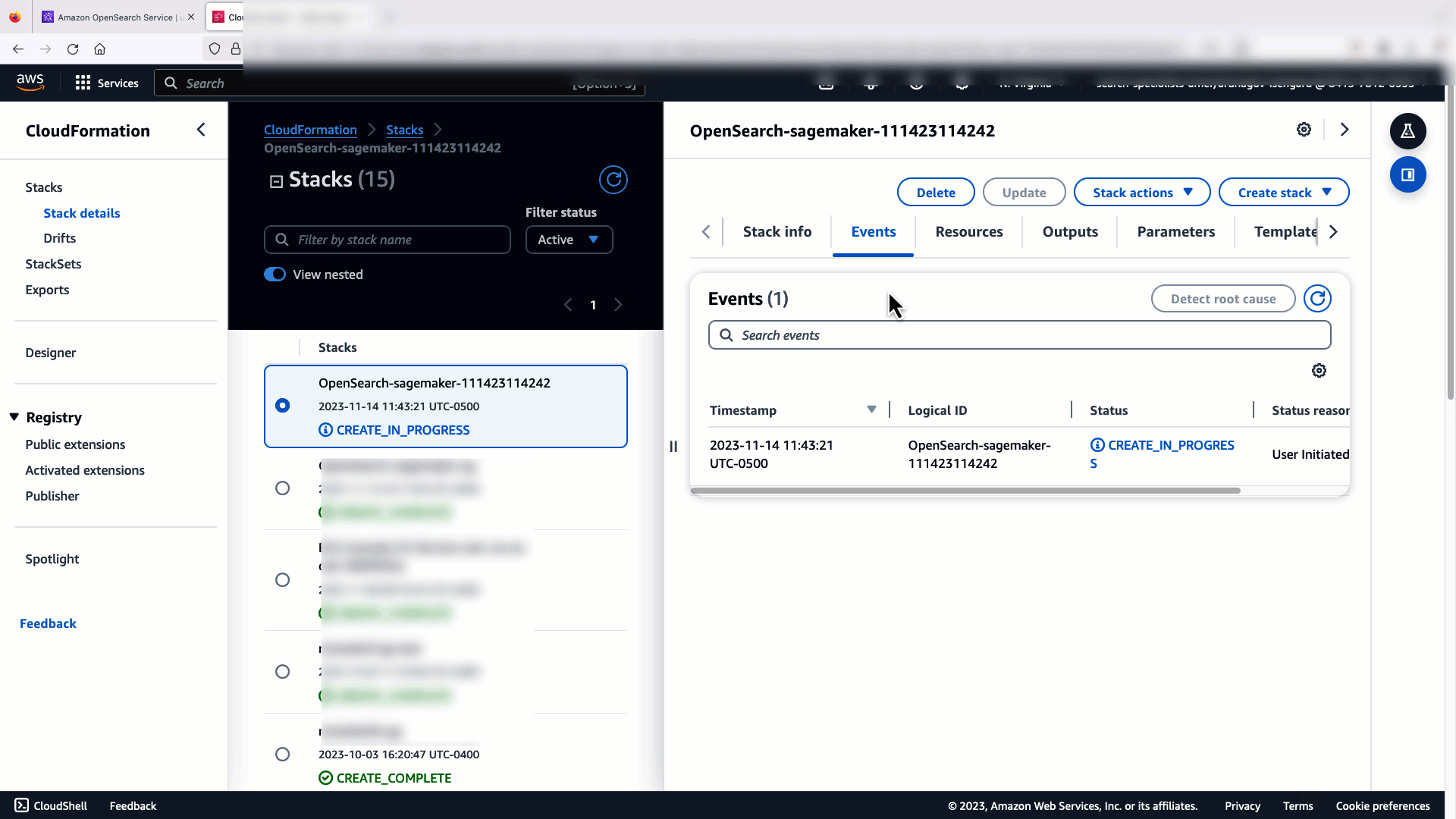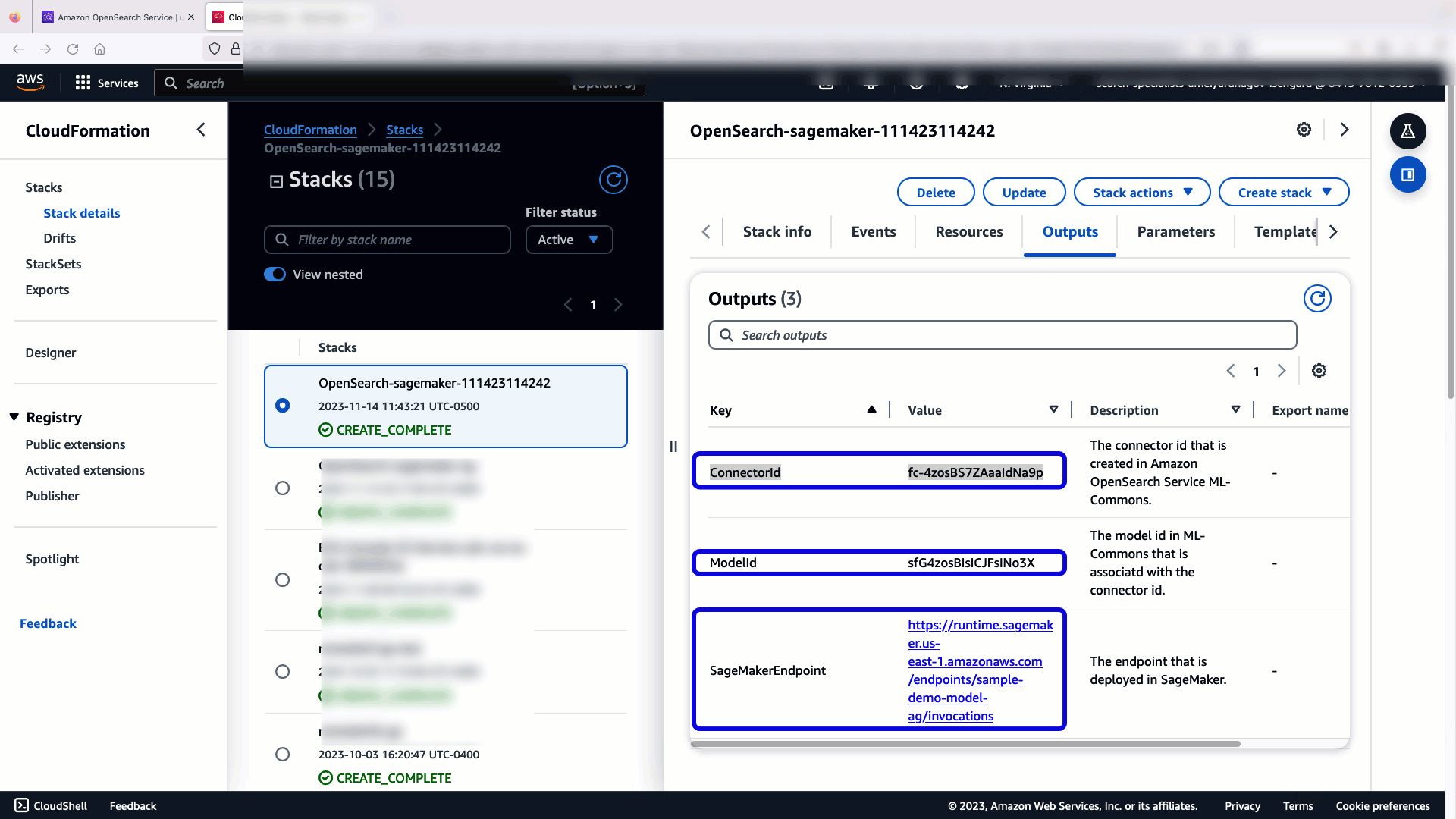
CloudFormation-stacken skapar en AWS Lambda applikation som distribuerar en modell från Amazon enkel lagringstjänst (Amazon S3), skapar kontakten och genererar modell-ID i utgången. Du kan sedan använda detta modell-ID för att skapa ett semantiskt index.
Om standardmodellen för alla MiniLM-L6-v2 inte tjänar ditt syfte kan du distribuera valfri textinbäddningsmodell på den valda modellvärden (SageMaker eller Amazon Bedrock) genom att tillhandahålla dina modellartefakter som ett tillgängligt S3-objekt. Alternativt kan du välja något av följande förutbildade språkmodeller och distribuera den till SageMaker. För instruktioner om hur du ställer in din slutpunkt och dina modeller, se Tillgängliga Amazon SageMaker-bilder.
SageMaker är en helt hanterad tjänst som sammanför en bred uppsättning verktyg för att möjliggöra högpresterande, lågkostnads-ML för alla användningsfall, vilket ger viktiga fördelar som modellövervakning, serverlös värd och arbetsflödesautomatisering för kontinuerlig utbildning och driftsättning. SageMaker låter dig vara värd för och hantera livscykeln för textinbäddningsmodeller och använda dem för att driva semantiska sökfrågor i OpenSearch Service. När SageMaker är ansluten, är SageMaker värd för dina modeller och OpenSearch Service används för att fråga baserat på slutledningsresultat från SageMaker.
Se den distribuerade modellen via OpenSearch Dashboards
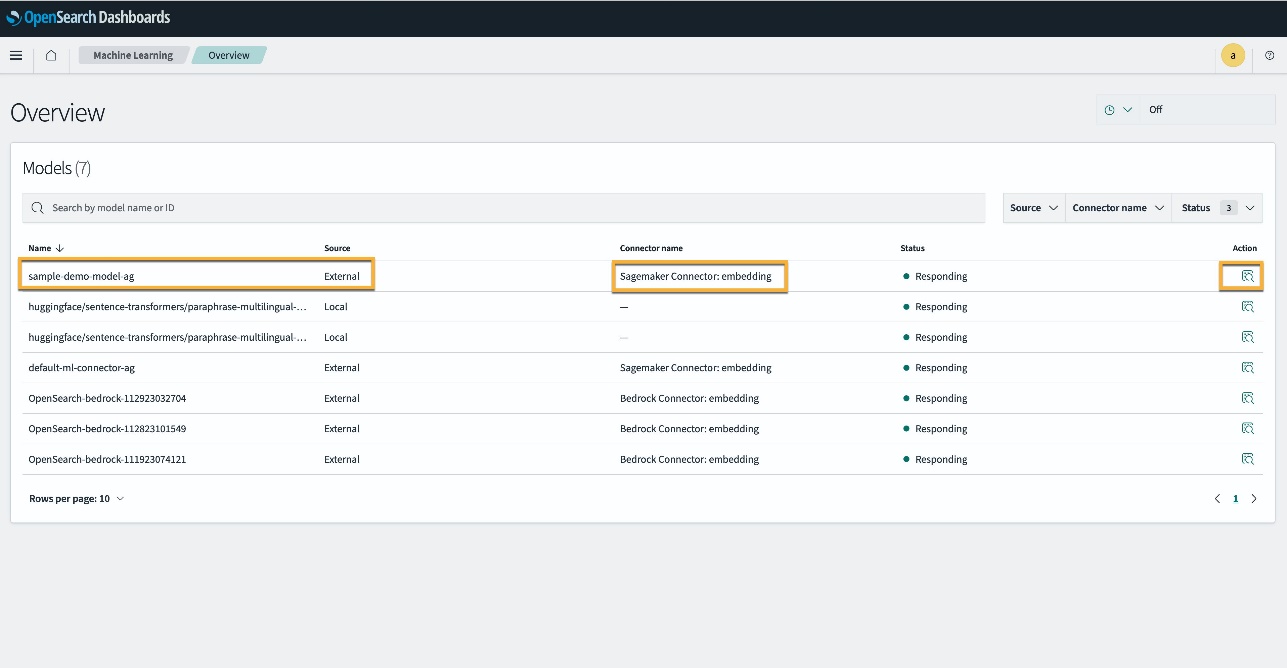
För att verifiera att CloudFormation-mallen har implementerat modellen på OpenSearch Service-domänen och få modell-ID:t kan du använda ML Commons REST GET API genom OpenSearch Dashboards Dev Tools.
GET _plugins REST API tillhandahåller nu ytterligare API:er för att även se modellstatus. Följande kommando låter dig se statusen för en fjärrmodell:
Som visas i följande skärmdump, a DEPLOYED status i svaret indikerar att modellen har implementerats på OpenSearch Service-klustret.

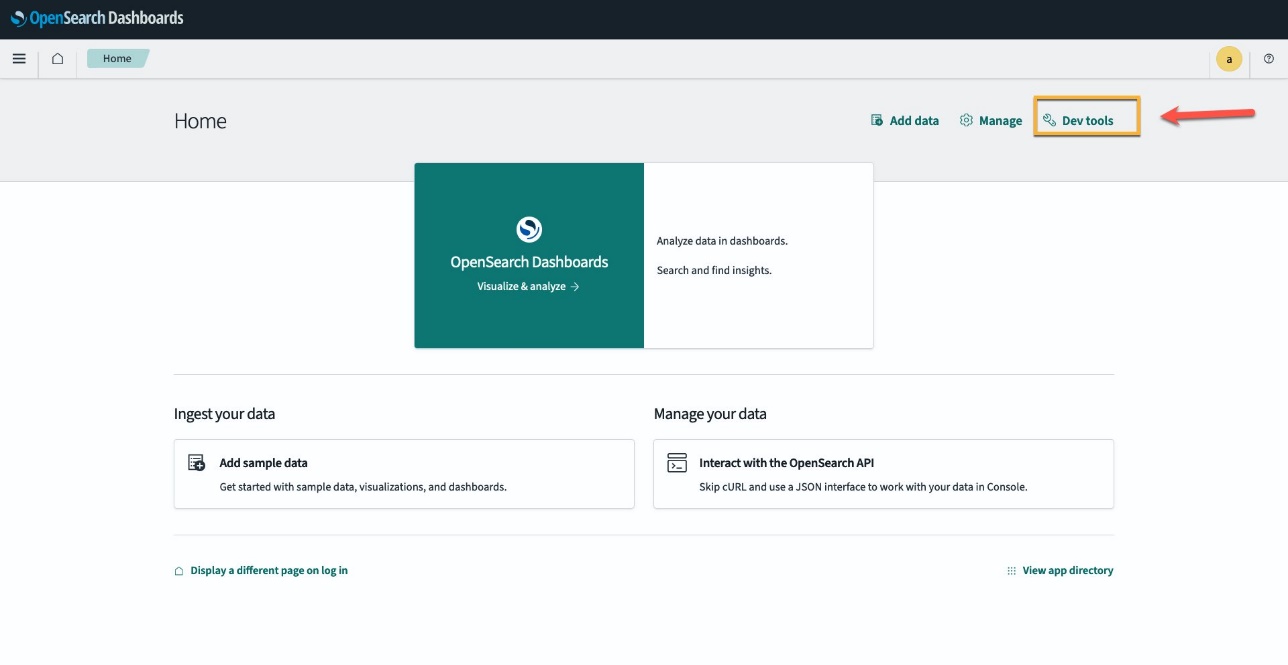
Alternativt kan du se modellen som distribueras på din OpenSearch Service-domän med hjälp av Maskininlärning sida i OpenSearch Dashboards.

Den här sidan listar modellinformationen och statusen för alla utplacerade modeller.

Skapa den neurala pipelinen med hjälp av modell-ID
När modellens status visas som antingen DEPLOYED i Dev Tools eller grön och svara i OpenSearch Dashboards kan du använda modell-ID:t för att bygga din neurala intagspipeline. Följande inmatningspipeline körs i din domäns OpenSearch Dashboards Dev Tools. Se till att du ersätter modell-ID:t med det unika ID som genereras för modellen som distribueras på din domän.

Skapa det semantiska sökindexet med den neurala pipeline som standardpipeline
Du kan nu definiera din indexmappning med standardpipeline konfigurerad för att använda den nya neurala pipeline som du skapade i föregående steg. Se till att vektorfälten deklareras som knn_vector och dimensionerna är lämpliga för modellen som används på SageMaker. Om du har behållit standardkonfigurationen för att distribuera all-MiniLM-L6-v2-modellen på SageMaker, behåll följande inställningar som de är och kör kommandot i Dev Tools.

Ta in exempeldokument för att generera vektorer
För denna demo kan du äta exempel på detaljhandelsdemostore produktkatalog till det nya semantic_demostore index. Ersätt användarnamn, lösenord och domänslutpunkt med din domäninformation och mata in rådata i OpenSearch Service:

Validera det nya semantic_demostore-indexet
Nu när du har matat in din datauppsättning till OpenSearch Service-domänen, verifiera om de nödvändiga vektorerna genereras med en enkel sökning för att hämta alla fält. Validera om fälten definieras som knn_vectors har de nödvändiga vektorerna.

Jämför lexikal sökning och semantisk sökning som drivs av neural sökning med hjälp av verktyget Jämför sökresultat
Smakämnen Verktyget Jämför sökresultat på OpenSearch Dashboards är tillgänglig för produktionsbelastningar. Du kan navigera till Jämför sökresultat sida och jämför frågeresultat mellan lexikal sökning och neural sökning konfigurerad för att använda modell-ID:t som genererats tidigare.

Städa upp
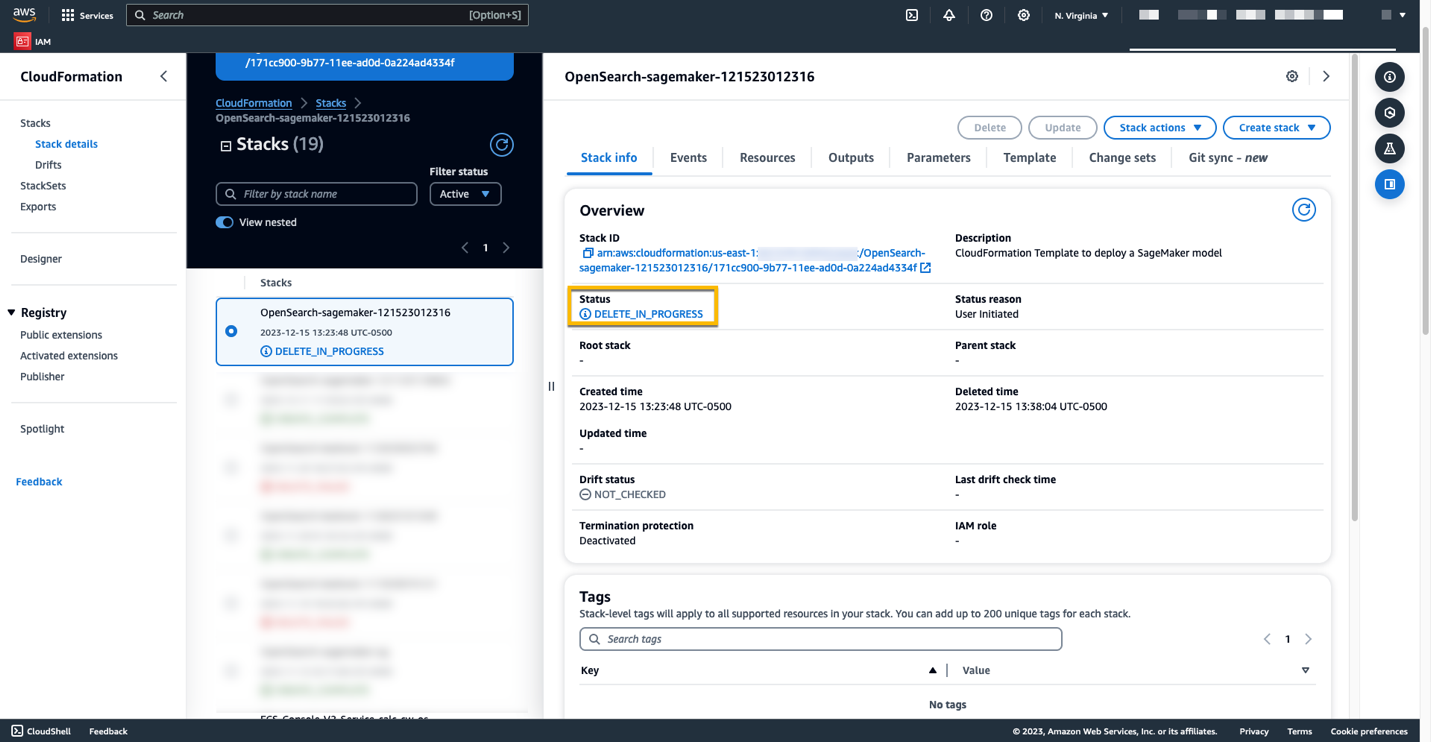
Du kan ta bort resurserna du skapade enligt instruktionerna i det här inlägget genom att ta bort CloudFormation-stacken. Detta kommer att ta bort Lambda-resurserna och S3-skopan som innehåller modellen som distribuerades till SageMaker. Slutför följande steg:
- På AWS CloudFormation-konsolen navigerar du till din stackinformationssida.
- Välja Radera.

- Välja Radera att bekräfta.

Du kan övervaka förloppet för borttagning av stack på AWS CloudFormation-konsolen.
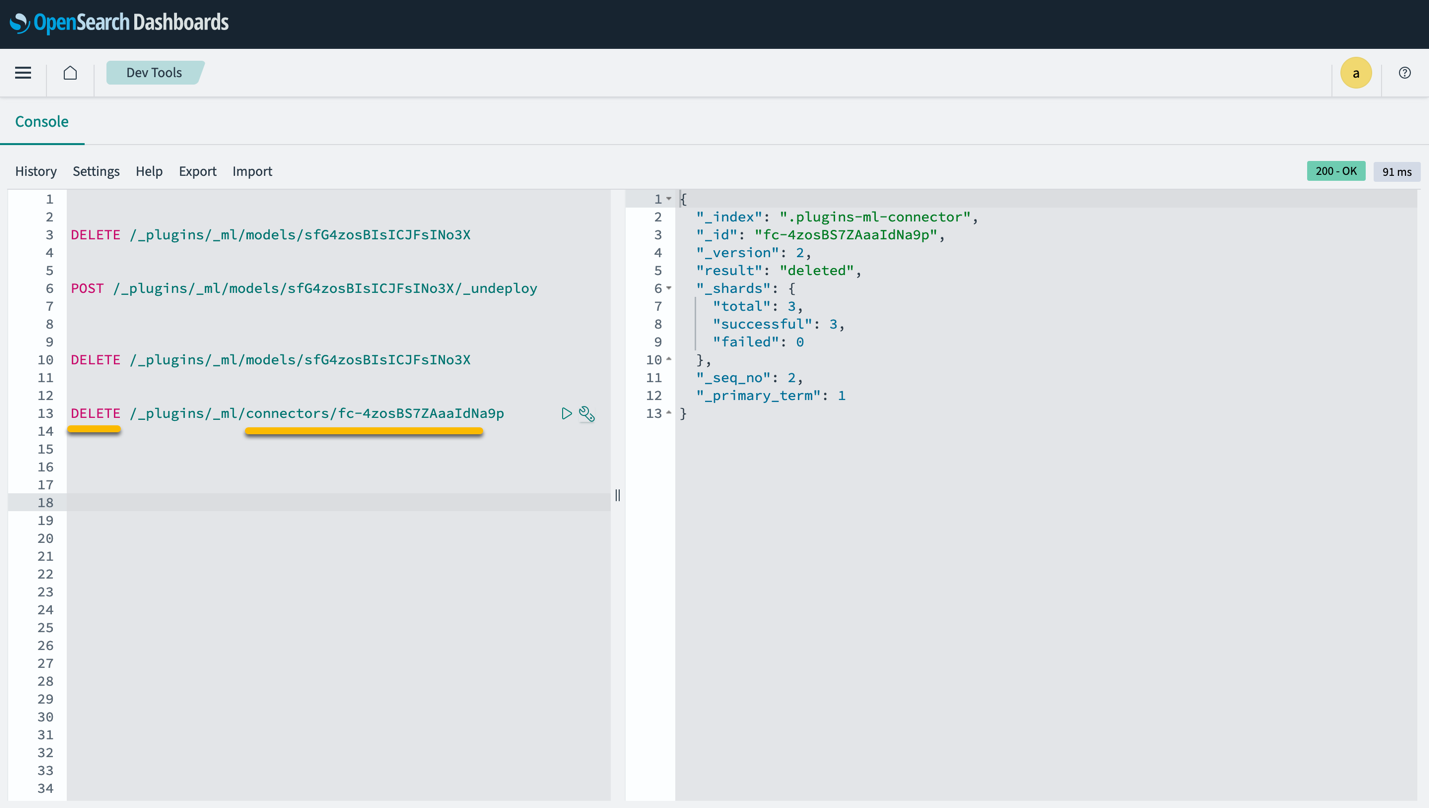
Observera att om du tar bort CloudFormation-stacken raderas inte modellen som distribueras på SageMaker-domänen och den skapade AI/ML-anslutningen. Detta beror på att dessa modeller och kopplingen kan associeras med flera index inom domänen. För att specifikt ta bort en modell och dess associerade anslutning, använd modellens API:er som visas i följande skärmdumpar.
Först, undeploy modellen från OpenSearch Service-domänminnet:

Sedan kan du ta bort modellen från modellindexet:

Ta slutligen bort anslutningen från anslutningsindex:
Slutsats
I det här inlägget lärde du dig hur du distribuerar en modell i SageMaker, skapar AI/ML-anslutningen med OpenSearch Service-konsolen och bygger det neurala sökindexet. Möjligheten att konfigurera AI/ML-anslutningar i OpenSearch Service förenklar vektorhydreringsprocessen genom att göra integrationerna till externa modeller inbyggda. Du kan skapa ett neuralt sökindex på några minuter med hjälp av den neurala intagspipeline och den neurala sökningen som använder modell-ID för att generera vektorinbäddningen i farten under intag och sökning.
För att lära dig mer om dessa AI/ML-kontakter, se Amazon OpenSearch Service AI-anslutningar för AWS-tjänster, AWS CloudFormation mallintegrationer för semantisk sökningoch Skapa kontakter för tredjeparts ML-plattformar.
Om författarna
 Aruna Govindaraju är en Amazon OpenSearch Specialist Solutions Architect och har arbetat med många kommersiella sökmotorer och sökmotorer med öppen källkod. Hon brinner för sökning, relevans och användarupplevelse. Hennes expertis med att relatera slutanvändarsignaler med sökmotorbeteende har hjälpt många kunder att förbättra sin sökupplevelse.
Aruna Govindaraju är en Amazon OpenSearch Specialist Solutions Architect och har arbetat med många kommersiella sökmotorer och sökmotorer med öppen källkod. Hon brinner för sökning, relevans och användarupplevelse. Hennes expertis med att relatera slutanvändarsignaler med sökmotorbeteende har hjälpt många kunder att förbättra sin sökupplevelse.
 Dagney Braun är en huvudproduktchef på AWS med fokus på OpenSearch.
Dagney Braun är en huvudproduktchef på AWS med fokus på OpenSearch.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- : har
- :är
- :inte
- $UPP
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- förmåga
- Om oss
- tillgång
- tillgänglig
- Annat
- AI
- AI / ML
- Alla
- tillåter
- också
- alternativ
- amason
- Amazon SageMaker
- Amazon Web Services
- an
- och
- vilken som helst
- api
- API: er
- Ansökan
- lämpligt
- arkitektur
- ÄR
- AS
- associerad
- At
- Automation
- tillgänglig
- AWS
- AWS molnformation
- backend
- baserat
- BE
- därför att
- beteende
- Fördelarna
- mellan
- båda
- Bringar
- bred
- SLUTRESULTAT
- Byggnad
- by
- KAN
- Vid
- fall
- katalog
- val
- Välja
- valda
- kluster
- kommersiella
- Commons
- jämföra
- fullborda
- Komplexiteten
- konfiguration
- konfigurerad
- konfigurering
- Bekräfta
- anslutna
- Anslutning
- anslutning
- Konsol
- innehålla
- fortsätta
- kontinuerlig
- korrelera
- skapa
- skapas
- skapar
- För närvarande
- beställnings
- Kunder
- instrumentpaneler
- datum
- Standard
- definiera
- definierade
- leverera
- demo
- demonstrera
- demonstrerar
- distribuera
- utplacerade
- utplacera
- utplacering
- vecklas ut
- beskrivning
- detaljerad
- detaljer
- dev
- Dimensionera
- dimensioner
- dokument
- inte
- domän
- under
- varje
- Tidigare
- enkel
- antingen
- inbäddning
- möjliggöra
- Slutpunkt
- Motor
- Motorer
- säkerställa
- Eter (ETH)
- exempel
- erfarenhet
- expertis
- extern
- Ansikte
- underlättar
- Leverans
- Fält
- hitta
- Förnamn
- fokuserade
- efter
- För
- Ramverk
- från
- fullständigt
- generera
- genereras
- genererar
- skaffa sig
- gif
- GitHub
- Grön
- Väx
- styra
- Har
- hjälpte
- här
- högpresterande
- värd
- värd
- värdar
- Hur ser din drömresa ut
- How To
- Men
- html
- http
- HTTPS
- Kramar ansikte
- hydratisering
- IAM
- ID
- identifiera
- Identitet
- if
- förbättra
- in
- index
- index
- pekar på
- informationen
- ingångar
- istället
- instruktioner
- integrera
- integrering
- integrationer
- in
- Beskrivning
- IT
- DESS
- jpg
- json
- Ha kvar
- Nyckel
- språk
- lansera
- LÄRA SIG
- lärt
- inlärning
- livscykel
- Lista
- listor
- låg kostnad
- Maskinen
- maskininlärning
- göra
- Framställning
- hantera
- förvaltade
- chef
- många
- karta
- kartläggning
- Minne
- metod
- minuter
- ML
- modell
- modeller
- Övervaka
- övervakning
- mer
- mycket
- multipel
- måste
- namn
- nativ
- Navigera
- Navigering
- nödvändigt för
- Behöver
- neural
- Nya
- nu
- objektet
- of
- on
- ONE
- endast
- öppet
- öppen källkod
- or
- Övriga
- produktion
- sida
- panelen
- brinner
- Lösenord
- behörigheter
- rörledning
- plato
- Platon Data Intelligence
- PlatonData
- plugin
- Inlägg
- kraft
- drivs
- föregående
- Principal
- Innan
- process
- processorer
- Produkt
- produktchef
- Produktion
- Framsteg
- egenskaper
- ge
- ger
- tillhandahålla
- Syftet
- sökfrågor
- Raw
- rådata
- rekommenderar
- hänvisa
- avlägsen
- bort
- ersätta
- Obligatorisk
- Resurser
- respons
- REST
- Resultat
- detaljhandeln
- behöll
- avkastning
- Roll
- rutter
- Körning
- sagemaker
- skärmdumpar
- Sök
- sökmotor
- Sökmotorer
- säkerhet
- se
- välj
- tjänar
- Server
- service
- Tjänster
- in
- inställningar
- hon
- visas
- Visar
- signaler
- Enkelt
- förenklar
- förenkla
- eftersom
- Lösningar
- Källa
- specialist
- specifikt
- stapel
- Starta
- status
- Steg
- Steg
- förvaring
- Framgångsrikt
- sådana
- Som stöds
- säker
- mall
- text
- den där
- Smakämnen
- deras
- Dem
- sedan
- vari
- Dessa
- tredje part
- detta
- Genom
- till
- tillsammans
- verktyg
- Utbildning
- Transformation
- Översättning
- sann
- Typ
- ui
- unika
- unikt
- användning
- användningsfall
- Begagnade
- Användare
- Användarupplevelse
- med hjälp av
- BEKRÄFTA
- verifiera
- version
- via
- Video
- utsikt
- promenader
- var
- we
- webb
- webbservice
- när
- som
- kommer
- med
- inom
- arbetade
- arbetsflöde
- arbetsflödesautomatisering
- dig
- Din
- zephyrnet