Bild av författare
När du dyker in i en värld av datavetenskap och maskininlärning är en av de grundläggande färdigheterna du kommer att möta konsten att läsa data. Om du redan har lite erfarenhet av det är du förmodligen bekant med JSON (JavaScript Object Notation) – ett populärt format för både lagring och utbyte av data.
Tänk på hur NoSQL-databaser som MongoDB älskar att lagra data i JSON, eller hur REST API:er ofta svarar i samma format.
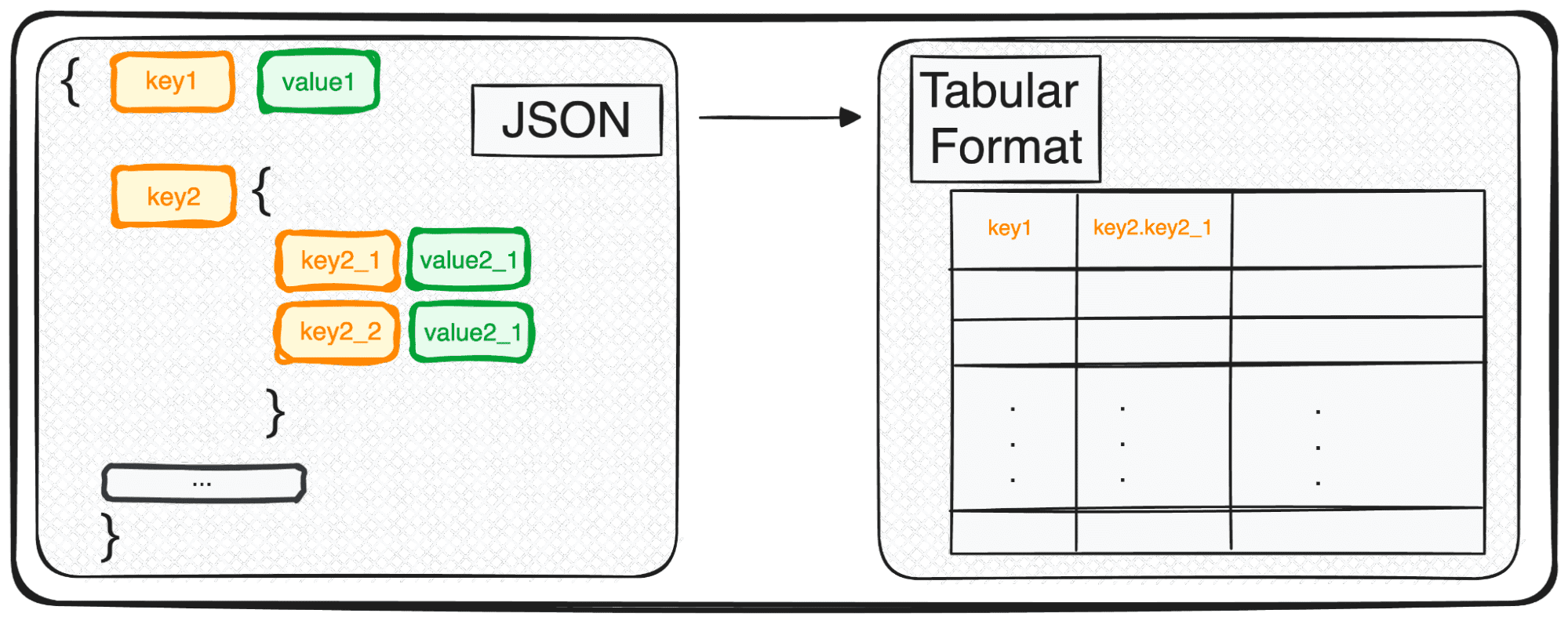
Men även om JSON är perfekt för lagring och utbyte, är det inte riktigt redo för djupgående analys i sin råa form. Det är här vi omvandlar det till något mer analytiskt vänligt – ett tabellformat.
Så oavsett om du har att göra med ett enda JSON-objekt eller en förtjusande samling av dem, i Pythons termer, hanterar du i huvudsak ett dikt eller en lista med dikter.
Låt oss tillsammans utforska hur denna transformation utvecklas, vilket gör våra data mogna för analys ????
Idag kommer jag att förklara ett magiskt kommando som gör att vi enkelt kan analysera vilken JSON som helst till ett tabellformat på några sekunder.
Och det är... pd.json_normalize()
Så låt oss se hur det fungerar med olika typer av JSON.
Den första typen av JSON som vi kan arbeta med är JSONs på en nivå med några få nycklar och värden. Vi definierar våra första enkla JSONs enligt följande:
Kod efter författare
Så låt oss simulera behovet av att arbeta med dessa JSON. Vi vet alla att det inte finns mycket att göra i deras JSON-format. Vi måste omvandla dessa JSONs till något läsbart och modifierbart format... vilket betyder Pandas DataFrames!
1.1 Hantera enkla JSON-strukturer
Först måste vi importera pandas-biblioteket och sedan kan vi använda kommandot pd.json_normalize(), enligt följande:
import pandas as pd
pd.json_normalize(json_string)
Genom att tillämpa detta kommando på en JSON med en enda post får vi den mest grundläggande tabellen. Men när våra data är lite mer komplexa och presenterar en lista över JSONs, kan vi fortfarande använda samma kommando utan ytterligare komplikationer och utdata kommer att motsvara en tabell med flera poster.

Bild av författare
Lätt... eller hur?
Nästa naturliga fråga är vad som händer när några av värdena saknas.
1.2 Hantera nollvärden
Föreställ dig att några av värdena inte är informerade, som till exempel att inkomstposten för David saknas. När vi omvandlar vår JSON till en enkel pandadataram kommer motsvarande värde att visas som NaN.
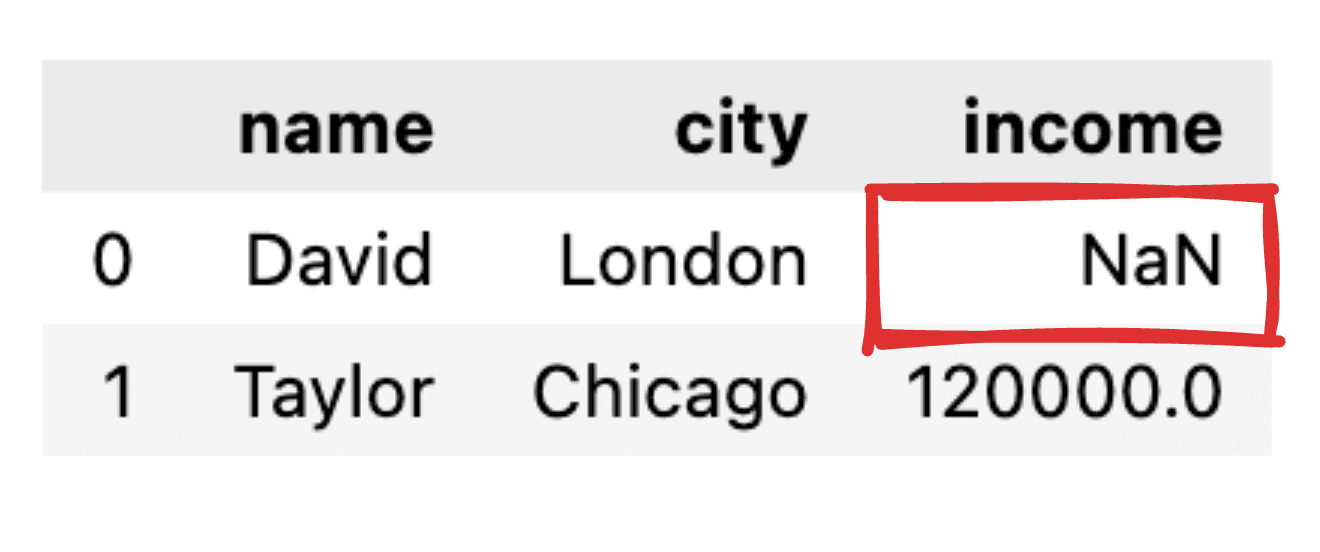
Bild av författare
Och vad händer om jag bara vill få några av fälten?
1.3 Välj endast de kolumner av intresse
Om vi bara vill omvandla några specifika fält till en tabellformad pandas DataFrame, tillåter inte kommandot json_normalize() oss att välja vilka fält som ska transformeras.
Därför bör en liten förbearbetning av JSON utföras där vi filtrerar just de kolumner av intresse.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Så låt oss gå till en mer avancerad JSON-struktur.
När vi har att göra med JSONs på flera nivåer befinner vi oss med kapslade JSONs inom olika nivåer. Proceduren är densamma som tidigare, men i det här fallet kan vi välja hur många nivåer vi vill transformera. Som standard kommer kommandot alltid att expandera alla nivåer och generera nya kolumner som innehåller det sammanlänkade namnet på alla kapslade nivåer.
Så om vi normaliserar följande JSONs.
Kod efter författare
Vi skulle få följande tabell med 3 kolumner under fältkunskaperna:
- skills.python
- färdigheter.SQL
- färdigheter.GCP
och 4 kolumner under fältrollerna
- roller.projektledare
- roller.dataingenjör
- roller.datavetare
- roller.dataanalytiker

Bild av författare
Föreställ dig dock att vi bara vill förändra vår högsta nivå. Vi kan göra det genom att specifikt definiera parametern max_level till 0 (den max_level vi vill utöka).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
De väntande värdena kommer att bibehållas inom JSONs inom vår pandas DataFrame.
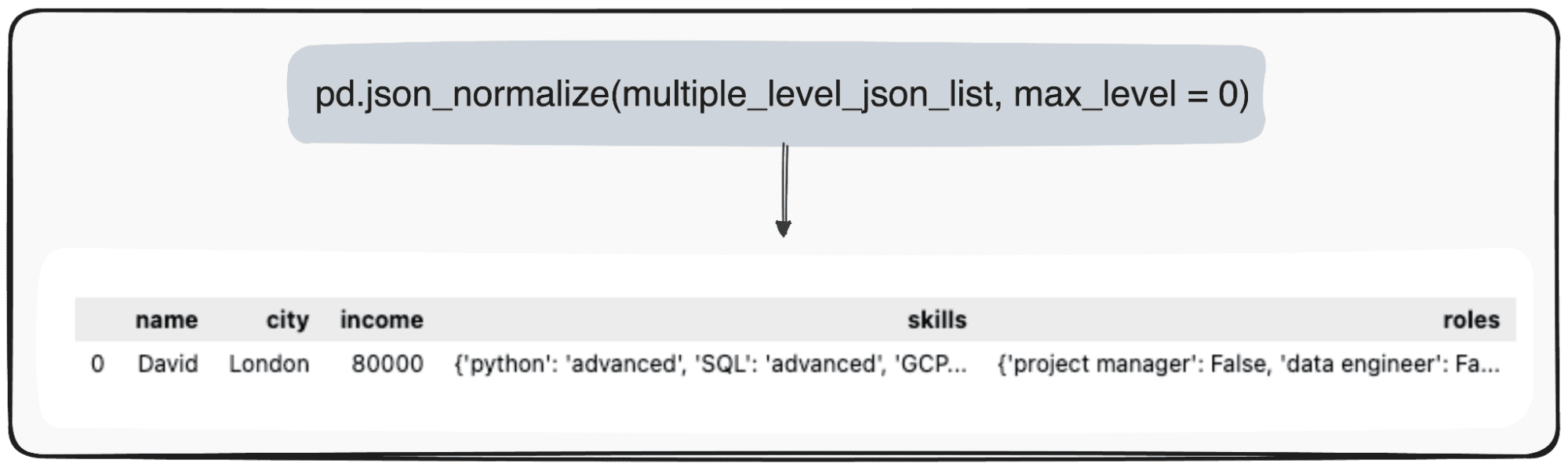
Bild av författare
Det sista fallet vi kan hitta är att ha en kapslad lista i ett JSON-fält. Så vi definierar först våra JSONs att använda.
Kod efter författare
Vi kan effektivt hantera denna data med Pandas i Python. Funktionen pd.json_normalize() är särskilt användbar i detta sammanhang. Det kan platta ut JSON-data, inklusive den kapslade listan, till ett strukturerat format som är lämpligt för analys. När den här funktionen tillämpas på våra JSON-data, producerar den en normaliserad tabell som inkluderar den kapslade listan som en del av dess fält.
Dessutom erbjuder Pandas möjligheten att ytterligare förfina denna process. Genom att använda parametern record_path i pd.json_normalize() kan vi styra funktionen för att specifikt normalisera den kapslade listan.
Denna åtgärd resulterar i en dedikerad tabell exklusivt för listans innehåll. Som standard kommer denna process bara att veckla ut elementen i listan. Men för att berika den här tabellen med ytterligare sammanhang, som att behålla ett associerat ID för varje post, kan vi använda metaparametern.

Bild av författare
Sammanfattningsvis är omvandlingen av JSON-data till CSV-filer med Pythons Pandas-bibliotek enkel och effektiv.
JSON är fortfarande det vanligaste formatet i modern datalagring och utbyte, särskilt i NoSQL-databaser och REST API:er. Det ger dock några viktiga analytiska utmaningar när man hanterar data i sitt råformat.
Den centrala rollen för Pandas pd.json_normalize() framstår som ett utmärkt sätt att hantera sådana format och konvertera vår data till pandas DataFrame.
Jag hoppas att den här guiden var användbar, och nästa gång du har att göra med JSON kan du göra det på ett mer effektivt sätt.
Du kan gå och kolla motsvarande Jupyter Notebook i efter GitHub repo.
Josep Ferrer är en analysingenjör från Barcelona. Han tog examen i fysikteknik och arbetar för närvarande inom datavetenskapsområdet tillämpat på mänsklig rörlighet. Han är en innehållsskapare på deltid med fokus på datavetenskap och teknologi. Du kan kontakta honom på LinkedIn, Twitter or Medium.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :är
- :inte
- :var
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- Om oss
- Handling
- Annat
- avancerat
- Alla
- tillåter
- tillåter
- redan
- alltid
- an
- analys
- analytiker
- Analytisk
- analytics
- och
- vilken som helst
- API: er
- visas
- tillämpas
- Tillämpa
- ÄR
- array
- Konst
- AS
- associerad
- Barcelona
- grundläggande
- BE
- innan
- Bit
- båda
- men
- by
- KAN
- kapacitet
- Vid
- utmaningar
- ta
- Välja
- Stad
- Kolonner
- Gemensam
- komplex
- komplikationer
- kontakta
- innehåll
- innehåll
- sammanhang
- konvertera
- omvandling
- motsvarar
- Motsvarande
- skaparen
- För närvarande
- datum
- dataanalytiker
- dataingenjör
- datavetenskap
- datavetare
- datalagring
- databaser
- David
- som handlar om
- dedicerad
- Standard
- definiera
- definierande
- förtjusande
- DICT
- olika
- rikta
- do
- gör
- varje
- lätt
- lätt
- Effektiv
- effektivt
- element
- framträder
- råka ut för
- ingenjör
- Teknik
- berika
- väsentligen
- utbyta
- utbyte
- uteslutande
- Bygga ut
- erfarenhet
- förklara
- utforska
- bekant
- få
- fält
- Fält
- Filer
- filtrera
- hitta
- Förnamn
- fokuserade
- efter
- följer
- För
- formen
- format
- vänliga
- från
- fungera
- grundläggande
- ytterligare
- GCP
- generera
- skaffa sig
- GitHub
- Go
- stor
- styra
- hantera
- Arbetsmiljö
- händer
- Har
- har
- he
- honom
- hoppas
- Hur ser din drömresa ut
- Men
- HTTPS
- humant
- i
- SJUK
- ID
- if
- bild
- importera
- med Esport
- in
- djupgående
- innefattar
- Inklusive
- Inkomst
- inkorporerar
- informeras
- exempel
- intresse
- in
- isn
- IT
- DESS
- JavaScript
- json
- Jupyter Notebook
- bara
- KDnuggets
- Nyckel
- nycklar
- Vet
- Efternamn
- inlärning
- Nivå
- nivåer
- Bibliotek
- tycka om
- Lista
- liten
- ll
- älskar
- Maskinen
- maskininlärning
- magi
- hållna
- Framställning
- hantera
- chef
- många
- betyder
- meta
- saknas
- mobilitet
- Modern Konst
- MongoDB
- mer
- mest
- flytta
- mycket
- multipel
- namn
- Natural
- Behöver
- kapslad
- Nya
- Nästa
- Nej
- i synnerhet
- anteckningsbok
- objektet
- få
- of
- Erbjudanden
- Ofta
- on
- ONE
- endast
- or
- vår
- själva
- produktion
- pandor
- parameter
- del
- särskilt
- väntan
- perfekt
- utfört
- Fysik
- svängbara
- plato
- Platon Data Intelligence
- PlatonData
- Populära
- presenterar
- förmodligen
- förfaranden
- process
- producerar
- projektet
- Python
- fråga
- ganska
- Raw
- RE
- Läsning
- redo
- post
- register
- förfina
- Svara
- REST
- Resultat
- kvarhållande
- höger
- Roll
- s
- Samma
- Vetenskap
- Vetenskap och teknik
- Forskare
- sekunder
- se
- väljer
- skall
- Enkelt
- simulera
- enda
- färdigheter
- Small
- So
- några
- något
- specifik
- specifikt
- SQL
- Fortfarande
- förvaring
- lagra
- struktur
- strukturerade
- sådana
- lämplig
- SAMMANFATTNING
- T
- bord
- Teknologi
- villkor
- den där
- Smakämnen
- världen
- deras
- Dem
- sedan
- Dessa
- detta
- de
- tid
- till
- tillsammans
- topp
- Förvandla
- Transformation
- omvandla
- Typ
- typer
- under
- us
- användning
- användbara
- med hjälp av
- Använda
- värde
- Värden
- vill
- var
- Sätt..
- we
- Vad
- när
- om
- som
- medan
- kommer
- med
- inom
- Arbete
- arbetssätt
- fungerar
- världen
- skulle
- dig
- zephyrnet