Finansiella tjänster kunder använder data från olika källor som kommer från olika frekvenser, vilket inkluderar realtid, batch och arkiverade datamängder. Dessutom behöver de strömmande arkitekturer för att hantera växande handelsvolymer, marknadsvolatilitet och regulatoriska krav. Följande är några av de viktigaste affärsanvändningsfallen som belyser detta behov:
- Handelsrapportering – Sedan den globala finanskrisen 2007–2008 har tillsynsmyndigheter ökat sina krav och granskning av tillsynsrapportering. Tillsynsmyndigheter har lagt ett ökat fokus på att både skydda konsumenten genom transaktionsrapportering (vanligtvis T+1, vilket betyder 1 arbetsdag efter handelsdatum) och öka transparensen på marknader via handelsrapporteringskrav i nästan realtid.
- Riskhantering – I takt med att kapitalmarknaderna blir mer komplexa och tillsynsmyndigheter lanserar nya riskramar, som t.ex Grundläggande översyn av handelsboken (FRTB) och Basel III, vill finansiella institutioner öka frekvensen av beräkningar för övergripande marknadsrisk, likviditetsrisk, motpartsrisk och andra riskmätningar och vill komma så nära realtidsberäkningar som möjligt.
- Handelskvalitet och optimering – För att övervaka och optimera handelskvaliteten måste du kontinuerligt utvärdera marknadsegenskaper som volym, riktning, marknadsdjup, fyllnadsgrad och andra riktmärken relaterade till slutförandet av affärer. Handelskvalitet är inte bara relaterad till mäklarprestanda, utan är också ett krav från tillsynsmyndigheter, till att börja med MiFID II.
Utmaningen är att komma på en lösning som kan hantera dessa olika källor, varierande frekvenser och förbrukningskrav med låg latens. Lösningen bör vara skalbar, kostnadseffektiv och enkel att använda och driva. Amazon RedShift funktioner som streamingintag, Amazon-Aurora noll-ETL integrationoch datadelning med AWS datautbyte möjliggör bearbetning i nästan realtid för handelsrapportering, riskhantering och handelsoptimering.
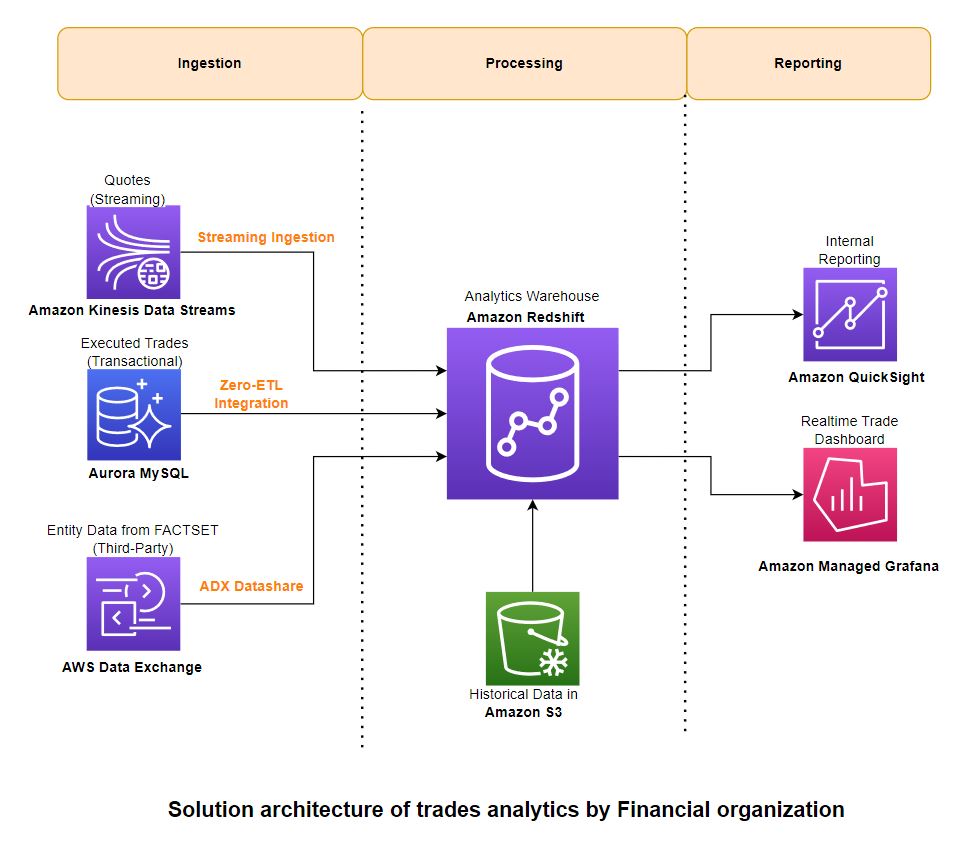
I det här inlägget tillhandahåller vi en lösningsarkitektur som beskriver hur du kan bearbeta data från tre olika typer av källor – strömmande, transaktionsdata och referensdata från tredje part – och aggregera dem i Amazon Redshift för rapportering om affärsintelligens (BI).
Lösningsöversikt
Denna lösningsarkitektur är skapad genom att prioritera ett tillvägagångssätt med låg kod/ingen kod med följande vägledande principer:
- Användarvänlighet – Det borde vara mindre komplicerat att implementera och driva med intuitiva användargränssnitt
- Skalbar – Du bör sömlöst kunna öka och minska kapaciteten på efterfrågan
- Infödd integration – Komponenter bör integreras utan extra kontakter eller programvara
- Kostnadseffektiv – Det ska ge balanserat pris/prestanda
- Lågt underhållsbehov – Det borde kräva mindre lednings- och driftskostnader
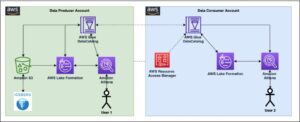
Följande diagram illustrerar lösningsarkitekturen och hur dessa vägledande principer tillämpades på komponenterna för intag, aggregering och rapportering.
![]()
Distribuera lösningen
Du kan använda följande AWS molnformation mall för att distribuera lösningen.
![]()
Denna stack skapar följande resurser och nödvändiga behörigheter för att integrera tjänsterna:
Förtäring
För att få in data använder du Amazon Redshift Streaming Intag för att ladda strömmande data från Kinesis-dataströmmen. För transaktionsdata använder du Redshift noll-ETL-integration med Amazon Aurora MySQL. För tredje parts referensdata drar du nytta av AWS Data Exchange-dataandelar. Dessa funktioner gör att du snabbt kan bygga skalbara datapipelines eftersom du kan öka kapaciteten för Kinesis Data Streams-skärvor, beräkna noll-ETL-källor och mål och Redshift-beräkna för datadelning när din data växer. Redshift streaming-intag och noll-ETL-integration är lösningar med låg kod/ingen kod som du kan bygga med enkla SQL-filer utan att investera betydande tid och pengar på att utveckla komplex anpassad kod.
För den data som användes för att skapa denna lösning samarbetade vi med Faktauppsättning, en ledande leverantör av finansiell data, analys och öppen teknik. FactSet har flera datauppsättningar tillgängligt på AWS Data Exchange-marknadsplatsen, som vi använde för referensdata. Vi använde också faktauppsättningar marknadsdatalösningar för historiska och strömmande marknadskurser och affärer.
Bearbetning
Data bearbetas i Amazon Redshift i enlighet med en extrahera, ladda och transformera (ELT) metodik. Med praktiskt taget obegränsad skala och isolering av arbetsbelastning är ELT mer lämpad för molndatalagerlösningar.
Du använder Redshift-strömningsinmatning för realtidsintag av strömmande offerter (bud/fråga) från Kinesis-dataströmmen direkt till en strömningsmaterialiserad vy och bearbetar data i nästa steg med PartiQL för att analysera dataströmsingångarna. Observera att strömmande materialiserade vyer skiljer sig från vanliga materialiserade vyer när det gäller hur automatisk uppdatering fungerar och vilka SQL-kommandon för datahantering som används. Hänvisa till Överväganden vid intag av streaming för mer information.
Du använder noll-ETL Aurora-integrationen för att ta emot transaktionsdata (affärer) från OLTP-källor. Hänvisa till Arbeta med noll-ETL-integrationer för för närvarande stödda källor. Du kan kombinera data från alla dessa källor med hjälp av vyer och använda lagrade procedurer för att implementera regler för affärstransformation som att beräkna viktade medelvärden över sektorer och börser.
Historiska handels- och offertdatavolymer är enorma och frågas ofta inte ofta. Du kan använda Amazon Redshift Spectrum för att komma åt denna data på plats utan att ladda den i Amazon Redshift. Du skapar externa tabeller som pekar på data in Amazon enkel lagringstjänst (Amazon S3) och fråga på samma sätt som du frågar någon annan lokal tabell i Amazon Redshift. Flera Redshift-datalager kan samtidigt fråga samma datauppsättningar i Amazon S3 utan att behöva göra kopior av data för varje datalager. Denna funktion förenklar åtkomst till extern data utan att skriva komplexa ETL-processer och förbättrar användarvänligheten för den övergripande lösningen.
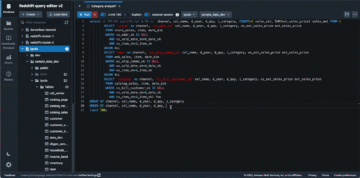
Låt oss granska några exempel på frågor som används för att analysera offerter och affärer. Vi använder följande tabeller i exempelfrågorna:
- dt_hist_quote – Historiska kursdata som innehåller köpkurs och volym, säljkurs och volym samt börser och sektorer. Du bör använda relevanta datauppsättningar i din organisation som innehåller dessa dataattribut.
- dt_hist_trades – Historiska handelsdata som innehåller omsatt pris, volym, sektor och börsinformation. Du bör använda relevanta datauppsättningar i din organisation som innehåller dessa dataattribut.
- faktauppsättning_sektorkarta – Kartläggning mellan sektorer och börser. Du kan få detta från FactSet Fundamentals ADX-datauppsättning.
Exempelfråga för att analysera historiska citat
Du kan använda följande fråga för att hitta vägda genomsnittliga spridningar på citat:
Exempelfråga för att analysera historiska affärer
Du kan använda följande fråga för att hitta $-volume på affärer efter detaljerad börs, efter sektor och efter större börs (NYSE och Nasdaq):
Rapportering
Du kan använda Amazon QuickSight och Amazon Managed Grafana för BI respektive realtidsrapportering. Dessa tjänster integreras naturligt med Amazon Redshift utan att behöva använda ytterligare kontakter eller programvara däremellan.
Du kan köra en direktfråga från QuickSight för BI-rapportering och instrumentpaneler. Med QuickSight kan du också lokalt lagra data i SPICE-cachen med automatisk uppdatering för låg latens. Hänvisa till Auktorisera anslutningar från Amazon QuickSight till Amazon Redshift-kluster för omfattande information om hur du integrerar QuickSight med Amazon Redshift.
Du kan använda Amazon Managed Grafana för handelsinstrumentpaneler i nästan realtid som uppdateras med några sekunders mellanrum. Instrumentpanelerna i realtid för att övervaka latenserna för intag av handel skapas med Grafana och data hämtas från systemvyer i Amazon Redshift. Hänvisa till Använder Amazon Redshift-datakällan för att lära dig hur du konfigurerar Amazon Redshift som en datakälla för Grafana.
De användare som interagerar med regulatoriska rapporteringssystem inkluderar analytiker, riskhanterare, operatörer och andra personer som stödjer affärs- och teknikverksamhet. Förutom att generera regulatoriska rapporter kräver dessa team insyn i rapporteringssystemens tillstånd.
Analys av historiska citat
I det här avsnittet utforskar vi några exempel på historiska citatanalyser från Amazon QuickSight instrumentbräda.
Vägt genomsnittlig spridning per sektor
Följande diagram visar den dagliga aggregeringen per sektor av de vägda genomsnittliga bud- och säljspreadarna för alla individuella affärer på NASDAQ och NYSE under 3 månader. För att beräkna den genomsnittliga dagliga spreaden, viktas varje spread med summan av budet och volymen av säljdollar. Frågan för att generera detta diagram behandlar totalt 103 miljarder datapunkter, ansluter till varje handel med sektorreferenstabellen och körs på mindre än 10 sekunder.
![]()
Vägt genomsnittlig spridning av börser
Följande diagram visar den dagliga sammanräkningen av de vägda genomsnittliga bud- och säljspreadarna för alla individuella affärer på NASDAQ och NYSE under 3 månader. Beräkningsmetoden och frågeprestandamåtten liknar de i föregående diagram.
![]()
Historisk branschanalys
I det här avsnittet utforskar vi några exempel på historiska handelsanalyser från Amazon QuickSight instrumentbräda.
Handelsvolymer per sektor
Följande diagram visar den dagliga sammanräkningen per sektor av alla enskilda affärer på NASDAQ och NYSE under 3 månader. Frågan för att generera detta diagram bearbetar totalt 3.6 miljarder avslut, sammanfogar varje handel med sektorreferenstabellen och körs på under 5 sekunder.
![]()
Handelsvolymer för större börser
Följande diagram visar den dagliga sammanräkningen per börsgrupp för alla individuella affärer under 3 månader. Frågan för att generera det här diagrammet har liknande prestandamått som det föregående diagrammet.
![]()
Instrumentpaneler i realtid
Övervakning och observerbarhet är ett viktigt krav för alla kritiska affärsapplikationer såsom handelsrapportering, riskhantering och handelsledningssystem. Förutom mätvärden på systemnivå är det också viktigt att övervaka nyckelprestandaindikatorer i realtid så att operatörer kan varnas och svara så snart som möjligt på händelser som påverkar verksamheten. För denna demonstration har vi byggt instrumentpaneler i Grafana som övervakar fördröjningen av offert- och handelsdata från Kinesis-dataströmmen respektive Aurora.
Instrumentpanelen för fördröjning av offertinmatning visar hur lång tid det tar för varje offertpost att tas in från dataströmmen och vara tillgänglig för sökning i Amazon Redshift.
![]()
Instrumentpanelen för fördröjning av handelsintag visar hur lång tid det tar för en transaktion i Aurora att bli tillgänglig i Amazon Redshift för sökning.
![]()
Städa upp
För att rensa upp dina resurser, ta bort stacken du distribuerade med AWS CloudFormation. För instruktioner, se Ta bort en stack på AWS CloudFormation-konsolen.
Slutsats
Ökande volymer av handelsaktivitet, mer komplex riskhantering och förbättrade regulatoriska krav leder till att kapitalmarknadsföretag anammar databehandling i realtid och nästan i realtid, även i mellan- och back-office-plattformar där bearbetning vid slutet av dagen och över natten. var standarden. I det här inlägget visade vi hur du kan använda Amazon Redshift-funktioner för enkel användning, lågt underhåll och kostnadseffektivitet. Vi diskuterade också integrationer över flera tjänster för att få in strömmande marknadsdata, bearbeta uppdateringar från OLTP-databaser och använda referensdata från tredje part utan att behöva utföra komplicerad och dyr ETL- eller ELT-bearbetning innan informationen blev tillgänglig för analys och rapportering.
Vänligen kontakta oss om du behöver någon vägledning för att implementera denna lösning. Hänvisa till Realtidsanalys med Amazon Redshift-strömning, Komma igång-guide för operationsanalys i nästan realtid med Amazon Aurora noll-ETL-integration med Amazon Redshiftoch Arbeta med AWS Data Exchange-dataandelar som producent för mer information.
Om författarna
![]() Satesh Sonti är en Sr. Analytics Specialist Solutions Architect baserad i Atlanta, specialiserad på att bygga företagsdataplattformar, datalagring och analyslösningar. Han har över 18 års erfarenhet av att bygga datatillgångar och leda komplexa dataplattformsprogram för bank- och försäkringskunder över hela världen.
Satesh Sonti är en Sr. Analytics Specialist Solutions Architect baserad i Atlanta, specialiserad på att bygga företagsdataplattformar, datalagring och analyslösningar. Han har över 18 års erfarenhet av att bygga datatillgångar och leda komplexa dataplattformsprogram för bank- och försäkringskunder över hela världen.
![]() Alket Memushaj arbetar som huvudarkitekt i Financial Services Market Development-teamet på AWS. Alket ansvarar för teknisk strategi för kapitalmarknader, och arbetar med partners och kunder för att distribuera applikationer över hela handelslivscykeln till AWS Cloud, inklusive marknadsanslutning, handelssystem och analys- och forskningsplattformar före och efter handel.
Alket Memushaj arbetar som huvudarkitekt i Financial Services Market Development-teamet på AWS. Alket ansvarar för teknisk strategi för kapitalmarknader, och arbetar med partners och kunder för att distribuera applikationer över hela handelslivscykeln till AWS Cloud, inklusive marknadsanslutning, handelssystem och analys- och forskningsplattformar före och efter handel.
![]() Ruben Falk är en kapitalmarknadsspecialist med fokus på AI och data & analys. Ruben rådgör med aktörer på kapitalmarknaden om modern dataarkitektur och systematiska investeringsprocesser. Han kom till AWS från S&P Global Market Intelligence där han var Global Head of Investment Management Solutions.
Ruben Falk är en kapitalmarknadsspecialist med fokus på AI och data & analys. Ruben rådgör med aktörer på kapitalmarknaden om modern dataarkitektur och systematiska investeringsprocesser. Han kom till AWS från S&P Global Market Intelligence där han var Global Head of Investment Management Solutions.
![]() Jeff Wilson är en världsomspännande Go-to-market-specialist med 15 års erfarenhet av att arbeta med analytiska plattformar. Hans nuvarande fokus är att dela fördelarna med att använda Amazon Redshift, Amazons inhemska molndatalager. Jeff är baserad i Florida och har varit på AWS sedan 2019.
Jeff Wilson är en världsomspännande Go-to-market-specialist med 15 års erfarenhet av att arbeta med analytiska plattformar. Hans nuvarande fokus är att dela fördelarna med att använda Amazon Redshift, Amazons inhemska molndatalager. Jeff är baserad i Florida och har varit på AWS sedan 2019.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/combine-transactional-streaming-and-third-party-data-on-amazon-redshift-for-financial-services/
- : har
- :är
- :inte
- :var
- ][s
- $UPP
- 1
- 10
- 100
- 130
- 15 år
- 15%
- 150
- 16
- 20
- 2019
- 27
- 30
- a
- Able
- Om oss
- tillgång
- åtkomst
- tvärs
- aktivitet
- Annat
- Dessutom
- vidhäftande
- anta
- Fördel
- ADX
- Efter
- aggregat
- aggregation
- AI
- Alla
- tillåter
- också
- amason
- Amazon Managed Grafana
- Amazon QuickSight
- Amazon Web Services
- mängd
- an
- analys
- analytiker
- Analytisk
- analytics
- analys
- och
- vilken som helst
- isär
- Ansökan
- tillämpningar
- tillämpas
- tillvägagångssätt
- arkitektur
- arkitekturer
- ÄR
- AS
- be
- Tillgångar
- At
- Atlanta
- attribut
- aurora
- bil
- tillgänglig
- genomsnitt
- AWS
- AWS molnformation
- b
- Balanserad
- Banking
- baserat
- BE
- därför att
- blir
- varit
- innan
- riktmärken
- Fördelarna
- mellan
- bud
- Miljarder
- till
- båda
- mäklare
- SLUTRESULTAT
- Byggnad
- byggt
- företag
- business intelligence
- Affärstransformation
- men
- by
- cache
- beräkna
- beräkning
- beräkning
- KAN
- kapacitet
- Kapacitet
- kapital
- Kapitalmarknader
- Vid
- fall
- CBOE
- utmanar
- egenskaper
- Diagram
- rena
- klienter
- Stäng
- cloud
- koda
- kombinera
- komma
- fullbordan
- komplex
- komponenter
- omfattande
- Compute
- Anslutningar
- Anslutningar
- Konsumenten
- konsumtion
- innehålla
- kontinuerligt
- kopior
- skapa
- skapas
- skapar
- kris
- kritisk
- Aktuella
- För närvarande
- beställnings
- Kunder
- dagligen
- instrumentbräda
- instrumentpaneler
- datum
- Datautbyte
- datahantering
- Dataplattform
- datapunkter
- databehandling
- datadeling
- datalagret
- datalager
- databaser
- datauppsättningar
- Datum
- dag
- minskning
- fördröja
- leverera
- krav
- demonstreras
- distribuera
- utplacerade
- djup
- beskriver
- detaljerad
- detaljer
- utveckla
- Utveckling
- utvecklingsteam
- Diagrammet
- olika
- rikta
- riktning
- direkt
- diskuteras
- disparat
- Dollar
- varje
- lätta
- enkel användning
- omfamna
- möjliggöra
- änden
- förbättrad
- Förbättrar
- Företag
- Eter (ETH)
- utvärdera
- Även
- händelser
- Varje
- exempel
- utbyta
- Utbyten
- dyra
- erfarenhet
- utforska
- extern
- extrahera
- Leverans
- Funktioner
- få
- fylla
- finansiella
- finanskris
- finansiella data
- Finansiella institut
- finansiella tjänster
- hitta
- företag
- florida
- Fokus
- fokuserade
- efter
- För
- ramar
- Frekvens
- ofta
- från
- Fundamentals
- generera
- generera
- skaffa sig
- Välgörenhet
- globala finansiella
- Global finansiell kris
- global marknad
- globen
- Gå till marknaden
- Grupp
- Odling
- Växer
- vägleda
- styra
- styrning
- hantera
- Har
- har
- he
- huvud
- Hälsa
- Markera
- hans
- historisk
- Hur ser din drömresa ut
- How To
- html
- http
- HTTPS
- stor
- if
- illustrerar
- genomföra
- genomföra
- med Esport
- in
- innefattar
- innefattar
- Inklusive
- Öka
- ökat
- indikatorer
- individuellt
- informationen
- ingångar
- institutioner
- instruktioner
- försäkring
- integrera
- integrering
- integrationer
- Intelligens
- interagera
- in
- intuitiv
- investera
- investering
- isolering
- IT
- delta
- fogade
- Fogar
- jpg
- Nyckel
- Kinesis dataströmmar
- Latens
- lansera
- ledande
- LÄRA SIG
- mindre
- livscykel
- tycka om
- Likviditet
- läsa in
- läser in
- lokal
- lokalt
- du letar
- Låg
- underhåll
- större
- göra
- Framställning
- förvaltade
- ledning
- chefer
- kartläggning
- marknad
- Market Data
- Marknadsvolatilitet
- marknadsplats
- Marknader
- betyder
- mätningar
- Metodik
- Metrics
- Modern Konst
- pengar
- Övervaka
- övervakning
- månader
- mer
- multipel
- MySQL
- Nasdaq
- nativ
- natively
- nödvändigt för
- Behöver
- Nya
- New York
- New York Stock Exchange
- Nästa
- Notera
- NYSE
- få
- of
- Ofta
- on
- endast
- öppet
- driva
- operativa
- Verksamhet
- operatörer
- optimering
- Optimera
- or
- beställa
- organisation
- Övriga
- ut
- över
- övergripande
- natten
- deltagare
- samarbetar
- partner
- utföra
- prestanda
- behörigheter
- Plats
- placeras
- plattform
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- poäng
- möjlig
- Inlägg
- efter handel
- föregående
- pris
- Principal
- Principerna
- prioritering
- förfaranden
- process
- bearbetade
- processer
- bearbetning
- Program
- skydda
- ge
- leverantör
- kvalitet
- sökfrågor
- fråga
- snabbt
- citera
- citat
- Betygsätta
- nå
- verklig
- realtid
- post
- hänvisa
- referens
- regelbunden
- Tillsynsmyndigheter
- regulatorer
- relaterad
- relevanta
- Rapportering
- Rapport
- kräver
- krav
- Krav
- forskning
- Resurser
- respektive
- Svara
- ansvarig
- översyn
- Risk
- riskhanterings
- regler
- Körning
- kör
- S & P
- S&P Global
- Samma
- skalbar
- Skala
- granskning
- sömlöst
- sekunder
- §
- sektor
- Sektorer
- välj
- Tjänster
- flera
- aktier
- delning
- skall
- Visar
- signifikant
- liknande
- Liknande
- Enkelt
- förenklar
- eftersom
- So
- Mjukvara
- lösning
- Lösningar
- några
- Alldeles strax
- Källa
- kommer från
- Källor
- specialist
- specialiserad
- krydda
- spridning
- Sprider
- SQL
- stapel
- standard
- igång
- Starta
- Steg
- lager
- Börsen
- förvaring
- lagra
- lagras
- okomplicerad
- Strategi
- ström
- streaming
- strömmar
- sådana
- summan
- stödja
- Som stöds
- system
- System
- bord
- Ta
- tar
- mål
- grupp
- lag
- Teknisk
- Teknologi
- mall
- villkor
- än
- den där
- Smakämnen
- deras
- Dem
- sedan
- Dessa
- de
- tredje part
- tredjepartsdata
- detta
- de
- tre
- Genom
- tid
- till
- Totalt
- handla
- handlas
- handel
- Handel
- transaktion
- transaktion
- Förvandla
- Transformation
- Öppenhet
- typer
- typiskt
- under
- obegränsat
- Uppdateringar
- us
- användning
- Begagnade
- Användare
- användare
- med hjälp av
- via
- utsikt
- visningar
- praktiskt taget
- synlighet
- Volatilitet
- volym
- volymer
- vill
- Warehouse
- Lagring
- var
- we
- webb
- webbservice
- vikt
- były
- när
- som
- VEM
- med
- utan
- arbetssätt
- fungerar
- skrivning
- jaml
- år
- york
- dig
- Din
- zephyrnet