Amazon OpenSearch Service är en hanterad tjänst som gör det enkelt att säkra, distribuera och driva OpenSearch och äldre Elasticsearch-kluster i stor skala i AWS-molnet. Amazon OpenSearch Service tillhandahåller alla resurser för ditt kluster, startar det och upptäcker och ersätter automatiskt misslyckade noder, vilket minskar kostnaden för självhanterade infrastrukturer. Tjänsten gör det enkelt för dig att utföra interaktiv logganalys, applikationsövervakning i realtid, webbplatssökningar och mer genom att erbjuda de senaste versionerna av OpenSearch, stöd för 19 versioner av Elasticsearch (1.5 till 7.10 versioner) och visualiseringsfunktioner som drivs av OpenSearch Dashboards och Kibana (1.5 till 7.10 versioner).
I den senaste versionen av serviceprogramvaran har vi uppdaterat shard-allokeringslogiken för att vara belastningsmedveten så att när shards omdistribueras i händelse av nodfel, tillåter tjänsten att överlevande noder inte överbelastas av shards som tidigare var värd på den misslyckade noden. Detta är särskilt viktigt för Multi-AZ-domäner för att ge konsekvent och förutsägbar klusterprestanda.
Om du vill ha mer bakgrund om shard allokeringslogik i allmänhet, se Avmystifierande Elasticsearch shard tilldelning.
Utmaningen
En Amazon OpenSearch Service-domän sägs vara "balanserad" när antalet noder är jämnt fördelat över konfigurerade tillgänglighetszoner, och det totala antalet shards är fördelat lika över alla tillgängliga noder utan koncentration av shards av något index på någon nod. OpenSearch har också en egenskap som heter "Zone Awareness" som, när den är aktiverad, säkerställer att den primära skärvan och dess motsvarande replika allokeras i olika tillgänglighetszoner. Om du har mer än en kopia av data ger det bättre feltolerans och tillgänglighet att ha flera tillgänglighetszoner. I händelse av att domänen skalas ut eller skalas in eller under fel på nod(er), omfördelar OpenSearch automatiskt skärvorna mellan tillgängliga noder samtidigt som man följer tilldelningsreglerna baserade på zonmedvetenhet.
Medan shard-balanseringsprocessen säkerställer att shards är jämnt fördelade över tillgänglighetszoner, i vissa fall, om det uppstår ett oväntat fel i en enskild zon, kommer shards att omfördelas till de överlevande noderna. Detta kan leda till att de överlevande noderna blir överväldigade, vilket påverkar klusterstabiliteten.
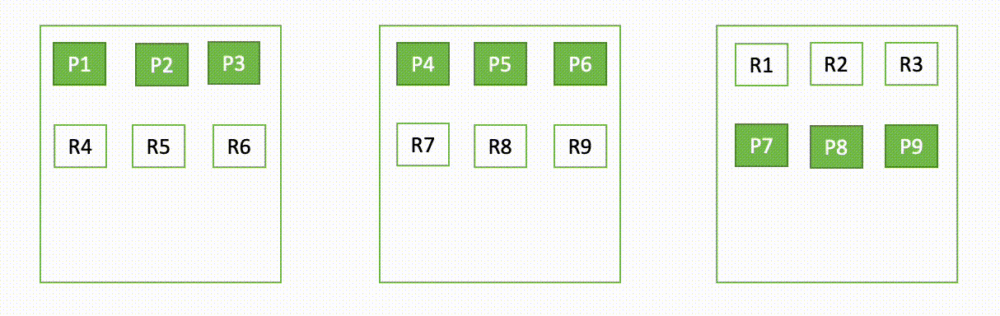
Till exempel, om en nod i ett trenodskluster går ner, omfördelar OpenSearch de otilldelade skärvorna, som visas i följande diagram. Här representerar "P" en primär skärvkopia, medan "R" representerar en replika skärvkopia.

Detta beteende hos domänen kan förklaras i två delar – under fel och under återställning.
Under misslyckande
En domän som distribueras över flera tillgänglighetszoner kan stöta på flera typer av fel under sin livscykel.
Komplett zonfel
Ett kluster kan förlora en enda tillgänglighetszon på grund av en mängd olika anledningar och även alla noder i den zonen. Idag försöker tjänsten placera de förlorade noderna i de återstående sunda tillgänglighetszonerna. Tjänsten försöker också återskapa de förlorade skärvorna i de återstående noderna samtidigt som allokeringsreglerna följer. Detta kan resultera i vissa oavsiktliga konsekvenser.
- När skärvorna från den påverkade zonen omfördelas till friska zoner utlöser de återställning av skärvor som kan öka latenserna eftersom det förbrukar ytterligare CPU-cykler och nätverksbandbredd.
- För en n-AZ, n-copy setup, (n>1), tilldelas de överlevande n-1 tillgänglighetszonerna med den n:te skärvkopian, vilket kan vara oönskat eftersom det kan orsaka skevhet i skärvfördelningen, vilket också kan resultera i obalanserad trafik över noder. Dessa noder kan bli överbelastade, vilket leder till ytterligare fel.
Delvis zonfel
I händelse av ett partiellt zonfel eller när domänen bara förlorar några av noderna i en tillgänglighetszon, försöker Amazon OpenSearch Service ersätta de misslyckade noderna så snabbt som möjligt. Men om det tar för lång tid att ersätta noderna, försöker OpenSearch att allokera de otilldelade skärvorna i den zonen till de överlevande noderna i tillgänglighetszonen. Om tjänsten inte kan ersätta noderna i den påverkade tillgänglighetszonen kan den allokera dem i den andra konfigurerade tillgänglighetszonen, vilket ytterligare kan skeva fördelningen av skärvor både över och inom zonen. Detta får återigen oavsiktliga konsekvenser.
- Om noderna på domänen inte har tillräckligt med lagringsutrymme för att rymma de ytterligare skärvorna, kan domänen skrivblockeras, vilket påverkar indexeringen.
- På grund av den skeva fördelningen av shards kan domänen också uppleva skev trafik över noderna, vilket ytterligare kan öka latenserna eller timeouts för läs- och skrivoperationer.
Återvinning
Idag, för att bibehålla domänens önskade nodantal, lanserar Amazon OpenSearch Service datanoder i de återstående hälsosamma tillgänglighetszonerna, liknande scenarierna som beskrivs i felavsnittet ovan. För att säkerställa korrekt nodfördelning över alla tillgänglighetszoner efter en sådan incident behövdes manuell ingripande av AWS.
Vad förändras
För att förbättra den övergripande felhanteringen och minimera inverkan av fel på domänens hälsa och prestanda, utför Amazon OpenSearch Service följande ändringar:
- Forcerad zonmedvetenhet: OpenSearch har en redan existerande konfiguration för shard-balansering som kallas forcerad medvetenhet som används för att ställa in de tillgänglighetszoner till vilka shards måste allokeras. Till exempel, om du har ett medvetenhetsattribut som heter zon och konfigurerar noder i
zone1ochzone2, kan du använda påtvingad medvetenhet för att förhindra OpenSearch från att tilldela repliker om bara en zon är tillgänglig:
Med denna exempelkonfiguration, om du startar två noder med node.attr.zone satt till zone1 och skapa ett index med fem skärvor och en replik, skapar OpenSearch indexet och allokerar de fem primära skärvorna men inga repliker. Repliker tilldelas endast en gång noder med node.attr.zone satt till zone2 finns tillgängliga.
Amazon OpenSearch Service kommer att använda den påtvingade medvetenhetskonfigurationen på Multi-AZ-domäner för att säkerställa att skärvor endast allokeras enligt reglerna för zonmedvetenhet. Detta skulle förhindra den plötsliga ökningen av belastningen på noderna i de friska tillgänglighetszonerna.
- Belastningsmedveten Shard Allocation: Amazon OpenSearch Service kommer att ta hänsyn till faktorer som tillhandahållen kapacitet, faktisk kapacitet och totala skärvor för att beräkna om någon nod är överbelastad med fler skärvor baserat på förväntade genomsnittliga skärvor per nod. Det skulle förhindra skärvtilldelning när någon nod har allokerat ett skärvtal som går utöver denna gräns.
Anmärkningar att alla otilldelade primär kopiering skulle fortfarande tillåtas på den överbelastade noden för att förhindra klustret från någon överhängande dataförlust.
På samma sätt, för att lösa problemet med manuell återställning (som beskrivs i avsnittet Återställning ovan), gör Amazon OpenSearch Service också ändringar i sin interna skalningskomponent. Med de nyare ändringarna på plats kommer Amazon OpenSearch Service inte att starta noder i de återstående tillgänglighetszonerna även när den går igenom det tidigare beskrivna felscenariot.
Visualisera det nuvarande och nya beteendet
Till exempel är en Amazon OpenSearch Service-domän konfigurerad med 3-AZ, 6 datanoder, 12 primära shards och 24 replika shards. Domänen tillhandahålls över AZ-1, AZ-2 och AZ-3, med två noder i var och en av zonerna.
Nuvarande skärvtilldelning:
Totalt antal skärvor: 12 primära + 24 repliker = 36 skärvor
Antal tillgänglighetszoner: 3
Antal skärvor per zon (zonmedvetenhet är sant): 36/3 = 12
Antal noder per tillgänglighetszon: 2
Antal skärvor per nod: 12/2 = 6
Följande diagram ger en visuell representation av domäninställningen. Cirklarna anger antalet skärvor som allokerats till noden. Amazon OpenSearch Service kommer att tilldela sex skärvor per nod.

Under ett partiellt zonfel, där en nod i AZ-3 misslyckas, tilldelas den misslyckade noden till den återstående zonen, och skärvorna i zonen omfördelas baserat på tillgängliga noder. Efter ändringarna som beskrivs ovan kommer klustret inte att skapa en ny nod eller omfördela skärvor efter att noden misslyckats.

I diagrammet ovan, med förlusten av en nod i AZ-3, skulle Amazon OpenSearch Service försöka starta ersättningskapaciteten i samma zon. Men på grund av ett avbrott kan zonen vara försämrad och skulle misslyckas med att starta ersättningen. I en sådan händelse försöker tjänsten lansera underskottskapacitet i en annan hälsosam zon, vilket kan leda till zonobalans över tillgänglighetszoner. Skärvor på den drabbade zonen stoppas på den överlevande noden i samma zon. Men med det nya beteendet skulle tjänsten försöka lansera kapacitet i samma zon men skulle undvika att lansera underskottskapacitet i andra zoner för att undvika obalans. Shard allocator skulle också säkerställa att de överlevande noderna inte blir överbelastade.

På liknande sätt, om alla noder i AZ-3 går förlorade, eller AZ-3 blir försämrad, tar Amazon OpenSearch Service upp de förlorade noderna i den återstående tillgänglighetszonen och omfördelar också skärvorna på noderna. Efter de nya ändringarna kommer Amazon OpenSearch Service dock inte att allokera noder till den återstående zonen eller så kommer den att försöka omfördela förlorade skärvor till den återstående zonen. Amazon OpenSearch Service väntar på att återställningen ska ske och på att domänen återgår till den ursprungliga konfigurationen efter återställning.
Om din domän inte tillhandahålls med tillräckligt med kapacitet för att motstå förlusten av en tillgänglighetszon, kan du uppleva en minskning av genomströmningen för din domän. Det rekommenderas därför starkt att följa de bästa metoderna när du dimensionerar din domän, vilket innebär att du har tillräckligt med resurser för att motstå förlusten av ett enstaka fel i tillgänglighetszonen.

För närvarande, när domänen återställs, kräver tjänsten manuellt ingripande för att balansera kapaciteten över tillgänglighetszoner, vilket också involverar skärvrörelser. Men med det nya beteendet behövs inget ingripande under återhämtningsprocessen eftersom kapaciteten återgår i den påverkade zonen och skärvorna också automatiskt allokeras till de återställda noderna. Detta säkerställer att det inte finns några konkurrerande prioriteringar på de återstående resurserna.
Vad du kan förvänta dig
När du har uppdaterat din Amazon OpenSearch Service-domän till den senaste versionen av serviceprogramvara, de domäner som har varit konfigurerad med bästa praxis kommer att ha mer förutsägbar prestanda även efter att en eller flera datanoder förlorats i en tillgänglighetszon. Det kommer att finnas minskade fall av överallokering av skärvor i en nod. Det är en god praxis att tillhandahålla tillräcklig kapacitet för att kunna tolerera ett fel i en enskild zon
Du kan ibland se en domän bli gul under sådana oväntade fel eftersom vi inte kommer att tilldela replikskärvor till överbelastade noder. Detta betyder dock inte att det blir dataförlust i en välkonfigurerad domän. Vi kommer fortfarande att se till att alla primärval tilldelas under avbrotten. Det finns en automatisk återställning på plats, som kommer att ta hand om att balansera noderna i domänen och säkerställa att replikerna tilldelas när felet återställs.
Uppdatera tjänstemjukvaran för din Amazon OpenSearch Service-domän för att få dessa nya ändringar tillämpade på din domän. Mer information om uppdateringsprocessen för tjänstens programvara finns i Amazon OpenSearch Service-dokumentation.
Slutsats
I det här inlägget såg vi hur Amazon OpenSearch Service nyligen förbättrade logiken för att distribuera noder och skärvor över tillgänglighetszoner under zonavbrott.
Denna förändring kommer att hjälpa tjänsten att säkerställa mer konsekvent och förutsägbar prestanda under nod- eller zonfel. Domäner kommer inte att se några ökade latenser eller skrivblockeringar under bearbetning av skrivningar och läsningar, som ibland dök upp tidigare på grund av överallokering av shards på noder.
Om författarna
 Bukhtawar Khan är en senior mjukvaruingenjör som arbetar på Amazon OpenSearch Service. Han är intresserad av distribuerade och autonoma system. Han är en aktiv bidragsgivare till OpenSearch.
Bukhtawar Khan är en senior mjukvaruingenjör som arbetar på Amazon OpenSearch Service. Han är intresserad av distribuerade och autonoma system. Han är en aktiv bidragsgivare till OpenSearch.
 Anshu Agarwal är en senior mjukvaruingenjör som arbetar med AWS OpenSearch på Amazon Web Services. Hon brinner för att lösa problem relaterade till att bygga skalbara och mycket pålitliga system.
Anshu Agarwal är en senior mjukvaruingenjör som arbetar med AWS OpenSearch på Amazon Web Services. Hon brinner för att lösa problem relaterade till att bygga skalbara och mycket pålitliga system.
 Shourya Dutta Biswas är en mjukvaruingenjör som arbetar med AWS OpenSearch på Amazon Web Services. Han brinner för att bygga mycket motståndskraftiga distribuerade system.
Shourya Dutta Biswas är en mjukvaruingenjör som arbetar med AWS OpenSearch på Amazon Web Services. Han brinner för att bygga mycket motståndskraftiga distribuerade system.
 Rishab Nahata är en mjukvaruingenjör som arbetar med OpenSearch på Amazon Web Services. Han är fascinerad av att lösa problem i distribuerade system. Han är aktiv bidragsgivare till OpenSearch.
Rishab Nahata är en mjukvaruingenjör som arbetar med OpenSearch på Amazon Web Services. Han är fascinerad av att lösa problem i distribuerade system. Han är aktiv bidragsgivare till OpenSearch.
 Ranjith Ramachandra är en ingenjörschef som arbetar på Amazon OpenSearch Service på Amazon Web Services.
Ranjith Ramachandra är en ingenjörschef som arbetar på Amazon OpenSearch Service på Amazon Web Services.
 Jon Handler är en Senior Principal Solutions Architect, specialiserad på AWS-sökteknologier – Amazon CloudSearch och Amazon OpenSearch Service. Baserad i Palo Alto hjälper han ett brett spektrum av kunder att få sina sök- och logganalysarbetsbelastningar att installeras rätt och fungera väl.
Jon Handler är en Senior Principal Solutions Architect, specialiserad på AWS-sökteknologier – Amazon CloudSearch och Amazon OpenSearch Service. Baserad i Palo Alto hjälper han ett brett spektrum av kunder att få sina sök- och logganalysarbetsbelastningar att installeras rätt och fungera väl.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/impact-of-infrastructure-failures-on-shard-in-amazon-opensearch-service/
- 1
- 10
- 100
- 7
- 9
- a
- Able
- Om oss
- ovan
- rymma
- Enligt
- tvärs
- aktiv
- Annat
- adress
- Efter
- Alla
- allokeras
- allokerar
- fördelning
- amason
- Amazon Web Services
- analytics
- och
- Annan
- Ansökan
- tillämpas
- delad
- attribut
- Automatiserad
- automatiskt
- autonom
- tillgänglighet
- tillgänglig
- genomsnitt
- medvetenhet
- AWS
- bakgrund
- Balansera
- Bandbredd
- baserat
- därför att
- blir
- BÄST
- bästa praxis
- Bättre
- mellan
- Bortom
- Block
- Bringar
- bred
- Byggnad
- kallas
- Kan få
- kan inte
- kapacitet
- Kapacitet
- vilken
- Vid
- fall
- Orsak
- byta
- Förändringar
- cirklar
- cloud
- kluster
- tävlande
- komponent
- koncentration
- konfiguration
- Konsekvenser
- övervägande
- konsekvent
- bidragsgivare
- Motsvarande
- skapa
- skapar
- Aktuella
- Kunder
- cykler
- datum
- dataförlust
- UNDERSKOTT
- distribuera
- utplacerade
- beskriven
- detaljer
- olika
- distribuera
- distribueras
- distribuerade system
- fördelning
- domän
- domäner
- inte
- ner
- Drop
- under
- varje
- Tidigare
- ingenjör
- Teknik
- tillräckligt
- säkerställa
- säkerställer
- säkerställa
- lika
- speciellt
- Eter (ETH)
- Även
- händelse
- exempel
- förväntat
- erfarenhet
- förklarade
- faktorer
- MISSLYCKAS
- Misslyckades
- misslyckas
- Misslyckande
- följer
- efter
- kraft
- från
- funktion
- ytterligare
- Allmänt
- skaffa sig
- få
- gif
- Går
- god
- Arbetsmiljö
- hända
- har
- Hälsa
- friska
- hjälpa
- hjälper
- här.
- höggradigt
- värd
- Hur ser din drömresa ut
- Men
- html
- HTTPS
- obalans
- Inverkan
- påverkade
- med Esport
- förbättra
- förbättras
- in
- I andra
- incident
- Öka
- ökat
- index
- Infrastruktur
- infrastruktur
- exempel
- interaktiva
- intresserad
- inre
- ingripande
- fråga
- IT
- senaste
- lansera
- lanserar
- lansera
- leda
- ledande
- Legacy
- BEGRÄNSA
- läsa in
- Lång
- förlorar
- förlorar
- förlora
- förlust
- bibehålla
- göra
- GÖR
- Framställning
- förvaltade
- chef
- manuell
- många
- betyder
- kanske
- minimerande
- övervakning
- mer
- rörelser
- multipel
- Behöver
- Varken
- nät
- Nya
- nod
- Nodfördelning
- noder
- antal
- erbjuda
- ONE
- driva
- drift
- Verksamhet
- beställa
- ursprungliga
- Övriga
- strömavbrott
- avbrott
- övergripande
- överväldigad
- Palo Alto
- reservdelar till din klassiker
- brinner
- utföra
- prestanda
- utför
- Plats
- plato
- Platon Data Intelligence
- PlatonData
- snälla du
- möjlig
- Inlägg
- drivs
- praktiken
- praxis
- Förutsägbar
- förhindra
- tidigare
- primär
- Principal
- problem
- process
- bearbetning
- rätt
- egenskapen
- ge
- ger
- tillhandahållande
- snabbt
- område
- Läsa
- realtid
- skäl
- nyligen
- rekommenderas
- återhämtar
- återvinning
- Minskad
- reducerande
- relaterad
- frigöra
- pålitlig
- Återstående
- ersätta
- svara
- representation
- representerar
- Kräver
- elastisk
- Resurser
- resultera
- avkastning
- återgår
- regler
- Nämnda
- Samma
- skalbar
- Skala
- skalning
- scenarier
- Sök
- §
- säkra
- service
- Tjänster
- in
- inställning
- visas
- liknande
- eftersom
- enda
- SEX
- skev
- So
- Mjukvara
- Programvara ingenjör
- Lösningar
- Lösa
- några
- Utrymme
- specialiserat
- Stabilitet
- starta
- Fortfarande
- förvaring
- starkt
- sådana
- plötslig
- tillräcklig
- stödja
- yta
- System
- Ta
- tar
- Tekniken
- Smakämnen
- deras
- därför
- Genom
- genomströmning
- gånger
- till
- i dag
- tolerans
- alltför
- Totalt
- trafik
- utlösa
- sann
- Vrida
- typer
- Oväntat
- Uppdatering
- uppdaterad
- användning
- Värden
- mängd
- visualisering
- vänta
- webb
- webbservice
- Webbplats
- som
- medan
- kommer
- inom
- utan
- arbetssätt
- skulle
- skriva
- Din
- zephyrnet
- zoner