Introduktion till automatiserat maskininlärning
AutoML gör det möjligt för utvecklare med begränsad ML-expertis (och kodningserfarenhet) att utbilda modeller av hög kvalitet som är specifika för deras affärsbehov. I den här artikeln kommer vi att fokusera på AutoML -system som tillgodoser vardagliga affärs- och teknikapplikationer.

Vad är AutoML -system?
Maskininlärning (ML) - som ett underfält till den bredare domänen Artificiell intelligens (AI) - tar över alla typer av branscher och affärsområden. Detta inkluderar detaljhandel, sjukvård, bil, finans, underhållning och mer. Med detta bredare antagande inom alla typer av verksamheter och av en personalstyrka med en mängd olika färdigheter blir det allt viktigare att lära sig hur man arbetar med maskininlärning.
På grund av denna expansion av ML -användningen av ständigt ökande tvärsnitt av anställda i en organisation, har det blivit avgörande att utveckla system som kan användas av företagare med alla möjliga bakgrunder. Och det betyder dessa system kan inte enbart vara kodnings- eller programmeringsorienterad som de som används av mjukvaruutvecklare eller datavetenskapare.
Det är här AutoML -systemen kommer in i bilden.
Kort sagt, AutoML möjliggör utvecklare med begränsad ML -expertis (och kodningsupplevelse) för att träna högkvalitativa modeller som är specifika för deras företag behov. Det finns andra aspekter av AutoML från akademisk forskningssynpunkt (dvs. att söka efter de bästa ML -algoritmerna för givna datatyper och bevisa teoretiska egenskaper om sådana system); men för den här artikeln kommer vi att fokusera på AutoML -system som tillgodoser vardagliga affärs- och teknikapplikationer.
Varför blir AutoML -system populära?
Som nämnts ovan kommer proffs från alla möjliga bakgrunder och färdigheter inom datavetenskap och maskininlärning för sina respektive verksamheter eller FoU -aktiviteter. Alla har inte en noggrann bakgrund eller formell utbildning i statistikvetenskap eller maskininlärningsteori.
De behöver bara kunna hämta eller ta in en datauppsättning, följa ett fullständigt datautforsknings- och modellutbildningsarbetsflöde och producera en utbildad modell för en ML -applikation nedströms.
Det skulle vara mer tidskrävande från deras sida om de måste göra allt detta själva:
- sök igenom alla möjliga ML -algoritmer,
- utvärdera dem på utbildningsdataset,
- kontrollera valideringsuppsättningens prestanda på ett noggrant sätt,
- tillämpa ytterligare bedömning (minne och CPU -fotavtryck) för att välja den bästa modellen för slutapplikationen.
AutoML -system gör i stor utsträckning allt detta tunga lyft för datavetenskapare eller analytiker och automatisera eller effektivisera generationen av mycket optimerade utbildade ML-modeller för produktionsklar användning.
Följaktligen blir dessa system allt populärare bland organisationer som använder stor datavetenskap eftersom de:
- spara organisationens arbetskraftskostnader och personalstyrka, eftersom en relativt smal arbetskraft kan använda sådana system för att utbilda och optimera ett stort antal ML -modeller
- minska risken för fel genom att inte bara automatisera modellutbildningen och optimeringen utan också de så kallade tråkiga aspekterna av datavetenskap (dvs dataintag, analys, krångling och utforskning av funktioner i stor utsträckning)
- minska time-to-market för en stor andel ML-drivna applikationer med en relativt högpresterande standard
När det gäller time-to-market kan man hävda att det slutliga resultatet som produceras av ett AutoML-system kanske inte är lika performant eller optimerat som det som arkitekterats av en expert ML-ingenjör (med hjälp av handgjorda funktionstekniker eller djupinlärningsinställning) ).
Men den här typen av handjustering är ofta en tidskrävande process och för de flesta situationer är det mycket mer kritiskt för en organisation att gå till en produktionsklar status med en anständig ML-modell på relativt kortare tid än att slösa tid på att producera den absolut bäst presterande modellen. AutoML -system hjälper organisationer att uppnå detta kritiska affärsmål, därav dess växande popularitet och bredare antagande.
Nu kan organisationer helt enkelt få anpassade maskininlärningsstationer för deras personalstyrka, installera verktygen som AutoML för att snabbt snurra upp ett arbetsmaskininlärningsbaserat system och gå vidare med nästa steg i AI-klar produktion för att gå till marknaden med sina resultat snabbare än någonsin.
Typer av AutoML -system och några framstående exempel
Det finns ganska många olika typer av AutoML -system eftersom de tillgodoser olika kategorier av uppgifter i ett datavetenskap eller ML -arbetsflöde.
Vissa typer av AutoML -system inkluderar:
- AutoML för automatiserad parameterinställning (en relativt grundläggande typ)
- AutoML för icke-djupt lärande, till exempel Auto-Sklearn. Denna typ tillämpas huvudsakligen i dataförbehandling, automatiserad funktionsanalys, automatiserad funktionsdetektering, automatiskt funktionsval och automatiskt modellval.
- AutoML för djupinlärning/ neurala nätverk, inklusive system som är speciellt utformade för neuralarkitektursökning (NAS) samt verktygspaket som t.ex. AutoKeras byggd ovanpå det mycket populära ramverket för djupinlärning.
Auto-Sklearn
Som namnet antyder är Auto-Sklearn ett automatiskt maskininlärningsprogram som är byggt på scikit-learn. Auto-Sklearn befriar en datavetenskapare från algoritmval och hyperparameterinställning. I huvudsak söker den automatiskt efter rätt inlärningsalgoritm för en ny datamaskininlärningsdataset och optimerar dess hyperparametrar.
Det utökar tanken på att konfigurera ett allmänt ramverk för maskininlärning med effektiv global optimering som introducerades med Auto-WEKA. För att förbättra generaliseringen bygger Auto-Sklearn en ensemble av alla modeller testats under den globala optimeringsprocessen. För att påskynda optimeringsprocessen använder Auto-Sklearn metalärande för att identifiera liknande datamängder och använda kunskap som samlats in tidigare.
Den innehåller funktionstekniska metoder som t.ex. en-het kodning, standardisering av digitala funktioner och analys av huvudkomponenter (PCA). I grunden använder biblioteket scikit-learn-uppskattare för att bearbeta klassificerings- och regressionsproblem.

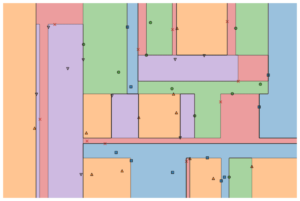
Auto-Sklearn arbetsflöde och diagram
Dokumentation: Du kan hitta detaljerad dokumentation här.
Kodsexempel: Här visar vi ett grundläggande exempel på klassificering av uppgiftskod med Auto-Sklearn. Vi bygger en ML-modell för att klassificera de numeriska siffrorna med hjälp av en inbyggd dataset i paketet scikit-learn.
import autosklearn.classification
import sklearn.model_selection
import sklearn.datasets
import sklearn.metrics if __name__ == "__main__": X, y = sklearn.datasets.load_digits(return_X_y=True) X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, random_state=1) automl = autosklearn.classification.AutoSklearnClassifier() automl.fit(X_train, y_train) y_hat = automl.predict(X_test) print("Accuracy score", sklearn.metrics.accuracy_score(y_test, y_hat))Obs om OS: Auto-Sklearn är starkt beroende av Python-modulresursen. Denna modul är en del av Pythons Unix Specific Services och är inte tillgänglig på en Windows -maskin. Från och med idag är det därför inte möjligt att köra auto-sklearn på en Windows-maskin.
Möjliga lösningar:
- Windows 10 bash shell (se 431 och 860 för förslag)
- Virtuell maskin
- Docker-bild
MLBox

MLBox är ett kraftfullt automatiserat maskininlärningspythonbibliotek. Enligt den officiella dokumentationen innehåller den följande funktioner:
- Snabb läsning och distribuerad dataförbehandling/rengöring/formatering
- Mycket robust funktionsval och läckagedetektering samt exakt hyperparameteroptimering
- Toppmoderna prediktiva modeller för klassificering och regression (Deep Learning, Stacking, LightGBM)
- Förutsägelse med modelltolkning
- MLBox har testats på Kaggle och visar bra prestanda
- Rörledning byggnad
TPOT

TPOT är ett Python Automated Machine Learning -verktyg som optimerar maskininlärningspipelines med hjälp av genetisk programmering. Det är också byggt ovanpå scikit-learn.

Exempel på TPOT -pipeline (från https://epistasislab.github.io/tpot/)
Dokumentation: Här är dokumentationslänk.
Kodexempel:
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64), iris.target.astype(np.float64), train_size=0.75, test_size=0.25, random_state=42) tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_iris_pipeline.py')
AutoKeras
AutoKeras är ett bibliotek med öppen källkod för automatiserat maskininlärning som utvecklats av DATA Lab vid Texas A&M University. Byggd ovanpå ramarna för djupinlärning Keras, AutoKeras tillhandahåller funktioner för att automatiskt söka efter arkitektur och hyperparametrar för djupinlärningsmodeller.
AutoKeras följer den klassiska scikit-learn API-designen och är därför lätt att använda. Målet med denna ram är att förenkla ML -praxis och forskning med hjälp av automatisk Neural Architecture Search (NAS) algoritmer.
Dokumentation: Här är detaljerad dokumentationslänk.
Kodexempel: Här är ett exempelkodsexempel för MNIST -bildklassificeringsuppgiften.
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import mnist
import autokeras as ak # Data loading
(x_train, y_train), (x_test, y_test) = mnist.load_data() # Initialize the image classifier.
clf = ak.ImageClassifier(overwrite=True, max_trials=1)
# Feed the image classifier with training data.
clf.fit(x_train, y_train, epochs=10) # Predict with the best model.
predicted_y = clf.predict(x_test)
print(predicted_y) # Evaluate the best model with testing data.
print(clf.evaluate(x_test, y_test))Sammanfattning av AutoML -system och deras betydelse
I den här artikeln började vi med att förklara kärnidén bakom automatiserade ML-ramverk, eller de så kallade AutoML-systemen. Vi beskrev deras användbarhet och varför de får grepp i olika affärs- och teknikorganisationer. Vi visade också upp några framstående AutoML -bibliotek och ramverk med relevanta exempel och arkitekturillustrationer efter behov.
Att lära sig om dessa kraftfulla ramar kommer att vara till nytta för alla kommande datavetenskapare eftersom de kommer att fortsätta att växa i kapacitet och utbredd användning.
Låt oss veta om alla ämnen du är intresserad av genom att släppa en kommentar nedan, eller gärna kontakta oss när som helst med frågor du har.
Bio: Kevin Vu hanterar Exxact Corp -bloggen och arbetar med många av dess begåvade författare som skriver om olika aspekter av Deep Learning.
Ursprungliga. Skickas om med tillstånd.
Relaterat:
| Topphistorier de senaste 30 dagarna | |||||
|---|---|---|---|---|---|
|
|
||||
Källa: https://www.kdnuggets.com/2021/09/introduction-automated-machine-learning.html
- "
- &
- 9
- Absolut
- aktiviteter
- Annat
- Antagande
- AI
- algoritm
- algoritmer
- Alla
- bland
- analys
- api
- Ansökan
- tillämpningar
- appar
- arkitektur
- Konst
- Artikeln
- artificiell intelligens
- Konstgjord intelligens (AI)
- Författarna
- bil
- Automatiserad
- automatiserad maskininlärning
- fordonsindustrin
- BÄST
- Blogg
- SLUTRESULTAT
- Byggnad
- företag
- klassificering
- koda
- Kodning
- kommande
- Gemensam
- komponent
- fortsätta
- Corp
- datum
- datavetenskap
- datavetare
- djupt lärande
- Designa
- Detektering
- utveckla
- utvecklare
- digital
- siffror
- domäner
- anställda
- ingenjör
- Teknik
- Ingenjörer
- Underhållning
- excel
- expansionen
- erfarenhet
- utforskning
- Leverans
- Funktioner
- Figur
- finansiering
- Förnamn
- Fokus
- följer
- Framåt
- Ramverk
- Fri
- Allmänt
- GitHub
- Välgörenhet
- god
- Väx
- hälso-och sjukvård
- här.
- Hur ser din drömresa ut
- How To
- HTTPS
- Tanken
- identifiera
- bild
- Inklusive
- industrier
- Intelligens
- IT
- Keras
- Large
- läckage
- inlärning
- Bibliotek
- Begränsad
- maskininlärning
- marknad
- Metrics
- Microsoft
- ML
- ML-algoritmer
- modell
- flytta
- nätverk
- neural
- neurala nätverk
- tjänsteman
- Verksamhet
- beställa
- Övriga
- prestanda
- Bild
- Synvinkel
- Populära
- inlägg
- Principal
- producerad
- Produktion
- yrkesmän/kvinnor
- Programmering
- projektet
- Python
- R&D
- RE
- Läsning
- regression
- forskning
- resurs
- Resultat
- detaljhandeln
- Körning
- Vetenskap
- VETENSKAPER
- vetenskapsmän
- Sök
- Tjänster
- in
- Shell
- Kort
- färdigheter
- Mjukvara
- Lösningar
- fart
- Snurra
- igång
- status
- Upplevelser för livet
- system
- System
- Målet
- Teknologi
- tensorflow
- Testning
- texas
- tid
- topp
- ämnen
- Utbildning
- us
- verktyg
- utsikt
- webb
- VEM
- fönster
- Arbete
- arbetsflöde
- arbetskraft
- fungerar
- X