Beskrivning
Inom området akademisk forskning kan resan från rådata till insiktsfulla slutsatser vara skrämmande om du är nybörjare eller nybörjare. Men med rätt tillvägagångssätt och verktyg är det en oerhört givande upplevelse att omvandla data till meningsfull kunskap. I den här guiden går vi igenom ett typiskt arbetsflöde för akademisk dataanalys, med hjälp av ett praktiskt exempel från en nyligen genomförd studie om effektiviteten av olika dieter på viktminskning.

Innehållsförteckning
Lärande mål
Vi kommer att använda en avancerad AI-dataverktyg - Julius, för att utföra analysen. Vårt mål är att avmystifiera den akademiska forskningsanalysprocessen och visa hur data, när den noggrant och korrekt analyseras, kan belysa fascinerande trender och ge svar på kritiska forskningsfrågor.
Navigera i det akademiska dataarbetsflödet med Julius
Inom akademisk forskning är sättet vi hanterar data på nyckeln till att avslöja nya insikter. Den här delen av vår guide leder dig genom standardstegen för att analysera forskningsdata. Från att börja med en tydlig fråga till att dela slutresultaten är varje steg avgörande.
Vi kommer att visa hur forskare, genom att följa denna tydliga väg, kan förvandla rådata till pålitliga och värdefulla resultat. Sedan går vi igenom varje steg i ett exempel på fallstudie, och visar dig hur du sparar tid samtidigt som du säkerställer resultat av högre kvalitet genom att använda Julius under hela processen.
1. Frågeformulering
Börja med att tydligt definiera din forskningsfråga eller hypotes. Detta vägleder hela analysen och bestämmer vilka metoder du kommer att använda.
2. Datainsamling
Samla in nödvändig data och se till att den stämmer överens med din forskningsfråga. Det kan handla om att samla in ny data eller använda befintliga datauppsättningar. Data bör innehålla variabler som är relevanta för din studie.
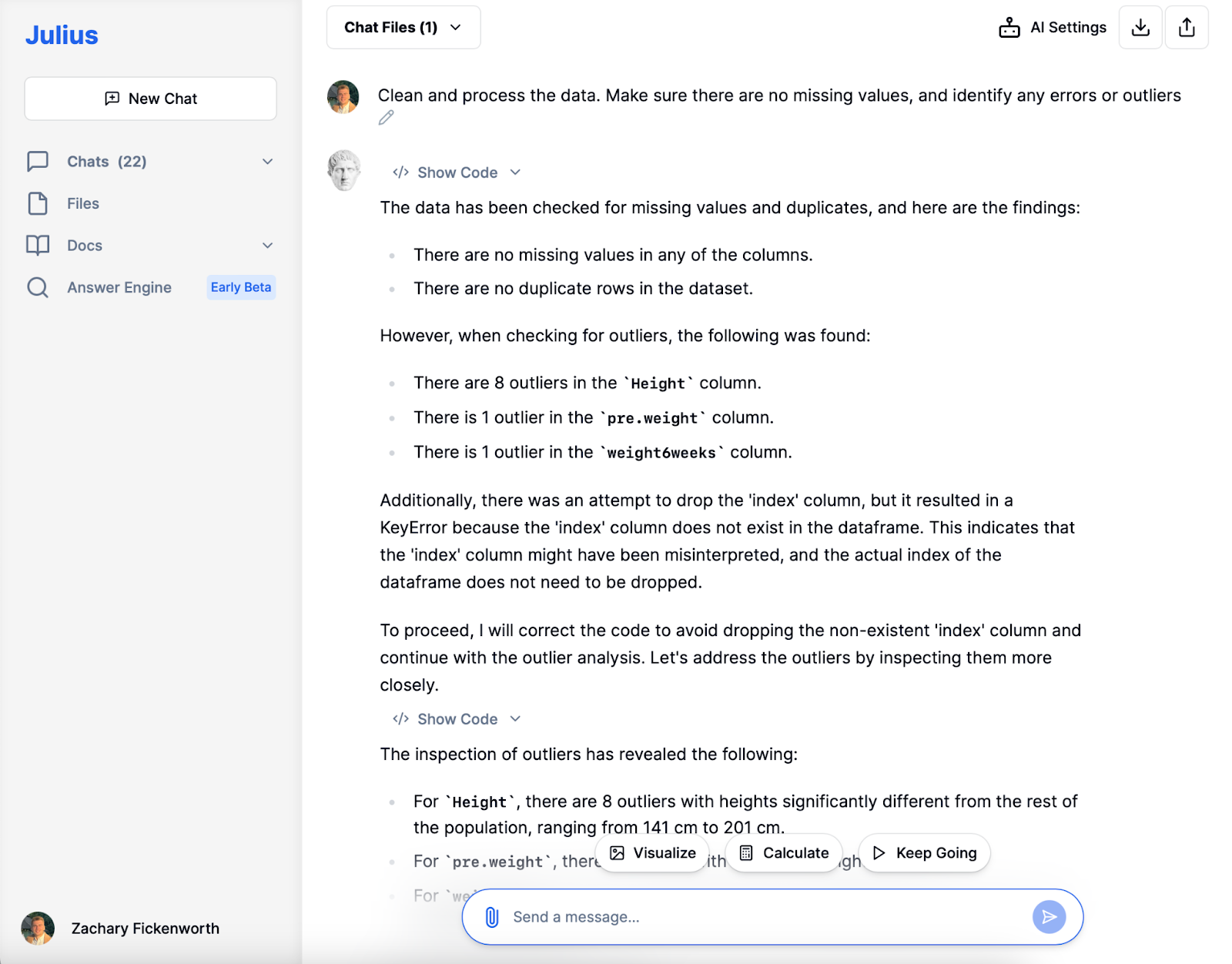
3. Datarening och förbearbetning
Förbered din datauppsättning för analys. Det här steget innebär att säkerställa datakonsistens (som standardiserade måttenheter), hantera saknade värden och identifiera eventuella fel eller extremvärden i din data.
4. Exploratory Data Analysis (EDA)
Gör en första granskning av uppgifterna. Detta inkluderar att analysera fördelningen av variabler, identifiera mönster eller extremvärden och förstå egenskaperna hos din datauppsättning.
5. Val av metod
- Fastställande av analystekniker: Välj lämpliga statistiska metoder eller modeller baserat på din data och din forskningsfråga. Detta kan innebära att jämföra grupper, identifiera relationer eller förutsäga resultat.
- Överväganden för val av metod: Urvalet påverkas av typen av data (t.ex. kategorisk eller kontinuerlig), antalet grupper som jämförs och arten av de relationer du undersöker.
6. Statistisk analys
- Operationaliserande variabler: Om det behövs, skapa nya variabler som bättre representerar de begrepp du studerar.
- Utföra statistiska tester: Använd de valda statistiska metoderna för att analysera dina data. Detta kan innebära tester som t-tester, ANOVA, regressionsanalys, etc.
- Redovisning för kovariater: I mer komplexa analyser, inkludera andra relevanta variabler för att kontrollera deras potentiella effekter.
7. Tolkning
Tolka resultaten noggrant i samband med din forskningsfråga. Det handlar om att förstå vad de statistiska resultaten betyder i praktiken och att överväga eventuella begränsningar.
8. rapportering
Sammanställ dina resultat, metodik och tolkningar till en omfattande rapport eller akademisk uppsats. Detta bör vara tydligt, kortfattat och välstrukturerat för att effektivt kommunicera din forskning.
Fallstudie Introduktion
I den här fallstudien undersöker vi hur olika dieter påverkar viktminskning. Vi har data inklusive ålder, kön, startvikt, diettyp och vikt efter sex veckor. Vårt mål är att ta reda på vilka dieter som är mest effektiva för viktminskning, med hjälp av riktiga data från riktiga människor.
Frågeformulering
I all forskning, som vår studie om dieter och viktminskning, börjar allt med en bra fråga. Det är som en färdplan för din forskning, som vägleder dig om vad du ska fokusera på.
Till exempel, med våra kostdata frågade vi, Leder en specifik diet till betydande viktminskning på sex veckor?
Den här frågan är okomplicerad och berättar exakt vad vi behöver leta efter i vår data, som inkluderar detaljer som varje persons diettyp, vikt före och efter sex veckor, ålder och kön. En tydlig fråga som denna ser till att vi håller oss på rätt spår och tittar på rätt saker i vår data för att hitta de svar vi behöver.
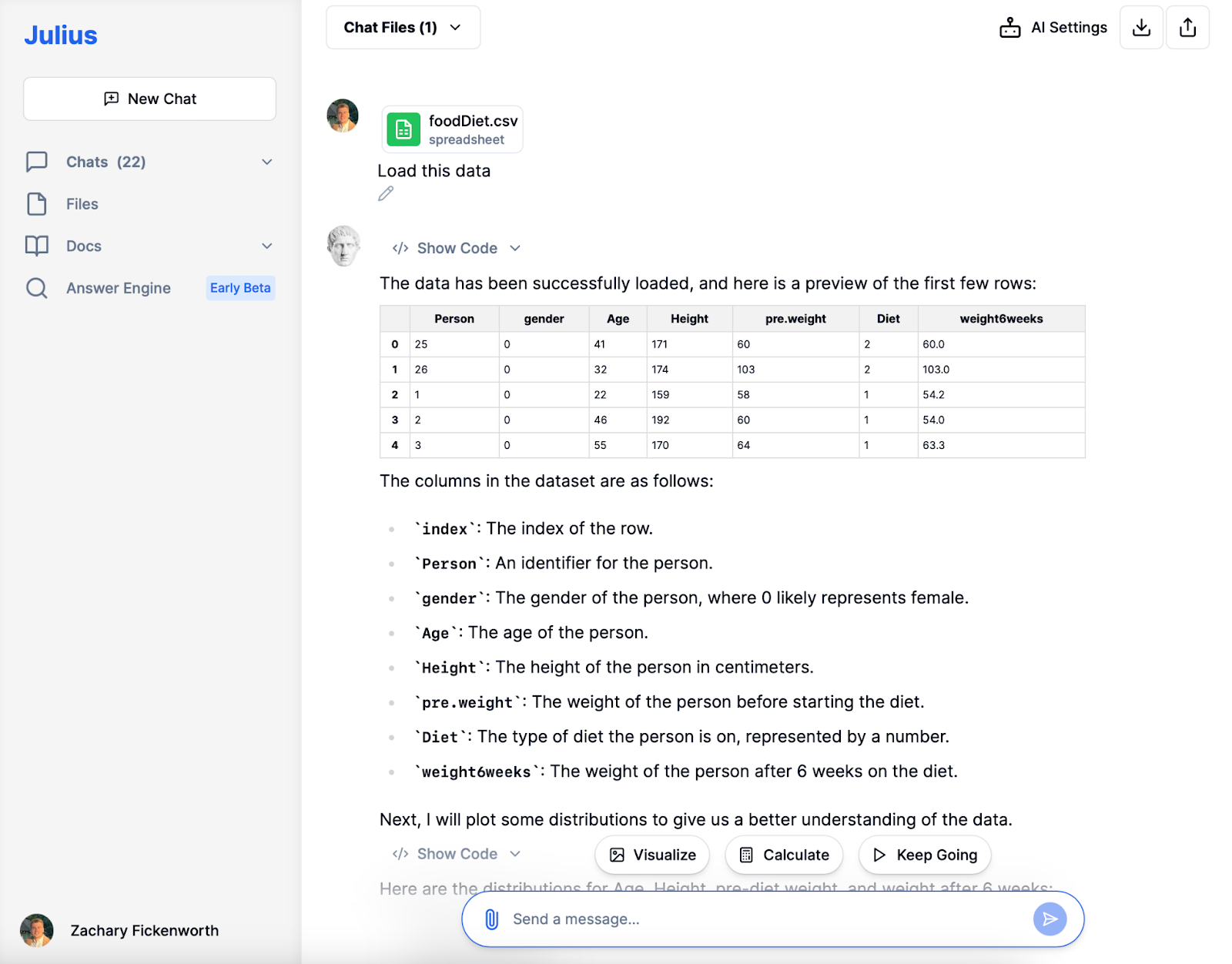
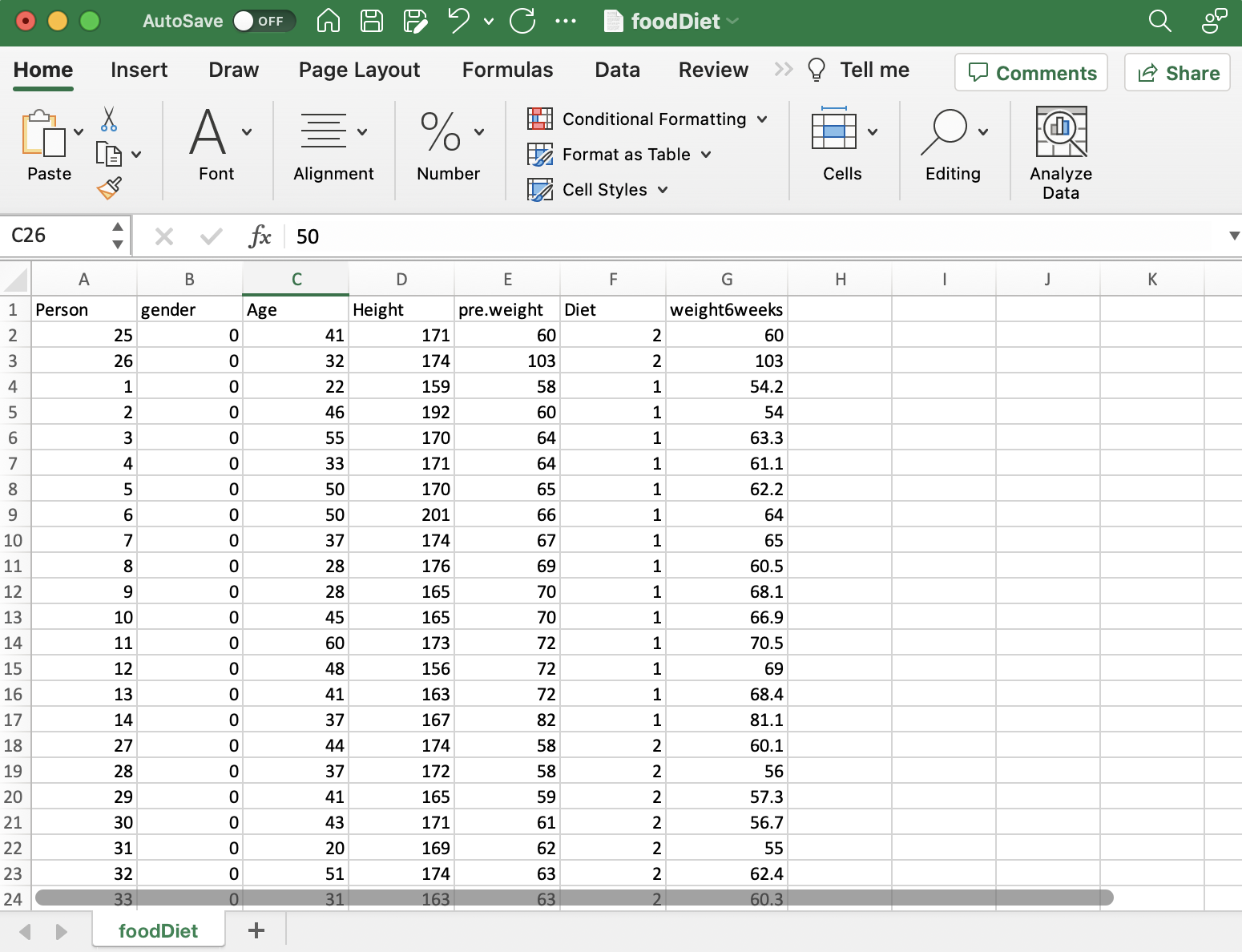
Datainsamling
Inom forskning är det viktigt att samla in rätt data. För vår studie om dieter och viktminskning samlade vi information om varje persons diettyp, deras vikt före och efter dieten, ålder och kön. Det är viktigt att se till att data passar din forskningsfråga. I vissa fall kan du behöva samla in ny information, men här använde vi befintlig data som redan hade alla detaljer vi behövde. Att få bra data är det första stora steget för att ta reda på vad du vill veta.
Datarening och förbearbetning
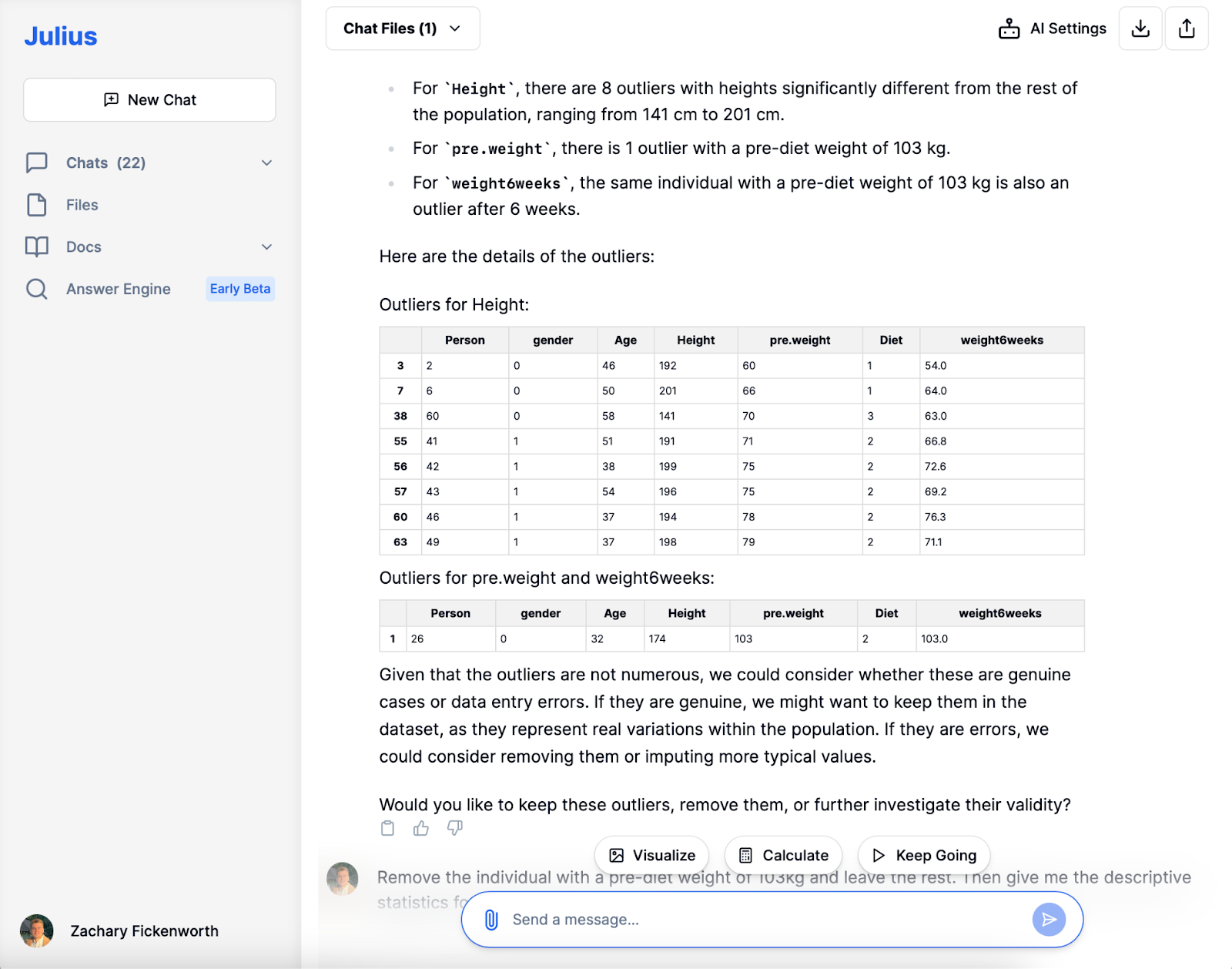
I vår koststudie var datarensning med Julius avgörande. Efter att ha laddat in data identifierade Julius saknade värden och dubbletter, vilket säkerställde datauppsättningens tydlighet. Samtidigt som vi bevarade höjdavvikelser för mångfald, valde vi att utesluta en individ med en exceptionellt hög vikt före dieten (103 kg) för att bibehålla analysintegriteten, vilket säkerställer att datauppsättningen är redo för efterföljande stadier.
Exploratory Data Analysis (EDA)
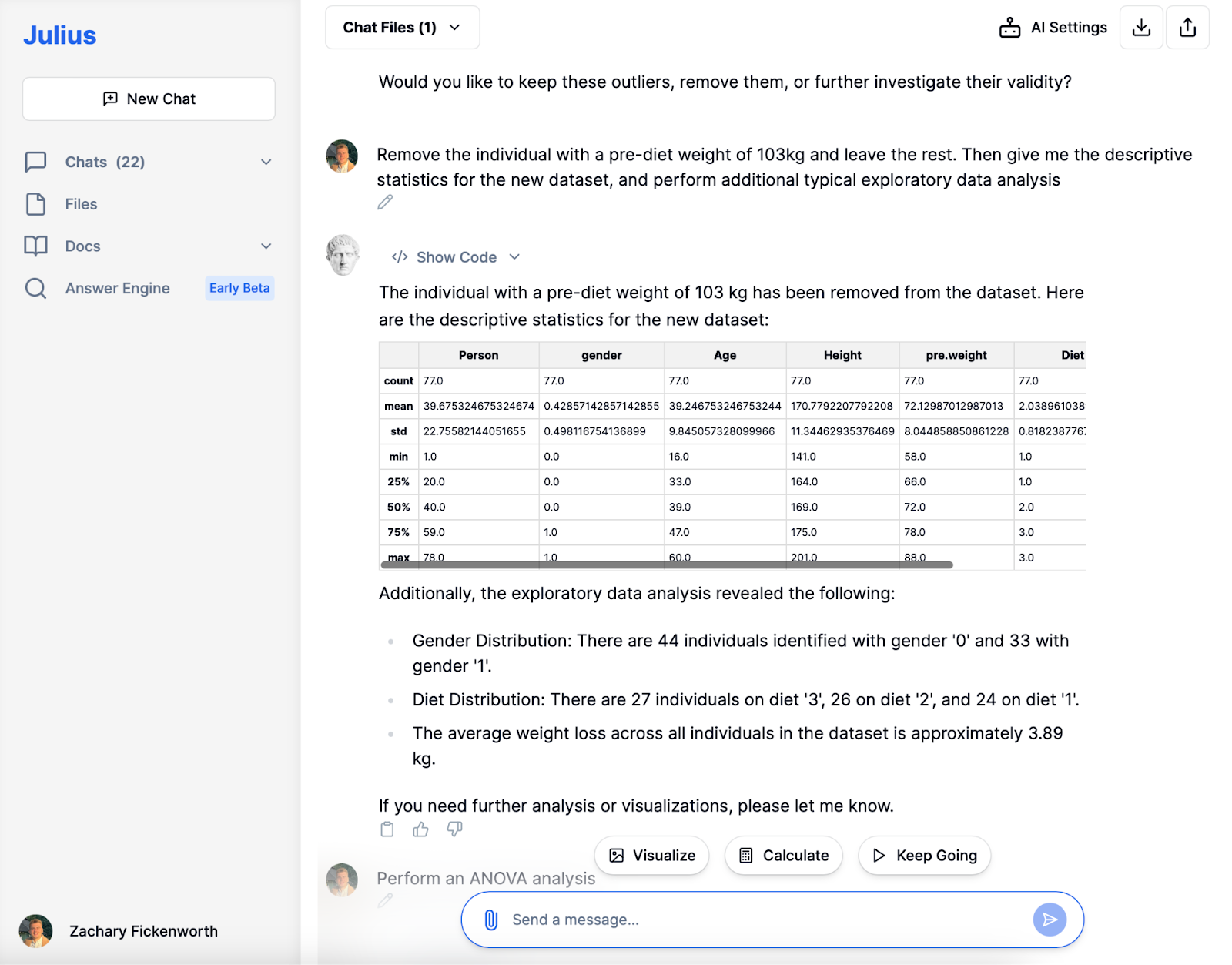
Efter avlägsnandet av extremvärdet med en ovanligt hög vikt före dieten, grävde vi in i den explorativa dataanalysfasen (EDA). Julius tillhandahöll snabbt ny beskrivande statistik, vilket gav en tydligare bild av våra 77 deltagare. Att upptäcka en genomsnittlig vikt före dieten på cirka 72 kg och en genomsnittlig viktminskning på cirka 3.89 kg gav värdefulla insikter.
Utöver grundläggande statistik underlättade Julius en undersökning av köns- och dietfördelningen. Studien avslöjade en balanserad könsfördelning och en jämn fördelning mellan olika diettyper. Denna EDA sammanfattar inte bara data; den avslöjar mönster och trender, avgörande för en djupare analys. Till exempel, att förstå genomsnittlig viktminskning sätter scenen för att bestämma den mest effektiva dieten. Denna AI-drivna fas etablerar grunden för efterföljande detaljerad analys.
Metodval
I vår koststudie var valet av lämpliga statistiska metoder ett avgörande steg. Vårt huvudsakliga mål var att jämföra viktminskning mellan olika dieter, vilket direkt informerade vårt val av analystekniker. Med tanke på att vi hade mer än två grupper (de olika diettyperna) att jämföra, var en Variansanalys (ANOVA) det idealiska valet. ANOVA är kraftfullt i situationer som vår, där vi behöver förstå om det finns signifikanta skillnader i en kontinuerlig variabel (viktminskning) över flera oberoende grupper (kosttyperna).
Men medan ANOVA talar om för oss om det finns skillnader, specificerar den inte var dessa skillnader ligger. För att fastställa vilka specifika dieter som var mest effektiva behövde vi ett mer riktat tillvägagångssätt. Det var här Pairwise-jämförelser kom in. Efter att ha hittat signifikanta resultat med ANOVA använde vi Pairwise-jämförelser för att undersöka skillnaderna i viktminskning mellan varje par av diettyper.
Denna tvåstegsmetod – som började med ANOVA för att upptäcka eventuella övergripande skillnader, följt av parvisa jämförelser för att detaljera dessa skillnader – var strategisk. Det gav en omfattande förståelse för hur varje diet presterade i förhållande till de andra, vilket säkerställde en grundlig och nyanserad analys av vår kostdata.
Statistisk analys
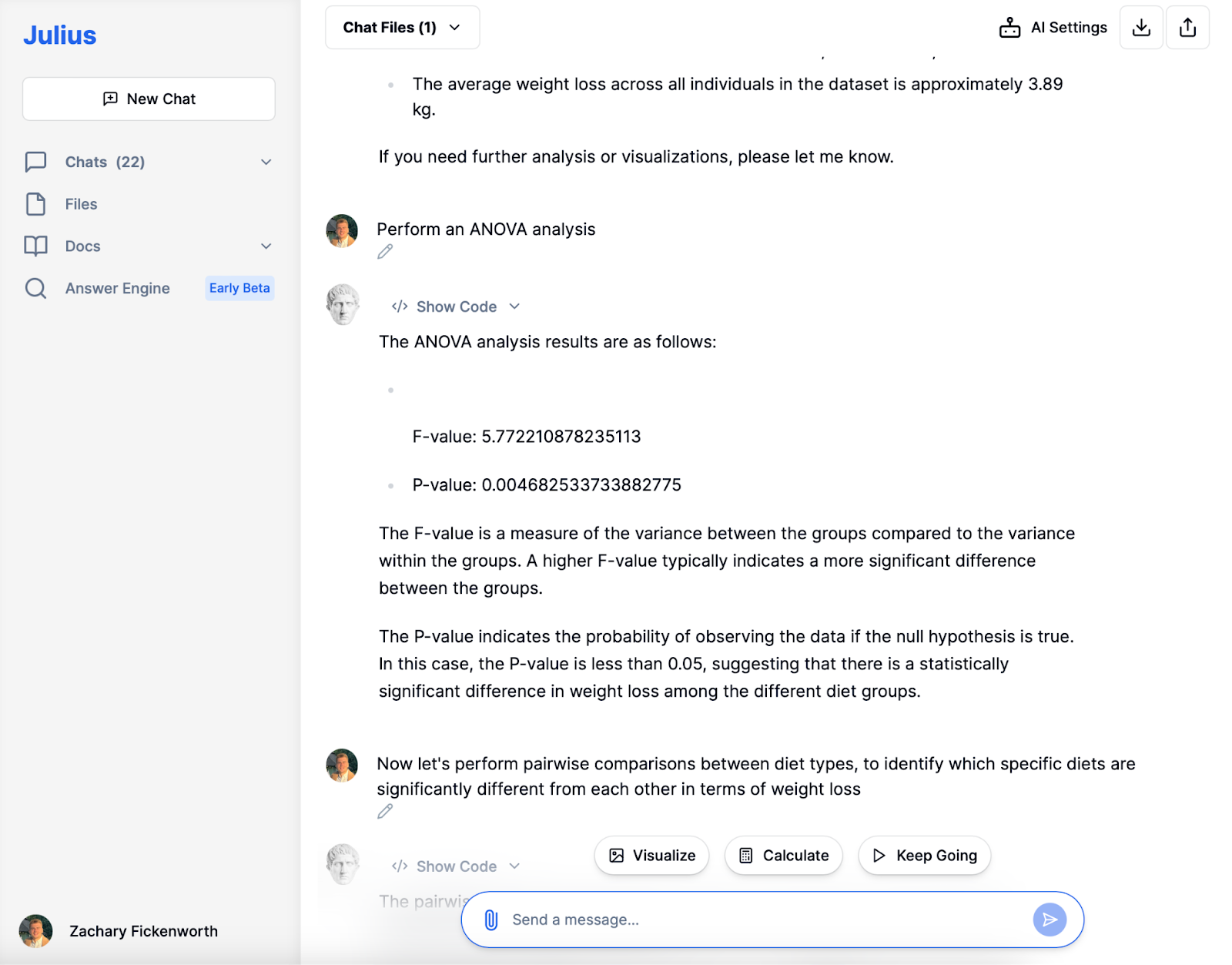
ANOVA
I hjärtat av vår statistiska utforskning genomförde vi en ANOVA analys för att förstå om skillnaderna i viktminskning mellan de olika diettyperna var statistiskt signifikanta. Resultaten var ganska avslöjande. Med ett F-värde på 5.772 antydde analysen en anmärkningsvärd variation mellan dietgrupperna jämfört med variansen inom varje grupp. Detta F-värde, som är högre, tydde på signifikanta skillnader i viktminskning mellan dieterna.
Mer avgörande var att P-värdet, på 0.00468, stack ut. Detta värde, som ligger långt under den konventionella tröskeln på 0.05, tydde starkt på att skillnaderna vi observerade i viktminskning bland dietgrupperna inte bara var av en slump. I statistiska termer innebar detta att vi kunde förkasta nollhypotesen – som inte skulle anta någon skillnad i viktminskning mellan dieterna – och dra slutsatsen att typen av diet verkligen hade en betydande inverkan på viktminskning. Detta ANOVA-resultat var en kritisk milstolpe, vilket ledde till att vi ytterligare undersökte exakt vilka dieter som skilde sig från varandra.
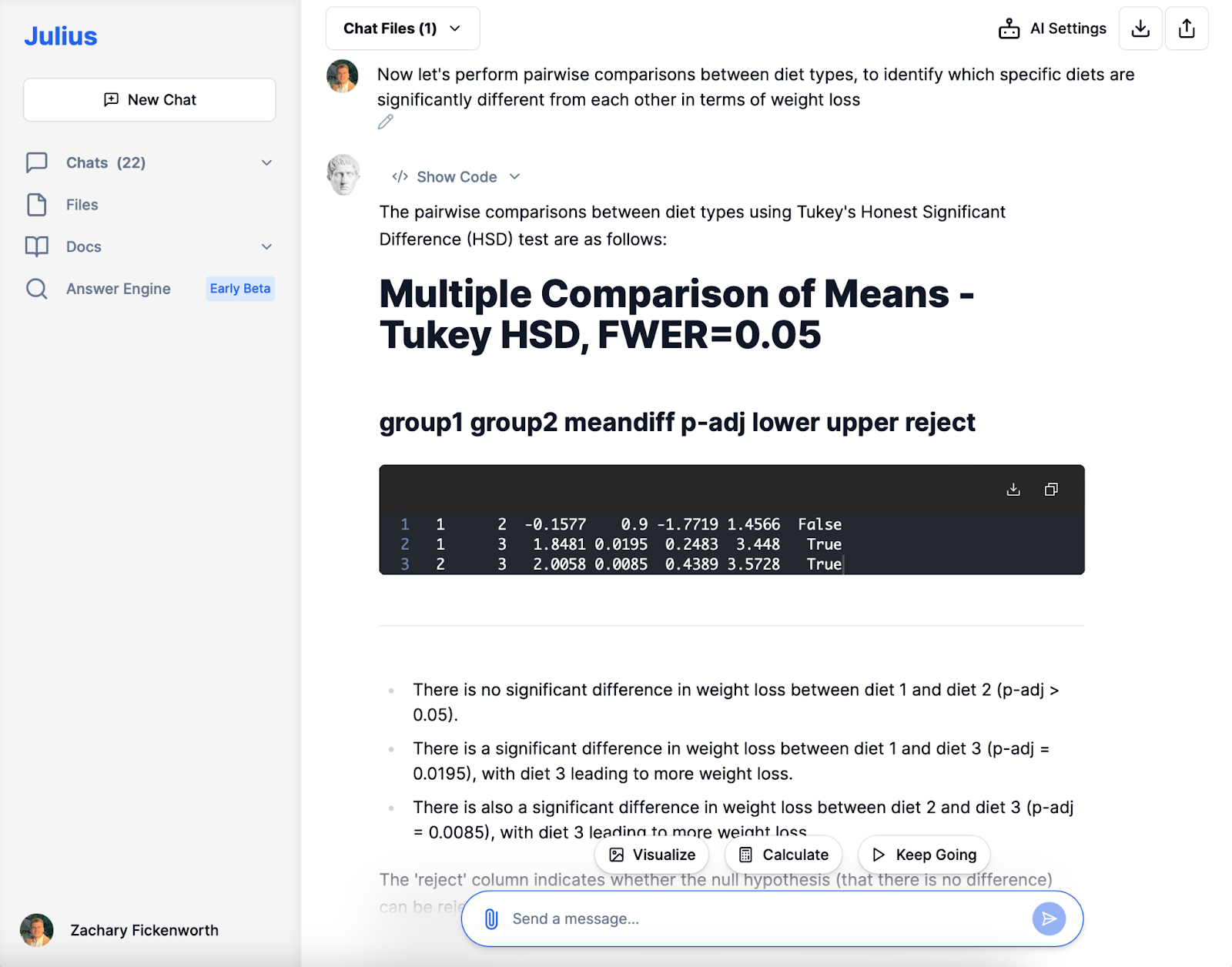
Parvis
I den följande analysfasen med Julius genomförde vi parvisa jämförelser mellan diettyper för att identifiera specifika skillnader i viktminskning. Tukey HSD-testet visade ingen signifikant skillnad mellan diet 1 och diet 2. Däremot avslöjade det att diet 3 resulterade i betydligt större viktminskning jämfört med både diet 1 och diet 2, med stöd av statistiskt signifikanta p-värden. Denna kortfattade men ändå insiktsfulla analys av Julius spelade en avgörande roll för att förstå den relativa effektiviteten av varje diet.
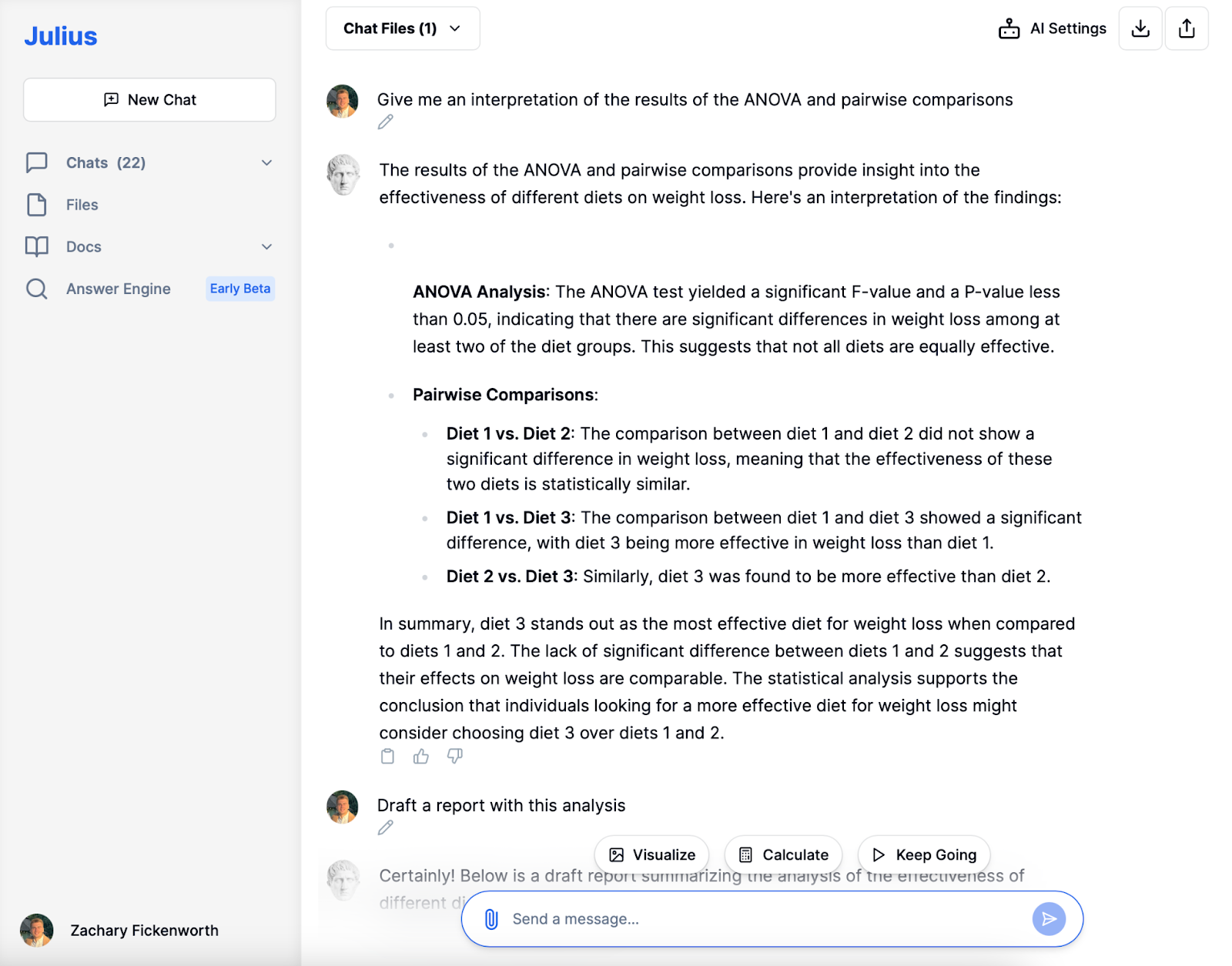
Tolkning
I vår studie om kosteffektivitet spelade Julius en nyckelroll i att tolka och förklara resultaten av ANOVA och parvisa jämförelser. Så här hjälpte det oss att förstå resultaten:
ANOVA tolkning
Den analyserade först ANOVA-resultaten, som visade ett signifikant F-värde och ett P-värde mindre än 0.05. Detta tydde på att det fanns betydelsefulla skillnader i viktminskning mellan de olika dietgrupperna. Det hjälpte oss att förstå att detta innebar att inte alla dieter i studien var lika effektiva för att främja viktminskning.
Tolkning av parvisa jämförelser
- Diet 1 vs. diet 2: Den jämförde dessa två dieter och fann ingen signifikant skillnad i viktminskning. Denna tolkning innebar att dessa två dieter statistiskt sett var lika effektiva.
- Diet 1 vs. Diet 3 & Diet 2 vs. Diet 3: I båda dessa jämförelser bekräftade jag att diet 3 var betydligt effektivare för att främja viktminskning än antingen diet 1 eller diet 2.
Julius tolkning var avgörande för att dra konkreta slutsatser från vår analys. Den klargjorde att medan diet 1 och 2 var lika i sin effektivitet, var diet 3 det enastående alternativet för viktminskning. Denna tolkning gav oss inte bara ett tydligt resultat av studien utan visade också de praktiska konsekvenserna av våra resultat. Med denna information kan vi med tillförsikt föreslå att Diet 3 kan vara det bättre valet för individer som söker effektiva viktminskningslösningar.
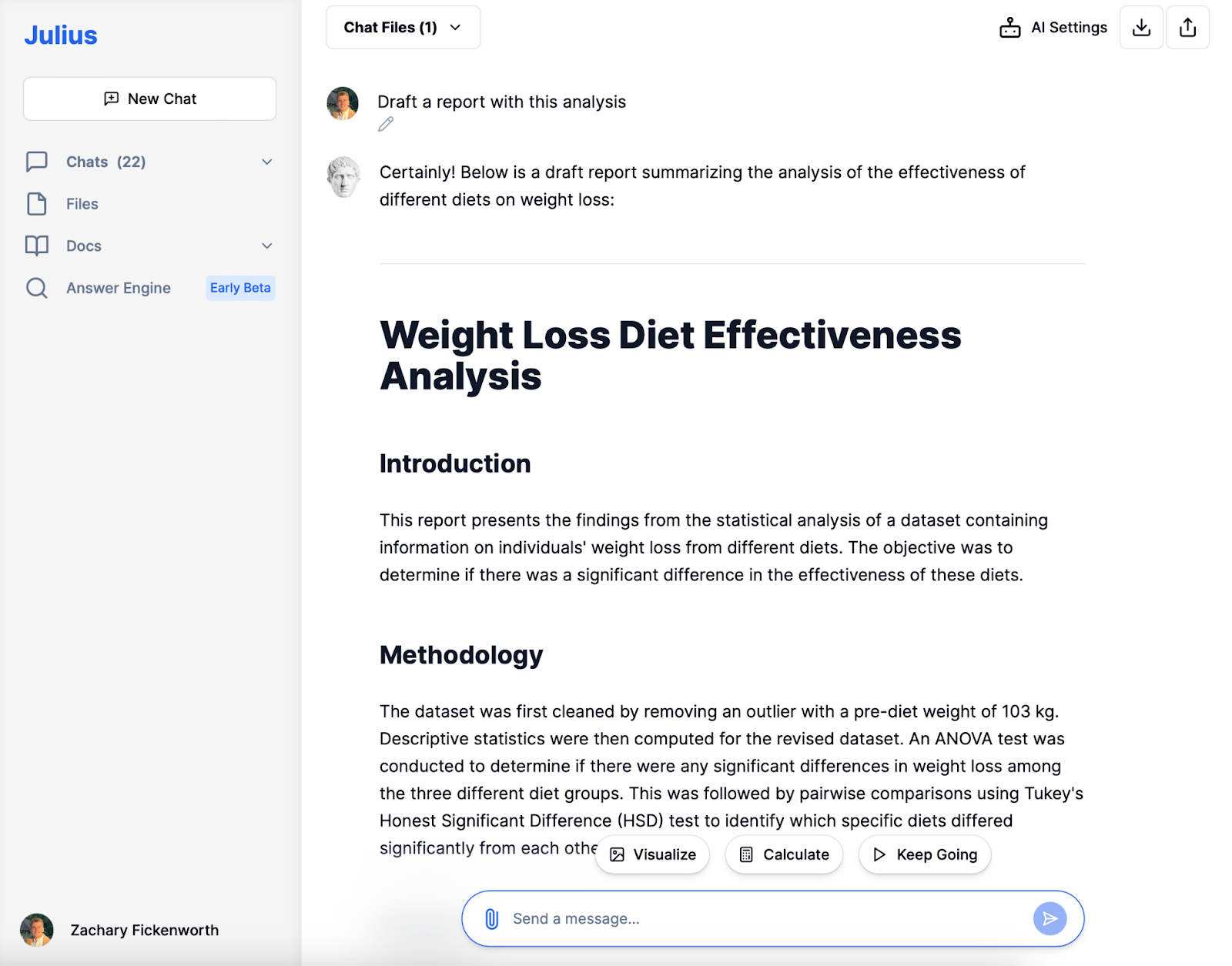
Rapportering
I slutskedet av vår koststudie skulle vi skapa en rapport som snyggt sammanfattar hela vår forskningsprocess och resultat. Denna rapport, vägledd av analysen gjord med Julius, skulle innehålla:
- Introduktion: En kort förklaring av studiens syfte, som är att utvärdera effektiviteten av olika dieter på viktminskning.
- Metodik: En kortfattad beskrivning av hur vi rensat data, de statistiska metoder som använts (ANOVA och Tukeys HSD), och varför de valdes.
- Resultat och tolkning: En tydlig presentation av resultaten, inklusive de signifikanta skillnaderna mellan dieterna, särskilt framhävde Diet 3:s effektivitet.
- Slutsats: Att dra slutliga slutsatser från data och föreslå praktiska konsekvenser eller rekommendationer baserat på våra resultat.
- Referenser: Citerar de verktyg och statistiska metoder, som Julius, som stödde vår analys.
Denna rapport skulle fungera som en tydlig, strukturerad och heltäckande redovisning av vår forskning, vilket gör den tillgänglig och informativ för sina läsare.
Slutsats
Vi har kommit till slutet av vår resa inom akademisk forskning och förvandlar en datauppsättning om dieter till meningsfulla insikter. Denna process, från den första frågan till den slutliga rapporten, visar hur rätt verktyg och metoder kan göra dataanalys lättillgänglig, även för nybörjare.
Använda Julius, vårt avancerade AI-verktyg, har vi sett hur strukturerade steg i dataanalys kan avslöja viktiga trender och svara på viktiga frågor. Vår studie om dieter och viktminskning är bara ett exempel på hur data, när den noggrant analyseras, inte bara berättar en historia utan också ger tydliga, genomförbara slutsatser. Vi hoppas att den här guiden har belyst dataanalysprocessen, vilket gör den mindre skrämmande och mer spännande för alla som är intresserade av att avslöja historierna som är gömda i deras data.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2024/01/guide-to-academic-data-analysis-with-julius-ai/
- : har
- :är
- :inte
- :var
- 1
- 72
- 77
- a
- akademiska
- akademisk forskning
- tillgänglig
- tvärs
- avancerat
- Efter
- ålder
- AI
- AI-powered
- Syftet
- Justerar
- Alla
- redan
- också
- bland
- an
- analyser
- analys
- analysera
- analyseras
- analys
- och
- svara
- svar
- vilken som helst
- någon
- tillvägagångssätt
- lättillgänglig
- lämpligt
- cirka
- ÄR
- OMRÅDE
- runt
- AS
- utgå ifrån
- At
- genomsnitt
- Balanserad
- baserat
- grundläggande
- BE
- innan
- Nybörjare
- Nybörjare
- Där vi får lov att vara utan att konstant prestera,
- nedan
- Bättre
- mellan
- Stor
- båda
- men
- by
- kom
- KAN
- försiktigt
- Vid
- fallstudie
- fall
- chans
- egenskaper
- val
- valda
- klar
- klarhet
- Rengöring
- klar
- klarare
- klart
- samla
- Samla
- samling
- komma
- kommunicera
- jämföra
- jämfört
- jämförande
- jämförelser
- komplex
- omfattande
- Begreppen
- koncis
- avslutar
- betong
- genomfördes
- självsäkert
- med tanke på
- sammanhang
- kontinuerlig
- kontroll
- konventionell
- kunde
- skapa
- kritisk
- avgörande
- avgörande
- datum
- dataanalys
- datauppsättningar
- djupare
- definierande
- demonstreras
- avmystifiera
- beskrivning
- detalj
- detaljerad
- detaljer
- upptäcka
- bestämd
- bestämmande
- DID
- Diet
- Skillnaden
- skillnader
- olika
- direkt
- upptäcka
- fördelning
- Mångfald
- inte
- gjort
- ritning
- dubbletter
- e
- varje
- Effektiv
- effektivt
- effektivitet
- effekter
- antingen
- änden
- säkerställa
- Hela
- lika
- fel
- speciellt
- upprättar
- etc
- Eter (ETH)
- utvärdera
- Även
- allt
- exakt
- undersökning
- undersöka
- Granskning
- exempel
- exceptionellt
- spännande
- befintliga
- erfarenhet
- förklara
- förklaring
- utforskning
- Utforskande dataanalys
- underlättas
- fascinerande
- slutlig
- hitta
- finna
- resultat
- Förnamn
- passar
- Fokus
- följt
- efter
- För
- formulering
- hittade
- färsk
- från
- ytterligare
- samlade ihop
- gav
- Kön
- få
- ges
- Målet
- god
- större
- grundarbeten
- Grupp
- Gruppens
- styra
- guidad
- Guider
- styrning
- hade
- hantera
- Arbetsmiljö
- Har
- Hjärta
- höjd
- hjälpte
- här.
- dold
- Hög
- högre
- belysa
- hoppas
- Hur ser din drömresa ut
- How To
- Men
- HTTPS
- i
- idealisk
- identifierade
- identifiera
- identifiera
- if
- belysa
- oerhört
- Inverkan
- implikationer
- med Esport
- in
- innefattar
- innefattar
- Inklusive
- oberoende
- indikerade
- indikativ
- individuellt
- individer
- påverkas
- informationen
- informativ
- informeras
- inledande
- insiktsfull
- insikter
- integritet
- intresserad
- tolkning
- in
- undersöka
- engagera
- innebär
- IT
- DESS
- resa
- Julius
- bara
- bara en
- Nyckel
- Vet
- kunskap
- leda
- ledande
- mindre
- lie
- ljus
- tycka om
- begränsningar
- läser in
- se
- förlust
- Huvudsida
- bibehålla
- göra
- GÖR
- Framställning
- max-bredd
- Maj..
- betyda
- meningsfull
- menas
- mätning
- endast
- metod
- Metodik
- metoder
- kanske
- milstolpe
- saknas
- modeller
- mer
- mest
- Natur
- nödvändigt för
- Behöver
- behövs
- Nya
- Nej
- anmärkningsvärd
- nybörjare
- nyanserad
- antal
- mål
- observerad
- of
- erbjuda
- on
- ONE
- endast
- Alternativet
- or
- Övriga
- Övrigt
- vår
- ut
- Resultat
- utfall
- uteliggare
- övergripande
- par
- Papper
- del
- deltagare
- bana
- mönster
- Personer
- utföra
- utfört
- fas
- svängbara
- plato
- Platon Data Intelligence
- PlatonData
- spelat
- potentiell
- den mäktigaste
- Praktisk
- förutsäga
- presentation
- konservering
- process
- främja
- ordentligt
- ge
- förutsatt
- ger
- kvalitet
- fråga
- frågor
- ganska
- Raw
- rådata
- läsare
- Beredskap
- verklig
- senaste
- rekommendationer
- post
- regression
- förhållande
- Förhållanden
- relativ
- relevanta
- avlägsnande
- rapport
- representerar
- forskning
- forskare
- resultera
- resulte
- Resultat
- avslöjar
- avslöjade
- avslöjande
- givande
- höger
- färdplan
- Roll
- Save
- söker
- sett
- väljer
- Val
- tjänar
- uppsättningar
- flera
- delning
- skjul
- skall
- show
- visade
- visar
- Visar
- signifikant
- signifikant
- liknande
- Liknande
- situationer
- SEX
- Lösningar
- några
- specifik
- delas
- Etapp
- stadier
- standard
- standardiserad
- stå ut
- Starta
- statistisk
- statistiskt
- statistik
- bo
- Steg
- Steg
- stod
- Upplevelser för livet
- Historia
- okomplicerad
- Strategisk
- starkt
- strukturerade
- Läsa på
- Studerar
- senare
- föreslå
- Som stöds
- säker
- SVG
- snabbt
- riktade
- tekniker
- berättar
- villkor
- testa
- tester
- än
- den där
- Smakämnen
- Området
- deras
- sedan
- Där.
- Dessa
- de
- saker
- detta
- tröskelvärde
- Genom
- hela
- tid
- till
- verktyg
- verktyg
- spår
- omvandla
- Trender
- trovärdig
- SVÄNG
- Vrida
- två
- Typ
- typer
- typisk
- förstå
- förståelse
- enheter
- avtäckt
- presenterar
- us
- användning
- Begagnade
- med hjälp av
- Värdefulla
- värde
- Värden
- variabel
- olika
- utsikt
- vs
- gå
- promenader
- vill
- var
- Sätt..
- we
- veckor
- vikt
- VÄL
- były
- Vad
- när
- om
- som
- medan
- varför
- kommer
- med
- inom
- arbetsflöde
- skulle
- ännu
- dig
- Din
- zach
- zephyrnet