Beskrivning
Maskininlärning är fantastiskt! Men det finns en sak som gör det ännu bättre: ensembleinlärning. Ensemble lärande hjälper till att förbättra prestandan hos modeller för maskininlärning. Konceptet bakom är enkelt. Flera maskininlärningsmodeller kombineras för att få en mer exakt modell.
Bagage, boost och stapling är de tre mest populära ensembleinlärningsteknikerna. Var och en av dessa tekniker erbjuder en unik metod för att förbättra prediktiv precision. Varje teknik används för olika ändamål, med användningen av var och en beroende på olika faktorer. Även om varje teknik är olika, har många av oss svårt att skilja mellan dem. Att veta när eller varför vi ska använda varje teknik är svårt.
I den här bloggen kommer jag att förklara skillnaden mellan bagging, boosting och stacking. Jag kommer att förklara deras syften, deras processer, såväl som deras fördelar och nackdelar. Så att du i slutet av den här artikeln kommer att förstå hur du fungerar och vilken teknik du ska använda och när.
Genom att förstå skillnaderna kommer du att kunna välja den bästa metoden för att förbättra din modells noggrannhet.
Denna artikel publicerades som en del av Data Science Blogathon.
Hur fungerar Ensemble Learning?
Ensemble learning är en inlärningsmetod som består av att kombinera flera maskininlärningsmodeller.
Ett problem i maskininlärning är att enskilda modeller tenderar att prestera dåligt. Med andra ord tenderar de att ha låg prediktionsnoggrannhet. För att mildra detta problem kombinerar vi flera modeller för att få en med bättre prestanda.
De individuella modellerna som vi kombinerar är kända som svaga elever. Vi kallar dem svaga elever eftersom de antingen har en hög partiskhet eller hög varians.
Eftersom de antingen har hög partiskhet eller varians kan svaga elever inte lära sig effektivt och prestera dåligt.
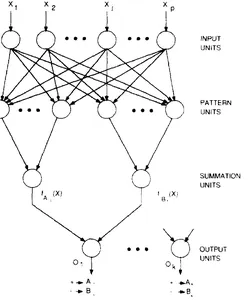
- En hög-bias-modell är resultatet av att inte lära sig data tillräckligt bra. Det är inte relaterat till distributionen av uppgifterna. Följaktligen kommer framtida förutsägelser inte att vara relaterade till data och därmed felaktiga.
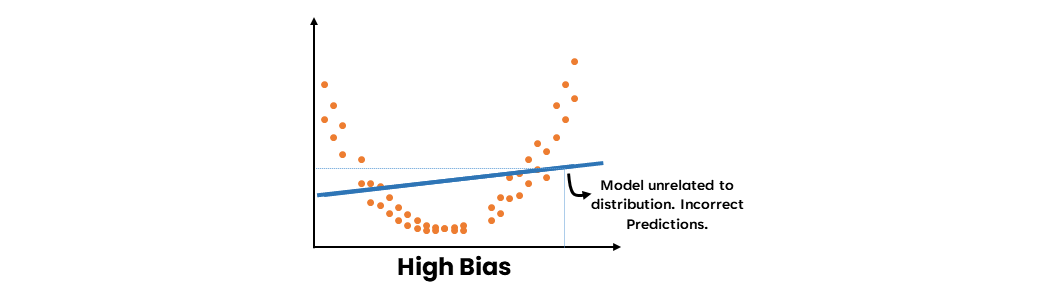
- En modell med hög varians är resultatet av att man lärt sig data för väl. Det varierar med varje datapunkt. Därför är det omöjligt att förutsäga nästa punkt exakt.
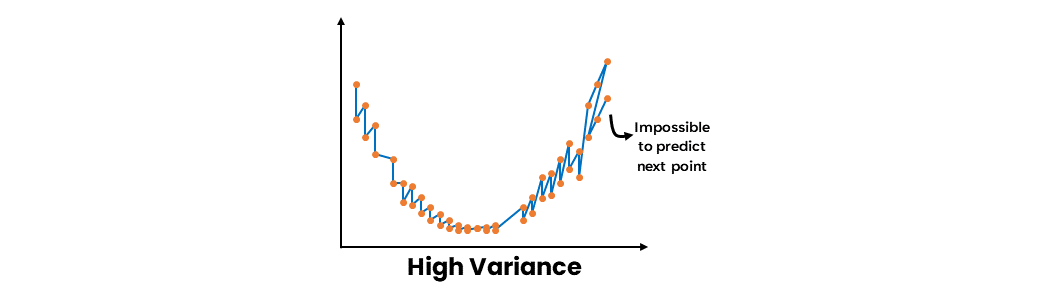
Både modeller med hög bias och hög varians kan därför inte generalisera ordentligt. Således kommer svaga elever antingen att göra felaktiga generaliseringar eller misslyckas med att generalisera helt och hållet. På grund av detta kan svaga elevers förutsägelser inte litas på av sig själva.
Som vi vet från avvägningen mellan bias-varians har en underfit-modell hög bias och låg varians, medan en overfit-modell har hög varians och låg bias. I båda fallen finns det ingen balans mellan bias och varians. För att det ska finnas en balans måste både bias och varians vara låg. Ensembleinlärning försöker balansera denna avvägning mellan bias och varians genom att minska antingen bias eller varians.
Ensemble learning kommer att syfta till att minska biasen om vi har en svag modell med hög bias och låg varians. Ensemble learning kommer att syfta till att minska variansen om vi har en svag modell med hög varians och låg bias. På så sätt blir den resulterande modellen mycket mer balanserad, med låg bias och varians. Således kommer den resulterande modellen att bli känd som en stark inlärare. Denna modell kommer att vara mer generaliserad än de svaga eleverna. Den kommer alltså att kunna göra korrekta förutsägelser.
Ensembleinlärning förbättrar en modells prestanda på huvudsakligen tre sätt:
- Genom att minska variationen hos svaga elever
- Genom att minska partiskheten hos svaga elever,
- Genom att förbättra den övergripande noggrannheten hos starka elever.
Bagage används för att minska variationen hos svaga elever. Boostning används för att minska fördomar hos svaga elever. Stapling används för att förbättra den övergripande noggrannheten hos starka elever.
Vi använder påsar för att kombinera svaga elever med hög varians. Bagging syftar till att producera en modell med lägre varians än de individuella svaga modellerna. Dessa svaga elever är homogena, vilket betyder att de är av samma typ.
Bagging är också känt som Bootstrap aggregating. Den består av två steg: bootstrapping och aggregering.
Bootstrapping
Innebär omsampling av delmängder av data med ersättning från en initial datauppsättning. Med andra ord, delmängder av data finns i den initiala datamängden. Dessa delmängder av data kallas bootstrappade datamängder eller helt enkelt bootstraps. Omsamplad "med ersättning" betyder att en enskild datapunkt kan samplas flera gånger. Varje bootstrap-dataset används för att träna en svag elev.
Aggregerande
De individuella svaga eleverna tränas oberoende av varandra. Varje elev gör självständiga förutsägelser. Resultaten av dessa förutsägelser aggregeras i slutet för att få den övergripande förutsägelsen. Förutsägelserna är aggregerade med antingen max röstning eller medelvärde.
Max röstning används ofta för klassificeringsproblem. Det består av att ta förutsägelsernas läge (den mest förekommande förutsägelsen). Det kallas att rösta för precis som vid valröstning är utgångspunkten att "majoriteten styr". Varje modell gör en förutsägelse. En förutsägelse från varje modell räknas som en enda "röst". Den mest förekommande 'omröstningen' väljs som representant för den kombinerade modellen.
Snittar används vanligtvis för regressionsproblem. Det handlar om att ta medelvärdet av förutsägelserna. Det resulterande medelvärdet används som den övergripande förutsägelsen för den kombinerade modellen.
Steg av påsar |
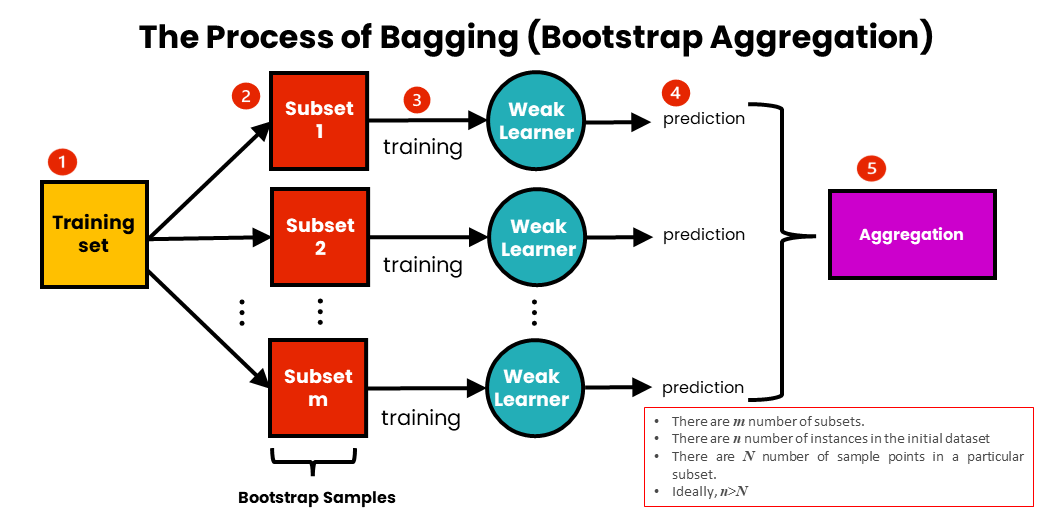
Stegen för att packa är som följer:
- Vi har en inledande träningsdatauppsättning som innehåller n-antal instanser.
- Vi skapar ett m-antal av delmängder av data från träningsuppsättningen. Vi tar en delmängd av N provpunkter från den initiala datamängden för varje delmängd. Varje delmängd tas med ersättning. Detta innebär att en specifik datapunkt kan samplas mer än en gång.
- För varje delmängd av data tränar vi de motsvarande svaga eleverna oberoende. Dessa modeller är homogena, vilket innebär att de är av samma typ.
- Varje modell gör en förutsägelse.
- Förutsägelserna är aggregerade till en enda förutsägelse. För detta används antingen maxröstning eller medelvärde.
Minska bias genom att öka
Vi använder boosting för att kombinera svaga elever med hög partiskhet. Boosting syftar till att producera en modell med lägre bias än de enskilda modellerna. Liksom i påsar är de svaga eleverna homogena.
Boost innebär att sekventiellt träna svaga elever. Här förbättrar varje efterföljande elev felen för tidigare elever i sekvensen. Ett urval av data tas först från den ursprungliga datamängden. Detta prov används för att träna den första modellen, och modellen gör sin förutsägelse. Proverna kan antingen vara korrekt eller felaktigt förutspådda. De prover som är felaktigt förutspådda återanvänds för att träna nästa modell. På så sätt kan efterföljande modeller förbättra felen från tidigare modeller.
Till skillnad från packning, som samlar förutsägelseresultat i slutet, samlar boost resultaten vid varje steg. De är aggregerade med hjälp av vägt medelvärde.
Vägt medelvärde innebär att ge alla modeller olika vikt beroende på deras prediktiva kraft. Det ger med andra ord mer vikt åt modellen med högst prediktiv kraft. Detta beror på att eleven med den högsta prediktiva kraften anses vara den viktigaste.
Steg för att öka
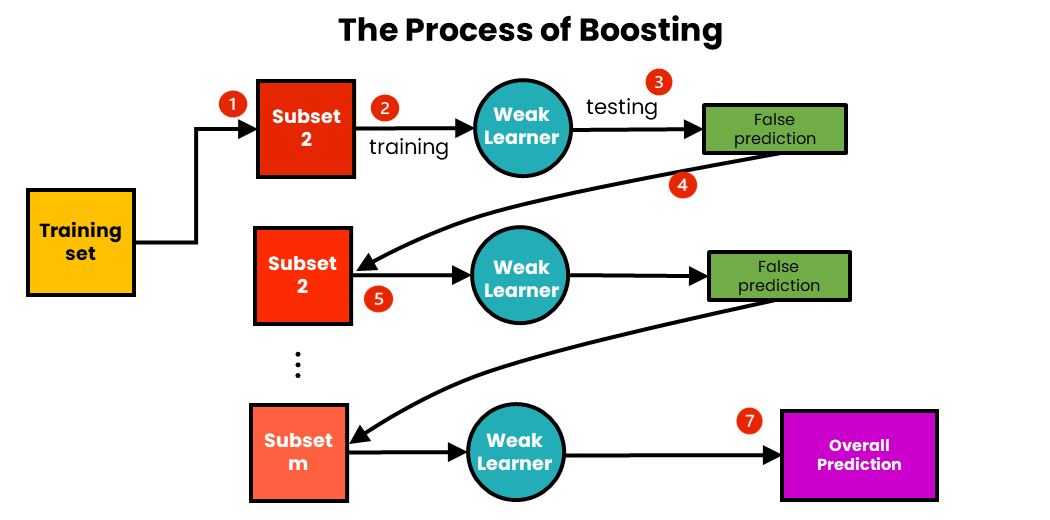
Boostning fungerar med följande steg:
- Vi samplar m-antal delmängder från en initial träningsdatauppsättning.
- Med den första delmängden tränar vi den första svaga eleven.
- Vi testar den tränade svaga eleven med hjälp av träningsdata. Som ett resultat av testningen kommer vissa datapunkter att förutsägas felaktigt.
- Varje datapunkt med fel förutsägelse skickas till den andra delmängden av data, och denna delmängd uppdateras.
- Med hjälp av denna uppdaterade delmängd tränar och testar vi den andra svaga eleven.
- Vi fortsätter med följande delmängd tills det totala antalet delmängder uppnås.
- Vi har nu den totala förutsägelsen. Den övergripande förutsägelsen har redan aggregerats vid varje steg, så det finns ingen anledning att beräkna den.
Förbättra modellnoggrannheten med stapling
Vi använder stapling för att förbättra prediktionsnoggrannheten för starka elever. Stacking syftar till att skapa en enda robust modell från flera heterogena starka elever.
Stacking skiljer sig från påsar och boosting genom att:
- Den kombinerar starka elever
- Den kombinerar heterogena modeller
- Det består av att skapa en metamodell. En metamodell är en modell skapad med hjälp av en ny datamängd.
Individuella heterogena modeller tränas med hjälp av en initial datauppsättning. Dessa modeller gör förutsägelser och bildar en enda ny datauppsättning med dessa förutsägelser. Denna nya datamängd används för att träna metamodellen, som gör den slutliga förutsägelsen. Förutsägelsen kombineras med hjälp av viktat medelvärde.
Eftersom stapling kombinerar starka elever, kan den kombinera modeller med säckar eller förstärkta modeller.
Steg av stapling
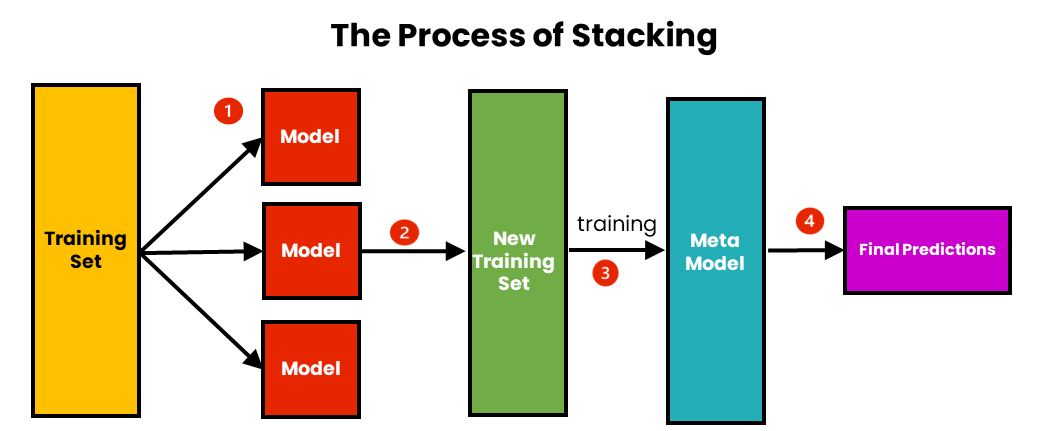
Stegen för stapling är följande:
- Vi använder initial träningsdata för att träna m-antal algoritmer.
- Med hjälp av utdata från varje algoritm skapar vi en ny träningsuppsättning.
- Med hjälp av det nya träningssetet skapar vi en metamodellalgoritm.
- Med hjälp av resultaten från metamodellen gör vi den slutliga förutsägelsen. Resultaten kombineras med hjälp av viktat medelvärde.
När ska man använda Bagging vs Boosting vs Stacking?
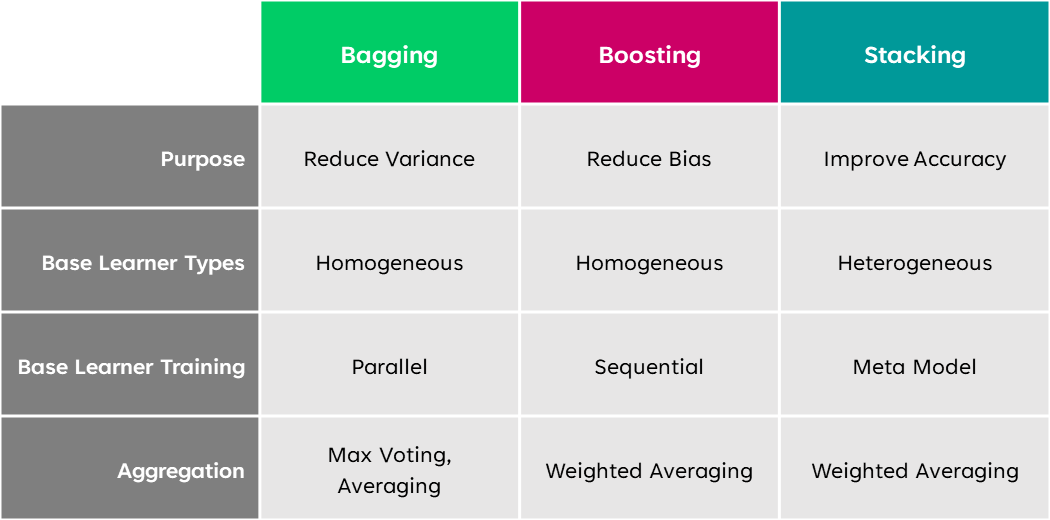
Om du vill minska överpassningen eller variansen på din modell använder du påsar. Om du vill minska underfitting eller bias använder du boosting. Om du vill öka prediktiv precision, använd stapling.
Bagging och boosting fungerar båda med homogena svaga elever. Stapling fungerar med heterogena solida elever.
Alla dessa tre metoder kan fungera med antingen klassificerings- eller regressionsproblem.
En nackdel med boosting är att det är benäget att variera eller överanpassa. Det är därför inte tillrådligt att använda boosting för att minska variansen. Boosting kommer att göra ett sämre jobb när det gäller att minska variansen jämfört med påsar.
Å andra sidan är det omvända sant. Det är inte tillrådligt att använda påsar för att minska fördomar eller undermontering. Detta beror på att påsar är mer benägna att vara partisk och inte hjälper till att minska fördomar.
Staplade modeller har fördelen av bättre prediktionsnoggrannhet än packning eller boosting. Men eftersom de kombinerar påsade eller förstärkta modeller har de nackdelen att de behöver mycket mer tid och beräkningskraft. Om du letar efter snabbare resultat, är det tillrådligt att inte använda stapling. Men stapling är rätt väg att gå om du letar efter hög noggrannhet.
Slutsats
En av de första användningarna av ensemblemetoder var säcktekniken. Denna teknik utvecklades för att övervinna instabilitet i beslutsträd. Faktum är att ett exempel på säcktekniken är den slumpmässiga skogsalgoritmen. Den slumpmässiga skogen är en ensemble av flera beslutsträd. Beslutsträd tenderar att vara benägna att överanpassas. På grund av detta kan man inte lita på ett enda beslutsträd för att göra förutsägelser. För att förbättra prediktionsnoggrannheten hos beslutsträd används säckar för att bilda en slumpmässig skog. Den resulterande slumpmässiga skogen har en lägre varians jämfört med de enskilda träden.
Framgången med bagging ledde till utvecklingen av andra ensembletekniker som boosting, stacking och många andra. Idag är denna utveckling en viktig del av maskininlärning.
De många verkliga maskininlärningsapplikationerna visar dessa ensemblemetoders betydelse. Dessa applikationer inkluderar många kritiska system. Dessa inkluderar beslutssystem, skräppostdetektering, autonoma fordon, medicinsk diagnos och många andra. Dessa system är avgörande eftersom de har förmågan att påverka människors liv och affärsintäkter. Därför är det av största vikt att säkerställa noggrannheten hos modeller för maskininlärning. En felaktig modell kan leda till katastrofala konsekvenser för många företag eller organisationer. I värsta fall kan de leda till fara för människoliv.
Bagning, boosting och stapling är viktiga för att säkerställa modellernas noggrannhet. De kan hjälpa till att förhindra oönskade konsekvenser som orsakas av felaktiga modeller. Nedan är några av de viktigaste tipsen från artikeln:
- Ensemble learning kombinerar flera maskininlärningsmodeller till en enda modell. Syftet är att öka modellens prestanda.
- Bagging syftar till att minska variansen, boosting syftar till att minska bias, och stacking syftar till att förbättra prediktionsnoggrannheten.
- Bagging och boost kombinerar homogena svaga elever. Stacking kombinerar heterogena solida elever.
- Bagging tränar modeller parallellt och boosting tränar modellerna sekventiellt. Stapling skapar en metamodell.
Jag hoppas att den här artikeln har löst några av dina tvivel om skillnaderna mellan packning, boosting och stapling. Och jag hoppas att du har förstått hur varje ensembleteknik fungerar och när varje teknik kan användas. Om du har frågor eller kommentarer, kontakta mig gärna på Linkedin.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/01/ensemble-learning-methods-bagging-boosting-and-stacking/
- a
- förmåga
- Able
- Om Oss
- noggrannhet
- exakt
- exakt
- Fördel
- fördelar
- aggregation
- Syftet
- algoritm
- algoritmer
- Alla
- redan
- Även
- analytics
- Analys Vidhya
- och
- tillämpningar
- tillvägagångssätt
- Artikeln
- autonom
- autonoma fordon
- genomsnitt
- Balansera
- därför att
- bakom
- nedan
- BÄST
- Bättre
- mellan
- förspänning
- Blogg
- bloggaton
- ökat
- öka
- Bootstrap
- företag
- företag
- Ring
- kallas
- kan inte
- Vid
- orsakas
- Välja
- valda
- klassificering
- kombinera
- kombinerad
- kombinerar
- kombinera
- kommentarer
- vanligen
- jämfört
- beräkningskraft
- begrepp
- Konsekvenser
- anses
- kontakta
- fortsätta
- Motsvarande
- skapa
- skapas
- skapar
- Skapa
- kritisk
- avgörande
- datum
- datapunkter
- datauppsättning
- datauppsättningar
- Beslutet
- Beslutsfattande
- beslutsträd
- minskning
- beroende
- Detektering
- utvecklade
- Utveckling
- utvecklingen
- Skillnaden
- skillnader
- olika
- svårt
- Nackdel
- katastrofal
- diskretion
- skilja på
- fördelning
- varje
- effektivt
- antingen
- Val
- tillräckligt
- säkerställa
- fel
- Eter (ETH)
- Även
- exempel
- Förklara
- faktorer
- MISSLYCKAS
- snabbare
- slutlig
- hitta
- Förnamn
- efter
- följer
- skog
- formen
- Fri
- från
- framtida
- allmänhet
- skaffa sig
- ger
- Ge
- Go
- Hård
- hjälpa
- hjälper
- här.
- Hög
- högsta
- hoppas
- Hur ser din drömresa ut
- Men
- HTTPS
- humant
- SJUK
- Inverkan
- vikt
- med Esport
- omöjligt
- förbättra
- förbättrar
- förbättra
- in
- I andra
- felaktig
- innefattar
- felaktigt
- Öka
- oberoende
- oberoende av
- individuellt
- inledande
- instabilitet
- IT
- Jobb
- Nyckel
- Vet
- Menande
- känd
- leda
- LÄRA SIG
- elev
- inlärning
- Led
- Bor
- du letar
- Låg
- Maskinen
- maskininlärning
- Majoritet
- göra
- GÖR
- Framställning
- många
- max
- betyder
- betyder
- Media
- medicinsk
- metod
- metoder
- Mildra
- Mode
- modell
- modeller
- mer
- mest
- Mest populär
- multipel
- Behöver
- behöver
- Nya
- Nästa
- antal
- Erbjudanden
- ONE
- organisationer
- Övriga
- Övrigt
- övergripande
- Övervinna
- ägd
- Parallell
- Yttersta
- del
- utföra
- prestanda
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- poäng
- Populära
- kraft
- förutse
- förutsagda
- förutsägelse
- Förutsägelser
- förhindra
- föregående
- Problem
- problem
- process
- processer
- producera
- ordentligt
- publicerade
- Syftet
- syfte
- frågor
- slumpmässig
- kommit fram till
- minska
- reducerande
- regression
- relaterad
- representativ
- resultera
- resulterande
- Resultat
- intäkter
- robusta
- Samma
- Vetenskap
- Andra
- Sekvens
- in
- skall
- show
- visas
- Enkelt
- helt enkelt
- enda
- So
- fast
- några
- skräppost
- specifik
- stapling
- Steg
- Steg
- stark
- senare
- framgång
- sådana
- System
- Ta
- takeaways
- tar
- tekniker
- testa
- Testning
- Smakämnen
- deras
- sig själva
- därför
- sak
- tre
- tid
- gånger
- till
- i dag
- alltför
- Totalt
- Tåg
- tränad
- Utbildning
- tåg
- Träd
- sann
- förståelse
- förstått
- unika
- uppdaterad
- us
- användning
- fordon
- Röstning
- sätt
- vikt
- som
- kommer
- ord
- Arbete
- fungerar
- värsta
- Fel
- Din
- zephyrnet