Den här bloggen är skriven tillsammans med Josh Reini, Shayak Sen och Anupam Datta från TruEra
Amazon SageMaker JumpStart tillhandahåller en mängd olika förtränade grundmodeller som Llama-2 och Mistal 7B som snabbt kan distribueras till en slutpunkt. Dessa grundmodeller fungerar bra med generativa uppgifter, från att skapa text och sammanfattningar, svara på frågor till att producera bilder och videor. Trots dessa modellers stora generaliseringsförmåga finns det ofta användningsfall där dessa modeller måste anpassas till nya uppgifter eller domäner. Ett sätt att yttra detta behov är genom att utvärdera modellen mot en kurerad datauppsättning av grundsanningar. Efter att behovet av att anpassa grundmodellen är klart kan du använda en uppsättning tekniker för att utföra det. Ett populärt tillvägagångssätt är att finjustera modellen med hjälp av en datauppsättning som är skräddarsydd för användningsfallet. Finjustering kan förbättra grundmodellen och dess effektivitet kan återigen mätas mot grundsanningsdataset. Detta anteckningsbok visar hur man finjusterar modeller med SageMaker JumpStart.
En utmaning med detta tillvägagångssätt är att kurerade datauppsättningar av grundsanningar är dyra att skapa. I det här inlägget tar vi oss an denna utmaning genom att utöka detta arbetsflöde med ett ramverk för utökningsbara, automatiserade utvärderingar. Vi börjar med en grundmodell från SageMaker JumpStart och utvärderar den med TruLens, ett bibliotek med öppen källkod för att utvärdera och spåra appar för stora språkmodeller (LLM). Efter att vi identifierat behovet av anpassning kan vi använda finjustering i SageMaker JumpStart och bekräfta förbättringar med TruLens.

TruLens utvärderingar använder en abstraktion av återkopplingsfunktioner. Dessa funktioner kan implementeras på flera sätt, inklusive modeller i BERT-stil, lämpliga LLM:er och mer. TruLens integration med Amazonas berggrund låter dig köra utvärderingar med hjälp av LLM:er tillgängliga från Amazon Bedrock. Tillförlitligheten hos Amazon Bedrock-infrastrukturen är särskilt värdefull för användning vid utvärderingar över utveckling och produktion.
Det här inlägget fungerar både som en introduktion till TruEras plats i den moderna LLM-appstacken och en praktisk guide för att använda Amazon SageMaker och TruEra att distribuera, finjustera och iterera på LLM-appar. Här är den kompletta anteckningsbok med kodexempel för att visa prestandautvärdering med TruLens
TruEra i LLM-appstacken
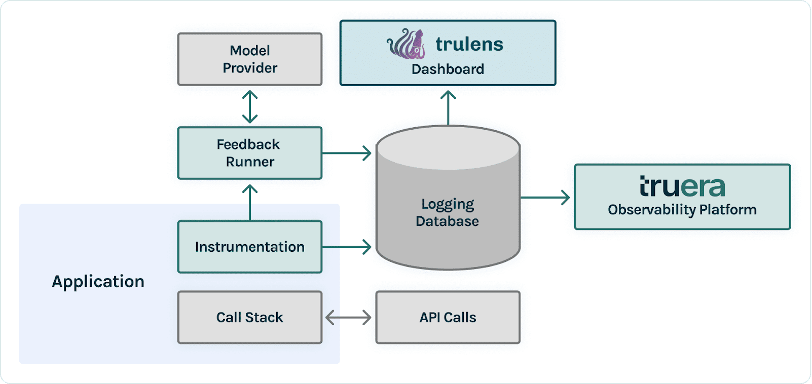
TruEra bor på observerbarhetslagret av LLM-appar. Även om nya komponenter har arbetat sig in i beräkningsskiktet (finjustering, promptteknik, modell-API) och lagringslagret (vektordatabaser), kvarstår behovet av observerbarhet. Detta behov sträcker sig från utveckling till produktion och kräver sammanlänkade möjligheter för testning, felsökning och produktionsövervakning, som illustreras i följande figur.

I utvecklingen kan du använda öppen källkod TruLens för att snabbt utvärdera, felsöka och iterera på dina LLM-appar i din miljö. En omfattande uppsättning utvärderingsmått, inklusive både LLM-baserade och traditionella mätvärden tillgängliga i TruLens, låter dig mäta din app mot kriterier som krävs för att flytta din applikation till produktion.
I produktionen kan dessa loggar och utvärderingsmått bearbetas i skala med TruEra produktionsövervakning. Genom att koppla samman produktionsövervakning med testning och felsökning kan nedgångar i prestanda som hallucinationer, säkerhet, säkerhet med mera identifieras och korrigeras.
Distribuera grundmodeller i SageMaker
Du kan distribuera grundmodeller som Llama-2 i SageMaker med bara två rader Python-kod:
Anropa modellens slutpunkt
Efter implementeringen kan du anropa den distribuerade modellens slutpunkt genom att först skapa en nyttolast som innehåller dina indata och modellparametrar:
Sedan kan du helt enkelt skicka denna nyttolast till slutpunktens förutsägelsemetod. Observera att du måste skicka attributet för att acceptera licensavtalet för slutanvändare varje gång du anropar modellen:
Utvärdera prestanda med TruLens
Nu kan du använda TruLens för att ställa in din utvärdering. TruLens är ett observerbarhetsverktyg som erbjuder en utbyggbar uppsättning feedbackfunktioner för att spåra och utvärdera LLM-drivna appar. Feedbackfunktioner är viktiga här för att verifiera frånvaron av hallucinationer i appen. Dessa återkopplingsfunktioner implementeras genom att använda hyllmodeller från leverantörer som Amazon Bedrock. Amazon Bedrock-modeller är en fördel här på grund av deras verifierade kvalitet och tillförlitlighet. Du kan ställa in leverantören med TruLens med följande kod:
I det här exemplet använder vi tre återkopplingsfunktioner: svarsrelevans, kontextrelevans och jordadhet. Dessa utvärderingar har snabbt blivit standarden för hallucinationsdetektering i kontextaktiverade frågesvarsapplikationer och är särskilt användbara för oövervakade applikationer, som täcker de allra flesta av dagens LLM-applikationer.

Låt oss gå igenom var och en av dessa feedbackfunktioner för att förstå hur de kan gynna oss.
Kontextrelevans
Kontext är en avgörande indata för kvaliteten på vår applikations svar, och det kan vara användbart att programmatiskt säkerställa att det angivna sammanhanget är relevant för inmatningsfrågan. Detta är avgörande eftersom detta sammanhang kommer att användas av LLM för att bilda ett svar, så all irrelevant information i sammanhanget kan vävas in i en hallucination. TruLens låter dig utvärdera sammanhangets relevans genom att använda strukturen för den serialiserade posten:
Eftersom sammanhanget som tillhandahålls till LLM:er är det mest följdriktiga steget i en RAG-pipeline (Retrieval Augmented Generation) är kontextrelevans avgörande för att förstå kvaliteten på hämtningar. Genom att arbeta med kunder över olika sektorer har vi sett en mängd olika fellägen identifierade med denna utvärdering, såsom ofullständig kontext, främmande irrelevant kontext eller till och med brist på tillräckligt tillgängligt sammanhang. Genom att identifiera arten av dessa fellägen kan våra användare anpassa sin indexering (som inbäddningsmodell och chunking) och hämtningsstrategier (som meningsfönster och automerging) för att mildra dessa problem.
Jordning
Efter att sammanhanget har hämtats, formas det sedan till ett svar av en LLM. LLM är ofta benägna att avvika från de fakta som tillhandahålls, överdriva eller utöka till ett korrekt klingande svar. För att verifiera att applikationen är grundad bör du dela upp svaret i separata påståenden och självständigt söka efter bevis som stöder var och en inom det hämtade sammanhanget.
Frågor med jordning kan ofta vara en nedströmseffekt av sammanhangsrelevans. När LLM saknar tillräckligt sammanhang för att bilda ett evidensbaserat svar, är det mer sannolikt att hallucinera i sitt försök att generera ett rimligt svar. Även i de fall där fullständig och relevant kontext tillhandahålls, kan LLM hamna i problem med jordning. Särskilt har detta utspelat sig i applikationer där LLM svarar i en viss stil eller används för att slutföra en uppgift som den inte är väl lämpad för. Grundade utvärderingar gör det möjligt för TruLens-användare att bryta ner LLM-svar påstående för anspråk för att förstå var LLM oftast hallucinerar. Att göra det har visat sig vara särskilt användbart för att belysa vägen framåt för att eliminera hallucinationer genom förändringar på modellsidan (som uppmaning, modellval och modellparametrar).
Svarsrelevans
Slutligen måste svaret fortfarande besvara den ursprungliga frågan. Du kan verifiera detta genom att utvärdera relevansen av det slutliga svaret på användarinmatningen:
Genom att nå tillfredsställande utvärderingar för denna triad kan du göra ett nyanserat uttalande om din ansökans riktighet; denna applikation är verifierad att vara hallucinationsfri upp till gränsen för dess kunskapsbas. Med andra ord, om vektordatabasen endast innehåller korrekt information, är svaren från den kontextaktiverade frågesvarsappen också korrekta.
Grund sanningsutvärdering
Utöver dessa återkopplingsfunktioner för att upptäcka hallucinationer har vi en testdatauppsättning, DataBricks-Dolly-15k, som gör det möjligt för oss att lägga till grund sanningslikhet som ett fjärde utvärderingsmått. Se följande kod:
Bygg applikationen
När du har ställt in dina utvärderare kan du bygga din ansökan. I det här exemplet använder vi en kontextaktiverad QA-applikation. I den här applikationen ger du instruktionen och sammanhanget till kompletteringsmotorn:
När du har skapat appen och feedbackfunktionerna är det enkelt att skapa en inpackad applikation med TruLens. Denna inpackade applikation, som vi kallar base_recorder, kommer att logga och utvärdera applikationen varje gång den anropas:
Resultat med bas Lama-2
När du har kört applikationen på varje post i testdatasetet kan du se resultaten i din SageMaker-anteckningsbok med tru.get_leaderboard(). Följande skärmdump visar resultatet av utvärderingen. Svarsrelevansen är oroväckande låg, vilket indikerar att modellen kämpar för att konsekvent följa instruktionerna.

Finjustera Llama-2 med SageMaker Jumpstart
Steg för att finjustera Llama-2-modellen med SageMaker Jumpstart finns också i denna anteckningsbok.
För att ställa in för finjustering måste du först ladda ner träningssetet och ställa in en mall för instruktioner
Ladda sedan upp både datasetet och instruktionerna till en Amazon enkel lagringstjänst (Amazon S3) hink för träning:
För att finjustera i SageMaker kan du använda SageMaker JumpStart Estimator. Vi använder för det mesta standardhyperparametrar här, förutom att vi ställer in instruktionsjustering till sant:
När du har tränat modellen kan du distribuera den och skapa din applikation precis som du gjorde tidigare:
Utvärdera den finjusterade modellen
Du kan köra modellen igen på ditt testset och se resultaten, denna gång i jämförelse med basen Llama-2:

Den nya, finjusterade Llama-2-modellen har förbättrats avsevärt vad gäller svarsrelevans och jordadhet, tillsammans med likheten med testsetet för grundsannhet. Denna stora kvalitetsförbättring sker på bekostnad av en liten ökning av latensen. Denna ökning av latens är ett direkt resultat av att finjusteringen ökar storleken på modellen.
Du kan inte bara se dessa resultat i anteckningsboken, utan du kan också utforska resultaten i TruLens UI genom att köra tru.run_dashboard(). Om du gör det kan du ge samma samlade resultat på leaderboard-sidan, men ger dig också möjlighet att dyka djupare in i problematiska poster och identifiera fellägen för applikationen.

För att förstå förbättringen av appen på rekordnivå kan du gå till utvärderingssidan och undersöka feedbackpoängen på en mer detaljerad nivå.
Till exempel, om du ställer den grundläggande LLM frågan "Vilken är den mest kraftfulla Porsche flat sex-motorn", hallucinerar modellen följande.

Dessutom kan du undersöka den programmatiska utvärderingen av denna post för att förstå programmets prestanda mot var och en av de återkopplingsfunktioner du har definierat. Genom att undersöka resultaten för jordad återkoppling i TruLens kan du se en detaljerad uppdelning av de bevis som finns tillgängliga för att stödja varje påstående som görs av LLM.

Om du exporterar samma post för din finjusterade LLM i TruLens, kan du se att finjustering med SageMaker JumpStart dramatiskt förbättrade jordningen av svaret.

Genom att använda ett automatiskt utvärderingsarbetsflöde med TruLens kan du mäta din applikation över en bredare uppsättning mätvärden för att bättre förstå dess prestanda. Viktigt är att du nu kan förstå den här prestandan dynamiskt för alla användningsfall – även de där du inte har samlat grundsanningen.
Hur TruLens fungerar
Efter att du har skapat en prototyp för din LLM-applikation kan du integrera TruLens (visas tidigare) för att instrumentera dess anropsstack. Efter att anropsstacken är instrumenterad kan den sedan loggas vid varje körning till en loggningsdatabas som finns i din miljö.
Förutom instrumenterings- och loggningsmöjligheterna är utvärdering en viktig del av värde för TruLens-användare. Dessa utvärderingar implementeras i TruLens av återkopplingsfunktioner som körs ovanpå din instrumenterade anropsstack, och i sin tur uppmanar externa modellleverantörer att producera feedbacken själv.
Efter feedback slutledning skrivs feedbackresultaten till loggdatabasen, från vilken du kan köra TruLens instrumentpanel. TruLens instrumentpanel, som körs i din miljö, låter dig utforska, iterera och felsöka din LLM-app.
I stor skala kan dessa loggar och utvärderingar skickas till TruEra för observerbarhet i produktionen som kan bearbeta miljontals observationer per minut. Genom att använda TruEra Observability Platform kan du snabbt upptäcka hallucinationer och andra prestandaproblem och zooma in på en enda post på några sekunder med integrerad diagnostik. Genom att flytta till en diagnostisk synvinkel kan du enkelt identifiera och mildra fellägen för din LLM-app som hallucinationer, dålig hämtningskvalitet, säkerhetsproblem och mer.
Utvärdera för ärliga, ofarliga och hjälpsamma svar
Genom att nå tillfredsställande utvärderingar för denna triad kan du nå en högre grad av förtroende för sanningshalten i svaren den ger. Utöver sanningshalten har TruLens brett stöd för de utvärderingar som behövs för att förstå din LLM:s prestanda på axeln "Ärlig, ofarlig och hjälpsam". Våra användare har haft enorm nytta av möjligheten att identifiera inte bara hallucinationer som vi diskuterade tidigare, utan också problem med säkerhet, säkerhet, språkmatchning, koherens med mera. Dessa är alla röriga, verkliga problem som LLM-apputvecklare möter och kan identifieras direkt med TruLens.

Slutsats
Det här inlägget diskuterade hur du kan påskynda produktionen av AI-applikationer och använda grundmodeller i din organisation. Med SageMaker JumpStart, Amazon Bedrock och TruEra kan du distribuera, finjustera och iterera på grundmodeller för din LLM-applikation. Kolla in det här länk för att ta reda på mer om TruEra och prova anteckningsbok själv.
Om författarna
 Josh Reini är en kärnbidragsgivare till TruLens med öppen källkod och grundaren Developer Relations Data Scientist på TruEra där han är ansvarig för utbildningsinitiativ och fostra en blomstrande gemenskap av AI-kvalitetsutövare.
Josh Reini är en kärnbidragsgivare till TruLens med öppen källkod och grundaren Developer Relations Data Scientist på TruEra där han är ansvarig för utbildningsinitiativ och fostra en blomstrande gemenskap av AI-kvalitetsutövare.
 Shayak Sen är CTO och medgrundare av TruEra. Shayak är fokuserad på att bygga system och leda forskning för att göra maskininlärningssystem mer förklarliga, integritetskompatibla och rättvisa.
Shayak Sen är CTO och medgrundare av TruEra. Shayak är fokuserad på att bygga system och leda forskning för att göra maskininlärningssystem mer förklarliga, integritetskompatibla och rättvisa.
 Anupam Datta är medgrundare, VD och chefsforskare för TruEra. Innan TruEra tillbringade han 15 år på fakulteten vid Carnegie Mellon University (2007-22), senast som anställd professor i elektro- och datorteknik och datavetenskap.
Anupam Datta är medgrundare, VD och chefsforskare för TruEra. Innan TruEra tillbringade han 15 år på fakulteten vid Carnegie Mellon University (2007-22), senast som anställd professor i elektro- och datorteknik och datavetenskap.
 Vivek Gangasani är en AI/ML Startup Solutions Architect för generativa AI-startups på AWS. Han hjälper nya GenAI-startups att bygga innovativa lösningar med hjälp av AWS-tjänster och accelererad beräkning. För närvarande är han fokuserad på att utveckla strategier för att finjustera och optimera slutledningsprestanda för stora språkmodeller. På fritiden tycker Vivek om att vandra, titta på film och prova olika kök.
Vivek Gangasani är en AI/ML Startup Solutions Architect för generativa AI-startups på AWS. Han hjälper nya GenAI-startups att bygga innovativa lösningar med hjälp av AWS-tjänster och accelererad beräkning. För närvarande är han fokuserad på att utveckla strategier för att finjustera och optimera slutledningsprestanda för stora språkmodeller. På fritiden tycker Vivek om att vandra, titta på film och prova olika kök.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/deploy-foundation-models-with-amazon-sagemaker-iterate-and-monitor-with-truera/
- : har
- :är
- :inte
- :var
- $UPP
- 1
- 10
- 100
- 11
- 12
- 120
- 125
- 14
- 15 år
- 15%
- 16
- 179
- 72
- 8
- 9
- a
- förmåga
- Able
- Om Oss
- abstraktion
- accelerera
- accelererad
- Acceptera
- exakt
- tvärs
- anpassa
- anpassning
- anpassat
- lägga till
- Dessutom
- adress
- Fördel
- Efter
- igen
- mot
- Avtal
- AI
- AI / ML
- Alla
- tillåter
- tillåter
- längs
- också
- Även
- amason
- Amazon SageMaker
- Amazon Web Services
- an
- och
- svara
- svar
- vilken som helst
- API: er
- app
- Ansökan
- tillämpningar
- tillvägagångssätt
- lämpligt
- appar
- ÄR
- AS
- be
- At
- försök
- augmented
- Automatiserad
- tillgänglig
- AWS
- Axis
- bas
- Baslinje
- BE
- därför att
- blir
- innan
- Där vi får lov att vara utan att konstant prestera,
- tro
- nedan
- fördel
- Bättre
- mellan
- Bortom
- Blogg
- båda
- Box
- Ha sönder
- Fördelning
- bred
- SLUTRESULTAT
- Byggnad
- men
- by
- Ring
- kallas
- KAN
- kapacitet
- Carnegie Mellon
- Carnegie Mellon University
- bära
- Vid
- fall
- Kategori
- utmanar
- Förändringar
- Till Kassan
- chef
- val
- patentkrav
- klass
- klar
- Medgrundare
- koda
- samling
- Kolonner
- kommer
- samfundet
- jämförelse
- fullborda
- slutför
- fullbordan
- kompatibel
- komponent
- komponenter
- omfattande
- Compute
- dator
- Datorteknik
- Datavetenskap
- förtroende
- Bekräfta
- Anslutning
- följder
- konsekvent
- innehåller
- sammanhang
- bidragsgivare
- konvertera
- Kärna
- kärnbidragsgivare
- Korrigerad
- kunde
- täcka
- skapa
- skapas
- Skapa
- kriterier
- kritisk
- CTO
- kurerad
- För närvarande
- Kunder
- instrumentbräda
- datum
- datavetare
- Databas
- databaser
- datauppsättningar
- djupare
- Standard
- definierade
- Examen
- distribuera
- utplacerade
- utplacering
- beskriver
- Trots
- detaljerad
- upptäcka
- Detektering
- Utvecklare
- utvecklare
- utveckla
- Utveckling
- diagnostik
- DID
- olika
- rikta
- diskuteras
- Dyk
- gör
- domäner
- ner
- ladda ner
- dramatiskt
- dynamiskt
- varje
- Tidigare
- lätt
- Utbildning
- effekt
- effektivitet
- eliminera
- inbäddning
- smärgel
- möjliggör
- änden
- Slutpunkt
- Motor
- Teknik
- säkerställa
- Miljö
- speciellt
- väsentlig
- Eter (ETH)
- utvärdera
- utvärdering
- utvärdering
- utvärderingar
- Även
- bevis
- undersöka
- Granskning
- exempel
- Utom
- expanderande
- dyra
- utforska
- export
- extern
- extraktion
- Ansikte
- fakta
- Misslyckande
- verkligt
- Höst
- falsk
- återkoppling
- Figur
- Fil
- slutlig
- hitta
- änden
- Förnamn
- platta
- fokuserade
- följer
- efter
- För
- formen
- bildad
- Framåt
- fundament
- grundande
- Fjärde
- Ramverk
- Fri
- från
- fungera
- funktioner
- ytterligare
- generera
- generering
- generativ
- Generativ AI
- ger
- Go
- stor
- Marken
- styra
- praktisk
- Har
- he
- hjälp
- hjälper
- här.
- högre
- vandring
- hans
- ärlig
- Hur ser din drömresa ut
- How To
- html
- http
- HTTPS
- i
- identifierade
- identifiera
- identifiera
- if
- Illuminating
- bilder
- genomföras
- importera
- viktigt
- förbättra
- förbättras
- förbättring
- in
- I andra
- Inklusive
- Öka
- ökande
- oberoende av
- indikerar
- informationen
- Infrastruktur
- initiativ
- innovativa
- ingång
- ingångar
- instruktioner
- Instrumentet
- integrera
- integrerade
- integrering
- sammankopplade
- in
- Beskrivning
- problem
- IT
- DESS
- sig
- jpg
- json
- bara
- Nyckel
- kunskap
- Brist
- språk
- Large
- Latens
- lager
- ledande
- inlärning
- Nivå
- Bibliotek
- Licens
- livet
- sannolikt
- BEGRÄNSA
- linje
- rader
- Lista
- Bor
- levande
- lokal
- log
- inloggad
- skogsavverkning
- Låg
- Maskinen
- maskininlärning
- gjord
- Majoritet
- göra
- massivt
- Match
- betyder
- mäta
- mätt
- mellon
- metod
- metriska
- Metrics
- miljoner
- minut
- Mildra
- ML
- modell
- modeller
- Modern Konst
- lägen
- Övervaka
- övervakning
- mer
- mest
- för det mesta
- flytta
- Filmer
- rörliga
- måste
- namn
- Natur
- Behöver
- behövs
- behov
- Nya
- Nästa
- Notera
- anteckningsbok
- nu
- vårda
- objektet
- observationer
- of
- sänkt
- erbjuda
- Ofta
- on
- ONE
- endast
- öppet
- öppen källkod
- optimera
- or
- organisation
- ursprungliga
- Övriga
- vår
- ut
- produktion
- sida
- parade
- parametrar
- särskilt
- särskilt
- passera
- utföra
- prestanda
- utför
- rörledning
- Plats
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- plausibel
- spelat
- dålig
- Populära
- Porsche
- Inlägg
- den mäktigaste
- förutse
- VD
- privatpolicy
- problem
- process
- bearbetade
- producera
- producerande
- Produktion
- Professor
- programma
- ge
- förutsatt
- leverantör
- leverantörer
- ger
- sköt
- Python
- Frågor och svar
- kvalitet
- fråga
- frågor
- snabbt
- slumpmässig
- snabbt
- nå
- nå
- verkliga världen
- nyligen
- post
- inspelning
- register
- relationer
- relevans
- relevanta
- tillförlitlighet
- resterna
- ersätta
- begära
- Obligatorisk
- Kräver
- forskning
- respons
- svar
- ansvarig
- resultera
- Resultat
- avkastning
- Körning
- rinnande
- Säkerhet
- sagemaker
- Samma
- Skala
- Vetenskap
- Forskare
- poäng
- Sök
- sekunder
- Sektorer
- säkerhet
- se
- sett
- välj
- mening
- separat
- serverar
- Tjänster
- in
- inställning
- flera
- skall
- show
- visas
- Visar
- Enkelt
- helt enkelt
- enda
- SEX
- Storlek
- So
- Lösningar
- Källa
- spann
- speciell
- spent
- delas
- stapel
- standard
- starta
- start
- Startups
- .
- uttalanden
- Steg
- Fortfarande
- förvaring
- okomplicerad
- strategier
- Herrelös
- struktur
- Kämpar
- stil
- sådana
- tillräcklig
- svit
- stödja
- Stöder
- yta
- System
- skräddarsydd
- uppgift
- uppgifter
- tekniker
- mall
- testa
- Testning
- text
- den där
- Smakämnen
- deras
- sedan
- Där.
- Dessa
- de
- detta
- de
- tre
- blomstrande
- Genom
- Således
- tid
- till
- dagens
- verktyg
- topp
- spår
- Spårning
- traditionell
- Tåg
- tränad
- Utbildning
- oerhört
- TRU
- sann
- sanningen
- prova
- försöker
- SVÄNG
- två
- ui
- förstå
- förståelse
- universitet
- på
- us
- användning
- användningsfall
- Begagnade
- Användare
- användare
- med hjälp av
- Värdefulla
- värde
- mängd
- Omfattande
- verifierade
- verifiera
- verifiera
- via
- Video
- utsikt
- W
- tittar
- Sätt..
- sätt
- we
- webb
- webbservice
- VÄL
- när
- som
- bredare
- kommer
- med
- inom
- ord
- arbetade
- arbetsflöde
- arbetssätt
- Wrapped
- skriva
- skriven
- år
- dig
- Din
- själv
- zephyrnet
- zoom