Resiliens spelar en avgörande roll i utvecklingen av all arbetsbelastning, och generativ AI arbetsbelastningen är inte annorlunda. Det finns unika överväganden när man konstruerar generativa AI-arbetsbelastningar genom en resilienslins. Att förstå och prioritera resiliens är avgörande för generativa AI-arbetsbelastningar för att möta organisatoriska tillgänglighets- och affärskontinuitetskrav. I det här inlägget diskuterar vi de olika stackarna för en generativ AI-arbetsbelastning och vad dessa överväganden bör vara.
Generativ AI i full stack
Även om mycket av spänningen kring generativ AI fokuserar på modellerna, involverar en komplett lösning människor, färdigheter och verktyg från flera domäner. Betrakta följande bild, som är en AWS-vy av a16z framväxande applikationsstacken för stora språkmodeller (LLM).
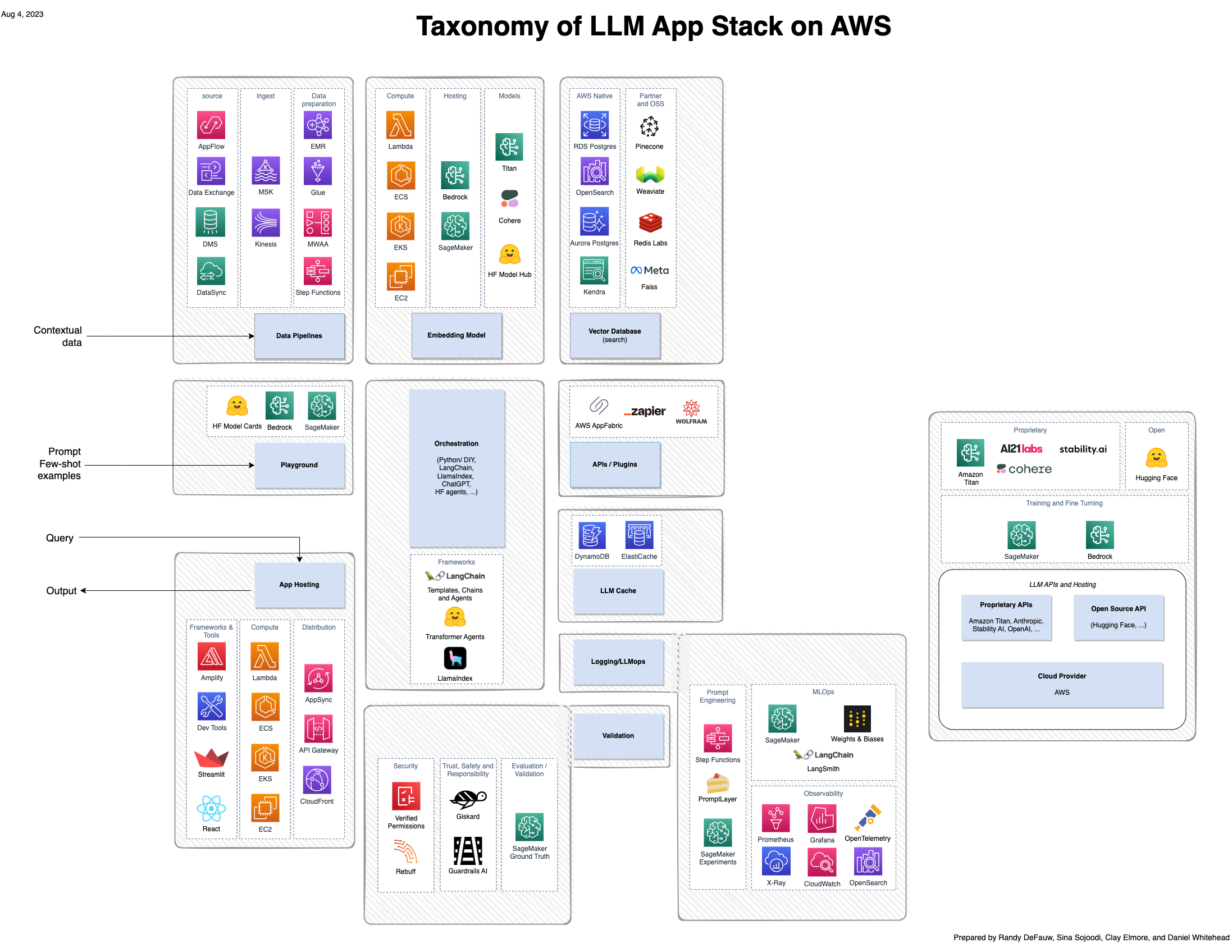
Jämfört med en mer traditionell lösning byggd kring AI och maskininlärning (ML), innebär en generativ AI-lösning nu följande:
- Nya roller – Du måste överväga modelltuners såväl som modellbyggare och modellintegratörer
- Nya verktyg – Den traditionella MLOps-stacken sträcker sig inte till att täcka den typ av experimentspårning eller observerbarhet som krävs för snabb ingenjörskonst eller agenter som anropar verktyg för att interagera med andra system
Agentresonemang
Till skillnad från traditionella AI-modeller tillåter Retrieval Augmented Generation (RAG) mer exakta och kontextuellt relevanta svar genom att integrera externa kunskapskällor. Följande är några överväganden när du använder RAG:
- Att ställa in lämpliga timeouts är viktigt för kundupplevelsen. Ingenting säger dålig användarupplevelse mer än att vara mitt i en chatt och koppla bort.
- Se till att validera promptinmatningsdata och promptinmatningsstorlek för tilldelade teckengränser som definieras av din modell.
- Om du utför prompt ingenjörskonst bör du fortsätta med dina uppmaningar till ett pålitligt datalager. Det kommer att skydda dina meddelanden i händelse av oavsiktlig förlust eller som en del av din övergripande katastrofåterställningsstrategi.
Datapipelines
I de fall du behöver tillhandahålla kontextuella data till grundmodellen med hjälp av RAG-mönstret, behöver du en datapipeline som kan ta in källdata, konvertera den till inbäddningsvektorer och lagra inbäddningsvektorerna i en vektordatabas. Denna pipeline kan vara en batchpipeline om du förbereder kontextuella data i förväg, eller en pipeline med låg latens om du införlivar ny kontextuell data i farten. I batchfallet finns det ett par utmaningar jämfört med typiska datapipelines.
Datakällorna kan vara PDF-dokument på ett filsystem, data från ett SaaS-system (Software as a Service) som ett CRM-verktyg eller data från en befintlig wiki eller kunskapsbas. Intag från dessa källor skiljer sig från de typiska datakällorna som loggdata i en Amazon enkel lagringstjänst (Amazon S3) hink eller strukturerad data från en relationsdatabas. Nivån av parallellitet du kan uppnå kan begränsas av källsystemet, så du måste ta hänsyn till strypning och använda backoff-tekniker. Vissa av källsystemen kan vara sköra, så du måste bygga in felhantering och logik igen.
Inbäddningsmodellen kan vara en prestandaflaskhals, oavsett om du kör den lokalt i pipeline eller anropar en extern modell. Inbäddningsmodeller är grundmodeller som körs på GPU:er och inte har obegränsad kapacitet. Om modellen körs lokalt måste du tilldela arbete baserat på GPU-kapacitet. Om modellen körs externt måste du se till att du inte mättar den externa modellen. I båda fallen kommer nivån av parallellitet du kan uppnå att dikteras av inbäddningsmodellen snarare än hur mycket CPU och RAM du har tillgängligt i batchbehandlingssystemet.
I fallet med låg latens måste du ta hänsyn till den tid det tar att generera inbäddningsvektorerna. Den anropande applikationen bör anropa pipelinen asynkront.
Vektordatabaser
En vektordatabas har två funktioner: lagra inbäddningsvektorer och kör en likhetssökning för att hitta den närmaste k matchar en ny vektor. Det finns tre generella typer av vektordatabaser:
- Dedikerade SaaS-alternativ som Pinecone.
- Vektordatabasfunktioner inbyggda i andra tjänster. Detta inkluderar inbyggda AWS-tjänster som Amazon OpenSearch Service och Amazon-Aurora.
- In-memory-alternativ som kan användas för övergående data i scenarier med låg latens.
Vi täcker inte likhetssökningsmöjligheterna i detalj i det här inlägget. Även om de är viktiga är de en funktionell aspekt av systemet och påverkar inte direkt motståndskraften. Istället fokuserar vi på motståndskraftsaspekterna av en vektordatabas som ett lagringssystem:
- Latens – Kan vektordatabasen prestera bra mot en hög eller oförutsägbar belastning? Om inte måste den anropande applikationen hantera hastighetsbegränsning och backoff och försöka igen.
- skalbarhet – Hur många vektorer kan systemet hålla? Om du överskrider kapaciteten för vektordatabasen måste du undersöka sönderdelning eller andra lösningar.
- Hög tillgänglighet och katastrofåterställning – Inbäddning av vektorer är värdefull data, och att återskapa dem kan bli dyrt. Är din vektordatabas mycket tillgänglig i en enda AWS-region? Har den möjlighet att replikera data till en annan region för katastrofåterställning?
Ansökningsnivå
Det finns tre unika överväganden för applikationsnivån när man integrerar generativa AI-lösningar:
- Potentiellt hög latens – Grundmodeller körs ofta på stora GPU-instanser och kan ha begränsad kapacitet. Se till att använda bästa praxis för hastighetsbegränsning, backoff och försök igen och belastningsminskning. Använd asynkron design så att hög latens inte stör programmets huvudgränssnitt.
- Säkerhetsställning – Om du använder agenter, verktyg, plugins eller andra metoder för att ansluta en modell till andra system, var extra uppmärksam på din säkerhetsställning. Modeller kan försöka interagera med dessa system på oväntade sätt. Följ normal praxis med minsta privilegieåtkomst, till exempel begränsa inkommande meddelanden från andra system.
- Ramverk som utvecklas snabbt – Ramverk med öppen källkod som LangChain utvecklas snabbt. Använd en mikrotjänstmetod för att isolera andra komponenter från dessa mindre mogna ramverk.
Kapacitet
Vi kan tänka på kapacitet i två sammanhang: slutledning och datapipelines för träningsmodeller. Kapacitet är ett övervägande när organisationer bygger sina egna pipelines. CPU- och minneskrav är två av de största kraven när du väljer instanser för att köra dina arbetsbelastningar.
Instanser som kan stödja generativa AI-arbetsbelastningar kan vara svårare att få fram än din genomsnittliga generella instanstyp. Instansflexibilitet kan hjälpa till med kapacitets- och kapacitetsplanering. Beroende på vilken AWS-region du kör din arbetsbelastning i, finns olika instanstyper tillgängliga.
För de användarresor som är kritiska kommer organisationer att vilja överväga att antingen reservera eller förprovisionera instanstyper för att säkerställa tillgänglighet vid behov. Detta mönster uppnår en statiskt stabil arkitektur, vilket är en bästa praxis för motståndskraft. För att lära dig mer om statisk stabilitet i AWS Well-Architected Framework reliability-pelare, se Använd statisk stabilitet för att förhindra bimodalt beteende.
observerbarhet
Förutom de resursmått du vanligtvis samlar in, som CPU och RAM-användning, måste du noggrant övervaka GPU-användningen om du är värd för en modell på Amazon SageMaker or Amazon Elastic Compute Cloud (Amazon EC2). GPU-användningen kan ändras oväntat om basmodellen eller indata ändras, och om det tar slut på GPU-minne kan systemet hamna i ett instabilt tillstånd.
Högre upp i stacken vill du också spåra flödet av samtal genom systemet och fånga interaktionerna mellan agenter och verktyg. Eftersom gränssnittet mellan agenter och verktyg är mindre formellt definierat än ett API-kontrakt, bör du övervaka dessa spår inte bara för prestanda utan också för att fånga nya felscenarier. För att övervaka modellen eller agenten för eventuella säkerhetsrisker och -hot kan du använda verktyg som Amazon Guard Duty.
Du bör också fånga baslinjer för inbäddningsvektorer, uppmaningar, sammanhang och utdata, och interaktionerna mellan dessa. Om dessa förändras över tid kan det tyda på att användare använder systemet på nya sätt, att referensdata inte täcker frågeutrymmet på samma sätt eller att modellens utdata plötsligt är annorlunda.
Katastrofåterställning
Att ha en affärskontinuitetsplan med en katastrofåterställningsstrategi är ett måste för alla arbetsbelastningar. Generativa AI-arbetsbelastningar är inte annorlunda. Att förstå de fellägen som är tillämpliga på din arbetsbelastning hjälper dig att styra din strategi. Om du använder AWS-hanterade tjänster för din arbetsbelastning, t.ex Amazonas berggrund och SageMaker, se till att tjänsten är tillgänglig i din återställnings-AWS-region. När detta skrivs stöder dessa AWS-tjänster inte replikering av data över AWS-regioner, så du måste tänka på dina datahanteringsstrategier för katastrofåterställning, och du kan också behöva finjustera i flera AWS-regioner.
Slutsats
Det här inlägget beskrev hur man tar hänsyn till motståndskraft när man bygger generativa AI-lösningar. Även om generativa AI-applikationer har några intressanta nyanser, gäller fortfarande de befintliga motståndsmönstren och bästa praxis. Det är bara en fråga om att utvärdera varje del av en generativ AI-applikation och tillämpa relevant bästa praxis.
För mer information om generativ AI och användning av den med AWS-tjänster, se följande resurser:
Om författarna
 Jennifer Moran är en AWS Senior Resiliency Specialist Solutions Architect baserad i New York City. Hon har en mångsidig bakgrund och har arbetat inom många tekniska discipliner, inklusive mjukvaruutveckling, agilt ledarskap och DevOps, och är en förespråkare för kvinnor inom teknik. Hon tycker om att hjälpa kunder att designa motståndskraftiga lösningar för att förbättra motståndskraften och talar offentligt om alla ämnen relaterade till motståndskraft.
Jennifer Moran är en AWS Senior Resiliency Specialist Solutions Architect baserad i New York City. Hon har en mångsidig bakgrund och har arbetat inom många tekniska discipliner, inklusive mjukvaruutveckling, agilt ledarskap och DevOps, och är en förespråkare för kvinnor inom teknik. Hon tycker om att hjälpa kunder att designa motståndskraftiga lösningar för att förbättra motståndskraften och talar offentligt om alla ämnen relaterade till motståndskraft.
 Randy DeFauw är Senior Principal Solutions Architect på AWS. Han har en MSEE från University of Michigan, där han arbetade med datorseende för autonoma fordon. Han har också en MBA från Colorado State University. Randy har haft en mängd olika positioner inom teknikområdet, allt från mjukvaruteknik till produkthantering. Han gick in i big data-utrymmet 2013 och fortsätter att utforska det området. Han arbetar aktivt med projekt inom ML-området och har presenterat på ett flertal konferenser, inklusive Strata och GlueCon.
Randy DeFauw är Senior Principal Solutions Architect på AWS. Han har en MSEE från University of Michigan, där han arbetade med datorseende för autonoma fordon. Han har också en MBA från Colorado State University. Randy har haft en mängd olika positioner inom teknikområdet, allt från mjukvaruteknik till produkthantering. Han gick in i big data-utrymmet 2013 och fortsätter att utforska det området. Han arbetar aktivt med projekt inom ML-området och har presenterat på ett flertal konferenser, inklusive Strata och GlueCon.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/designing-generative-ai-workloads-for-resilience/
- : har
- :är
- :inte
- :var
- $UPP
- 100
- 2013
- 90
- a
- A16Z
- förmåga
- Om oss
- tillgång
- oavsiktligt
- Konto
- exakt
- Uppnå
- uppnår
- tvärs
- aktivt
- avancera
- förespråkare
- påverka
- mot
- Recensioner
- medel
- smidig
- AI
- AI-modeller
- Alla
- allokeras
- tillåter
- också
- Även
- amason
- Amazon EC2
- Amazon Web Services
- an
- och
- Annan
- vilken som helst
- api
- app
- tillämplig
- Ansökan
- tillämpningar
- Ansök
- Tillämpa
- tillvägagångssätt
- lämpligt
- arkitektur
- ÄR
- OMRÅDE
- runt
- AS
- aspekt
- aspekter
- At
- uppmärksamhet
- augmented
- autonom
- autonoma fordon
- tillgänglighet
- tillgänglig
- genomsnitt
- AWS
- bakgrund
- Badrum
- bas
- baserat
- BE
- därför att
- Där vi får lov att vara utan att konstant prestera,
- BÄST
- bästa praxis
- mellan
- Stor
- Stora data
- störst
- flaskhals
- SLUTRESULTAT
- byggare
- Byggnad
- byggt
- företag
- kontinuitet i verksamheten
- men
- by
- Ring
- anropande
- Samtal
- KAN
- kapacitet
- Kapacitet
- fånga
- Fångande
- Vid
- fall
- utmaningar
- byta
- Förändringar
- karaktär
- chatt
- välja
- Stad
- nära
- samla
- Colorado
- jämfört
- fullborda
- komponenter
- Compute
- dator
- Datorsyn
- konferenser
- Anslutning
- Tänk
- övervägande
- överväganden
- sammanhang
- kontexter
- kontextuella
- fortsätter
- kontinuitet
- kontrakt
- konvertera
- kunde
- Par
- täcka
- beläggning
- CPU
- kritisk
- CRM
- avgörande
- kund
- kundupplevelse
- Kunder
- datum
- datahantering
- Databas
- databaser
- definierade
- beroende
- beskriven
- Designa
- design
- mönster
- detalj
- Utveckling
- DevOps
- Dikterad
- olika
- svårt
- direkt
- katastrof
- discipliner
- bortkopplad
- diskutera
- flera
- do
- dokument
- gör
- inte
- domäner
- inte
- varje
- antingen
- inbäddning
- smärgel
- Teknik
- säkerställa
- gick in i
- fel
- Eter (ETH)
- utvärdering
- utvecklas
- exempel
- överstiga
- Spänning
- befintliga
- dyra
- erfarenhet
- experimentera
- utforska
- förlänga
- extern
- externt
- extra
- Misslyckande
- Funktioner
- Fil
- hitta
- Flexibilitet
- flöda
- Fokus
- fokuserar
- följer
- efter
- För
- Formellt
- fundament
- Ramverk
- ramar
- från
- funktionella
- funktioner
- Allmänt
- generell mening
- generera
- generering
- generativ
- Generativ AI
- få
- GPU
- GPUs
- styra
- hantera
- Arbetsmiljö
- Har
- har
- he
- Held
- hjälpa
- hjälpa
- Hög
- höggradigt
- hålla
- innehar
- värd
- Hur ser din drömresa ut
- How To
- html
- http
- HTTPS
- if
- med Esport
- förbättra
- in
- innefattar
- Inklusive
- Inkommande
- införlivande
- indikerar
- informationen
- ingång
- exempel
- instanser
- istället
- Integrera
- interagera
- interaktioner
- intressant
- Gränssnitt
- interferera
- in
- innebär
- IT
- Journeys
- bara
- kunskap
- språk
- Large
- Latens
- Ledarskap
- LÄRA SIG
- inlärning
- Lins
- mindre
- Nivå
- tycka om
- Begränsad
- begränsande
- gränser
- llm
- läsa in
- lokalt
- log
- Logiken
- se
- förlust
- Lot
- Maskinen
- maskininlärning
- Huvudsida
- göra
- förvaltade
- ledning
- många
- tändstickor
- Materia
- mogen
- Maj..
- MBA
- Möt
- Minne
- metoder
- Metrics
- Michigan
- microservices
- Mitten
- ML
- MLOps
- modell
- modeller
- lägen
- Övervaka
- mer
- mycket
- multipel
- måste
- nativ
- natively
- nödvändigt för
- Behöver
- behövs
- behov
- Nya
- New York
- new york city
- Nej
- normala
- inget
- nu
- nyanser
- talrik
- få
- of
- Ofta
- on
- endast
- öppet
- öppen källkod
- Tillbehör
- or
- organisatoriska
- organisationer
- Övriga
- ut
- produktion
- över
- övergripande
- egen
- del
- Mönster
- mönster
- Betala
- Personer
- utföra
- prestanda
- utför
- Bild
- Pelare
- rörledning
- svängbara
- Planen
- planering
- plato
- Platon Data Intelligence
- PlatonData
- spelar
- insticksmoduler
- positioner
- Inlägg
- praktiken
- praxis
- Förbered
- presenteras
- förhindra
- Principal
- prioritering
- bearbetning
- Produkt
- produktledning
- projekt
- prompter
- ge
- publicly
- syfte
- sätta
- fråga
- trasa
- RAM
- som sträcker sig
- snabbt
- Betygsätta
- snarare
- återvinning
- hänvisa
- referens
- Oavsett
- region
- regioner
- relaterad
- relevanta
- tillförlitlighet
- pålitlig
- replikation
- Krav
- motståndskraft
- elastisk
- resurs
- Resurser
- svar
- begränsa
- hämtning
- risker
- Roll
- Körning
- rinnande
- kör
- SaaS
- sagemaker
- Samma
- säger
- scenarier
- Sök
- söka
- säkerhet
- säkerhetsrisker
- senior
- service
- Tjänster
- flera
- sharding
- hon
- shedding
- skall
- Enkelt
- enda
- Storlek
- färdigheter
- So
- Mjukvara
- mjukvara som en service
- mjukvaruutveckling
- mjukvaruutveckling
- lösning
- Lösningar
- några
- Källa
- Källor
- Utrymme
- talar
- specialist
- Stabilitet
- stabil
- stapel
- Stacks
- Ange
- Fortfarande
- förvaring
- lagra
- strategier
- Strategi
- strukturerade
- sådana
- stödja
- säker
- system
- System
- Ta
- tar
- taxonomi
- tech
- Teknisk
- tekniker
- Teknologi
- än
- den där
- Smakämnen
- källan
- deras
- Dem
- Där.
- Dessa
- de
- tror
- detta
- de
- hot
- tre
- Genom
- djur
- tid
- till
- verktyg
- verktyg
- ämnen
- spåra
- Spårning
- traditionell
- Utbildning
- prova
- två
- Typ
- typer
- typisk
- typiskt
- förståelse
- Oväntat
- unika
- universitet
- University of Michigan
- obegränsat
- oförutsägbar
- användning
- Begagnade
- Användare
- Användarupplevelse
- användare
- med hjälp av
- BEKRÄFTA
- Värdefulla
- mängd
- fordon
- utsikt
- syn
- vill
- Sätt..
- sätt
- we
- webb
- webbservice
- VÄL
- Vad
- när
- om
- som
- kommer
- med
- Kvinnor
- kvinnor inom teknik
- Arbete
- arbetade
- arbetssätt
- skrivning
- york
- dig
- Din
- zephyrnet